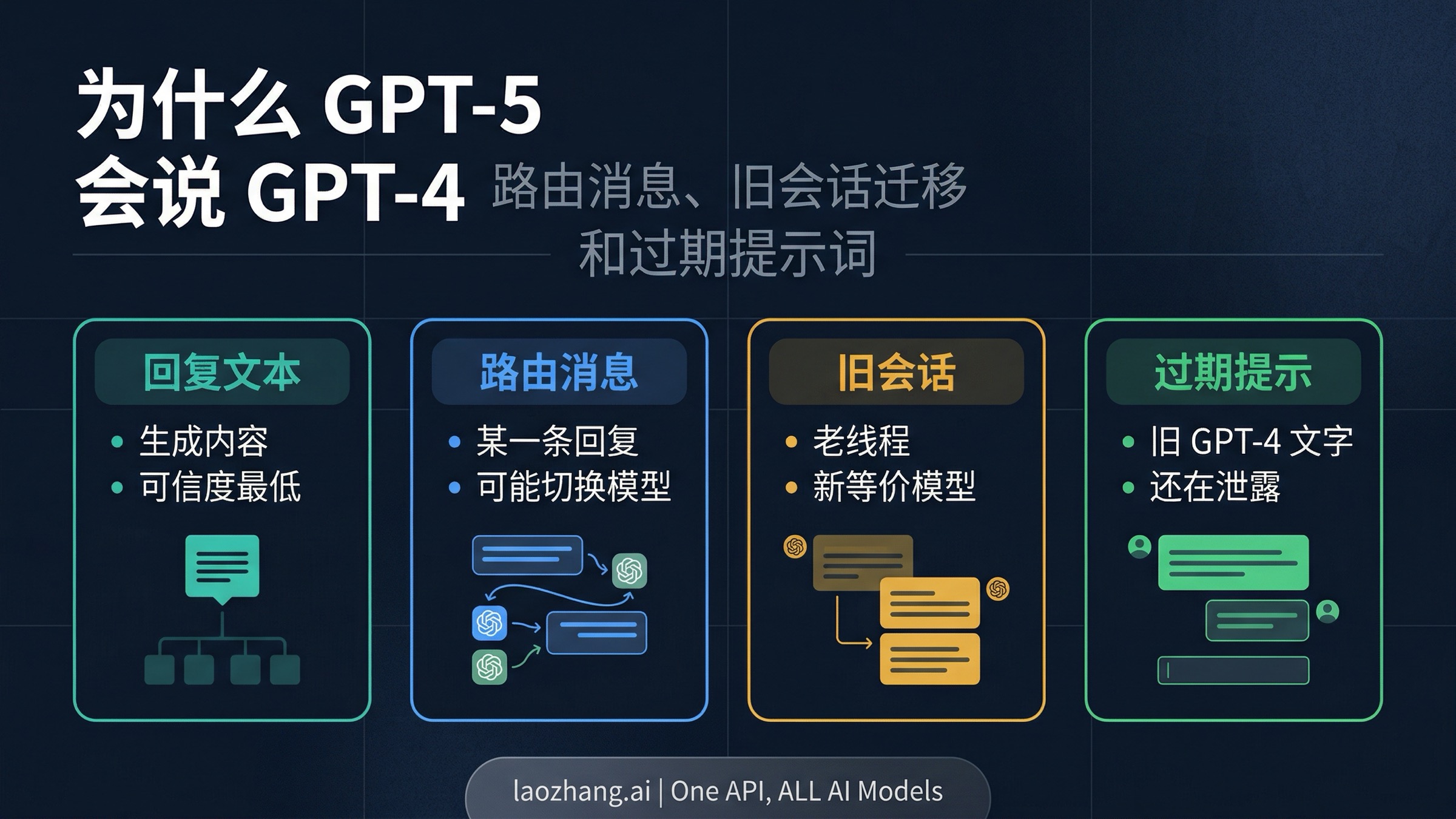
GPT-5 说自己是 GPT-4, 本身并不等于 ChatGPT 真的偷偷把你切回了 GPT-4。OpenAI 现在已经把这件事写得很直接: 回复里的模型自称属于生成文本, 可能是泛化说法, 也可能是错的。如果界面同时出现 Used GPT-5 这样的消息级标记, OpenAI 说应该信这个标记, 而不是信回答里那句“我是 GPT-4”。
这个问题在现在的 ChatGPT 里更常见, 是因为它已经不是“一个聊天窗口只对应一个静态模型标签”的旧结构了。顶部选择器显示的是会话默认模型, 某一条消息又可能被路由到别的模型, 旧聊天还可能在模型退役后继续映射到新的等价模型, 而 Custom GPT 或自定义指令里残留的旧文案也可能继续把 GPT-4 这个名字带出来。几层信息一旦不一致, 最不该优先相信的, 往往反而是模型在回复里对自己的那一句介绍。
本文基于 2026 年 4 月 1 日重新核对的 OpenAI Help Center、ChatGPT Release Notes、GPT-5 System Card 和 OpenAI 开发者文档整理。
快速答案: 该信哪个信号?
