
Claude Opus 4.6 于 2026 年 2 月 5 日发布,是 Anthropic 迄今为止最强大的模型,支持 100 万 Token 上下文窗口和 128K 输出——API 价格与前代相同,仍为每百万 Token $5/$25。但这个标题数字只是故事的一部分。快速模式收费高出六倍,长上下文请求使输入价格翻倍,而仅限美国的数据驻留还会在所有费用之上额外加收 10%。无论你是在 API 和 Claude Pro 订阅之间做选择,还是在扩展生产应用,或者将 Claude 与 GPT-5 和 Gemini 2.5 Pro 进行对比,本指南都会为你提供所需的每一个数字,以及五种切实可行的策略来控制支出。
要点速览
Opus 4.6 标准 API 定价为每百万 Token 输入 $5 / 输出 $25(Anthropic 官方定价,2026 年 2 月)。订阅方案从免费版($0)到 Max 20x($200/月)不等。关键省钱方式:Batch API 节省 50%,提示缓存在缓存读取上最多节省 90%,跨 Haiku-Sonnet-Opus 的智能模型混合可将平均成本降低 60-80%。完整的速率限制、隐藏费用和方案选择决策树详见下文。
Claude Opus 4.6 API 定价:所有模型一览
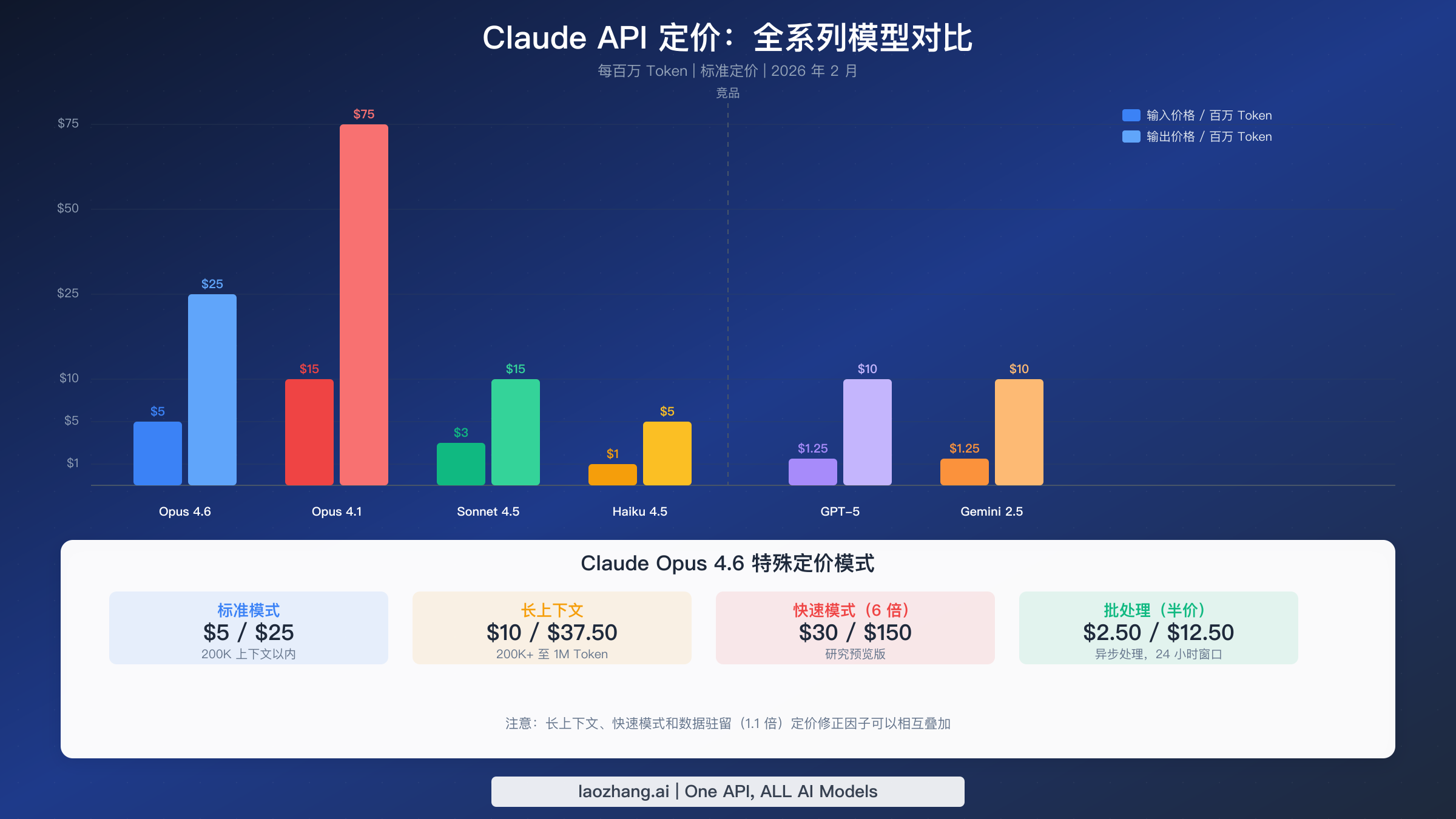
Anthropic 的模型产品线分为三个层级,针对不同的成本-性能权衡而设计。了解 Opus 4.6 在整个产品系列中的定位,是做出明智购买决策的第一步。下表反映的定价直接来自 Anthropic 官方定价页面,数据截至 2026 年 2 月。
| 模型 | 输入(每百万 Token) | 输出(每百万 Token) | 上下文窗口 | 最佳用途 |
|---|---|---|---|---|
| Claude Opus 4.6 | $5.00 | $25.00 | 200K(1M 测试版) | 复杂推理、编程、研究 |
| Claude Opus 4.5 | $5.00 | $25.00 | 200K(1M 测试版) | 同价格,上一代 |
| Claude Opus 4.1 | $15.00 | $75.00 | 200K | 旧版,贵 3 倍 |
| Claude Sonnet 4.5 | $3.00 | $15.00 | 200K(1M 测试版) | 速度与质量的平衡 |
| Claude Sonnet 4 | $3.00 | $15.00 | 200K(1M 测试版) | 上一代 Sonnet |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K | 快速任务、分类、提取 |
| Claude Haiku 3.5 | $0.80 | $4.00 | 200K | 预算选项 |
