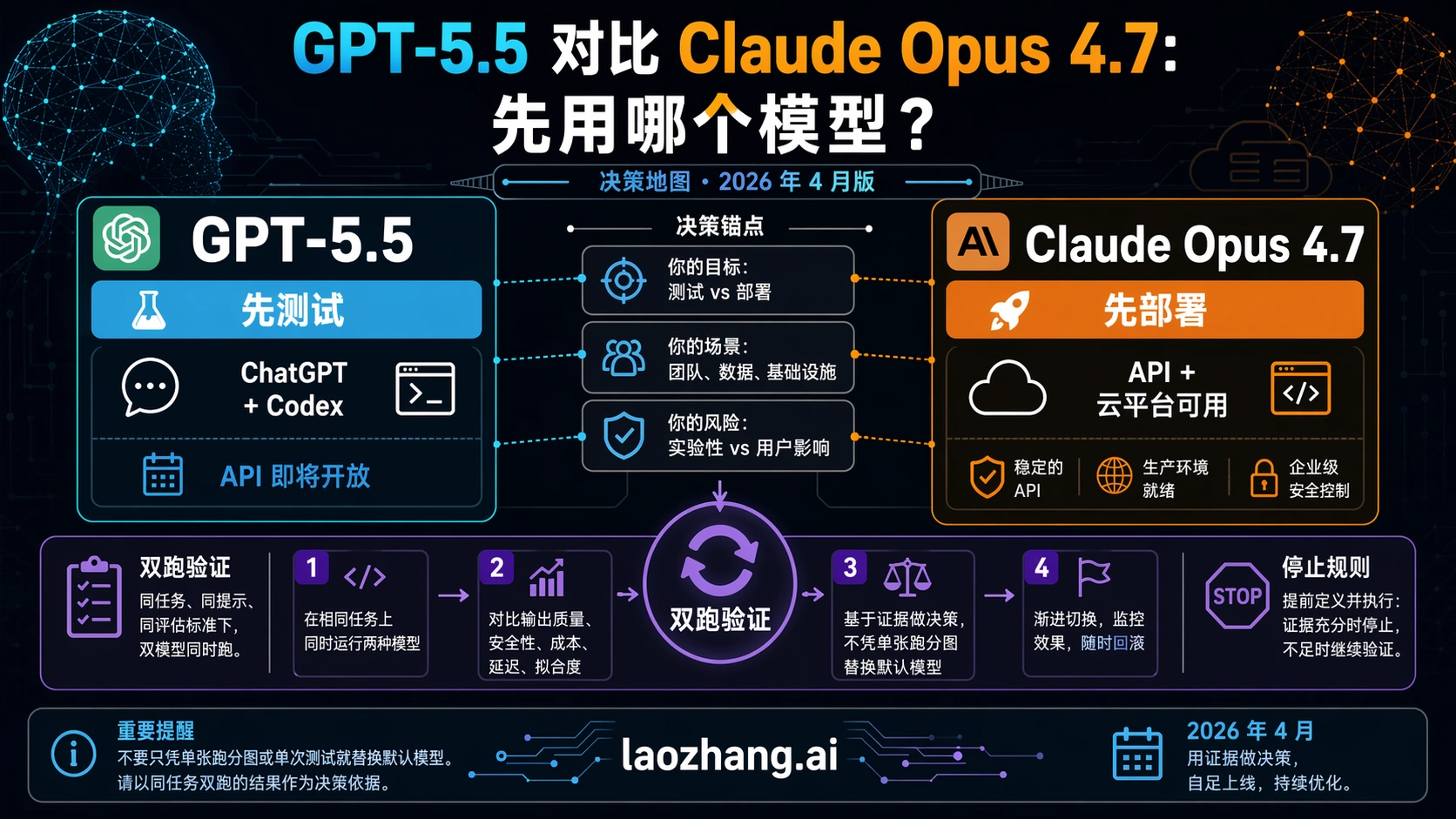
GPT-5.5 和 Claude Opus 4.7 现在不是一个完全对称的 API 选择题。截至 2026 年 4 月 24 日,GPT-5.5 已经进入 ChatGPT 和 Codex 这类 OpenAI 付费使用面,但 OpenAI API 仍然是即将开放;Claude Opus 4.7 则已经能通过 Anthropic API、Amazon Bedrock、Google Vertex AI 和 Microsoft Foundry 进入生产评估。
所以先别问“谁赢”。更有用的问题是:你的工作现在跑在哪条路线。OpenAI 原生的 ChatGPT、Codex、人工审查和代码试验,可以先测 GPT-5.5;今天就要服务端 API、云端 endpoint 或企业部署,先让 Claude Opus 4.7 进入评估;如果要替换一个已经赚钱或承载客户工作的默认模型,两边必须在同一批任务上双跑。
| 使用路线 | 先做什么 | 为什么 | 停止规则 |
|---|---|---|---|
| ChatGPT 或 Codex 测试 | 先测 GPT-5.5 | 它是 OpenAI 当前推向专业工作和 agentic coding 的最新路线,而且这些面已经可用。 | 不要在 OpenAI API 正式开放前规划生产迁移。 |
| 生产 API 或云端部署 | 先测 Claude Opus 4.7 | 它已经在 Anthropic API 和主流云平台可调用。 | 不要只凭一张发布周跑分表就替换高风险默认模型。 |
| 输出量大或预算敏感 | 用真实 prompt 同时算价 | GPT-5.5 API 标价是即将开放的每百万输入 5 美元、输出 30 美元;Opus 4.7 已上线价格是输入 5 美元、输出 25 美元。 | 批处理、缓存、地区、tokenizer 和重试成本没有复查前,不批准预算。 |
| 替换现有默认模型 | 先双跑 | 替换价值取决于失败率、人工审查时间和回滚成本,不取决于热搜里的第一名。 | 同仓库、同 prompt、同工具预算、同验收测试之前,不换默认。 |
快速答案
如果只需要操作结论,不要先看模型名,先看路线。
| 你的需求 | 先用哪一个 | 关键理由 | 需要复查 |
|---|---|---|---|
