Most developers searching for "Gemini 3.1 Pro vs Claude Opus 4.6" are not asking for a philosophy of model evaluation. They are asking a faster question: which API should I test first? In March 2026, the practical answer is simple. Start with Gemini if your workload is mostly long-context analysis plus cost control. Start with Claude if coding-agent reliability matters more than token price. Keep both available if your product already has a wide ingestion stage and a narrower execution stage.
That answer holds because the official evidence is uneven but useful. Google gives the cleaner story on pricing, token limits, and long-context product positioning. Anthropic gives the stronger public case for premium coding and autonomy. The mistake is not caring about benchmarks. The mistake is treating mixed benchmark tables, preview labels, beta context claims, and mismatched SKUs as if they formed one clean scoreboard.
If You Only Need the Answer
If most of your production volume is document analysis, repository ingestion, retrieval-heavy research, or other large prompts where direct API cost matters, start with Gemini 3.1 Pro Preview. If your hardest tasks are code review, patch generation, multi-step tool use, and debugging where a bad first attempt creates expensive human cleanup, start with Claude Opus 4.6. If your system already separates broad context gathering from narrow execution, do not force a single winner. Keep both models available and route by task. That is the fastest honest answer for March 2026, and it fits the official pricing, context, and product-positioning evidence better than most one-line benchmark verdicts.
| If your product mostly needs... | Start with | Why |
|---|---|---|
| Long documents, repository ingestion, cost-sensitive analysis | Gemini 3.1 Pro Preview | Lower official price and a clearer million-token input story |
| Code review, debugging, multi-step tool use, patch generation | Claude Opus 4.6 | Stronger first-party evidence for coding-heavy autonomy |
| A wide ingestion stage plus a narrow execution stage | Route both | Gemini handles cheap context-heavy work; Claude handles premium execution |
Benchmark Reality in 60 Seconds
Public performance data still matters, because searchers expect it. The problem is not that benchmarks are useless. The problem is that this matchup does not come with a clean, symmetrical public scoreboard. Anthropic publishes the clearer benchmark case for Opus 4.6 as a premium coding and autonomy model, highlighting Terminal-Bench 2.0, Humanity's Last Exam, BrowseComp, and GDPval-AA. Google’s public case for Gemini 3.1 Pro Preview is stronger in hard specs and product behavior: price, million-token input, token efficiency, groundedness, and software-engineering positioning. So the practical reading is straightforward: public benchmarks make Claude easier to justify for coding-agent evaluation; pricing and token-limit docs make Gemini easier to justify for long-context, cost-sensitive systems. What you should not trust is any table that mixes Sonnet, Opus, preview variants, and beta context claims as if they were perfectly comparable.
Fast Comparison Snapshot

The first thing worth correcting is the object of comparison. When people say “Gemini 3.1,” they often mean several different products at once: Gemini 3.1 Pro Preview, Gemini 3.1 Pro Preview Customtools, or other Gemini 3.1 family variants discussed in forums and tool wrappers. For a direct API comparison against Claude Opus 4.6, the cleanest match is Gemini 3.1 Pro Preview, because that is the flagship long-context model Google is publicly documenting with pricing, token limits, and software-engineering positioning. On the Anthropic side, the relevant comparison target is Claude Opus 4.6, not Sonnet 4.6. Sonnet is often the more cost-effective Claude choice, but it is a different product decision. If you want the full Claude pricing ladder after reading this article, the separate Claude Opus 4.6 pricing guide goes deeper.
Release timing matters because both models are still new enough that stale assumptions are common. Google announced Gemini 3.1 Pro on February 19, 2026, and the official model page still labels it Preview. Anthropic announced Claude Opus 4.6 on February 5, 2026, positioning it as the newest Opus-class model and its most capable option for complex reasoning and coding. This means the comparison is inherently freshness-sensitive: older posts written against Gemini 2.5 or Claude 4.1-era pricing are not just outdated around the edges, they can point you toward the wrong architectural tradeoff entirely.
