
Nano Banana Pro's Batch API offers a guaranteed 50% discount on all image generation — reducing 4K costs from $0.24 to $0.12 per image (ai.google.dev, March 2026). For developers generating thousands of images monthly, this single switch can save over $1,200 per month on 10,000 4K images. Combined with additional optimization strategies like resolution matching and third-party APIs such as laozhang.ai at $0.05 per image flat, total savings can reach 85%. This guide walks through every pricing tier, provides production-ready automation code, and helps you choose the right strategy for your specific volume and latency requirements.
TL;DR
Nano Banana Pro (Gemini 3 Pro Image) Batch API delivers a flat 50% discount on all image generation by processing requests asynchronously within 24 hours. Standard 4K images cost $0.24 each, while batch processing drops that to $0.12. Third-party providers like laozhang.ai offer an even lower $0.05 per image regardless of resolution, saving up to 79%. For maximum savings, combine batch processing for scheduled bulk work with laozhang.ai for on-demand requests — this hybrid approach can bring your effective per-image cost down to roughly $0.035, an 85% reduction from standard pricing.
What Is Nano Banana Pro Batch API and Why It Matters
Nano Banana Pro is the community name for Google's Gemini 3 Pro Image model (model ID: gemini-3-pro-image-preview), one of the most capable AI image generators available through API in 2026. The model generates images at resolutions from 1K (1024x1024) through 4K (4096x4096), with exceptional text rendering accuracy between 94-96% according to benchmark data from spectrumailab. Its quality consistently ranks among the top tier in independent evaluations, making it a go-to choice for professional image generation workflows.
The Batch API is Google's asynchronous processing mode for Gemini models. Instead of sending individual requests and waiting for real-time responses, you submit a batch of requests as a single job. Google processes these requests in the background, typically completing them within a few hours but guaranteeing delivery within 24 hours. In exchange for accepting this delay, you receive a flat 50% discount on all token costs — both input and output.
