El error thought_signature de Nano Banana 2 (400 INVALID_ARGUMENT) aparece cuando tus solicitudes API multironda omiten el campo thought_signature que el modelo devolvió en su respuesta anterior. Nano Banana 2 (gemini-3.1-flash-image-preview) utiliza pensamiento extendido que genera tokens de razonamiento cifrados, y cada solicitud posterior en la misma conversación debe incluir estas firmas sin modificar. La solución es directa: extraer el campo thoughtSignature de cada respuesta de la API y pasarlo de vuelta en el historial de conversación de tu siguiente solicitud. Si estás usando las funciones de chat del SDK oficial de Google Gen AI, esto se gestiona automáticamente — pero si estás llamando a la API REST directamente, usando endpoints compatibles con OpenAI, o trabajando a través de plataformas como Dify o n8n, necesitas gestionarlo manualmente.
¿Qué es el error de Thought Signature y por qué lo necesita Nano Banana 2?
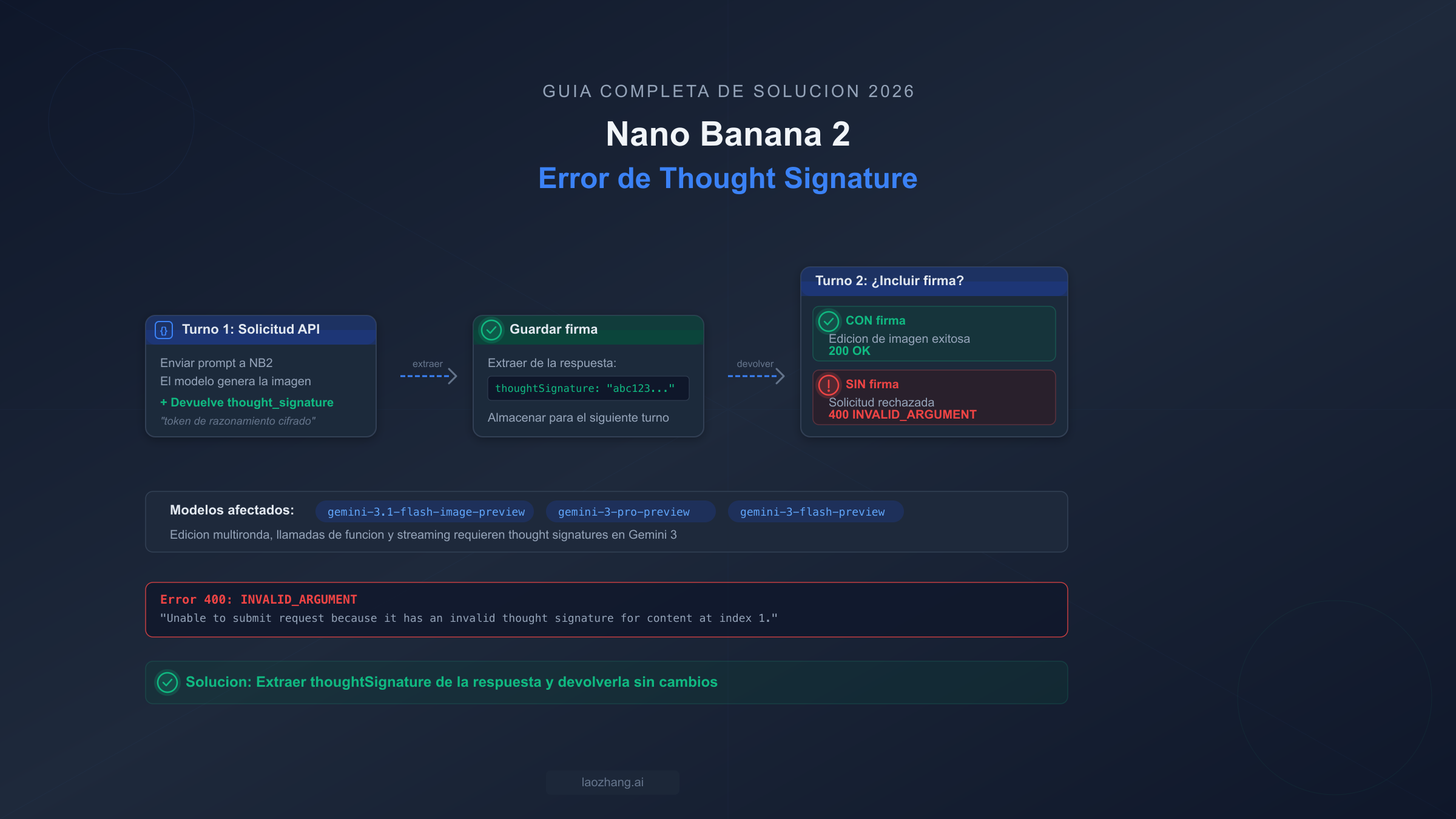
Cuando envías una solicitud multironda a Nano Banana 2 y la API responde con 400 INVALID_ARGUMENT: Unable to submit request because it has an invalid thought signature for content at index N, estás lidiando con uno de los errores más comunes — y más frustrantes — de la familia de modelos Gemini 3. Este error no significa que tu clave API sea incorrecta ni que tu solicitud esté mal formada en el sentido tradicional. Significa que la cadena de razonamiento interno del modelo se ha roto porque falta una pieza requerida de contexto en tu historial de conversación.
