先不要问 Realtime API 和转录管道哪个便宜。先问你的产品是否必须在通话中听懂用户、允许打断、调用工具,并且用自然语音马上回答。如果这件事本身就是产品价值,gpt-realtime-2 的成本可以被业务结果证明;如果产品交付的是文字、摘要、归档、质检、合规记录或分析标签,先按转录优先管道建模。
路线先于价格表:
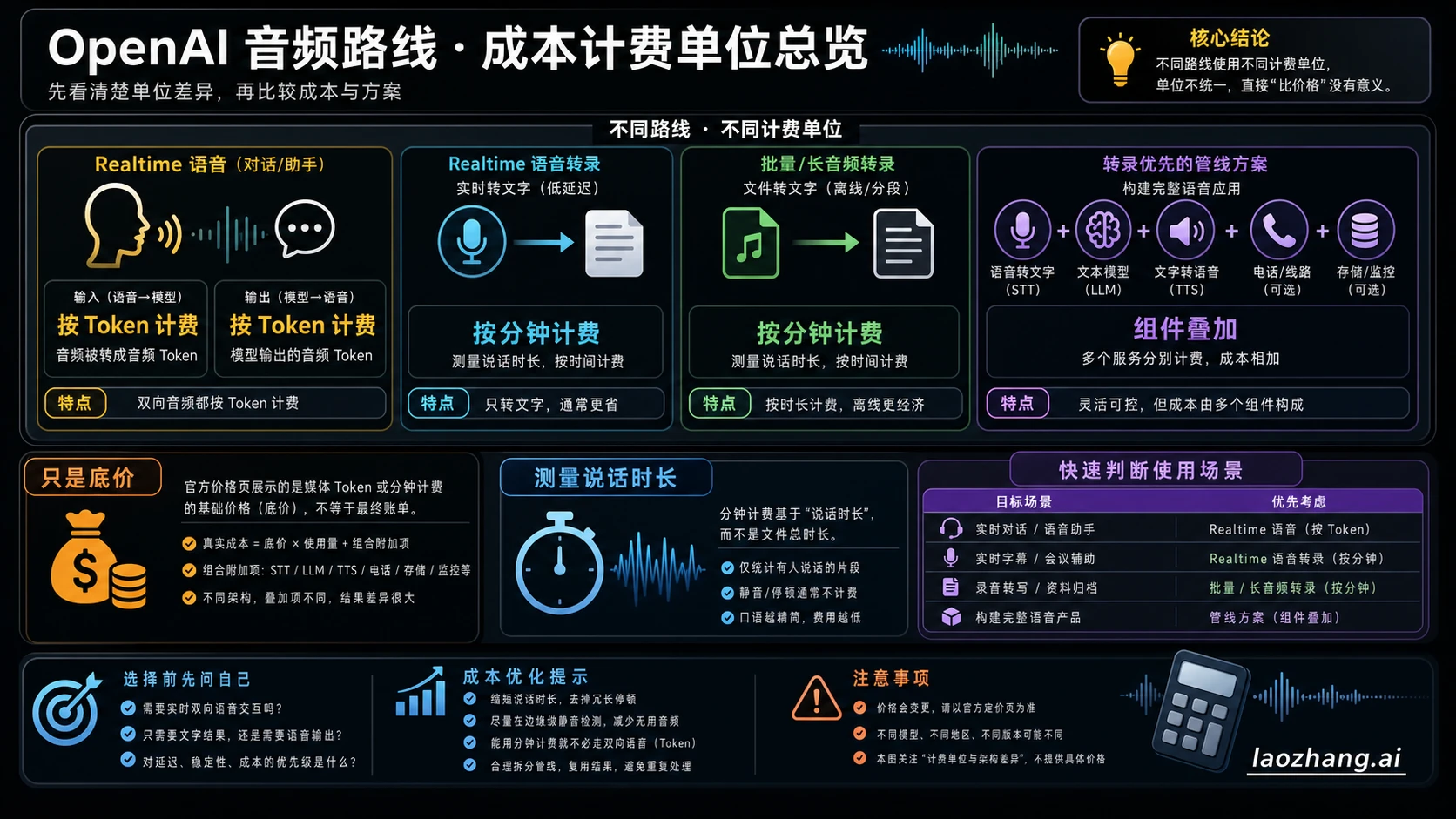
- 实时语音代理:当语音质量、低延迟、打断和通话中的工具调用决定体验时,才从
gpt-realtime-2开始。 - 实时文本转录:如果只需要人在说话时产生文字流,而不需要语音助手回答,先看
gpt-realtime-whisper。 - 录音或文件转写:如果音频可以上传、排队或在通话后处理,先比较
gpt-4o-transcribe和gpt-4o-mini-transcribe。 - 转录优先管道:只有在需要摘要、抽取、质检、存储、检索、人工审核或后续 TTS 时,才把这些组件逐项加入预算。
- 混合方案:把 Realtime 留给高价值的现场互动,把归档、复盘、质检和分析放到转录优先流程里。
截至 2026 年 6 月 14 日,OpenAI 价格页列出 gpt-realtime-whisper 为 $0.017/minute,gpt-4o-transcribe 为 estimated $0.006/minute,gpt-4o-mini-transcribe 为 estimated $0.003/minute。直接换算就是 $1.02/hour、$0.36/hour 和 $0.18/hour。gpt-realtime-2 的语音代理会按音频输入和音频输出 token 计费:一小时被计入的用户音频加一小时助手语音输出,会形成 $5.76/hour 的媒体 token 底线,但这还没有包括文本 token、工具调用、不断变长的对话历史、可选输入转录、电话线路和后处理管道。
停止规则很简单:当文本足够时,不要为语音助手输出付费。下面的工作表会把 OpenAI 官方价格行、Realtime 成本驱动、转录管道变量和混合边界拆开,帮助你判断低延迟语音什么时候值得多花钱。
先按产品任务选路线
“Realtime API vs 转录管道成本”不是一个抽象的价格题。它先是产品任务,再是 OpenAI 路线,最后才是计费单位。把这三层混在一起,最容易把实时转录误当成语音代理,或者把一个低价 STT 行误当成完整系统成本。
| 产品任务 | 首先估算的路线 | 主要计费单位 | 什么时候用 | 停止规则 |
|---|---|---|---|---|
| 实时语音代理 | gpt-realtime-2 | 每次 Response 的音频和文本 token | 用户需要打断、轮次切换、工具调用和语音回应 | 如果文本输出足够,不要从这里开始 |
