
截至 2026 年 5 月 7 日,xAI 开发者文档列出 grok-4.3 这个 API 模型。实用判断不是先问它是不是最新、是不是最强,而是先确认能不能按 xAI API 合同调用、会不会影响迁移、成本是否真实、同一任务能不能赢过现有默认路线。
| 你的当前任务 | 当前答案 | 下一步 |
|---|---|---|
| 想通过 API 调 Grok 4.3 | 以 xAI API 文档和控制台为准,不要把 Grok 聊天、X 会员、社区截图或第三方供应商当成同一个合同。 | 先用 grok-4.3 做最小请求,再决定是否测试 grok-4.3-latest 或 grok-latest。 |
| 想估算价格 | 5 月 7 日证据显示 xAI 文档列出输入、缓存输入、输出的每百万 token 价格,并提示 20 万 token 以上存在高上下文边界。 | 按成功任务成本建账,把长上下文、工具、重试、延迟和人工复核都算进去。 |
| 正在迁移旧 Grok API | xAI 迁移说明给出 2026 年 5 月 15 日太平洋时间 12:00 的旧模型退役节点。 | 盘点调用点、做兼容检查、跑同任务试点,并保留回滚路线。 |
| 想判断是否比当前默认模型好 | 公开榜单、媒体和社区讨论只能决定要测什么,不能直接决定上线。 | 用同一批提示词、文件、工具、预算和评分规则对比当前默认路线。 |
官方合同来源应优先落在 xAI 的 Grok 4.3 模型页、模型与价格页、以及 5 月 15 日迁移说明。它们决定模型 ID、别名、上下文、价格行、区域、限制和退役时间;媒体、社区、视频和第三方供应商页面只能作为测试线索。
停线规则很简单:不要因为它新、基础价格低、或者某个榜单表现强,就把 Grok 4.3 推成默认生产模型。只有当同任务试点在质量、延迟、总成本、失败率和复核时间上同时优于现有路线时,才扩大流量。
先锁定官方 xAI 合同
Grok 4.3 的关键问题不是“市场上有没有人在讨论”,而是“今天能按哪个合同写进代码”。API 侧的合同是 xAI 开发者文档和你的 xAI 控制台。模型页决定 grok-4.3 这个模型 ID、可用别名、上下文窗口、区域和限制;模型与价格页决定当前价格行;迁移说明决定旧 Grok API 模型的退役时间。

| 合同项 | 2026 年 5 月 7 日应如何使用 | 决策意义 |
|---|---|---|
| 模型 ID | grok-4.3 | 需要可复现测试、问题定位和回滚证据时,优先固定这个字符串。 |
| 别名 | grok-4.3-latest、grok-latest | 适合探索,不适合作为没有发布策略的生产默认值。 |
| 调用路线 | xAI API,或配置到 xAI base URL 的 OpenAI 兼容客户端 | 不要和 Grok 聊天、X 订阅、SuperGrok、OpenRouter 或其他包装商混在一起。 |
| 上下文 | 文档列出 100 万 token | 长上下文仍要测成本、延迟和召回质量。 |
| 高上下文边界 | 20 万 token 以上可能进入不同价格或行为边界 | 大型证据包和日志分析任务不能只看基础价格行。 |