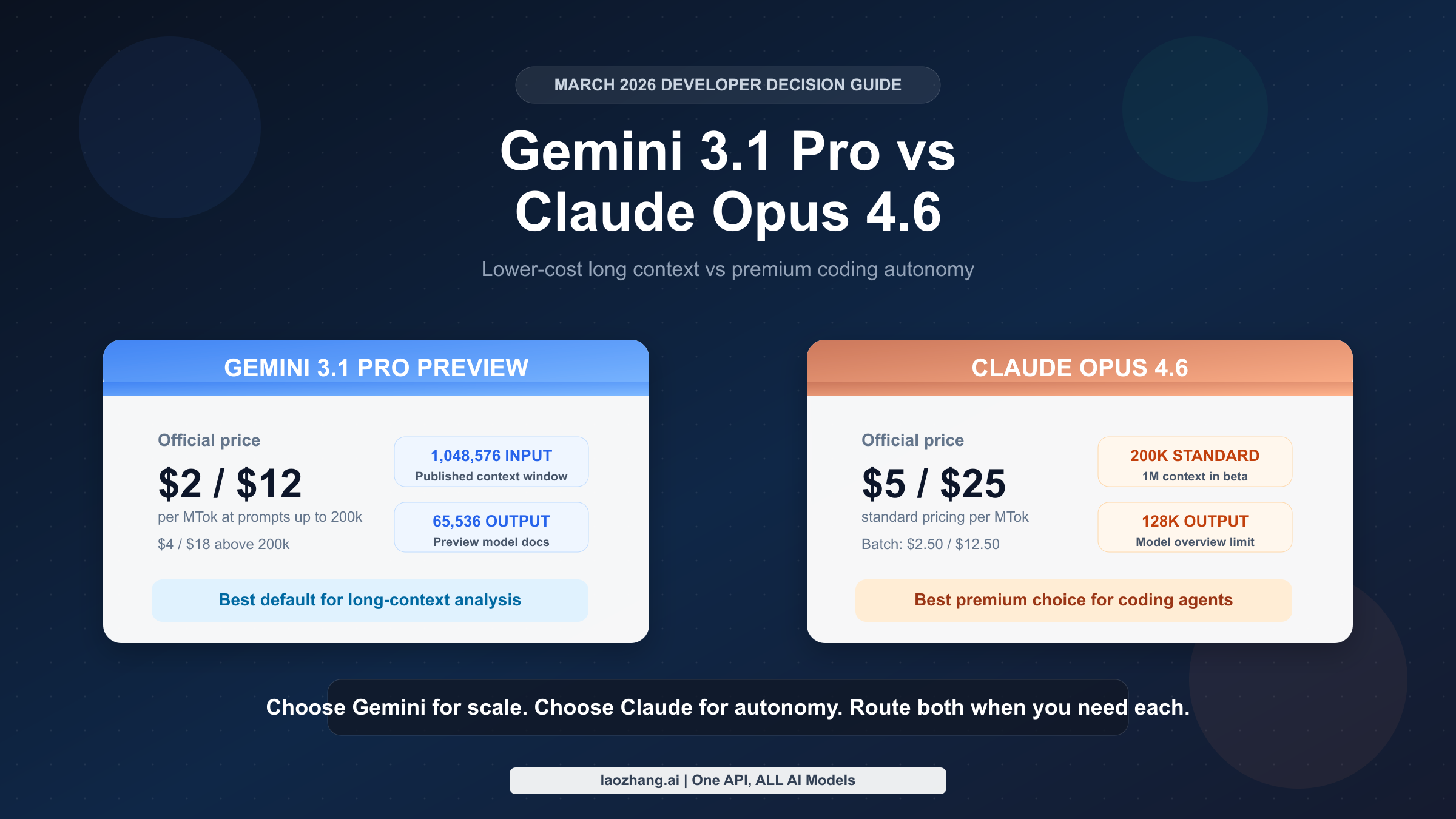
The hard-spec snapshot already suggests the shape of the decision. Google’s official model docs publish 1,048,576 input tokens and 65,536 output tokens for Gemini 3.1 Pro Preview. Anthropic’s model overview table shows Opus 4.6 with 200k context and 128k max output, while Anthropic’s launch post separately says Opus 4.6 supports a 1M-token context window in beta. Those are not cosmetic details. If your workload is dominated by very large prompt payloads, Gemini’s public documentation is cleaner and cheaper. If your workflow depends on unusually long generated output, Claude’s 128k max output is a real advantage.