| 实时字幕或转录 | gpt-realtime-whisper | 实时音频分钟数 | 产品需要边说边出文字,但不需要助手说话 | 如果可以等音频结束,先算录音转写 |
| 录音或文件转写 | gpt-4o-transcribe 或 gpt-4o-mini-transcribe | 提交音频分钟数 | 上传文件、通话后复盘、会议纪要、质检、归档和合规 | 如果必须实时显示文字,再看实时转录 |
| 自定义转录管道 | STT -> 文本模型 -> 可选 TTS -> 运营层 | 每个组件自己的 meter | 团队需要组件控制、电话集成、审计、供应商组合或区域合规 | 不要把 TTS、电话和人工审核默认算进去 |
| 混合方案 | Realtime 处理现场,转录管道处理后台 | 多个 meter 叠加 | 现场互动有价值,但归档和分析不需要语音输出 | 明确现场结束点和后台处理起点 |
这张表的作用是防止“都是音频,所以可以只比每小时价格”的预算错误。语音代理买的是一个互动闭环:用户说话、模型理解、工具运行、助手用语音回应。转录管道买的是文本和围绕文本的处理能力。它们都可能用到音频,但购买的结果完全不同。
当前需要锚定的 OpenAI 价格
预算可以从 OpenAI 当前价格行开始,但不能停在那里。下面这些价格在 2026 年 6 月 14 日核对自 OpenAI pricing page,只用于锚定 OpenAI 直接计价的部分;电话线路、存储、人工质检、第三方服务和你自己的重试策略都要另算。
| 路线 | 当前 OpenAI 价格行 | 小时直觉 | 没有包括什么 |
|---|---|---|---|
gpt-realtime-whisper | $0.017/minute | 直接换算 $1.02/hour | 文本模型、存储、监控、电话线路和非 OpenAI 组件 |
gpt-4o-transcribe | estimated $0.006/minute | 直接换算 $0.36/hour | 摘要、分类、后处理、存储和编排 |
gpt-4o-mini-transcribe | estimated $0.003/minute | 直接换算 $0.18/hour | 准确率复核、领域词汇处理、质检和运营工作 |
gpt-realtime-2 音频输入 | $32.00/1M audio input tokens | 用户音频按 1 token/100 ms 计,一小时为 $1.152/hour | 助手语音、文本、工具、历史增长、输入转录和外部管道 |
