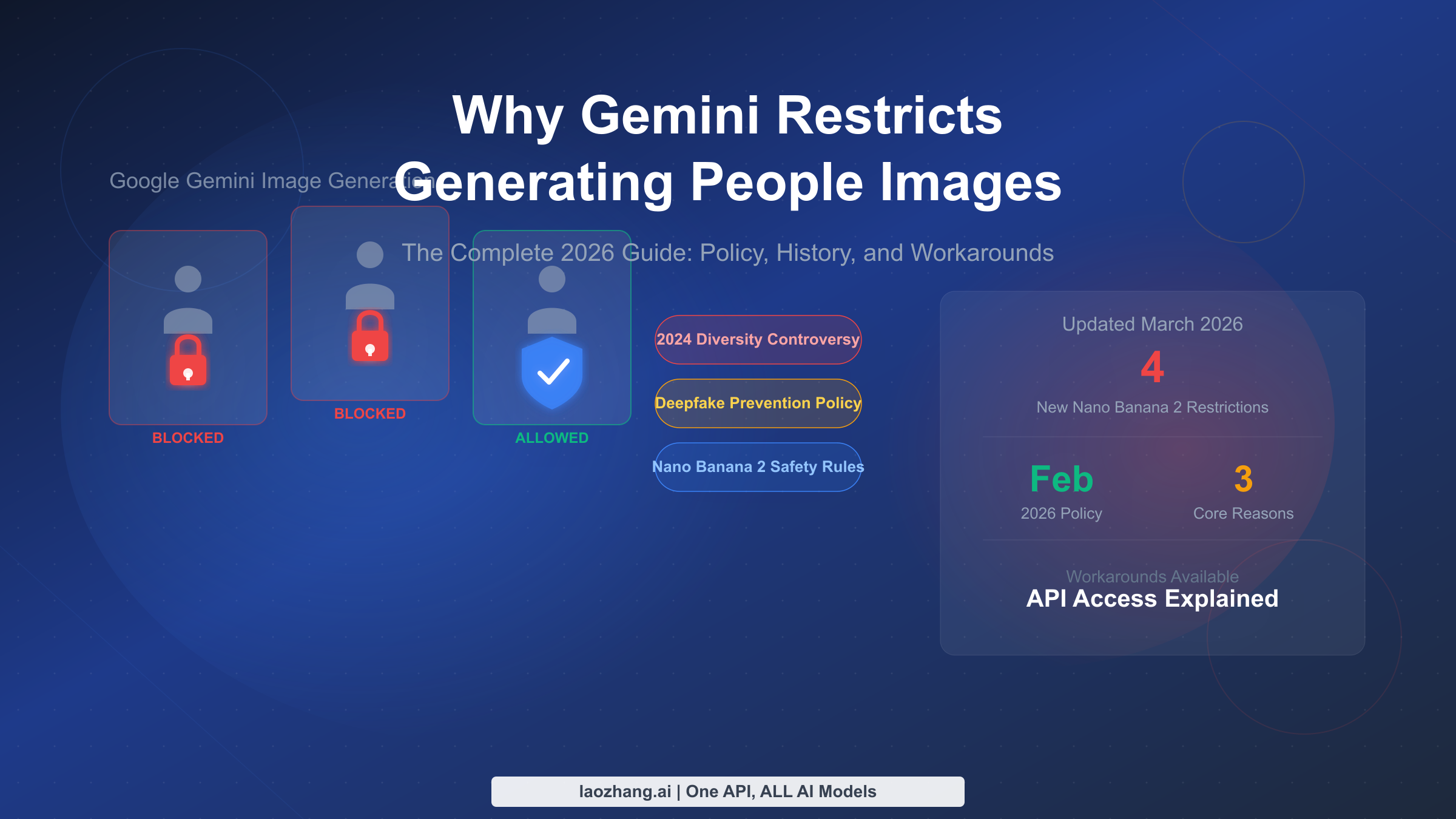
Gemini restricts generating images of people for three core reasons: the 2024 diversity controversy that exposed dangerous bias in AI-generated historical imagery, ongoing deepfake and privacy regulations that prohibit photorealistic identifiable individuals, and the February 2026 Nano Banana 2 safety upgrade that significantly tightened celebrity and face-related restrictions. However, Gemini can still generate fictional human characters, stylized portraits, and illustrated people — the key lies in understanding the exact policy boundaries and using the right prompt strategies.