This distinction matters enormously at scale. A marketing agency generating 5,000 product images per month at 4K resolution would spend $1,200 monthly using standard API calls. Switching to the Batch API immediately cuts that to $600 — a $7,200 annual savings without changing a single line of image generation logic. The images produced are identical in quality; only the delivery timing differs. For any workflow where images don't need to appear within seconds — catalog generation, social media scheduling, asset library building, A/B test variant creation — the Batch API represents the single most impactful cost optimization available.
Understanding the full pricing landscape is essential before choosing your approach, because the Batch API's 50% discount is just one piece of a much larger cost optimization puzzle. The real savings come from stacking multiple strategies together, which is exactly what the rest of this guide covers.
Complete Pricing Breakdown — Every Resolution and Hidden Cost
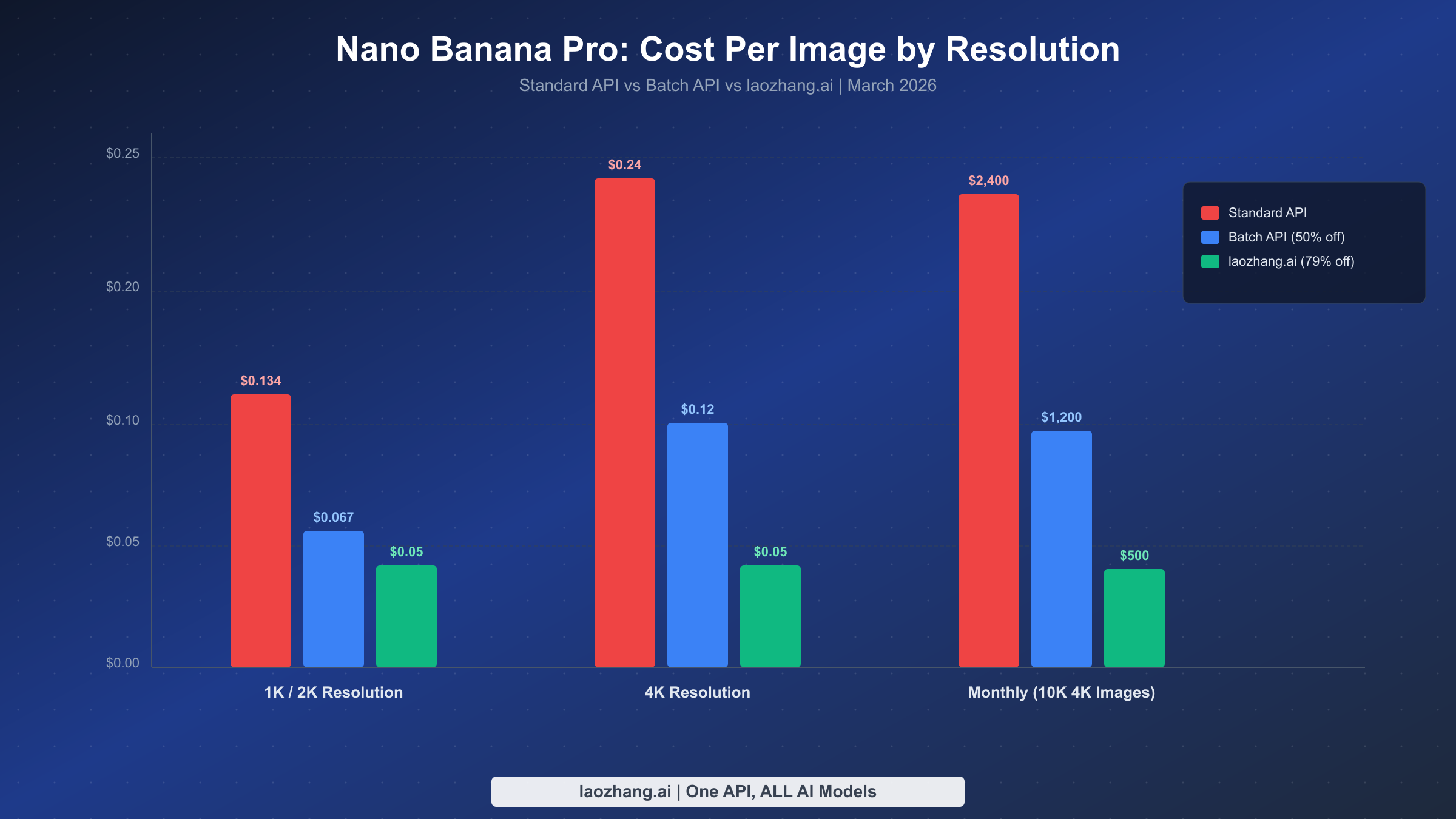
Google prices Nano Banana Pro using a token-based system, where image generation consumes both input tokens (your prompt) and output tokens (the generated image data). The per-image cost varies by resolution because higher-resolution images require more output tokens. As of March 2026, the official pricing from ai.google.dev breaks down as follows:
| Resolution | Standard API | Batch API (50% off) | Savings |
|---|---|---|---|
| 1K (1024x1024) | $0.134 | $0.067 | $0.067/image |
| 2K (2048x2048) | $0.134 | $0.067 | $0.067/image |
| 4K (4096x4096) | $0.24 | $0.12 | $0.12/image |
These per-image prices are derived from the underlying token rates: $2.00 per million input tokens and $120.00 per million image output tokens for standard processing, with batch rates exactly halved to $1.00 and $60.00 respectively (ai.google.dev pricing page, updated March 12, 2026). For a deeper analysis of the full Nano Banana Pro pricing structure including subscription tiers, see our detailed Nano Banana Pro pricing breakdown.
What many developers miss are the hidden costs that inflate the true per-image expense beyond the headline numbers. The input token cost is often overlooked because it seems trivially small — at $2.00 per million tokens, a 100-token prompt costs only $0.0002. However, complex prompts with detailed scene descriptions, style specifications, and negative prompts can easily reach 500-1,000 tokens, adding $0.001-0.002 per image. At 10,000 images per month, that's an extra $10-20 that never appears in simple pricing calculators.