Para entender por qué sucede esto, necesitas saber cómo los modelos Gemini 3 manejan el "pensamiento." Cuando Nano Banana 2 (ID de modelo: gemini-3.1-flash-image-preview, documentación de Google AI, marzo 2026) procesa tu solicitud, realiza pensamiento extendido — un paso de razonamiento interno que ayuda al modelo a planificar su respuesta antes de generar la salida. Este paso de pensamiento produce una cadena cifrada llamada thought_signature, que es esencialmente una representación comprimida del proceso de razonamiento del modelo. Piensa en ello como un punto de guardado en un videojuego: el modelo necesita este estado guardado para continuar la conversación de forma coherente en el siguiente turno. Sin él, el modelo no puede verificar que el historial de conversación que recibe sea consistente con lo que realmente generó, y rechaza la solicitud con un error 400.
El detalle crítico que confunde a la mayoría de los desarrolladores es que esta firma se genera incluso cuando estableces explícitamente thinkingConfig: { thinkingBudget: 0 } o configuras el pensamiento en "off." El proceso de pensamiento sigue ejecutándose internamente, y la firma se produce y se requiere de todas formas. La documentación oficial de Google confirma que los tokens de pensamiento siempre se facturan independientemente de tu configuración de pensamiento (ai.google.dev/thought-signatures, marzo 2026). Esto toma desprevenidos a muchos desarrolladores — asumen que desactivar el pensamiento significa que pueden ignorar el campo de firma, solo para encontrar el error 400 en su segundo turno. Si has estado luchando con este error mientras construyes flujos de trabajo de edición de imágenes conversacional, no estás solo: issues en GitHub en Dify (#2262), CherryStudio (#11391), n8n, OpenClaw (#5001) y Pipecat (#3557) todos se remontan a esta misma causa raíz. Para una visión más amplia de otros errores de NB2 más allá de las thought signatures, consulta nuestra guía completa de solución de problemas de Nano Banana 2.
¿Cuándo son obligatorias las Thought Signatures y cuándo son opcionales?

Entender cuándo debes pasar de vuelta las thought signatures versus cuándo puedes ignorarlas de forma segura es la clave para prevenir este error en toda tu base de código. Las reglas difieren entre los modelos Gemini 3 y Gemini 2.5, y difieren nuevamente para el caso de uso de generación de imágenes de Nano Banana 2. Equivocarse en esta decisión significa complejidad innecesaria en tu código o errores 400 inesperados en producción.
Para los modelos Gemini 3 (gemini-3-flash-preview, gemini-3-pro-preview), las thought signatures son obligatorias para todos los escenarios de llamadas de función. Esto significa que si tu aplicación usa herramientas o llamadas de función con Gemini 3, debes extraer y devolver la thought signature en cada turno posterior — sin excepciones. Las llamadas de función secuenciales son particularmente complicadas porque cada paso en la secuencia genera su propia firma, y todas deben incluirse cuando envías los resultados de la función de vuelta. Las llamadas de función paralelas tienen un patrón diferente: solo la primera parte functionCall en la respuesta lleva una firma, así que solo necesitas capturar y devolver esa. Para conversaciones multironda de texto plano sin llamadas de función, las firmas son recomendadas pero no obligatorias en Gemini 3 — lo que significa que no obtendrás un error 400 si las omites, pero Google recomienda incluirlas para una calidad de respuesta óptima.
Para los modelos Gemini 2.5, las reglas son más flexibles. Las thought signatures son opcionales en todos los escenarios — llamadas de función, conversaciones de texto, todo. El modelo aceptará solicitudes con o sin firmas. Sin embargo, si estás construyendo código que necesita funcionar tanto con modelos Gemini 2.5 como Gemini 3, el enfoque más seguro es siempre pasar de vuelta todo lo que el modelo devuelve, incluyendo las firmas.
