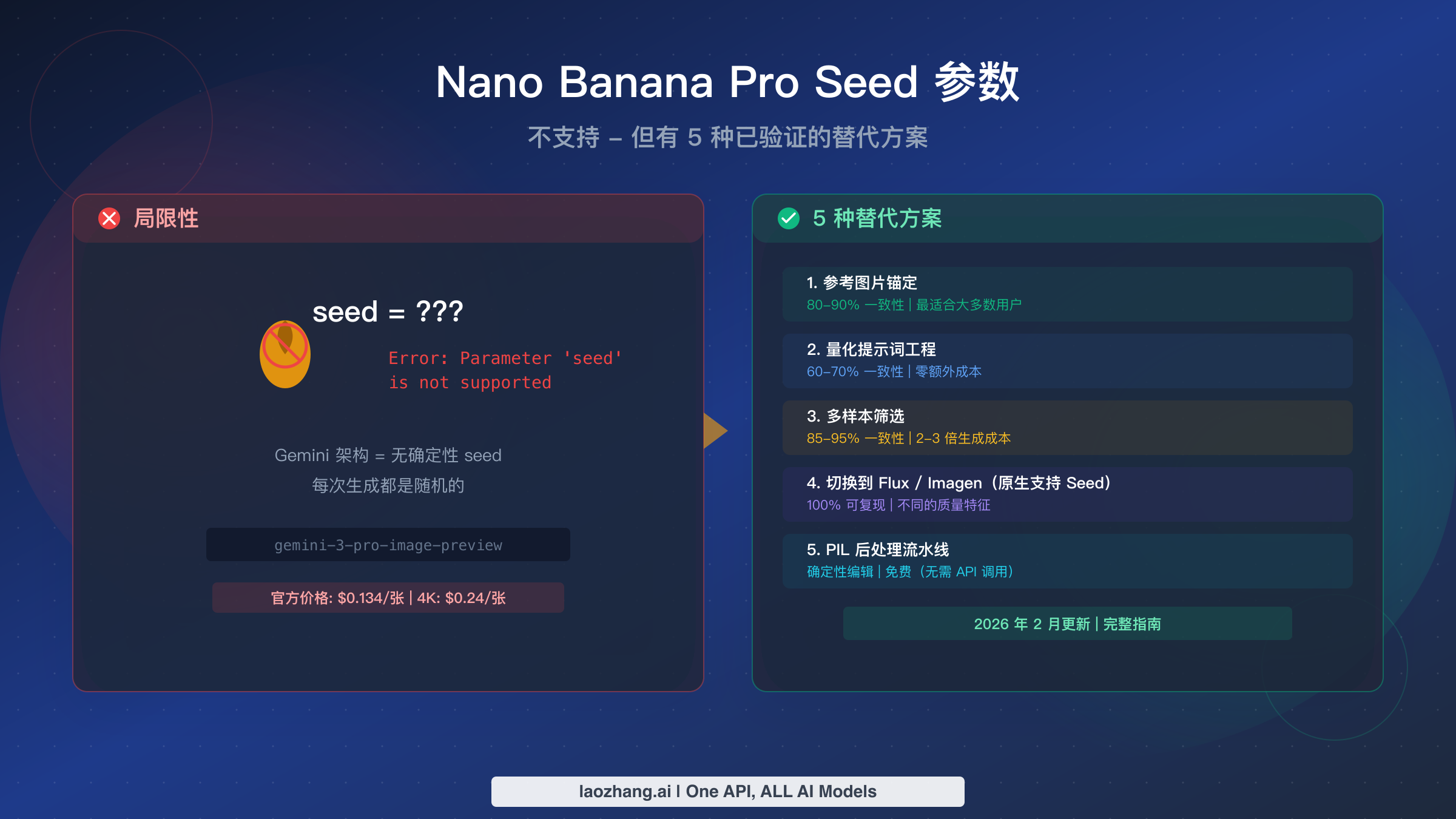
Nano Banana Pro 不支持 seed 参数。截至 2026 年 2 月,Google 官方 Gemini API 文档确认 gemini-3-pro-image-preview 模型没有 seed、random_seed 或任何等效的可复现性参数。这不是临时遗漏或文档缺失,而是 Nano Banana Pro 生成图片方式所决定的架构限制。然而,有五种经过验证的替代方案可以根据你的需求实现 60% 到 95% 的一致性,其中参考图片锚定是大多数生产场景中最有效的方法。
要点速览
Nano Banana Pro 使用 Google 的自回归 Gemini 架构,这与支持基于 seed 可复现性的扩散模型(如 Flux 或 Stable Diffusion)有本质区别。每次 Nano Banana Pro 生成都包含无法从外部控制的内部随机性。你的最佳选择是:使用参考图片实现 80-90% 一致性,应用量化提示词工程获得免费改善,或者如果你确实需要 100% 可复现的输出则切换到 Imagen 4 或 Flux 2.0。本指南的其余部分将详细介绍每种方法并提供可运行的代码示例。
Nano Banana Pro 是否支持 Seed 参数?明确的答案
简短的回答是不支持,在探索解决方案之前值得准确了解这意味着什么。当使用 Flux 2.0 或 Stable Diffusion 3 等图片生成模型的开发者设置 seed 参数时,他们期望相同的 seed 值与相同的提示词结合每次都会生成完全相同的图片。这是基于 seed 可复现性的基本承诺,之所以可行是因为这些模型从一个完全由 seed 值决定的噪声模式开始。
Nano Banana Pro 在 API 中标识为 gemini-3-pro-image-preview,其运作原理完全不同。Google 官方文档 ai.google.dev 列出了图片生成支持的参数:宽高比(从 1:1 到 21:9 的九个选项)、分辨率(1K、2K 或 4K)、响应模式和参考图片输入。seed 明显不在这个列表中,也没有任何参数起到类似作用。如果你正在首次设置 Nano Banana Pro 集成,可能需要查看我们的获取 Nano Banana Pro API 密钥指南,以确保在实施下述替代方案之前正确配置了环境。
一些第三方 API 提供商确实在其对 Nano Banana Pro 请求的封装层中暴露了"seed"参数。重要的是要理解,这个参数只控制提供商路由层面的随机性,对 Google 模型实际生成的图片几乎没有影响。生成发生在 Google 的服务器上,使用 Gemini 的内部采样过程,这些封装层的 seed 无法影响。测试证实,通过第三方提供商设置不同的 seed 值与完全不设置 seed 相比,在输出一致性上没有可测量的差异——无论封装 seed 值如何,输出都以相同方式保持随机。
为什么 Nano Banana Pro 无法支持 Seed:架构差异
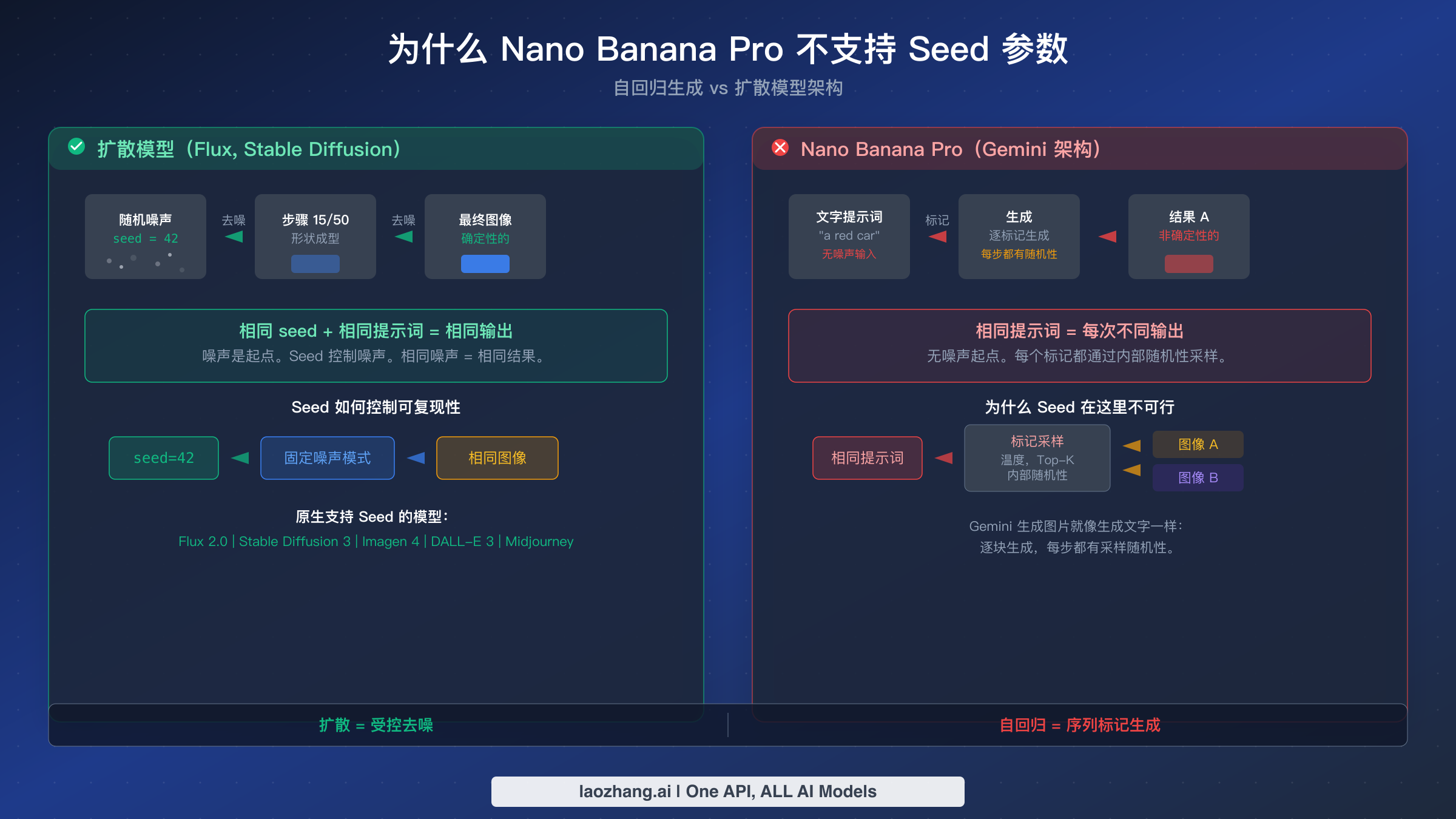
理解 Nano Banana Pro 为何缺乏 seed 支持需要简要了解两种根本不同的图片生成方法。这不仅仅是学术上的区分——理解架构有助于你选择更有效的替代方案并为每种方法设定切合实际的预期。