这里真正重要的定价变化在于代际跨越。 Opus 4.1 和 Opus 4 的定价为每百万 Token $15/$75——是 Opus 4.6 的三倍。Anthropic 在将 Opus 层级价格降低 67% 的同时,有效实现了重大性能升级。如果你仍在使用 Opus 4.1,切换到 Opus 4.6 可以立即省钱,同时获得更好的结果。关于 Claude Opus 与 Sonnet 模型的详细对比,包括基准测试分数和使用场景建议,请参阅我们的专题对比指南。
提示缓存倍率 适用于所有模型,使用相同的比率。五分钟缓存写入费用为基础输入价格的 1.25 倍,一小时缓存写入为 2 倍,而缓存读取仅为 0.1 倍。对于 Opus 4.6 而言,这意味着缓存读取从每百万 Token $5.00 降至 $0.50——当你反复处理相同的文档或系统提示时,这个细节变得至关重要。
订阅方案对比:免费版 vs Pro vs Max vs Team
Anthropic 为偏好固定月费(而非按 Token 付费的 API 计费)的用户提供了六种不同的订阅层级。每个层级逐步解锁更多用量、模型访问权限和协作功能。以下是基于 claude.com/pricing 的完整对比。
| 功能 | 免费版 | Pro | Max 5x | Max 20x | Team 标准版 | Team 高级版 |
|---|---|---|---|---|---|---|
| 价格 | $0 | $20/月(年付 $17) | $100/月 | $200/月 | $25/席位/月(年付 $20) | $125/席位/月(年付 $100) |
| 用量 | 30-100 条消息/天 | 约 5 倍免费版 | 约 25 倍免费版 | 约 100 倍免费版 | 约 1.25 倍 Pro | 约 6.25 倍 Pro |
| 模型 | Sonnet、Haiku | 全部(含 Opus) | 全部 | 全部 | 全部 | 全部 |
| Claude Code | 否 | Web + CLI | 完整 | 完整 | 否 | 完整 |
| 扩展思考 | 否 | 是 | 是 | 是 | 是 | 是 |
| 优先访问 | 否 | 高峰期优先 | 最高优先 | 零延迟保证 | 标准 | 优先 |
| 最少席位 | - | - | - | - | 5 | 5 |
| SSO/管理 | 否 | 否 | 否 | 否 | 是 | 是 |
免费版适合轻度体验,但每天 30-100 条消息的上限以及无法访问 Opus 使其不适用于专业用途。消息配额按滚动方式重置(大约每 4-8 小时,取决于服务器负载),而包含大型附件的大量对话可能在一次会话中就耗尽你的配额。免费版也无法使用 Claude Code 或扩展思考功能,限制了其在开发工作流中的效用。
Pro 版每月 $20 是个人专业用户的最佳选择。 你可以访问包括 Opus 4.6 在内的所有 Claude 模型,在网页和终端模式下使用 Claude Code,利用扩展思考处理复杂问题,并获得大约五倍于免费版的消息配额。年付选项为每月 $17,节省 15%,全年可省下 $36——如果你计划使用 Claude 超过几个月,这是值得的。Anthropic 没有公布 Pro 版的精确消息限制,而是使用根据服务器负载和对话复杂度动态调整的上限。