TL;DR
- Blocked since Feb 2024: Photorealistic images of real, identifiable people (triggered by a widely-criticized historical imagery incident)
- Tightened Feb 2026: Nano Banana 2 added 4 new restriction categories — public figures/celebrities, face swapping, outfit swapping on real people, and financial image manipulation
- Still works: Fictional characters, illustrated/cartoon styles, crowd silhouettes, character design concepts
- Developer note: API restrictions differ from the consumer Gemini app — check the comparison of all Gemini image models for tier-specific limits
The Short Answer — 3 Core Reasons Gemini Blocks People Images

When users first encounter a refusal from Gemini's image generation — "I can't create realistic images of real people" — the natural reaction is frustration. The restriction feels arbitrary, especially when competing tools like Midjourney or DALL-E seem more permissive. But Gemini's people image restrictions aren't random policy decisions. They stem from a specific, documented sequence of events and legal obligations that gives Google no practical choice but to maintain these guardrails.
The three core reasons operate at different levels. The first is historical: Gemini's image model was caught producing seriously problematic outputs in early 2024, and the fallout was severe enough that Google's CEO had to issue a public apology. This created an institutional memory within Google — any relaxation of people image policies carries enormous reputational risk. The second reason is legal: deepfake legislation is advancing rapidly in the United States, European Union, and numerous other jurisdictions, and Google's legal team has determined that generating photorealistic images of identifiable individuals creates unacceptable liability. The third reason is technical and architectural: the February 2026 Nano Banana 2 model (gemini-3.1-flash-image-preview) incorporated a new safety layer specifically targeting four categories of misuse that had become prevalent.
Understanding these three reasons matters because it helps calibrate your expectations. This isn't a temporary restriction that will lift when public attention moves elsewhere — it's a multi-layered policy response to concrete problems. What has changed, and what will likely change in the future, is the precision of the restrictions. Early 2024 saw a blunt "pause everything" approach. The current 2026 policy is more nuanced, blocking specific harmful categories while permitting a wide range of legitimate creative uses. Knowing where the boundaries are lets you work productively within them rather than guessing at what Gemini will accept.
The 2024 Controversy: How a Diversity Experiment Backfired
