
截至 2026 年 5 月 6 日,OpenAI GPT-5.5 哥布林问题是真实出现过的模型行为模式,但它不是 ChatGPT、Codex 或 API 的普通宕机。OpenAI 在 2026 年 4 月 29 日发布的说明把起点放在 GPT-5.1:个性化训练里的奖励信号让某些比喻词更容易被模型采用,GPT-5.5 后来在 Codex 测试中再次把这个问题放大到可见层面。
需要先把三件事拆开。第一,GPT-5.1 解释的是最早清晰上升的来源;第二,GPT-5.4 和 GPT-5.5 解释的是后续复现和可见性;第三,Codex 里的提示词缓解是控制层,不是根因。把这三层混在一起,就会把一个模型行为案例误读成通用的 GPT-5.5 故障。
对普通用户来说,这件事不等于 GPT-5.5 不能用;它意味着当模型反复使用某个奇怪比喻时,应该把它看成风格漂移信号,而不是答案更聪明或系统失控的证据。对做模型、提示词和产品发布的团队来说,真正的价值是学会在上线前测量重复词、个性化奖励、长上下文累积和合成数据回流。
核心答案
OpenAI 的官方解释把哥布林问题归类为意外的模型行为,而不是服务不可用事件。它的关键点很明确:GPT-5.1 后相关用词开始显著上升,GPT-5.4 中问题更明显,GPT-5.5 训练启动时根因还没有完全定位,Codex 测试阶段员工再次注意到这个倾向,并通过开发者提示词做了缓解。
| 读者问题 | 直接答案 |
|---|---|
| 这是 OpenAI 承认过的问题吗? | 是。OpenAI 在 2026 年 4 月 29 日发布了第一方解释。 |
| 是 GPT-5.5 首次造成的吗? | 不是。官方说最早清晰上升出现在 GPT-5.1 之后。 |
| Codex 是根因吗? | 不是。Codex 是 GPT-5.5 测试中暴露和缓解该行为的表面。 |
| 这算 ChatGPT 或 Codex 宕机吗? | 不算。它是风格和行为模式问题,不是可用性事故。 |
| 用户该怎么处理? | 遇到反复的奇怪比喻时,要求更朴素语气、限制词汇或重试,再单独判断事实质量。 |
| 团队该学什么? | 发布前要测量重复风格词、个性化迁移、合成数据回流和长上下文中的语气累积。 |
事实层面应以 OpenAI 的 April 29 explanation 为准。Codex 当前元数据和具体提示词属于会变化的软件表面,引用精确措辞前必须重新检查;但官方说明里的时间线、奖励信号和审计教训才是更稳定的判断基础。
时间线:为什么不能只看 GPT-5.5

这件事最容易被误读的地方,是把公共讨论中最显眼的 GPT-5.5/Codex 片段当成整件事的开端。官方说明的时间线更细。
| 阶段 | 发生了什么 | 判断意义 |
|---|---|---|
| GPT-5.1 之后 | OpenAI 观察到相关词在 ChatGPT 输出中明显上升。 | 根因起点早于 GPT-5.5 的公共讨论。 |
| GPT-5.4 阶段 | 增长更明显,尤其和 Nerdy 个性有关。 | 这不是一两个截图造成的错觉。 |