| Dimension | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| Release date | Feb 19, 2026 | Feb 5, 2026 |
| Status | Preview | Current flagship model |
| Input price | $2/MTok at <=200k, $4/MTok above 200k | $5/MTok |
| Output price | $12/MTok at <=200k, $18/MTok above 200k | $25/MTok |
| Input context | 1,048,576 tokens | 200k in model overview; 1M beta in launch post |
| Max output | 65,536 tokens | 128k tokens |
| Public performance read | better economics and clearer long-context fit | stronger public case for coding-heavy autonomy |
| Official positioning | better thinking, token efficiency, grounded behavior, software engineering, precise tool usage | complex coding, agentic work, computer use, tool use, search, finance |
If you only remember one thing from this section, make it this: Gemini 3.1 Pro Preview is not “cheap Claude,” and Claude Opus 4.6 is not just “more expensive Gemini.” Each model is being sold into a different failure profile. Gemini is optimized and priced like a long-context, tool-using workhorse that should still stay cost-competitive after you cross the 200k prompt threshold. Opus is priced like a model that expects to earn its keep by reducing failure loops on the hardest coding and autonomy-heavy tasks.
Pricing and Context: Gemini Starts as the Value Default
Claim: Gemini should be your default when direct API cost and prompt size dominate the decision.
Evidence: Google prices Gemini 3.1 Pro Preview at $2/$12 per MTok up to 200k prompt tokens and $4/$18 above that threshold, while also publishing a 1,048,576-token input limit.
Decision: Test Gemini first for document analysis, repository ingestion, batch extraction, and other high-volume workloads where large context and lower unit cost matter more than premium autonomy.
On direct API pricing, Gemini 3.1 Pro Preview starts with the strongest raw advantage. According to Google’s official Gemini pricing page, Gemini 3.1 Pro Preview costs $2.00 input / $12.00 output per million tokens when prompts stay at or below 200k tokens, and $4.00 input / $18.00 output once prompts exceed 200k. Anthropic’s pricing documentation puts Claude Opus 4.6 at $5.00 input / $25.00 output per million tokens. That means Gemini is 60% cheaper on input and 52% cheaper on output in the common <=200k case. Even after the higher long-prompt tier kicks in, Gemini remains 20% cheaper on input and 28% cheaper on output.
The most important pricing nuance is that Gemini’s advantage is threshold-sensitive, not absolute. Plenty of quick comparisons quote the cheap tier and stop there, which makes Gemini look almost absurdly inexpensive relative to Opus. In real usage, the picture depends on how often you cross 200k prompt tokens. If you are building ordinary interactive coding tools, support copilots, structured document Q&A, or moderately sized planning agents, many of your requests will stay below that threshold and Gemini’s price advantage will feel large. If you are regularly pushing giant repositories, long legal bundles, or massive research packets into context, Gemini’s price increases. It still stays cheaper than Opus, but the gap stops looking like a landslide and starts looking like a narrower margin you have to interpret against quality.
Batch and caching make the comparison more interesting. Google publishes batch pricing for Gemini 3.1 Pro Preview at $1/$6 for prompts up to 200k and $2/$9` above that threshold. Anthropic prices Opus 4.6 batch requests at $2.50/$12.50. For asynchronous workloads such as repository indexing, large-scale extraction, or overnight analysis, both providers become more attractive than their standard prices suggest, but Gemini still keeps the lower-cost position. On caching, Google uses an explicit price plus storage model, while Anthropic uses write multipliers and a low read multiplier. That makes direct, one-line comparison messy, but the strategic conclusion is simple: both providers reward repeated context, and both become much more economical when you stop sending the same static prompt payload over and over.
