
A 20 de mayo de 2026 UTC, Gemini 3.5 Flash es un modelo GA/stable de Gemini API y se llama con gemini-3.5-flash. El veredicto corto: merece una primera prueba cuando tu trabajo combina agentes de código, flujos largos con herramientas, entrada multimodal y contexto amplio.
No lo trates como sustituto automático de todos los modelos Flash. Si necesitas generación de imágenes, generación de audio, Live API, Computer Use o el pipeline masivo más barato, empieza por otra ruta. Que el modelo sea fuerte no significa que el runtime contract encaje con tu producto.
| Decisión | Prueba Gemini 3.5 Flash primero cuando | Evita o compara primero cuando |
|---|---|---|
| Usarlo | Hay codificación agentic, tool-heavy workflow, contexto largo, entrada multimodal, structured outputs e iteración rápida. | El trabajo es extracción barata, traducción masiva, voz en tiempo real, salida de imagen, salida de audio o control de UI/browser. |
| Tratarlo como oficial | En código, configuración y logs usas gemini-3.5-flash. | No reutilizas precios de Gemini 3 Flash, supuestos preview ni model strings antiguos. |
| Migrar con prueba | Ya usas Gemini 3 Flash, Flash-Lite, Live o Pro y buscas una ruta más fuerte para agentes o código. | No cambias el default de producción sin comparar los mismos prompts, tools, token budget y failure cases. |
En la instantánea oficial del 20 de mayo de 2026, Gemini 3.5 Flash acepta text, image, video, audio y PDF input, y devuelve text output. La ventana de entrada figura como 1,048,576 tokens y la salida máxima como 65,536 tokens. La misma tabla de precios muestra Standard a $1.50 / 1M input tokens y $9.00 / 1M output tokens. La pregunta útil no es solo si es potente, sino si su mejora en agentes, código y long context justifica esa ruta para tu workload.
Estado oficial y model ID
Gemini 3.5 Flash no es un apodo de Gemini 3 Flash ni una etiqueta informal. Google AI for Developers lo lista como modelo estable y el API model ID que importa es gemini-3.5-flash. El changelog de Gemini API también registra la salida del modelo el 19 de mayo de 2026.
Esa diferencia afecta la implementación. gemini-3-flash-preview, Flash-Lite, Live y Pro tienen precios, salidas, funciones y modos de ejecución distintos. Ver la palabra Flash no autoriza a copiar precios antiguos ni a asumir que todas las capacidades del árbol Flash se comportan igual.
Mantén model ID, serving mode, Developer API o Vertex AI, Batch/Flex/Priority y owner de logs en una capa de configuración. Así el equipo puede evaluar, hacer rollback y presupuestar por ruta real, no por nombre comercial.
Si vienes siguiendo dudas sobre Gemini 3.2 Flash, separa ese seguimiento del material sobre Gemini 3.2 Flash. La decisión actual es más concreta: un contrato oficial para 3.5 Flash y una prueba real para saber si mejora tu sistema.