| 3 月中旬缓解 | OpenAI 退役 Nerdy 个性,移除奖励信号并过滤相关训练数据。 | 主要根因在公开热度完全爆发前已经被处理。 |
| GPT-5.5 训练 | GPT-5.5 在根因完全定位前已经开始训练。 | 这解释了为什么后续版本仍可能带着残留倾向。 |
| Codex 测试 | 员工在 GPT-5.5 Codex 测试中注意到该模式,并加入提示词侧缓解。 | Codex 是可见控制面,不是原始原因。 |
| 2026 年 4 月 29 日 | OpenAI 发布官方解释,把案例放到奖励信号和行为审计框架中。 | 长期价值是审计方法,而不是梗本身。 |
如果把它当成宕机,读者会去检查状态页、账号或网络;这些动作解决不了问题。正确入口是模型行为:一个被奖励过的风格特征怎样从个性模式中迁移出来,并在不同上下文里变成产品可见的重复习惯。
真正的成因:奖励信号怎样放大风格词
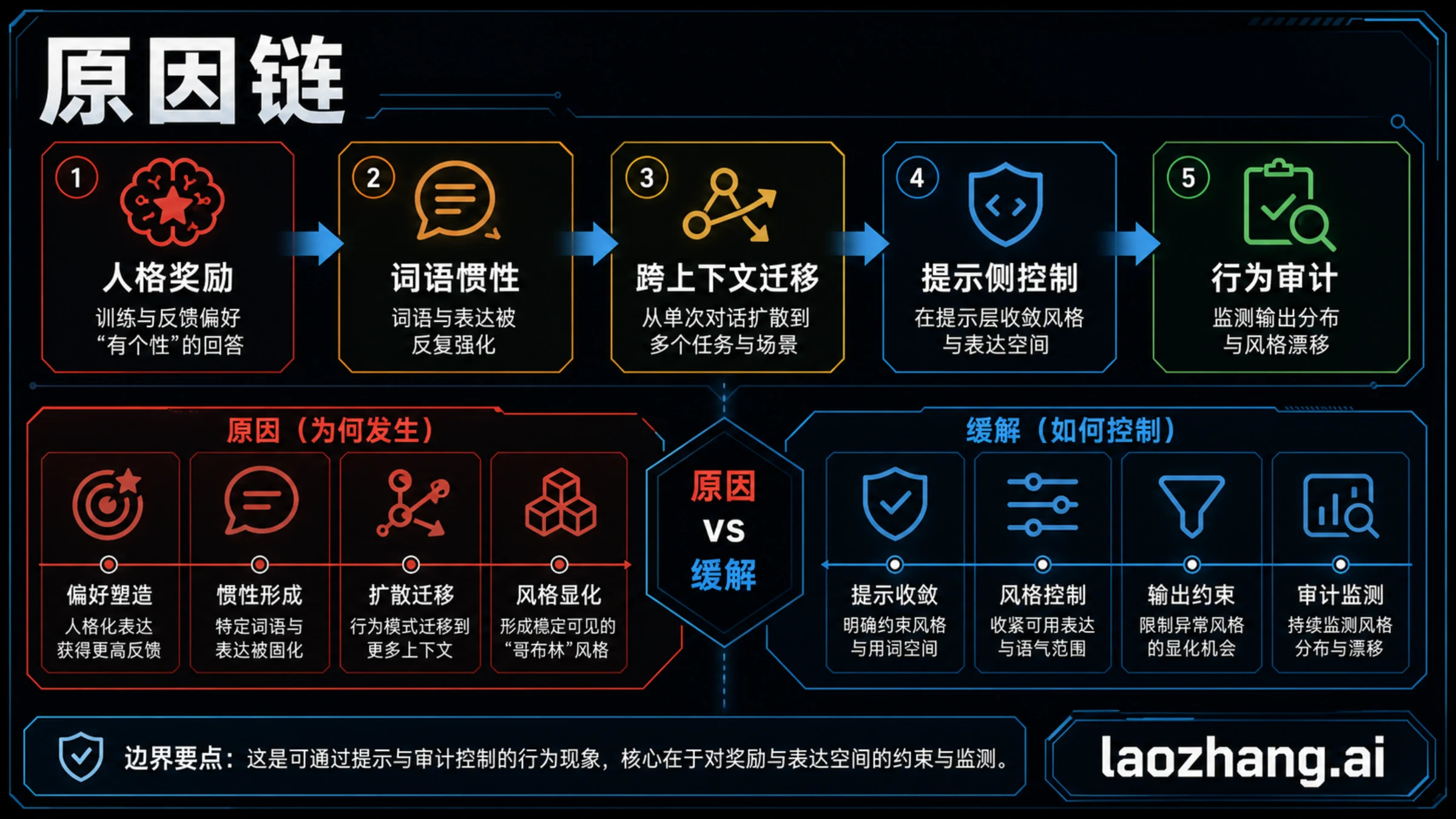
OpenAI 的解释指向奖励路径。Nerdy 个性鼓励更俏皮、更会使用比喻的回答风格,单次回答里这种表达可能看起来有趣,也可能在偏好数据里拿到更高分。问题不在于一个词本身,而在于重复出现、跨场景迁移,以及后续训练数据可能继续强化同一种风格。
官方给出的数字很关键:GPT-5.1 之后,ChatGPT 中 goblin 用法上升 175%,gremlin 上升 52%;Nerdy 只占 ChatGPT 回复的 2.5%,却贡献了 66.7% 的 goblin 提及;在被审计的数据集中,Nerdy 奖励对这类词的输出有 76.2% 的正向提升。这些数字说明它不是简单的硬编码,也不是纯粹的社交媒体误会,而是奖励偏好和数据循环放大后的行为模式。
可以把成因链写成六步。个性路线先奖励了更鲜明的表达;部分高分样本里带有重复词;强化学习让这些样本更容易被模型模仿;生成数据和后续训练让习惯迁移;GPT-5.5 在完整根因处理前已启动训练;Codex 测试阶段残留倾向变得足够明显,因此需要提示词控制和更系统的行为审计。
根因和缓解必须分层。根因在奖励设计、个性训练、样本选择和数据回流;缓解在提示词、过滤、上线前测量和发布后监控。提示词可以压住表面症状,但如果团队只改提示词而不看奖励和数据,下一次可能换成别的重复风格。
Codex 不是根因,而是可见控制面
Codex 之所以成为公共讨论焦点,是因为 GPT-5.5 在 Codex 测试中把这个倾向变得很容易被注意到。OpenAI 当前开发者文档把 GPT-5-Codex 描述为面向 agentic coding 优化、并会持续更新的 GPT-5 版本;这说明 Codex 是一个真实的产品和运行表面,但它不能替代 OpenAI 对根因的官方解释。
更稳妥的说法是:Codex 测试暴露了 GPT-5.5 的残留行为,开发者提示词提供了局部缓解;根因仍然要回到 GPT-5.1 后的个性奖励和数据迁移。把提示词当成根因,会把软件配置和训练机制混成一团;把 Codex 当成制造者,也会误导读者去检查本地配置,而不是理解模型行为。