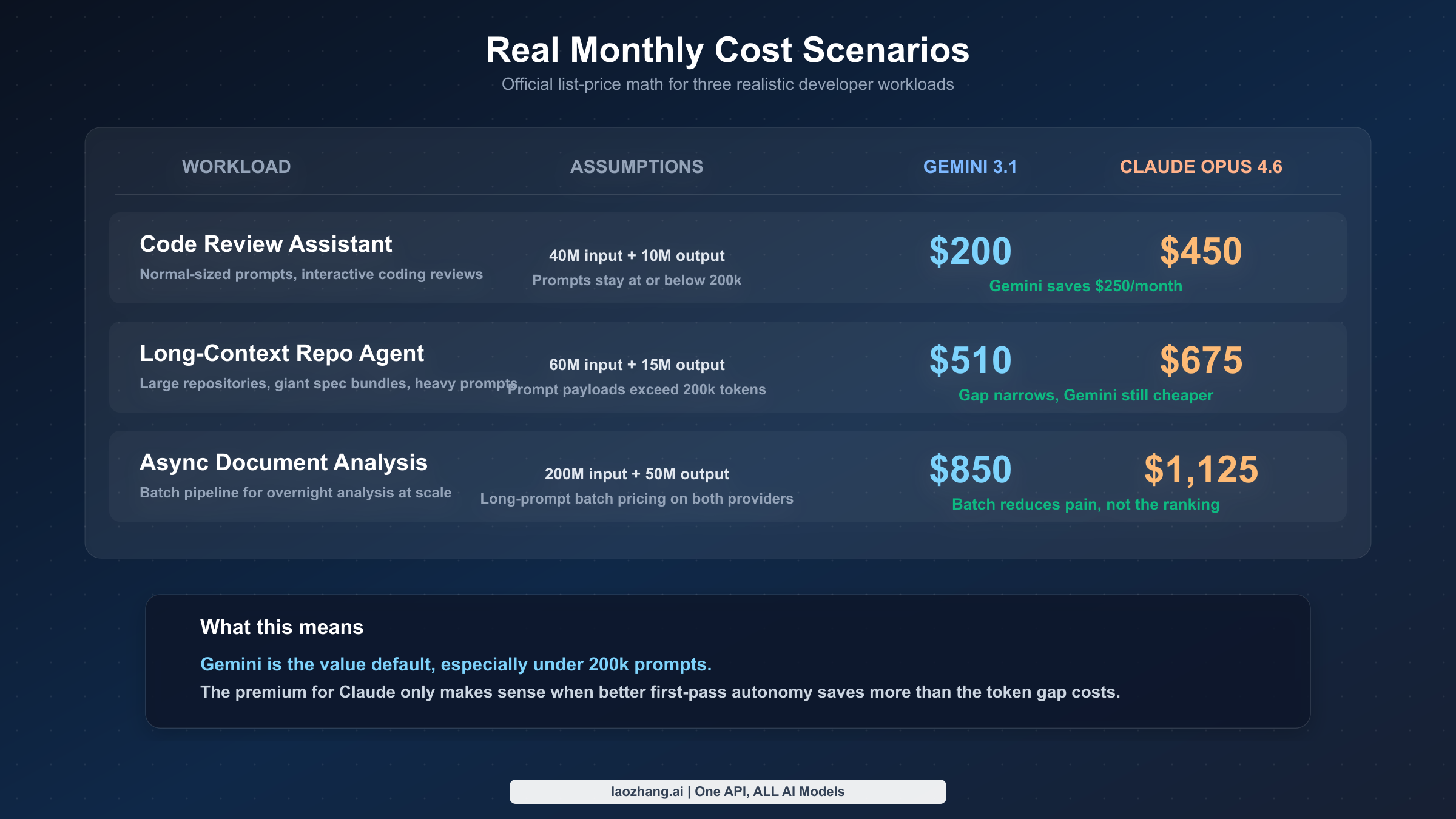
The difference is easier to see in concrete monthly scenarios:
| Workload | Assumptions | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|---|
| Code review assistant | 40M input, 10M output, prompts <=200k | $200 | $450 |
| Long-context repo agent | 60M input, 15M output, prompts >200k | $510 | $675 |
| Async document analysis (batch) | 200M input, 50M output, long-prompt batch usage | $850 | $1,125 |
These numbers are intentionally simple. They do not include search-grounding fees, storage charges for cached context, or any value judgment about model quality. They exist to show the price shape. In the ordinary prompt case, Gemini is more than twice as cost-efficient. In the long-context case, the advantage narrows because Gemini steps up to the higher input and output tier. In batch mode, Gemini still wins on direct cost, but not by such a huge amount that quality becomes irrelevant.
