
GPT-5.6 Sol, Claude Fable 5 y Claude Opus 4.8 no son tres opciones igual de disponibles. A 28 de junio de 2026, OpenAI describe GPT-5.6 Sol como limited preview para organizaciones aprobadas; Anthropic indica que Claude Fable 5 esta currently unavailable; Claude Opus 4.8 es la ruta Anthropic live que puedes poner en una evaluacion de coding-agent hoy.
La decision practica es esta: conserva Opus 4.8 como live fallback si tu organizacion no tiene el acceso exacto a GPT-5.6 Sol preview que necesitas. Prueba Sol solo en el API org o Codex workspace donde el acceso exista realmente. Trata Fable 5 como wait-and-recheck hasta que Anthropic cambie el access status oficial. No sustituyas un production default sin el mismo repo, el mismo prompt, las mismas tools, los mismos tests y el mismo cost log.
| Ruta actual el 28-06-2026 | Primer movimiento | Por que | Regla de parada |
|---|---|---|---|
| Tienes Sol preview access en la surface necesaria | Probar Sol en tareas coding-agent dificiles | OpenAI presenta Sol como flagship GPT-5.6 y enfatiza terminal-driven coding. | No generalices resultados de preview workspace a equipos sin acceso. |
| Estas considerando Claude Fable 5 | Esperar y revisar el access de Anthropic | Anthropic marca Fable 5 como unavailable. | No trates list price o demos antiguos como deployability proof. |
| Necesitas produccion hoy | Usar Claude Opus 4.8 como live baseline | Opus 4.8 aparece disponible en Anthropic y rutas partner listadas. | No cambies default sin same-task evidence. |
Respuesta rapida
Para equipos de coding, esta comparacion empieza por acceso, no por coronar un modelo. Sol es el preview model interesante, Fable es una promesa premium no disponible y Opus 4.8 es el live fallback. Ese orden puede cambiar, asi que el estado de acceso, precio y plataformas debe estar fechado: estas filas se revisaron contra fuentes oficiales de OpenAI y Anthropic el 28 de junio de 2026.
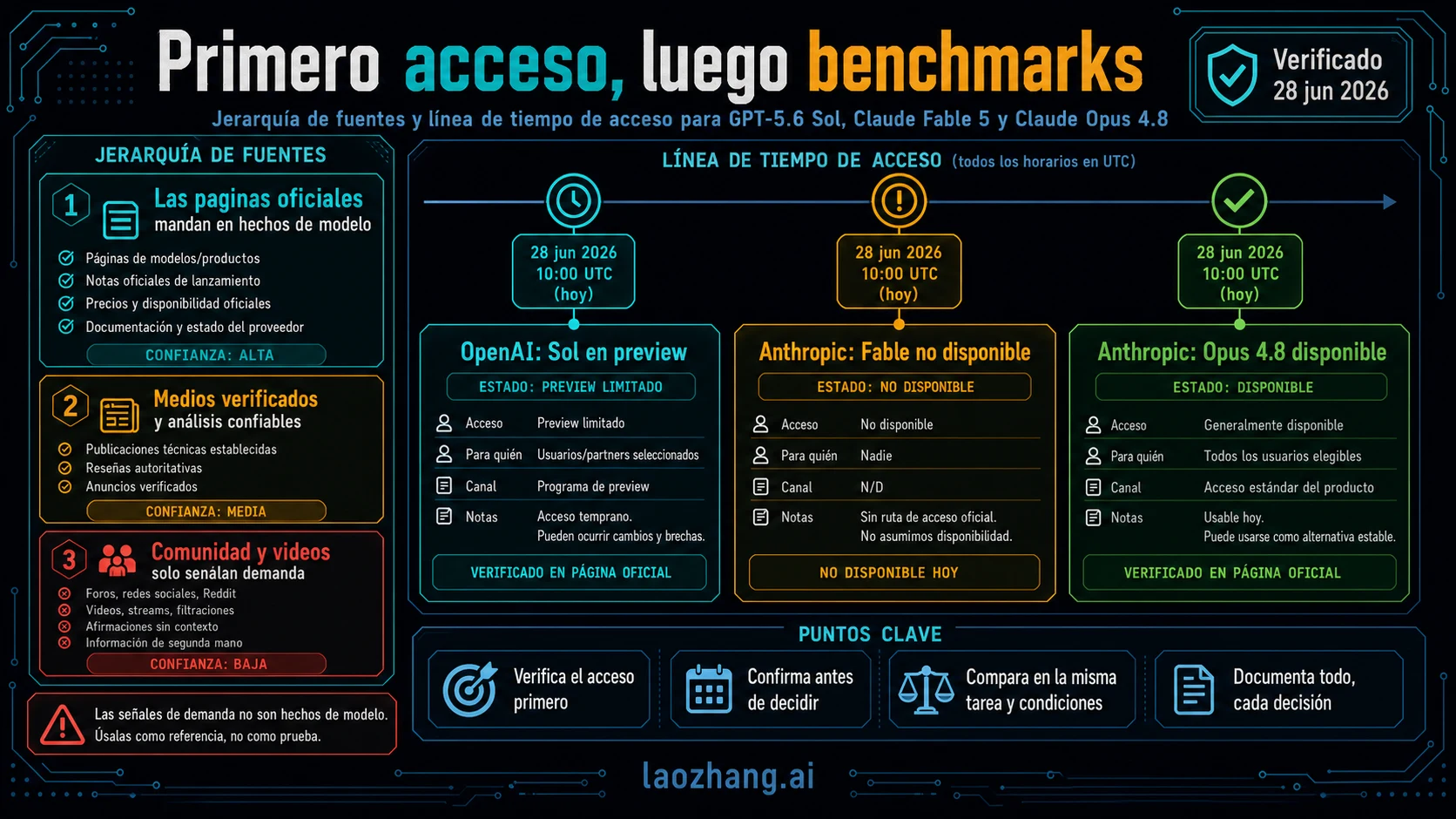
Usa Sol cuando tu ruta OpenAI aprobada pueda llamarlo y el trabajo justifique el preview risk. Usa Opus 4.8 cuando necesitas endpoint soportado, account policy, logs y rollout path ahora. Mantén Fable 5 como waitlist/recheck, no como recomendacion de produccion, hasta que Anthropic restaure acceso.
