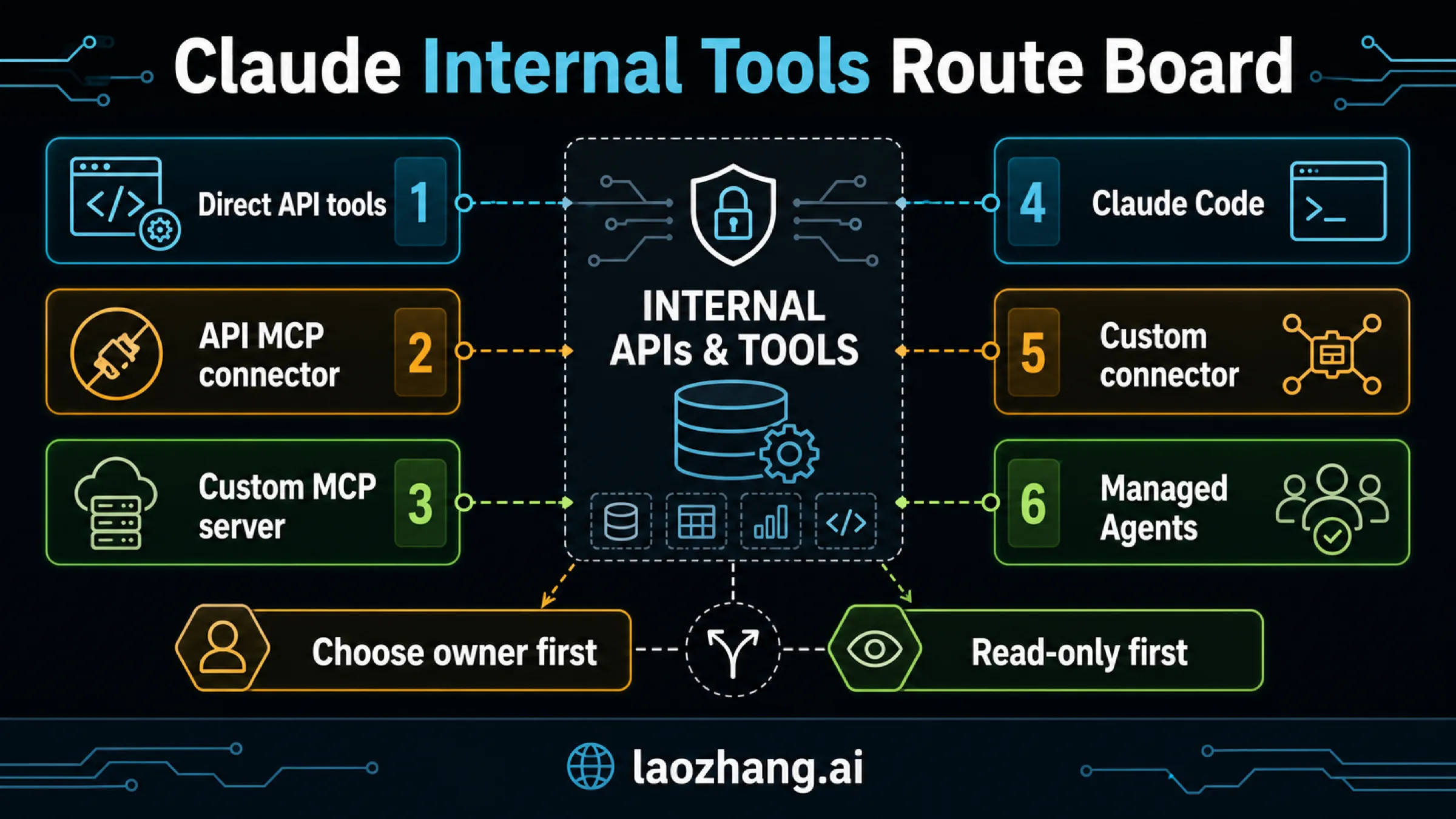
Claude can use an internal API in more than one way. MCP is useful when you want a reusable tool contract, but it is not a replacement for API design, authorization, approvals, or audit logs.