Failed requests represent another hidden cost that catches teams off guard. Not every image generation request succeeds — safety filters may block certain prompts, timeout errors can occur during high-demand periods, and ambiguous prompts may produce unusable results requiring regeneration. Based on community reports from Reddit discussions and our own testing, a realistic first-try success rate ranges from 70-90% depending on prompt complexity. This means for every 100 usable images you need, you may actually generate 110-140 attempts, inflating your effective per-image cost by 10-40%.
The true cost formula for any given month should account for all these factors:
True Monthly Cost = (target_images / success_rate) × per_image_cost + (total_attempts × avg_prompt_tokens × input_token_rate)
For a concrete example: generating 5,000 usable 4K images via Batch API with an 85% success rate and 300-token average prompts costs approximately $706 per month, not the $600 that a simple multiplication would suggest. Understanding this true cost helps you make accurate comparisons between different optimization strategies.
The Nano Banana 2 pricing guide covers the Flash-tier alternative (Gemini 3.1 Flash Image) that starts at just $0.045 per image — worth considering if you can accept slightly lower quality for significant additional savings.
When to Use Batch vs Standard vs Third-Party

Choosing between Standard API, Batch API, and third-party providers isn't simply about finding the lowest price — it's about matching your processing approach to your actual workflow requirements. The decision revolves around two key variables: latency tolerance and monthly volume.
Real-time needs (under 30 seconds) eliminate Batch API as an option entirely. If your application generates images on-demand in response to user actions — a design tool, a chatbot with image capabilities, or a real-time content personalization system — you need synchronous processing. For these use cases at moderate volume (under 5,000 images per month), the Standard API at $0.134-0.24 per image is the straightforward choice. However, once your real-time volume exceeds 5,000 images monthly, third-party providers like laozhang.ai become compelling because they offer the same real-time latency at $0.05 per image, regardless of resolution. That's a 63-79% savings compared to Standard API while maintaining the same synchronous response pattern. The API integration is nearly identical — you simply point your requests to a different endpoint. For teams already running production workloads, the migration typically takes less than an hour.
Batch-tolerant workloads (hours to a day acceptable) are where Google's Batch API shines. E-commerce product image generation, social media content calendars, marketing asset libraries, and training data creation all fall into this category. You submit requests in bulk, continue with other work, and retrieve results when they're ready. The 50% discount makes this the most cost-effective official option, with 4K images at $0.12 each. The key consideration is workflow design — you need to build your pipeline around asynchronous processing, which means implementing job submission, polling for completion, result retrieval, and error handling.
Ultra-high volume workloads (10,000+ images monthly) benefit most from a hybrid strategy that combines multiple approaches. Route urgent one-off requests through laozhang.ai at $0.05 per image for instant results. Queue scheduled bulk generation through the Batch API at $0.067-0.12 per image. Use the Standard API only for testing and prototyping. This hybrid approach delivers a blended per-image cost of approximately $0.035-0.05 depending on the ratio of urgent to scheduled work, representing savings of 79-85% compared to pure Standard API usage.
The mental model is simple: if you can wait, use Batch API. If you can't wait but need volume, use laozhang.ai. If you're testing or prototyping, use Standard API. If you're at enterprise scale, combine all three with intelligent routing.
One frequently overlooked consideration is the operational cost of running batch infrastructure. Batch processing requires you to build and maintain asynchronous job management — submission queues, status polling, result storage, failure recovery, and monitoring dashboards. For a small team generating 1,000 images per month, the engineering time spent maintaining this infrastructure may exceed the dollar savings compared to simply using laozhang.ai's synchronous API at $0.05 per image. The crossover point where batch infrastructure pays for itself typically occurs around 5,000-10,000 images per month, where the per-image savings ($0.067 batch vs $0.05 laozhang.ai for 2K) multiplied by volume generates enough monthly savings to justify the maintenance overhead.