Max 方案是为持续达到 Pro 限制的重度用户设计的。 Max 5x 每月 $100,提供大约 25 倍于免费版的容量,在正常条件下相当于每天约 2,000-2,500 条消息。Max 20x 每月 $200,将此数量推至每天约 8,000-10,000 条消息,单个用户几乎不可能用完。两个 Max 层级都包含新功能的优先体验资格以及流量高峰期的最高优先级。如果你通过 Claude 运行自动化工作流或每天编程 8 小时以上,Max 是合理的选择。否则,Pro 可以舒适地处理大多数专业工作负载。
Team 方案在个人用量基础上增加了协作和管理功能。 标准席位每月 $25,提供大约 1.25 倍 Pro 级别的用量,加上 SSO、集中计费、管理控制台和域名捕获。高级席位每月 $125,将用量提升至 Pro 的 6.25 倍,并包含完整的 Claude Code 访问权限和终端集成——本质上将 Max 级别的个人用量与 Team 级别的治理功能结合在一起。团队方案最少需要五个席位。企业方案则通过 Anthropic 的销售团队协商自定义定价、用量级别、HIPAA 就绪配置、审计日志、SCIM 配置和合规 API。
大多数指南忽略的隐藏费用
Opus 4.6 每百万 Token $5/$25 的标题价格仅适用于 200K Token 上下文窗口内的标准请求。几个定价修正因子可能会显著增加你的实际成本,而且它们之间可以叠加。在承诺某个工作负载之前了解这些倍率,可以避免预算意外。
快速模式收取 6 倍溢价。 Opus 4.6 提供研究预览版的快速模式,优先考虑输出速度,价格为每百万 Token 输入 $30 / 输出 $150。对于快速模式下超过 200K 输入 Token 的请求,价格进一步跳升至每百万 Token $60/$225。快速模式适用于对延迟敏感的应用,如实时编程助手或交互式代理,但在对速度无要求的批处理工作负载中使用它是一个昂贵的错误。快速模式不可通过 Batch API 使用,因此无法与 50% 的批处理折扣叠加。
长上下文定价使输入费用翻倍。 当你启用 100 万 Token 上下文窗口测试版并发送超过 200K 输入 Token 的请求时,该请求中的所有 Token——不仅仅是超过 200K 的部分——都按溢价费率计费:每百万 Token 输入 $10 / 输出 $37.50。200K 阈值仅计算输入 Token(包括缓存读取和写入);输出 Token 数量不影响适用哪个定价层级。长上下文定价目前仅对 Tier 4 组织和拥有自定义速率限制的组织开放。
仅限美国的数据驻留额外加收 10%。 从 Opus 4.6 开始,指定 inference_geo: "us" 以保证仅在美国处理,会对所有 Token 类别产生 1.1 倍的乘数。这适用于输入 Token、输出 Token、缓存写入和缓存读取。如果你不需要保证仅在美国推理,使用默认的全球路由即可完全避免此项费用。无论 inference_geo 设置如何,早期模型不受此乘数影响。