Dónde destaca
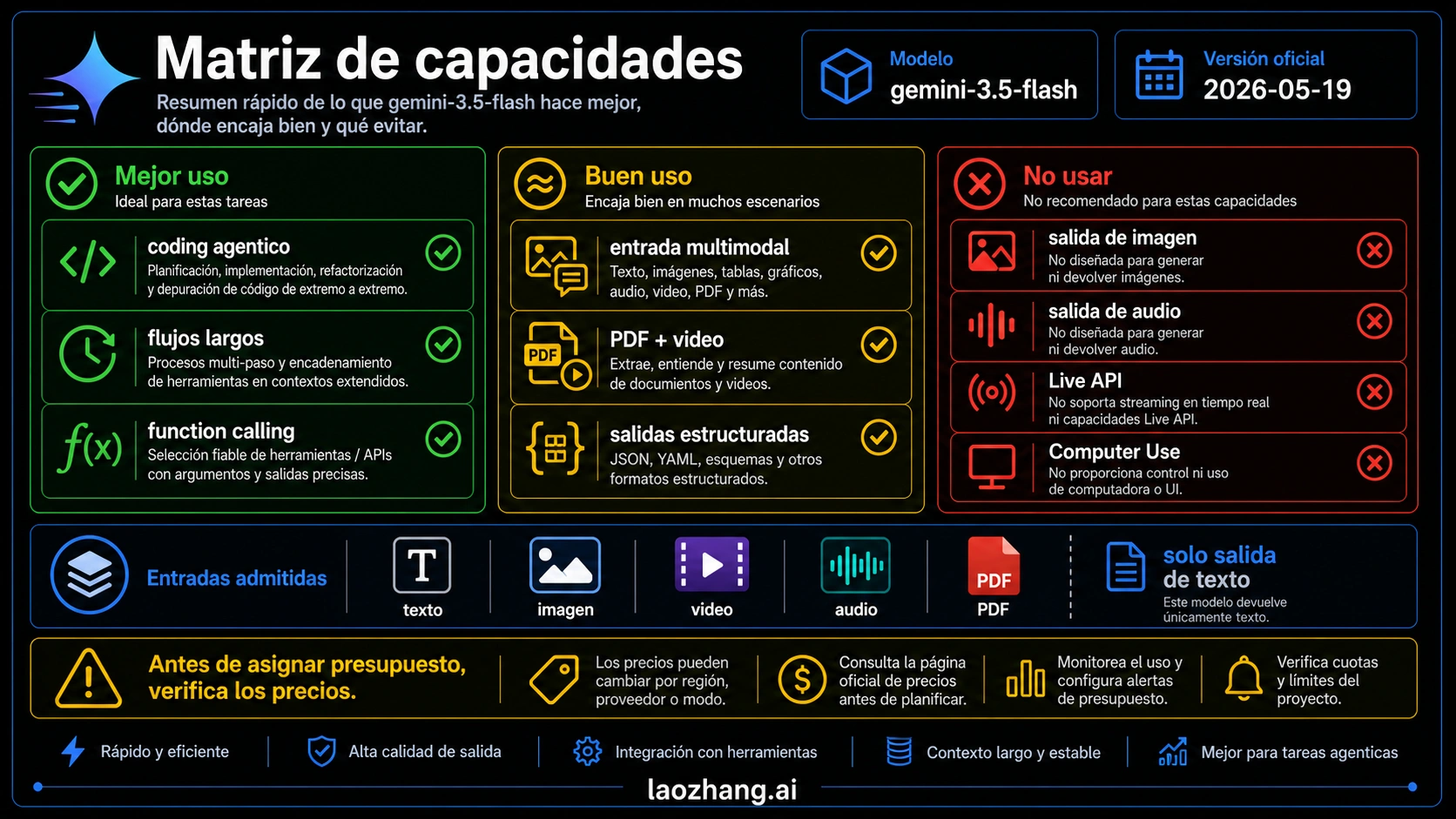
Gemini 3.5 Flash encaja mejor cuando una sola llamada debe razonar, usar herramientas, leer mucho contexto y entender varios tipos de entrada. Los casos naturales son coding agents, asistentes internos con herramientas, análisis de PDFs largos, tickets de soporte con capturas, incidentes con audio o video, respuestas con grounding, tareas file-heavy y salidas JSON que necesitan validación.
La página oficial del modelo lista Batch API, caching, code execution, file search, function calling, Google Maps grounding, Google Search grounding, structured outputs, thinking, URL context, Flex inference y Priority inference. Eso describe una superficie de backend, no solo un chat corto. Puede formar parte de flujos donde importan herramientas, archivos, validación y prioridad de ejecución.