Nano Banana 2 (gemini-3.1-flash-image-preview) cae en una categoría especial porque se usa principalmente para generación y edición de imágenes multironda. Cuando generas una imagen y luego le pides al modelo que la edite en un turno posterior, la thought signature es obligatoria. Este es el caso de uso principal que trae a la mayoría de los desarrolladores a este error, y está menos documentado que el escenario de llamadas de función. La regla práctica es simple: si estás construyendo cualquier flujo de trabajo multironda con NB2 — ya sea generando una imagen y luego refinándola, teniendo una conversación sobre contenido visual, o encadenando ediciones de imagen — debes manejar las thought signatures. Para una comparación detallada de las capacidades de NB2 versus otros modelos, consulta nuestra comparación de Nano Banana Pro vs Nano Banana 2.
Corregir el error en la generación de imágenes multironda
La edición de imágenes multironda es el caso de uso principal de Nano Banana 2, y es donde la mayoría de los desarrolladores encuentran por primera vez el error de thought signature. El flujo de trabajo es directo — generar una imagen, luego pedir al modelo que la modifique — pero el manejo de la firma añade un paso crítico que es fácil pasar por alto. Aquí está el flujo completo con la extracción de la firma destacada en cada paso.
Implementación en Python usando el SDK de Google Gen AI:
pythonimport google.generativeai as genai import base64 genai.configure(api_key="YOUR_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content( "Generate a photo of a golden retriever playing in a park", generation_config=genai.GenerationConfig( response_modalities=["TEXT", "IMAGE"] ) ) # Paso 2: Extraer la thought signature y la imagen de la respuesta thought_signature = None image_data = None text_response = "" for part in response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: thought_signature = part.thought_signature if hasattr(part, "inline_data") and part.inline_data: image_data = part.inline_data if hasattr(part, "text") and part.text: text_response += part.text print(f"Firma capturada: {thought_signature[:30]}...") # Paso 3: Construir el historial multironda CON la firma history = [ # Tu solicitud original {"role": "user", "parts": [{"text": "Generate a photo of a golden retriever playing in a park"}]}, # La respuesta del modelo — DEBE incluir thought_signature {"role": "model", "parts": []} ] # Reconstruir las partes de la respuesta del modelo con la firma for part in response.candidates[0].content.parts: part_dict = {} if hasattr(part, "text"): part_dict["text"] = part.text if hasattr(part, "inline_data") and part.inline_data: part_dict["inline_data"] = { "mime_type": part.inline_data.mime_type, "data": part.inline_data.data } if hasattr(part, "thought_signature") and part.thought_signature: part_dict["thought_signature"] = part.thought_signature history[-1]["parts"].append(part_dict) # Paso 4: Enviar la solicitud de edición con el historial completo edit_response = model.generate_content( contents=history + [ {"role": "user", "parts": [{"text": "Now add a red frisbee in the dog's mouth"}]} ], generation_config=genai.GenerationConfig( response_modalities=["TEXT", "IMAGE"] ) ) # Paso 5: Extraer la NUEVA firma para posibles ediciones posteriores new_signature = None for part in edit_response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: new_signature = part.thought_signature print(f"Edición exitosa! Nueva firma: {new_signature[:30]}...")
El paso crítico está en el Paso 3: cuando reconstruyes el historial de conversación, la respuesta anterior del modelo debe incluir el campo thought_signature exactamente como fue devuelto. Si lo eliminas, simplificas la respuesta a solo texto y datos de imagen, u olvidas iterar a través de todas las partes, el siguiente turno fallará con el error 400. Cada respuesta de generación de imagen de NB2 incluirá una thought signature en alguna parte de sus partes — tu trabajo es preservarla fielmente.
Implementación en TypeScript:
typescriptimport { GoogleGenerativeAI } from "@google/generative-ai"; const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); // El enfoque más fácil: usar la interfaz de chat const chat = model.startChat({ generationConfig: { responseModalities: ["TEXT", "IMAGE"] } }); // Turno 1: Generar imagen (firma gestionada automáticamente por el SDK) const result1 = await chat.sendMessage("Generate a photo of a sunset over mountains"); // Turno 2: Editar imagen (el SDK pasa la firma automáticamente) const result2 = await chat.sendMessage("Add a silhouette of a person hiking"); // Turno 3: Refinar más const result3 = await chat.sendMessage("Make the colors more vibrant and add lens flare");
El ejemplo de TypeScript usa la interfaz de chat del SDK, que gestiona las firmas automáticamente. Si puedes usar este enfoque, elimina toda la clase de errores de thought signature. El SDK internamente rastrea todas las firmas y las incluye en solicitudes posteriores sin ninguna intervención manual. Este es, con diferencia, el enfoque recomendado para la mayoría de las aplicaciones. Para detalles de precios sobre la generación de imágenes con NB2, consulta nuestro desglose de precios de la API de Nano Banana 2.
Manejar streaming, llamadas paralelas y modo de compatibilidad OpenAI
Las respuestas en streaming, las llamadas de función paralelas y el modo de compatibilidad OpenAI introducen cada uno sus propios casos límite de thought signature que pueden romper silenciosamente tu aplicación. El caso de streaming es particularmente insidioso porque implica una interacción sutil entre cómo funcionan los parsers de stream y dónde aparece realmente la firma en el flujo de respuesta.