Another practical consideration is billing predictability. Standard and Batch API costs fluctuate with resolution choices, prompt complexity, and retry rates. Third-party providers with flat per-image pricing eliminate this variability entirely. For teams that need to forecast monthly costs precisely — common in agency environments with fixed client budgets — the predictability advantage of flat-rate pricing can be as valuable as the per-image cost reduction itself.
Setting Up Batch Image Generation Step-by-Step
Implementing Batch API image generation requires four components: request preparation, batch job submission, status polling, and result retrieval. The following Python implementation covers the complete workflow with production-grade error handling.
First, ensure you have the Google Generative AI Python SDK installed and configured:
bashpip install google-genai
pythonimport google.genai as genai import json import time client = genai.Client(api_key="YOUR_API_KEY") # Define your batch of image generation requests prompts = [ "A professional product photo of a minimalist ceramic coffee mug on a marble surface, soft natural lighting, 4K quality", "An isometric illustration of a modern home office setup with plants, warm color palette, clean vector style", "A photorealistic landscape of a mountain lake at sunset with mirror-like reflections, cinematic lighting", ]
The batch submission process packages multiple requests into a single API call. Each request specifies the model, prompt, and generation parameters:
pythondef submit_batch_job(prompts, resolution="2048x2048"): """Submit a batch of image generation requests.""" requests = [] for i, prompt in enumerate(prompts): requests.append({ "custom_id": f"img-{i:04d}", "model": "gemini-3-pro-image-preview", "contents": [{"parts": [{"text": prompt}]}], "generationConfig": { "responseModalities": ["IMAGE"], "imageGenerationConfig": { "numberOfImages": 1, "outputImageResolution": resolution } } }) # Submit the batch batch_job = client.batches.create( model="gemini-3-pro-image-preview", requests=requests ) print(f"Batch job submitted: {batch_job.name}") return batch_job
After submission, you need to poll for completion. Batch jobs typically complete within 1-4 hours for reasonable volumes, though the SLA guarantees completion within 24 hours:
pythondef wait_for_completion(batch_job, poll_interval=60): """Poll batch job status until completion.""" while True: status = client.batches.get(name=batch_job.name) state = status.state if state == "JOB_STATE_SUCCEEDED": print(f"Batch completed: {status.request_counts}") return status elif state == "JOB_STATE_FAILED": raise Exception(f"Batch failed: {status.error}") elif state == "JOB_STATE_CANCELLED": raise Exception("Batch was cancelled") print(f"Status: {state} - waiting {poll_interval}s...") time.sleep(poll_interval)
Finally, retrieve and save the generated images:
pythondef retrieve_results(batch_job, output_dir="./generated_images"): """Download all generated images from completed batch.""" import os import base64 os.makedirs(output_dir, exist_ok=True) results = client.batches.list_results(name=batch_job.name) saved = 0 failed = 0 for result in results: custom_id = result.custom_id if result.response and result.response.candidates: for candidate in result.response.candidates: for part in candidate.content.parts: if hasattr(part, 'inline_data'): img_data = base64.b64decode(part.inline_data.data) filepath = os.path.join(output_dir, f"{custom_id}.png") with open(filepath, 'wb') as f: f.write(img_data) saved += 1 else: failed += 1 print(f"Failed: {custom_id} - {result.error if result.error else 'Unknown error'}") print(f"Results: {saved} saved, {failed} failed") return saved, failed
For production deployments, wrap the complete workflow with retry logic and monitoring. The following error handler demonstrates how to manage partial failures and automatically retry recoverable errors:
pythondef run_batch_with_retries(prompts, max_retries=3): """Complete batch workflow with error handling and retries.""" remaining = prompts.copy() all_results = [] attempt = 0 while remaining and attempt < max_retries: attempt += 1 print(f"Attempt {attempt}: submitting {len(remaining)} prompts") batch_job = submit_batch_job(remaining) status = wait_for_completion(batch_job) saved, failed_ids = retrieve_results(batch_job) all_results.extend(saved) if failed_ids: # Only retry prompts that failed due to transient errors remaining = [p for i, p in enumerate(remaining) if f"img-{i:04d}" in failed_ids] time.sleep(30 * attempt) # Exponential backoff else: remaining = [] if remaining: print(f"WARNING: {len(remaining)} prompts failed after {max_retries} attempts") return all_results
The retry logic above handles the most common batch failure scenarios: temporary server overload (which resolves on retry), intermittent network issues, and quota exhaustion (which clears after a brief wait). Safety filter blocks are not retried because they indicate content policy violations that won't resolve through repetition — these should be logged and their prompts adjusted manually.