Muchas paginas exact-match ponen primero una tabla de benchmarks. Sirve para escanear, pero puede ocultar la decision importante: un modelo fuerte que no puedes usar no es tu default de produccion. Un precio alto en un modelo unavailable sigue siendo solo un numero de planificacion.
El acceso es la primera division
Los materiales de OpenAI sobre GPT-5.6 Sol hablan de limited preview, no de self-service launch. La ayuda de OpenAI tambien separa API organization access de Codex workspace access. Una aprobacion en API org no demuestra que tu Codex workspace pueda usar Sol. Si tu migracion depende de Codex, confirma entitlement del workspace antes de planificar pruebas.
Anthropic marca el limite contrario para Fable 5. Puede existir model page, price row y benchmark discussion, pero si el current access statement dice unavailable, no es una traffic route. Videos antiguos, screenshots y demos de terceros no reemplazan el official access status actual.
Claude Opus 4.8 tiene el deployability contract mas claro hoy. La pagina Opus y el model overview de Anthropic lo listan en Claude products, Claude Platform, AWS, Google Cloud y Microsoft Foundry. La fila de implementacion que debes verificar es `claude-opus-4-8`; no la sustituyas por shorthand social ni por IDs antiguos.
| Contract item | GPT-5.6 Sol | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|---|
| Access status | Limited preview para approved organizations y scoped workspaces. | Current Anthropic materials: unavailable. | Generally available por Anthropic y rutas partner listadas. |
| Papel hoy | Preview test si tienes acceso. | Wait and recheck. | Live baseline o fallback. |
| API/model ID | Revisar en tu approved OpenAI org antes de programar. | No planificar production calls mientras access este disabled. | `claude-opus-4-8`. |
| Riesgo principal | Entitlement mismatch y extrapolar demasiado el preview. | Confundir demos antiguos o list price con live access. | Asumir que gana todo sin same-task test. |
Coste: compara una misma tarea
Los official list prices solo ayudan si se ponen sobre la misma unidad de trabajo. OpenAI lista Sol preview pricing en `5\` input y \`30` output por millon de tokens. Anthropic lista Fable 5 en `10\` input y \`50` output, pero esa fila no es deployable mientras el acceso este unavailable. Anthropic model docs lista Opus 4.8 en `5\` input y \`25` output.

