2026 年,Gemini API 仍然有部分模型可走免费层,但免费层速率限制不是一张可以从旧表格、AI 摘要或论坛帖子里直接复制的固定数字。免费创建 API key 只是拿到绑定 Google Cloud project 的凭证,不会让每个 key 拥有独立 quota,也不代表后端调用无限。真正可用的免费容量取决于模型、serving mode、project、region、usage tier、billing 状态,以及 AI Studio 对这个 project 显示的实时限额。如果你在 quota 面板、429 报错或近期讨论里看到 “20 RPD”,把它当成某个 project 的可能快照,而不是通用的 Gemini API 免费层合同。先用 pricing 确认模型是否有免费资格,再打开 AI Studio 读取当前 project 的 active limits,最后再判断 429 属于 quota、billing、region、traffic shape 还是 route choice。
先说结论
| 问题 | 2026 年 5 月 6 日的可发布答案 |
|---|---|
| Gemini API key 可以免费获取吗? | 可以。Google 的 API key 文档把 key 创建和管理入口放在 Google AI Studio;新用户接受条款后可获得默认 project 和 API key。免费 key 是凭证,不是独立额度桶。 |
| Gemini API 可以免费调用吗? | 可以,但前提是目标模型和 serving mode 仍有免费资格。Google pricing 页面仍然给部分 Gemini Developer API 路线标出 Free Tier。 |
| 免费 Gemini API key 会一直免费吗? | 不要把它当成永久 entitlement。key 创建可以免费,但模型资格、project 限额、未付费服务条款、billing 要求和地区规则都可能变化,上线前必须复核。 |
| 20 RPD 免费层限制是真的吗? | 它可能对某个 project、model 或账号状态真实存在,但不是可以写进代码的通用额度。真正可用的 RPD 要在 AI Studio 里按 project、model、tier 和 billing state 查看。 |
| 有没有一个可以写进代码的公开固定限额? | 没有。公开文档解释 RPM、TPM、RPD 和 project 级规则,实际 active limits 要看 AI Studio。 |
| 多个 API key 会增加免费额度吗? | 不会。同一 project 下多个 key 共享同一个 quota bucket。 |
| 哪些路线现在可以先按免费资格评估? | 先查 pricing。当前可见的免费输入/输出路线包括 gemini-3-flash-preview、gemini-3.1-flash-lite-preview、gemini-3.1-flash-live-preview、gemini-2.5-pro、gemini-2.5-flash 和 gemini-2.5-flash-lite 的合格 serving mode。 |