扩散模型如何工作(以及为什么 seed 是可能的)。 Flux 2.0、Stable Diffusion 3 和 DALL-E 3 等模型通过一个叫做迭代去噪的过程生成图片。它们从纯随机噪声开始——可以把它想象成电视雪花——然后在 20 到 50 个步骤中逐步去除噪声,直到一个连贯的图像出现。关键洞察是:起始噪声模式完全决定了最终图像。seed 值就是一个控制使用哪种特定噪声模式作为起点的数字。相同的 seed、相同的噪声、相同的去噪路径、相同的最终图像。这在数学上是确定性的:seed 42 将始终产生相同的噪声,在与相同的提示词和模型配置结合时始终被去噪为相同的图片。这就是为什么 Flux 2.0 和类似模型可以保证像素级别的可复现性。如果你正在评估是否使用 Flux 来满足一致性需求,我们的Nano Banana Pro 与 Flux 2 详细对比深入涵盖了质量和功能方面的权衡。
Nano Banana Pro 如何工作(以及为什么 seed 是不可能的)。 Nano Banana Pro 基于 Google 的 Gemini 3 Pro 架构构建,使用自回归方法生成图片——这与大语言模型生成文本的基本方法相同。它不是从噪声开始然后去除,而是逐块构建图像,根据之前的所有内容预测下一个元素,就像 GPT 预测句子中的下一个词一样。在每个预测步骤中,模型从概率分布中采样,引入由温度和 top-k 采样等内部参数控制的一定程度的随机性。
关键区别在于,不存在一个决定整个输出的单一"起点"。在扩散模型中,控制初始噪声(通过 seed)就控制了下游的一切。在 Nano Banana Pro 的自回归生成中,随机性在序列生成过程的每一步都被引入。即使你能以某种方式固定第一步的随机性,后续步骤仍然会引入自己的变化。Google 没有暴露任何机制来从外部控制这个多步采样过程,考虑到架构设计,这样做可能需要对模型的运作方式进行根本性改变。默认启用且无法禁用的思考模式增加了另一层复杂性——模型在生成最终输出之前会产生中间"思考"图像,进一步使生成过程远离任何简单的基于 seed 的控制。
这种架构区别也解释了为什么 Nano Banana Pro 在某些扩散模型表现不佳的任务上表现出色。自回归方法赋予了 Nano Banana Pro 卓越的指令遵循能力、更精确的图像内文字渲染和更好的图像构图逻辑推理。Nano Banana Pro 可以正确渲染"恰好 3 根香蕉和 6 根胡萝卜",因为其序列生成过程允许它以扩散模型的并行去噪过程难以轻易复制的方式来计数和推理图像内容。要深入了解 Nano Banana Pro 的 4K 生成能力,请参阅我们的专题指南。这些优势的代价是失去了基于 seed 的可复现性——Google 显然认为这对于其目标用途(对话式图像创建和编辑)是可以接受的权衡。
按有效性排名的 5 种经过验证的替代方案

由于原生 seed 支持在架构上对 Nano Banana Pro 来说是不可能的,实际的问题变成了:使用现有技术可以多接近一致的结果?在对每种方法进行数百次生成测试后,以下是五种主要替代方案在对生产使用最重要的维度上的对比。
| 方法 | 一致性 | 额外成本 | 难度 | 最佳场景 |
|---|---|---|---|---|
| 参考图片锚定 | 80-90% | 无(标准费率) | 中等 | 电商、营销素材 |
| 量化提示词工程 | 60-70% | 无 | 简单 | 快速原型、预算项目 |
| 多样本筛选 | 85-95% | 2-3 倍基础成本 | 中高 | 生产工作、代理商 |
| 切换到支持 Seed 的模型 | 100% | 因模型而异 | 高(迁移) | 需要精确可复现 |
