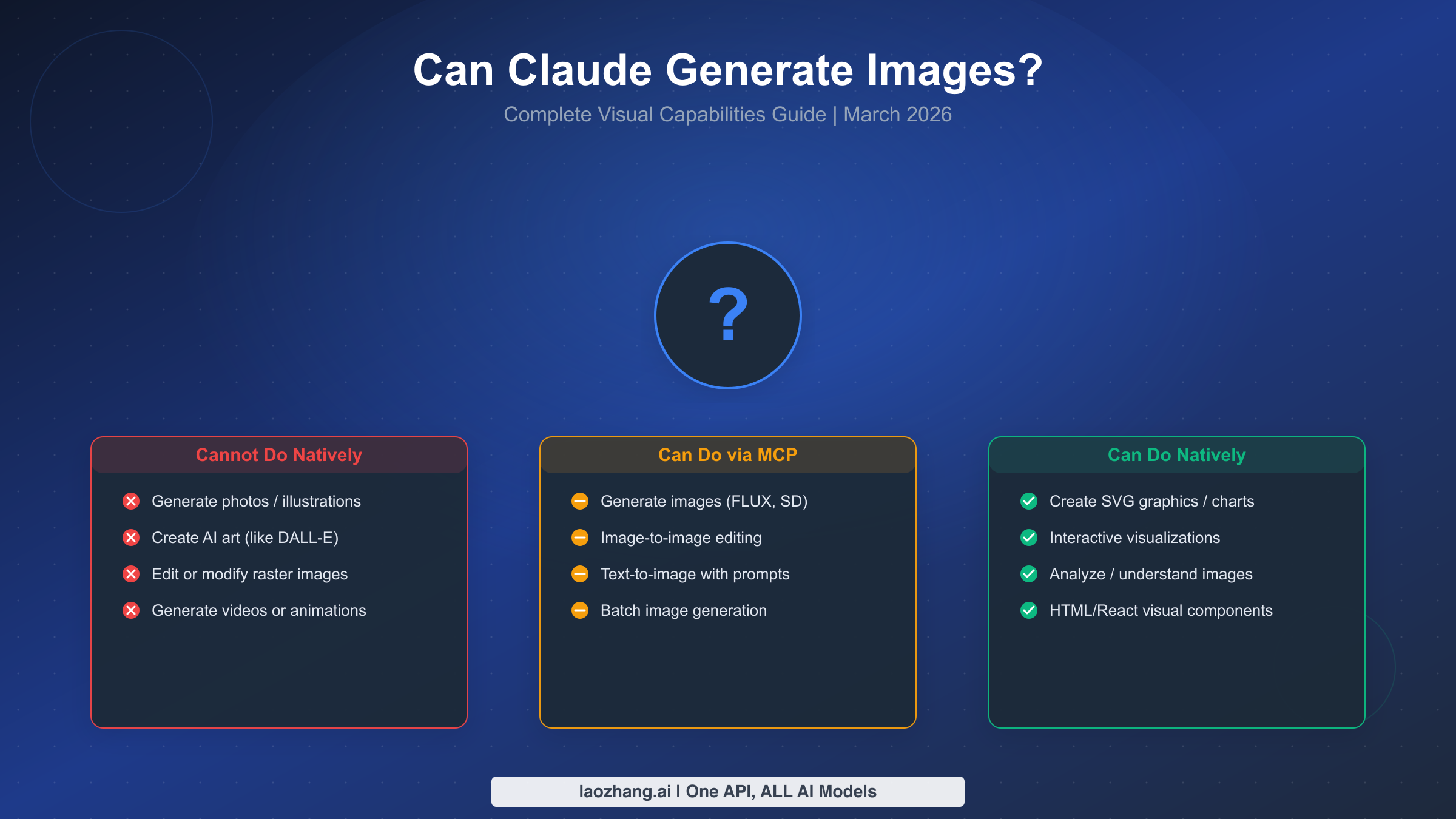
Claude cannot natively generate raster images like photos or illustrations — unlike ChatGPT with DALL-E or Gemini with Imagen. However, Claude offers powerful visual capabilities that many users overlook: it can create SVG graphics, interactive charts, diagrams, and React-based visualizations through Artifacts. Claude also excels at image analysis and understanding through its Vision feature, and can generate images through MCP (Model Context Protocol) integrations with tools like FLUX and Stable Diffusion. This guide covers every visual pathway available as of March 2026.