| 哪些路线不应该叫免费 API? | gemini-3.1-pro-preview、Gemini 2.5 Flash Image、Gemini 3 Pro Image Preview、Gemini 3.1 Flash Image Preview、Imagen、Veo,以及很多 Batch/Flex/Image 路线在 Free Tier 栏里是 Not available。 |
| 遇到 429 先做什么? | 先确认调用面、project、model、serving mode 和 AI Studio quota,再判断是 RPM、TPM、RPD、突发并发、billing、模型资格还是 provider route 的限制。 |
事实复核:本文在 2026 年 5 月 6 日核对了 Google rate limits、pricing、billing、API key 和 terms 文档,并重新确认了 20 RPD 的边界。价格、模型资格和限额都是易变事实,上线前要重新查看官方页面和 AI Studio。
最大变化不在数字,在答案入口
很多旧文章会直接给一张 “Gemini API 免费额度表”。只问 “20 RPD” 本质上也是想把当前额度压成一个固定数字。这种表最多只能当历史快照,不能当 2026 年的上线合同。现在要把两个问题拆开:
- 目标模型和 serving mode 有没有 Free Tier 资格。
- 你的 project 今天在 AI Studio 里实际显示多少 RPM、TPM、RPD 或其他模型维度。
Gemini API rate-limits 文档 仍然解释了最重要的机制:限制会按 requests per minute、tokens per minute、requests per day 等维度生效;只要其中一个维度超限,就可能触发错误;RPD 按太平洋时间午夜重置;quota 按 project 而不是按 API key 生效。它的价值是规则说明,不是替你承诺每个账号的最终容量。
真正可执行的做法是把 Gemini pricing 页面 当作模型资格入口,把 AI Studio rate-limit view 当作实时 project quota 入口。只要旧表或被反复引用的数字和这两个入口冲突,旧表就不能作为决策依据。
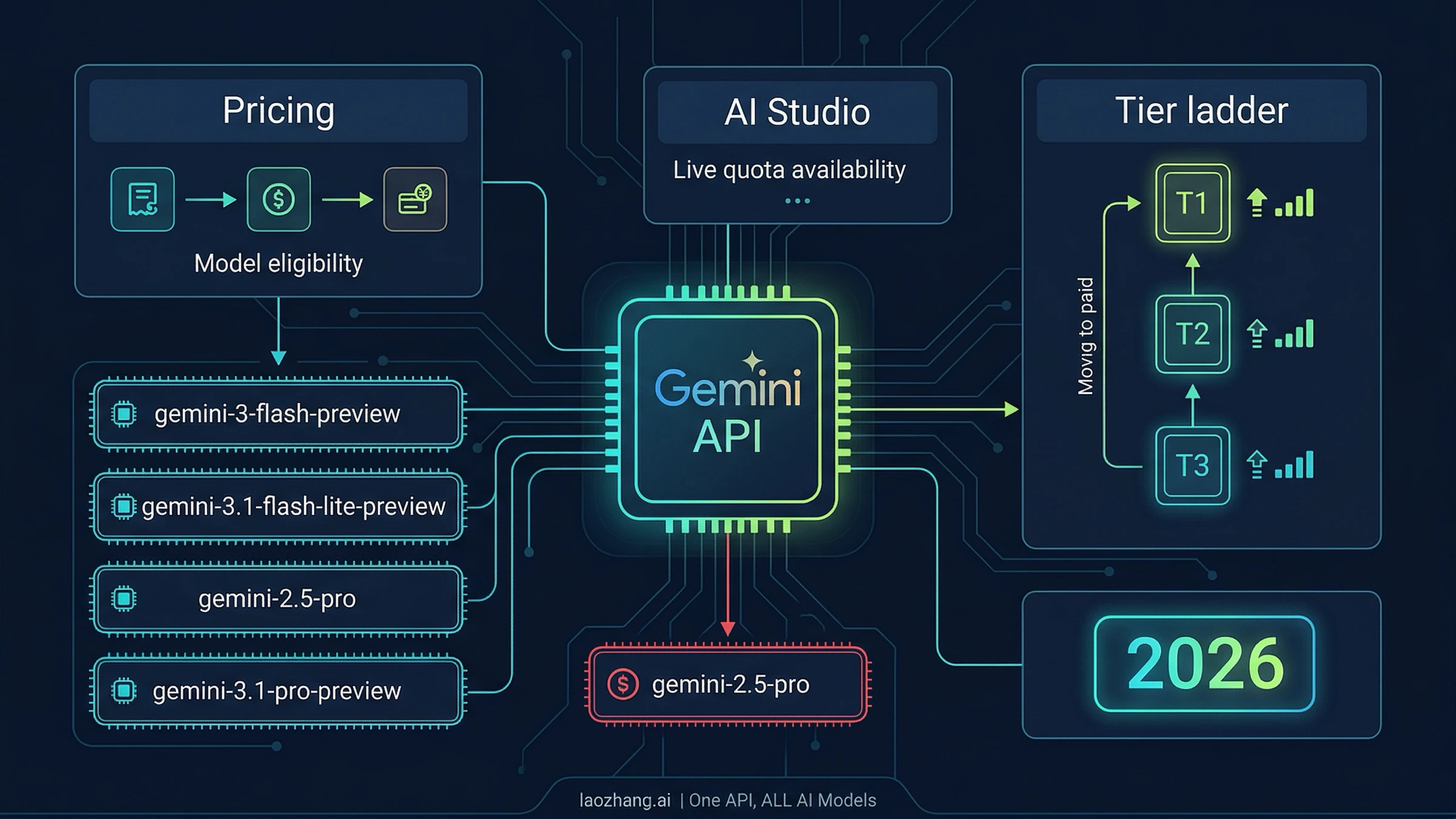
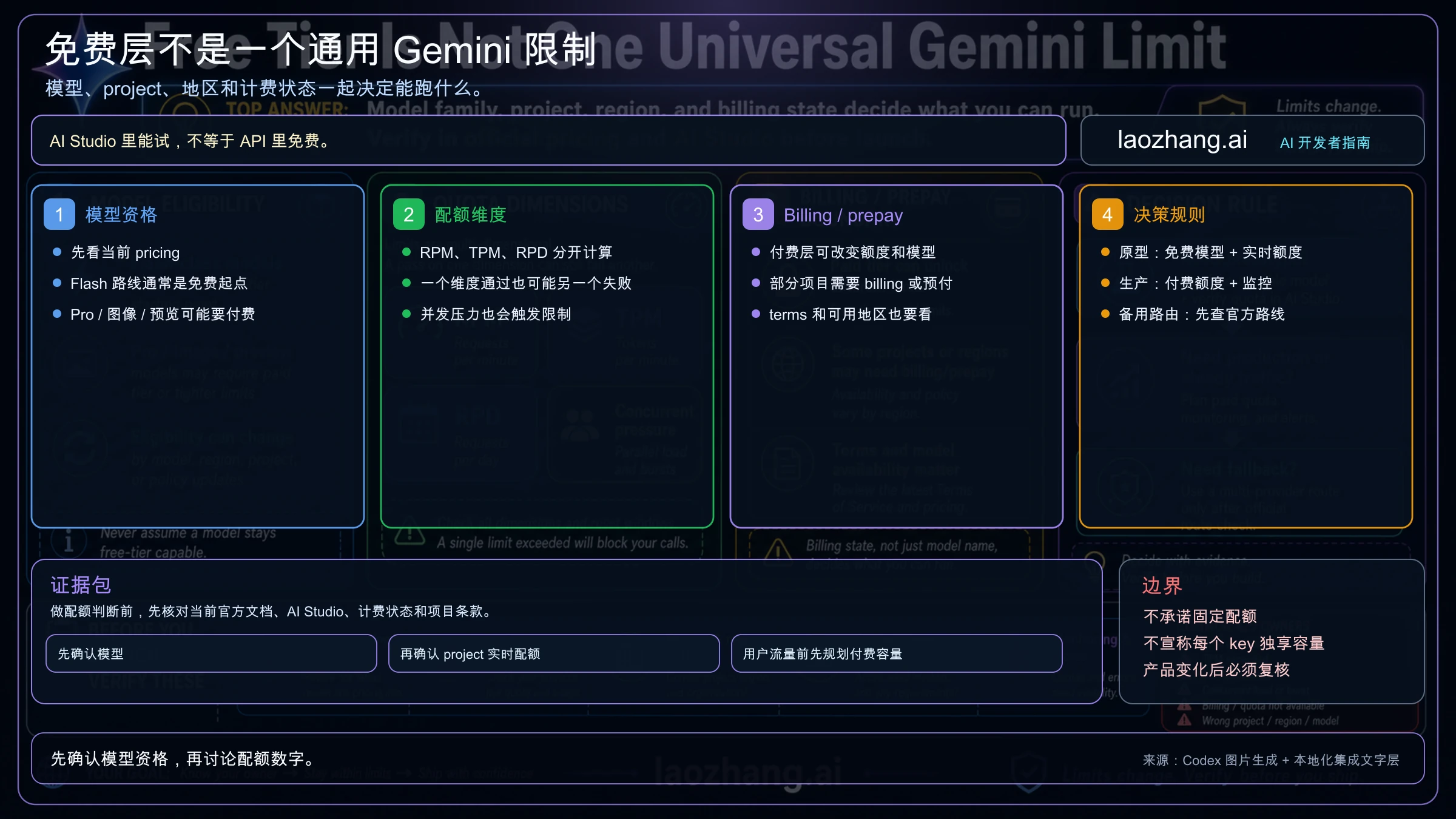
现在 Gemini API 里到底哪些模型还免费?
模型资格是第一道门。如果目标模型本来就没有 Free Tier,后面讨论每分钟多少次请求没有意义。
| 路线 | 免费层状态怎么读 | 实际含义 |
|---|---|---|