| 主要在 ChatGPT、Codex 或 OpenAI 原生编码流程里工作 | GPT-5.5 | OpenAI 的 GPT-5.5 发布信息把它定位为更强的专业任务和 agentic work 路线,这些用户面已经开始可用。 | API 开放状态、模型 ID、生产限制和账号权限。 |
| 今天需要生产 API 或云端 endpoint | Claude Opus 4.7 | Anthropic 已经让 Opus 4.7 进入 Claude API、Bedrock、Vertex AI 和 Microsoft Foundry。 | 你自己的延迟、地区、限流、token 用量和部署约束。 |
| 输出很多,或者预算审批严格 | 先把 Opus 4.7 当作 live API 基线 | Anthropic live 价是输入 5 美元、输出 25 美元;OpenAI 对 GPT-5.5 的 API 价仍是 coming soon,输出标价 30 美元。 | 缓存输入、批处理折扣、地区倍率、tokenizer 差异和重试。 |
| 想规划 GPT-5.5 API pilot | 等正式 API 路线开放后再跑 | coming-soon 价格可以做预算预案,但不能当作今天可调用的生产 endpoint。 | 开始测试当天重新看 OpenAI 官方文档和价格页。 |
| 想替换一个已经工作的默认模型 | 双跑两边 | 发布周对比不能代表你的失败模式、人工审核负担和回滚成本。 | 同一批任务、同一组工具、同一验收脚本、同一成本口径。 |
这就是本文的主判断:GPT-5.5 不是“因为新所以直接替换”,Claude Opus 4.7 也不是“因为 API 已经可用所以永远更稳”。GPT-5.5 的第一价值是让 OpenAI 原生工作流立刻进入更强模型试验;Opus 4.7 的第一价值是今天就能把 API 和云平台放进真实部署评估。任何涉及钱、客户交付或自动化执行的替换,都要用同一批任务让模型自己证明。
可用性和价格是第一分叉
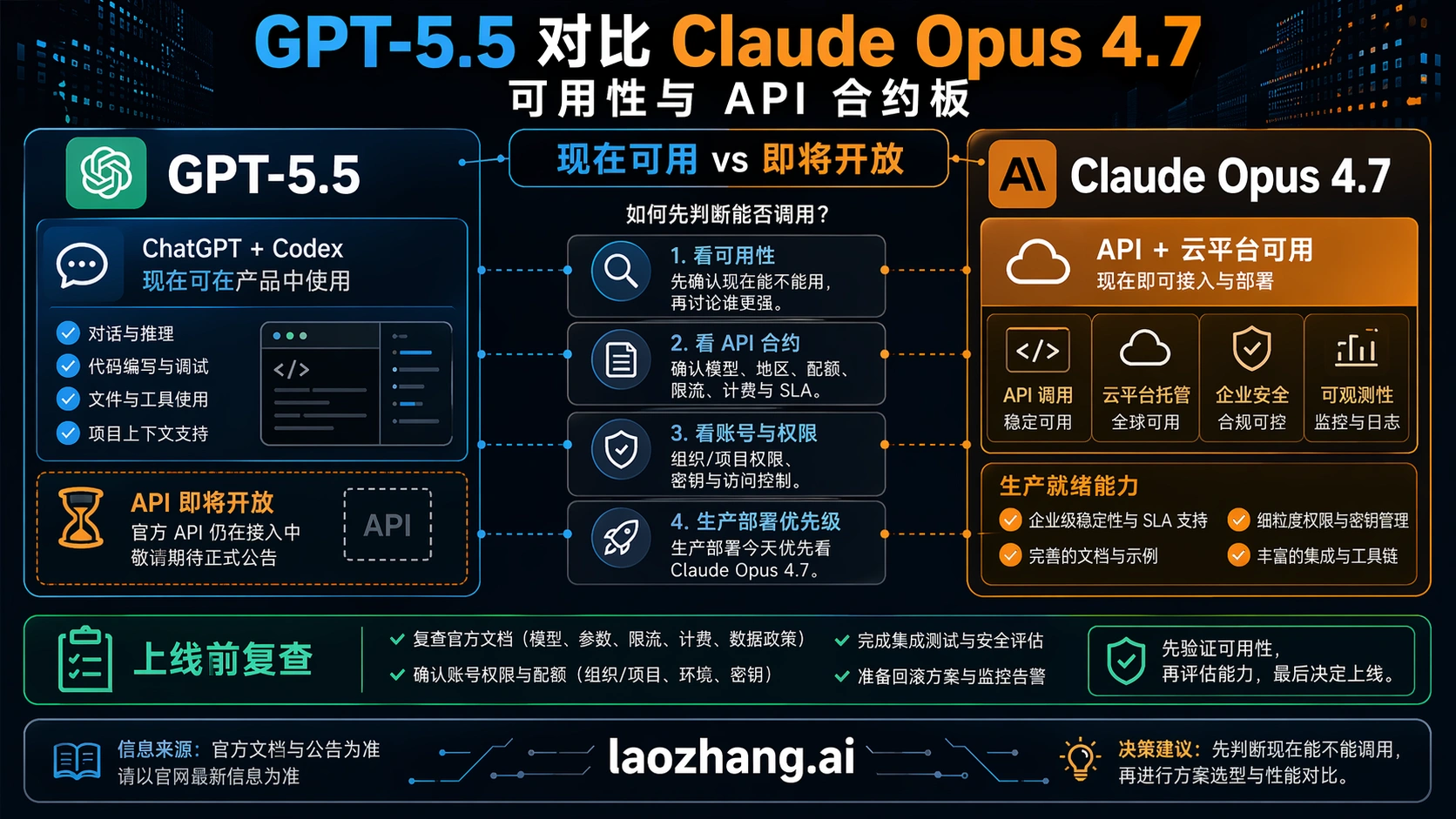
成本对比要从可用性开始。如果一个模型已经能在你需要的 API 路线里部署,另一个还停在 coming soon,那么第一步不是选跑分冠军,而是确认你能不能把它放进真实系统。
| 合约项 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 当前用户面 | OpenAI 发布信息显示,GPT-5.5 面向付费用户在 ChatGPT 和 Codex 中滚动开放。 | Anthropic 的 Opus 页面显示,Opus 4.7 已进入 Claude 产品。 |