TL;DR
Claude does not generate photos, illustrations, or AI art natively. What it can do: create professional SVG graphics and diagrams, build interactive visualizations through Artifacts, analyze and understand images with industry-leading accuracy via Vision, and generate raster images through MCP integrations with external models like FLUX and Stable Diffusion XL. For most business and technical use cases, Claude's visual toolkit is more versatile than a simple image generator — it just works differently than you might expect.
The Direct Answer — What Claude Can and Cannot Do with Images
The short answer to "can Claude generate images?" is both no and yes, depending on what you mean by "images." If you are asking whether Claude can create photorealistic pictures, digital art, or illustrations the way DALL-E or Midjourney does, the answer is no. Anthropic, the company behind Claude, has not built a native image generation model into Claude. When you ask Claude to "draw me a sunset" or "create a photo of a cat," it cannot produce a JPEG or PNG pixel-based image from scratch. This is a fundamental architectural decision — Claude is a large language model optimized for text understanding and generation, not a diffusion-based image synthesis system.
However, the complete picture is far more nuanced than a simple "no." Claude possesses several powerful visual capabilities that many users either do not know about or significantly underestimate. First, Claude can generate SVG (Scalable Vector Graphics) code that renders as professional-quality diagrams, charts, flowcharts, logos, and infographics directly in your browser. Second, through the Artifacts feature available on claude.ai, Claude can create fully interactive HTML and React-based visualizations — think animated dashboards, data explorers, and interactive presentations that respond to user input. Third, Claude has industry-leading image understanding capabilities through its Vision feature, allowing it to analyze, describe, extract text from, and answer questions about images you upload. Fourth, and perhaps most excitingly for users who specifically need raster image generation, Claude can now generate images through MCP (Model Context Protocol) integrations that bridge Claude's intelligence with dedicated image generation models like FLUX, Stable Diffusion, and others.
The capability matrix breaks down as follows. Claude cannot natively create: photographs, digital paintings, AI art, raster image files (PNG/JPEG), or video content. Claude can natively create: SVG vector graphics, HTML/CSS visual layouts, interactive React components via Artifacts, Mermaid diagrams, and ASCII art. Claude can do through integrations: generate photorealistic images via MCP servers, edit existing images using external tools, and batch-generate images using API-connected workflows. Understanding this distinction is essential because it determines which approach to use for your specific visual content needs, and as you will see throughout this guide, Claude's actual visual capabilities are considerably broader than most users realize.
What Claude CAN Create Visually (More Than You Think)

When most people think about AI image generation, they picture tools like DALL-E producing photorealistic images from text prompts. Claude operates in a fundamentally different visual space — one that is arguably more useful for professional and technical workflows, even if it cannot paint you a picture of a dragon riding a bicycle. Claude's native visual capabilities fall into four distinct categories, each serving different user needs and producing different types of visual output.
SVG Graphics and Diagrams
Claude's ability to generate SVG code is genuinely impressive and often underappreciated. SVG (Scalable Vector Graphics) is a web-standard format that describes images using mathematical instructions rather than pixels, which means the output scales perfectly to any size without losing quality. When you ask Claude to create a flowchart, organizational chart, comparison diagram, data visualization, or even a simple logo, it generates clean SVG code that renders as a professional-quality graphic in any modern browser. The quality of Claude's SVG output consistently exceeds what ChatGPT and Gemini produce in this format, largely because Claude's code generation capabilities are best-in-class and SVG is fundamentally a code-based format.
Practical applications for Claude's SVG capabilities include technical documentation diagrams, presentation graphics, data visualizations for reports, simple brand assets and icons, and architectural diagrams for software systems. The key advantage here is precision and editability — unlike a raster image generated by DALL-E, an SVG diagram from Claude can be easily modified by editing the underlying code, and it will look sharp on everything from a phone screen to a conference room projector.
Interactive Visualizations Through Artifacts
Perhaps the most exciting and least-known visual capability is Claude's ability to create fully interactive visualizations through the Artifacts feature on claude.ai. Artifacts allow Claude to generate complete HTML, CSS, and JavaScript applications — including React components — that render in a dedicated panel alongside the conversation. This means Claude can create interactive data dashboards where users can filter and sort data, animated educational visualizations that explain complex concepts, interactive calculators and comparison tools, and prototype UI components with full interactivity. As of March 2026, Anthropic has expanded Artifacts capabilities to support even more complex interactive visuals, making Claude a legitimate prototyping tool for designers and developers.