gemini-3.1-flash-lite-preview | pricing 当前在多个 serving mode 里列出 free input/output。 | 适合成本敏感的文本、多模态和高频原型,但 preview 限额会更紧、更易变。 |
gemini-3.1-flash-live-preview | Live API 路线当前列出免费输入/输出。 | 这是实时音频/Live API 合同,不等同于普通文本请求。 |
gemini-3-flash-preview | Standard/Priority 当前有 Free Tier,Batch/Flex 不能直接按免费理解。 | 适合一般 3 系能力原型,但 serving mode 会改变资格。 |
gemini-2.5-pro | Standard/Priority 当前有 Free Tier。 | 当 3.1 Pro API paid-only 时,它仍是强推理的免费 fallback。 |
gemini-2.5-flash / gemini-2.5-flash-lite | 当前仍有免费输入/输出路线。 | 适合低风险原型、教学、成本测试和小流量工具。 |
gemini-3.1-pro-preview | Free Tier 显示 Not available。 | AI Studio 试用不等于后端 API 免费调用。需要这条路线时,先读 Gemini 3.1 Pro free API 边界。 |
| Gemini 2.5 Flash Image、图像预览、Imagen、Veo 等路线 | 多数 API 图像/视频路线当前不是 Free Tier。 | 不要把 AI Studio 体验、促销演示和 API 免费后端混成一个结论。 |
这张表故意不是 quota 表。它只回答“有没有资格开始免费评估”。一个模型可以免费合格,但你的 project active limit 仍然很低;一个模型可以出现在 AI Studio 里,但 API 后端仍是 paid-only;一个 preview 模型今天能用,也可能在下一次发布或限额调整后变得更严格。
为什么新 API key 不会增加配额
API key 是访问凭证,quota bucket 属于 project。这个边界必须写在免费层文章前半部分,因为很多人看到 429 后第一反应是“再创建几个 key”。如果这些 key 仍然挂在同一个 Google Cloud project 下,它们只是同一个限额池的多个入口。
只有在真实所有权不同的时候,才应该拆 project:例如 staging 和 production 由不同 billing owner 管理;团队权限、审计和安全边界不同;地区、合规或客户隔离要求不同;或者你确实需要分别监控用量和成本。为了绕过免费层 cap 而拆 project,既不稳定,也容易把诊断做乱。
所以遇到速率限制时,正确问题不是“还能开几个 key”,而是:
- 这个 key 是否属于我以为的 project?
