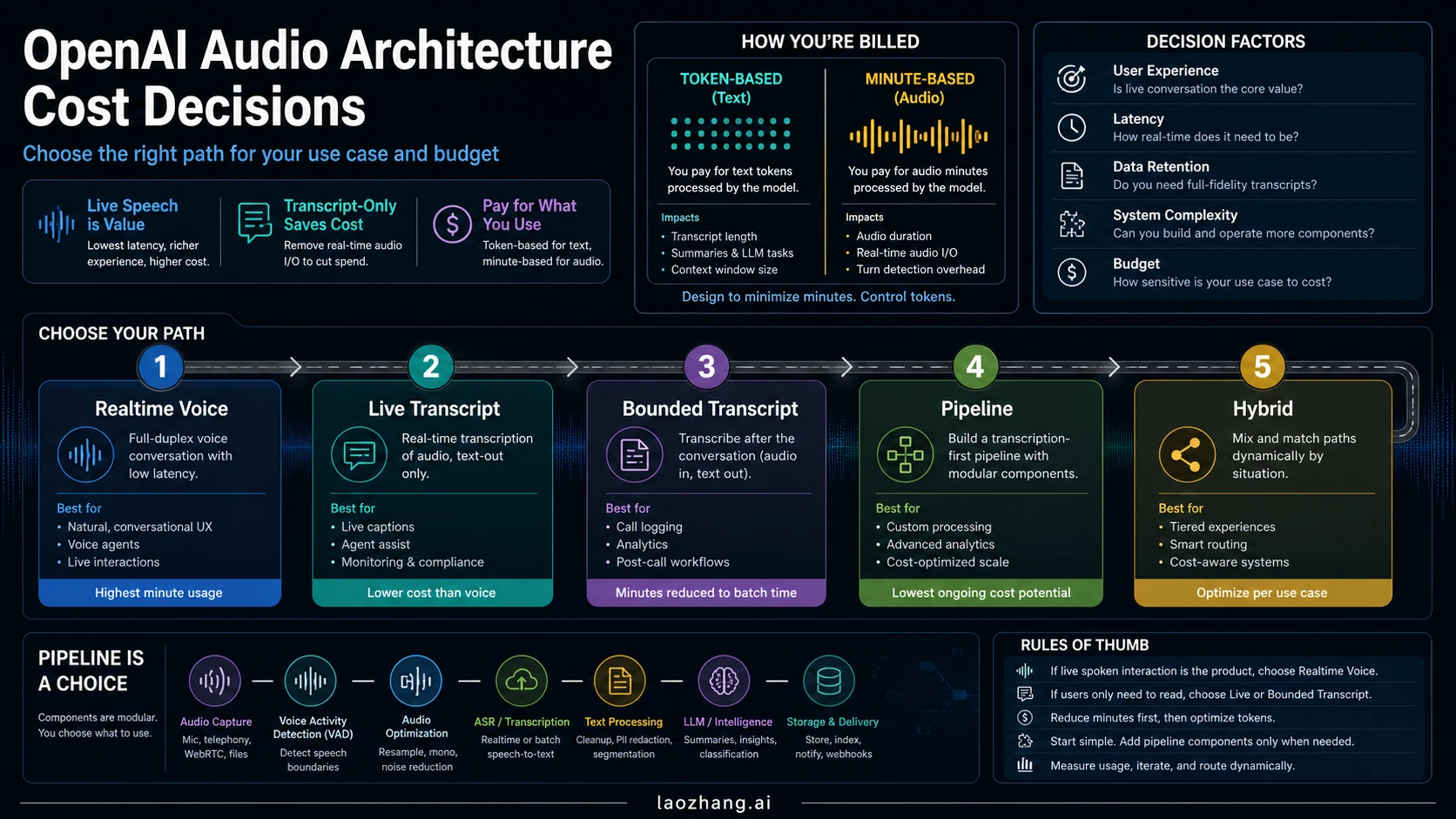
Realtime API is worth the extra cost when your product sells live spoken interaction: interruption, fast turn-taking, tool use during a call, and a voice response that feels present. If the product mainly needs a transcript, summary, archive, QA review, compliance trail, or analytics feed, start with a transcription-first route.