| 区域和限额 | 以模型页和控制台为准 | 团队、账号、地区、等级都会改变真实可调用能力。 |
这个合同优先顺序能避免两个常见误判。第一,社区说“已经能用”不等于你的项目、区域和账号能按同一限制调用。第二,第三方页面显示可接入,不等于它就是官方 xAI API 合同。生产系统需要能解释账单、请求 ID、限额、错误码和回滚路径。
生产测试先用固定模型字符串
测试和上线的第一条规则是从 grok-4.3 开始。固定模型字符串让评估、日志、支持工单和回滚判断都更清楚。别名可以省去手动跟进版本的麻烦,但它也可能让模型行为在代码没有变化时发生移动。对于生产默认值,这种移动应该由发布策略批准,而不是由别名自动发生。
| 使用环境 | 模型标签策略 | 原因 |
|---|---|---|
| 本地探索 | grok-4.3 或 grok-4.3-latest | 结果不作为生产证据时,可以更快试错。 |
| 评测脚本 | grok-4.3 | 前后对比必须稳定,否则无法判断变化来自模型还是别名。 |
| 预发环境 | grok-4.3 加控制台核验 | 需要确认账号、区域、限额和生产一致。 |
| 生产默认 | 固定模型 ID,除非发布策略允许别名 | 隐性版本漂移会被误判为应用回归。 |
日志里至少记录模型标签、请求 ID、区域、提示词版本、输入 token、缓存命中、输出 token、工具调用、重试次数、状态码和延迟。真正排查问题时,“Grok 4.3 有问题”几乎没有用;“grok-4.3 在某区域、某提示词版本、某工具路径、某输入大小下失败”才可行动。
最小 API 请求先保持无聊
xAI 的快速开始文档支持原生 xAI 用法,也支持 OpenAI 兼容客户端。已有 OpenAI 风格客户端的团队,通常可以先保留客户端形状,把 base URL 指向 https://api.x.ai/v1,并使 用 XAI_API_KEY。把这件事做小,是为了先证明密钥、端点、模型字符串、组织或团队、区域、配额、超时和日志都是通的。
pythonfrom openai import OpenAI import os client = OpenAI( api_key=os.environ["XAI_API_KEY"], base_url="https://api.x.ai/v1", ) response = client.chat.completions.create( model="grok-4.3", messages=[{"role": "user", "content": "Summarize the migration risk in three bullets."}], ) print(response.choices[0].message.content)
第一条请求不要同时换模型、换提示词、换 agent 框架、换工具栈、再切生产流量。先让一个最小请求从真实运行环境成功返回,再接入真实提示词和工具。这样失败时只有少数变量需要排查,成功时也能把日志基线保存下来。
| 检查项 | 通过信号 |
|---|---|
| 密钥和 base URL | 同一运行环境里至少一条请求成功。 |