- 这个 project 是否绑定了正确 billing account?
- 目标 model 和 serving mode 是否仍然 free-capable?
- 当前 RPM、TPM、RPD 哪个维度先被打满?
- 这个 workload 是否应该改成 queue、cache、token cap、paid tier 或官方 quota increase?
如果答案已经指向容量问题,就不要用 key rotation 假装修复。
Billing 和预付费可能才是隐藏限制
付费层也不能再简单理解成“绑卡就结束”。Google 的 billing 文档 把 Prepay 和 Postpay 计划拆开,并说明新的 billing plan 系统从 2026 年 3 月 23 日开始生效。
真正需要检查的是:project 是否已经绑定 billing account;AI Studio 是否要求 set up billing 或 set up prepay;billing account 是否还有余额;账户是在 Prepay 还是 Postpay;是否设置 auto-reload;当前 tier 是否支持你期待的容量。Prepay 尤其关键,因为余额归零可能让挂在同一个 billing account 下的 Gemini API 服务一起停掉。
如果你只是想看从 key 创建到 tier 检查的界面路径,可以接着读 Gemini API key 与 Tier 3 指南。对免费层速率限制来说,billing 的角色很清楚:它是容量、数据条款和可持续服务的边界,不是免费层速率限制的魔法开关。
上线前如何确认实时限额
把这套检查当成每次正式原型、demo 或上线前的短流程:
- 打开 pricing 页面,确认目标模型和 serving mode 仍有 Free Tier。
- 打开 AI Studio,切到真正准备调用的 project。
- 在 rate-limit view 里记录 RPM、TPM、RPD,以及模型可能额外出现的维度。
- 确认 project 的 billing 状态、prepay 或 postpay 状态、余额和 billing account tier。
- 记录 model、project、region、billing state、timestamp 和看到的 limit。
- 一旦切换模型、project、region、billing account、serving mode 或流量形态,就重新检查。
这一步看起来很机械,却能避免大多数错误架构。如果 AI Studio 显示 RPD 不足以支撑 demo day,修复不是复制旧表,也不是新建 key,而是排队、换模型、降低输出、转 paid tier 或准备 quota increase。
429 在免费层里真正意味着什么
429 不是“免费层没了”的证据,也不是“立刻付费”这一种答案。它说明某个 owner 先拦住了请求。

| 步骤 | 要确认什么 | 为什么重要 |
|---|---|---|
| 调用面 | 官方 Gemini API、AI Studio UI,还是第三方 provider。 | provider 429 不一定是 Google project quota。 |
| project 与 key | key 所属 project、key restriction、billing account 是否一致。 | 混用 project 会让观察到的 limit 看起来互相矛盾。 |
| model 与 serving mode | model ID、Standard/Batch/Flex/Priority、preview 状态、region。 | 免费资格和限额按模型与模式变化。 |
| AI Studio quota | RPM、TPM、RPD、reset window、usage 和额外维度。 | 这里决定是哪一个 owner 触发。 |
| 降低压力 | 降并发、排队、缓存、缩短 prompt、限制 max output、加入 jittered backoff。 | 真正的 rate-limit 修复通常先改变流量形态。 |
| 带证据升级 | 记录 project、model、时间、当前 limit、用量曲线和已尝试修复。 | 申请提高限额或找支持时,需要事实包。 |
如果你已经确认错误属于更一般的 API 限流,而不是免费资格,可以继续看 Gemini API rate limits guide 和 Gemini API 错误排查指南。
什么时候免费层够用,什么时候不够
免费层适合评估,不适合承诺基础设施。它很适合 prompt exploration、课程示例、低风险 PoC、内部 demo、个人工具、模型比较、早期成本测试和短期 agent 原型。即使是这些场景,也应该从第一天就写 queue、cache、token cap、429 logging 和 backoff。这样以后转付费或换 provider 时,不需要推翻架构。
