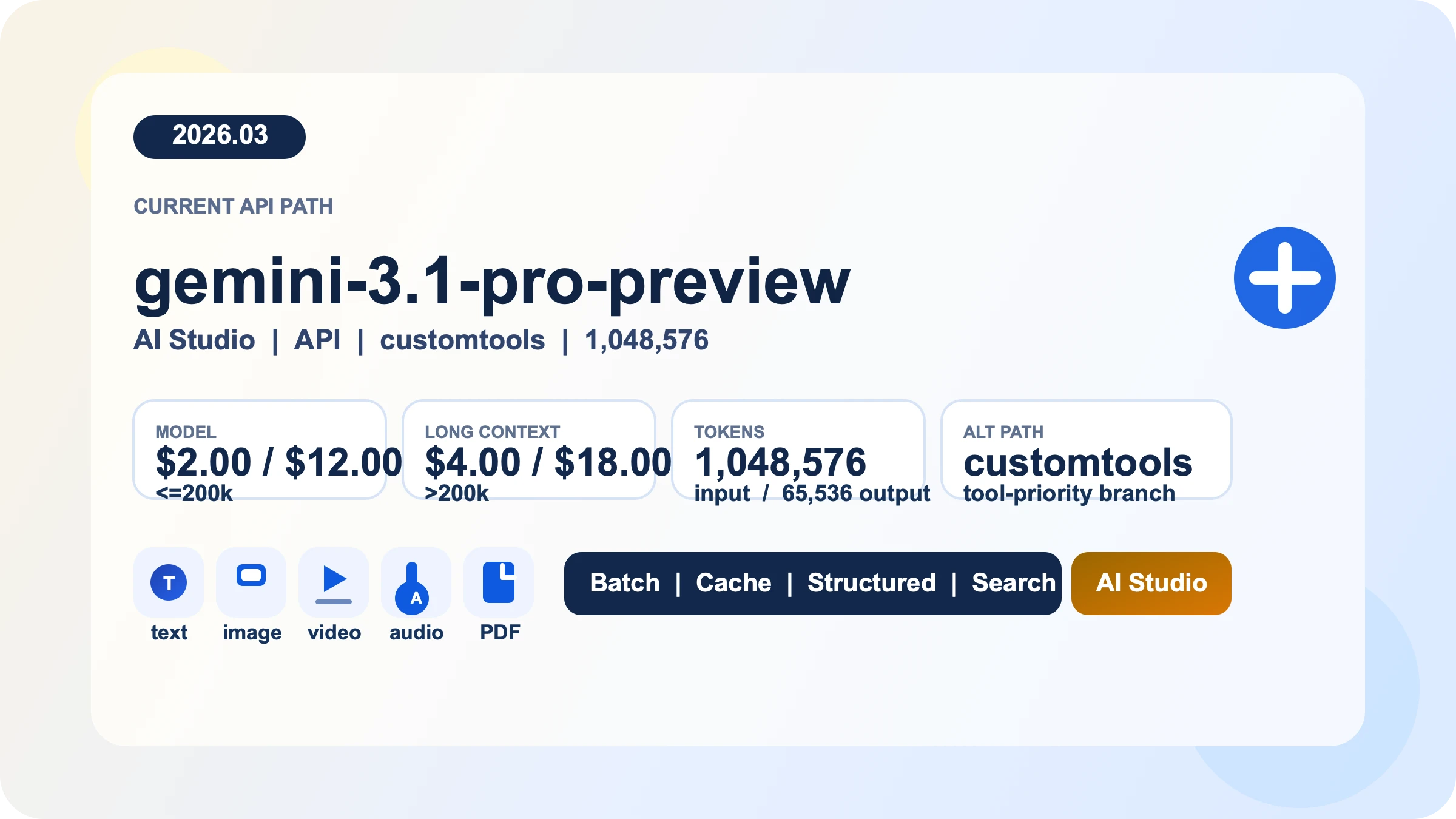
Gemini 3.1 Pro API 是 Google 当前面向长上下文推理、多模态输入和工具型开发工作流的付费 Preview 路径。按 2026 年 3 月 28 日 官方定价,200k tokens 以内标准价为每百万 input $2、output $12,超过 200k 后为 $4 / $18,Batch 价格为标准的一半。根据同日我重新核对的官方文档,当前主模型是 gemini-3.1-pro-preview,旧的 gemini-3-pro-preview 已经停用并指向新模型,同时还新增了适合 bash 与自定义工具混合场景的 gemini-3.1-pro-preview-customtools。如果你的目标不是“看新闻”,而是尽快跑通第一条请求、避开过时 model ID、过时配额表和不必要的成本踩坑,那么你应该从这里开始。
“证据说明:本文基于 Google 的 Gemini 3.1 Pro 模型页、定价页、rate limits 页、API key 指南、OpenAI compatibility 文档、Gemini 3 developer guide 和 release notes,并已在 2026 年 3 月 28 日复核。
TL;DR
- 默认应使用
gemini-3.1-pro-preview。 - 只有当“工具优先级”本身是工作流问题时,才应改用
gemini-3.1-pro-preview-customtools。 - Gemini 3.1 Pro 的编程 API 访问不是免费的,但你仍然可以先在 Google AI Studio 里验证提示词和行为。
- 在 200k prompt 以内,价格是每百万 input $2.00、output $12.00;超过 200k 后为 $4.00 / $18.00。Batch 为标准价的一半,caching 是真正的成本杠杆。
- 真正属于你项目的 RPM、TPM、RPD 现在应该在 AI Studio 里看,而不是相信被转抄的静态博客表格。
- 如果你还在用
gemini-3-pro-preview,这已经不是“建议升级”,而是迁移任务。
最快跑通 Gemini 3.1 Pro 请求的方式
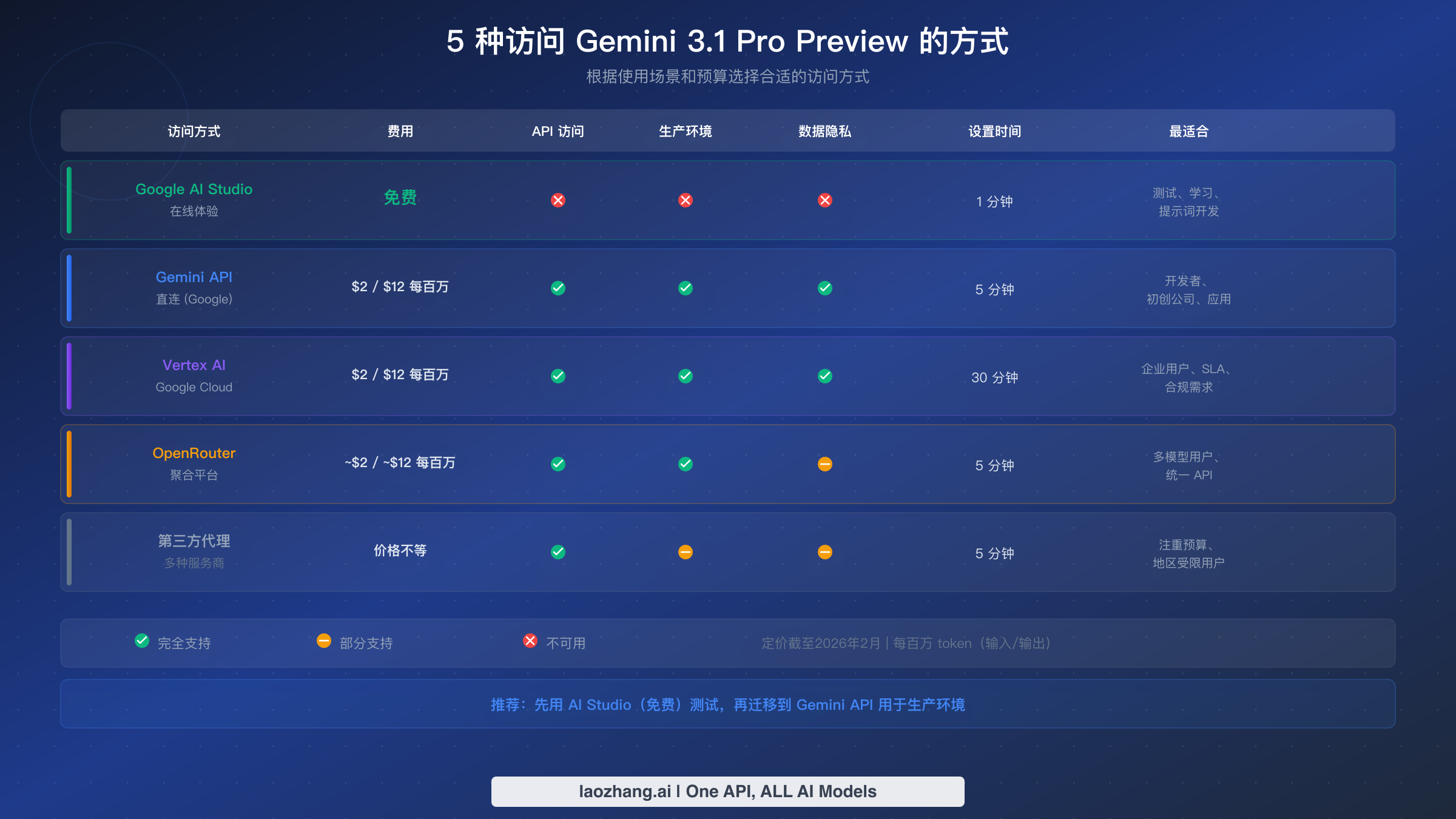
Google 仍然把 Gemini API key 的创建放在 Google AI Studio 里。最实用的顺序很简单:打开 AI Studio,导入或创建要使用的项目,在里面生成 API key,然后在本地设置 GEMINI_API_KEY 或 GOOGLE_API_KEY。Google 的 API key 文档明确写到,官方库会自动读取这两个环境变量,而如果两者同时存在,则 GOOGLE_API_KEY 优先。如果你现在只是想验证提示词表现,先停留在 AI Studio 就够了;如果你要做编程接入,那就先把 billing 接好,不要把 Gemini 3.1 Pro 当成一条“免费 API 路线”来预期。