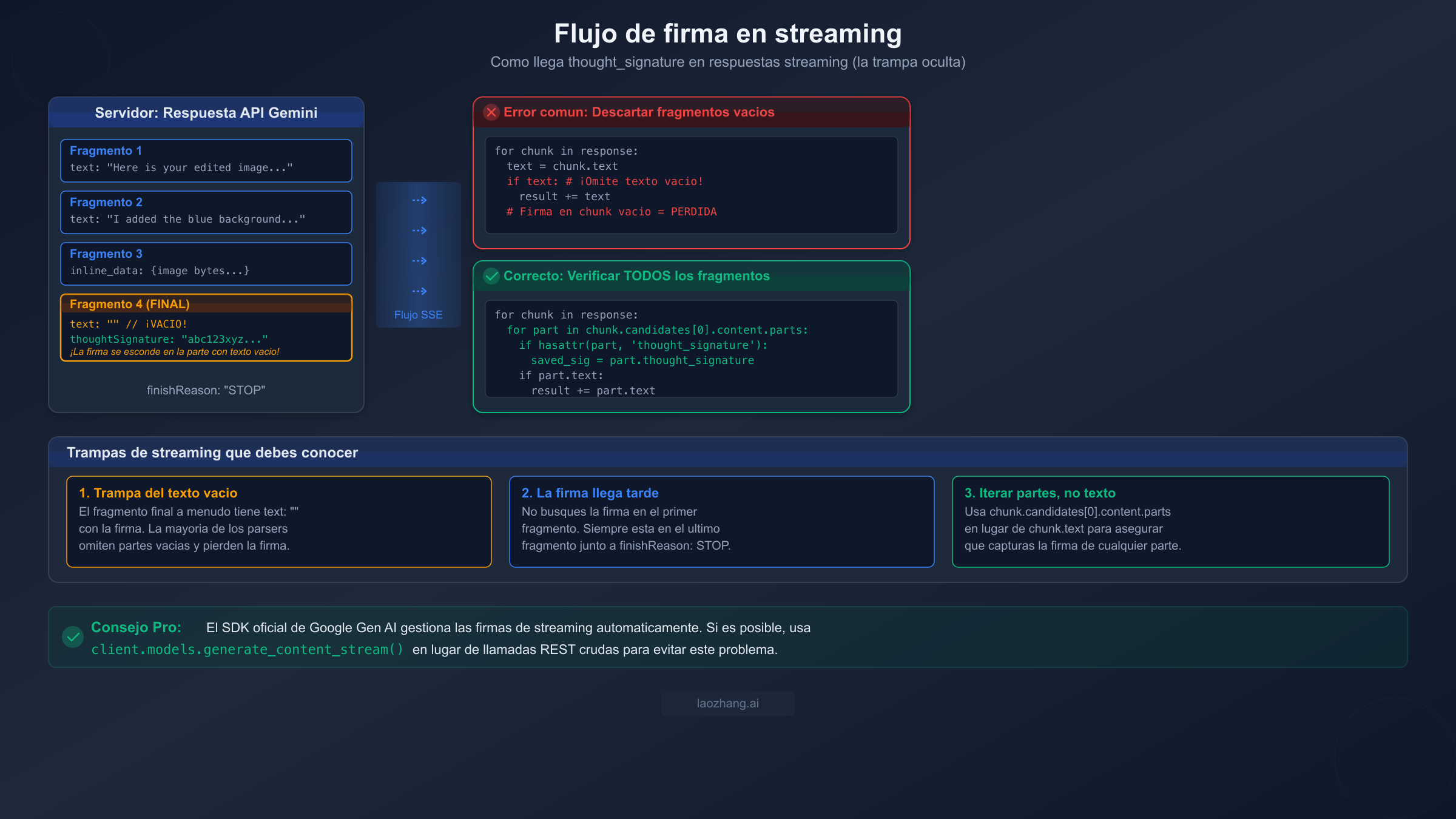
Streaming: La trampa de la parte de texto vacía
Cuando usas streaming con NB2 o cualquier modelo Gemini 3, la thought signature no llega en el primer fragmento ni siquiera en un fragmento intermedio predecible. Llega en el fragmento final del stream, y aquí está la trampa: el fragmento final a menudo contiene una parte con una cadena de texto vacía (text: "") junto al campo thought_signature. La mayoría de los parsers de streaming verifican if chunk.text: para decidir si procesar un fragmento, y una cadena vacía se evalúa como false en la mayoría de los lenguajes. Esto significa que tu parser omite silenciosamente el único fragmento que contiene la firma, y tu siguiente turno falla con un error 400.