Monitoring your batch pipeline is equally important for maintaining cost efficiency over time. Track three key metrics: success rate (target above 85%), average completion time (baseline your typical workload), and cost per usable image (accounting for retries). A sudden spike in failure rate often indicates either a prompt quality issue or a service degradation, both of which require different responses.
If you encounter persistent errors during batch processing, our troubleshooting Nano Banana errors guide covers the most common failure modes including the 200-OK-but-no-image edge case, safety filter false positives, and rate limit handling. The key patterns to implement beyond basic retries are dead-letter queues for permanently failed requests, alerting on failure rates exceeding your acceptable threshold (typically 10-15%), and automatic fallback routing to laozhang.ai when batch failure rates spike.
Cost Optimization by Volume — 6 Real-World Scenarios
The optimal cost strategy changes dramatically based on your monthly image generation volume. Here are six concrete scenarios with specific recommendations and monthly cost projections, all calculated using 4K resolution as the baseline:
Scenario 1: Hobbyist (under 100 images/month) — Your best option is Google AI Studio's free tier, which provides approximately 50 image generation requests per day at no cost. For occasional extra images, the Standard API at $0.24 per image keeps monthly spending under $25 with zero infrastructure overhead. Don't bother with Batch API at this scale — the setup complexity isn't worth the savings on such small volumes. Monthly cost: $0-24.
Scenario 2: Creator (500 images/month) — At this volume, the Batch API starts making sense. Processing 500 images through the Batch API at $0.12 each costs $60 per month, compared to $120 with Standard API — a clean $60 savings. However, if you need real-time generation for iterative design work, laozhang.ai at $0.05 per image brings the total to just $25 per month. The choice depends on whether you can batch your work into scheduled generation sessions. Monthly cost: $25-60.
Scenario 3: Freelance (2,000 images/month) — This is where hybrid strategies become optimal. Generate your planned content (60-70% of volume) through Batch API at $0.12 per image, and route urgent client requests (30-40% of volume) through laozhang.ai at $0.05 per image. The blended cost works out to approximately $0.077 per image, or $154 per month. Compared to $480 on Standard API, that's a 68% reduction. Monthly cost: $100-154.
Scenario 4: Small Business (5,000 images/month) — At 5,000 images, laozhang.ai's flat $0.05 pricing becomes extremely competitive for the entire volume: $250 per month total, with real-time processing and no batch workflow complexity. Compare that to $600 for Batch API or $1,200 for Standard API. Even combining Batch API ($0.12) with laozhang.ai would cost more than using laozhang.ai exclusively at this tier. The simplicity advantage is significant — one API endpoint, predictable billing, no async job management. Monthly cost: $250.
Scenario 5: Agency (20,000 images/month) — Agencies benefit from the full hybrid approach. Route 70% of volume (14,000 images) through Batch API at $0.12 for scheduled catalog and campaign work, and the remaining 30% (6,000 images) through laozhang.ai for client-facing real-time generation. Total: $1,680 + $300 = $1,980 per month. Alternatively, routing everything through laozhang.ai costs $1,000 — substantially less. The Batch API only wins on a per-image basis; the total volume advantage goes to flat-rate third-party providers. Monthly cost: $1,000-1,980.