Start by choosing who owns execution. If your application already owns the loop, direct Claude API tools are usually the shortest path. If several Claude surfaces need the same internal toolset, build a narrow remote MCP server and expose only the operations Claude actually needs.
As of June 1, 2026, Anthropic's docs separate direct tool use, the Messages API MCP connector, Claude Code MCP, and Claude custom connectors. Treat those as separate routes:
| If your integration needs... | Start with... | Why |
|---|---|---|
| One app owns prompts, state, execution, and audit | Direct Claude API tools | The app can run the tool call, return tool_result, and keep auth inside its own boundary. |
| Messages API should call a reusable remote toolset | Claude API MCP connector | It connects Claude to a reachable remote MCP server without a separate MCP client in your app. |
| Several Claude clients should share the same internal tool contract | Custom MCP server | MCP gives the API team one bounded tool interface instead of client-specific adapters. |
| A developer needs local repo or machine workflow access | Claude Code MCP | Local stdio, project scope, and /mcp controls belong to the developer workflow branch. |
| A human Claude.ai or Desktop workflow needs an approved connector | Custom connector | This is a user-facing connector route with its own network, plan, and permission boundaries. |
| A long-running hosted agent should own more runtime machinery | Managed Agents | Use this only when hosted session runtime is the real problem, not just tool access. |
Stop rule: do not build an MCP server just because MCP is available. Build it when reuse, connector ownership, or cross-client consistency is worth the extra server, auth, and review surface.
Direct Claude API Tools vs MCP
The shortest route is often the Claude API tool use path. Your application sends tool definitions, Claude may return a tool_use block, your code executes the internal operation, and your code returns tool_result. That is enough when one app owns the prompt, user session, authorization checks, tool execution, audit log, retries, and response shaping.
MCP becomes valuable when the tool contract needs to outlive one app. If an API team wants the same internal search, ticket, billing, deployment, or reporting tool to work across several Claude surfaces, a custom MCP server can be the right abstraction. The server becomes the bounded interface. Claude clients consume tools; the API team owns names, schemas, auth, output limits, and policy.
| Decision | Use direct Claude API tools | Build or expose MCP |
|---|---|---|
| Runtime owner | One application already runs the loop | Several clients need the same tool contract |
| Tool execution | Your app can execute the call and return tool_result | A remote server should own tool execution behind a protocol boundary |
| Auth boundary | Existing app session and service account are enough | Connector-level auth, headers, allowlists, or per-tool ownership matter |
| Change control | One product team can update the integration | API/platform team needs one stable contract for many Claude clients |
| Operational cost | Keep the first version small | Accept extra server, deployment, review, and monitoring surface |
The practical threshold is reuse plus ownership. If the tool is only used inside one product workflow, direct tools are usually cleaner. If the same operation should be available to Claude API calls, Claude.ai connectors, Claude Code projects, or future internal agents, MCP may be worth the extra moving parts.
Do not define MCP tools as thin copies of backend endpoints. Claude does not need your whole admin API. It needs a small set of task-shaped capabilities such as search_customer_ticket, summarize_invoice_status, create_refund_draft, or open_deployment_incident. Those names are not cosmetic. Tool names, descriptions, schemas, and returned content become part of the interface Claude reasons over, as described in the MCP tool specification.