La solución es iterar a través de las partes explícitamente en lugar de depender de propiedades de conveniencia:
python# INCORRECTO: Pierde la firma en fragmentos con texto vacío signature = None for chunk in response: if chunk.text: # Cadena vacía = False = ¡firma perdida! result += chunk.text # CORRECTO: Verificar todas las partes en cada fragmento signature = None full_text = "" for chunk in response: for part in chunk.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: signature = part.thought_signature if hasattr(part, "text") and part.text: full_text += part.text
Este patrón asegura que capturas la firma independientemente del fragmento en que aparezca e independientemente de si la parte de texto que la acompaña está vacía. El impacto en el rendimiento es despreciable — simplemente estás iterando a través de partes que ya estarías procesando — pero la mejora en fiabilidad es significativa.
Llamadas de función paralelas
Cuando Gemini 3 devuelve múltiples llamadas de función en una sola respuesta (llamadas de función paralelas), solo la primera parte functionCall lleva una thought signature. Las partes de llamada de función subsiguientes en la misma respuesta no tienen sus propias firmas. Cuando devuelves los resultados de las funciones, necesitas incluir la firma de esa primera parte de llamada de función en tu respuesta. Esto está documentado en la documentación oficial de Google pero es fácil pasarlo por alto cuando estás concentrado en manejar las llamadas de función en sí. Si estás procesando llamadas de función en un bucle y extrayendo firmas de cada una, descubrirás que solo la primera tiene un valor — y esa única firma es la que devuelves.
Modo de compatibilidad OpenAI
Si estás accediendo a modelos Gemini a través de un endpoint compatible con OpenAI (común al migrar desde OpenAI o al usar servicios de gateway), la thought signature se encuentra en una ubicación completamente diferente en la respuesta. En lugar de thought_signature a nivel de parte, está anidada bajo extra_content.google.thought_signature en el objeto del mensaje. Esto atrapa a muchos desarrolladores que están migrando su código de OpenAI para funcionar con Gemini — implementan el manejo de firmas basándose en la documentación de la API nativa de Gemini, pero la capa de compatibilidad con OpenAI estructura la respuesta de manera diferente. La solución es verificar la ruta alternativa del campo cuando se usa el modo de compatibilidad:
python# API nativa de Gemini signature = part.thought_signature # Modo de compatibilidad OpenAI signature = message.get("extra_content", {}).get("google", {}).get("thought_signature")
Ambas rutas necesitan manejarse si tu aplicación soporta múltiples modos de API. Para aplicaciones en producción que necesitan funcionar tanto con endpoints nativos como compatibles, recomendamos abstraer la extracción de firma en una función auxiliar que verifique ambas ubicaciones.
Soluciones avanzadas — Firmas ficticias y migración de modelos
Hay una solución oculta en la documentación oficial de Google que ningún otro artículo ha destacado de forma prominente: las firmas de pensamiento ficticias (dummy thought signatures). Cuando tienes historial de conversación que no fue generado por Gemini 3 — por ejemplo, si estás migrando desde otro modelo, inyectando contexto de conversación sintético, o reconstruyendo historial desde una base de datos que no almacenó firmas — puedes usar una cadena de marcador de posición especial en lugar de una firma real.
Google proporciona dos cadenas de firma ficticia oficiales que evitan el validador de firmas (ai.google.dev/thought-signatures FAQ, marzo 2026):
python# Opción 1: La firma ficticia recomendada dummy_signature = "context_engineering_is_the_way_to_go" # Opción 2: Firma ficticia alternativa dummy_signature = "skip_thought_signature_validator"
Cuando incluyes cualquiera de estas cadenas como el valor de thought_signature en un turno del modelo dentro de tu historial de conversación, la API lo aceptará sin validación. Esto es increíblemente útil para varios escenarios: migrar historiales de conversación existentes de GPT-4 o Claude a Gemini 3, restaurar conversaciones desde bases de datos que no fueron diseñadas para almacenar thought signatures, inyectar turnos de contexto a nivel de sistema que nunca pasaron por el modelo, y probar flujos de trabajo multironda sin necesitar firmas reales.
Sin embargo, hay advertencias importantes que entender antes de depender de firmas ficticias en producción. La firma ficticia le indica al modelo que el contexto de pensamiento del turno asociado no está disponible, lo que significa que el modelo no puede verificar la coherencia del razonamiento de ese turno. Para flujos de trabajo de llamadas de función en Gemini 3, esto puede resultar en una calidad de respuesta ligeramente degradada porque el modelo no puede hacer referencia a su cadena de razonamiento original. Para la edición de imágenes con NB2 específicamente, usar una firma ficticia en el turno de generación de imagen significa que el modelo puede no "recordar" perfectamente las decisiones creativas que tomó, lo que podría afectar la calidad de las ediciones posteriores. El enfoque de firma ficticia funciona mejor como herramienta de migración o respaldo, no como un reemplazo permanente de la gestión adecuada de firmas.