Context is the other half of this section, and it changes how you interpret the pricing. Gemini 3.1 Pro Preview gives you a published 1,048,576-token input limit out of the box. Anthropic’s model overview still presents Opus 4.6 as a 200k context model, which is what many teams will operationalize around by default, even though Anthropic’s launch announcement says a 1M-token context window exists in beta. If your application roadmap assumes million-token ingestion as a normal, production-grade behavior, Gemini’s documentation is simply clearer. If your application needs very long generated output rather than very long input, Claude’s published 128k output limit becomes part of the argument in the other direction.
There is one more pricing detail that matters more than it first appears: Google charges separately for grounding with Google Search after a free monthly allowance, while Anthropic’s pricing page is more focused on token, caching, fast-mode, batch, and regional inference costs. That makes Gemini especially attractive for workflows where grounded search is part of the product, but it also means you need to model those search-query costs instead of assuming “token price” is the whole bill. For teams that just want to evaluate Gemini before going deep on that math, the separate Gemini 3.1 Pro Preview access guide is the better next stop.
Coding and Agentic Work: Why Claude Opus 4.6 Still Earns the Premium
Claim: Claude Opus 4.6 is easier to justify first when the cost of a bad first attempt is mostly human cleanup, not token spend.
Evidence: Anthropic’s public materials make a much clearer direct case around coding, tool use, debugging, code review, and long-running agentic execution than Google currently does for Gemini.
Decision: Put Claude first in evaluation queues for coding agents, patch generation, multi-step tool orchestration, and debugging flows where retries are expensive.
If pricing were the whole story, Gemini would be the obvious winner and this article would be over already. The reason Opus 4.6 still deserves serious evaluation is that Claude’s official evidence is unusually strong where many expensive AI systems fail in practice: coding, tool use, and multi-step agent behavior. Anthropic’s launch post does not hedge much here. It says Opus 4.6 improves coding skills, plans more carefully, sustains agentic tasks longer, works more reliably in larger codebases, and has better code review and debugging ability to catch its own mistakes. Those are not vague branding claims. They map directly onto the behavior that determines whether a coding agent is a credible teammate or an expensive source of cleanup work.
This matters because the cost of the wrong model is often not the token bill. It is the human repair loop. A long-context model that is cheap to run can still be the more expensive system if it repeatedly takes the wrong tool action, misses a codebase-wide side effect, or needs multiple retries before it converges on a workable fix. In those situations, Opus’s price premium can be rational even when the raw per-token economics look painful. One strong first pass can be cheaper than three mediocre ones, especially when those failures consume developer time, CI minutes, and review attention rather than just tokens.
The public evidence gap is also important here. With Gemini 3.1 Pro Preview, Google is telling you the model is optimized for software engineering behavior, token efficiency, groundedness, and agentic workflows requiring precise tool usage. That is promising and relevant. But Google is not, at least in the official sources used for this article, making as detailed a public benchmark case for “Gemini is the best coding-autonomy model” as Anthropic is making for Opus. If you are choosing where to spend premium evaluation time first for a coding-heavy product, that difference in public proof burden should influence your testing plan. Opus has more first-party evidence to justify a premium coding evaluation. Gemini has more first-party evidence to justify a cost-sensitive long-context evaluation.
Another way to say this is that Opus 4.6 is strongest when the model is expected to carry more responsibility per request. If the model is writing patches, orchestrating tools, debugging across multiple files, or synthesizing high-value research in a way that users will trust without constant babysitting, the premium is easier to defend. If the model is doing long ingestion, triage, filtering, or first-pass analysis before a second model or a human takes over, Gemini’s economics often make more sense.
This is also where many “winner” articles fail readers by compressing coding into one benchmark row. Real software engineering work is not just code generation. It is scoping, tool choice, repository navigation, error recovery, code review, and the ability to stay coherent over multi-step execution. Anthropic is talking directly to that problem with Opus 4.6. Google is talking more directly to long-context, grounded, tool-precise engineering workflows. Those are overlapping but not identical jobs, and the premium only makes sense if your product sits close to the Anthropic side of that overlap.
Long Context, Grounded Analysis, and Large Inputs: Where Gemini Pulls Ahead
Claim: Gemini’s strongest architectural edge is large-input work that needs scale, lower price, and grounded behavior more than premium first-pass autonomy.
Evidence: Google publishes a million-token input window, lower list pricing, and explicit grounding economics, which makes Gemini much easier to operationalize for big-context systems.
