No existe un único límite universal para la API de Gemini. En Gemini Developer API, el contrato activo depende del proyecto, el modelo, el nivel de uso, la métrica y la modalidad de servicio. Google dirige a los desarrolladores a AI Studio para consultar los valores vigentes y advierte que los límites publicados no equivalen a capacidad garantizada.
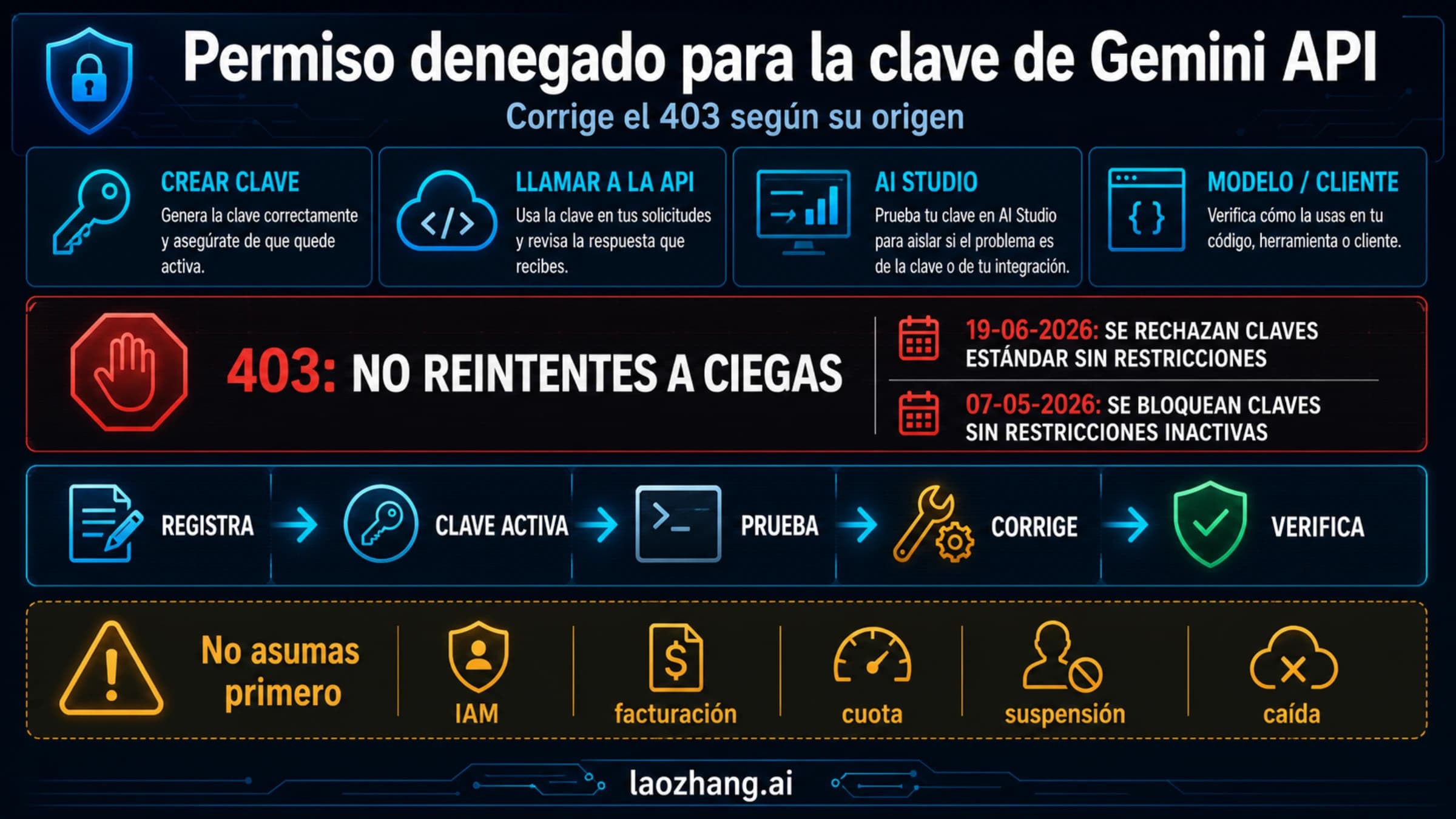
Cuando una llamada falla, conserva el estado HTTP y el cuerpo completo del error antes de cambiar el código o la facturación. 429 RESOURCE_EXHAUSTED es la rama documentada de límite agotado; 503 UNAVAILABLE corresponde a indisponibilidad o capacidad temporal. Reintentar a ciegas no crea cuota diaria, no repone un saldo prepago ni eleva un tope de gasto.