The difference between a static DALL-E image and a Claude interactive Artifact is the difference between a photograph of a dashboard and a working dashboard. For business presentations, educational content, and technical documentation, interactive visuals often communicate information far more effectively than static images. Claude's Artifacts are available on Pro ($20/month, as of March 2026, claude.ai) and Max plans, with limited availability on the free tier.
HTML and CSS Visual Layouts
Beyond interactive Artifacts, Claude excels at generating complete HTML and CSS layouts that can serve as visual assets. Need a pricing comparison card? A feature highlight section? A styled data table with hover effects? Claude generates production-quality HTML/CSS that can be screenshot or directly embedded in web projects. This capability bridges the gap between "I need an image" and "I need a visual" — often, what users really need is a well-designed visual presentation of information, not necessarily a raster image file.
Claude's Image Understanding — Powerful Vision Capabilities
While Claude cannot generate raster images, it is one of the most capable AI systems available for understanding and analyzing them. Claude's Vision feature, available across all Claude models including the free tier on claude.ai, allows you to upload images and ask Claude to analyze, describe, interpret, and extract information from them with remarkable depth and accuracy. This is a distinctly different capability from image generation, but for many professional workflows, image understanding is actually more valuable than image creation — and it is a capability where Claude genuinely leads the industry.
Claude's Vision capabilities cover several important use cases that demonstrate why Anthropic chose to invest heavily in image understanding rather than image generation. Document analysis and OCR represents one of the strongest applications, and it is the use case where Claude most clearly outperforms competing AI assistants. Claude can read text from photographs of documents, handwritten notes, receipts, and business cards with remarkable accuracy, often outperforming dedicated OCR tools that cost hundreds of dollars per year. The accuracy extends to challenging scenarios that trip up other systems — partially obscured text, unusual fonts, multi-language documents, and handwriting with varying legibility. Developers routinely upload screenshots of error messages, code snippets, or configuration files and ask Claude to debug or explain what they see, making it an invaluable development companion that bridges the gap between visual information and actionable technical guidance.
Image description and accessibility is another area where Claude's Vision excels in ways that directly impact business outcomes. When you upload a photograph, chart, or diagram, Claude can provide detailed, accurate descriptions that capture not just what is in the image but the relationships between elements, the mood of a photograph, or the key takeaways from a data visualization. This capability has practical applications that extend well beyond casual use. Website owners use Claude to generate alt text for thousands of images, improving both accessibility compliance and SEO performance. Research teams use it to catalog and describe image archives. Media companies use it to automatically generate captions and metadata for visual content. The quality of Claude's descriptions is consistently detailed enough to meet WCAG accessibility guidelines, which require alt text that conveys the same information a sighted user would obtain from the image.
Visual reasoning and question answering demonstrates Claude's deeper understanding of images and represents perhaps the most technically impressive aspect of its Vision system. You can upload a complex infographic and ask Claude to explain the key trends and whether the data supports the conclusion being presented. You can upload a photograph of a room and ask Claude to estimate dimensions, identify potential safety issues, or suggest interior design improvements. You can upload a technical diagram — an electrical schematic, a network topology, a chemical structure — and ask Claude to identify potential errors or suggest optimizations. Claude's ability to reason about visual content, not just describe it, sets it apart from simpler image recognition tools and makes it genuinely useful for expert-level work.
The practical workflow for many users involves a powerful combination of Vision and generation capabilities working in sequence: upload an existing image for Claude to analyze, then ask Claude to create an improved version as an SVG diagram, an interactive Artifact, or even a raster image through MCP integration. This analyze-then-recreate workflow leverages Claude's strengths in both directions and is particularly valuable for users who need to modernize legacy diagrams, recreate charts from photographed whiteboards, or convert static images into interactive visual experiences.