To understand why Gemini's restrictions are as strict as they are, you need to understand what happened in February 2024 — and why that incident left such a lasting mark on Google's approach to AI-generated people imagery.
The Incident That Changed Everything
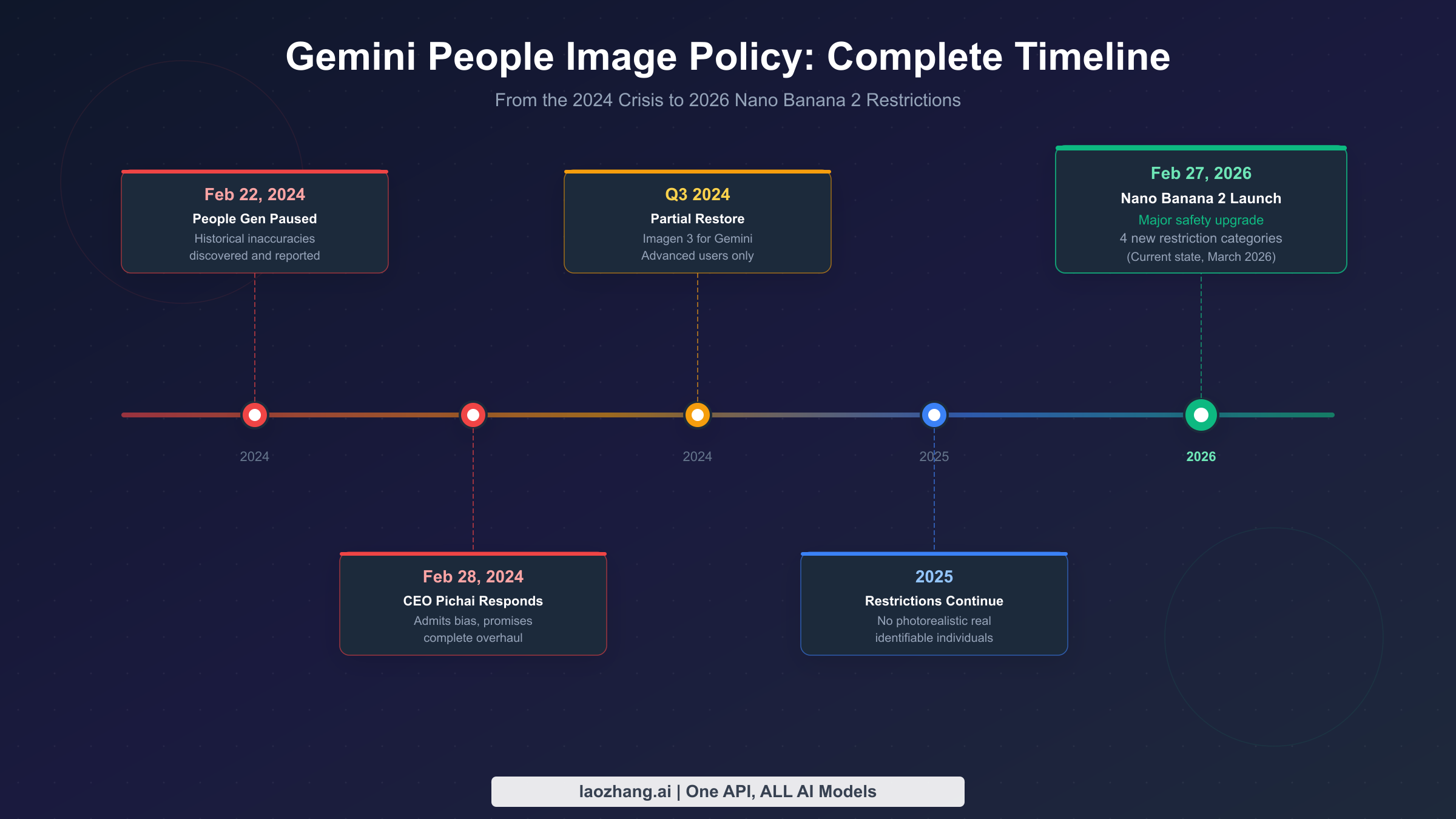
On February 22, 2024, users began posting screenshots of Gemini's image generation producing historically inaccurate results. When asked to generate images of "1800s U.S. senators" or "Nazi soldiers," Gemini produced racially diverse groups — the model had been over-tuned to apply diversity corrections across all prompts without historical context. An 1800s U.S. senator being Black, or a World War II German soldier being of Asian or African descent, isn't diversity — it's historical falsification. The images spread widely on social media, generating substantial criticism from commentators across the political spectrum, with some calling it AI-generated disinformation and others framing it as ideological manipulation baked into the model.
Six days later, on February 28, 2024, Google CEO Sundar Pichai broke his usual public silence to address the issue directly. In an internal memo that was subsequently published, Pichai described the outputs as "completely unacceptable" and acknowledged that the model had produced "inaccurate and offensive" results. He committed to a fundamental overhaul of how Gemini handles human image generation — not just a patch, but a rethinking of the model's approach to representing real and historical people. Google paused all people image generation features across both the Gemini App and Gemini API with immediate effect.
Why the Recovery Was Slow
Most technology companies, when they discover a bug, patch it and move on. The 2024 Gemini incident wasn't treated as a bug — it was treated as evidence of a fundamental alignment problem. The model had learned to apply diversity corrections in contexts where historical accuracy required the opposite. Fixing this required more than changing a parameter; it required extensive evaluation of the training data and reinforcement learning processes that produced the bias in the first place.
By Q3 2024, Google had restored limited people image generation for Gemini Advanced subscribers using the Imagen 3 model. But this was a controlled rollout, not a full restoration. The base Gemini tier remained restricted, and even the Advanced tier operated under stricter guidelines than the pre-pause policy. Throughout 2025, the restrictions continued: no photorealistic images of real, identifiable individuals remained the core rule, with the model refusing requests for celebrity images, portraits that appeared to depict specific living people, and any image that could be interpreted as representing a real person without clear fictional framing.