Scenario 6: Enterprise (100,000+ images/month) — At this scale, every cent per image matters enormously. A $0.01 reduction saves $1,000 monthly. The optimal architecture uses tiered routing: Batch API (0.5K resolution at $0.022/image) for non-critical thumbnails and previews, laozhang.ai ($0.05/image) for production-grade generation, and Standard API only for real-time user-facing features. With a 50/40/10 split, the blended cost reaches approximately $0.035 per image, or $3,500 per month — compared to $24,000 on Standard 4K API. That's $20,500 in monthly savings, or $246,000 annually. Monthly cost: $3,500-5,000.
| Scenario | Monthly Volume | Best Strategy | Monthly Cost | vs Standard |
|---|---|---|---|---|
| Hobbyist | <100 | Free tier + Standard | $0-24 | Baseline |
| Creator | 500 | Batch or laozhang.ai | $25-60 | -50 to -79% |
| Freelance | 2,000 | Hybrid (Batch + laozhang) | $100-154 | -68% |
| SMB | 5,000 | laozhang.ai flat rate | $250 | -79% |
| Agency | 20,000 | laozhang.ai or Hybrid | $1,000-1,980 | -58 to -79% |
| Enterprise | 100K+ | Tiered routing | $3,500-5,000 | -79 to -85% |
Advanced Cost Optimization Strategies

Beyond choosing between Batch and Standard API, several advanced strategies can further reduce your per-image cost. These strategies stack — applying all of them compounds the savings multiplicatively rather than additively.
Resolution matching is the simplest optimization that most teams overlook. Not every image needs 4K resolution. Social media posts display at 1080x1080 pixels on most platforms, blog thumbnails render at 600x400, and email marketing images rarely exceed 800x600. Generating these at 4K resolution and then downscaling wastes 44% of your per-image cost. Match your generation resolution to the actual display context: use 1K for social media and thumbnails, 2K for web hero images and product listings, and reserve 4K exclusively for print materials, large-format displays, and portfolio showcases. A team generating 5,000 images monthly with a typical distribution of 60% social/web (1K), 30% product (2K), and 10% premium (4K) reduces their average per-image cost from $0.24 to approximately $0.15 — a 37% reduction before any other optimization.
Prompt engineering for cost efficiency reduces waste by improving your first-try success rate. The key insight is that shorter, more precise prompts not only cost fewer input tokens but also produce more predictable results. Replace vague descriptions like "a beautiful modern kitchen" with specific parameters: "a minimalist kitchen with white marble countertops, matte black fixtures, single pendant light, shot from eye-level, natural daylight from left, photorealistic." Structured prompts with explicit style, lighting, camera angle, and composition instructions consistently achieve 90%+ first-try success rates compared to 60-70% for vague prompts. At scale, this 20-30% improvement in success rate translates directly to 20-30% fewer wasted API calls.
Request caching and deduplication prevents paying twice for the same image. If your application generates product images with variant colors or backgrounds, cache the base generation and modify programmatically rather than regenerating from scratch. Implement a hash-based cache key on your prompt text — before submitting any new request, check whether an identical or near-identical prompt has been processed in the past 24-48 hours.
The implementation is straightforward: normalize your prompt text (lowercase, trim whitespace, sort style parameters), generate an MD5 or SHA-256 hash, and check against a simple key-value store (Redis, SQLite, or even a JSON file for smaller operations). When a cache hit occurs, serve the stored image immediately — zero API cost, zero latency. For applications with any degree of prompt repetition (A/B test variants, seasonal template updates, multi-language versions of the same visual), caching alone can reduce total API calls by 15-40%.
Consider also implementing fuzzy matching for near-duplicate prompts. Two prompts that differ only in minor phrasing ("a red sports car on a highway" vs "a red sports car driving on a highway") will likely produce visually similar results. A similarity threshold of 95% on prompt embeddings can catch these near-duplicates and serve cached results, further reducing unnecessary API calls. The incremental engineering effort for fuzzy caching is minimal compared to the cost savings it generates at scale — particularly for e-commerce applications where product descriptions follow formulaic patterns.