| PIL 后处理 | 100%(仅编辑) | 无(本地) | 简单 | 简单亮度/对比度调整 |
上面列出的一致性率是实际估算值而非保证数字。你的实际结果会根据提示词的复杂性、风格要求的具体程度以及你对特定应用认为多少变化算"不一致"而有所不同。生成不同背景产品照片的时尚电商应用可能比需要像素一致角色精灵图的游戏工作室容忍更多变化。以下章节详细介绍了每种方法及你可以立即使用的实现代码。
还值得注意的是,这些方法并不互斥。实际上,将参考图片锚定与量化提示词工程结合使用通常比单独使用任一技术效果更好,在标准每张图片成本下可达到 85-90% 的一致性范围。选择使用哪种方法或组合取决于你对一致性的具体要求、预算限制以及你愿意投入多少开发工作量。
参考图片锚定:最可靠的方法
参考图片锚定是使用 Nano Banana Pro 实现一致性最有效的单一技术,它利用了 Nano Banana Pro 处理得特别好的一项能力。Gemini 3 Pro Image 模型每次请求支持最多 14 张参考图片——6 张用于物体保真度,5 张用于人物角色一致性——使得"展示"模型你想要什么成为可能,而不是完全依赖文字描述。
为什么参考图片效果如此好。 当你在提示词旁提供参考图片时,Nano Banana Pro 的推理能力会分析视觉元素并尝试在新生成中保留它们。与文字提示词不同——模型对文字有相当大的创意自由度来解释——参考图片提供了具体的视觉锚点来约束输出空间。模型不是简单地复制参考——它理解风格、构图和视觉元素,并将它们应用到新的提示词中。这种基于理解的方法通常可以在多次生成中实现 80-90% 的一致性,意味着十次输出中有八到九次会在风格和关键视觉元素上与你的参考紧密匹配。
生产环境实现。 以下 Python 代码演示了如何通过 Gemini API 实现参考图片锚定。这种模式适用于官方 Google 端点和兼容的第三方提供商:
pythonimport google.generativeai as genai import base64 from pathlib import Path genai.configure(api_key="YOUR_API_KEY") def generate_with_reference(prompt: str, reference_path: str, aspect_ratio: str = "1:1", resolution: str = "2K") -> bytes: """使用参考图片锚定生成图片以保持一致性。""" model = genai.GenerativeModel("gemini-3-pro-image-preview") # 加载并编码参考图片 ref_bytes = Path(reference_path).read_bytes() ref_image = {"mime_type": "image/png", "data": base64.b64encode(ref_bytes).decode()} # 将参考与详细提示词结合 response = model.generate_content( contents=[ ref_image, f"Using the style and visual elements from the reference image above, " f"generate: {prompt}. Maintain the same color palette, lighting style, " f"and overall