工具使用会增加隐藏 Token。 每个包含工具的 API 请求都会增加系统提示开销。对于所有 Claude 4.x 模型,工具使用系统提示消耗 346 个 Token(auto/none)或 313 个 Token(any/tool),加上你的工具定义、tool_use 块和 tool_result 块的 Token。网页搜索在标准 Token 费用之外每 1,000 次搜索额外收取 $10。代码执行在每个组织每月 1,550 个免费小时之后收费 $0.05/小时。在估算月度预算时,这些工具费用很容易被忽视。
最坏情况的叠加场景 说明了理解修正因子的重要性。考虑一个使用快速模式的 Opus 4.6 请求,指定仅限美国推理,且超过 200K 输入 Token。输入价格变为:基础 $5 x 6(快速)x 2(长上下文)x 1.1(美国)= 每百万输入 Token $66。输出价格:$25 x 6 x 1.5 x 1.1 = 每百万输出 Token $247.50。这分别是标准价格的 13 倍和 10 倍。了解哪些修正因子适用于你的工作负载,对于准确的成本预测至关重要。
真实场景下的月度费用估算
抽象的按 Token 定价只有在转化为真实使用场景的月度账单时才有意义。以下估算使用 Opus 4.6 标准定价(每百万 Token $5/$25),并假设每种使用场景典型的输入和输出 Token 比例。
轻度使用(个人开发者、聊天机器人原型开发): 大约每天 50 万输入 Token 和 10 万输出 Token。月度费用:约 $75 输入($5 x 0.5 x 30)加上 $75 输出($25 x 0.1 x 30)= Opus 4.6 标准 API 每月约 $150。在这个用量级别,$20/月的 Pro 订阅明显更经济——你需要每天生成约 133K 输入 Token 加 44K 输出 Token,API 才会比 Pro 更便宜。对于大多数进行对话或编程任务的个人用户,订阅方案更划算。
中等使用(小团队、生产聊天机器人、内容管道): 大约每天 500 万输入 Token 和 100 万输出 Token。月度费用:$750 输入 + $750 输出 = Opus 4.6 每月 $1,500。通过智能模型混合——将 70% 的请求路由到 Haiku($1/$5)、20% 到 Sonnet($3/$15)、仅 10% 到 Opus($5/$25)——混合成本降至约 $450/月。再加上对重复系统提示的提示缓存,费用可以进一步降低。在这个规模下,API 定价明显优于订阅,优化策略值得投入工程资源。
重度使用(企业应用、大规模数据处理): 大约每天 5000 万输入 Token 和 1000 万输出 Token。优化前月度费用:$7,500 输入 + $7,500 输出 = 仅 Opus 4.6 每月 $15,000。这种规模的企业应组合使用所有可用折扣:Batch API(非紧急任务节省 50%)、提示缓存(缓存读取节省 90%)、模型混合(每请求平均成本节省 60-80%),以及基于用量的企业协商。通过积极优化,团队通常可将 $15,000 的基线降至每月 $2,000-$4,000。