Build A Narrow Internal API Wrapper
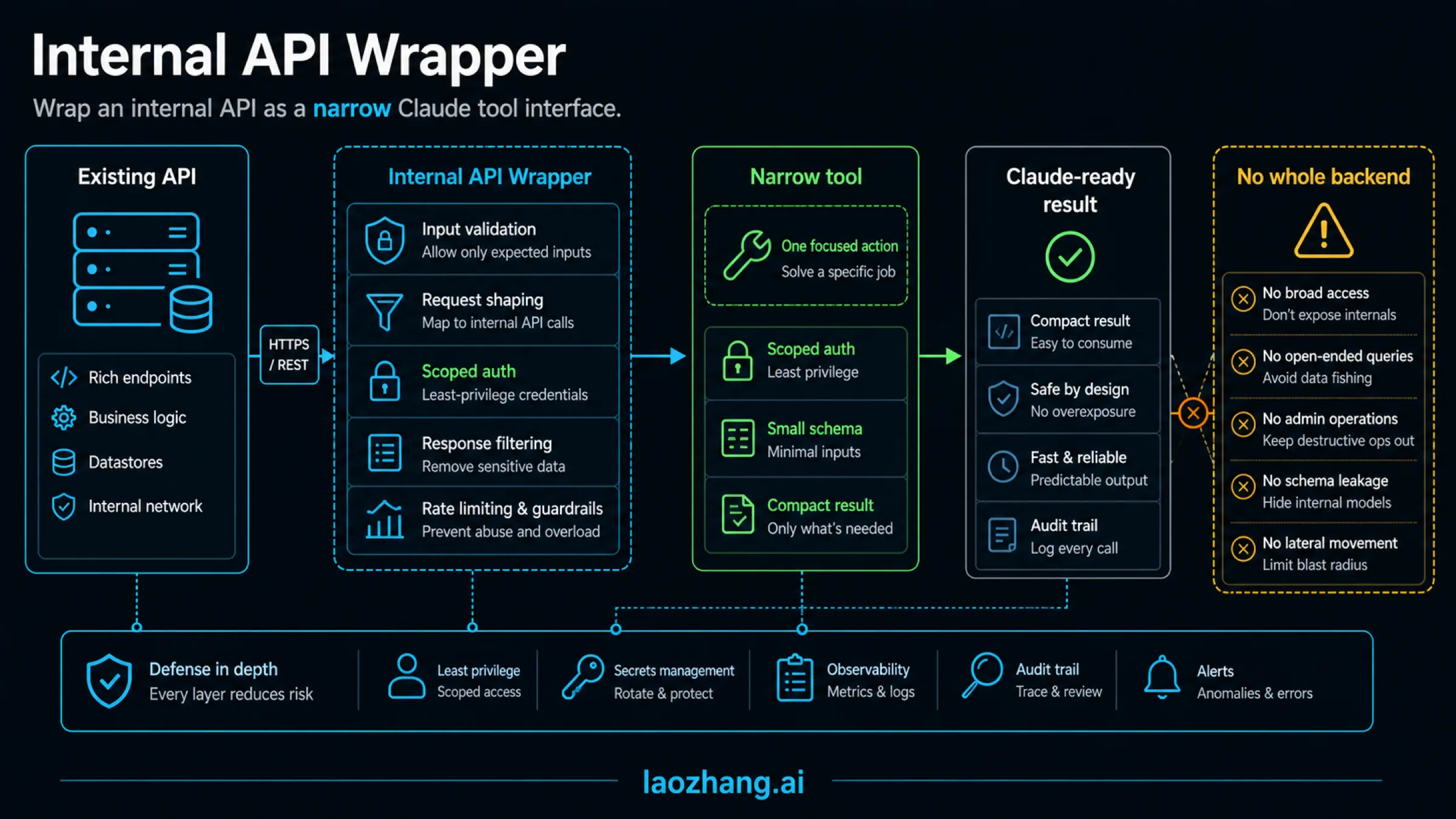
A safe Claude internal tool integration starts with a wrapper layer. The wrapper translates an existing internal API into a small tool contract with explicit inputs, bounded outputs, scoped credentials, and predictable failure behavior. The point is not to hide complexity from engineers. The point is to give Claude an action surface that is useful enough to complete the job and narrow enough to review.