Decision: Choose Gemini first for research assistants, long-document pipelines, repository explainers, and other systems where ingestion and synthesis are the real bottleneck.
Gemini’s clearest architectural edge is not that it is “good enough.” It is that it combines published million-token input capacity, lower pricing, and explicit grounding economics into a model that is easy to justify for large-input systems. If you are building an internal research tool, repository explainer, contract-analysis pipeline, transcript intelligence layer, or any workflow where the hard part is carrying a lot of source material into one coherent reasoning pass, Gemini 3.1 Pro Preview is unusually attractive on first principles. You get the large context window without paying Opus-level flagship rates, and even the higher >200k prompt tier still undercuts Claude Opus on both input and output.
Google’s own positioning reinforces this use case. The model page emphasizes improved token efficiency, more grounded and factually consistent behavior, and agentic workflows that need precise tool usage across real-world domains. That reads less like “best autonomous coder” and more like “strong large-context reasoning engine for real product work.” The pricing page also makes the search-grounding model explicit, which is valuable if your application needs to blend giant context with fresh information retrieval. Unlike some vendors who leave grounding economics vague, Google forces you to think about it upfront. That is annoying when you are budgeting, but good when you are designing a production system honestly.
Gemini also becomes more compelling the larger your input payloads get. Many long-context workloads are only superficially about reasoning. Under the hood, they are bottlenecked by ingestion and recall: getting enough of the source material into a single coherent frame so the model can do something useful with it. That is where the difference between a published 1,048,576-token input limit and a default 200k context table becomes operationally important. Even if Opus’s 1M beta context ends up working well for your use case, Gemini is the model whose public documentation makes the million-token story easiest to operationalize today.
None of this means Gemini automatically wins at the final step. There are plenty of systems where the best architecture is to use Gemini for ingestion, filtering, and large-context synthesis, then escalate to Claude for the hardest coding or autonomy-sensitive action. That is not overengineering. It is often the most rational split. Long-context analysis and tool-heavy execution are different bottlenecks. A model can be better at one without winning the other.
The subtle mistake to avoid is using Gemini’s lower price as an excuse to force it into every stage of the stack. The right conclusion from Google’s docs is not “Gemini replaces Claude.” It is “Gemini deserves to be the default candidate whenever context size, groundedness, and direct cost matter more than premium first-pass autonomy.” In a lot of engineering organizations, that already describes a large share of production volume.
Production Reality: Preview, Beta, and What Those Labels Mean
Claim: Status labels are part of the architecture decision, not a footnote.
Evidence: Gemini 3.1 Pro remains officially marked Preview, while Opus 4.6 is current flagship but its 1M context story is still explicitly described as beta in Anthropic’s launch material.
Decision: Treat Gemini as a stronger fit for controlled rollouts and fallback-friendly systems, and treat Opus’s 1M context as optional beta capacity unless you have validated it directly.
The fastest way to make a bad model decision is to treat status labels as marketing trivia. They are not. They are deployment signals. Google’s official material still marks Gemini 3.1 Pro as Preview, which should immediately change how you use it. Preview does not mean “unusable.” It means you should assume faster iteration, possible behavior drift, and a higher need for regression testing than you would want from a long-settled production baseline. That is perfectly acceptable for internal tools, evaluation loops, long-context analysis systems with fallback paths, and products where you control rollout tightly. It is less comfortable if the model is the single point of truth for a mission-critical external workflow.
Anthropic’s story is different but not risk-free. Opus 4.6 itself is clearly positioned as the current flagship Claude model, and Anthropic’s model overview is usable enough to support ordinary production planning. But the million-token story is still explicitly phrased as beta in the launch post. That means teams should avoid writing “Claude Opus 4.6 has a fully normalized 1M context window everywhere” into architecture docs unless they have validated the beta path in their own environment. The safest wording, and the one used in this article, is that Opus has a published 200k context in the overview table and a 1M context capability in beta according to Anthropic’s launch announcement.