API 与订阅的盈亏平衡点 完全取决于你的使用模式。对于大致达到 Sonnet 质量的文本对话,Pro 订阅与 Sonnet 4.5 API 的盈亏平衡点约在每天 222K 输入 Token 加 44K 输出 Token。低于此阈值,支付 $20/月的 Pro 版。高于此阈值,切换到带优化的 API 计费。对于 Opus 级别的推理,盈亏平衡点更低,因为 Opus 每 Token 成本更高,使得订阅对中等用户相对更有价值。
速率限制与使用层级:完整参考
Anthropic 在四个层级上执行速率限制,随着你的消费增长自动扩展。了解这些限制对生产应用至关重要——在高峰流量期间遇到 429 速率限制错误可能会中断你的服务。下表展示了来自 Anthropic 官方文档 的完整速率限制数据。
| 层级 | 所需充值 | 最大月消费 | Opus 4.x RPM | Opus 4.x ITPM | Opus 4.x OTPM |
|---|---|---|---|---|---|
| Tier 1 | $5 | $100 | 50 | 30,000 | 8,000 |
| Tier 2 | $40 | $500 | 1,000 | 450,000 | 90,000 |
| Tier 3 | $200 | $1,000 | 2,000 | 800,000 | 160,000 |
| Tier 4 | $400 | $5,000 | 4,000 | 2,000,000 | 400,000 |
层级升级是自动且即时的,一旦你达到累计充值阈值即可升级。你不需要联系 Anthropic 或等待批准。但是,你不能在单笔交易中充值超过当前层级的最大充值额(Tier 1:$100,Tier 2:$500,Tier 3:$1,000,Tier 4:$5,000),这可以防止意外过度充值。
Opus 速率限制在所有 Opus 模型之间共享。 发送到 Opus 4.6、4.5、4.1 和 4 的流量从同一个 RPM/ITPM/OTPM 池中消耗。类似地,Sonnet 4.x 限制在 Sonnet 4.5 和 Sonnet 4 之间共享。但 Opus 和 Sonnet 的限制是分开的——你可以同时使用两个模型系列,各自达到其相应的限制。Haiku 4.5 在 Tier 4 提供最高吞吐量:4,000 RPM、4,000,000 ITPM 和 800,000 OTPM。
提示缓存大幅提升你的有效吞吐量。 Anthropic 的速率限制只计算未缓存的输入 Token(input_tokens + cache_creation_input_tokens)到你的 ITPM 限制中。缓存读取不计入。在 80% 缓存命中率和 Tier 4 的 2,000,000 ITPM 限制下,你的有效吞吐量达到每分钟 10,000,000 总输入 Token——是名义限制的五倍。这使得提示缓存不仅是成本优化,更是吞吐量倍增器,对高流量生产应用至关重要。