Use the route before the price table:
- Live spoken assistant: use
gpt-realtime-2when voice response quality, interruption, and low latency are the value. - Live transcript only: use
gpt-realtime-whisperwhen the product needs streaming text but not a spoken assistant. - Bounded audio to text: use
gpt-4o-transcribeorgpt-4o-mini-transcribewhen the audio can be uploaded or processed as a request. - Custom pipeline: combine STT, a text model, optional TTS, telephony, storage, monitoring, and QA only when those components are actually needed.
- Hybrid: reserve Realtime for high-value live moments and use transcription-first processing for archive, review, and summaries.
As of June 14, 2026, OpenAI lists gpt-realtime-whisper at $0.017/minute, gpt-4o-transcribe at an estimated $0.006/minute, and gpt-4o-mini-transcribe at an estimated $0.003/minute. By direct conversion, that is $1.02/hour, $0.36/hour, and $0.18/hour for duration-billed transcription. gpt-realtime-2 voice-agent sessions are different: audio input and output are token-billed, and one counted hour of user audio plus one generated hour of assistant audio creates a $5.76/hour media-token floor before text tokens, tool calls, repeated conversation history, optional input transcription, and pipeline or telephony components.
The stop rule is simple: do not pay for spoken assistant output when text is enough. The rest of the page gives the worksheet for deciding when low-latency speech is worth the extra spend, how Realtime costs grow, and which pipeline costs must stay variable until you verify them for your own stack.
Fast answer: choose by product job
The cost decision is not "Realtime API versus transcription pipeline" in the abstract. It is the product job first, then the OpenAI route, then the billing unit.
| Product job | First route to price | Cost unit to model | Use it when | Stop rule |
|---|---|---|---|---|
| Live spoken assistant | gpt-realtime-2 | audio and text tokens per Response | users need interruption, turn-taking, tool use, and spoken output during the session | if text output is enough, do not start here |
| Live transcript only | gpt-realtime-whisper | minutes of live audio | the product needs streaming text while someone is speaking | if audio can wait, price bounded transcription instead |
| Bounded audio to text | gpt-4o-transcribe or gpt-4o-mini-transcribe | minutes of submitted audio | files, recordings, uploads, post-call review, summaries, QA, or compliance can run after capture | if live deltas are required, use a realtime transcription route |
| Custom pipeline | STT -> text model -> optional TTS -> operations layer | separate component meters | teams need control, vendor mix, telephony fit, auditability, or component-level optimization | do not add TTS, telephony, or a text model unless the workflow needs them |
| Hybrid | Realtime for the live moment, transcription-first for the back office | combined meters | live help creates value, but archive, review, and analytics do not need spoken output | measure where the live session ends and back-office processing begins |
That route table prevents the most common budget error. A voice agent and a transcript are both audio products, but they do not buy the same thing. The voice agent buys an interactive spoken loop. A transcription pipeline buys text and downstream processing.