Para una ejecucion coding-agent con 200k input y 40k output, antes de cache, batch, retries y terminos regionales, la cuenta simple es: Sol cuesta alrededor de `2.20\`, Fable costaria alrededor de \`4.00` pero esta unavailable, y Opus 4.8 cuesta alrededor de `$2.00`. Eso no convierte a Opus en ganador universal. Lo convierte en el live price baseline que Sol debe superar con calidad, tiempo ahorrado o menor failure rate.
El coste real es task cost. Un modelo con output rate mas alto puede ser mas barato si termina en una pasada y reduce review minutes. Un modelo con buena fila de precio puede salir caro si hace tool loops, rompe formatos o exige reparacion manual. Registra input, cached input, output, retries, tool calls, elapsed time y human review minutes antes de aprobar un switch.
Como leer benchmarks
Los benchmarks son motivo para probar, no para saltarse la tabla de acceso. El lanzamiento de Sol por OpenAI enfatiza terminal-driven agentic coding y reporta resultados fuertes. Para equipos con Sol preview access, es una señal seria cuando el workload se parece a repository edits, terminal recovery y multi-step coding.
Pero provider benchmark claims responden una pregunta mas estrecha que la production decision. No prueban que tu cuenta tenga acceso, que tu tool harness sea compatible, que tus prompts sobrevivan long-context drift ni que el modelo reduzca total review time. Tampoco convierten Fable 5 en deployable mientras Anthropic lo marca unavailable.
Usa benchmark rows como workload hints. Si la tarea es terminal coding y tienes Sol access, Sol entra en first pilot lane. Si la tarea es un live API agent con customer-facing output, Opus 4.8 entra en stable lane. Si el interes es Fable-specific research, conserva el harness, pero no programes production cutover hasta que cambie la access page de Anthropic.
Plan de prueba coding-agent
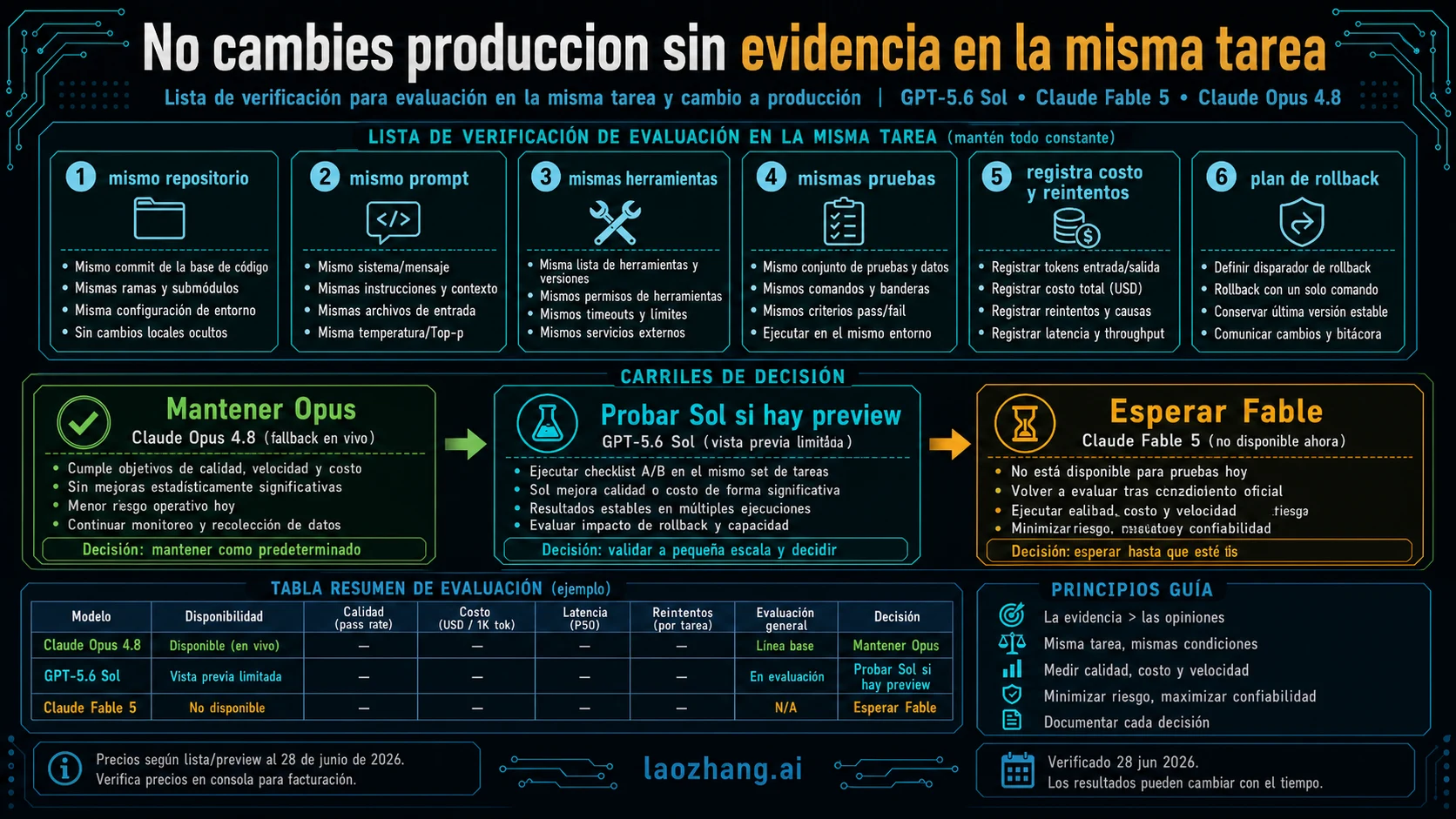
Una comparacion justa usa el mismo trabajo, no el mismo titular. Elige 10-20 tareas que ya consumen review time: failing test fix, refactor con hidden constraints, long-context bug hunt, docs update con code verification y tool recovery despues de errores. No elijas demo prompts que favorecen a tu modelo preferido.
Ejecuta Opus 4.8 por el endpoint que realmente puedes desplegar. Ejecuta Sol solo por la OpenAI surface aprobada que realmente tienes. Deja Fable en future-test column hasta que vuelva el acceso. En cada run registra first-pass correctness, tool recovery, format stability, output length, total tokens, retry count, latency y review minutes.