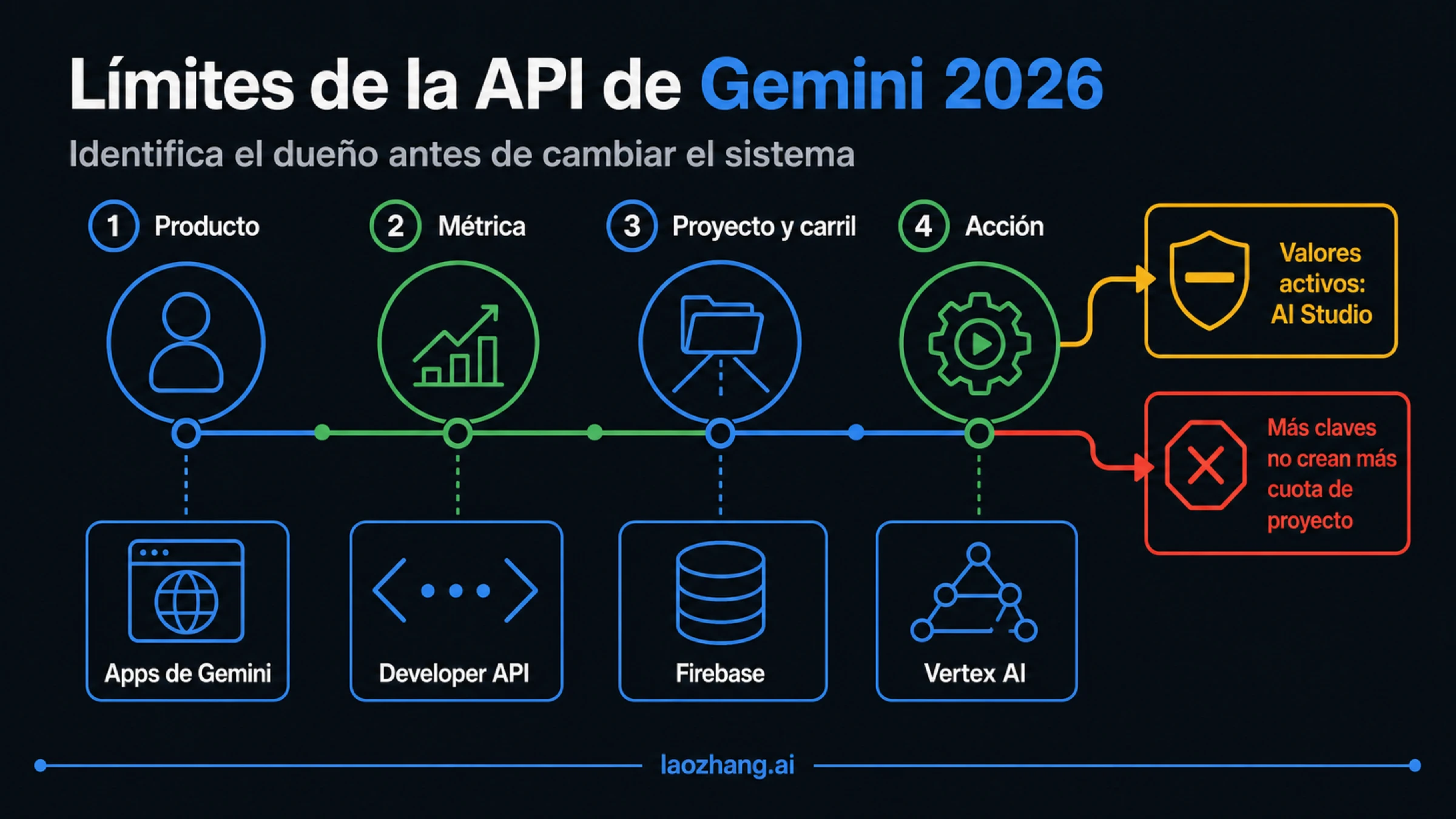
Empieza por el producto de Google que recibió la llamada
La palabra «Gemini» identifica varios productos, pero esos productos no comparten un solo contrato de cuota. Reconoce la superficie por el SDK, el endpoint, el proyecto y la autenticación; el nombre del modelo, por sí solo, no basta.