100 万上下文窗口需要 Tier 4,并配有专用的长上下文速率限制:1,000,000 ITPM 和 200,000 OTPM,与标准限制分开。快速模式也有自己的专用速率限制池,与标准 Opus 限制分开。这些分离设计意味着使用快速模式或长上下文不会消耗你的标准速率限制预算,这有助于混合使用标准和专用请求的架构设计。
如何选择正确的 Claude 方案
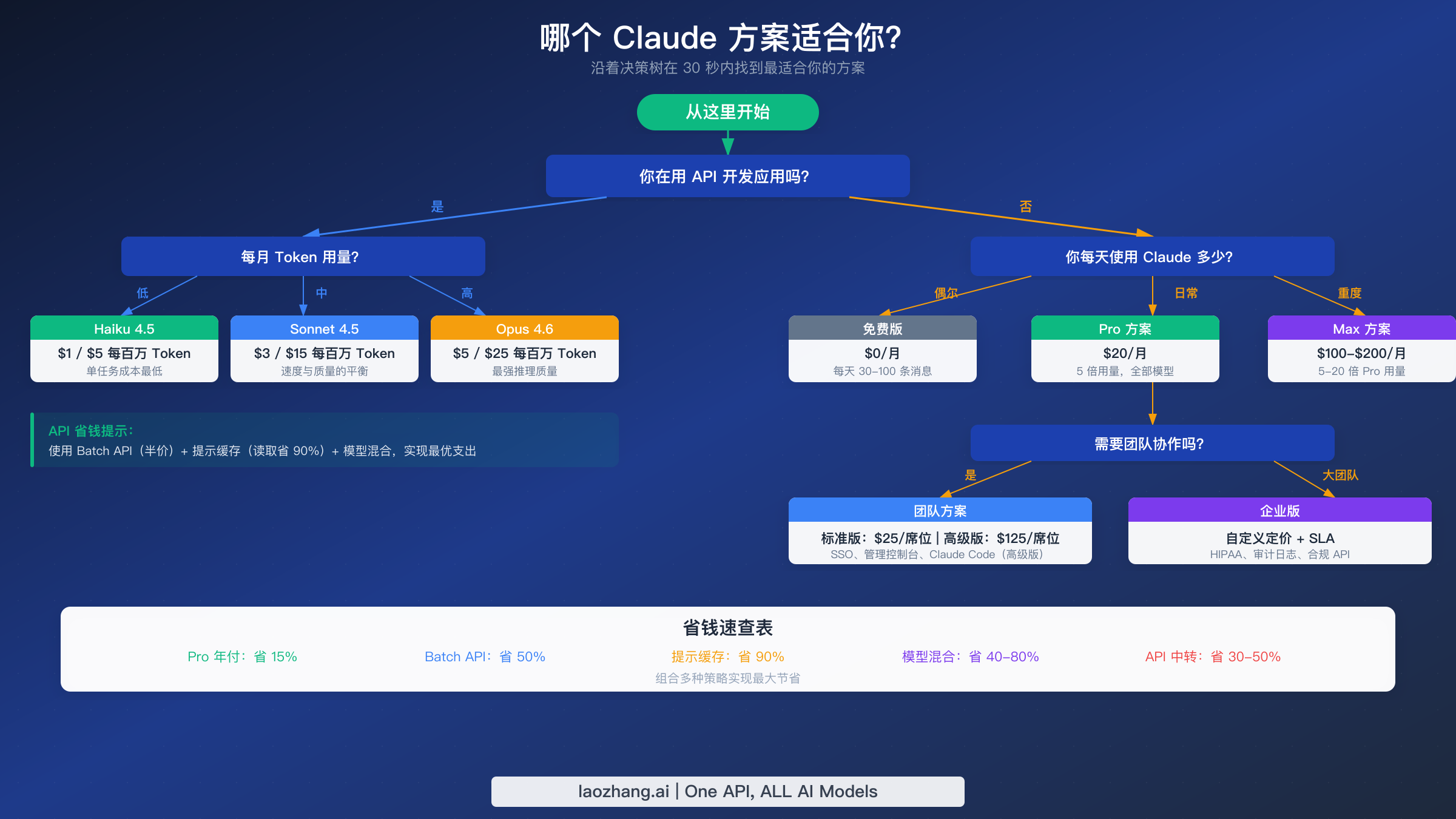
选择正确的方案归结为三个问题:你是在用 API 构建应用还是交互式使用 Claude?你每天使用多少?以及你是否需要团队协作功能?上方的决策树将这些问题映射到具体的建议,以下是每条路径背后的推理。
对于个人交互使用,从 Pro 开始,只有在持续达到限制时才升级。 $20/月的 Pro 方案覆盖绝大多数专业使用场景——写作、编程、分析、研究——无需担心每 Token 成本。如果你发现自己每周超过两次达到使用上限,$100/月的 Max 5x 可以消除这种摩擦。$200/月的 Max 20x 实际上只有在你通过 Claude 界面运行自动化工作流或每天编程 10 小时以上并大量使用 Opus 时才有必要。年付折扣(Pro 为 15%,Team 方案同样适用)计算起来很简单:如果你计划使用 Claude 三个月以上,年付更省钱。
对于基于 API 的应用,模型选择比方案选择更重要。 API 不需要订阅——你从 $5 开始直接为账户充值即可获得 Tier 1。关键决策是默认使用哪个模型层级。Haiku 4.5 每百万 Token $1/$5,以 Opus 五分之一的成本处理分类、提取和简单生成任务。Sonnet 4.5 每百万 Token $3/$15,为大多数生产用途提供强大的推理和编码能力。将 Opus 4.6 每百万 Token $5/$25 留给其卓越推理真正重要的任务:复杂代码生成、多步骤研究和代理编排。构建一个根据任务复杂度将请求发送到正确模型的路由层,是 API 用户最具影响力的成本优化。
对于团队,标准版与高级版的决策取决于 Claude Code。 如果你的开发人员需要基于终端的 Claude Code 访问(用于编码、调试和仓库级分析),$125/席位/月的 Team 高级版是唯一包含此功能的团队层级。如果你的团队主要通过 Web 界面使用 Claude 进行内容、分析和沟通任务,$25/席位的 Team 标准版每席位每月节省 $100。5 席位的最低要求意味着你的最低团队承诺为标准版每月 $125 或高级版每月 $625。
五种经过验证的方法让 Claude 费用减半

降低 Claude 支出不是要减少使用——而是要更智能地使用。以下五种策略可以单独应用或组合使用以获得最大效果。每种策略都包含具体的节省百分比和最能发挥价值的使用场景。