El default-switch threshold debe ser conservador. Ningun modelo pasa a production default si no reduce total work en el mismo task set y no tiene rollback route. Si Sol gana solo dentro de un preview workspace, mantenlo como specialist route. Si Opus gana por reliability y live support, mantenlo como baseline. Si Fable vuelve despues, repite el mismo harness en vez de confiar en comparaciones antiguas.
Si ya usas un modelo cercano
Si leiste una comparacion de GPT-5.5 u Opus 4.7, conserva el habito route-first, no los facts antiguos. La pagina GPT-5.5 vs Claude Opus 4.7 sirve como estructura de evaluacion, pero access state, model names y price rows cambiaron. Cualquier precio, context o availability debe revisarse en la pagina oficial.
Si tu pregunta real es si Fable merece espera, la comparacion Claude Fable 5 vs GLM 5.2 aporta el framing anterior de Fable. Para esta pagina, la regla actual es mas dura: mientras Anthropic diga unavailable, Fable 5 no debe recomendarse como siguiente production step.
La regla duradera es simple. Mantén el live model que sostiene tu sistema hoy. Agrega el preview model solo donde existe acceso y el riesgo es aceptable. Deja los modelos unavailable en watchlist. No promociones nada a default sin same-task evidence.
Preguntas frecuentes
GPT-5.6 Sol esta disponible publicamente?
No. OpenAI describe GPT-5.6 Sol como limited preview para approved organizations, con acceso separado para API org y Codex workspace. Sin ese acceso, Sol no es production option para esa ruta hoy.
Claude Fable 5 esta disponible ahora?
Los materiales actuales de Anthropic sobre Fable dicen unavailable, y el statement del 12 de junio indica que Fable 5 y Mythos 5 fueron disabled for all customers. Tratalo como wait-and-recheck model.
Claude Opus 4.8 es el default mas seguro?
En esta terna, Opus 4.8 es el live Anthropic baseline mas claro. Aun asi necesita same-task evaluation antes de sustituir otro default que ya funciona.
Cual es mas barato?
Con simple list math para 200k input y 40k output, Opus 4.8 cuesta alrededor de `2.00\`, Sol preview alrededor de \`2.20`, y Fable list row alrededor de `$4.00` pero unavailable. El coste real depende de cache, batch, retries, latency y review minutes.
Deben decidir los benchmarks?
No. Los benchmarks deciden que probar primero. El production default lo deciden access status, task fit, cost logs, failure rate y rollback safety.