| Superficie | Quién posee el límite | Primera comprobación | Regla para detener una rama equivocada |
|---|---|---|---|
| Aplicaciones Gemini | Cuenta de consumidor, plan, modelo y función | Límites de las aplicaciones Gemini y cuenta iniciada | Una suscripción de la aplicación no demuestra capacidad de API |
| Gemini Developer API | Proyecto, modelo, nivel de uso, métrica y modalidad | Proyecto y modelo exactos en AI Studio | Otra clave del mismo proyecto no crea un nuevo fondo de cuota |
| Firebase AI Logic | Cuota del proveedor más límite por usuario de la pasarela Firebase | Cuotas de Firebase, App Check y luego estado del proveedor | Un límite de pasarela no es una cuota de proyecto de Developer API |
| Vertex AI | Proyecto de Google Cloud, ubicación, endpoint y contrato de capacidad | Cuotas de Cloud y estado de pago por uso o Provisioned Throughput | No apliques los valores de AI Studio al tráfico de Vertex |
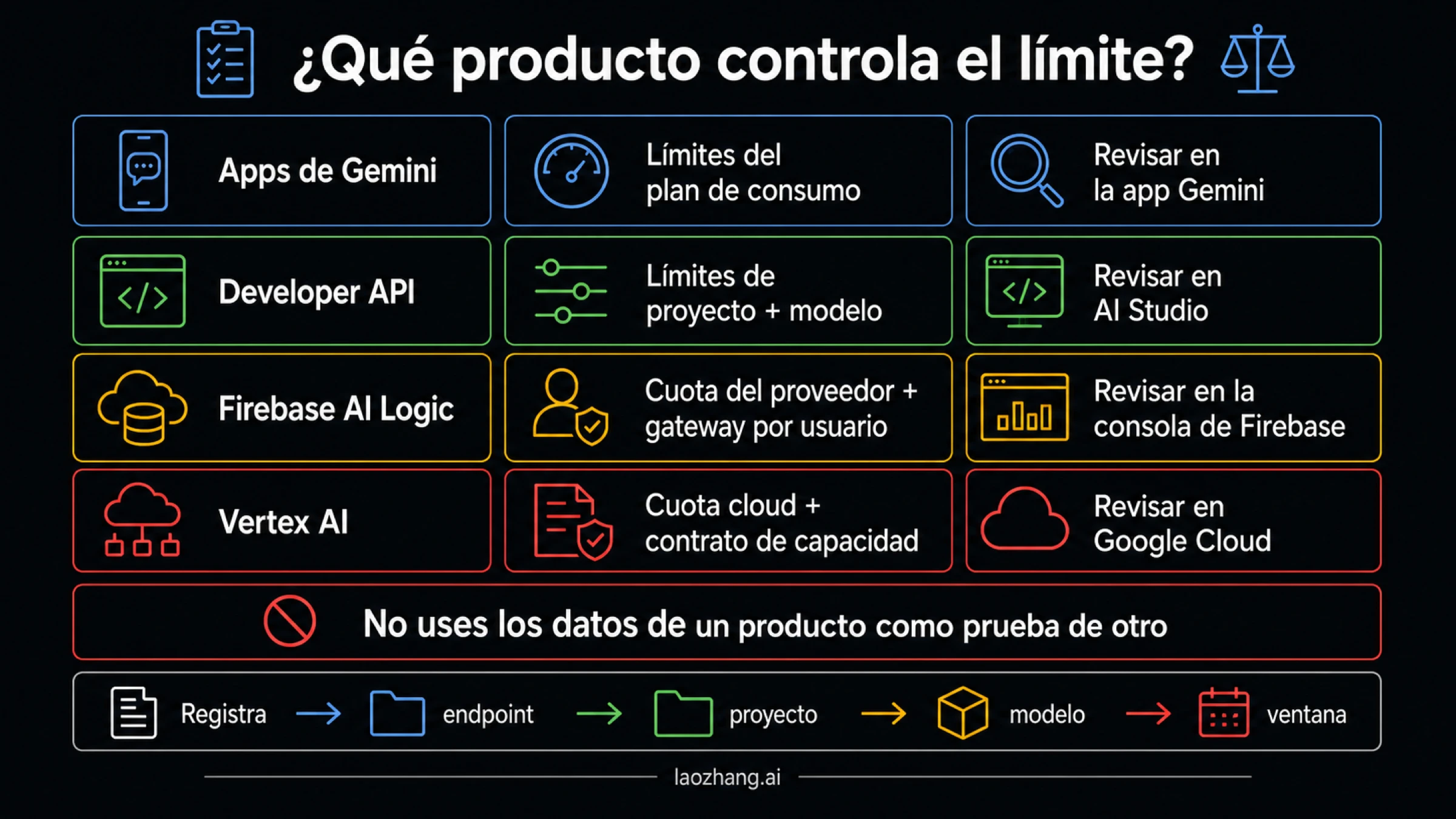
Esta separación resuelve contradicciones aparentes. Una persona puede agotar el cupo de una función de la aplicación Gemini mientras su proyecto de Developer API aún responde. Un cliente de Firebase puede pasar la cuota del modelo y chocar con el límite por usuario de la pasarela. Vertex AI puede devolver 429 por capacidad de Google Cloud aunque la misma familia de modelos también aparezca en AI Studio.