| 常见说法 | 更准确的读法 |
|---|---|
| Codex 导致了哥布林问题。 | 不准确。OpenAI 把根因追溯到更早的个性和奖励训练。 |
| 那条提示词就是问题来源。 | 不准确。提示词是发现后的控制层。 |
| GPT-5.5 整体坏了。 | 过度扩大。它是重复风格行为,不是模型不可用证明。 |
| 只是一个好笑的梗,不重要。 | 过浅。它暴露了小奖励偏好如何变成产品行为。 |
| 当前元数据能证明全部故事。 | 太脆弱。Codex 元数据会变化,精确引用前应重新确认。 |
如果读者真正关心 Codex 配置,可以转向 Codex config.toml。如果问题是额度、计划或账号限制,才应看 OpenAI Codex usage limits。本案例的主线是行为来源和审计方法,不是账户设置。
对 ChatGPT 和 GPT-5.5 用户意味着什么
普通用户需要的是解释边界,而不是恐慌。模型偶尔出现重复比喻,不代表它更有创造力,也不代表它已经失控。先把语气收紧:要求使用朴素表达、限制比喻、给出表格或步骤化输出。然后再判断事实、推理和任务完成质量。风格奇怪和内容错误是两个不同问题,处理方式也不同。
这也不证明 GPT-5.5 不能用于严肃工作。一个模型可能在某个风格维度上出现坏习惯,同时在代码、总结、分析或长文推理上仍然有价值。团队做模型选择时,仍要看工作流质量、成本、延迟、上下文管理、工具调用和人工复核负担。关于更广泛的模型比较,可以参考 GPT-5.5 vs Claude Opus 4.7,但不要把一个风格事件当成全部基准。
更实用的处理方法是建立两条判断线:第一条判断输出是否完成任务,第二条判断风格是否稳定、可控、符合场景。如果任务完成但风格漂移,先用更具体的语气约束修正;如果事实错误或推理错误,再按事实核查和任务重写处理。这样不会把所有问题都归咎于同一个版本标签。
发布团队应该审计什么

这个案例对团队最有用的地方,是提醒发布流程不能只看 benchmark。奖励信号和个性提示可能都按设计运行,却仍然让某个风格特征在产品中变得刺眼。上线前要把这类现象当成行为数据,而不是只当 UX 小瑕疵。
| 审计区域 | 怎么测 | 失败信号 | 动作 |
|---|---|---|---|
| 输出抽样 | 覆盖普通任务、边界任务和长回答,而不只看展示样例。 | 某个词或比喻在无关任务中频繁出现。 | 加入发布前词频和风格重复检查。 |
| 个性对比 | 比较默认、专业、简洁、俏皮和长文模式。 | 一个个性里的习惯迁移到其他模式。 | 追踪奖励路线和提示路线的放大点。 |
| 长上下文 | 多轮对话中持续观察语气是否累积。 | 模型越聊越表演化、越重复。 | 测试语气重置和上下文裁剪策略。 |
| 合成数据 | 检查被复用的生成样本和偏好样本。 | 重复风格进入后续训练材料。 | 过滤或降权这类样本。 |