La entrada también es amplia: text, image, video, audio y PDF. La salida es texto. Esa combinación sirve para sistemas que leen material complejo y devuelven una decisión, un plan de corrección, JSON, una checklist o el siguiente paso operativo. No significa que genere imágenes o audio.
| Workload | Encaje | Por qué |
|---|---|---|
| Coding agent y tool workflow | Alto | Function calling, code execution, structured outputs y long context afectan directamente el resultado. |
| Asistente documental multimodal | Alto | PDF, imágenes, video, audio y texto pueden entrar en la misma evaluación. |
| Backend con grounding | Bueno | URL context y Google Search grounding ayudan a respuestas verificables. |
| Evaluaciones batch u offline | Bueno con revisión de coste | Batch/Flex puede bajar precio si la latencia lo permite. |
| Extracción simple a gran volumen | Comparar antes | Flash-Lite u otra ruta low-cost puede ganar por margen. |
La demanda en español suele mezclar velocidad, bajo costo, razonamiento y agentes. Para una decisión de producto, lo importante es más específico: si reduce fallos de herramientas, reintentos, revisión humana y errores de salida en el trabajo real.
Límites que cambian la decisión
La página actual del modelo no presenta Gemini 3.5 Flash como ruta de image generation, audio generation, Live API o Computer Use. Esa lista no es secundaria; define qué producto puedes construir con seguridad.
Si necesitas conversación de voz en tiempo real, revisa un modelo de Live API. Si necesitas salida de imagen, usa una ruta de imagen de Gemini o Imagen. Si necesitas controlar navegador o UI, elige un modelo con Computer Use explícito. No intentes compensar un runtime incorrecto con más inteligencia del modelo.
| Requisito | ¿Gemini 3.5 Flash? | Ruta más segura |
|---|---|---|
| Respuesta textual desde entrada multimodal | Sí | gemini-3.5-flash |
| Agente de voz en tiempo real | No | Live API model |
| Generación de imágenes | No | Gemini image o Imagen |
| Generación de audio | No | Live/audio route |
| Control de UI o navegador | No | Modelo con Computer Use |
| Pipeline masivo al menor precio | No por defecto | Flash-Lite, Batch/Flex u otra opción low-cost |
La regla de producción es simple: primero output type y runtime, después calidad. Si ese orden se invierte, puedes elegir un modelo muy bueno que aun así no sirve para el contrato del producto.
Cómo leer el precio

En el corte oficial del 20 de mayo de 2026, Google lista Gemini 3.5 Flash Standard a $1.50 / 1M input tokens y $9.00 / 1M output tokens. Batch y Flex figuran a $0.75 / 1M input y $4.50 / 1M output. Priority figura a $2.70 / 1M input y $16.20 / 1M output.
No leas Flash como sinónimo de barato. Standard es la ruta normal para llamadas online. Batch/Flex sirve para trabajos offline, evaluaciones y tareas donde esperar es aceptable. Priority paga más por tráfico donde la prioridad vale más que el precio.
| Modo | Precio input | Precio output | Uso principal |
|---|---|---|---|
| Standard | $1.50 / 1M | $9.00 / 1M | Online calls, piloto inicial, backend normal. |
| Batch / Flex | $0.75 / 1M | $4.50 / 1M | Evaluaciones, jobs offline, trabajos tolerantes a latencia. |
| Priority | $2.70 / 1M | $16.20 / 1M | Tráfico con prioridad alta o menor tolerancia a cola. |
Los output tokens dominan rápido en generación de código, reportes largos y reparación iterativa. Aun así, calcula el costo completo del workflow: si una ruta más cara reduce reintentos, errores de tool calling y revisión humana, puede resultar más barata en la operación total.
Para límites gratuitos y cuotas, usa la guía de free tier de Gemini API. La capacidad gratuita y los rate limits dependen del proyecto, modelo, región, billing state y serving mode.