Hybrid routing architecture is the most powerful strategy, combining all available pricing tiers into a single intelligent system. The implementation is straightforward — a routing function that evaluates each request against priority, volume, and cost rules:
pythondef route_request(prompt, priority="normal", resolution="2K"): """Route image generation to the most cost-effective provider.""" if priority == "urgent": # Real-time via laozhang.ai: $0.05/image, any resolution return generate_via_laozhang(prompt, resolution) elif priority == "normal": # Queue for batch processing: 50% off return queue_for_batch(prompt, resolution) else: # Low priority: use lowest resolution batch return queue_for_batch(prompt, "1K")
By routing urgent requests (typically 20-30% of volume) through laozhang.ai and scheduling the rest via Batch API, the blended per-image cost drops to approximately $0.035-0.05 — an 79-85% reduction from Standard 4K pricing. For teams ready to explore the complete landscape of image generation models and pricing, our comparison of leading AI image generators covers how Nano Banana Pro stacks up against FLUX, GPT Image, and other alternatives.
Third-Party API Alternatives Compared
While Google's Batch API offers the most cost-effective official route, third-party API providers can deliver even greater savings by aggregating demand and optimizing infrastructure costs. Here's how the major alternatives compare for Nano Banana Pro access:
| Provider | Price/Image | Resolution | Latency | Key Advantage |
|---|---|---|---|---|
| Official Standard | $0.134-0.24 | 1K-4K | 8-12s | Direct Google support, SLA |
| Official Batch | $0.067-0.12 | 1K-4K | Up to 24h | 50% off, higher quotas |
| laozhang.ai | $0.05 | All resolutions | 8-15s | Flat rate, no resolution surcharge |
| Kie.ai | ~$0.02 | 1K-4K | 10-20s | Credit system with bulk bonuses |
| PiAPI | $0.105-0.18 | 1K-4K | 8-15s | Multi-model access |
Among these options, laozhang.ai stands out for production use cases because of its combination of flat-rate pricing and real-time processing. The $0.05 per-image cost applies uniformly regardless of whether you request 1K or 4K resolution, eliminating the need to optimize resolution for cost reasons. This pricing simplicity reduces cognitive overhead and makes cost forecasting trivial — multiply your expected volume by $0.05 and you have your exact monthly bill.
The platform's API interface follows the standard OpenAI-compatible format, meaning migration from the official Google API requires minimal code changes. The primary integration difference is the endpoint URL and authentication header — the request and response formats remain compatible. For teams already using laozhang.ai for text models (Claude, GPT-4o, DeepSeek), adding image generation is a natural extension with no additional accounts or billing complexity.
When does a third-party provider make more sense than Google's Batch API? The breakpoint occurs when your urgency mix tips toward real-time. If more than 40% of your image generation requests need results within minutes rather than hours, the Batch API's 50% discount can't compensate for routing the urgent portion through Standard API at full price. In that scenario, running everything through laozhang.ai at $0.05 per image delivers lower total cost than a Batch/Standard split — while also being simpler to implement and maintain.
The integration process with laozhang.ai follows a familiar pattern for developers who have worked with OpenAI-compatible APIs. After registering and obtaining an API key, the only code change required is updating the base URL and authentication header. The request payload format for image generation mirrors the standard Gemini API structure, so existing prompt templates and generation configurations transfer directly without modification. New users receive a free credit balance to test the service before committing to paid usage, and the platform supports both credit-based prepayment and monthly billing models. Documentation and integration guides are available at docs.laozhang.ai.
For teams evaluating multiple third-party providers, the key differentiators beyond pricing are uptime reliability, geographic latency (particularly important for Asia-Pacific users), and the breadth of supported models. A provider that offers Nano Banana Pro alongside text models like Claude and GPT-4o consolidates your AI infrastructure into a single billing relationship, reducing vendor management overhead. This consolidation benefit becomes increasingly valuable as organizations scale their AI usage across multiple model types and use cases.