Aquí, «Developer API» significa tráfico con clave de API bajo el contrato documentado en ai.google.dev. Firebase y Vertex AI mantienen capas de cuota propias. Si no puedes indicar el endpoint y el proyecto de la llamada fallida, todavía no sabes qué límite estás investigando.
El contrato de Developer API es métrica × proyecto × modelo × nivel
La documentación oficial de límites define tres métricas básicas y especifica que los límites se aplican por proyecto, no por clave de API. También cambian según el modelo y el nivel de uso.
| Métrica | Qué mide | Señal típica de presión | Ventana o reinicio | Cambio que sí puede ayudar |
|---|---|---|---|---|
| RPM | Solicitudes por minuto | Muchas llamadas cortas o workers sincronizados | Ventana de un minuto | Encolar, distribuir llegadas, limitar concurrencia y cachear duplicados |
| TPM de entrada | Tokens de entrada por minuto | Historial largo, contexto recuperado grande o prompts extensos en paralelo | Ventana de un minuto | Recortar contexto, dividir documentos y espaciar trabajos largos |
| RPD | Solicitudes por día | Volumen sostenido durante el día | Según el contrato actual, medianoche del Pacífico | Esperar el reinicio, reducir demanda diaria u obtener capacidad apta |
Superar cualquiera de las dimensiones aplicables puede producir un 429. Estar por debajo de RPM no excluye haber agotado TPM de entrada; enviar prompts pequeños no excluye RPD. «Solo hice unas pocas llamadas» no es una prueba hasta sumar producción, staging, cuadernos, tareas cron, compañeros y todas las claves del mismo proyecto.
Algunos modelos y modalidades añaden dimensiones como tokens por día (TPD), imágenes por minuto (IPM) o límites de Batch. No son cifras universales de Gemini: pertenecen al modelo y a la ruta concretos. Si la evidencia apunta a IPM o generación de imágenes, usa la guía específica del error 429 en Gemini Image.
Dos reglas evitan la mayoría de los diagnósticos falsos:
- La frontera de agregación es el proyecto. Rotar claves dentro del mismo proyecto cambia credenciales, no capacidad. Producción, desarrollo, scripts y procesos por lotes pueden consumir el mismo fondo.
- AI Studio posee el valor activo. La documentación pública explica la mecánica, pero Google avisa que los valores indicados no están garantizados. Consulta el proyecto y el modelo exactos en la vista de límites activos.

Los modelos preview y experimentales suelen tener límites más estrictos. La disponibilidad del modelo y su acceso gratuito o de pago cambian de forma independiente a la mecánica de cuota. Si esa es la duda pendiente, revisa la guía del nivel gratuito de Gemini API antes de interpretar un 429 como un problema de reintentos.
Identifica al propietario del límite en sesenta segundos
Empieza con un paquete de evidencia que sobreviva al traspaso entre equipos. Para la llamada fallida, registra:
- superficie del producto y endpoint completo;
- ID de proyecto y propietario de la clave, sin guardar el secreto;
- modelo exacto y modalidad de servicio;
- código HTTP, estado y mensaje completos;
- hora de la solicitud con zona horaria;
- tamaño de entrada, concurrencia y número reciente de reintentos;
- vista de uso de AI Studio o Google Cloud para el mismo intervalo.
Después sigue este orden fijo:
- Superficie: ¿aplicación Gemini, Developer API, Firebase AI Logic o Vertex AI?
- Estado: ¿es un evento de límite 429 o un evento temporal 503?
- Métrica: ¿RPM, TPM de entrada, RPD, gasto, saldo, Priority o Batch puede explicar el fallo?
- Agregación: ¿qué proyecto o cuenta de facturación posee ese control y qué cargas lo comparten?
- Modalidad: ¿Standard interactivo, Priority, Batch, pasarela Firebase o capacidad de Vertex?
- Consola: ¿la consola del propietario coincide con el error en la misma franja horaria?
- Acción: cambia la opción mínima que puede afectar al propietario demostrado.
- Verificación: repite una carga representativa y observa la misma métrica y tasa de error.