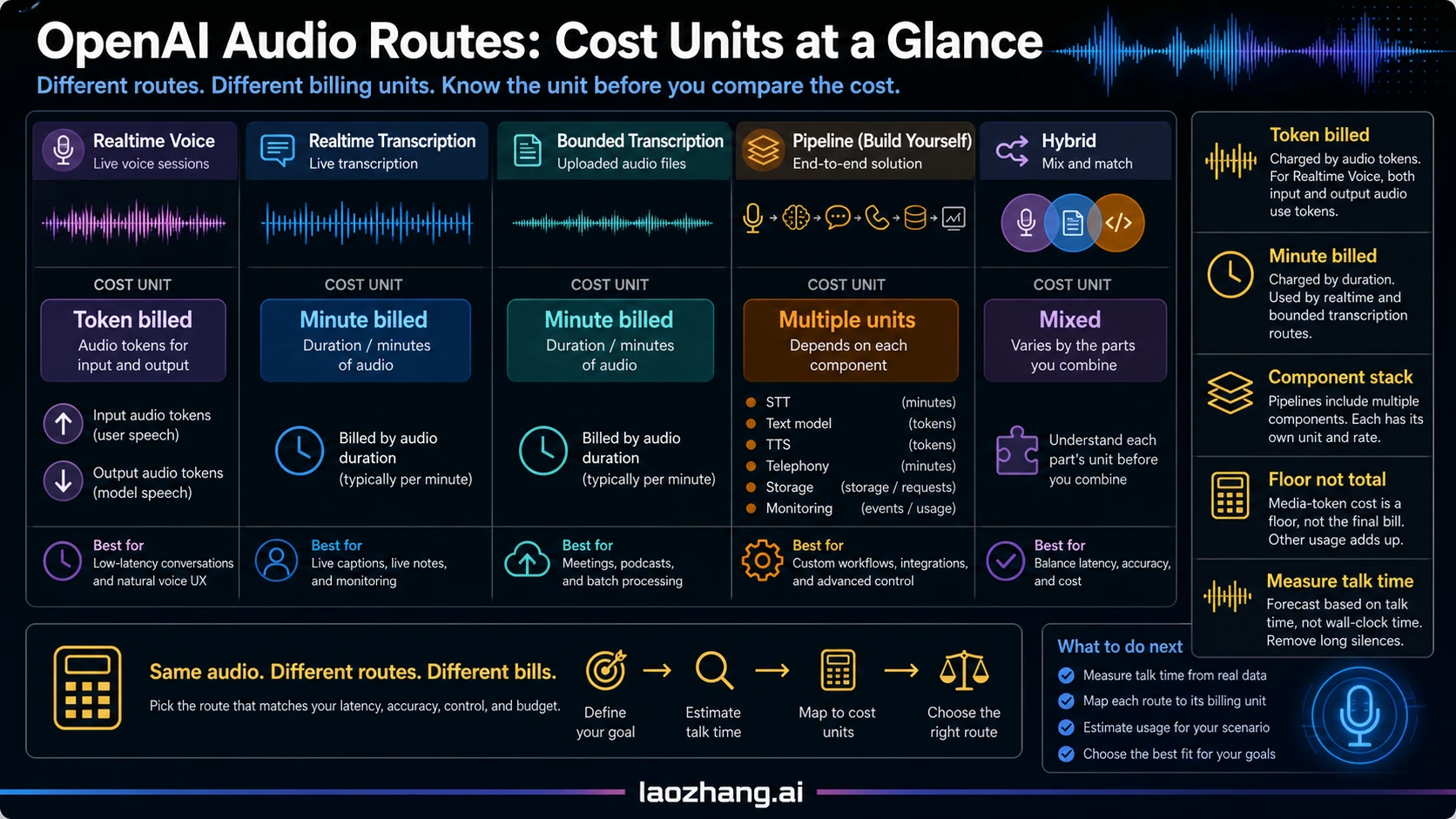
Current OpenAI prices that matter
Use OpenAI's current price rows as anchors, then add your own measured workload. Checked on June 14, 2026, the OpenAI pricing page lists these rows for the routes in this decision:
| Route | Current OpenAI price row | Hourly intuition | What it does not include |
|---|---|---|---|
gpt-realtime-whisper | $0.017/minute | $1.02/hour by direct conversion | custom text model work, storage, monitoring, telephony, and non-OpenAI components |
gpt-4o-transcribe | estimated $0.006/minute | $0.36/hour by direct conversion | post-processing, summaries, classification, storage, and orchestration |
gpt-4o-mini-transcribe | estimated $0.003/minute | $0.18/hour by direct conversion | accuracy review, domain tuning, post-processing, and operations work |
gpt-realtime-2 audio input | $32.00/1M audio input tokens | $1.152/hour for one counted hour of user audio at 1 token per 100 ms | assistant audio, text, tools, history growth, optional transcription, and pipeline components |
gpt-realtime-2 audio output | $64.00/1M audio output tokens | $4.608/hour for one generated hour of assistant audio at 1 token per 50 ms | user audio, text, tools, history growth, optional transcription, and pipeline components |
The duration-billed transcription math is direct:
textgpt-realtime-whisper: 60 minutes * $0.017 = $1.02/hour gpt-4o-transcribe: 60 minutes * $0.006 = $0.36/hour gpt-4o-mini-transcribe: 60 minutes * $0.003 = $0.18/hour
The gpt-realtime-2 media-token floor is also straightforward, but it is only a floor:
textUser audio input: 36,000 tokens/hour * $32 / 1,000,000 = $1.152/hour Assistant audio output: 72,000 tokens/hour * $64 / 1,000,000 = $4.608/hour Media-token floor: $1.152 + $4.608 = $5.76/hour
Use that $5.76/hour number as a warning label, not as a quote. It assumes one counted hour of user audio and one generated hour of assistant audio, then excludes the parts that often move the real bill: text tokens, repeated conversation context, tools, optional input transcription, session design, telephony, and any pipeline outside the Realtime session.
Why Realtime voice-agent cost grows
The Realtime cost guide explains why a voice-agent session is not priced like a simple audio file. Cost accrues when a Response is created and is based on input and output tokens, with input transcription billed separately when enabled. OpenAI also notes that connections and network bandwidth are not currently billed, but that does not make the session free while it is open.