| 2026 年 4 月 24 日的 API 状态 | API access coming soon。不要把价格表当成可调用 endpoint。 | Anthropic API 和主流云平台已经可用。 |
| API 模型 ID | 等 OpenAI API 正式开放后复查,不要自造模型名。 | Anthropic 模型概览列出 claude-opus-4-7。 |
| 标准 API 价格 | OpenAI 价格页列出的 coming soon 价是每百万输入 5 美元、缓存输入 0.50 美元、输出 30 美元。 | Anthropic 价格文档列出输入 5 美元、输出 25 美元,并支持缓存和批处理选项。 |
| 上下文和输出 | GPT-5.5 API 对你的账号开放后再复查。 | Messages API 中是 1M context 与 128k max output。 |
| 高端变体 | GPT-5.5 Pro 是未来高精度、高价格路线,不是多数团队今天的默认比较对象。 | Opus 4.7 已经是当前 premium Opus 路线。 |
这张表会直接改变默认动作。做生产集成的开发者今天可以把 Opus 4.7 放进 live evaluation path;想要 GPT-5.5 API 的团队应先保留评估 harness,等官方可调用路线开放后再跑,而不是把第三方截图、非官方模型 ID 或社媒消息写进部署计划。
输出价格也不能忽略。如果 GPT-5.5 API 按当前列出的价格开放,它的输出侧比 Opus 4.7 更贵。这个事实不等于 Opus 在每个任务上都更便宜,因为缓存输入、批处理、prompt 长度、tokenizer、失败重试和人工修改都会改变最终账单。但在输出密集型任务上,不能先假设新模型就是预算默认值。
跑分应该按工作负载理解

跑分表只有在贴近你的工作流时才有价值。发布方给出的 benchmark 是有用证据,但不是中立的万能判决书。实际决策中最容易把“某项领先”写成“全面碾压”,而工程决策需要拆开看:这是 Codex 任务、终端 agent、长上下文审阅、网页检索、安全任务,还是纯聊天?