对大多数团队来说,官方 GenAI SDK 是最干净的默认路径,因为你不用一开始就给自己增加一层额外抽象。Python、JavaScript 和 REST 的最小可用示例如下:
pythonfrom google import genai from google.genai import types client = genai.Client() response = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Review this API design and list the main tradeoffs.", config=types.GenerateContentConfig( thinking_config=types.ThinkingConfig(thinking_level="medium") ), ) print(response.text)
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3.1-pro-preview", contents: "Review this API design and list the main tradeoffs.", config: { thinkingConfig: { thinkingLevel: "medium", }, }, }); console.log(response.text);
bashcurl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Review this API design and list the main tradeoffs."}] }], "generationConfig": { "thinkingConfig": { "thinkingLevel": "medium" } } }'
这里真正重要的不是“能跑”,而是“带着明确的 model 和 reasoning 设定去跑”。Gemini 3 developer guide 说明 Gemini 3.1 Pro 支持 thinking,而且 high 是这个模型族的默认动态等级。如果你把 reasoning 完全交给默认值,其实也等于把延迟和 output token 成本更多地交给默认值。
在优化之前,先选对 model ID
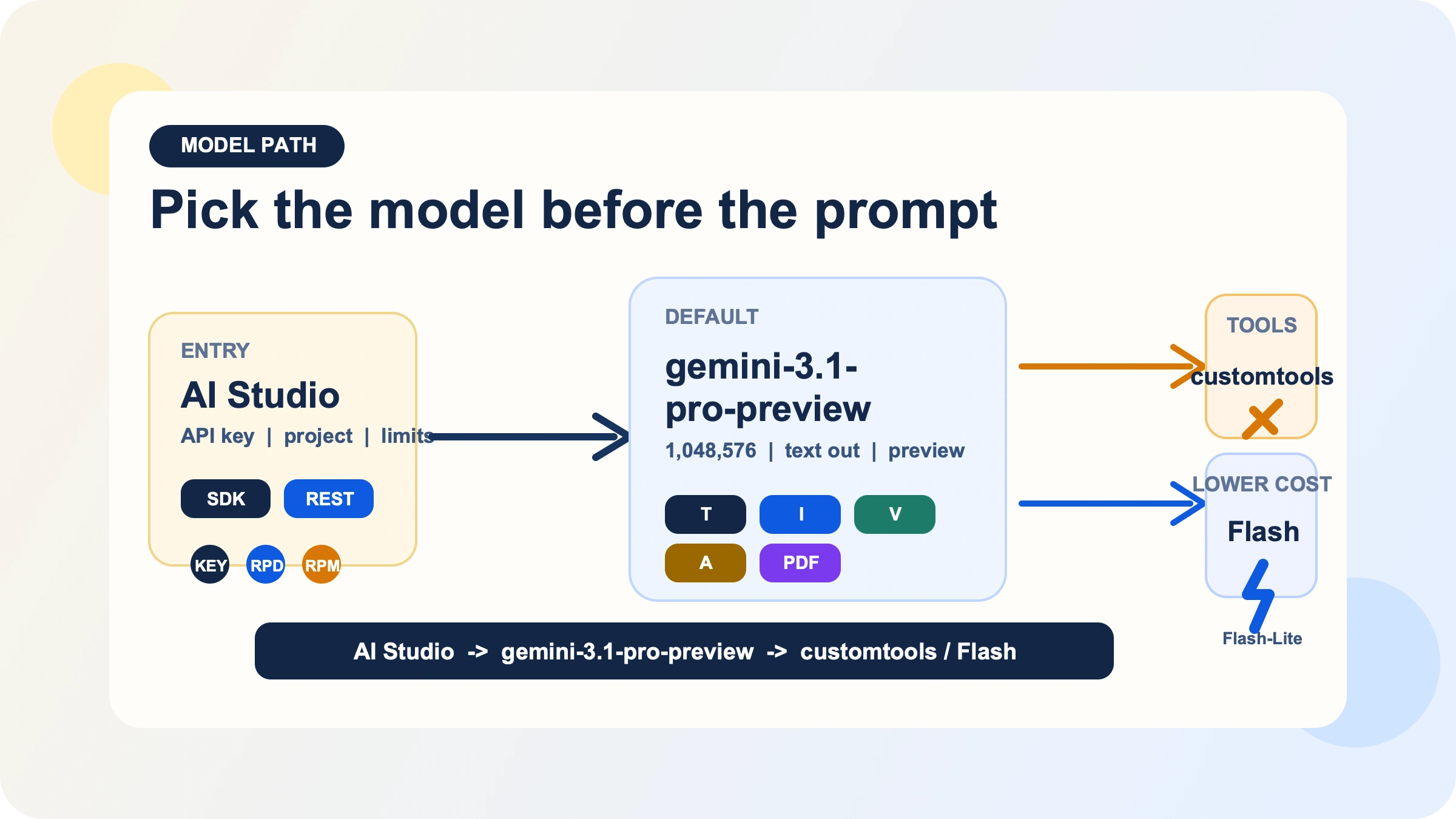
这个阶段最重要的决策不是 prompt engineering,而是模型路径选择。
