OpenAI API 429 先不要当成“多试几次”的问题。它更像一个分流信号:你的请求可能撞到了请求速率、token 速率、quota 或计费状态、project 或 model scope,或者你根本把 ChatGPT / Codex 这类产品面的限制误当成了 OpenAI Platform API 的限流。真正更快的处理顺序是先读 owner,再读 reset,再做最小修复动作。
很多中文教程会把 429 直接写成“加 sleep”“充钱”“换 key”“换中转”四选一,但这四个动作分别对应的是不同 owner。请求过快时,sleep 和退避是对的;quota 或 billing 有问题时,单纯退避不会解决;scope 用错时,买 credits 和换 key 都是偏题;如果问题根本属于 ChatGPT 或 Codex 产品窗口,那你甚至已经在错误的产品面里排错。
先记住一条最实用的 operator 规则:看 response headers、对照 Limits 页面、选最小修复动作。不要先做破坏性大的动作。
TL;DR
| 问题 | 最短答案 |
|---|---|
| OpenAI API 429 一般表示什么? | 当前 API 路由撞到了 requests、tokens、quota、billing、scope 或 reset-window 的边界。 |
| 第一件事看什么? | 先看 x-ratelimit 相关响应头,再去账号里的 Limits 页面核对。 |
| 最常见的技术 owner 是谁? | 请求过快、并发过高、token 预算太大、短时间 burst。 |
| 最常见的非代码 owner 是谁? | quota 不足、billing 状态异常、trial 结束、项目范围不对。 |
| 提额前该先做什么? | 降并发、指数退避、缩 prompt / 输出、把非实时任务移到队列或 Batch API。 |
| 最不该先做什么? | 盲目重试、换 key、把 credits 当吞吐、把 ChatGPT / Codex 限制当成 Platform API 限流。 |
先找 owner,不要先写重试循环
大多数排错时间并不是浪费在“不知道什么叫 rate limit”,而是浪费在把所有 429 当成同一种问题。OpenAI 官方的 rate limits guide 给出的真实合同并不神秘:你的账号有 live limits,usage tier 会影响 headroom,响应头会告诉你剩余量和 reset,缓解动作应该从 backoff 和 traffic shaping 开始。
这意味着真正应该先问的问题不是“OpenAI API 的限流是多少”,而是“这次请求到底撞到了哪一个 owner”。请求速率问题和 token 速率问题都可能返回 429,但修法不同。quota 或 billing 问题看起来也像 rate limit,可它不会被 sleep 真正修好。项目、组织、模型或 endpoint 路由错了时,表面也是 429 或类似的容量报错,但根因其实是 scope。
把顺序写得更直接一点:
- 看 owner。
- 看 reset 信号。
- 做最小修复。
- 只有在路由正确、证据稳定之后,才谈提额。
如果你真正困惑的是 project、organization 或 API key scope,应该转去看 OpenAI API Key 和 Organization ID。如果你其实是在排 Codex 或消费产品窗口,正确的兄弟页是 OpenAI Codex usage limits 和 Codex API key vs subscription,而不是继续把一切都写成 Platform API 429。
OpenAI rate limits 真正在量什么
OpenAI 的一手文档并不是把限流写成一个固定数字,而是多个维度一起作用。对开发者最重要的是下面几层:
- Requests per minute:短时间请求次数太多。
- Tokens per minute:prompt 加输出的 token 体量太大,即使请求次数不算多,也会撞线。
- Usage tier:账号层级会影响 headroom。