| 报告中的 benchmark | GPT-5.5 公开结果 | Claude Opus 4.7 对照 | 实用读法 |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | 很适合推动 GPT-5.5 先进入 Codex 或终端型 OpenAI 工作流测试。 |
| GDPval-agentic | 84.9% | 80.3% | 对专业任务质量有参考价值,但仍要看你的领域审查流程。 |
| OSWorld-Verified | 78.7% | 78.0% | 接近到足以说明:部署路线和 harness 质量比单行分数更重要。 |
| BrowseComp | 84.4% | 以来源表格为准 | 可以当浏览和研究能力信号,不要直接当生产 API 决策。 |
| FrontierMath Tier 4 | 35.4% | 以来源表格为准 | 硬推理行适合纳入 pilot,不适合替代真实任务验收。 |
| CyberGym | 81.8% | 以来源表格为准 | 只有当你的安全类任务相似时才有较高迁移价值。 |
这些数字足以说明 GPT-5.5 值得在 agentic coding 和专业任务里认真测试。它们不足以支持“一键替换默认模型”。OpenAI 拥有发布时的跑分语境,Anthropic 拥有 Opus 的 API 合约,你的生产工作流才拥有最终裁决权。
最常见的错误,是把 live API 模型和 coming-soon API 模型当成同等可部署。若你在 ChatGPT 或 Codex 里选择先测谁,GPT-5.5 的这些行非常有价值。若你今天要把模型放在 API 后面服务客户,可部署性仍是第一过滤器,Opus 4.7 的合约更清楚。
编码和 agent 应该怎么选
当真实路线是 OpenAI 原生时,先用 GPT-5.5:ChatGPT 分析、Codex 代码工作、仓库编辑、终端任务、人工审查和 OpenAI 账号内的协作。此时问题不是“API 怎么接”,而是“GPT-5.5 能不能在我已经使用的工具里减少审查时间、处理更难任务、降低来回修改次数”。这个问题现在就能回答,因为这些 surface 已经可用。
当真实路线是 API-first、Claude-native 或 cloud-provider-first 时,先用 Claude Opus 4.7。Anthropic 当前材料强调 Opus 4.7 的编码、agent、长上下文、高分辨率图像和更高努力控制;更关键的是,路线已经可部署。如果你的系统需要服务端任务队列、账号权限、地区约束、日志、回滚和成本审批,live endpoint 比发布热度更重要。