The practical drivers are:
- User audio: counted at 1 token per 100 ms.
- Assistant audio: counted at 1 token per 50 ms.
- Response count: each Response is a new model generation event.
- Conversation history: previous conversation content is sent again, so later turns can become more expensive.
- Empty audio control: VAD can filter empty input audio unless the client manually adds it.
- Text and tool work: instructions, tool schemas, tool results, and text output still matter.
- Optional input transcription: if enabled, it uses a separate transcription model and rate card.

This is why "Realtime costs X dollars per hour" is usually too weak for launch planning. A quiet 60-minute support call with short assistant replies can have a very different bill from a 20-minute tutoring session where the assistant speaks often, uses tools, and carries a long instruction and history context through many Responses.
You can reduce waste without changing the product route:
- Keep VAD configured so silence is not manually added as input.
- End or summarize long sessions when the old history no longer improves the next answer.
- Keep tool schemas and system instructions tight.
- Avoid assistant monologues when a short spoken answer is enough.
- Enable input transcription only when the product needs a transcript from inside the Realtime session.
- Measure real Response count and assistant-audio duration before committing to a public margin.
The upside is also real. gpt-realtime-2 buys a native spoken interaction loop: low latency, interruption handling, and voice response quality in one session. If those traits change conversion, containment, accessibility, or completion rate, the extra cost can be the product value rather than waste.
Transcription-first pipeline cost model
A transcription-first pipeline starts cheaper because the first paid step can be plain speech-to-text. For files and bounded audio, the Speech to text guide points to transcription routes such as gpt-4o-transcribe, gpt-4o-mini-transcribe, and gpt-4o-transcribe-diarize; file uploads are capped at 25 MB and are a different shape from live transcript deltas. For live text without a spoken assistant, the Realtime transcription guide maps the job to gpt-realtime-whisper.