- Live account limits:当前真正生效的 ceiling 在账号 Limits 页面,不在旧教程里复制出来的表格。
- Reset signals:响应头会告诉你多久后窗口重新打开。
这也是为什么“OpenAI 每分钟固定允许多少次请求”这种表格不适合作为主结论。它把 live account boundary 扁平化成了一个看起来永远不变的 universal number。更安全的做法是:用公开文档理解定义、headers、tiers、mitigation,用 Limits 页面理解你当前账号的真实 ceiling。
请求压力和 token 压力一定要分开看。RPM 问题通常来自并发太高、短循环、重试太密。TPM 问题常见于 prompt 太长、历史太厚、max output 过大,或者一批请求每个都 asking for too much output。如果你不分这两类,就会在 token 问题上只顾着降并发,或者在 burst 问题上只顾着砍输出。
还有一个很容易被忽略的点:就算按分钟平均值看起来没超,短时间 quantized burst 仍然可能触发限制。也就是说,“按纸面平均值我没超”并不能证明流量形状安全。
改代码前,先读 response
OpenAI Cookbook 和 rate-limit guide 其实都在强调同一件事:先读 response,再动手。因为失败的重试本身也会继续消耗预算。盲目重试会把一次限流事件打成一串 cooldown spiral。
最值得先看的 headers 包括:
- x-ratelimit-limit-requests
- x-ratelimit-remaining-requests
- x-ratelimit-reset-requests
- x-ratelimit-limit-tokens
- x-ratelimit-remaining-tokens
- x-ratelimit-reset-tokens
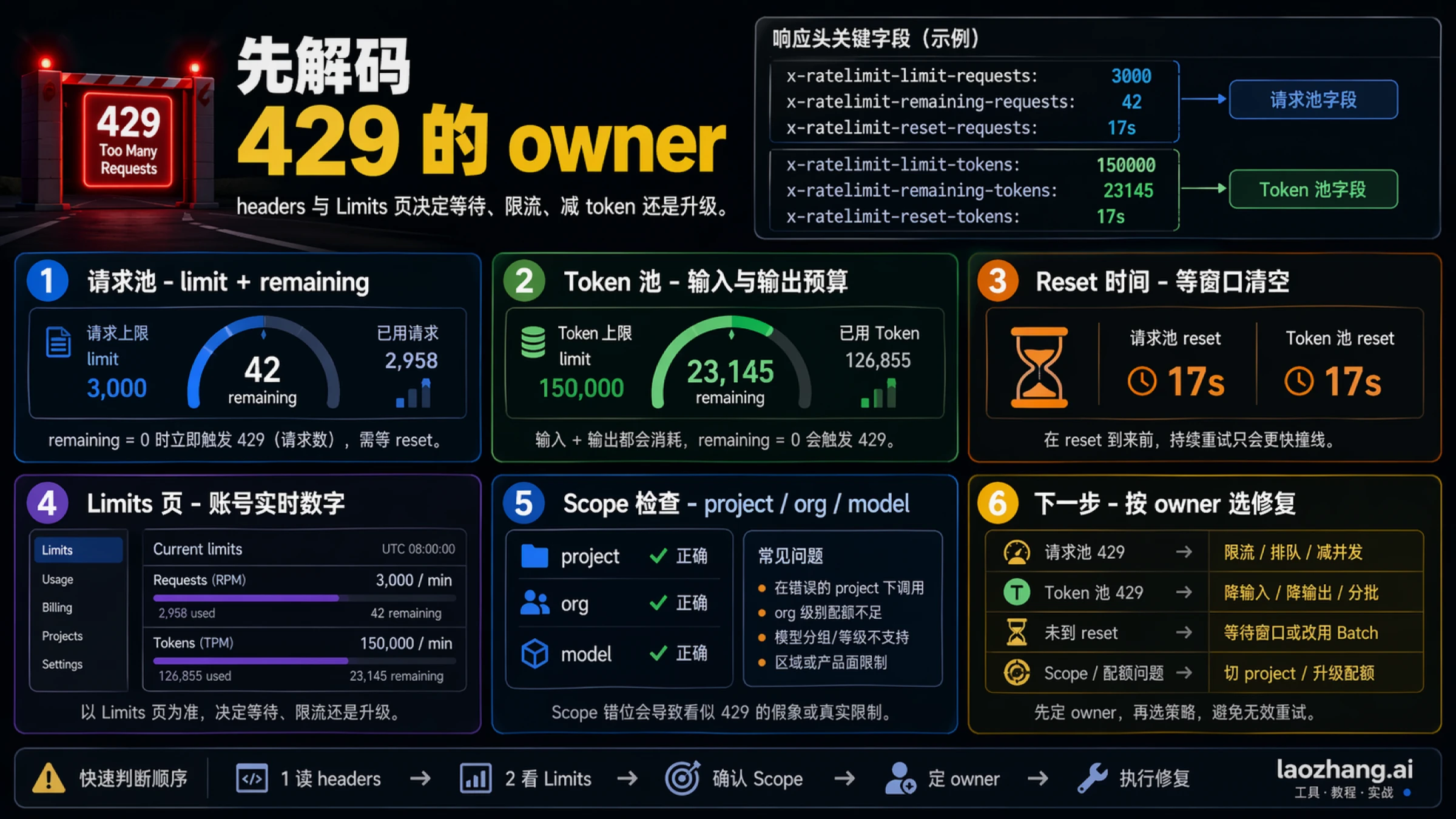
如果这些头存在,它们比 error message 本身更能决定下一步:
| 信号 | 它通常说明什么 | 第一动作 |
|---|---|---|
| remaining-requests 接近 0 | 请求频率或并发太高 | 降并发,平滑 burst,并加入 backoff |
| remaining-tokens 接近 0 | prompt 加输出体积太大 | 缩 prompt、缩输出、把任务分流 |
| reset 很短 | 路由大概率没错,只是窗口没开 | 等到 reset 再重试,外加 jitter |
| Limits 页面 headroom 很低 | 真正的 ceiling 在账号或路由层 | 先优化,再决定是否提额 |
| 头信息看起来正常但仍失败 | 可能是 scope、billing、wrapper 或 endpoint 问题 | 查 project、org、model 和产品面 |
实践里最有用的是把失败请求记成可比较的 incident evidence:状态码、错误体、endpoint、model、project / organization 上下文、以及 x-ratelimit 相关值。这样你比较的是证据,而不是记忆。
最小可用的判断逻辑长这样:
tsconst resetRequests = res.headers.get("x-ratelimit-reset-requests"); const resetTokens = res.headers.get("x-ratelimit-reset-tokens"); const remainingRequests = res.headers.get("x-ratelimit-remaining-requests"); const remainingTokens = res.headers.get("x-ratelimit-remaining-tokens"); const owner = remainingRequests === "0" ? "requests" : remainingTokens === "0" ? "tokens" : "unknown"; // 如果 request 和 token 两个窗口都重要,就按更晚的 reset 走。