La tabla convierte síntomas en decisiones y, sobre todo, impone una condición de parada:
| Observación | Propietario probable | Acción mínima útil | Cómo verificar | Cuándo detenerse |
|---|---|---|---|---|
| Los picos fallan, pero el mismo volumen espaciado funciona | RPM o presión temporal | Encolar y suavizar llegadas; limitar concurrencia | Baja el 429 por minuto sin perder trabajo | No aumentes reintentos si recrean el pico |
| Los prompts largos fallan y los cortos pasan | TPM de entrada | Reducir contexto, dividir entrada y programar trabajos largos | Baja TPM y termina el mismo trabajo | Una nueva clave del mismo proyecto no cambia nada |
| Todo falla tras uso sostenido durante el día | RPD | Esperar el reinicio del Pacífico o cambiar capacidad apta | Se recupera tras el reinicio o aumento aprobado | El backoff no crea solicitudes diarias |
| El fallo coincide con avisos de gasto, crédito o facturación | Control financiero | Separar nivel, gasto móvil, saldo y topes | Se corrige el estado y vuelve el servicio | «Facturación activada» no es prueba suficiente |
| Los trabajos offline presionan la experiencia interactiva | Modalidad de servicio | Mover trabajo apto a Batch | Baja la utilización interactiva y termina el job | No sondees Batch como si fuera síncrono |
| Uso y error no coinciden | Desajuste desconocido o del proveedor | Preservar evidencia y escalar por la misma ruta | Soporte relaciona proyecto, modelo, endpoint y hora | No ocultes la discrepancia con un fallback antes de capturarla |
No confundas nivel, gasto móvil, saldo y topes
Los 429 relacionados con dinero son fáciles de diagnosticar mal porque varios controles aparecen cerca. Comprobados el 14 de julio de 2026, los documentos oficiales distinguen al menos cuatro propietarios:
| Control | Comportamiento documentado en esa fecha | Lo que no demuestra |
|---|---|---|
| Nivel de uso | Tier 1 exige una cuenta de facturación activa; Tier 2, al menos $100 pagados y 3 días desde el primer pago correcto; Tier 3, al menos $1,000 pagados y 30 días | Cumplir el umbral no garantiza servicio inmediato ni ilimitado |
| Límite móvil de gasto | Para 10 minutos: no aplica en Free, $10 en Tier 1 y $200 en Tier 2 y Tier 3 | No es lo mismo que RPM, RPD, tope de proyecto o tope de cuenta |
| Saldo prepago | En cuentas asignadas a Prepay, el servicio de pago puede exigir saldo positivo | Haber activado la facturación antes no prueba que hoy haya saldo utilizable |
| Topes de gasto | Los topes de proyecto y de cuenta de facturación tienen semánticas y retrasos distintos | Elevar un tope no evita los límites por proyecto y modelo |
La documentación de facturación indica que el nivel de límites se determina en la cuenta de facturación, mientras que las solicitudes de Developer API siguen agregándose por proyecto. Dos proyectos vinculados pueden optar al mismo nivel sin convertirse en un solo fondo de solicitudes. Del mismo modo, elevar el tope de gasto de un proyecto no elimina una cuota dura del modelo.
Trata estas cifras de julio como valores fechados, no como promesas permanentes. Antes de mover tráfico de producción, vuelve a abrir la sección oficial de niveles de uso y límites de gasto y la vista activa del proyecto. El estado de la cuenta, el historial de pagos, la elegibilidad y el retraso de los informes pueden cambiar el resultado.
Ejemplo: un proyecto Tier 2 recibe 429 aunque RPM parece bajo. Si el uso pagado reciente cruza el límite móvil de gasto, añadir concurrencia o claves solo crea más fallos. Si ese control está sano pero el saldo Prepay llegó a cero, esperar un minuto tampoco sirve. Si ambos están bien y RPD está agotado, pagar de nuevo sigue siendo la acción equivocada. Nombra al propietario antes de tocar la palanca.
Elige Standard, Priority o Batch antes de comprar capacidad
La modalidad de servicio forma parte del contrato de límite. No es una etiqueta que se añade después del incidente.
| Modalidad | Cuándo encaja | Contrato de capacidad | Regla operativa |
|---|---|---|---|
| Standard interactivo | Llamadas de usuario que necesitan respuesta inmediata | Límites interactivos por proyecto, modelo y nivel | Suavizar picos, limitar concurrencia y respetar el presupuesto de latencia |
| Priority | Trabajo elegible que necesita procesamiento prioritario bajo contrato de pago | Tiene un límite Priority; el valor predeterminado documentado es 0.3× del límite Standard correspondiente y además cuenta para el uso interactivo | Comprueba margen Priority y margen interactivo antes de migrar tráfico |
| Batch | Evaluaciones, enriquecimiento, indexación y trabajos asíncronos grandes | Límites separados de jobs concurrentes, archivos, almacenamiento y tokens encolados por modelo y nivel | Diseña para finalización asíncrona y divide trabajos cuando importen resultados parciales |
El multiplicador de Priority y las restricciones de Batch son volátiles; los valores anteriores se verificaron el 14 de julio de 2026. La guía de Batch API describe una finalización asíncrona de hasta 24 horas y avisa que crear un job no es idempotente. Asigna un ID duradero en el cliente, persiste el nombre devuelto y no interpretes un timeout de creación como permiso para enviar duplicados.