gpt-realtime-2 音频输出 | $64.00/1M audio output tokens | 助手语音按 1 token/50 ms 计,一小时为 $4.608/hour | 用户音频、文本、工具、历史增长、输入转录和外部管道 |
转录按分钟计费,换算很直接:
textgpt-realtime-whisper: 60 minutes * $0.017 = $1.02/hour gpt-4o-transcribe: 60 minutes * $0.006 = $0.36/hour gpt-4o-mini-transcribe: 60 minutes * $0.003 = $0.18/hour
gpt-realtime-2 的媒体 token 底线也能算出来,但它只是底线:
textUser audio input: 36,000 tokens/hour * $32 / 1,000,000 = $1.152/hour Assistant audio output: 72,000 tokens/hour * $64 / 1,000,000 = $4.608/hour Media-token floor: $1.152 + $4.608 = $5.76/hour
不要把 $5.76/hour 写成 Realtime 的最终小时价。这个数字只假设一小时用户音频被计入、一小时助手语音被生成,还没有算文本 token、工具 schema、工具结果、系统指令、对话历史重复发送、可选输入转录、特殊 token、电话线路、录音留存和后台处理。它是一个提醒:只要产品需要助手频繁说话,成本形状就会和纯转录不同。
Realtime 语音代理为什么不能按固定小时价理解
Realtime cost guide 的关键点是:Realtime 成本在创建 Response 时产生,并基于输入和输出 token;如果开启输入转录,转录模型会单独计费。OpenAI 还说明目前不对连接和网络带宽收费,但这不等于一个打开的会话没有成本。真正决定账单的是会话里发生了多少生成、多少音频、多少上下文和多少工具工作。
实际成本驱动可以拆成七类:
- 用户音频:按 1 token/100 ms 计入,静音是否被过滤会影响输入量。
- 助手音频:按 1 token/50 ms 计入,长语音回答常常比用户说话更影响成本。
- Response 次数:每一次模型生成都会带来新的计费事件。
- 对话历史:旧内容会随新 Response 再次进入上下文,后半段会话可能比前半段贵。
- VAD 和空音频:配置正确时可以过滤空白输入;手动添加静音则会浪费预算。
- 文本和工具:系统指令、工具 schema、工具结果、文本输出仍然消耗 token。
- 可选输入转录:如果产品需要在 Realtime 会话内保留文字,会额外使用转录模型。