El árbol de decisión práctico es claro: si puedes extraer y almacenar firmas reales, hazlo siempre. Si tienes historial heredado sin firmas, usa firmas ficticias para desbloquear tu migración en lugar de reconstruir todo el historial de conversación desde cero. Y si estás haciendo prototipos o pruebas, las firmas ficticias te permiten enfocarte en la lógica de negocio sin preocuparte por la fontanería de firmas.
Correcciones específicas por plataforma para Dify, CherryStudio, n8n y más
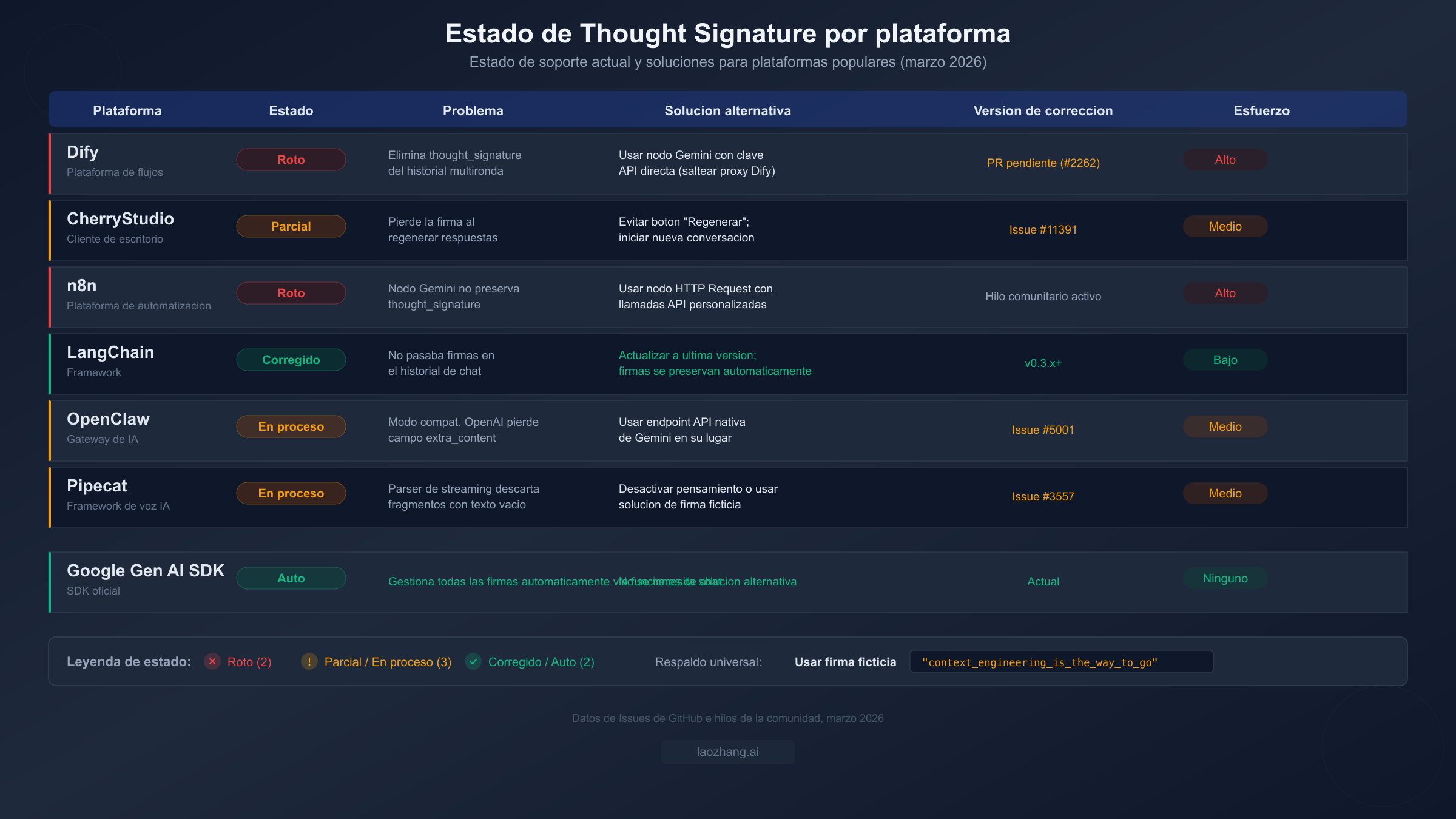
El error de thought signature no es solo un problema de API cruda — también es un problema generalizado en plataformas y herramientas de desarrollo de IA. Cuando usas modelos Gemini 3 a través de Dify, CherryStudio, n8n o plataformas similares, el manejo interno de mensajes de la plataforma a menudo elimina o pierde la thought signature durante la gestión de turnos de conversación. Esto significa que puedes tener credenciales de API y configuración del modelo perfectamente correctas, y aun así encontrar el error 400 porque la plataforma está descartando silenciosamente un campo que no conoce.