先记住下面这张表:
| 信号 | 它真正说明什么 | 可信度 | 适用场景 |
|---|---|---|---|
| 回复里写着“我是 GPT-4” | 模型在回答中的自我描述 | 低 | 只能当线索, 不能当最终证据 |
Used GPT-5 之类的消息标记 | 这条消息实际由哪个模型处理 | 高 | 在 ChatGPT 里优先看这个 |
| 顶部模型选择器 | 当前聊天的默认模型 | 中 | 适合看会话默认值, 不一定能代表每条消息 |
| API 请求配置和日志 | 你的应用真正调用了哪个模型 | API 场景最高 | 做产品或调试时看这个, 不要看模型自称 |

最核心的纠偏只有一句话: 在 ChatGPT 里, OpenAI 把消息级标记当成可信来源, 把回复里的模型自称当成可能出错的生成文本; 在 API 场景里, 最可信的是你的请求配置和日志, 不是模型自己在自然语言里怎么描述自己。
为什么现在更容易出现这种情况: ChatGPT 里的 GPT-5 是路由系统
OpenAI 自己的产品表述已经解释了大半原因。GPT-5 System Card 把 GPT-5 写成一个统一系统, 背后有实时路由器, 会根据上下文、复杂度、工具需求和显式意图来决定走哪条模型路径。ChatGPT 的 release notes 也把 GPT-5 写成一个会自动切换的系统, 后来又逐步把 Instant、Thinking 以及 legacy model access 这类控制暴露给用户。
这意味着 ChatGPT 里的“模型”其实分成了好几层。一个是你给这个聊天选的默认模型, 一个是具体某条消息真正走到的模型, 一个是旧会话在模型退役后被映射到的新等价模型, 还有一个是模型在回答里随口说出的自我身份。这几层很多时候会一致, 但只要不一致, 用户就会自然地把它理解成 bug。
OpenAI 关于 Used GPT-5 的帮助页把这个逻辑说得更明确: 系统可能按消息级别切换模型, 但你选中的模型仍然是会话默认值。也就是说, 顶部选择器和某条消息的真实处理模型, 本来就可能在短时间内不一样。
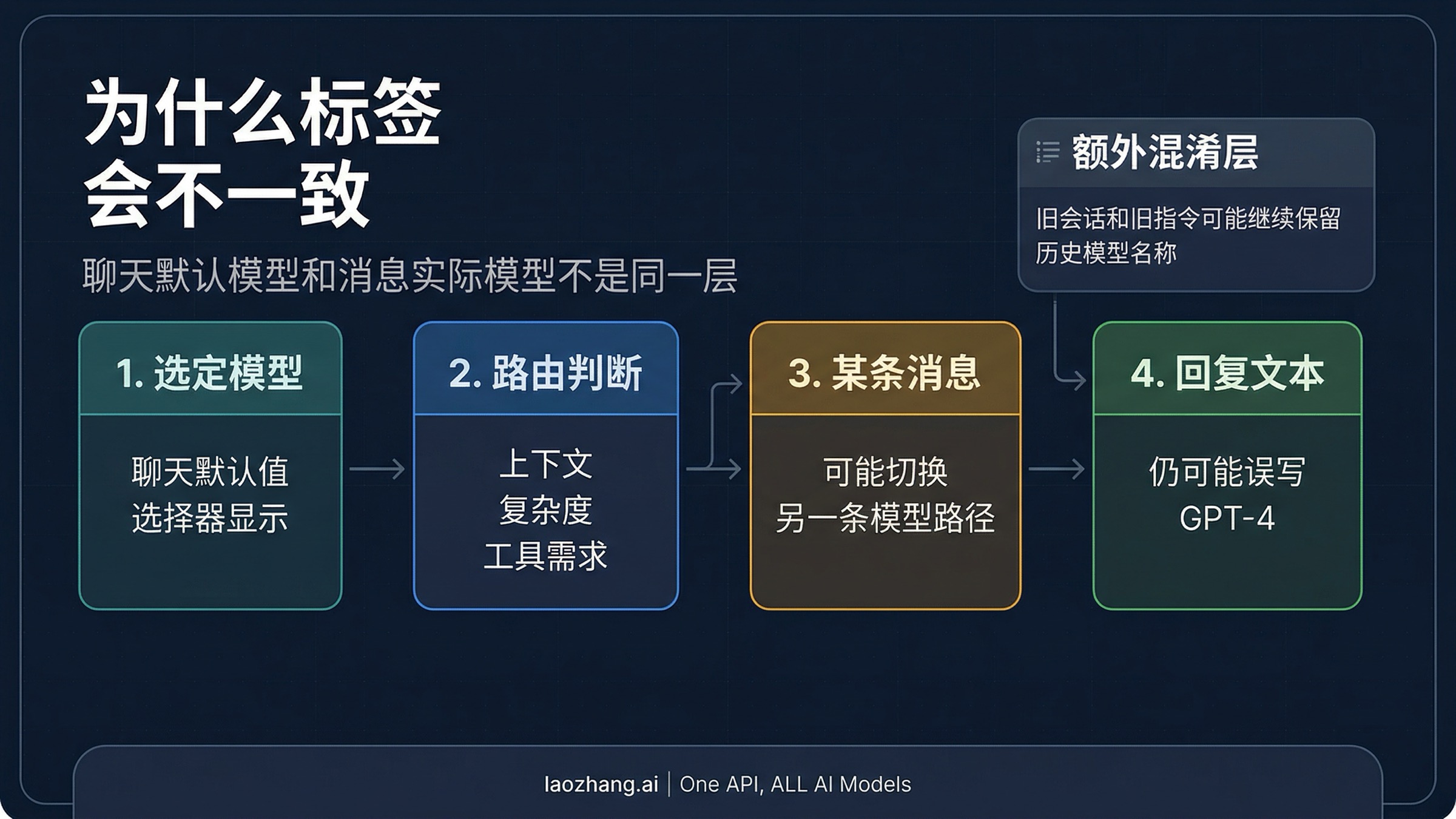
所以你完全可能同时看到这三件事:
- 顶部选择器还停留在你原来选的默认模型
- 某条消息出现了
Used GPT-5标记 - 回答正文里却写着“作为 GPT-4 模型……”
这三者并不一定互相否定。它们只是位于不同层, 而回复里的那句自称恰好最不可靠。
三个最常见的根因
大多数真实案例都可以归到三个桶里。你想修它, 先要分清自己属于哪一类。