默认路径是 gemini-3.1-pro-preview。Google 的模型页把它描述为:在 Gemini 3 Pro 系列基础上进一步优化的 Preview 模型,重点提升 thinking、token efficiency,以及软件工程与 agentic workflow 场景下的可靠性。它支持 text、image、video、audio、PDF 输入,输出是 text,并且具备一组对生产很关键的能力:Batch API、caching、code execution、function calling、search grounding、Maps grounding、structured outputs 和 URL context。对于大文档分析、多模态推理、结构化提取以及需要工具调用的工作流,这条路径是成立的。
但同一份模型页也把限制写得很清楚。Gemini 3.1 Pro Preview 不支持 image generation、audio generation 和 Live API。如果你真正的任务是图片输出、实时语音交互,或“尽量便宜地跑高吞吐文本处理”,那你从一开始就不该把 Pro 当默认答案。这种情况下,更合适的通常是 Flash、Flash-Lite、image 或 live 方向的模型。如果你关心的是无成本试验,那么更应该先看我们的 Gemini API 免费额度指南,而不是勉强让 Pro 承担它并不擅长的角色。
第二条路径是 gemini-3.1-pro-preview-customtools。它不是另一个更贵或更长上下文的旗舰,而是一个单独 endpoint,专门面向“既有 bash,又有注册工具”的 agent 场景。Google 模型页明确说它更擅长优先选择你定义的自定义工具,例如 view_file 或 search_code,但同时也提醒:在那些根本不依赖这类工具的用例里,质量可能会出现波动。也就是说,只有当“工具优先级”本身构成你的可靠性问题时,customtools 才是正确答案;如果你主要做的是普通推理、聊天或文档分析,就应留在标准版。如果你需要更深入的判断框架,可以继续看我们单独写的 Gemini 3.1 Pro customtools 指南。
还有一个迁移事实不应再模糊处理。Google 的 release notes 写得很明确:gemini-3-pro-preview 已在 2026 年 3 月 9 日 停用,并指向 gemini-3.1-pro-preview。哪怕 alias 还让旧调用暂时不至于全部失败,新代码也应该显式写当前模型字符串,这样在审计、维护和未来迁移上都更清晰。
不靠猜的定价与限额理解方式

Gemini 3.1 Pro 的定价表面上看并不复杂,真正容易被忽略的是 prompt 大小一旦跨过阈值,价格就变了。根据当前 Google pricing 页,200k tokens 以内的标准价格是:
| 区间 | Input | Output | Batch |
|---|---|---|---|