Batch no significa «más reintentos en otro lugar». Es un contrato de planificación distinto. Ayuda cuando el trabajo puede esperar y quieres proteger el tráfico interactivo; no ayuda a la persona que espera la respuesta actual y conserva límites propios de cola, archivos y almacenamiento.
Reintenta solo si el tiempo o la forma del tráfico cambian el resultado
La guía oficial de solución de problemas separa 429 RESOURCE_EXHAUSTED de 503 UNAVAILABLE. Haz esa clasificación antes de entrar en un bucle de reintento.
| Estado | Significado | Decisión de reintento |
|---|---|---|
429 RESOURCE_EXHAUSTED | Un límite de frecuencia, tokens, día, gasto u otro control bloqueó la llamada | Reintenta solo si esperar o suavizar puede liberar esa frontera; detente ante RPD, saldo, gasto o cuota dura |
503 UNAVAILABLE | El servicio no está disponible o carece de capacidad temporal | Usa backoff exponencial acotado con jitter; si persiste, considera un modelo más ligero o una ruta elegible |
| Otros 4xx | Autenticación, permisos, entrada, precondición de facturación o solicitud no compatible | Corrige la solicitud o la cuenta; no repitas sin cambios |
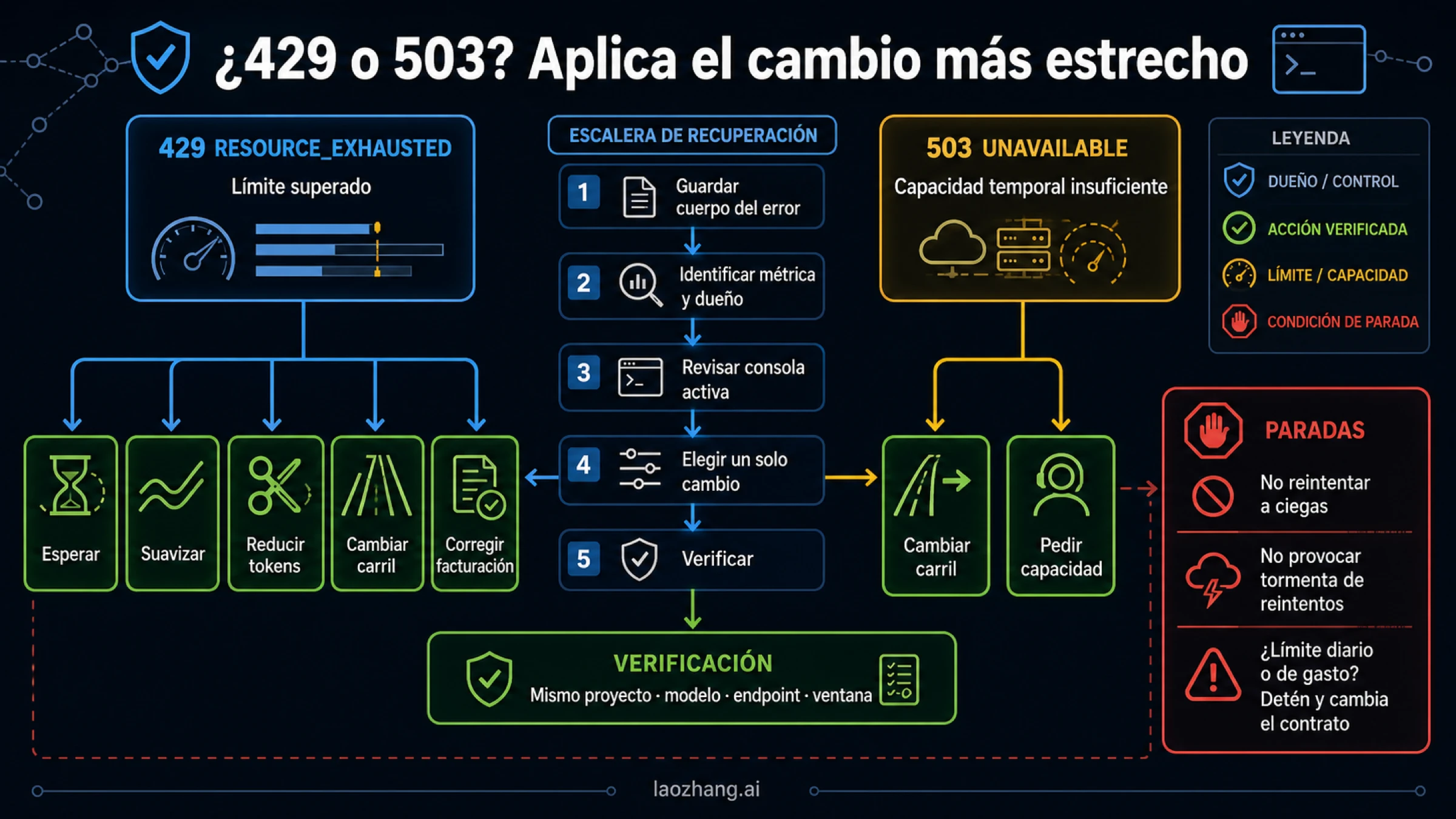
El siguiente helper obliga al llamador a decidir si un 429 es transitorio. Esa fricción deliberada evita que un wrapper genérico martillee una frontera dura.