| 模型 ID | 日志显示 grok-4.3,而不是被别名或供应商映射替换。 |
| 账号路线 | 账单和限额落在预期 xAI 团队或项目上。 |
| 超时和重试 | 失败有上限,重试不会静默放大成本。 |
| 输出格式 | 下游需要的 JSON、结构化输出或文本约束能稳定满足。 |
| 可观测性 | 请求 ID、token、延迟、状态和工具调用都可追踪。 |
基础价格不是成功任务成本
5 月 7 日证据显示,xAI 文档为 Grok 4.3 列出每百万 token 1.25 美元输入、0.20 美元缓存输入、2.50 美元输出的基础价格行。这是预算入口,不是迁移结论。一个基础价更低的模型,如果需要更多重试、更多上下文、更长复核、或更多付费工具,最终可能不便宜。
| 成本变量 | 必须记录什么 | 为什么会改变判断 |
|---|---|---|
| 输入 token | 提示词、上下文、检索文件、日志、策略文本 | 重复任务里长提示词会快速累积。 |
| 缓存输入 | 重复前缀和缓存命中表现 | 高命中工作流可能因为缓存价格显著不同而改变赢家。 |
| 输出 token | 最终答案、结构化 JSON、工具摘要和修复文本 | 输出密集任务可能吃掉输入端节省。 |
| 长上下文 | 是否越过 20 万 token 边界 | 大证据包可能同时影响价格、速度和准确度。 |
| 服务端工具 | Web Search、X Search 或其他工具调用 | 实时价值可能依赖额外计费或限制。 |
| 重试 | 超时、格式修复、工具失败后的再次请求 | 单次便宜不等于三次请求仍便宜。 |
| 人工复核 | 接受、修改或驳回结果所需时间 | 工程和运营任务里,复核时间经常比 token 更贵。 |
更可靠的指标是“每个被接受任务的成本”。客服场景可以是一张解决的工单,代码场景可以是一次可合并修改,研究场景可以是一份事实无误的证据包。Grok 4.3 如果在这个单位上更便宜、质量又不下降,才值得扩大流量。
5 月 15 日迁移要按运维任务处理
旧 Grok API 模型如果受 2026 年 5 月 15 日太平洋时间 12:00 的退役说明影响,团队需要做的不是临时把模型名替换掉。迁移会改变模型行为、输出格式、工具调用、延迟和成本,任何一个点都可能让下游系统出问题。
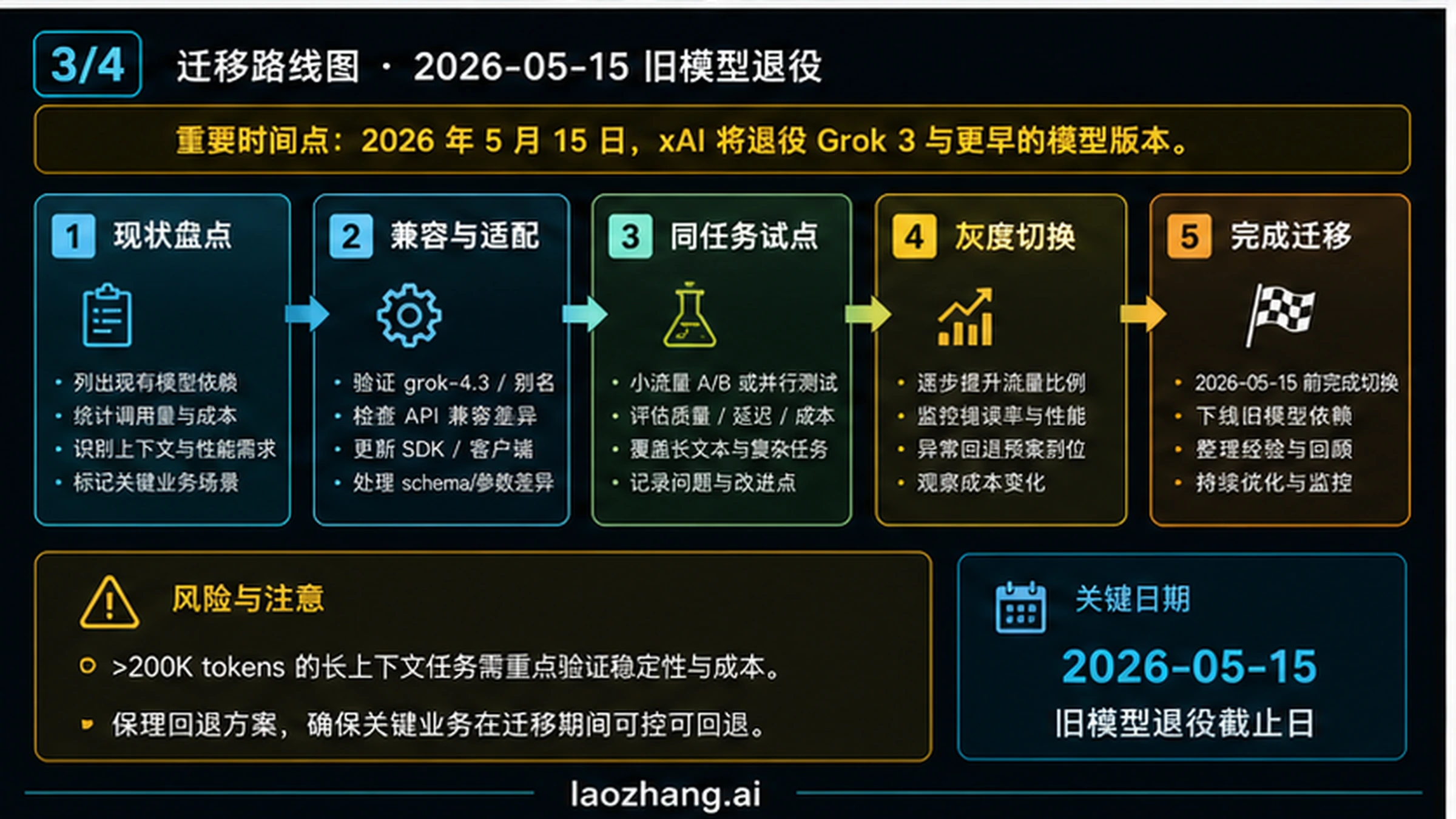
| 迁移步骤 | 要做什么 | 要保留的证据 |
|---|---|---|
| 盘点 | 找出每个 Grok 调用点、负责人、模型字符串、别名、提示词、工具和流量等级。 | 调用点清单和 owner。 |
| 兼容检查 | 用 grok-4.3 跑相同提示词,比较参数、响应结构、格式约束和错误处理。 | 差异日志和失败样例。 |
| 同任务试点 | 用代表性生产任务测试,不先改默认路由。 | 质量分、延迟、成本和复核记录。 |
| 分阶段发布 | 先迁低风险流量,再按指标扩大。 | 流量比例、失败率和回滚触发器。 |
| 监控 | 观察成本、延迟、质量、用户投诉和支持日志。 | 迁移后的计分板。 |
保留回滚不是保守,而是必要。只要新模型在某些长上下文、函数调用、结构化输出或安全边界上表现不同,API 请求成功也可能导致业务失败。等新路线在关键任务里稳定后,再缩短旧路线的保留时间。