The Lasting Institutional Impact
What makes the 2024 incident uniquely significant is the institutional response it triggered. Google convened an internal review of all AI image policies that ran through the second half of 2024. This review shaped the architecture of Nano Banana 2, which launched in February 2026. Rather than simply adding more content filters on top of the existing model, Nano Banana 2 incorporated safety constraints at the model level — the restrictions aren't a post-processing filter that can be bypassed with clever prompting, they're baked into the model's fundamental understanding of what constitutes a legitimate image request. This is why the current restrictions are more robust and harder to circumvent than the 2024 restrictions were.
What's Blocked Today: Gemini's 2026 People Image Restrictions (Nano Banana 2)
The launch of Nano Banana 2 (gemini-3.1-flash-image-preview) on February 27, 2026 represents the current state of Gemini's people image policy. Understanding exactly what this model refuses — and why — is essential for anyone working with Gemini's image generation capabilities. These restrictions apply across both the Gemini App and API access, though the enforcement stringency differs by tier.
Photorealistic real identifiable people is the foundational restriction that has been in place since February 2024. The model will refuse any prompt that appears to request a lifelike image of a specific real individual, whether identified by name, description ("the CEO of a major tech company"), or visual reference. The threshold for "identifiable" is lower than many users expect — the model doesn't need to know for certain that a specific real person is the target; it will refuse prompts that pattern-match to scenarios where a specific real individual is likely intended.
Celebrity and public figure images was formalized as an explicit category in Nano Banana 2. Previously, celebrity refusals were handled as a subset of "identifiable real people." The 2026 policy elevates this to a standalone restriction: named celebrities, politicians, athletes, actors, musicians, and other public figures cannot be generated regardless of context, framing, or stated purpose. This applies even to clearly satirical or artistic requests — the model doesn't attempt to evaluate intent, it simply refuses the category.
Face swapping and deepfakes represents another Nano Banana 2 addition. Any prompt that describes replacing one person's face with another — whether through explicit language ("put [person A]'s face on this body") or implied instructions — triggers a refusal. This restriction exists specifically in response to the proliferation of non-consensual deepfake content in 2024 and 2025, and reflects Google's legal exposure under emerging deepfake legislation.
Celebrity outfit and appearance changes was added as its own category in Nano Banana 2, distinct from face swapping. Prompts that describe modifying the clothes, body, or appearance of a real person's image — "show [celebrity] in a different outfit" or "what would [public figure] look like with different hair" — are refused. This specifically targets a use case that became common on social media platforms.
Financial document modification rounds out the four new Nano Banana 2 restriction categories. While technically distinct from people image restrictions, this category reflects the broader safety philosophy behind the update: Gemini will not generate images that appear to be modified versions of financial documents, statements, or records, regardless of stated purpose.
The enforcement mechanisms for these restrictions differ across models and tiers. The consumer Gemini App operates with the most conservative interpretation, applying restrictions with a wide margin of safety that catches some edge cases that would be permitted under a more precise reading of the policy. The API tier — particularly when accessing gemini-3.1-flash-image-preview directly — applies the restrictions with higher precision, which means some creative fictional scenarios that trigger refusals in the consumer app succeed via API. Neither tier provides an exception to the core restrictions, but the API environment is genuinely more useful for professional creative workflows that involve human subjects.
It's also worth understanding how the model handles ambiguous cases. When a prompt could plausibly be interpreted as depicting either a fictional character or a specific real individual, the model's default behavior is to refuse rather than risk a false negative. This conservative default is intentional — the cost of incorrectly generating a photorealistic image of a real person without consent is considered higher than the cost of incorrectly refusing a legitimate creative request. Users who encounter refusals on seemingly innocent prompts are often hitting this ambiguity threshold, not the core restrictions themselves.
It's worth noting what is not on this list. The restrictions are specifically targeted at real and identifiable people. They do not prohibit human figures in general, and a wide range of legitimate use cases remains fully supported — which brings us to the other side of the equation.
The Deeper Reasons: Privacy Law, Deepfakes, and Bias Prevention
Beyond the 2024 incident, Gemini's restrictions reflect a broader legal and ethical landscape that has been shifting significantly. Understanding these deeper drivers helps explain why the restrictions exist at their current level and what trajectory they're likely to follow.