<=200k | $2.00 / 1M | $12.00 / 1M | $1.00 / $6.00 |
>200k | $4.00 / 1M | $18.00 / 1M | $2.00 / $9.00 |
这个阈值之所以重要,是因为 Gemini 3.1 Pro 的卖点之一正是 1,048,576 tokens 的输入窗口。很多文章只会强调“1M context 很大”,却不继续解释:你一旦真的频繁进入超长上下文区间,账单结构也会变。就实际工程而言,比再看一张 benchmark 表更重要的,通常是以下四个成本杠杆:
- 能不跨过 200k 的常规请求,就尽量别跨。
- 后台异步任务优先考虑 Batch。
- 重复发送的大 system prompt 或大参考上下文,要尽量用 caching。
- 把 thinking level 当成真实的成本控制项,而不是一个可有可无的开关。
Google 的 pricing 页把最容易被忽略的两项费用写得很清楚:context caching 和 grounding。Caching 价格是每百万 tokens $0.20 / $0.40(<=200k / >200k),另加每百万 tokens 每小时 $4.50 的 storage 费用,所以只有在反复复用大块上下文时才划算。Search 与 Maps grounding 共享每月 5,000 prompts 的免费额度(Batch 的免费额度更小),之后按每 1,000 次查询 $14 计费;如果你的工作流不需要实时网页事实,grounding 就会变成可避免的成本放大器。
限额则需要另一种理解方式。Google 的 rate limits 页面现在明确写到:实际 API limits 取决于 usage tier 和 account 状态,应当在 AI Studio 里查看。这意味着任何博客,包括这篇文章,都不应该再假装自己能为你的项目写死最终 RPM。官方文档目前仍然明确的,是这些基础规则:
- rate limiting 主要看 RPM、TPM、RPD
- 配额按 project 计,而不是按 API key 计
- RPD 在 Pacific 午夜重置
- preview 模型的限额更严格
- 你的 active limits 在 AI Studio 里看
同一页还解释了 tier 的基本升级路径:Tier 1 从启用并绑定 billing 开始,Tier 2 需要已有付费使用与一定时间,Tier 3 则需要更高累计消费与更长历史。如果你真的在做容量规划,就应该用官方 rate limits 页理解规则,再回到 AI Studio 看真正作用于自己项目的数字。
还有一个 3 月中旬后很有价值的细节:Google 的 release notes 说明,AI Studio 在 2026 年 3 月 12 日 引入了 project-level spend caps。如果你准备让团队正式接入 Gemini 3.1 Pro,又不想第一批超长上下文任务直接把预算打穿,这个设置值得先配上。