Primera prueba API
La primera prueba no debería ser una pregunta genérica. Usa el trabajo que realmente quieres mejorar: un trace de coding agent, un PDF largo, un incidente multimodal, una salida estructurada o una cadena con tool calls.
tsimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }); const response = await ai.models.generateContent({ model: "gemini-3.5-flash", contents: [ { role: "user", parts: [ { text: "Analyze this failing coding-agent trace. Return the likely owner, first verification step, and safe rollback plan.", }, ], }, ], }); console.log(response.text);
Registra model ID, serving mode, input tokens, output tokens, latency, éxito de tools, validez de structured output, reintentos y tiempo de revisión humana. Si tu operación exige IAM, auditoría, región, facturación Cloud o Vertex AI, combina la prueba con Gemini API vs Vertex AI API.
Smoke test antes de migrar
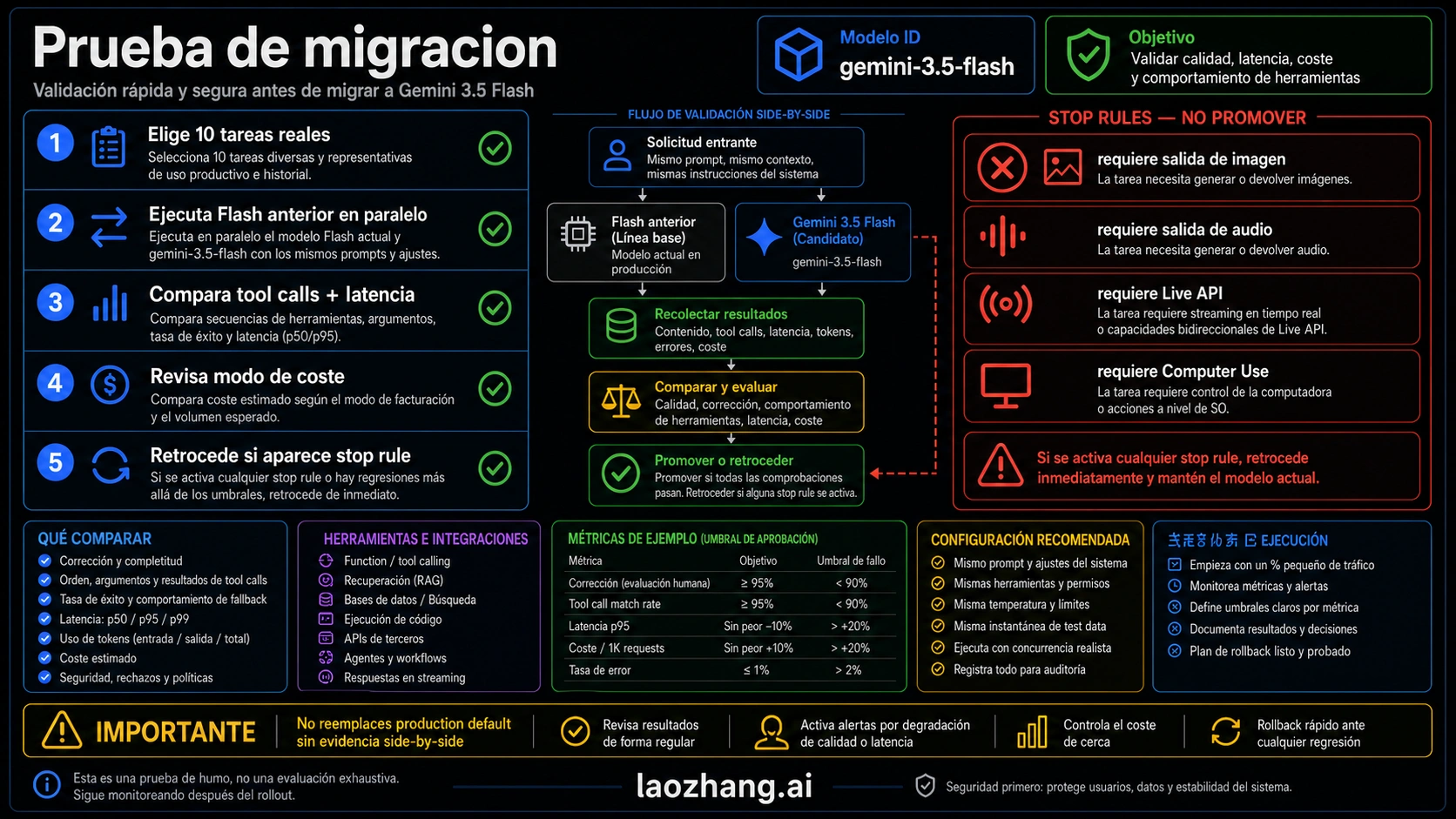
No cambies el default de producción solo porque el modelo es nuevo. Compara tareas iguales, con criterios iguales.