公平的工程测试很直接:选十个已经消耗真实审查时间的任务;在 GPT-5.5 已可用的 OpenAI surface 跑一遍;用你会真正部署的 API 或云路线跑 Opus 4.7;记录首次正确率、工具恢复、格式稳定性、token 用量、延迟和人工审查分钟;最后只根据总工作量减少来决定,而不是根据第一印象或榜单排名。
如果测试主要是 repo edits、终端命令、Codex 任务和 OpenAI 内部协作,GPT-5.5 应该坐第一席。如果测试是生产 agent、长上下文资料处理、明确 API 预算、云上部署和受控 rollout,Opus 4.7 应该坐第一席。
上下文、输出和迁移风险
上下文和输出限制在短聊天里不明显,在长文档、代码库、审计、生成报告和 agent 循环里非常关键。Claude Opus 4.7 的 live contract 很清楚:Anthropic 文档列出 1M context 和 128k max output;价格文档还说明 Opus 4.7 在标准价格下包含完整 1M context。这个边界很重要,因为很多二级页面仍会混用旧的长上下文假设。
GPT-5.5 的 API context、rate limit、工具支持和生产限制,需要等你的账号拿到官方 API 路线后再复查。当前诚实写法是“计划中的 API 路线”或“即将开放的 API 价格”,不是“今天部署”。这不是措辞洁癖;生产迁移最容易出问题的恰好就是模型 ID、限流、上下文、工具能力和账单行为。
Opus 4.7 也不是无迁移风险。Anthropic 当前说明里,非默认 sampling 参数如 temperature、top_p、top_k 会返回 400;旧的 extended thinking budget 字段被移除;新 tokenizer 对固定文本可能多出约 35% token,取决于内容。这些不是拒绝 Opus 的理由,而是提醒你不要只改一个模型字符串就宣布迁移完成。
对长篇编码 agent、文档审阅和生产工作流来说,真正的问题不是“哪个模型上下文更大”,而是“哪条路线能装下上下文,产出足够长的结果,保持成本可控,并且在失败时能被系统恢复”。
如果你已经在用 GPT-5.4 或 Opus 4.7