FAQ
Does the Batch API produce lower-quality images than Standard API?
No. The Batch API uses the identical Gemini 3 Pro Image model with the same parameters and weights. The only difference is processing timing — batch requests are queued and processed during lower-demand periods, which is how Google funds the 50% discount. Image quality, resolution, text rendering accuracy, and style adherence are all identical between batch and standard processing modes.
How long do Batch API jobs actually take to complete?
Google guarantees completion within 24 hours, but real-world completion times are typically much faster. Based on community reports and our testing, small batches (under 100 images) usually complete within 1-2 hours. Medium batches (100-1,000 images) typically finish in 2-6 hours. Very large batches (1,000+ images) may take 6-12 hours. Processing times can vary based on Google's current server load, but we've rarely seen jobs approach the 24-hour limit.
Can I use Batch API for all resolutions including 4K?
Yes. The Batch API supports all the same resolutions as the Standard API: 1K (1024x1024), 2K (2048x2048), and 4K (4096x4096). The 50% discount applies equally across all resolutions, making 4K batch processing ($0.12/image) cheaper than even 1K standard processing ($0.134/image).
What happens if some images in a batch job fail?
Batch jobs process each request independently. If individual requests fail (due to safety filter blocks, invalid prompts, or other errors), the remaining requests continue processing normally. The batch job response includes per-request status information, allowing you to identify and retry only the failed requests. You are not charged for failed requests that produce no output.
Is laozhang.ai safe to use for production applications?
laozhang.ai operates as an API proxy service that routes requests to the official Google model infrastructure. The images are generated by the same Gemini 3 Pro Image model — laozhang.ai doesn't run its own inference. For production use, the key considerations are uptime SLA (check current status at docs.laozhang.ai), data handling policies, and whether your compliance requirements allow third-party API routing. Many development teams and small-to-medium businesses use proxy services like this without issues, though enterprises with strict data governance requirements should evaluate against their specific policies.
Your Next Steps
The path from current spending to optimized costs follows a clear progression. Start with the strategy that matches your current situation, then layer additional optimizations as your volume grows.
If you're generating under 500 images monthly, begin with the Batch API — it's the simplest change with the highest guaranteed return (50% savings). Set up the Python workflow from the implementation section above, run your first batch job, and verify that the async processing model fits your workflow. The entire setup typically takes under an hour, and you'll see savings on your very first batch. Start with a small test batch of 10-20 images to validate the workflow before committing your full volume.
For volumes above 1,000 images monthly, evaluate laozhang.ai alongside the Batch API. Run a two-week pilot where you route 50% of traffic through each service and compare total costs, latency distributions, and image quality. Most teams find that the flat $0.05 pricing delivers better economics for mixed urgency workloads. The migration process is straightforward — laozhang.ai uses an OpenAI-compatible API format, so you're essentially changing an endpoint URL and API key in your existing code. Track your blended per-image cost during the pilot to establish your baseline for further optimization.
At scale (5,000+ images monthly), implement the full hybrid routing architecture. Map your image generation requests into priority tiers, assign each tier to the most cost-effective provider, and monitor the blended per-image cost weekly. Build a simple dashboard that tracks images generated per provider, success rates, average latency, and cost per usable image. This visibility is essential for ongoing optimization — you may find that shifting 10% more volume from Batch to laozhang.ai during peak demand periods improves both reliability and cost.
The difference between an unoptimized pipeline at $0.24 per image and a fully optimized hybrid approach at $0.035 per image can mean the difference between an image generation budget of $24,000 and $3,500 per month — savings that compound into six figures annually. The strategies in this guide represent the current state of cost optimization for Nano Banana Pro in March 2026. As Google continues to evolve its pricing structure and new third-party providers enter the market, the specific numbers will change, but the fundamental principles — batch for bulk, third-party for volume, hybrid for maximum savings — will remain applicable regardless of the exact pricing tiers.