第一版代码不需要完美。它只需要足够诚实,别让你走错分支。
先把 429 分成不同 owner
拿到 response 和 Limits 页面后,真正的工作是分类,而不是立刻 patch retry loop。
1. 请求速率 owner
这是最典型的 burst 问题。请求次数、并发或重试循环太激进,当前路由顶不住。常见表现是 remaining-requests 见底、reset 窗口很短,而且 workload pattern 明显集中。它的修法主要是 traffic shaping,不是充值。
2. Token 速率 owner
这类 owner 经常被漏判,因为请求次数看起来不多,但每次请求都太贵。长历史、超长 system prompt、max output 设得过大、没有约束 completion size,都可能把 TPM 先打满。这里最便宜的修法通常不是降并发,而是缩 prompt、缩输出、拆任务。
3. Quota 或 billing owner
如果账号可用额度不够、billing 状态异常、trial 已结束,单纯 backoff 没什么意义。你这时面对的不是每分钟窗口问题,而是 account availability 问题。真正要做的是去核对 credits、billing method、trial state。如果你的问题其实是 credits 或试用边界,应该转看 OpenAI API free trial。
4. Project、organization 或 model scope owner
请求语法没错,不代表路由就对。不同 project、不同 organization、不同 model 可能有不同的 limit profile 或访问权限。复制一份“以前能跑的配置”到新环境,结果撞的往往不是吞吐问题,而是 scope。
5. 错产品面 owner
这是现实里最浪费时间的一类:把 OpenAI Platform API、ChatGPT、Codex,或者某个 wrapper 的限制混成同一件事。ChatGPT 升级不会自动修复 Platform API 429。Codex 使用窗口不是 API throughput。某个兼容网关自己的限流,也不能直接当成 OpenAI 官方 ceiling。
这个区分不是概念洁癖,而是直接决定下一步该找谁。
用最小动作修流量,不要一上来就提额
知道 owner 以后,先做最小安全修复。OpenAI 的文档和 Cookbook 都更偏向 backoff with jitter,而不是立即重复 resend。
常见恢复梯子是:
- 路由没问题时,先等 reset。
- burst 明显时,先降并发。
- 给 retry path 加指数退避和 jitter。
- token 压力大时,缩 prompt 和预期输出。
- 非实时任务移到队列或 Batch API。
- 只有证据稳定之后,才申请更高 limits。

代码层面最大的误区,是把 backoff 写成装饰品。正确的 retry path 应该越失败越安静,而不是越失败越吵。一个最小模式可以长这样:
tsconst base = 500; // ms const max = 15000; for (let attempt = 0; attempt < 6; attempt += 1) { const wait = Math.min(max, base * 2 ** attempt); const jitter = Math.random() * 0.25 * wait; await sleep(wait + jitter); }
对 TPM 压力来说,控 token 往往是最便宜的修法。把 max output 调回真实需要值,缩短历史,去掉无用上下文。如果工作是后台批处理,优先考虑队列或 Batch API,不要把一切都硬塞在同步路径里。
只有证据稳定了,才谈更高吞吐
很多团队提额提得太早。这样既掩盖了架构问题,也浪费沟通成本。真正应该升级到提额阶段的前提至少包括:
- 路由是对的;
- billing 是健康的;
- owner 已经确定;