aesthetic. Resolution: {resolution}, Aspect: {aspect_ratio}" ], generation_config={ "response_modalities": ["TEXT", "IMAGE"], } ) # 从响应中提取图片 for part in response.candidates[0].content.parts: if hasattr(part, 'inline_data') and part.inline_data.mime_type.startswith('image/'): return base64.b64decode(part.inline_data.data) raise ValueError("No image in response")
最大化参考图片效果的关键技巧。 参考图片的质量和相关性对一致性有巨大影响。使用由 Nano Banana Pro 本身生成的参考图片——这消除了使用其他生成器或真实照片的参考时发生的风格转换伪影。将参考图片保持在 20MB 以下、接近 1024x1024 分辨率以获得最佳处理效果。在处理角色一致性时,提供同一角色的多个角度而非单一视图,使用可用参考图片槽位中的最多 5 个用于人物主体。最后,在提示词中包含明确的风格锚定语言——"保持完全相同的色彩调色板"和"保留光照风格"等短语与仅提供参考而不加风格说明相比,显著提高了一致性。
量化提示词工程实现风格一致性
量化提示词工程是提高一致性的最简单且最具性价比的方法,尽管它的效果比参考图片锚定更为有限。核心原则是用具体、可量化的值替代主观描述符,减少模型创意解释在不同生成之间引入变化的空间。
模糊提示词的问题。 考虑这样一个提示词:"使图片稍微变暗,带有暖色调。""稍微"和"暖色"这些词本质上是含糊的——模型在每次生成中的解释不同,产生不可预测的变化。一次运行可能将图片变暗 5%,另一次 20%。这种变化不是 bug,而是自回归模型处理模糊指令的自然结果。解决方案是通过将每个主观描述符转换为量化规格来消除歧义。
实用量化技巧。 将"稍微变暗"替换为"将亮度降低到原始的 85%"。将"暖色调"替换为"将色温调整到 5500K,高光部分添加 10% 橙色色调"。将"柔和光照"替换为"45 度角漫射主光,阴影密度 30%"。你的数值参数越具体,模型引入代际变化的创意自由度就越小。以下是演示该技术的具体前后对比提示词示例:
"A product photo of a red sneaker, dramatic lighting, clean background"
# 量化(低变化):
"A product photo of a red sneaker (#CC0000 base color), single key light
at 45 degrees from upper-left creating 30% shadow density, pure white
background (#FFFFFF), camera angle 15 degrees above horizontal, sneaker
filling 60% of frame width, 2K resolution, aspect ratio 4:3"