This creates a straightforward production posture:
| Deployment concern | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| Official status signal | Preview | Current flagship model |
| Safest default assumption | million-token input is part of the documented product | 200k context is the documented default; 1M should be treated as beta capacity |
| Better fit today | large-context internal tools, evaluation loops, grounded analysis | premium coding agents, high-autonomy tasks, long-output synthesis |
The interesting outcome is that neither label should scare you away if the workload matches. A Preview model can still be the right choice if its documented strengths line up cleanly with the job and you build proper fallback logic around it. A beta context expansion can still be extremely useful if you treat it as optional capacity rather than a hidden guarantee. What you should not do is flatten these labels into “both models support 1M context, so status does not matter.” Status matters because it tells you how much of your architecture is built on behavior that the vendor is still actively shaping.
If you are unsure how much this operational nuance matters for your broader stack, that is usually a sign that you should not frame the choice as a single-model commitment. Keep both models reachable. Evaluate each on the stage where its documentation is strongest. That is safer than trying to squeeze a permanent winner out of incomplete symmetry.
Which One Should You Choose?

At this point the recommendation can be stated plainly. Choose Gemini 3.1 Pro Preview first if your main problem is handling large prompt payloads at a rational price, building grounded research or document-analysis flows, or evaluating long-context product ideas without paying Opus rates on every request. Gemini is also the better starting point if you expect most of your high-volume traffic to be ingestion, filtering, retrieval-heavy analysis, or first-pass engineering assistance rather than deeply autonomous action.
Choose Claude Opus 4.6 first if the hardest part of your product is agentic coding, tool orchestration, code review, debugging across large repositories, or premium reasoning where a bad first pass is expensive. Anthropic’s official case is simply stronger here. If a model mistake triggers manual repair, retry loops, or lost trust from developers, Claude’s premium is easier to justify than it looks in a pricing table.
Route between both if your system already has two stages in practice: a high-volume, large-context stage and a smaller, quality-critical execution stage. This is likely the best answer for many technical teams in 2026. Use Gemini to absorb context, ground analysis, and cheaply process the wide funnel of inputs. Use Claude on the narrower but more valuable step where execution quality matters most. The common mistake is forcing a single model to own both jobs because it feels simpler operationally.
This is also where a product mention becomes genuinely useful rather than promotional. If you want to keep both Google and Anthropic available without managing separate keys, billing flows, and routing glue from day one, a unified gateway like laozhang.ai can reduce that operational overhead. The value is not “cheaper magic.” It is that a two-model architecture becomes easier to test and maintain when the integration surface is smaller.
The broader pattern to notice is that the best 2026 answer is rarely a permanent vendor choice. It is a workload strategy. If, after reading this, you realize the real decision is bigger than a two-model comparison, the next useful step is the broader provider comparison guide, not another narrower benchmark article.
How to Evaluate Both Models Without Wasting a Sprint
One reason this comparison gets distorted online is that teams try to settle it with abstract argument instead of a disciplined evaluation plan. The right evaluation for Gemini 3.1 Pro Preview and Claude Opus 4.6 is not “ask both to solve one flashy prompt and pick the nicer answer.” It is to test both models against the exact workload buckets that would make you spend money in production. If you do not separate those buckets, you end up benchmarking the wrong thing and overfitting architecture decisions to demo tasks.
The cleanest way to do it is to create three workload tracks. The first track should be a large-context synthesis track: long documents, long repositories, research packets, or specification bundles that expose how well each model ingests and reasons over large input. The second should be a coding and agent track: multi-file changes, tool-using tasks, debugging, code review, or iterative repository work that reveals whether a model can stay coherent while taking action. The third should be a grounded analysis track: tasks where the model needs to use external information or cross-check fresh material rather than only operate inside a static prompt. Those three tracks map directly onto the tradeoff this article has been describing, and they let you test the real boundaries between Gemini’s value proposition and Claude’s premium case.
Once the workloads are split correctly, measure first-pass usefulness, not just answer quality in the abstract. A good rubric usually includes four numbers per task: whether the first response was usable, how many retries or corrections were needed, total token cost, and human repair time. The first two tell you whether Claude’s premium is buying enough execution quality to matter. The third tells you whether Gemini’s cheaper pricing remains meaningful after your prompts cross the 200k threshold. The fourth is the missing metric in most public comparisons: the model that produces the cheaper API bill is not automatically the cheaper system if your team spends twenty minutes repairing each bad result.