How to Generate Images Through Claude Using MCP
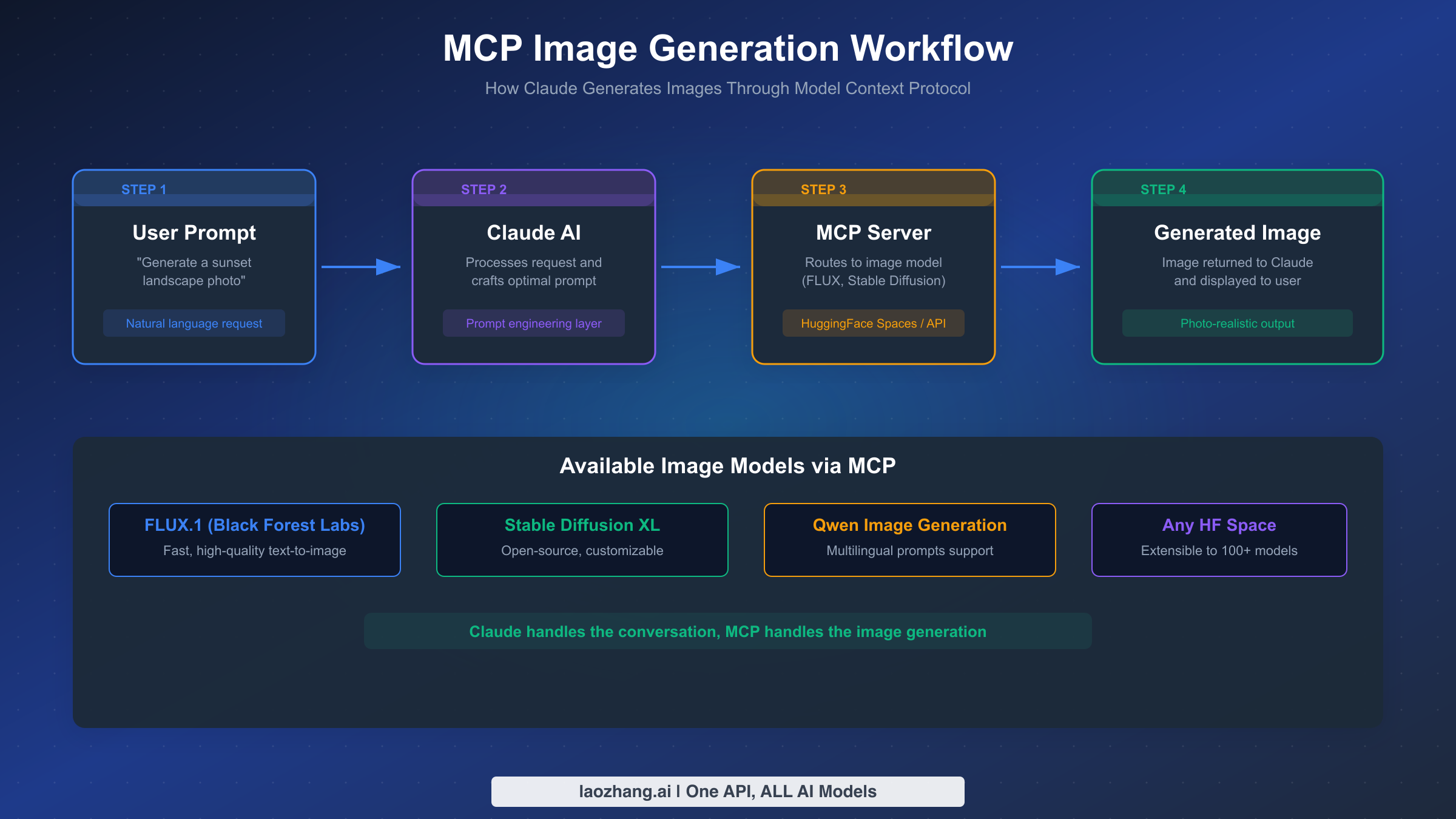
For users who specifically need Claude to produce raster images — photographs, illustrations, digital art — the Model Context Protocol (MCP) provides a powerful bridge between Claude's conversational intelligence and dedicated image generation models. MCP is an open protocol developed by Anthropic that allows Claude to interact with external tools and services, effectively extending Claude's capabilities beyond what the base model can do. Through MCP, Claude can connect to image generation APIs like FLUX.1 (from Black Forest Labs), Stable Diffusion XL, and virtually any model hosted on HuggingFace Spaces, enabling true text-to-image generation within the Claude workflow.
How MCP Image Generation Works
The workflow is straightforward once configured. You send a natural language request to Claude ("Generate a professional product photo of a laptop on a minimalist desk"). Claude processes your request using its language understanding to craft an optimized prompt for the target image model. The MCP server routes this prompt to the selected image generation model (FLUX, Stable Diffusion, etc.). The generated image is returned through MCP and displayed directly in your Claude conversation. The key advantage of this approach is that Claude acts as an intelligent prompt engineering layer — it understands context, refines vague requests, and optimizes prompts for the specific model being used, often producing better results than directly prompting the image model yourself.