第一类: 某条消息被路由到了不同模型。 这是 OpenAI 写得最明确的一类。帮助页直接说过, 某些消息会按消息级别被路由到别的模型。公开文档里最清楚的例子是敏感话题处理, 但 GPT-5 System Card 已经说明, 路由并不只发生在这一种场景, 还和上下文、复杂度、工具需求有关。如果界面告诉你这条消息 Used GPT-5, 那就优先信这个, 不要被正文里一句旧型号名带偏。
第二类: 你在旧会话或旧模型表层里继续聊天。 OpenAI 在 2026 年退役了多种旧的 ChatGPT 模型, 同时把已有会话映射到了新的等价模型。Release notes 说明, 原先使用 GPT-5.1 的对话会自动继续到 GPT-5.3 Instant 或 GPT-5.4 Thinking / Pro 的对应路径。GPT-4o 等旧模型的退役说明, 也明确写了 conversations 和 projects 会默认转到 GPT-5.3 Instant / GPT-5.4 的等价路线。这种情况下, 线程的历史上下文和你脑中的旧模型印象, 很容易落后于当前真实的后端路径。
第三类: 过期指令里还写着 GPT-4。 OpenAI 没有单独发一篇帮助文说“这就是为什么 GPT-5 还会说自己是 GPT-4”, 所以这一点应当诚实地视为推断, 不是逐字的官方原话。但这个推断非常合理, 因为它正好建立在两条官方事实之上。第一, OpenAI 说 personality 和 custom instructions 现在会立即作用于所有聊天, 不只作用于新聊天。第二, OpenAI 的 GPT-5 提示词指南又明确说, GPT-5 对指令非常敏感, 含糊或互相冲突的指令尤其容易把行为带偏。把这两条放在一起, 一个常见失败模式就很清楚了: 如果你的 Custom GPT 指令、自定义提示模板、系统提示词里还残留着 You are GPT-4 之类的旧身份文案, 那么即使底层已经是 GPT-5, 回答里也可能继续冒出 GPT-4 这个名字。
这第三类也是最容易让人误以为“系统一直坏了”的原因。消息级路由通常是一时的, 旧会话迁移也通常能通过日期和设置解释清楚, 但过期提示词会在每次生成时不断把旧名称重新带出来。
怎样确认到底是哪一个模型在回答
确认方法要按表层来分。
在 ChatGPT 里, 先看 OpenAI 自己指定你该看的东西。只要某条回答旁边出现 Used GPT-5 这样的标记, 就把它当成这条消息的可信来源。然后再看顶部模型选择器, 因为它只告诉你这个聊天的默认模型, 不一定能代表刚刚那一条消息。
如果你用的是旧线程, 不要只凭会话历史里原来的模型印象下判断。先回到最新的 release notes 和退役说明去核对当前映射关系。OpenAI 已经明确写过, 老对话会在模型退役后继续跑在新的等价模型上。
