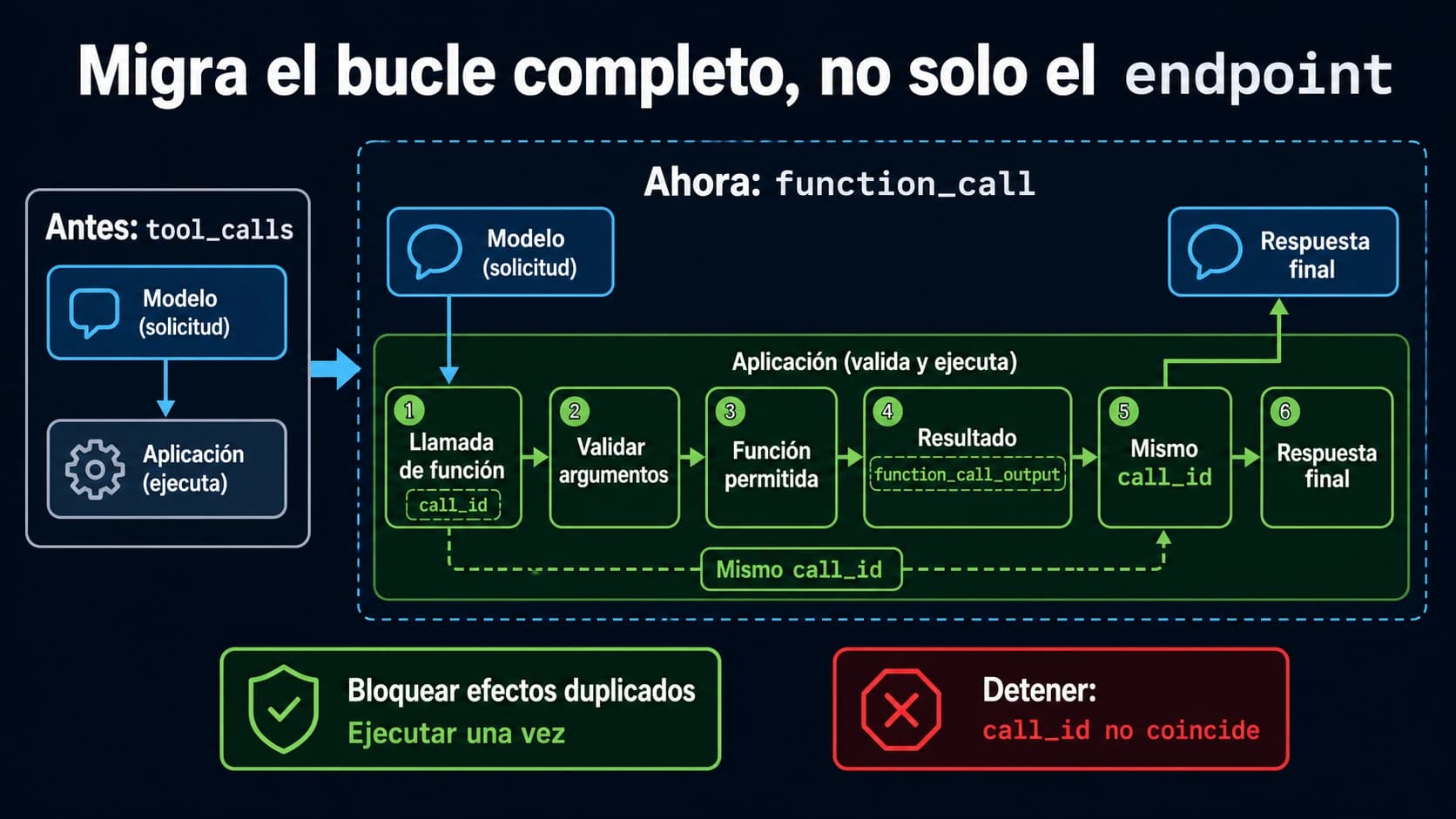
Claude Fable 5 y GLM-5.2 no son dos opciones igualmente ejecutables hoy. Según las fuentes oficiales revisadas el 14 de junio de 2026, Anthropic dice que el acceso a Fable/Mythos está deshabilitado, así que Fable 5 es una rama de espera y nueva verificación. Z.AI, en cambio, documenta GLM-5.2 dentro de su GLM Coding Plan, por lo que GLM-5.2 es la rama que puedes validar primero con una tarea acotada de agente de código.