- retry 已经被约束;
- prompt 和输出预算已经合理;
- 任务仍然确实需要更高 sustained capacity。
这时 usage tier 和 limit increase request 才有意义。公开文档会告诉你 tiers 和 increase path 的基本逻辑,但你自己的 Limits 页面才是实际入口。
提额前最好准备好一包证据:
- 具体 model 和 endpoint;
- 观测到的 request / token 压力;
- reset 行为;
- 并发特征;
- 你已经做过的优化;
- 为什么队列或 Batch API 仍然不够。
这样做有两个好处。第一,它能支持正式提额请求。第二,它能防止团队在根因还没搞清时就把“加资源”当成默认答案。
Stop rules
下面几件事太常见,也太容易把排错带偏,值得单独列成 stop rules。

不要默认先做这些:
- 换 key。只要 owner 还是同一个账号、project 或 route,key rotation 通常不是修复。
- 不核对吞吐就先买 credits。credits 也许能解决 quota 或 billing,但不会自动抬高 RPM / TPM。
- 升级 ChatGPT 或 Codex 套餐来修 API 限流。它们不是同一张合同。
- 复制旧教程里的固定数字当成当前 ceiling。live limits 属于 Limits 页面。
- 什么都不看就盲重试。失败重试会继续消耗预算。
更稳的心智表是:
| 如果问题属于 | 下一步该做什么 |
|---|---|
| Request burst | 降并发,平滑流量,加 jitter |
| Token pressure | 缩 prompt 和输出规模 |
| Reset 很短 | 按 reset 等待,再安全重试 |
| Billing 或 quota | 修账号状态 |
| Project / model scope | 纠正 scope 和路由 |
| 非 API 产品限制 | 离开这篇 API 文章,去正确产品面排错 |
最后这一行非常关键。如果你的真实问题其实是“Codex / ChatGPT 为什么不让我继续跑”,那这篇就不是你的 runbook。
FAQ
OpenAI API 429 到底表示什么?
它表示当前 API 路由撞到了 requests、tokens、quota、billing、scope 或 reset-window 其中之一。先把它当分类问题,而不是统一重试问题。
当前准确的 OpenAI API limits 在哪里看?
在账号里的 Limits 页面。公开文档负责解释概念、headers 和 tier 逻辑,真正的 live ceiling 以你的账号界面为准。
Credits 会不会自动提高吞吐?
不会。credits 只在 owner 真的是 quota 或 billing 时才相关。它不会自动抬高请求速率或 token 速率 ceiling。
ChatGPT Plus、Pro 或 Codex 订阅能修 Platform API rate limit 吗?
不能。消费产品和 Codex 产品窗口,跟 OpenAI Platform API throughput 是不同合同。
Batch API 什么时候值得上?
当任务不需要实时响应时。只要不是必须同步返回,Batch API 或队列通常比把一切都堆在实时请求里更合理。
什么时候才该申请更高 limits?
当你已经确认路由正确、billing 健康、retry 受控、token 预算合理,而且 workload 仍然确实需要更高 sustained capacity 的时候。
实际结论
处理 OpenAI API rate limits 最快也最诚实的办法,不是“多试几次”,也不是“先升级点什么”。而是先确认 429 的 owner,读 reset 信号,再做最小修复动作。requests 问题就平滑流量,tokens 问题就缩 payload,billing 或 quota 问题就修账号,scope 问题就回到正确 project / model / endpoint,非实时任务就别硬塞在同步路径里。