Start with the user outcome, then work backward to the minimum tool:
| Outcome | Bad tool shape | Better tool shape |
|---|---|---|
| Check a customer billing state | call_internal_billing_api with arbitrary path and body | get_customer_billing_summary with customer_id, status fields, last invoice, and next action |
| Prepare a refund | admin_mutation with raw JSON | create_refund_draft that returns a draft id and requires human approval before execution |
| Investigate an incident | query_logs with unrestricted text and time range | summarize_incident_errors with service, time window, limit, count, and sample lines |
| Update a CRM note | write_crm with free-form endpoint access | append_account_note with account id, note text, reason, actor, and audit id |
The wrapper should also decide what Claude does not get. Keep secrets server-side. Do not return tokens, raw PII, full database rows, or unrestricted logs unless the specific reader workflow truly requires them and policy allows it. If Claude only needs a decision, return a decision-ready summary with source ids, counts, timestamps, and a small sample.
Use compact result design from the beginning. Token cost is not the only reason. Large internal API payloads make tool use less reliable because Claude has to inspect noisy fields, irrelevant rows, and repeated metadata. A better result shape is short, typed, and action-oriented:
json{ "customer_id": "cus_123", "billing_status": "past_due", "open_invoice_count": 2, "latest_invoice": { "id": "inv_789", "amount_due_usd": 42.5, "due_date": "2026-06-03" }, "recommended_next_action": "ask customer to update payment method", "source_records": ["inv_789", "ticket_456"] }
The wrapper should make unsafe actions slower than safe reads. A read-only summary can return immediately. A write should usually create a draft, require approval, and record who approved it. The tool should have a clear reason field, an idempotency key, a preview response, and a rollback or cancel path where the domain supports it.
Remote Connector Boundaries: API MCP Connector, Custom Connectors, And Network Reach
The Claude API MCP connector is not the same thing as a local Claude Code MCP server. It lets the Messages API connect to remote MCP servers directly, but the server must be reachable through HTTP with Streamable HTTP or SSE. Local stdio servers do not connect directly through that API route.
As of June 1, 2026, the current API connector boundary has several implementation facts that should stay close to any production plan:
| Boundary | Current planning consequence |
|---|---|