Eso no convierte a GLM-5.2 en sustituto automático de Fable. La disponibilidad decide qué puedes probar antes; no decide qué modelo merece ser el predeterminado de producción. Para tomar una decisión defendible necesitas el mismo repositorio, el mismo issue, el mismo prompt, las mismas herramientas, la misma prueba de aceptación y el mismo registro de coste, latencia, reintentos y rollback.
| Ruta | Cuándo usarla | Primer paso | Regla de parada |
|---|---|---|---|
| Esperar a Fable 5 | Necesitas comportamiento, facturación, política o fallback propios de Anthropic. | Revisa el comunicado de acceso, los modelos y los precios de Anthropic antes de planear una prueba. | No puntúes Fable 5 en tareas reales si no puedes ejecutarlo. |
| Probar GLM-5.2 | Necesitas una ruta de coding agent que sí puedas validar esta semana. | Configura la ruta documentada de Z.AI, confirma GLM-5.2 o GLM-5.2[1m] y ejecuta una tarea pequena. | No lo llames reemplazo hasta ver diff, tests, logs, cuota, latencia y coste de rollback. |
| Guardar una doble prueba | Estás pensando en cambiar el modelo predeterminado del equipo. | Conserva el paquete exacto de tarea y repítelo si Fable vuelve. | Sin evidencia comparable de ambas ramas ejecutables, no hay ganador. |
Nota de evidencia: las páginas de lanzamiento, acceso, modelos y precios de Anthropic, junto con la documentación de Z.AI GLM Coding Plan, fueron revisadas el 14 de junio de 2026. La disponibilidad, la cuota, el ruteo y el precio son datos volátiles; revisa las fuentes oficiales antes de publicar una recomendación nueva o cambiar una ruta predeterminada.
Respuesta rápida
La respuesta útil es operacional: Fable 5 no es el punto de partida para una evaluación viva de coding agent mientras el acceso esté deshabilitado. Sus especificaciones siguen importando, porque indican cómo se debería disenar una prueba si el acceso vuelve. Pero una especificación no ejecutable no puede competir con una ruta que sí puedes poner en marcha en tu entorno.
GLM-5.2 sí merece una prueba pequena cuando la pregunta real es “qué puedo ejecutar ahora”. La documentación de Z.AI indica soporte de GLM-5.2 en GLM Coding Plan y muestra rutas de herramienta compatibles con un proveedor estilo OpenAI. Eso basta para justificar una validación controlada. No basta para decir que supera a Fable, Opus, Kimi o tu modelo actual.
La palabra clave es “primero”. GLM-5.2 puede ser la primera rama ejecutable sin ser la respuesta final para todas tus cargas de trabajo. Mantén separadas las capas: disponibilidad, ruta, coste, calidad de parche, revisión humana y riesgo de rollback.
Lo que muestra el resultado local en espanol
La primera pantalla de Google en espanol mezcla videos, comparadores genéricos, resultados traducidos y piezas de noticias. Ese tipo de resultado invita a mirar quién parece más fuerte, quién tiene más benchmarks o quién aparece en una tabla de comparación. El problema es que muchas tablas tratan a Fable como si siguiera siendo una opción ejecutable y a GLM-5.2 como si todo wrapper tuviera la misma ruta documentada.
La página local necesita empezar por otro lugar. Para un lector que mantiene repositorios, la pregunta no es si un video “probó” GLM-5.2 ni si un comparador importó una fila de precios. La pregunta es: qué fuente posee la afirmación, qué ruta puedes reproducir, qué tarea vas a ejecutar y qué evidencia quedará si el parche falla.
Por eso esta versión no usa el lenguaje de corona o ranking. La superficie local debe corregir la promesa de comparación: primero se verifica la disponibilidad, después se mide una misma tarea, y solo entonces se decide si vale la pena cambiar la ruta de trabajo.
La disponibilidad cambió la comparación
Anthropic anunció Claude Fable 5 el 9 de junio de 2026. Después publicó una declaración separada sobre Fable/Mythos indicando que debía deshabilitar el acceso para todos los clientes. Esa línea cambia la comparación porque impide una prueba justa de Fable en tareas reales mientras el estado no cambie.
Z.AI presenta una capa distinta de evidencia. En este artículo GLM-5.2 no se trata como una fila suelta de catálogo, sino como una ruta documentada dentro de GLM Coding Plan. Las páginas de Z.AI mencionan GLM-5.2, el uso en herramientas y una configuración de contexto grande. Esa documentación permite preparar una prueba, pero no prueba de antemano que la ruta sea estable, rápida o adecuada para tu repositorio.