Setting Up MCP for Image Generation
Setting up MCP image generation with Claude Desktop requires a few steps but is well within reach for users with basic technical comfort. You need Claude Desktop (the downloadable application, not the web version) and a configuration file that tells Claude which MCP servers to connect to. The most popular approach uses HuggingFace Spaces as the image generation backend, which provides free access to models like FLUX.1.
To configure Claude Desktop for image generation, you need to edit the MCP settings file located at ~/Library/Application Support/Claude/claude_desktop_config.json on macOS or the equivalent path on Windows. A basic configuration for connecting to a FLUX model on HuggingFace looks like this:
json{ "mcpServers": { "image-generator": { "command": "npx", "args": [ "-y", "@anthropic/mcp-server-huggingface", "--space", "black-forest-labs/FLUX.1-schnell" ] } } }
After saving this configuration and restarting Claude Desktop, you will see a new tool icon in the chat interface indicating that the MCP server is connected. From that point, you can simply ask Claude to generate images in natural language, and it will use the connected model to produce them.
For developers and teams who need more flexibility, you can configure multiple image generation models simultaneously and let Claude choose the most appropriate one based on the request. For example, you might configure FLUX.1 for fast concept art, Stable Diffusion XL for photorealistic images, and a specialized model for specific styles. For a deeper dive into API-based image generation pricing, see our AI image generation API pricing comparison.
Available Image Models via MCP
The MCP ecosystem supports a growing number of image generation models, each with different strengths. FLUX.1 by Black Forest Labs is currently the most popular choice for MCP image generation due to its speed and quality balance — the "schnell" variant generates images in under two seconds while maintaining good visual quality. Stable Diffusion XL remains popular for users who want maximum customization through LoRA models and fine-tuning. Qwen Image Generation offers strong multilingual prompt support, making it ideal for non-English creative work. And because MCP connects to HuggingFace Spaces, any of the hundreds of image generation models hosted there can potentially be integrated with Claude.
Claude vs ChatGPT vs Gemini — Image Generation Compared
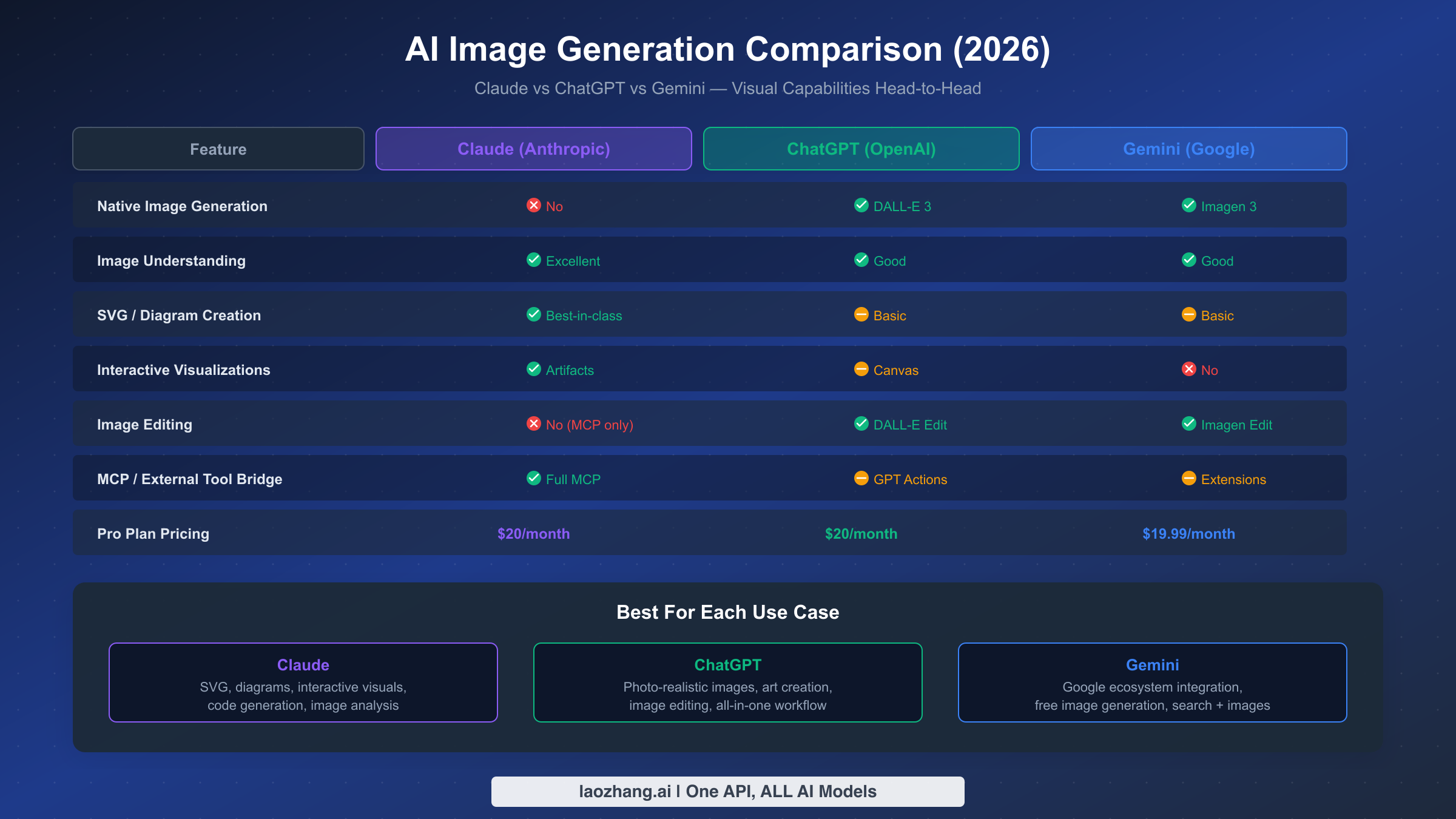
Understanding how Claude's visual capabilities compare to its main competitors — ChatGPT (OpenAI) and Gemini (Google) — requires looking beyond the simple "can it generate images?" question. Each platform has adopted a fundamentally different strategy for handling visual content, and the best choice depends entirely on your specific workflow needs. The comparison below uses verified pricing and feature data as of March 2026.