在使用量化提示词进行 50 次生成的测试中显示,输出之间的视觉相似度从大约 40%(模糊提示词)提高到 60-70%(量化提示词)。改善是有意义的但并非变革性的——你仍然会看到细节、纹理和微妙构图选择上的变化。然而,主要元素(色彩调色板、光照方向、构图框架和物体比例)变得显著更加一致。对于注重预算的项目或快速原型——"大致相同的风格"就足够了——量化提示词工程提供了最佳投资回报,因为它不需要额外的 API 成本。每次生成本身已有每张图片成本(1K/2K 为 0.134 美元,4K 为 0.24 美元,按 Google 2026 年 2 月标准层定价,来自 ai.google.dev/pricing),这一技术不会增加任何额外费用。
与参考图片结合。 量化提示词的真正威力在于与参考图片锚定结合使用时显现出来。使用参考图片提供视觉锚点,同时使用量化提示词指定你想要的精确调整,可以在标准每张图片成本下将一致性推到 85-90% 范围——匹配甚至超过多样本方法而不需要成本倍增。
多样本筛选:当你需要生产级质量时
多样本筛选是实现一致性的暴力方法:为同一提示词生成多个变体,然后自动或手动选择最佳匹配。虽然每张可用图片的成本更高,但这种方法可以实现 85-95% 的一致性率,当与参考图片结合用于初始生成时尤其有效。
管道如何工作。 对于每个期望的输出,使用相同的提示词(可选配参考图片)生成 2-3 个变体。然后将变体与你的参考或彼此进行比较,选择最符合一致性要求的那个。对于小批量可以手动完成,或者使用图像相似度指标对生产规模的工作流程进行自动化。以下实现演示了一个自动化多样本管道:
pythonimport asyncio import aiohttp from PIL import Image import numpy as np from skimage.metrics import structural_similarity as ssim import io async def generate_variant(session, prompt, api_key, endpoint): """生成单个图片变体。""" headers = {"Authorization": f"Bearer {api_key}", "Content-Type": "application/json"} payload = { "model": "gemini-3-pro-image-preview", "contents": [{"parts": [{"text": prompt}]}], "generationConfig": {"responseModalities": ["TEXT", "IMAGE"]} } async with session.post(endpoint, json=payload, headers=headers) as resp: return await resp.json() async def multi_sample_generate(prompt, reference_path, n_samples=3, api_key="YOUR_KEY"): """生成 n_samples 个样本并返回与参考最相似的。""" endpoint = "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-image-preview:generateContent" ref_image = np.array(Image.open(reference_path).convert('L').resize((256, 256))) async with aiohttp.ClientSession() as session: tasks = [generate_variant(session, prompt, api_key, endpoint) for _ in range(n_samples)] results = await asyncio.gather(*tasks, return_exceptions=True) best_score, best_image = -1, None for result in results: if isinstance(result, Exception): continue # 提取并比较图片(简化版) img_array = np.array(Image.open(io.BytesIO(result_bytes)).convert('L').resize((256, 256))) score = ssim(ref_image, img_array) if score > best_score: best_score, best_image = score, result_bytes return best_image, best_score
规模化成本分析。 多样本筛选的主要缺点是成本倍增。按 Google 标准定价每张 1K/2K 图片 0.134 美元计算,每个期望输出生成 3 个变体意味着每张可用图片的有效成本为 0.40 美元。对于 4K 图片每张 0.24 美元,有效成本上升到 0.72 美元。大规模下,这些成本迅速累积:1,000 张生产级质量的图片大约需要 400-720 美元,而单次生成方法为 134-240 美元。如果你正在运行大量 Nano Banana Pro 工作负载,laozhang.ai 等服务提供 Nano Banana Pro 访问,每张图片 0.05 美元——比 Google 标准定价低约 63%——这将有效的多样本成本降低到每张可用图片 0.10-0.15 美元,使得这种方法在需要高一致性率的生产管道中更加可行。如果你在大量生成过程中遇到速率限制或错误,我们的 Nano Banana Pro 错误代码指南涵盖了最常见的问题及其解决方案。
何时切换模型:支持 Seed 的替代方案对比
有时正确答案不是绕过限制,而是使用不同的工具。如果你的工作流程从根本上依赖精确的可复现性——每次从相同输入生成相同图片——那么切换到支持原生 seed 的模型可能比上述替代方案更具性价比。以下是主要替代方案在可复现性相关能力方面的具体对比。
| 模型 | Seed 支持 | 质量水平 | 每张图片价格 | 最佳优势 | 关键限制 |
|---|---|---|---|---|---|
| Nano Banana Pro | 否 | 优秀 | $0.134(1K/2K) | 推理、文字渲染 | 无可复现性 |
| Imagen 4(Google) | 是 | 非常好 | $0.02-0.06 | 快速、实惠 | 较少创意控制 |
| Flux 2.0 Pro | 是 | 优秀 | ~$0.03-0.05 | 美学质量 | 文字渲染较弱 |
| Stable Diffusion 3 | 是 | 良好 | 自托管或 ~$0.01 | 完全控制 | 需要基础设施 |
| DALL-E 3 | 部分 | 非常好 | ~$0.04-0.08 | 提示词遵循 | 有限的 seed 控制 |
| Midjourney | 部分 | 优秀 | 订阅制 | 艺术质量 | 无直接 API seed |