La consecuencia es simple: si no puedes ejecutar Fable, no lo puntúes. Si puedes ejecutar GLM-5.2, no lo promociones a modelo por defecto hasta que haya evidencia observable. La disponibilidad decide el orden de prueba; la misma tarea decide la confianza.
Tabla de contrato oficial
| Punto de contrato | Claude Fable 5 | GLM-5.2 |
|---|---|---|
| Dueno de la fuente | Anthropic | Z.AI |
| Estado revisado el 2026-06-14 | No disponible según la declaración de acceso Fable/Mythos. | Documentado dentro de GLM Coding Plan. |
| Etiqueta a vigilar | claude-fable-5 | glm-5.2 y glm-5.2[1m] |
| Contexto y salida | Documentos de Anthropic mencionan 1M context y 128k output, pero no lo vuelven ejecutable. | La ruta de coding documenta una clase de 1M context. |
| Unidad de coste | Precio por millón de tokens en Anthropic. | Cuota y multiplicadores de Coding Plan. |
| Implicación para agentes de código | Especificación fuerte, rama de espera mientras el acceso no vuelva. | Candidato de prueba si la ruta Z.AI está disponible para tu cuenta. |
| Lo que no demuestra | Que Fable pueda probarse hoy. | Que GLM-5.2 sea mejor ni que reemplace tu ruta actual. |
Esta tabla no pretende elegir campeón. Sirve para que no mezcles fuentes. Anthropic posee el estado de Fable, su identificador, sus límites y su precio. Z.AI posee la ruta GLM-5.2 de Coding Plan. Tu entorno posee la prueba final: diff, tests, logs, latencia, cuotas y rollback.
Si tu flujo real pasa por Claude Code, separa también la configuración. Cambiar un provider o base URL es una decisión de ruteo, no una prueba de calidad del modelo. Para la capa de configuración puedes revisar Claude Code API configuration, y para propiedad de credenciales o facturación, Claude Code API key vs subscription billing.
Normaliza el coste antes de comparar
Fable y GLM-5.2 no usan la misma unidad visible. Fable tiene una fila oficial de precio por token. GLM-5.2, en la evidencia usada aquí, aparece dentro de un plan de coding con cuotas y multiplicadores. Una respuesta como “es más barato” o “es más caro” se vuelve frágil si no has ejecutado la misma tarea.
Un agente de código consume más que tokens. Consume llamadas a herramientas, salidas largas, reintentos, tiempo de revisión, ejecución de tests y capacidad de rollback. Un intento barato que produce un parche incorrecto puede ser más caro que una ruta costosa que pasa con una revisión pequena.

| Medida | Por qué importa |
|---|---|
| Tokens de entrada | El contexto largo de un repositorio puede dominar el coste o la cuota. |
| Tokens de salida | Parches, explicaciones y logs pueden aumentar la salida. |
| Llamadas a herramientas | La ruta de coding puede limitar o cobrar distinto según el patrón de uso. |
| Latencia | Una ruta barata que bloquea revisión o CI puede perder en la práctica. |
| Resultado pass/fail | Un fallo repetido no es barato si exige rescate humano. |
| Reintentos | Suben cuota, tiempo y ruido de revisión. |
| Rollback | El coste real de un parche malo suele estar fuera de la factura. |
Si no puedes llenar esa tabla, di que las unidades aún no son comparables. Esa frase es más honesta que una conclusión de precio que nadie puede reproducir.
Cuándo probar GLM-5.2 primero
GLM-5.2 tiene sentido como primera prueba cuando el trabajo es acotado y revisable: un bug reproducible, una migración pequena, una corrección de tests, una tarea de documentación técnica o un refactor con una aceptación clara. Debe ser una tarea donde un parche malo sea fácil de aislar y revertir.
No empieces por GLM-5.2 si necesitas exactamente semántica, facturación, política o fallback de Anthropic. Tampoco lo conviertas en única rama para cambios de seguridad, migraciones de datos, cumplimiento o trabajos donde un error sutil cueste mucho detectar.
La prueba debe tener un alcance estrecho. No pidas al modelo que cambie arquitectura, tests, documentación y despliegue a la vez. Una prueba mide una capacidad: entender el issue, producir un diff revisable, pasar la prueba indicada, dejar logs claros y fallar de una manera que puedas revertir.