| Beta header | Requests currently require anthropic-beta: mcp-client-2025-11-20; older header names should be treated as stale unless verified again. |
| Transport | Use a reachable remote HTTP/SSE MCP server for the API connector. Do not paste a local stdio Claude Code command into this path. |
| Capability scope | The connector currently supports MCP tool calls, not a general tunnel for every MCP primitive. |
| Data retention | Anthropic's docs state the MCP connector is not covered by ZDR, so sensitive-tool policy needs an explicit review. |
| Tool control | Use allowlists, denylists, and connector-level controls so the model sees only the tools needed for the task. |
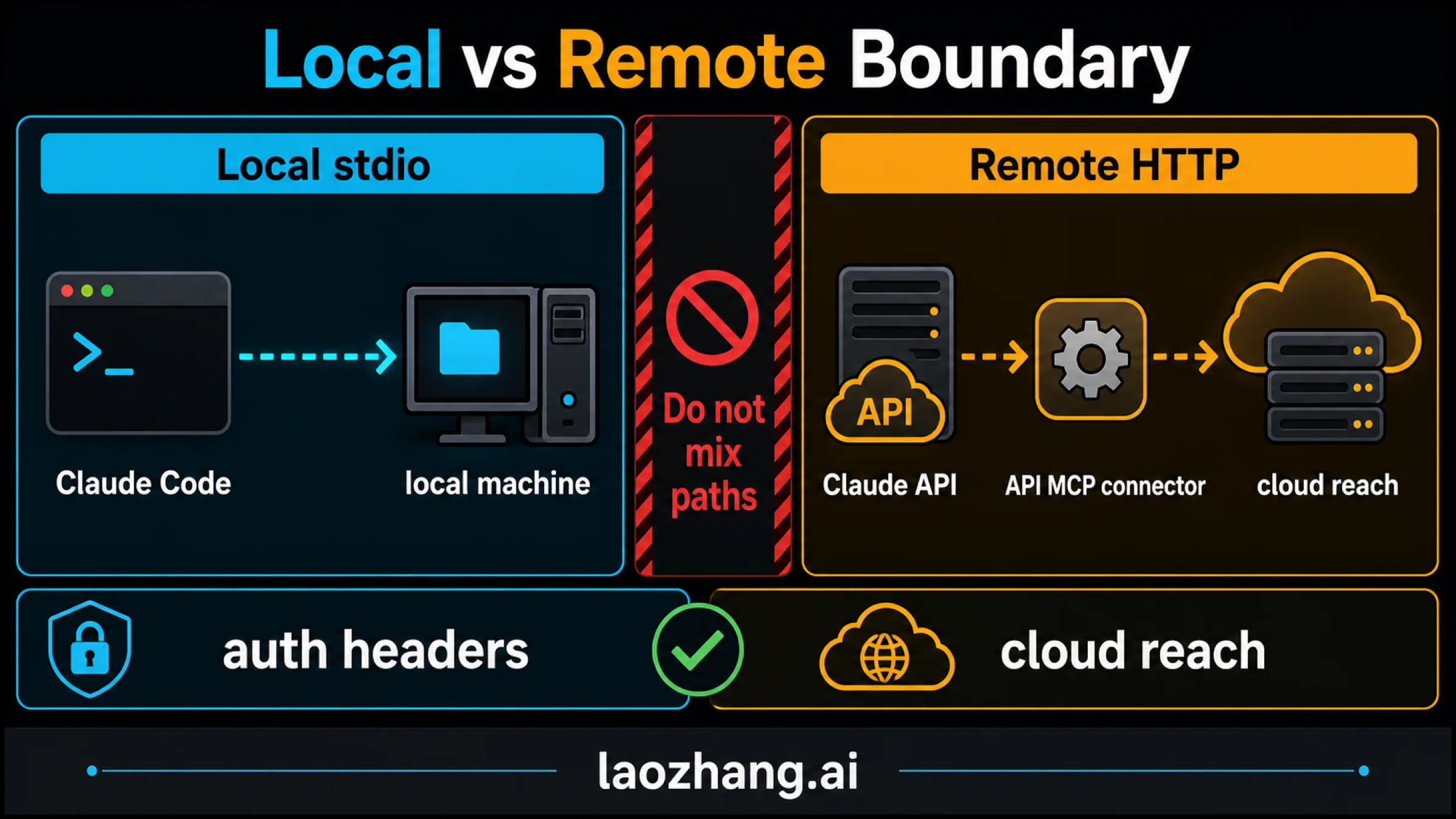
Custom connectors for Claude.ai or Claude Desktop are a separate user-facing route. They also use remote MCP, but the product surface, approval model, plan availability, and admin controls differ from a backend Messages API integration. Anthropic cloud infrastructure must be able to reach the connector, so private-network assumptions need to be tested before the design is accepted.
For internal APIs, that network fact is not a minor deployment detail. It decides where the MCP server runs, which firewall rules exist, how OAuth or service tokens are issued, how tenant boundaries are enforced, and who can approve tool access. A connector that reaches a sensitive internal system needs the same security review as any external integration that can read or mutate company data.
Use this boundary table before writing code:
| Question | Direct tools | API MCP connector | Custom connector |
|---|---|---|---|
| Who reaches the internal system? | Your application backend | Remote MCP server reachable by Claude API path | Remote MCP server reachable by Claude user surface |
| Where is auth enforced? | App session, service account, and tool executor | MCP server, connector config, headers, and internal policy | Connector auth, user/admin approval, MCP server, and internal policy |
| Good first use | Product-owned workflow | Shared internal toolset for Messages API | Human Claude workflow with approved remote tools |
| First production risk | Hidden broad tool execution in app code | Exposing too many tools or returning too much data | User-facing permissions, write actions, and prompt-injection risk |
If the MCP server is remote, design it like a production integration, not a developer convenience script. Add health checks, request logging, auth verification, rate limits, schema tests, and safe failure responses. If the server is only a local helper for one developer, keep it in the Claude Code branch instead of promoting it to an API connector.