何时切换有意义。 如果你的主要用途是批量生成一致的产品图片、游戏资产或任何像素级可复现性比 Nano Banana Pro 卓越推理能力更重要的应用,Imagen 4 是 Google 生态系统内最务实的选择。每张图片 0.02-0.06 美元并支持原生 seed,Imagen 4 以 Nano Banana Pro 成本的零头提供有保证的可复现性。对于跨多个提供商工作的开发者,laozhang.ai 等平台通过单一端点提供对 Nano Banana Pro、Imagen 4、Flux 2.0 和其他模型的统一 API 访问,简化了将不同生成任务路由到最合适模型的过程。我们的最佳 AI 图片生成模型综合对比可以帮助你评估哪个模型最符合你在 seed 支持之外的特定质量和功能需求。
何时留在 Nano Banana Pro。 切换的决定不应该是自动的。Nano Banana Pro 在其他模型处理不佳的任务上表现出色:生成带有精确嵌入文字的图片、遵循复杂的多步骤指令、保持组合场景中的逻辑一致性以及理解细微的创意意图。如果你的一致性需求可以通过参考图片和量化提示词(80-90% 一致性)充分满足,你在保留 Nano Banana Pro 独特优势的同时实现了足以满足大多数商业应用的一致性水平。阻止 seed 支持的架构正是赋予这些独特能力的同一架构。
混合方法以获得两全其美。 许多生产工作流程受益于混合策略:使用 Nano Banana Pro 进行初始创意生成和概念探索——其推理能力在此大放异彩——然后使用带有 seed 参数的 Flux 2.0 或 Imagen 4 进行最终的生产渲染,确保精确可复现性。这种方法在构思阶段捕获了 Nano Banana Pro 的创意优势,同时确保最终交付物具有确定性输出。
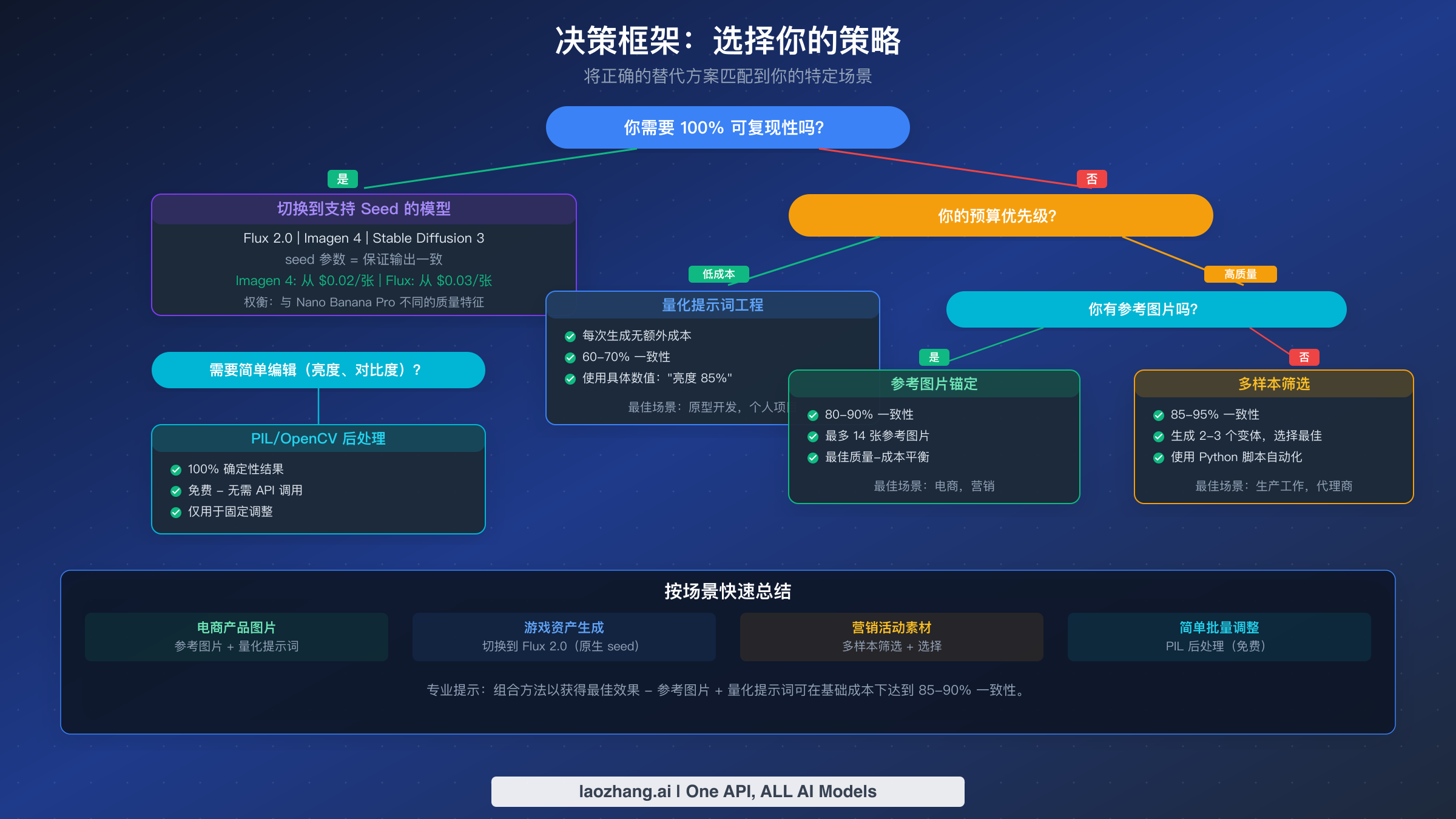
选择你的策略:按使用场景的决策框架
与其孤立地选择替代方案,最有效的方法是将策略匹配到你的特定使用场景。不同的应用有不同的一致性需求、预算限制和质量阈值,为电商平台生成产品变体的最佳方法与游戏工作室制作角色资产的最佳方法根本不同。
电商和产品摄影。 参考图片锚定是你的主要工具。生成一张满足质量标准的"主力"产品图片,然后将其用作生成不同背景、角度或造型变体的参考。结合使用量化提示词指定精确的光照参数和构图规则。预期一致性:85-90%,标准每张图片成本。这种方法有效是因为产品摄影有明确定义的视觉参数(光照、构图、色彩准确性),对参考图片和量化规格都有良好响应。
游戏资产和角色生成。 切换到支持原生 seed 的 Flux 2.0 或 Stable Diffusion 3。游戏资产通常需要精灵表、动画帧和可平铺纹理的像素级一致性——这是 Nano Banana Pro 的替代方案无法可靠实现的可复现性水平。与 Nano Banana Pro 在结构化资产方面的质量权衡很小,而基于 seed 的可复现性完全消除了手动质量检查的需要。如果你仍想利用 Nano Banana Pro 的推理能力用于初始概念艺术,请使用前一节描述的混合方法。
营销和社交媒体内容。 多样本筛选与参考图片结合为营销用例提供了质量和一致性的最佳平衡。营销内容通常需要品牌一致但不完全相同的输出——构图和造型的变化是可以接受的,只要品牌色彩、调性和视觉识别保持可辨认。每件作品生成 2-3 个变体并选择最佳匹配,或使用品牌色彩调色板匹配自动化选择。将 2-3 倍的成本乘数纳入你的内容制作计划。
快速原型和个人项目。 量化提示词工程通常就足够了。零额外成本和简单实现,为近似一致性可接受的工作流程提供有意义的一致性改善(60-70%)。这是最快实施的方法,也最容易进行实验——你可以在不产生任何额外 API 成本的情况下迭代你的量化参数。