公开榜单和社区讨论只能决定测试面
Grok 4.3 的公开讨论混合了官方文档、Reddit、X、视频、媒体、Artificial Analysis、供应商列表和开发者论坛。它们有价值,但价值在于告诉你哪些工作负载值得纳入试点,而不是替你的系统宣布胜负。
| 来源类型 | 合理用法 | 不安全用法 |
|---|---|---|
| xAI 文档 | 模型 ID、API 路线、别名、上下文、价格、迁移时间 | 不复查就写成长期不变事实。 |
| xAI 状态页 | 判断是否有实时事故或服务异常 | 写成稳定性保证。 |
| benchmark 和榜单 | 选择推理、工具、长上下文等测试任务 | 宣布 Grok 4.3 一定赢你的工作负载。 |
| 媒体和发布报道 | 理解发布叙事和市场关注点 | 把报道里的价格或能力当作合同。 |
| 社区和视频 | 收集常见困惑、失败样例和测试角度 | 当作生产事实来源。 |
| 供应商列表 | 发现第三方可用路线 | 把第三方路线写成官方 xAI API 真相。 |
如果公开测试说它推理强,就把推理任务纳入试点;如果讨论说它便宜,就把总成本做成账本;如果视频强调实时问题,就把搜索工具任务加进去并检查引用质量。读公开信号没有问题,把公开信号当上线证明才有问题。
切换默认前必须跑同任务试点
公平试点只改变模型路线,不同时改变提示词、输入文件、检索集合、工具、输出格式、超时、重试和评分规则。否则你测到的可能是外围系统变化,而不是 Grok 4.3 本身。

| 试点车道 | 最小测试 | 停线规则 |
|---|---|---|
| 质量 | 比较可接受答案、事实错误、推理缺口和遗漏约束。 | 如果复核者修 Grok 输出的时间更多,不切默认。 |
| 工具 | 测函数调用、JSON、检索、搜索和失败恢复。 | 如果工具错误更难发现或恢复,不切默认。 |
| 长上下文 | 覆盖常规、高上下文和 20 万 token 以上区间。 | 如果关键区间召回或延迟崩掉,不切默认。 |
| 成本 | 记录输入、缓存输入、输出、工具、重试和复核分钟。 | 不因为基础 token 价格单独切换。 |
| 延迟 | 在真实负载下记录中位数、p95 和超时。 | 如果慢尾影响体验,不切默认。 |
| 稳定性 | 同一任务多次运行,覆盖不同流量窗口。 | 如果波动超过产品容忍度,不切默认。 |
试点结束时最好得到三类结论之一:只在明确胜出的窄路线采用 Grok 4.3;保留现有默认,只把 Grok 4.3 放进特定 fallback 或实验路线;继续测试,因为信号不错但证据还不足以上线。这比简单回答“换不换”更有价值。
试点记录还应写清楚“为什么没有扩大”。如果质量赢了但 p95 延迟变差,就把 Grok 4.3 留在后台任务或低时效任务;如果价格赢了但结构化输出修复次数增加,就先优化提示词和 schema 校验;如果长上下文表现好但短任务没有优势,就只给大证据包路线开白名单。这样做可以防止团队把一次平均分胜利误读成全局默认胜利。