Do not stop the worksheet at STT if the product does more than produce text. Count the stack honestly:
| Component | Count as | Price treatment |
|---|---|---|
| Audio capture and transport | app, browser, WebRTC, telephony, or recording infrastructure | variable; depends on your product stack |
| STT | gpt-realtime-whisper, gpt-4o-transcribe, or gpt-4o-mini-transcribe | official OpenAI minute rows can anchor the estimate |
| Text model | summarization, extraction, routing, QA, coaching, moderation, or agent logic | variable; price the actual model, tokens, cache, and retries |
| Optional TTS | speech output after text processing | variable unless separately verified for the launch route |
| Telephony | PSTN, SIP, call recording, carrier fees, phone numbers, compliance features | variable; verify provider and region |
| Storage and retrieval | audio files, transcripts, embeddings, logs, retention policy | variable; count retention and privacy requirements |
| Monitoring and QA | human review, audits, metrics, failure replay, alerting | variable; often larger than the STT row in regulated workflows |

The pipeline can still be cheaper and more predictable than a live voice-agent session, especially when the product does not need spoken output. It can also be easier to debug because each component produces an artifact: audio, transcript, text-model output, summary, classification, or audit log.
The tradeoff is product latency and integration load. A cascaded STT -> text model -> TTS design has more moving parts. Streaming each component can reduce delay, but it does not make the pipeline the same as a native spoken session. Choose it because the workflow is text-centered or because component control matters, not because it sounds universally cheaper.
When live voice is worth paying for
Pay for gpt-realtime-2 when spoken interaction changes user behavior during the session. Good candidates include:
- sales or onboarding calls where interruption and turn-taking affect completion
- tutoring, coaching, or accessibility flows where the user should not wait for a transcript-first loop
- voice agents that call tools while the user is still in the conversation
- consumer voice experiences where speech quality and low latency are the interface
- support containment where a completed spoken resolution avoids a human escalation
The pilot question is not "Is Realtime more expensive than STT?" It is "Does live speech produce enough value to justify the additional meter?" Measure:
| Metric | Why it matters |
|---|---|
| real user talk time | drives counted user audio |
| assistant speech time | drives audio output and often dominates the media-token floor |
| Responses per session | controls how often the model generates |
| average history size by turn | reveals late-session cost growth |
| tool calls per session | captures hidden text and tool context |
| containment or completion lift | tells you whether the voice loop pays back |
| human fallback rate | catches cases where a cheaper transcript route would have worked |
If those metrics show that live spoken interaction improves the business or user outcome, Realtime can be the correct spend even when a transcription route has a lower raw hourly row.
When transcription-first wins
Start transcription-first when text is the product artifact. Typical winners include meeting summaries, call QA, compliance review, searchable archives, support analytics, coaching notes, medical or legal intake drafts that need review, asynchronous voice notes, and post-call classification.
The stop rules are practical:
- If the user does not need the assistant to speak back, do not pay for assistant audio output.
- If the transcript can arrive after the audio ends, compare bounded transcription before live transcription.
- If the product needs live captions but not a spoken assistant, price
gpt-realtime-whisperbeforegpt-realtime-2. - If summaries and classifications run after capture, budget them as text-model work outside the STT row.
- If the workflow needs a compliance trail, pipeline artifacts can be easier to inspect than a live spoken loop alone.
This route also gives teams finer control over quality gates. You can store the original audio, rerun transcription, compare model outputs, inspect prompt changes, and batch non-urgent work. For many operations teams, that control is worth more than shaving a few seconds from the transcript path.
Hybrid budget pattern
Hybrid is often the best production shape. Use Realtime for the live segment where speech changes the result, then use transcription-first processing for the parts that do not need spoken output.
A simple hybrid sequence looks like this:
- Start a
gpt-realtime-2session only for the live interaction that needs interruption, turn-taking, and speech. - Capture session metadata: user audio duration, assistant audio duration, Response count, tool calls, and whether input transcription was enabled.
- Store or export the transcript artifact only if the product and privacy policy need it.
- Run post-call summaries, QA, compliance classification, analytics, and search indexing through text or transcription-first routes.
- Review sample sessions weekly until the Realtime-live boundary and the back-office boundary are stable.
This keeps the most expensive route attached to the part of the product that actually needs it. A live onboarding agent might use Realtime for the call, then use lower-cost post-processing for CRM notes and QA. A call-center monitor might use live transcription for supervisor visibility, then run summaries and compliance checks after the call. A voice note app might avoid Realtime entirely because it only needs accurate text and a clean summary after recording.