如果你已经通过 API 使用 GPT-5.4,不要因为 GPT-5.5 发布就立刻拆掉。GPT-5.5 是新的 OpenAI 原生 pilot 路线,但在 GPT-5.5 API 对你的账号开放之前,GPT-5.4 仍是更清楚的 OpenAI API 基线。如果你的问题是 OpenAI、Anthropic、Google 三条路线谁更适合,旁边这篇 Claude Opus 4.7 对比 GPT-5.4 对比 Gemini 3.1 Pro 更适合处理三方默认选择。
如果你已经使用 Claude Opus 4.7,GPT-5.5 发布应该触发 pilot,而不是自动替换。只要 API 合约、云端部署和长上下文是你选择 Opus 的原因,就先保留 Opus 4.7 的生产路线;然后在 OpenAI 已开放的 surface 里测试 GPT-5.5,等 API 官方开放后再决定是否值得重开生产路线评估。
如果你的真实问题是 Anthropic 内部升级,而不是 OpenAI 与 Anthropic 的路线选择,请看更窄的 Claude Opus 4.7 对比 Claude Opus 4.6。那篇更适合处理同系列迁移、prompt 行为、token 漂移和成本变化。
实用切换计划
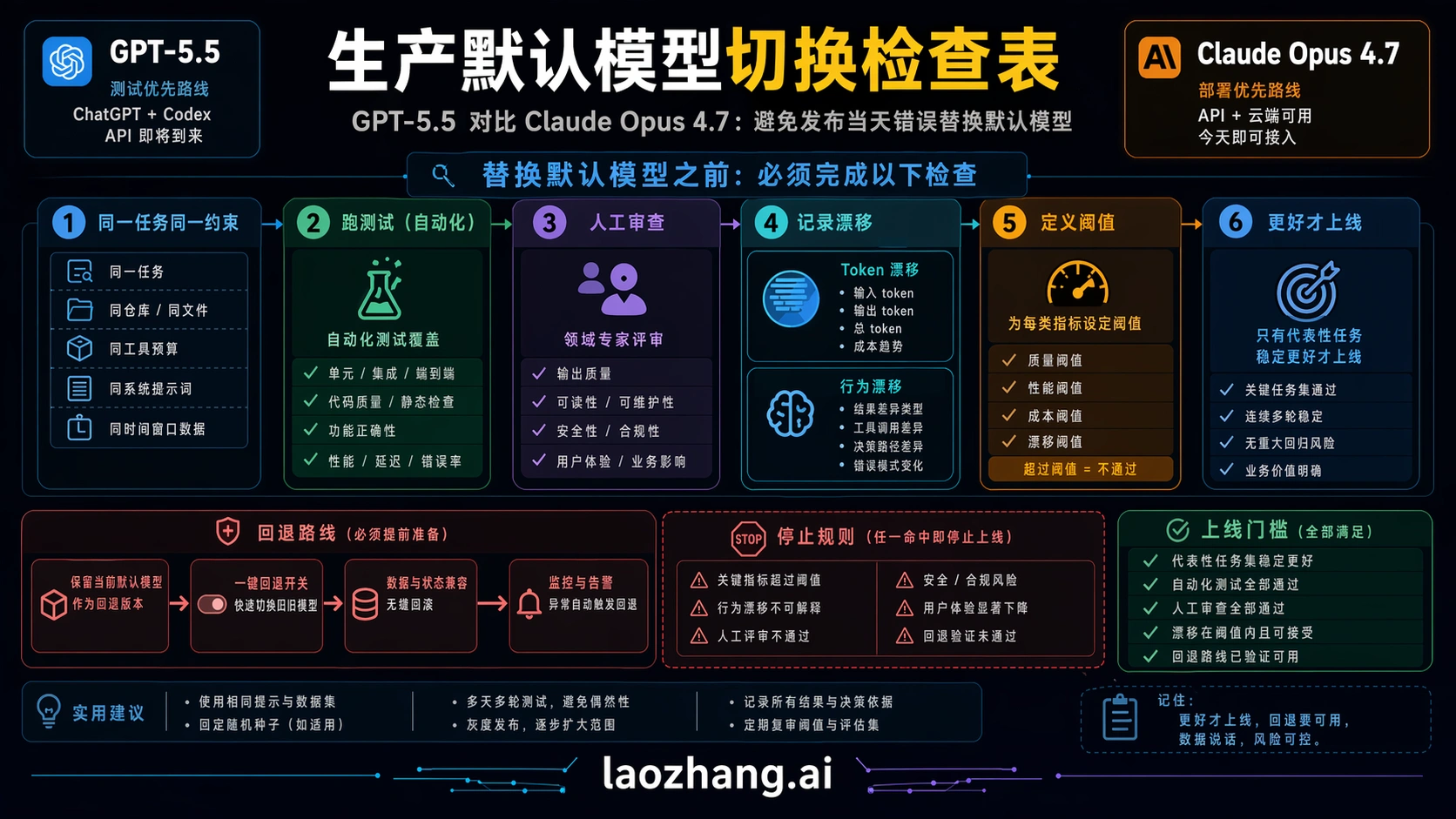
模型切换应该像发布一样管理。最小可用计划有六项。
| 检查项 | 怎么做 | 通过条件 |
|---|---|---|
| 路线检查 | 确认模型是否已经在你需要的 ChatGPT、Codex、API 或云路线里可用。 | 生产计划不依赖 coming-soon endpoint。 |
| 任务集合 | 选择代表性任务,不挑 demo。 | 包含简单、困难、长上下文、格式输出和高失败率任务。 |
| harness 对齐 | 在 surface 允许范围内用同 prompt、同工具、同文件、同预算运行两边。 | 差异来自模型行为,而不是一边的测试环境更好。 |
| 质量分 | 记录正确性、恢复能力、格式稳定性和人工审查分钟。 | 胜出模型减少总工作量,而不只是第一眼更好。 |
| 成本分 | 记录输入、缓存输入、输出、重试和任务级成本。 | 所选路线在真实工作负载下可支付。 |
| 回滚路线 | rollout 期间保留旧模型或 fallback route。 | 失败迁移可以撤回,不需要重建 pipeline。 |
小团队可以用一个下午完成一轮 disciplined test;企业流程应拆成 private pilot、shadow run、小流量生产、默认切换。阈值仍然一样:不要因为模型新而切换。只有它在真实工作上减少失败、时间或成本,才值得改变默认。