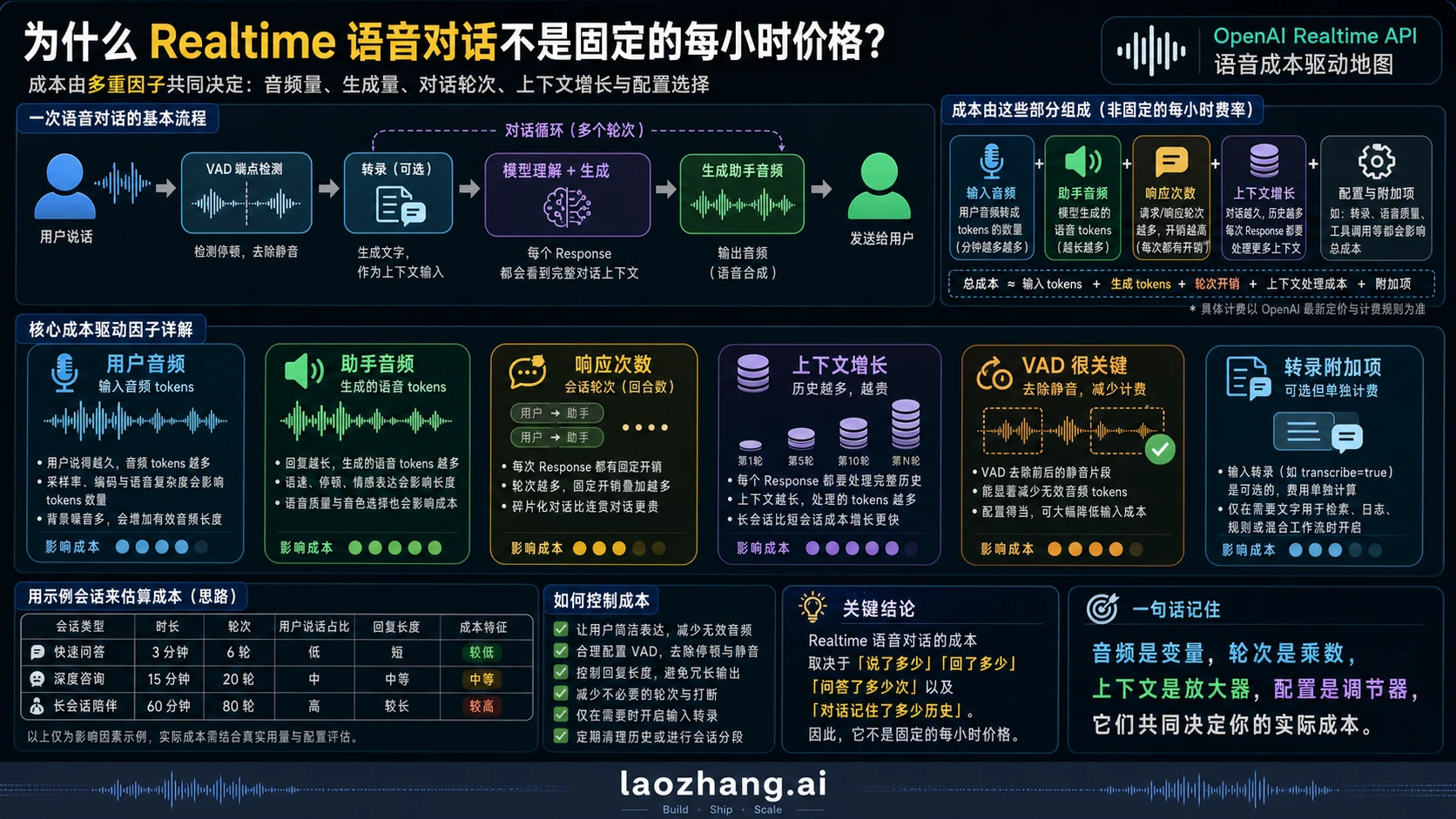
这也是为什么“Realtime 每小时多少钱”通常不是上线预算能接受的答案。一个 60 分钟客服通话可能大部分时间是用户讲述,助手只短句确认;一个 20 分钟口语教练可能需要助手频繁说话、纠错、调用工具、保留长上下文。后者时长更短,但不一定更便宜。
可控的节省动作不是把路线硬换成转录,而是先减少浪费:保持 VAD 生效,不把静音手动追加成输入;当旧历史不再改善回答时结束或总结会话;压缩工具 schema 和系统指令;让助手少说废话;只在产品真的需要会话内文字时开启输入转录;上线前用真实样本记录 Response 数、助手语音时长和后半段上下文大小。
Realtime 的价值也要正面承认。gpt-realtime-2 买的是原生语音互动环路:低延迟、自然打断、语音输出质量和通话中工具调用。如果这些能力提高转化、完成率、可访问性或自助解决率,多出来的成本就是产品成本,而不是纯浪费。
转录优先管道要把哪些组件算进去
转录优先路线看起来便宜,是因为第一步可以只是 speech-to-text。对于文件或有边界的音频,Speech to text guide 指向 gpt-4o-transcribe、gpt-4o-mini-transcribe 和 gpt-4o-transcribe-diarize 等路线;文件上传有 25 MB 限制,这和实时流式字幕是不同形态。对于实时文字但没有语音助手的场景,Realtime transcription guide 更贴近 gpt-realtime-whisper 的工作。
如果产品只需要原始文字,STT 行就可以解释大部分 OpenAI 成本。如果产品还要摘要、结构化字段、质检标签、自动工单、风险审核、电话录音、长期留存或人工抽检,预算必须继续往下拆。
| 组件 | 按什么理解 | 价格处理 |
|---|---|---|
| 音频采集和传输 | App、浏览器、WebRTC、电话线路或录音基础设施 | 变量,取决于产品栈和区域 |
| STT | gpt-realtime-whisper、gpt-4o-transcribe 或 gpt-4o-mini-transcribe | OpenAI 分钟价格可以作为锚点 |
| 文本模型 | 摘要、抽取、路由、质检、教练、审核或 agent 逻辑 | 变量,要按实际模型、token、缓存和重试估算 |
| 可选 TTS | 文本处理后再生成语音 | 只有验证具体路线后才能填固定数 |
| 电话和通话层 | PSTN、SIP、号码、录音、合规功能、运营商费用 | 变量,按供应商和地区核对 |
| 存储和检索 | 音频、文本、embedding、日志、保留策略 | 变量,受隐私和留存要求影响 |