javascriptconst sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms)); export async function withGeminiRetry(run, { maxAttempts = 5, baseDelayMs = 750, maxDelayMs = 20_000, isTransient429 = () => false, onRetry = () => {}, } = {}) { let lastError; for (let attempt = 1; attempt <= maxAttempts; attempt += 1) { try { return await run(); } catch (error) { lastError = error; const status = Number(error?.status ?? error?.code ?? 0); const retryable = status === 503 || status === 500 || status === 504 || (status === 429 && isTransient429(error)); if (!retryable || attempt === maxAttempts) throw error; const exponential = Math.min( maxDelayMs, baseDelayMs * 2 ** (attempt - 1), ); const delayMs = Math.floor(Math.random() * exponential); onRetry({ attempt, status, delayMs, message: error?.message }); await sleep(delayMs); } } throw lastError; }
Coloca un limitador de concurrencia fuera del helper. De lo contrario, diez workers pueden despertar juntos y convertir la recuperación en el siguiente pico. Usa idempotencia cuando la operación lo permita, cachea trabajo duplicado y acota el tiempo total de reintento al presupuesto visible para el usuario.
Para un 429, isTransient429 solo debe devolver true cuando la evidencia indique que esperar puede cambiar al propietario, por ejemplo un pico breve de RPM sin agotar RPD. Debe devolver false si falta saldo, RPD está agotado, existe un tope de gasto o la solución exige cambiar configuración o capacidad.
Firebase AI Logic añade una capa de cuota de pasarela
Firebase AI Logic no sustituye la cuota del proveedor. Su documentación de cuotas explica que los límites del proveedor siguen aplicándose y tienen prioridad, mientras la pasarela Firebase añade un límite configurable por usuario. Verificado el 14 de julio de 2026, el valor predeterminado documentado es 100 RPM por usuario.
Eso produce dos ramas válidas. Muchos usuarios pueden agotar la cuota del proyecto o modelo aunque cada uno permanezca bajo el límite de Firebase. A la inversa, un cliente defectuoso o abusivo puede superar el límite por usuario cuando el proveedor todavía tiene capacidad.
Comprueba la capa Firebase, la identidad de App Check y el uso del proveedor para la misma llamada. Elevar el valor por usuario no amplía la capacidad del proveedor. Aumentar la cuota del proveedor tampoco borra un límite de seguridad deliberadamente bajo. Cambia solo la capa que dejó evidencia.
Vertex AI posee un contrato de capacidad 429 diferente
Vertex AI usa endpoints, proyectos, ubicaciones y controles de capacidad de Google Cloud. La guía de 429 de Vertex AI distingue pago por uso de Provisioned Throughput y asigna mensajes y soluciones diferentes.
En pago por uso, puede ser útil emplear un endpoint global cuando sea compatible, suavizar tráfico, aplicar reintentos acotados, solicitar cuota para modelos sujetos a cuota o cambiar el plan de capacidad. Con Provisioned Throughput, comprueba si el tráfico cabe dentro del rendimiento comprado y si el exceso se atiende como pago por uso. Conserva el mensaje exacto: Google Cloud lo usa para identificar la rama.
No diagnostiques tráfico de Vertex solo desde AI Studio. Empieza por el proyecto de Cloud, endpoint, ubicación, vista de cuota y estado de Provisioned Throughput. Consulta la comparación entre Gemini API y Vertex AI si la decisión pendiente es elegir plataforma y no recuperar un límite.
Usa una escalera de capacidad que cambie al propietario demostrado
Una vez identificado el propietario, elige la acción duradera más pequeña:
- Elimina desperdicio: cachea trabajo duplicado, recorta contexto repetido, bloquea reintentos recursivos y cancela solicitudes abandonadas.