Dify es actualmente la plataforma más afectada. La gestión de historial de mensajes de Dify elimina campos no estándar de las respuestas del modelo antes de almacenarlas, y thought_signature se trata como un campo no estándar. Esto significa que las conversaciones multironda con modelos Gemini 3 fallan consistentemente después del primer turno. El problema está registrado en el issue de GitHub #2262, y un pull request para corregirlo está pendiente de revisión. Mientras tanto, la solución alternativa es saltarse la integración integrada de Gemini de Dify y usar el nodo de Solicitud HTTP para llamar directamente a la API de Gemini con tu propia gestión de historial de conversación. Esto requiere más configuración pero te da control total sobre la carga útil de solicitud y respuesta.
CherryStudio tiene un problema más sutil. El cliente de escritorio sí preserva las thought signatures durante el flujo de conversación normal, pero las pierde cuando usas el botón "Regenerar." Cuando CherryStudio regenera una respuesta, reconstruye el historial de conversación sin la firma original del turno que se está regenerando, provocando el error 400. La solución alternativa es directa: evitar usar Regenerar y en su lugar iniciar una nueva conversación o reformular tu mensaje como un nuevo turno. Este problema está registrado en el issue de GitHub #11391.
n8n enfrenta el mismo problema fundamental que Dify — su nodo de Gemini no preserva el campo thought signature en el estado de conversación entre ejecuciones del flujo de trabajo. Para usuarios de n8n, el enfoque recomendado es usar el nodo de Solicitud HTTP en lugar del nodo específico de Gemini, dándote control directo sobre la carga útil de la API. Puedes almacenar la respuesta completa (incluyendo firmas) en los datos del flujo de trabajo de n8n y reconstruir el historial de conversación manualmente en turnos posteriores.
LangChain ya ha corregido este problema en la versión 0.3.x y posteriores. Si estás usando una versión anterior, actualizar a la última versión resuelve el manejo de thought signatures automáticamente. La clase ChatGoogleGenerativeAI de LangChain ahora preserva todos los metadatos de respuesta incluyendo thought signatures al construir el historial de conversación.
OpenClaw y otros servicios de gateway API que ofrecen endpoints compatibles con OpenAI para modelos Gemini tienen un problema diferente: pueden no reenviar el campo extra_content.google.thought_signature de la respuesta de compatibilidad OpenAI. La solución alternativa es usar el endpoint de API nativa de Gemini a través del gateway en lugar del endpoint compatible con OpenAI, o configurar el gateway para preservar todos los campos de respuesta.
Para todas las plataformas, el respaldo universal es la solución de firma ficticia descrita en la sección anterior. Si una plataforma elimina tu firma real, puedes inyectar "context_engineering_is_the_way_to_go" como el valor de firma en tu historial de conversación para mantener la conversación fluyendo, aunque con las advertencias de calidad mencionadas anteriormente.
Manejador de Thought Signature listo para producción
Para aplicaciones en producción que necesitan un manejo robusto de thought signatures en todos los escenarios — edición de imágenes, llamadas de función, streaming y múltiples modos de API — aquí hay una clase de manejador reutilizable que encapsula todos los casos límite cubiertos en esta guía.
pythonclass ThoughtSignatureHandler: """Gestiona thought signatures en conversaciones Gemini multironda.""" DUMMY_SIGNATURES = [ "context_engineering_is_the_way_to_go", "skip_thought_signature_validator" ] def __init__(self): self.signatures = {} # turn_index -> signature def extract_from_response(self, response, turn_index: int) -> str | None: """Extrae la thought signature de una respuesta de la API de Gemini.""" sig = None if hasattr(response, "candidates") and response.candidates: for part in response.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: sig = part.thought_signature break if sig: self.signatures[turn_index] = sig return sig def extract_from_stream(self, stream, turn_index: int): """Extrae la firma de una respuesta en streaming, emitiendo fragmentos.""" sig = None for chunk in stream: if hasattr(chunk, "candidates") and chunk.candidates: for part in chunk.candidates[0].content.parts: if hasattr(part, "thought_signature") and part.thought_signature: sig = part.thought_signature yield chunk if sig: self.signatures[turn_index] = sig def extract_from_openai_compat(self, message: dict, turn_index: int) -> str | None: """Extrae la firma del formato de respuesta compatible con OpenAI.""" sig = (message.get("extra_content", {}) .get("google", {}) .get("thought_signature")) if sig: self.signatures[turn_index] = sig return sig def get_signature(self, turn_index: int, fallback_dummy: bool = False) -> str | None: """Obtiene la firma almacenada para un turno, con respaldo ficticio opcional.""" sig = self.signatures.get(turn_index) if sig is None and fallback_dummy: return self.DUMMY_SIGNATURES[0] return sig def build_history_part(self, part_data: dict, turn_index: int) -> dict: """Asegura que una parte de respuesta del modelo incluya su thought signature.""" sig = self.signatures.get(turn_index) if sig and "thought_signature" not in part_data: part_data["thought_signature"] = sig return part_data
Este manejador cubre los tres escenarios principales de extracción (respuesta estándar, streaming y compatibilidad OpenAI), almacena firmas por índice de turno y proporciona un respaldo a firmas ficticias cuando las reales no están disponibles. El método extract_from_stream es un generador que emite fragmentos de forma transparente mientras captura la firma de cualquier fragmento que la contenga — puedes incorporarlo en código de streaming existente sin cambiar tu lógica de procesamiento.