Native image generation is the area where Claude's gap is most visible. ChatGPT integrates DALL-E 3 directly into its conversation interface, allowing users to generate photorealistic images, illustrations, and creative art without any additional setup — this is the most seamless image generation experience among the three platforms. Gemini similarly integrates Google's Imagen 3 model, offering native image generation with particular strengths in photorealism and text rendering within images. Claude does not offer native raster image generation, and this remains its most significant gap relative to competitors. However, Claude's approach through MCP integration offers greater model flexibility, since users can connect to any image generation model rather than being locked into a single provider's output style. The trade-off is clear: ChatGPT and Gemini prioritize convenience with built-in models, while Claude prioritizes flexibility and choice through its open protocol architecture.
Visual creation beyond photos is where Claude's competitive position shifts dramatically in its favor. Claude's SVG generation quality consistently exceeds both ChatGPT and Gemini, producing cleaner code, more accurate layouts, and better-designed diagrams. This advantage stems from Claude's best-in-class code generation capabilities — since SVG is fundamentally a code format, better code generation directly translates to better visual output. Claude's Artifacts feature for interactive visualizations has no direct equivalent in ChatGPT or Gemini. While ChatGPT offers Canvas for collaborative editing and Gemini can generate some visual content, neither matches the sophistication of Claude's interactive React-based Artifacts, which can produce fully functional dashboards, calculators, and data explorers. For users whose "image generation" needs are actually about creating professional diagrams, data visualizations, or interactive visual content, Claude is arguably the strongest platform available today.
Image Understanding and Analysis
All three platforms offer strong image understanding capabilities, but Claude's Vision is widely regarded as the most accurate for detailed image analysis, document OCR, and visual reasoning tasks. Independent benchmarks consistently place Claude at or near the top for image understanding accuracy, particularly for complex multi-element images and nuanced visual interpretation. Claude's advantage is especially pronounced in document analysis scenarios — extracting data from tables in photographs, reading handwritten notes, and interpreting complex technical diagrams. ChatGPT's image understanding is strong and improving with each model update, while Gemini benefits from Google's extensive computer vision research, making it particularly good at identifying objects, locations, and landmarks in photographs.