- Da forma a la demanda: encola picos, limita concurrencia por proyecto y modelo, y reserva margen para el tráfico interactivo.
- Cambia a una modalidad apta: mueve trabajo offline a Batch; usa Priority solo si su contrato y su margen encajan.
- Cambia la forma del trabajo: utiliza un modelo más ligero que cumpla la tarea, divide entradas largas o reduce procesamiento innecesario.
- Corrige al propietario financiero: repón un saldo elegible, ajusta el tope correcto o espera a que se cumpla la antigüedad del nivel.
- Obtén capacidad: solicita un aumento de límite o adopta la ruta apropiada de Vertex AI cuando necesites controles de Google Cloud.
- Diversifica después del diagnóstico: si el riesgo demostrado es la concentración de proveedor y no un error de cuota local, evalúa una arquitectura de fallback multimodelo.
Una pasarela como laozhang.ai puede evaluarse para ese último trabajo de integración. No amplía la cuota de un proyecto de Google. Antes de enviar producción por una ruta alternativa, prueba equivalencia del modelo, políticas de timeout y failover, idempotencia, tratamiento de datos, observabilidad y coste.
Cada cambio de capacidad necesita una señal de verificación. Observa la misma métrica que falló, en el mismo proyecto y modelo, bajo una carga representativa. «El despliegue terminó» no verifica una cuota. La prueba útil es una tasa 429 menor, latencia estable, ausencia de trabajo duplicado y utilización de tokens y solicitudes dentro del margen previsto.
Preguntas frecuentes
¿Dónde puedo ver mis límites actuales de Gemini API?
Abre AI Studio y selecciona el proyecto y el modelo exactos. Los documentos públicos explican RPM, TPM de entrada, RPD, niveles y modalidades, pero indican que los límites publicados no están garantizados. La vista activa es la fuente operativa para tu proyecto.
¿Los límites se aplican por clave de API o por proyecto?
En Gemini Developer API se aplican por proyecto, no por clave. Varias claves del mismo proyecto comparten el fondo. Separa proyectos por límites reales de propiedad, facturación, gobierno o carga, no como rotación de claves disfrazada de planificación de capacidad.
¿Cuándo se reinicia el RPD de Gemini API?
El contador RPD documentado se reinicia a medianoche, hora del Pacífico. Confirma primero que RPD sea la métrica agotada: RPM, TPM, gasto, saldo, Firebase y Vertex usan ventanas o contratos distintos.
¿Por qué activar la facturación no corrigió mi 429?
Porque la facturación es solo uno de los posibles propietarios. El proyecto aún puede haber agotado RPM, TPM de entrada, RPD, gasto móvil, un tope, Priority o un límite del modelo. Una cuenta Prepay también puede no tener saldo positivo. Comprueba cada control por separado.
¿Priority ofrece más capacidad de Gemini API?
Priority es un contrato elegible con un límite propio y sus solicitudes también cuentan en el uso interactivo. No es un multiplicador automático para cualquier proyecto. Comprueba en vivo el margen de Priority y Standard antes de mover tráfico.
¿Batch evita los límites interactivos?
Batch tiene límites separados y sirve para trabajo asíncrono, pero no es ilimitado. Impone fronteras de jobs concurrentes, archivos, almacenamiento y tokens encolados, y un job puede tardar hasta 24 horas. Úsalo cuando el trabajo pueda esperar.
¿Debo reintentar todos los errores 429 de Gemini?
No. Reintenta solo si el tiempo o la forma del tráfico pueden liberar al propietario. El backoff acotado ayuda ante un pico breve; no crea RPD, repone saldo, eleva topes ni concede capacidad. Los problemas de IPM pertenecen a la rama de generación de imágenes descrita antes.
¿Qué envío a soporte si el uso y el error no coinciden?
Envía el cuerpo completo de la respuesta, hora y zona, ID de proyecto, modelo, endpoint, modalidad, tamaño de entrada, concurrencia reciente y una vista de uso del mismo intervalo. Elimina claves y datos de usuario. Si el estado pertenece a permisos o credenciales, sigue la guía de permisos de la API de Gemini en lugar de tratarlo como un límite.
La regla práctica
Nombra el producto, la métrica, la frontera de agregación, la modalidad y la acción correctiva antes de cambiar código, facturación o arquitectura. Comprueba el propietario activo, haz un solo cambio que pueda afectarlo y repite la misma carga. Si una frontera dura sigue agotada, deja de reintentar: espera el reinicio correcto, reduce demanda, elige una modalidad apta u obtén capacidad.