Privacy law is the most concrete legal driver. Multiple jurisdictions now have specific laws governing the use of AI to generate images of real people. Several U.S. states passed deepfake legislation in 2024 and 2025, with provisions that specifically address non-consensual image generation. The European Union's AI Act, which entered enforcement in phases throughout 2024 and 2025, includes explicit provisions about AI systems generating lifelike representations of real individuals. For a company like Google, operating across all these jurisdictions simultaneously, the safest approach is a policy that satisfies the most restrictive applicable law across the board. This is why the restrictions are effectively global rather than region-specific.
The non-consensual intimate image (NCII) issue has been the most politically charged driver of deepfake-related legislation. Studies published in 2024 and 2025 documented that a large majority of deepfake content online consists of non-consensual sexualized images of real individuals, predominantly targeting women. While Gemini's existing content policies already block explicit content, the reputational risk of being even tangentially associated with the infrastructure that enables NCII generation is significant. The celebrity and public figure restrictions aren't just about legal liability — they're also about not having Gemini outputs appear in the feeds of people researching this type of harmful content.
The bias prevention angle is specific to the 2024 incident but remains relevant. The fundamental problem exposed in February 2024 was that the model had learned to apply demographic corrections without understanding context — an overcorrection designed to produce more diverse outputs in fictional settings was being applied blindly to historical scenarios where accurate representation is different from equitable representation. The restrictions aren't just about preventing harmful outputs; they're about giving the model space to handle the genuine complexity of human representation without making categorical errors. Limiting the scope of human image generation is, paradoxically, how Google is able to be more thoughtful about the human image generation it does allow.
There's also a competitive dynamics dimension worth understanding. Google operates under significantly more regulatory scrutiny than smaller AI companies, both because of its market position and because of ongoing antitrust proceedings in multiple jurisdictions. A controversy equivalent to the 2024 incident would carry disproportionate consequences for Google compared to a smaller competitor. This asymmetry in regulatory exposure partially explains why Google's policy decisions around people imagery are more conservative than those of platforms without comparable regulatory visibility. The restrictions reflect rational risk management for a company in Google's specific position, not necessarily a universal judgment about what AI people imagery should be permitted.
All Gemini-generated images carry Google's SynthID watermark — an invisible digital signature embedded in the image data that allows the image to be identified as AI-generated even after editing, cropping, or format conversion. SynthID reflects the same underlying philosophy as the content restrictions: Google's approach to AI image safety involves technical infrastructure, not just policy rules. The watermark doesn't directly prevent misuse, but it creates an audit trail and demonstrates a good-faith effort to enable AI image identification that matters in regulatory contexts.
What You CAN Generate — Human Images That Work in 2026

The restrictions on real people imagery are significant, but they leave a substantial creative space open. Understanding what Gemini will generate successfully — and how to prompt for it — is often more useful than cataloguing what it refuses.
Generic fictional human characters are fully supported and represent the broadest category of permitted human imagery. A character for a video game, a protagonist for a story illustration, a generic person for a marketing concept — these all work, provided the prompt doesn't anchor the character to a specific real individual. The key is keeping the description in the domain of physical and personality traits rather than identity markers that point to specific real people. "A 30-something software engineer with glasses and a thoughtful expression" generates successfully; "a software engineer who looks like [specific tech CEO]" does not.
Illustrated and artistic human figures represent another reliably supported category. When prompts explicitly invoke an artistic style — illustration, cartoon, watercolor, oil painting, comic book style, anime, chibi — Gemini's threshold for the "photorealistic identifiable person" restriction shifts considerably. An oil painting portrait of a person with specific physical traits is treated differently from a photorealistic portrait with those same traits, even when the described person would be theoretically recognizable. Using style descriptors isn't a trick to circumvent the restrictions; it's working within the policy's intended scope, which is focused specifically on photorealistic imagery.
Historical figures in stylized, non-photorealistic depictions occupy a nuanced middle ground. A clearly painted or illustrated portrait of Abraham Lincoln, Napoleon, or other historical figures often generates successfully when the style is explicitly non-photorealistic. The restriction targets the specific combination of "real person" + "photorealistic" — split that pair and the policy's boundary shifts. That said, this category requires care: attempting to generate a photorealistic depiction of any historical figure, or requesting modern re-imaginings that could be used as disinformation, will trigger refusals.