| 监控和 QA | 人工复核、审计、失败回放、告警、指标 | 变量,在受监管场景里可能大于 STT 行 |
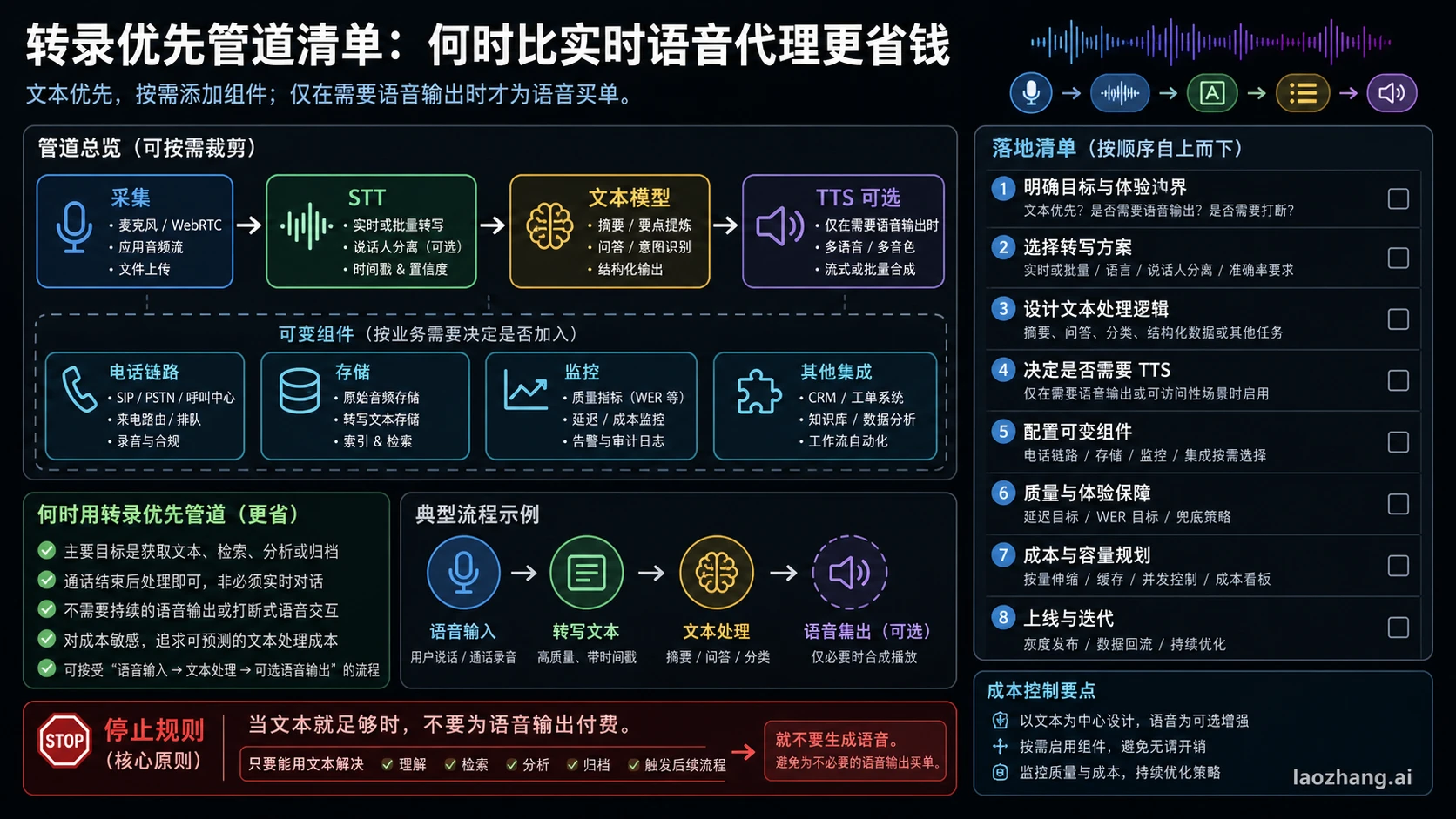
这个管道通常更可预测,也更容易调试。每个组件都会留下明确产物:原始音频、转录文本、摘要、分类、质检意见、审计日志。问题发生时,你可以重跑转录、更换文本模型、比较 prompt、抽查人工审核,而不是只看一个实时会话的最终体验。
代价是延迟和集成复杂度。STT -> 文本模型 -> TTS 的串联流程可以被流式化,但它仍然不是原生语音会话。选择它的理由应该是工作流以文本为中心、组件控制很重要,或者后台处理更适合批量运行;不要因为某个 STT 行便宜,就把整个管道说成一定便宜。
什么时候值得为实时语音付费
当“说话中的互动”改变用户行为时,gpt-realtime-2 才值得进入主预算。典型场景包括销售或 onboarding 电话、需要随时打断的教学和辅导、无障碍语音体验、通话中调用工具的客服 agent、消费者端语音产品,以及能够减少人工升级的自助支持。
试点不要只问“Realtime 是否比 STT 贵”。更好的问题是:“实时语音带来的完成率、转化、满意度、留存、可访问性或人工节省,是否超过额外 meter?”如果不能回答这个问题,先不要把 Realtime 变成全量默认路线。
| 试点指标 | 为什么重要 |
|---|---|
| 用户真实讲话时长 | 决定被计入的用户音频 |
| 助手语音时长 | 决定音频输出,常常主导媒体 token 底线 |
| 每会话 Response 次数 | 控制模型生成事件数量 |
| 后半段平均历史大小 | 暴露长会话成本增长 |
| 每会话工具调用 | 捕捉隐藏文本和工具上下文 |
| 完成率或转化提升 | 判断语音环路是否回本 |
| 人工转接率 | 检查较便宜的文本路线是否已经足够 |
如果这些指标显示实时语音能明显改善结果,那么即使纯转录价格更低,Realtime 也可能是正确支出。成本优化应该围绕会话设计、助手发言长度和高价值场景筛选展开,而不是简单把所有语音都降级成转录。
什么时候转录优先更划算
当文本才是最终产物时,转录优先通常赢。会议纪要、通话质检、合规复核、可搜索归档、支持分析、销售教练笔记、医疗或法律 intake 草稿、异步语音笔记、通话后分类,这些工作大多不需要助手在现场说话。
停止规则可以写进产品规格:如果用户不需要助手说话,不要支付助手音频输出;如果转录可以等音频结束,先比较录音转写;如果只要直播字幕,先算 gpt-realtime-whisper;如果摘要和分类在通话后运行,把它们作为文本模型成本,不要塞进 STT 行;如果需要合规证据链,管道产物往往比单纯实时语音环路更容易审计。