另一个容易忽略的变量是复核者信心。很多 API 迁移在自动分数上接近,但 reviewer 需要花更多时间确认引用、检查格式或补充边界。此时 token 账单看起来下降,交付时间却上升。把复核分钟写进试点表,才能看见真实业务成本。
最终发布记录建议保留三份材料:一份固定模型字符串和参数的请求样例,一份同任务对比表,一份回滚触发清单。请求样例证明调用路线没有漂移;对比表证明迁移不是凭感觉;回滚清单让值班人员在质量、成本、延迟或限额异常时知道该退到哪条路线。缺少其中任何一份,默认切换都还没有完成。
如果团队只有时间做一轮试点,优先选择真实高频任务,而不是最容易展示效果的演示任务。高频任务能暴露缓存、成本、格式、延迟和人工复核的长期压力,也更容易让业务 owner 判断是否值得切换。演示任务可以留作补充,但不应决定默认路线,也不能替代上线前的限额、账单和告警验证。
什么时候转向跨模型比较
如果你的问题是 xAI API 可用性、模型 ID、价格、迁移和 Grok 专属试点,就留在这个决策框架。如果真正问题是 OpenAI、Anthropic、xAI 之间先测谁、默认谁、fallback 谁,则应该阅读 Grok 4.3、Claude Opus 4.7 与 GPT-5.5 的路线比较。
两类问题拆开才清楚。Grok 专属判断可以深入别名、迁移时间、高上下文价格和 xAI 工具成本;跨厂商比较应该先回答不同供应商的首测路线和适用任务。混在一起会让首屏变慢,也会让生产建议变钝。
常见问题
xAI API 现在能调用吗?
截至 2026 年 5 月 7 日,xAI 文档列出 grok-4.3 这个 API 模型。上线前仍要重新检查模型页和控制台,因为可用性、区域、限额、别名和账号权限会变化。
应该用哪个模型字符串?
需要可复现时用 grok-4.3。grok-4.3-latest 和 grok-latest 应视为别名,只有在发布策略允许自动跟随时才适合生产。
API 是免费的吗?
xAI API 不应和 Grok 聊天、X Premium 或 SuperGrok 混为一谈。API 文档列出 token 价格,所以不能假定 API 免费。消费者端权益要按另一个产品面单独核验。
现在标价是多少?
5 月 7 日证据显示,xAI 文档列出每百万 token 1.25 美元输入、0.20 美元缓存输入、2.50 美元输出,并提示 20 万 token 以上的高上下文边界。预算前必须复查。
100 万上下文是否意味着长任务都划算?
不是。100 万 token 是上下文能力,不是成本、延迟和质量保证。跨过大上下文区间时要单独测召回、速度、价格和失败率。
旧 Grok API 流量要迁移吗?
如果调用的旧模型受 5 月 15 日退役说明影响,就需要迁移计划。先盘点调用点,再做兼容检查、同任务试点、分阶段发布和回滚准备。
它比 GPT-5.5 或 Claude Opus 4.7 更好吗?
不能给通用结论。Grok 4.3 是 xAI 路线中值得测试的 API 模型,尤其适合围绕 xAI 合同、实时/X 相关能力、低基础价格和长上下文做试点。跨厂商优先级应看比较文。
生产切换前最后核验什么?
核验模型 ID、端点、密钥、账号、区域、限额、价格、上下文、工具成本、重试、输出格式、延迟和复核通过率。只有同任务证据成立,才扩大默认流量。