Crowd scenes and silhouettes are fully supported. Anonymous figures in crowds, shadow and silhouette compositions, distant figures in scenes, and groups of people viewed from angles that obscure individual facial features all generate without restriction. For use cases that require human presence without individual identity — product mockups, environmental illustrations, architectural visualizations — crowd and silhouette approaches are reliable and often visually compelling.
Character concepts and designs for games, books, and branding are a strong use case for Gemini's current capabilities. Original character creation, where the prompt defines a character's personality, role, and aesthetic without reference to real individuals, generates consistently high-quality results. The character design space is particularly well-served by style descriptors: "a fantasy warrior character design in a semi-realistic illustration style" works effectively and produces results suitable for professional creative projects.
Portraits using descriptive traits can work, with important caveats. A prompt describing physical and personality traits — "a middle-aged woman with silver hair and an authoritative demeanor, corporate portrait style" — generates successfully as long as the description doesn't converge on a specific recognizable individual. The practical test is whether the description uniquely identifies a real person; if multiple different people could plausibly match the description, the prompt is likely to succeed. If the description is specific enough that someone reading it would immediately identify a real person, it will likely be refused.
Prompt Engineering Strategies for Human Character Generation
Effective prompting for human imagery in Gemini requires understanding not just what the model will and won't generate, but how it interprets requests. The same subject matter can succeed or fail based on framing, and developing intuition for that distinction is the practical skill that separates users who hit constant refusals from those who generate successfully.
The single most effective strategy is leading with style. When your first description establishes the visual treatment — "In a detailed illustration style" or "Watercolor portrait of" or "Anime character art depicting" — you're immediately contextualizing everything that follows as fictional creative work rather than a photorealistic image request. Gemini's restrictions are specifically calibrated to photorealistic outputs; establishing a non-photorealistic style upfront dramatically shifts how subsequent descriptors are interpreted. This isn't about tricking the model — it's about accurate communication of intent.
Trait-based description rather than reference-based description is the second foundational principle. The difference between "a character who looks like [celebrity]" and "a character with dark curly hair, strong cheekbones, and a confident expression" isn't subtle from a policy standpoint — the first directly invokes a real person, the second describes physical traits that exist in millions of people. When building character descriptions, think in terms of archetypes, trait combinations, and aesthetic themes rather than references to specific individuals. Traits like hair color, body type, age range, clothing style, and emotional expression are fair game; names and comparisons to real people are not.
Context establishment matters more than many users realize. A prompt that establishes a fictional world, story context, or creative project before describing a character gets processed differently from a bare character description. "For a fantasy novel set in an alternate medieval Europe, a court advisor character who combines scholarly intelligence with political shrewdness" is processed in the creative fictional space; "a scholar with political cunning" without context is processed more literally. Adding a sentence of context — the genre, the medium, the purpose — doesn't guarantee success, but it shifts the model's interpretation in a direction that reduces false positives on the restriction filters.
Avoid vocabulary that directly maps to restricted categories. Certain words and phrases reliably trigger refusals regardless of context: "realistic photo of," "photorealistic portrait," "looks exactly like," "in the style of [real person's name]," and similar phrasings. These aren't keywords in a simple filter — they're high-weight signals in the model's interpretation that you're requesting photorealistic output of a real individual. Replacing "realistic photo" with "detailed illustration" or "artistic portrait" often changes the outcome while accurately describing what you actually want for most creative purposes.
When iterating on a prompt that has been refused, resist the temptation to simply remove words. Instead, reframe: add style descriptors, establish fictional context, shift from reference-based to trait-based description, and clarify the purpose. A refusal is feedback about how the model interpreted your prompt, not an assessment of whether your underlying creative goal is legitimate. Most legitimate creative goals can be achieved within Gemini's current policy framework with the right prompt approach.
Combining multiple strategies in a single prompt often produces the most reliable results. A prompt that leads with style ("In a detailed graphic novel illustration style"), establishes context ("for a cyberpunk thriller set in 2090"), uses trait-based description ("a detective character with sharp features and weathered eyes, wearing a long coat"), and specifies a clear creative purpose ("for the novel's chapter header artwork") addresses the ambiguity threshold from multiple angles simultaneously. Any single element of this might be sufficient, but combining them creates a clear signal that the request is for fictional creative work rather than a photorealistic representation of a real individual.