转录优先也给团队更多质量控制空间。你可以保存原始音频、重跑识别、比较模型输出、抽查敏感行业术语、分批处理不紧急任务、把人工复核放在高风险样本上。对运营团队来说,这种可控性常常比几秒钟的延迟更重要。
混合方案:只把 Realtime 用在高价值现场
生产环境里最常见的合理形态不是二选一,而是混合:把 Realtime 放在现场互动真正改变结果的那一段,把后台复盘、归档、质检、合规和分析交给转录优先流程。
一个简单的混合序列可以这样设计:
- 只有在用户需要打断、轮次切换和语音回应时才启动
gpt-realtime-2。 - 记录会话元数据:用户音频时长、助手音频时长、Response 次数、工具调用、是否开启输入转录。
- 只有在产品和隐私策略需要时,才保存或导出 transcript。
- 把通话后摘要、质检、合规分类、分析和搜索索引交给文本或转录优先路线。
- 每周抽样复盘,直到现场边界和后台边界都稳定。
例如,实时 onboarding agent 可以用 Realtime 完成关键沟通,再用更低成本的后处理生成 CRM 备注和质检记录。呼叫中心监控可以用实时转录给主管可见性,而不是让语音助手全程说话。语音笔记 App 可能完全不需要 Realtime,因为用户只是录音,稍后拿到准确文本和摘要即可。
混合方案的关键是定义“实时价值结束点”。只要现场互动结束,后续每一步都要重新证明自己为什么还需要实时语音。这样预算会沿着产品价值分布,而不是沿着技术兴奋点分布。
预算工作表
做预算时至少跑三组估算:纯转录、Realtime 媒体 token 底线、完整管道。先用官方价格行填锚点,再用真实试点数据替换占位数。
| 工作表行 | 公式 |
|---|---|
| 实时转录成本 | live_audio_minutes * $0.017,对应 gpt-realtime-whisper |
| 高准确录音转写成本 | audio_minutes * $0.006,对应 gpt-4o-transcribe |
| 低成本录音转写成本 | audio_minutes * $0.003,对应 gpt-4o-mini-transcribe |
| Realtime 用户音频底线 | user_audio_hours * $1.152,对应 gpt-realtime-2 音频输入 |
| Realtime 助手音频底线 | assistant_audio_hours * $4.608,对应 gpt-realtime-2 音频输出 |
| Realtime 媒体 token 底线 | user_audio_floor + assistant_audio_floor |
| Realtime 会话估算 | media floor + text tokens + tool tokens + history growth + optional input transcription |