Claude Code And Desktop Are Local Workflow Branches
Claude Code MCP is excellent for local developer workflows: repository tools, project-local scripts, internal docs, issue trackers, database read helpers, browser verification, or team-specific development utilities. It is also the branch where local stdio servers make sense. The current Claude Code MCP docs and CLI help separate local, project, and user scopes, and current CLI syntax supports stdio, sse, and http transports.
That does not make Claude Code the runtime for every internal tool integration. If your production app calls the Messages API, Claude Code settings on a developer laptop do not define the app's tool surface. If a local stdio server works in Claude Code, that only proves the local workflow branch. It does not prove that a remote API connector can reach the same tool.
Use Claude Code MCP when the reader job is local:
bashclaude mcp add --scope project support-search --transport stdio -- ./scripts/support-search-mcp claude mcp list
Use a remote route when the reader job is backend or cross-client:
bashclaude mcp add --scope project support-search https://mcp.example.com/mcp
Keep the two branches documented separately. A local MCP server can read a local file system, call local commands, or depend on developer-specific credentials. A remote MCP server needs deployment, reachable networking, auth, observability, and a stricter public interface. Mixing those assumptions is how teams accidentally build something that worked in a demo but cannot be approved for production.
If the decision is about which Claude Code MCP servers belong in a developer setup, use the workflow-first Claude Code best MCP servers page. If the problem is too many active MCP servers or oversized tool returns, use the Claude Code MCP context overload cleanup path. If the confusion is credential routing, environment variables, or provider base URLs, use Claude Code API configuration.
Production Safety Checklist

Internal tools should move through a safety ladder. The first version should prove that Claude can read the right bounded data and return useful summaries. Write access comes later, after preview, approval, audit, and rollback behavior are boring enough to trust.
| Gate | Pass condition | Stop if... |
|---|---|---|
| Tool scope | Each tool maps to one user outcome and one narrow internal operation | The tool accepts arbitrary endpoint, SQL, shell, or mutation input |
| Credential scope | Credentials are server-side, least-privilege, and separated by environment | Claude can see secrets or reuse broad admin credentials |
| Read-only proof | Reads return compact, decision-ready results with source ids | Reads return raw dumps, secrets, or unbounded result sets |
| Write preview | Write tools create drafts or previews before execution | A write executes immediately without human or policy approval |
| Approval path | Risky actions require an approver, reason, and durable audit id | Approval exists only in the prompt text |
| Audit log | Every tool call records actor, user, tool, input summary, output summary, and result id | You cannot reconstruct what Claude attempted and what actually changed |
| Output budget | Results have limits, pagination, summaries, and file handles for deep data | A single call can flood the context with logs, rows, or full documents |
| Prompt-injection guard | Tool results are treated as untrusted data, especially from tickets, docs, web pages, and user content | Tool output can instruct Claude to override policy or call write tools |
Treat prompt injection as an internal-tool problem, not only a web-browsing problem. Support tickets, CRM notes, docs, emails, Slack exports, database comments, and customer-uploaded files can all contain adversarial instructions. Your wrapper should label retrieved content as data, separate it from system policy, and avoid returning unnecessary raw text when a structured summary is enough.
The approval design should match the action. Low-risk read summaries may only need normal auth and logging. A refund, deployment, permission change, account suspension, or database mutation needs a preview, an approval record, and a way to verify the final state. If the internal domain cannot offer rollback, the tool should say so before approval.
Implementation Sketch
The implementation pattern is the same whether you start with direct tools or MCP: define a narrow tool, execute it in trusted code, return compact output, and log the attempt. The difference is where the tool contract lives and which runtime calls it.
For direct Claude API tools, the application loop owns execution:
tsconst tools = [ { name: "get_customer_billing_summary", description: "Return a compact billing summary for a support-approved customer id.", input_schema: { type: "object", properties: { customer_id: { type: "string" }, reason: { type: "string" } }, required: ["customer_id", "reason"] } } ]; // 1. Send tools with the request. // 2. When Claude returns tool_use, verify caller permission. // 3. Call the internal API with a scoped service credential. // 4. Return a compact tool_result and write an audit entry.