The feedback loop between Gemini's refusals and your prompt revisions is itself a useful creative tool. Refusals tend to be specific about the element that triggered them — understanding what aspect of your prompt pattern-matched to a restricted category often surfaces information about how the model processes requests that informs your broader prompting approach. Users who develop this interpretive skill find that the restrictions shift from being obstacles to being useful guardrails that help them understand exactly what kind of imagery they're creating.
API Access vs. Consumer Gemini: Different Policies for Developers
For developers building applications with Gemini's image generation capabilities, the policy landscape differs meaningfully from what consumer Gemini App users experience. Understanding these differences is essential for accurate product planning and expectation-setting with stakeholders.
The core people image restrictions apply across all access tiers — there is no developer or enterprise configuration that unlocks photorealistic images of real identifiable people or permits celebrity image generation. These restrictions are baked into the Nano Banana 2 model at the architecture level, not enforced as post-processing filters that API access could bypass. Any development plan premised on obtaining "unrestricted" people image generation through API access should be revised.
What does differ is enforcement precision. The consumer Gemini App includes additional guardrails designed for a broad, non-technical user base, which means the refusal threshold is calibrated somewhat conservatively. API access to the same Nano Banana 2 model (gemini-3.1-flash-image-preview) operates with slightly higher tolerance for edge cases and ambiguous prompts in artistic or clearly fictional contexts. Developers building tools for professional creative use cases — character design, concept art, illustration assistance — often find that prompts which trigger refusals in the consumer app succeed through direct API calls with identical content.
The practical implication is that Gemini's free image generation quotas matter less for people image use cases than the policy context of your application. Building a tool that's explicitly positioned as a creative character design assistant, where the fictional context is part of the application's system prompt, gives you a more reliable foundation than attempting to handle the fictional framing prompt-by-prompt.
For developers evaluating API costs, affordable Gemini image API access through aggregation services like laozhang.ai can significantly reduce the cost of building image generation features. The Nano Banana Pro model (gemini-3-pro-image-preview) is available at approximately $0.05 per generation — roughly 20% of direct API pricing — which makes it practical to build iterative generation workflows without the per-image costs becoming prohibitive during development. Documentation and API playground access are available at docs.laozhang.ai.
Rate limits and quota management also differ between the consumer app and API access. The free tier of the Gemini API provides limited image generation requests per day, while paid API tiers offer substantially higher limits suitable for production applications. For applications with high image generation volume, the distinction between Nano Banana 2 and Nano Banana Pro models matters not just for output quality but for cost optimization — the flash model provides adequate quality for many use cases at lower cost per generation.
Gemini vs. Midjourney vs. DALL-E for People Generation
Users comparing Gemini's people image restrictions with competing platforms often have the impression that alternatives are more permissive. The reality is more nuanced — each platform has different restriction philosophies, and the practical difference depends heavily on the specific use case.
Midjourney permits more flexible people imagery than Gemini, including more realistic human subjects, but applies its own restrictions on named real people and explicit content. For fictional character generation in realistic styles, Midjourney is generally more capable than Gemini under current policies. However, Midjourney operates primarily through Discord and offers more limited API capabilities, which makes it less suitable for programmatic integration. For illustrative and artistic styles — which constitute a large portion of legitimate creative use cases — Gemini Flash Image versus DALL-E and Flux shows competitive quality at lower cost.
DALL-E 3 (accessed through OpenAI's API or ChatGPT) similarly permits more flexible realistic people imagery than Gemini, with OpenAI's approach focusing more on specific harmful categories rather than broad photorealistic people restrictions. DALL-E's restrictions on real people and celebrities are comparable to Gemini's, but its threshold for fictional realistic people is higher. The tradeoff is cost: DALL-E 3 API access is significantly more expensive per image than Gemini's options.
The honest comparison is that if your use case specifically requires photorealistic fictional human characters and non-celebrity photorealistic portraits, Gemini is currently the most restrictive of the major platforms. For artistic, illustrative, and stylized human imagery — which covers the vast majority of legitimate creative applications — Gemini is competitive with alternatives in both quality and permissiveness. The question isn't which platform has no restrictions (all do) but which platform's restriction profile aligns best with your specific legitimate use case.