Pricing and Value Comparison
All three platforms offer their core features at remarkably similar price points: Claude Pro at $20/month, ChatGPT Plus at $20/month, and Gemini Advanced at $19.99/month (all prices verified March 2026, respective official pricing pages). The value calculation depends on which capabilities matter most to you. If native image generation is essential, ChatGPT and Gemini offer better value since that capability is included in the subscription. If you primarily need SVG graphics, interactive visuals, and superior image analysis, Claude Pro provides the best return on investment. For a detailed breakdown of how Claude stacks up against ChatGPT across all dimensions, see our detailed ChatGPT vs Claude comparison.
Which Platform for Which Need?
The decision framework is straightforward once you identify your primary use case. Choose ChatGPT if your primary need is generating photorealistic images, creative art, or illustrations within a conversation — DALL-E integration is unmatched for ease of use, and the quality of generated images continues to improve with each model update. Choose Gemini if you need image generation tightly integrated with Google's ecosystem (Search, Docs, Slides) or want the best free-tier image generation option, as Google offers generous free access to Imagen through Gemini. Choose Claude if your visual needs center on professional diagrams, interactive visualizations, image analysis, or if you want maximum flexibility through MCP to connect to any image generation model available in the ecosystem. Many power users maintain subscriptions to multiple platforms, using each for its strengths — Claude for analysis and diagrams, ChatGPT for quick image generation, and Gemini for Google Workspace integration. This multi-platform approach is becoming increasingly common as each AI assistant carves out distinct areas of excellence.
Practical Workflows — Using Claude for Visual Content Creation
Understanding Claude's capabilities in theory is useful, but seeing how they combine in real workflows demonstrates their practical value. The following scenarios illustrate how different types of users leverage Claude's visual toolkit to accomplish tasks that might initially seem to require a dedicated image generator.
Content creators and marketers frequently use Claude to produce visual assets for blog posts, social media, and presentations. A typical workflow involves asking Claude to create a comparison infographic as an SVG diagram, then requesting an interactive version as an Artifact for the web version of the content. For example, a content marketer writing about cloud storage options might ask Claude to generate a pricing comparison chart as an SVG, create an interactive calculator in Artifacts that lets readers input their storage needs and see cost projections, and then use Claude's Vision to analyze competitor infographics for inspiration. The entire visual content pipeline happens within a single Claude conversation, with each visual building on the context of the previous ones.
Software developers and technical writers represent perhaps the largest group of users who benefit from Claude's visual approach. When documenting a microservices architecture, a developer can ask Claude to generate a system diagram as SVG, create an interactive architecture explorer as an Artifact where users can click on services to see their connections, and produce sequence diagrams for API flows. Because Claude understands the code context deeply, its technical diagrams are often more accurate and informative than what a generic image generator would produce — Claude knows what a well-structured architecture diagram should communicate, not just what it should look like.
Educators and trainers leverage Claude's interactive Artifacts extensively. An instructor teaching statistics can ask Claude to create an interactive normal distribution visualizer where students can adjust mean and standard deviation values and see the curve change in real time. A language teacher might request an interactive vocabulary flashcard system with spaced repetition. These interactive educational tools go far beyond what a static image could achieve, and Claude's ability to generate them conversationally makes it accessible even to educators without programming experience.
Data analysts and researchers use Claude's combined Vision and SVG capabilities for rapid data visualization workflows. Upload a screenshot of a data table from a PDF report, and Claude can extract the data using Vision, then immediately generate a publication-quality SVG chart visualizing the key trends. This analyze-then-visualize workflow collapses what would traditionally require multiple tools (OCR software, spreadsheet program, charting tool) into a single conversational interaction. Researchers have found this particularly valuable for literature reviews, where they need to quickly visualize data from multiple papers — upload the charts from each paper, ask Claude to extract the key data points, then generate a unified comparison visualization that synthesizes findings across studies.
Product managers and UX designers are increasingly discovering Claude as a rapid prototyping companion. Rather than spending hours in Figma creating mockups for stakeholder reviews, they can describe a user interface concept to Claude and receive an interactive Artifact prototype within minutes. The prototype is not pixel-perfect, but it is functional — buttons click, forms accept input, and data flows between components. This allows product teams to test interaction concepts and gather stakeholder feedback at a fraction of the traditional prototyping cost and timeline. When combined with Claude's ability to analyze screenshots of existing applications (via Vision), this creates a powerful workflow: photograph the current state, describe the desired changes, and receive a working prototype of the improved version.