Budget worksheet
Use three estimates: transcription-only, Realtime media floor, and full pipeline. Then replace the placeholders with measured pilot data.
| Worksheet line | Formula |
|---|---|
| Live transcript-only cost | live_audio_minutes * $0.017 for gpt-realtime-whisper |
| Bounded high-accuracy transcription cost | audio_minutes * $0.006 for gpt-4o-transcribe |
| Bounded low-cost transcription cost | audio_minutes * $0.003 for gpt-4o-mini-transcribe |
| Realtime user-audio floor | user_audio_hours * $1.152 for gpt-realtime-2 audio input |
| Realtime assistant-audio floor | assistant_audio_hours * $4.608 for gpt-realtime-2 audio output |
| Realtime media-token floor | user_audio_floor + assistant_audio_floor |
| Realtime session estimate | media floor + text tokens + tool tokens + history growth + optional input transcription |
| Pipeline estimate | STT + text model + optional TTS + telephony + storage + monitoring + QA |
Run the worksheet with low, typical, and high usage. For Realtime, change assistant speech time and Response count before changing user talk time; assistant output and repeated context often reveal the real margin risk. For a transcription-first route, change audio duration, text-model output length, retry rate, storage retention, and human-review load.
Before launch, capture evidence from real pilot sessions:
- median and p95 user audio duration
- median and p95 assistant audio duration
- Response count by session
- average conversation history size by late turn
- input transcription usage and model
- text tokens used by tools, summaries, and follow-up processing
- failed or retried sessions
- human review minutes per transcript
- current OpenAI price rows on the launch date
Recheck prices on the day you deploy. Model IDs, availability, minute rows, token rows, and account-specific access can change, and old calculators age quickly.
For adjacent cost-methodology reading, see the broader API budgeting guide in Claude API vs OpenAI API Pricing. If you are comparing standalone speech-to-text products beyond OpenAI, the Grok Speech-to-Text API guide shows a separate STT route-selection pattern.
FAQ
Is Realtime API always more expensive than a transcription pipeline?
No. Realtime voice-agent sessions usually have a higher cost floor than plain transcription, but the better question is whether live spoken interaction creates value. If the product needs interruption, low latency, tool use during the call, and spoken output, Realtime can be worth paying for. If the product needs text artifacts, a transcription-first route usually starts cheaper and is easier to budget.
Is gpt-realtime-whisper the same as using gpt-realtime-2?
No. gpt-realtime-whisper is for live transcription-only workflows that need transcript deltas without spoken assistant output. gpt-realtime-2 is the Realtime voice-agent route for live spoken assistant sessions. Treating both as one "Realtime API" row is the source of many bad cost comparisons.
Why not call $5.76/hour the Realtime hourly price?
Because it is only the media-token floor for one counted hour of user audio plus one generated hour of assistant audio at the current gpt-realtime-2 audio token rows. It excludes text tokens, repeated conversation history, tools, optional input transcription, special tokens, and any telephony or pipeline components outside the Realtime session.
Which route should I use for live captions?
Start with realtime transcription-only. The OpenAI route to price is gpt-realtime-whisper when the product needs live transcript deltas but not a spoken assistant. If the audio can wait until recording ends, compare gpt-4o-transcribe and gpt-4o-mini-transcribe instead.
Should a custom STT -> LLM -> TTS pipeline always beat Realtime?
No. A pipeline can be cheaper for text-centered work and more controllable for compliance, telephony, debugging, and vendor mix. It also adds integration work and component latency. If the user experience depends on natural interruption and spoken response quality, a native Realtime voice-agent session may be the better route even with a higher meter.
What is the safest production rule?
Pick the route first, use current official OpenAI rows for the parts OpenAI prices directly, label everything else as a variable, and pilot with real sessions before setting margin. Do not pay for spoken assistant output when text is enough, and do not call a media-token floor a final bill.