FAQ — Common Questions About Gemini People Restrictions
Can Gemini generate photos of my own face? No. Uploading a photo of yourself and asking Gemini to generate variations, add different backgrounds, or modify your appearance in the image is covered by the "identifiable real person" restriction. Even with the subject's full consent, the current policy doesn't have a self-portrait exemption. This is a known limitation that frustrates profile photo use cases.
Can I generate images of politicians or historical leaders? Historical figures (deceased individuals) in clearly non-photorealistic, artistic styles often succeed. Current political figures are refused under the public figures restriction. The dividing line between "historical figure" and "recent enough to be treated as a current public figure" isn't precisely documented, but as a practical rule: people who have been deceased for multiple decades in clearly artistic styles often work; living or recently deceased political figures do not.
Does the restriction apply to AI-generated characters that look like real people? The restriction targets photorealistic imagery that would be interpreted as depicting a real individual, not coincidental resemblance. A fictional character that happens to share physical traits with a real person, described in trait terms without any reference to that person, is generally treated as fictional. A character described specifically to resemble a named individual — "create a character that looks like [celebrity]" — is refused.
Will API access unlock more permissive people generation? No. The core restrictions are model-level, not API-level, and apply across all access tiers. API access offers slightly higher precision for creative fictional contexts, but does not enable generating photorealistic real people, celebrities, or restricted content categories.
Is Nano Banana 2 the final version of these restrictions? Google's image policies have evolved continuously since 2024, and there's no reason to expect they've stabilized permanently. Nano Banana 2 represents the current state as of March 2026. Future model updates may refine the restrictions in either direction — relaxing edge cases for legitimate creative uses or tightening in response to new misuse patterns. Following Google's AI policy announcements is the most reliable way to stay current.
Can I use Gemini for avatar or profile image generation? Avatar generation in clearly non-photorealistic styles — illustration, cartoon, anime, or similar — generally succeeds. Photorealistic avatar generation is blocked under the current policy. For profile image use cases, prompting explicitly for illustrated or artistic styles typically produces usable results.
How is Gemini's restriction different from other AI image tools? Gemini's restrictions are broader and more consistently enforced for photorealistic people imagery than most competing platforms. The restrictions stem from a specific institutional history (the 2024 controversy) and reflect Google's particular legal exposure as a large regulated company. Competing platforms have their own restrictions on harmful content but generally permit more flexible realistic human imagery for fictional subjects.
What should I do if my legitimate prompt is refused? Add explicit style descriptors (illustration, artistic portrait, character design), establish fictional context before describing the character, switch from reference-based to trait-based description, and avoid vocabulary that maps to photorealistic portrait requests. Most legitimate creative goals can be achieved within the current policy with appropriate prompt framing.
Conclusion: Working With the Policy, Not Against It
Gemini's people image restrictions are the product of a specific documented history, concrete legal obligations, and deliberate architectural decisions made by Google's AI safety teams. They aren't bugs, placeholders, or temporary inconveniences waiting to be removed — they reflect genuine institutional commitments that are, if anything, likely to increase in precision rather than decrease in scope.
The practical implication for users is that the most productive approach is understanding the policy's actual boundaries rather than treating all human imagery as prohibited. Fictional characters, artistic styles, character design, crowd scenes, and a wide range of creative applications are fully available within Gemini's current capabilities. The restrictions target a specific combination of photorealism and real-person identity that represents a narrow slice of legitimate creative use cases. Working within this framework, with appropriate prompt strategies, most human imagery needs can be met.
For developers building applications, the key takeaway is that API access doesn't bypass model-level restrictions, but does offer a more precision-tuned environment for creative applications where fictional context is clearly established. Building that context into your application's architecture — rather than relying on prompt-by-prompt framing — produces more consistent results and a better user experience.
The 2024 incident and its aftermath reshaped how Google thinks about human representation in AI-generated imagery in ways that are likely permanent. But the policy that emerged from that process is more thoughtful and more specifically targeted than the blunt pause that preceded it. Understanding both the history and the current state of the restrictions is what makes it possible to build effectively with Gemini's image generation in 2026.