FAQ
GPT-5.5 比 Claude Opus 4.7 更好吗?
取决于路线和工作负载。OpenAI 原生的 ChatGPT、Codex、代码试验和人工协作,GPT-5.5 更适合作为第一测试对象。今天需要 live API 或云端 endpoint,Claude Opus 4.7 更适合作为第一部署对象。
GPT-5.5 API 已经可用了吗?
截至 2026 年 4 月 24 日,OpenAI 对 GPT-5.5 API 的公开表述仍是 coming soon。价格页可以用于预算规划,但不能当作今天已经可调用的生产证明。
哪个模型更便宜?
今天的 live API 部署里,Opus 4.7 的价格边界更清楚:每百万输入 5 美元、输出 25 美元,缓存、批处理和地区因素另算。OpenAI 列出的 GPT-5.5 coming-soon 价格是输入 5 美元、输出 30 美元,所以输出密集型任务必须等 API 开放后用真实 prompt 算。
哪个更适合编码 agent?
Codex、OpenAI 原生代码流和终端类任务先测 GPT-5.5;Claude API agent、云端部署、长上下文循环和今天就要生产 endpoint 的团队先测 Opus 4.7。最终按任务正确率、恢复能力和审查时间决定。
Opus 4.7 还有明显优势吗?
有。它今天在 API 和云部署问题上更清楚,并且有 live 的 1M context、128k output 和多平台可用性合约。这些优势对生产工作流很现实。
我应该等 GPT-5.5 API 吗?
如果目标是 OpenAI API 迁移到 GPT-5.5,就等官方 API 路线开放再跑 pilot。如果眼前任务是生产 API,且 Opus 4.7 已经满足需求,就不需要等,把 GPT-5.5 放进后续评估计划即可。
GPT-5.5 Pro 怎么看?
GPT-5.5 Pro 是未来更高精度也更高价格的路线,不是大多数团队今天比较 GPT-5.5 和 Claude Opus 4.7 时的默认选项。除非你的任务能承受显著更高单价,并且确实需要高精度覆盖,否则先不要把它当成主路线。
工作在 OpenAI 已上线 surface 里,先用 GPT-5.5;工作需要今天可部署的 API 或云路线,先用 Claude Opus 4.7。只要牵涉预算或生产可靠性,就让两边在同一批任务里赢得切换资格。