免费层不适合的场景也很明确:需要 predictable capacity、付费模型、真实客户数据处理、生产支持预期,或者在 EEA、瑞士、英国面向用户提供 API client。Google 的 Gemini API terms 对 unpaid services 和 paid services 的数据使用边界不同;未付费使用可以被用于改进 Google 产品,并可能有人审处理输入输出。对客户数据或正式产品来说,这不是脚注,而是上线边界。
第三方 fallback 应该放在哪里
官方 Google 路线必须先查清楚。只有当你已经知道官方路线无法满足容量、地区、模型、billing、稳定性或兼容性要求时,fallback provider 或多模型网关才有意义。
如果团队需要一个跨 provider 的兼容网关,可以把 laozhang.ai 放在后置评估位:先确认官方 Gemini 模型是否 free-capable,再确认 AI Studio 中这个 project 的真实 quota,再减少可避免的 429,最后决定 paid tier、quota increase 或 provider fallback。不要把 provider 当作当前官方事实的替代品。模型覆盖、价格、延迟、服务范围都属于易变事实,真正切流前要在 provider dashboard 里验证。
上线检查清单

- Pricing 页面确认目标 model 与 serving mode 仍然 free-capable。
- AI Studio 对同一个 project 和 model 显示的 active quota 足够。
- API key 属于预期 project,没有混用 staging、demo 或个人项目。
- billing 状态、prepay 余额和 billing account owner 已经明确。
- 请求代码有 queue、jittered backoff、token cap 和 429 owner logging。
- dashboard 能区分 RPM、TPM、RPD、billing failure 和 provider failure。
- unpaid quota 中发送的数据符合 unpaid-service terms。
- EEA、瑞士、英国用户面向场景走 paid services。
- 用户流量依赖容量前,已经有 paid-tier、quota-increase 或 fallback-route 决策。
FAQ
Gemini API key 还能免费创建吗?
可以。Google AI Studio 仍然能创建 Gemini API key。免费创建 key 不等于每个 key 都有独立免费容量,真正要看 project、model 和 AI Studio active limits。
每个 key 都有自己的免费速率限制吗?
没有。rate-limits 文档写明配额按 project 生效,不按 API key 生效。同一 project 下更多 key 不会创造更多 quota。
我的真实免费层限额在哪里看?
看 AI Studio 的 rate-limit view,并确保选中正确 project 和 model。公开文档解释维度;AI Studio 显示当前 project 的实际限制。
哪些 Gemini 模型现在还能免费 API 调用?
答案随模型和 serving mode 变化。2026 年 5 月 6 日,pricing 页面仍给多个路线列出免费输入/输出,包括 Gemini 3.1 Flash-Lite Preview、Gemini 3.1 Flash Live Preview、Gemini 3 Flash Preview、Gemini 2.5 Pro、Gemini 2.5 Flash 和 Gemini 2.5 Flash-Lite。上线前仍要复核。
Gemini 3.1 Pro API 免费吗?
不免费。pricing 页面把 gemini-3.1-pro-preview 的 Free Tier 标为 Not available。AI Studio 体验不要和后端 API 免费混为一谈。
429 是不是说明免费层被取消了?
通常不是。429 说明某个活跃限制被打满,可能是 RPM、TPM、RPD、突发并发、模型资格、billing、project scope 或 provider route。先查 AI Studio 和日志,再改架构。
免费层能不能用于生产?
适合原型和低风险评估。需要可预测容量、付费数据处理、paid-only 模型、正式用户流量或特定地区合规边界时,应转向 paid services 或更稳定的 route。
实际结论
Gemini API 免费层仍然真实存在,但它不是一张全网通用的静态 quota 表,也不会因为你多开几个 API key 而变多。正确顺序是:pricing 页面判断模型资格,AI Studio 判断当前 project 的 live quota,billing 页面判断容量和 prepay,terms 判断数据使用与地区上线边界。这个顺序比任何复制来的 RPM/RPD 数字更有用,因为它回答的是你的项目今天能不能安全运行,以及上线前到底该改哪一层。