真正影响成本和延迟的,是 thinking、长上下文与缓存
Gemini 3.1 Pro 不是那种“API 长得不复杂,所以可以无脑默认”的模型。Gemini 3 developer guide 说明,Gemini 3.1 Pro 支持 low、medium、high 三档 thinking level,且 high 是默认动态等级。它也明确指出:你不能在同一个请求里同时使用 thinking_level 和旧的 thinking_budget,否则会返回 400。这个限制并不只是语法细节,它意味着从旧版 Gemini 流程迁移过来时,参数必须显式清理,而不是半改半不改。
我的实践建议是:把 medium 当作日常工作的第一默认值,然后按任务复杂度往下或往上调。这个建议是基于官方文档行为和定价关系做出的工程推断,不是 Google 的逐字规定,但它通常更符合生产环境。对于抽取、分类、短文本转换等任务,low 往往是更稳妥的第一选择;而当你真正使用 Gemini 3.1 Pro 来做复杂分析、大代码库审阅或多步推理时,high 才更有理由被显式打开。关键不是“高级一定更强”,而是“你要知道自己为什么在为更高 reasoning 和更长延迟付费”。
长上下文同样如此。1M token 窗口是真实存在的,它也是 Gemini 3.1 Pro 值得被考虑的重要原因之一。但工程问题不是“能不能塞进去”,而是“我是否需要高频为这类上下文付费,以及其中哪些部分应该先被缓存或摘要化”。如果你每次请求都重复发送一大段不变的 system prompt、文档包或 repo 上下文,最贵的路径往往正是最懒的路径。
如果你想更深入理解 Google 的 thinking 控制怎么映射到不同任务,可以继续看我们单独写的 Gemini 3.1 Pro thinking level 指南。但作为这篇总指南,你只需要先记住三点:reasoning 要显式设定,200k 阈值要始终放在脑中,长上下文绝不能因为模型支持就被默认滥用。
如果你之前用的是 Gemini 3 Pro Preview 或 OpenAI SDK,该怎么迁移
如果你之前用的是 Gemini 3 Pro Preview,那么迁移结论其实很直接。Google 的 2026 年 3 月 9 日 release notes 已经写明:该模型已停用,而 gemini-3-pro-preview 现在指向 gemini-3.1-pro-preview。更合理的做法是:把代码里的 model string 显式改为当前值,顺手检查你对 thinking 行为的假设,并判断工作负载应继续留在标准版,还是应该改走 -customtools。