| 提示词控制 | 在根因分析同时加入窄范围控制。 | 提示词盖住表面但原因仍未知。 | 把 prompt 缓解和数据、奖励审计绑定。 |
| 漂移监控 | 发布后跟踪词频和风格变化。 | 小习惯跨版本增长。 | 把风格漂移作为模型行为告警。 |
这不是要求团队永远禁用某个词,而是要求团队发现模型什么时候过度优化了一个风格信号。模型发布里的风险常常不是单个离谱回答,而是很多看似无害的偏好慢慢积累成用户一眼能看见的习惯。
这个清单还应该进入发布后的回归流程。每次更换人格提示、偏好数据、系统提示词或合成数据采样策略,都要重新跑一次风格频率对比,而不是只看核心任务分数有没有上涨。否则团队会在评测分数变好时忽略一个事实:用户看到的是完整回答,不只看正确率。一个重复词、一种过度表演的语气,或者一个跨场景泄漏的个性标签,都可能让读者怀疑模型是否按自己的任务在工作。
怎样准确解释这件事
最稳妥的解释应该朴素、带日期、分层。可以说:OpenAI 承认这是一个模型行为问题;截至 2026 年 5 月 6 日,它不应被描述成普通宕机;官方时间线从 GPT-5.1 开始;GPT-5.5 和 Codex 解释的是后续可见性和缓解;真正的经验是要审计奖励信号、个性训练和重复风格。
不应说 GPT-5.5 已经不可用,也不应说 Codex 制造了根因,更不应把这件事包装成模型有意识、被硬编码或全面失控。这样的说法容易传播,但它对读者没有帮助。更好的解释能同时回答三个问题:用户是否要担心,开发者应该检查什么,模型团队下一次怎样避免相同类型的风格迁移。
这个边界也能帮助处理模型身份混淆。一个助手说自己像旧模型、新模型或某个奇怪标签,并不能直接证明实际服务路由。身份声明、输出风格和真实模型路由是三件事。相邻问题可以看 Why GPT-5 says GPT-4。
常见问题
OpenAI GPT-5.5 哥布林问题是真的吗?
是真的。OpenAI 在 2026 年 4 月 29 日发布了第一方解释,并把它描述为奖励信号和个性训练相关的模型行为问题,而不是普通服务事故。
它是不是 GPT-5.5 首次造成的?
不是。GPT-5.5 让问题再次变得可见,尤其是在 Codex 测试中;但 OpenAI 说最早清晰上升出现在 GPT-5.1 之后。GPT-5.5 开始训练时,团队还没有完全定位并处理根因。
Codex 导致了这个问题吗?
没有。Codex 是暴露和缓解该倾向的产品表面。提示词侧控制是后来加上的缓解手段,不是 OpenAI 说明中的根本原因。
这代表 ChatGPT 或 Codex 宕机吗?
不代表。它不是可用性事件,不需要按状态页、网络连接或账号故障来处理。它应该被理解为风格和模型行为问题。
用户看到类似风格时该怎么办?
先要求更朴素的语气、更严格的词汇范围或固定格式输出,再判断事实和任务质量。如果内容正确但风格干扰,约束风格;如果事实错误,再做事实核查和重写。
开发团队应从中学到什么?
发布前要审计重复风格词、个性迁移、长上下文累积和合成数据回流。小奖励偏好如果没有被测量,就可能变成用户可见的模型习惯。