| 完整管道估算 | STT + text model + optional TTS + telephony + storage + monitoring + QA |
用低、中、高三组使用量跑这张表。Realtime 里优先改变助手语音时长和 Response 次数,因为它们经常比用户讲话时长更能暴露毛利风险。转录优先路线里,优先改变音频时长、文本模型输出长度、重试率、存储留存和人工复核比例。
上线前至少采集这些证据:中位和 p95 用户音频时长、中位和 p95 助手音频时长、每会话 Response 数、后半段上下文大小、是否启用输入转录、工具和后处理文本 token、失败或重试会话、人工复核分钟数,以及上线当天的 OpenAI 价格行。
价格在发布日必须重查。模型 ID、分钟价格、token 价格、账号权限、地区可用性和产品限制都可能变化,旧计算器很快会过期。
常见问题
Realtime API 一定比转录管道贵吗?
不一定。Realtime 语音代理通常有更高的成本底线,但如果实时语音互动能带来完成率、转化或人工节省,它可能是正确支出。文本交付物则通常从转录优先开始更便宜,也更容易预算。
gpt-realtime-whisper 和 gpt-realtime-2 是一回事吗?
不是。gpt-realtime-whisper 面向实时转录,只产生文字流;gpt-realtime-2 是实时语音代理路线,支持语音互动、工具调用和助手语音输出。把它们都叫 Realtime API,会造成错误的成本比较。
为什么不能把 $5.76/hour 叫做 Realtime 小时价?
因为它只是媒体 token 底线:一小时用户音频输入加一小时助手音频输出。它没有包括文本 token、历史增长、工具、输入转录、电话线路、存储和后台管道。最终预算必须用真实会话数据填充。
实时字幕应该用哪条路线?
先看实时转录路线。产品只需要边说边出文字时,gpt-realtime-whisper 更贴近任务。如果音频可以等录制结束再处理,继续比较 gpt-4o-transcribe 和 gpt-4o-mini-transcribe。
自建 STT -> LLM -> TTS 管道一定更省吗?
不一定。它可能更适合文本中心、合规、电话集成和组件控制,但会增加延迟、编排和维护成本。如果用户体验依赖自然打断和高质量语音回应,原生 Realtime 会话可能更合适。
最安全的生产规则是什么?
先选路线,再用当前官方价格行锚定 OpenAI 直接计价部分,把其余组件标为变量,并用真实试点数据验证。文本足够时不要支付语音助手输出,也不要把媒体 token 底线当成最终账单。