如果你的团队已经深度使用 OpenAI SDK,那么 Google 的 OpenAI compatibility 层就是最省改动的桥接方式。官方文档说明,Gemini 模型可以通过 OpenAI 的 Python 或 JavaScript 库访问,核心只需要改三处:API key、base URL 和 model 名称。对于想先在既有 OpenAI client 栈中试用 Gemini 的团队,这条路线非常实用。
pythonfrom openai import OpenAI client = OpenAI( api_key="GEMINI_API_KEY", base_url="https://generativelanguage.googleapis.com/v1beta/openai/" ) response = client.chat.completions.create( model="gemini-3.1-pro-preview", reasoning_effort="medium", messages=[ {"role": "user", "content": "Summarize the migration risks in this API design."} ] ) print(response.choices[0].message.content)
这份 compatibility 文档还有一个很实用的地方:它把 OpenAI 的 reasoning_effort 映射到了 Gemini 的 reasoning 控制。minimal 和 low 会映射到 Gemini low,medium 对应 medium,high 对应 high。规则和原生接口上一样:不要在同一个请求里叠加两套功能重合的 reasoning 控制。如果你已经通过 OpenAI 兼容层使用 reasoning_effort,就不要再额外塞一份 Gemini thinking 配置,除非官方文档明确说明该路径支持。
这也是你审视旧教程的最佳时点。处于 preview 阶段的模型家族,表面看起来“只是一个 model name 变了”,但实际更危险的是一整套参数和成本假设会一起漂移。更稳妥的路径是:统一使用当前模型字符串,重新核对成本假设,再在 AI Studio 里用几条代表性 prompt 做一次回归验证,然后再把请求切进生产。
什么时候应该用 Gemini 3.1 Pro,什么时候不该用
当你的工作负载同时真正需要三件事时,Gemini 3.1 Pro 才是对的:强推理、长上下文和工具感知的多模态表面。这种组合非常适合大文档审阅、大代码库分析、复杂输入上的结构化抽取,以及需要 code execution、function calling、grounding 或 URL context 的 agent 工作流。它也适合那些能接受付费 Preview 模型现实约束的团队,包括更严格的限额和更频繁的行为变化。