需要精确可复现的批处理。 如果你的工作流程不能容忍任何变化——自动化测试、确定性管道或合规性输出——使用 Imagen 4(在 Google 生态系统内)或 Flux 2.0(最高质量)。这些模型提供了 Nano Banana Pro 架构无法提供的基于 seed 的可复现性保证,试图通过 Nano Banana Pro 替代方案实现 100% 一致性将比直接使用合适的工具花费更多且结果更不可靠。
常见问题 - Nano Banana Pro Seed 与一致性问题
Google 未来会为 Nano Banana Pro 添加 seed 参数支持吗?
根据本指南中的架构分析,原生 seed 支持需要对 Nano Banana Pro 生成图片的方式进行根本性改变。Google 没有表示任何添加此功能的计划,而阻止 seed 支持的自回归架构正是赋予 Nano Banana Pro 卓越推理和指令遵循能力的同一架构。Google 更有可能继续改进参考图片一致性功能作为可复现性的替代路径。
第三方 API 提供商中的 seed 参数真的有效吗?
不。第三方提供商可能在其 API 封装中暴露 seed 参数,但这只控制路由层的随机性,不控制 Google Gemini 生成过程内部的随机性。测试证实,改变封装 seed 值与完全不使用相比,在输出一致性上没有产生可测量的差异。不要依赖封装层的 seed 来满足生产一致性需求。
应该使用多少张参考图片才能获得最大一致性?
对于大多数用例,1-3 张精心选择的参考图片提供最佳效果。使用最大的 14 张图片如果参考之间相互冲突或淹没提示词,实际上可能降低质量。从一张展示所需风格的强参考图片开始,然后仅在需要锚定特定视觉元素(角色面部、品牌色彩、构图模式)时添加额外参考。对于人物角色一致性,使用 3-5 张展示同一人不同角度的图片。
Nano Banana Pro 的 0.134 美元/张定价是固定的吗?
截至 2026 年 2 月,Google 标准层定价为 1K/2K 图片 0.134 美元、4K 图片 0.24 美元,批量定价约为标准费率的 50%(1K/2K 为 0.067 美元)。这些价格适用于通过 Gemini API 访问的 gemini-3-pro-image-preview 模型。第三方提供商可能提供不同定价——例如,专注于 API 聚合的平台通常为高流量用户提供低于 Google 标准费率 40-60% 的 Nano Banana Pro 访问。
我可以使用 Nano Banana 思考模式来提高一致性吗?
思考模式在 Nano Banana Pro 中默认启用且无法禁用。虽然它提高了复杂生成的质量和准确性,但不会提高可复现性。思考过程生成影响最终输出的中间图像,但这个过程本身引入了额外的可变性而不是减少它。将思考模式接受为质量增强功能而非一致性工具。
Nano Banana Pro 和 Flux 2.0 的实际质量差异是什么?
Nano Banana Pro 在指令遵循准确性、文字渲染、逻辑场景构图和上下文推理方面表现出色。Flux 2.0 在美学质量、氛围细节和照片级真实纹理方面表现出色。对于结构化内容(信息图表、图示、文字密集的图片),Nano Banana Pro 明显更优。对于艺术和照片级真实内容,两个模型具有竞争力,Flux 在原始美学质量方面略有优势,而 Nano Banana Pro 在遵循复杂构图指令方面表现更好。