No cambies el modelo por defecto todavía
Cambiar un modelo por defecto es una decisión de producción. La suspensión de Fable decide qué rama no puedes medir ahora, pero no decide qué rama merece confianza permanente. Incluso si GLM-5.2 pasa una tarea, eso solo prueba esa tarea con esa ruta y esa configuración.
Antes de cambiar el predeterminado, exige condiciones duras: mismo paquete de tarea, misma barra de aceptación, mismo registro de evidencia, mismo plan de rollback y umbral de decisión definido antes de ejecutar. Si el equipo no puede explicar qué resultado fuerza volver atrás, todavía no está listo para cambiar.
| Requisito | Condición de paso |
|---|---|
| Paquete idéntico | Mismo repo, issue, prompt, archivos, herramientas y tiempo. |
| Barra idéntica | Los mismos tests y la misma revisión aplican a cada rama. |
| Evidencia idéntica | Logs, diff, salida de tests, latencia, cuota y motivo de fallo. |
| Rollback definido | Se sabe revertir, aislar o repetir sin improvisar. |
| Umbral previo | Se decide antes qué cuenta como suficiente y qué obliga a volver. |
Si Fable vuelve, repite el paquete conservado. No compares un nuevo trabajo de GLM-5.2 con una impresión antigua de Fable, ni compares una especificación de Fable con un log real de GLM-5.2.
Checklist de la misma tarea
La prueba más limpia es pequena por diseno. Elige un repositorio, un issue y una aceptación. Debe ser real para mostrar comportamiento de agente, pero lo bastante pequena para que la revisión no dependa de intuición.

- Bloquea prompt, branch, archivos, herramientas permitidas y presupuesto de tiempo.
- Ejecuta GLM-5.2 por la ruta documentada de Z.AI.
- Guarda etiqueta de modelo, provider, base URL, diff, logs, tests, latencia, cuota y causa de fallo.
- Evalúa solo resultados observables: calidad del parche, tests, reintentos, revisión y rollback.
- Si Fable vuelve, ejecuta el mismo paquete sin cambiar el problema.
- Si ambas ramas son ejecutables, compara coste aceptado y modo de fallo, no la popularidad del nombre.
Una frase defendible sería: “GLM-5.2 pasó nuestra migración acotada con un reintento y cuota aceptable”. Una frase no defendible sería: “GLM-5.2 ganó porque Fable estaba suspendido”.
Preguntas frecuentes
¿Claude Fable 5 está disponible ahora?
No según la declaración de acceso de Anthropic revisada el 14 de junio de 2026. Anthropic indica que el acceso a Fable 5 y Mythos 5 está deshabilitado para todos los clientes. Revisa las páginas actuales antes de planear una prueba.
¿GLM-5.2 es mejor que Claude Fable 5?
No hay una afirmación justa mientras Fable no pueda ejecutarse. GLM-5.2 puede ser la primera rama que pruebas, pero “mejor” requiere la misma tarea, las mismas entradas y resultados observables de ambas ramas.
¿Qué identificador debo buscar?
Para Fable, revisa claude-fable-5 y el estado de acceso de Anthropic. Para GLM, revisa glm-5.2 y glm-5.2[1m] dentro de la ruta de Z.AI Coding Plan.
¿GLM-5.2 es más barato que Fable?
No se puede decidir con una fila. Fable usa precio por token; GLM-5.2 usa cuota y multiplicadores de plan. Compara solo después de medir la misma tarea, incluyendo reintentos, latencia, pass/fail y rollback.
¿Debo usar GLM-5.2 como reemplazo de Fable?
Úsalo como ruta de prueba viva, no como reemplazo automático. Conserva el paquete para repetirlo si Fable vuelve y cambia un predeterminado solo cuando la evidencia de la misma tarea supere tu barra de calidad y riesgo.
Conclusión
La comparación honesta no pregunta qué nombre suena más fuerte. Pregunta qué ruta se puede probar sin mentirse. El 14 de junio de 2026, Fable 5 tiene contrato oficial pero acceso suspendido; GLM-5.2 tiene una ruta documentada en Z.AI Coding Plan que puede validarse con una tarea pequena.
Empieza por ahí. Revisa Fable antes de puntuarlo, normaliza unidades antes de hablar de precio y exige una misma tarea antes de cambiar cualquier modelo predeterminado.