It also helps to force a prompt-length split inside the Gemini evaluation. Keep one test bucket below 200k prompt tokens and another clearly above it. That way you do not accidentally conclude that Gemini is “dramatically cheaper” based only on the low tier. For Claude, pay close attention to where the published 128k output limit changes what you can get done in one pass. If your product frequently needs long generated reports, long code transformations, or giant structured outputs, that output headroom can matter more than one or two benchmark rows ever will.
The evaluation should be reversible by design. Use the same instructions, the same scoring rubric, and as much of the same surrounding infrastructure as possible. If you already know you may route between both providers, build the test harness so the prompt format and success criteria stay portable. This is exactly where a unified gateway or adapter layer becomes useful. Whether you do it through your own router or through a service like laozhang.ai, the goal is not convenience for its own sake. The goal is preserving optionality while the model landscape is still moving this quickly.
The practical outcome of a good evaluation is usually less dramatic than the internet wants. Many teams will discover that Gemini is clearly better for one part of the stack, Claude is clearly better for another, and the real win comes from preserving both paths. That is a better result than forcing a single winner, because it gives you a system design you can keep improving as pricing, limits, and model behavior continue to change.
Integration Notes That Actually Change Your Architecture
The most useful engineering differences between these models are not the headline qualities. They are the details that change how you build a routing layer, how you budget, and how you monitor production.
First, Gemini’s pricing threshold means token counting has to happen before routing. If your requests regularly cross 200k prompt tokens, you should not treat Gemini’s lower headline price as a constant. That does not make Gemini a bad deal. It means your model router needs to know prompt size as part of the decision. Systems that ignore this can end up with noisy cost estimates and poor escalation rules.
Second, Claude’s output limit materially changes what you can ask for in one pass. Opus 4.6’s published 128k max output is not just a spec-table curiosity. It changes the kinds of patch generation, long-form synthesis, and structured report generation that you can do comfortably in a single response. Gemini’s 65,536 output limit is still large, but it is meaningfully smaller.
Third, grounding and caching economics are model-specific features, not generic “optimization.” Google surfaces search-grounding charges explicitly, which matters if your app’s value depends on freshness. Anthropic surfaces prompt caching multipliers and regional inference premiums more explicitly. If you care about serious production economics, you should model those lines directly rather than bury them in a catch-all “other usage costs” bucket.
Fourth, you should normalize evaluation harnesses before you standardize on one model. The most robust architecture step you can take is to keep prompts, test cases, and success criteria portable. That way the model choice stays reversible. If you know in advance that you may route across both providers, a unified integration layer or gateway, including options like docs.laozhang.ai, can make that portability much easier to preserve.
The core architectural lesson is simple: do not design your system as if model choice is a one-time branding decision. Design it as if context size, autonomy quality, and pricing curves will continue to move, because they will.
Frequently Asked Questions
Is Gemini 3.1 Pro Preview cheaper than Claude Opus 4.6?
Yes. On official list price, Gemini is cheaper in both pricing tiers. At prompts up to 200k tokens, Gemini costs $2/$12 per MTok versus Opus at $5/$25. Above 200k, Gemini rises to $4/$18 and remains cheaper, though the gap narrows.
Is Claude Opus 4.6 better for coding?
Claude has the stronger official evidence case for coding and agentic execution. Anthropic’s launch material directly emphasizes coding, debugging, code review, computer use, and long-running agentic work. Google positions Gemini for software engineering too, but not with the same benchmark-forward public case in the official sources used here.
Does Claude Opus 4.6 really have a 1M context window?
Anthropic’s launch post says Opus 4.6 has a 1M token context window in beta. Anthropic’s model overview still shows 200k context in the main table. The safest production interpretation is that 200k is the documented default and 1M is a beta capability you should validate directly before relying on it.
Should I avoid Gemini because it is still Preview?
Not necessarily. Preview status should change how you roll out Gemini, not automatically eliminate it. Gemini is still a strong choice for internal tools, evaluation loops, large-context analysis, and other workloads where its documented strengths align well with the job and you can tolerate iteration.
Should most teams pick one model or route between both?
Many teams will get better results by routing. Gemini is the better first candidate for high-volume large-context work. Claude is the better first candidate for premium coding and high-autonomy execution. If your system does both jobs, forcing a permanent single-model answer is usually less rational than keeping both available.