Para aplicaciones TypeScript, el patrón equivalente es aún más simple porque puedes usar la interfaz de chat del SDK, que gestiona todo automáticamente. Si debes usar llamadas REST crudas en TypeScript, aplica la misma lógica de extracción usando encadenamiento opcional:
typescriptconst extractSignature = (response: any): string | undefined => { return response?.candidates?.[0]?.content?.parts ?.find((p: any) => p.thoughtSignature)?.thoughtSignature; };
Al construir sistemas de producción, considera también implementar el manejo de límites de tasa junto con la gestión de firmas, ya que NB2 tiene límites de tasa estrictos que pueden combinarse con errores de firma para crear modos de fallo confusos. Consulta nuestra guía completa de límites de tasa de Nano Banana 2 para más detalles. Para equipos que necesitan mayor rendimiento o límites de tasa relajados para la generación de imágenes con NB2, servicios como laozhang.ai ofrecen acceso alternativo a la API a precios competitivos ($0.05/imagen frente a los ~$0.067/imagen estándar a 1K tokens).
FAQ — Preguntas frecuentes sobre Thought Signatures
¿Nano Banana 2 siempre devuelve un thought_signature en su respuesta?
Sí. Cada respuesta de NB2 y otros modelos Gemini 3 incluye una thought signature, incluso cuando el pensamiento está configurado en "off" o thinkingBudget es 0. El proceso de pensamiento siempre se ejecuta internamente, y la firma siempre se genera. No puedes optar por no generar la firma — solo puedes elegir si pasarla de vuelta (lo cual siempre deberías hacer).
¿Qué sucede si uso la firma incorrecta o una firma de una conversación diferente?
La API rechazará la solicitud con el mismo error 400 INVALID_ARGUMENT. Las firmas están criptográficamente vinculadas al turno específico de conversación que las generó. No puedes intercambiar firmas entre conversaciones ni entre turnos dentro de la misma conversación. La firma de cada turno debe usarse exactamente una vez, en exactamente la posición donde fue generada.
¿El SDK oficial de Google Gen AI gestiona las thought signatures automáticamente?
Sí, cuando usas la interfaz de chat del SDK (model.startChat() en TypeScript o model.start_chat() en Python). El SDK gestiona internamente todo el historial de conversación incluyendo las thought signatures. Si usas model.generate_content() directamente con historial de conversación construido manualmente, eres responsable de la gestión de firmas tú mismo.
¿Puedo almacenar thought signatures en una base de datos para uso posterior?
Sí, y deberías hacerlo si tu aplicación necesita reanudar conversaciones entre sesiones. Almacena la respuesta completa del modelo incluyendo la thought signature para cada turno. Al reanudar, reconstruye el historial de conversación con todas las firmas almacenadas. Si tienes turnos donde las firmas no se almacenaron (datos heredados), usa la firma ficticia "context_engineering_is_the_way_to_go" como marcador de posición.
¿Se factura el campo thought_signature? ¿Cuenta para mi uso de tokens?
Los tokens de pensamiento que generan la firma siempre se facturan, independientemente de tu configuración de thinkingBudget (ai.google.dev, marzo 2026). Sin embargo, la cadena de firma en sí es una representación cifrada compacta y no aumenta significativamente el tamaño de la solicitud cuando se pasa de vuelta. El impacto en la facturación está en la computación de pensamiento inicial, no en la transmisión de la firma.
¿Por qué el error dice "invalid thought signature" en lugar de "missing thought signature"?
El mensaje de error Unable to submit request because it has an invalid thought signature for content at index N cubre ambos casos: firmas faltantes (donde el campo está completamente ausente) y firmas corruptas (donde el campo existe pero contiene datos incorrectos). El "at index N" te indica qué turno en tu historial de conversación es problemático — verifica la respuesta del modelo en ese índice para asegurarte de que incluye la thought signature original.