Frequently Asked Questions About Claude and Images
Can Claude generate photos like DALL-E or Midjourney?
No, Claude cannot natively generate photorealistic images, digital art, or illustrations. Unlike ChatGPT which integrates DALL-E 3 or Midjourney which is purpose-built for image creation, Claude does not have an internal image synthesis model. However, Claude can generate photos through MCP integrations with models like FLUX.1 and Stable Diffusion, which requires Claude Desktop and some initial configuration. Once set up, the experience is conversational — you describe what you want and Claude uses the connected model to produce it.
What kind of visuals CAN Claude create without any integrations?
Out of the box, Claude can create SVG graphics (charts, diagrams, flowcharts, infographics, logos, icons), interactive HTML/React visualizations through Artifacts, Mermaid diagrams, and styled HTML/CSS layouts. These capabilities are available on all plans including the free tier, though Artifacts functionality is more limited on free accounts. For many professional use cases — technical documentation, presentations, data visualization — these native capabilities are actually more useful than raster image generation.
Can Claude analyze and understand images I upload?
Yes. Claude's Vision feature is one of the most capable image understanding systems available. You can upload photos, screenshots, documents, charts, diagrams, and other images, and Claude will analyze them in detail. It can extract text (OCR), describe visual content, answer questions about images, identify objects and patterns, and reason about spatial relationships. Vision is available on all Claude plans including free (claude.ai, March 2026).
Is Claude's image understanding better than ChatGPT's?
Claude's image understanding is generally considered industry-leading, particularly for detailed analysis, document OCR, and complex visual reasoning. Independent benchmarks consistently place Claude at or near the top for image understanding accuracy. ChatGPT's vision capabilities are also strong and continue to improve, but Claude tends to provide more nuanced and detailed analysis, especially for technical images, multi-element compositions, and document extraction tasks.
Will Claude add native image generation in the future?
Anthropic has not publicly announced plans to add native raster image generation to Claude. The company has historically focused on safety, reasoning, and language capabilities rather than competing directly in the image generation space. However, the MCP ecosystem means that Claude can already access virtually any image generation model through integrations, which may reduce the urgency for Anthropic to build their own. For the most current information on Claude's capabilities, check Anthropic's official documentation and the Claude subscription pricing guide for plan details.
Final Verdict — Is Claude Enough for Your Visual Needs?
Whether Claude is "enough" for your visual content needs depends entirely on what those needs actually are. If you primarily need photorealistic image generation for creative projects, social media content, or marketing materials, Claude alone is not the right tool — you will want ChatGPT with DALL-E, Midjourney, or a dedicated image generator. Claude can bridge this gap through MCP integrations, but the setup requires technical effort and the workflow is less seamless than native image generation in competing platforms.
However, if your visual needs center on professional diagrams, technical documentation, data visualization, interactive presentations, or image analysis, Claude is not just "enough" — it is arguably the best AI platform available. Its SVG generation quality, interactive Artifact capabilities, and industry-leading Vision make it uniquely suited for knowledge work that requires precise, editable, and interactive visual content rather than artistic image creation.
The most pragmatic approach for users with diverse visual needs is to use Claude as the primary AI assistant for its superior reasoning, coding, and analytical capabilities, while leveraging MCP integrations for the occasional raster image generation need. This gives you Claude's intelligence as the orchestration layer — understanding your intent, refining prompts, choosing the right tool — while accessing the full ecosystem of image generation models when needed. For many users, this combination proves more powerful than any single platform's native capabilities, because Claude's understanding of context and intent translates into better results regardless of which image model ultimately produces the pixels.
For teams and organizations evaluating AI platforms, the recommendation is to audit your actual visual content needs over the past quarter before making a decision. If more than half of your "image generation" requests were actually for diagrams, charts, documentation graphics, or data visualizations, Claude is likely the better investment. If the majority were for creative imagery, marketing photos, or artistic content, ChatGPT or a dedicated tool like Midjourney will serve you better. And if you need both, the MCP integration path means Claude can handle creative image generation too — it just requires a bit more setup than the out-of-the-box experience offered by competitors.
The bottom line: Claude cannot generate photos natively, but its visual capabilities are broader, more versatile, and in many professional contexts more useful than simple image generation. The question is not whether Claude can create images — it is whether Claude's approach to visual content better serves your actual workflow needs.