For a remote MCP server, the API team owns the server contract. The server exposes tool definitions and handlers; Claude clients connect through the chosen product surface. Keep the first server boring:
| Server design choice | Better default |
|---|---|
| Tool naming | Verb plus domain outcome, such as get_customer_billing_summary |
| Input schema | Required ids, reason fields, time windows, limits, and enum values |
| Output schema | Summary fields, source ids, next action, warnings, and cursor |
| Error handling | Typed domain errors instead of raw stack traces |
| Observability | Tool call id, actor id, request id, latency, result size, and policy decision |
| Permissions | Read-only by default; write tools behind explicit approval |
If you use the Claude API MCP connector, make the connector request a small set of tools instead of exposing every capability the server offers. If you use custom connectors, review user-facing consent and admin controls. If you use Claude Code, store local setup in the right scope and avoid committing secrets. The same internal tool may eventually support multiple surfaces, but the first production version should prove one route cleanly before branching.
Best Next Move
The right next step depends on the route that owns execution:
| Your current situation | Next move |
|---|---|
| One app owns the workflow and only needs a few internal reads | Implement direct Claude API tools with compact tool_result payloads and audit logs. |
| Several Claude clients need the same internal toolset | Design a custom MCP server with read-only tools first, then connect it through the API MCP connector or another approved surface. |
| The work is local developer automation | Keep it in Claude Code MCP, choose project/user scope deliberately, and monitor context load. |
| The work is a human Claude.ai or Desktop workflow | Use a custom connector plan, approval model, and network design rather than local stdio assumptions. |
| The hard problem is long-running hosted runtime | Compare the route against Claude Managed Agents before building your own loop. |
The most reliable first milestone is a read-only tool that proves the full path: model request, tool selection, auth check, internal API call, compact result, audit log, and human-visible answer. Once that works, add tool allowlists, output caps, approval flows, and write previews. Only then decide whether the same contract deserves a reusable MCP server.
FAQ
Is MCP required to connect Claude to internal APIs?
No. Direct Claude API tools are often enough when one application owns the loop and can execute tool calls itself. MCP is useful when you need a reusable tool contract across several Claude clients or connector surfaces.
What is the difference between direct Claude API tools and the Claude API MCP connector?
With direct tools, your application receives tool_use, executes the internal operation, and returns tool_result. With the Claude API MCP connector, the Messages API connects Claude to a remote MCP server that owns the tool interface. The connector route adds a server and network boundary, so it should earn that complexity.
Can the Claude API MCP connector use a local stdio MCP server?
Not directly. As of June 1, 2026, Anthropic's API connector docs require a remote HTTP/SSE MCP server. Local stdio belongs to Claude Code or local Desktop-style workflows, not the Messages API connector path.
Should I expose my whole internal API as MCP tools?
No. Expose task-shaped tools with narrow schemas and compact outputs. Broad endpoint callers, arbitrary SQL tools, shell tools, or admin mutation tools are hard for Claude to use safely and hard for humans to review.
How should write actions work?
Start with read-only tools. For writes, prefer draft or preview tools first, then require approval with a reason, actor, idempotency key, audit id, and verification path. High-risk actions should not execute only because a prompt asked for them.
Do MCP tool results affect context size?
Yes. Tool definitions, tool calls, and tool results can all add context. Keep outputs short, summarized, filtered, and paginated. Return handles or source ids when Claude does not need the full raw payload.
Where does Claude Code MCP fit?
Claude Code MCP fits local developer workflows. Use it for project-scoped tools, local scripts, repo helpers, and developer automation. Do not treat a local Claude Code MCP setup as proof that a backend Messages API connector is deployed or reachable.
What should I verify before production?
Verify the route owner, server reachability, beta headers or connector requirements, auth scope, tool allowlist, read-only result shape, write approval flow, audit logging, output limits, and prompt-injection handling. If any of those are unclear, keep the integration in a read-only pilot.