如果你在用 Custom GPT, 真正该检查的是 builder 里的模型设置和指令文本, 而不是不停问模型“你到底是谁”。自然语言里的自我介绍价值很低, builder 配置和提示词文本的价值更高。
如果你是在用 API, 就不要把 ChatGPT 的直觉原封不动搬过去。ChatGPT 的消息级路由是产品体验的一部分, API 调用是你自己显式指定的模型请求。在 API 场景里, 真正该信的是 request config 和日志。模型回答里说自己是 GPT-4, 通常说明的是输出层或提示词层的问题, 而不是 API 暗中给了你别的模型。
如果错误名称反复出现, 该怎么修
一旦你知道自己属于哪一类, 修复路径就不复杂了。
- 先开一个新聊天再测。 如果你是真的在验证模型身份, 旧线程会带来太多噪音: 旧上下文、旧模型映射、旧指令、旧习惯用语。
- 检查模型设置里是否启用了自动切换或 legacy model access。 这些功能本身没有问题, 但会让顶部标签和某条消息的真实处理路径更容易被混为一谈。
- 审计 Custom GPT 指令、自定义指令和长期保存的提示模板。 重点搜
You are GPT-4、As GPT-4、旧产品身份设定这类文案。持续性的错名问题, 很多时候就卡在这一层。 - API 场景一律看日志, 不要继续问回答文本。 当你要做回归测试、上线验证或对比实验时, 自然语言自我介绍不是可靠的验证方法。

有一个习惯能显著减少后续混乱: 不要再把“让模型说出自己是谁”当作模型验证步骤。这个办法在旧时代勉强还能用, 但在今天的路由式 ChatGPT 结构里已经不可靠, 在 API 调试里更不是好方法。
这是否意味着你其实还在用 GPT-4?
多数时候, 不是。至少不能只凭这一点下结论。
如果你唯一的证据, 只是回答里出现了 GPT-4, 那这属于弱证据。OpenAI 已经明确说过, 这种自我引用可能是错的, 也可能只是泛化写法。相反, 如果 UI 明确显示 Used GPT-5, 这才是更强的证据; 如果 API 日志显示你请求的是 GPT-5, 这也比回复里的自称更值得信。
真正需要重视的情况, 是这个错误名称同时和更强的信号对上了。例如你的 Custom GPT 指令里真的写着旧型号, 或者你自己明确选中了 legacy surface, 又或者日志显示请求路径和你预期不一致。只有到了那一步, 才能说“这不是简单的生成文本失误, 而是配置层或产品层真的需要排查”。
最实用的一条规则
当 GPT-5 说自己是 GPT-4 时, 先假设错的是这句话, 再去怀疑错的是后端。
然后按表层去找最强信号: ChatGPT 里看消息标记和设置, API 里看请求与日志, Custom GPT 里看 builder 配置和指令文本。这样你面对的就不再是一个模糊的命名谜题, 而是一套很短的诊断流程。