如果你的 agent 同时有 bash 和注册工具,且问题核心是“模型到底优先用哪个工具”,那就该考虑 gemini-3.1-pro-preview-customtools。如果延迟和预算敏感性比旗舰级 reasoning 更重要,就优先考虑更便宜的 Flash 或 Flash-Lite 路径。如果你需要的是 image generation 或 live audio,就直接换模型家族。至于“我只想找一个免费的 API 先试”,那一开始就不该把 Pro 当作默认答案,这种场景下更应该先看 Gemini API 免费额度指南 和 Gemini API Rate Limits 指南。
如果你正在同时比较 Gemini、OpenAI 和 Claude,并且希望把路由放在一层统一网关后面,那么像 laozhang.ai 这样的服务会有实际价值,因为它能减少认证和结算碎片化。但真正该检查的不是“是否列出了模型名称”,而是“是否透传了你真正依赖的变体与能力”,尤其当你需要 preview 行为或 customtools 路径时。
实际结论并不复杂。只有当你的任务真正需要 Gemini 3.1 Pro 这套形状时,它才值得用。如果你的真实工作是“快、便宜、高吞吐的文本处理”,不要因为发布周期的热度就默认上 Pro;如果你的真实工作是“一个超大多模态上下文 + 结构化输出 + grounding + 可靠多步执行”,那么 Gemini 3.1 Pro 的确是当前很强的一条路线。
FAQ
Gemini 3.1 Pro API 免费吗?
不免费。Google 当前 pricing 页明确显示 Gemini 3.1 Pro Preview 没有 free API tier。你可以在 AI Studio 里先试,但编程调用是付费的。
gemini-3-pro-preview 现在还能用吗?
它已在 2026 年 3 月 9 日停用。Google 的 release notes 说明该旧模型现在会指向 gemini-3.1-pro-preview,但新代码应显式写当前模型名。
是不是所有项目都应该用 gemini-3.1-pro-preview-customtools?
不是。只有当 custom-tool 优先级本身是问题时,它才值得单独使用。Google 模型页也明确提醒,在不依赖这类工具的场景里,它可能出现质量波动。
真正属于我的 RPM、TPM、RPD 去哪里看?
去 AI Studio。Google 的 rate limits 页现在明确让用户在那里看 active limits,因为容量取决于 tier 和 account 状态。
能不能用 OpenAI SDK 调 Gemini 3.1 Pro?
可以。Google 的 OpenAI compatibility 文档说明,只要改 API key、base URL 和 model 名称即可。
Gemini 3.1 Pro 支持图片生成或 Live API 吗?
不支持。当前模型页把 image generation、audio generation 和 Live API 都列为 unsupported。