- Elige cinco tareas reales donde el modelo actual falla, cuesta demasiado o requiere demasiada edición humana.
- Ejecuta la ruta actual y
gemini-3.5-flashcon los mismos inputs. - Compara calidad final, tool correctness, JSON validity, latency, token use, retry count y review time.
- Calcula Standard y luego revisa Batch/Flex si la latencia lo permite.
- Migra solo el workload que supere el umbral definido y conserva rollback al model string anterior.
| Ruta actual | Cuándo probar 3.5 Flash | Cuándo conservarla |
|---|---|---|
| Gemini 3 Flash | Necesitas mejor agente, código o long context. | La ruta actual ya es precisa y más barata. |
| Flash-Lite | Los fallos de calidad cuestan más que el ahorro. | El trabajo es simple, masivo y sensible al precio. |
| Flash Live | Dejas voz y pasas a backend de texto. | El producto sigue siendo voz en tiempo real. |
| Pro route | Quieres iteración más rápida o barata en tareas no críticas. | La precisión crítica justifica Pro. |
La migración debe ser por workload, no por marca. Un equipo puede mover agentes de código a 3.5 Flash, dejar extracción masiva en Flash-Lite y mantener voz en Live API.
Preguntas frecuentes
¿Gemini 3.5 Flash está oficialmente disponible?
Sí. Google AI for Developers lista gemini-3.5-flash como modelo GA/stable y el changelog de Gemini API registra la salida el 19 de mayo de 2026. Revisa las páginas oficiales antes de prometer precio o disponibilidad.
¿Cuál es el API model ID?
Usa gemini-3.5-flash. No lo cambies por gemini-3-flash-preview, gemini-3.5-flash-preview ni otra cadena antigua salvo que la documentación de tu ruta lo indique.
¿Para qué sirve mejor?
Para codificación agentic, flujos largos con herramientas, entrada multimodal, structured outputs, file-heavy tasks, URL context, Google Search grounding y trabajos que aprovechan una ventana de entrada de 1,048,576 tokens.
¿Sirve para generar imágenes o audio?
No como ruta principal. El contrato actual indica text output y no presenta Gemini 3.5 Flash como image generation ni audio generation.
¿Soporta Live API o Computer Use?
No aparece así en la página del modelo revisada. Para voz en tiempo real, usa Live API. Para control de UI/browser, usa un modelo con Computer Use explícito.
¿Es más barato que Gemini 3 Flash?
No lo supongas. La Standard price actual es $1.50 / 1M input y $9.00 / 1M output. Calcula con la tabla oficial y tu mezcla real de entrada y salida.
¿Debería migrar desde Gemini 3 Flash?
Solo si una prueba lado a lado mejora tu workload real. Es una gran candidata para agentes, código y long context, pero no reemplaza rutas de bajo costo, voz en vivo o generación de imagen.
Recomendación
Usa Gemini 3.5 Flash como primera prueba seria para agentes, código, long-context workflows y entrada multimodal compleja. Trata gemini-3.5-flash como contrato oficial, mantén el precio con fecha y valida las capacidades no soportadas antes de diseñar el producto alrededor de él.
Evítala cuando el trabajo pertenezca a otro runtime: live voice, image output, audio output, Computer Use o el pipeline masivo más barato. La mejor decisión no es elegir el modelo más nuevo, sino la ruta que coincide con el trabajo, el precio y el modo de operación.