策略 1:提示缓存可在重复上下文上节省高达 90%。 每次你发送相同的系统提示、工具定义或参考文档时,你都按全价支付输入费用。启用提示缓存后,后续请求读取缓存内容仅需基础费率的 10%——对于 Opus 4.6 而言,是每百万 Token $0.50 而非 $5.00。初始缓存写入对于 5 分钟 TTL 的费用为 1.25 倍,对于 1 小时 TTL 为 2 倍,但节省效果随用量迅速复合增长。一个每天处理 10,000 个请求的客服应用,使用共享的 2,000 Token 系统提示,仅在系统提示 Token 上每天就节省约 $2.70——一项优化每月节省 $81。提示缓存还不计入你的 ITPM 速率限制,实质上免费增加了你的吞吐量。
策略 2:批处理提供固定 50% 折扣。 Batch API 在 24 小时窗口内以标准价格的一半异步处理请求。Opus 4.6 批处理定价降至每百万 Token $2.50/$12.50。这对于内容生成、数据提取、分类管道、文档摘要以及任何不需要实时响应的工作负载非常理想。批处理折扣与长上下文定价和数据驻留乘数叠加,因此即使是溢价请求也能受益。你无法将批处理与快速模式结合使用,但由于这两者服务于相反的使用场景(延迟容忍 vs. 延迟敏感),这很少构成限制。
策略 3:智能模型混合将平均成本降低 60-80%。 并非每个请求都需要你最强大的模型。构建一个根据任务复杂度将请求分配给 Haiku、Sonnet 或 Opus 的路由层,是多请求应用中最具影响力的优化。典型的企业模式:将 70% 的流量(简单查询、分类、提取)路由到 Haiku 4.5($1/$5),20%(起草、中等分析)发送到 Sonnet 4.5($3/$15),仅 10%(复杂推理、代码生成)保留给 Opus 4.6($5/$25)。混合平均值约为每百万 Token $1.60/$7.50——相比全 Opus 定价降低 68%。路由逻辑可以简单到基于关键词的规则,也可以复杂到使用轻量级分类器对任务复杂度评分。
策略 4:Token 优化将消耗减少 20-40%。 除了模型级别的定价之外,每个请求的原始 Token 数量也会影响你的账单。编写简洁的系统提示,避免重复指令。将 max_tokens 设置为合理值而非最大值,因为 OTPM 速率限制基于此参数进行估算。使用 effort 参数(Opus 4.6 可用:low、medium、high、max)来控制模型执行多少内部推理——更低的 effort 意味着更少的思考 Token 和更快的响应,适用于简单任务。截断对话历史,仅包含最近相关的轮次而非完整线程。
**策略 5:API 中转服务提供额外 30-50% 的节省。中转服务处理认证、负载均衡和故障转移,无需管理跨提供商的多个 API 密钥和计费账户。
组合这些策略可以产生显著效果。 考虑一个每月在 1000 万 Token 全 Opus 标准定价上花费 $2,500 的工作负载。应用模型混合(70/20/10 Haiku/Sonnet/Opus)将其降至约 $1,000。为非紧急任务添加批处理(假设占 50% 的用量)降至 $500。在剩余的实时请求上叠加提示缓存,总费用降至约 $250/月——从起点减少 90%。即使部分采用两到三种策略,通常也能实现 50-70% 的节省。
Claude Opus 4.6 vs GPT-5 vs Gemini 2.5 Pro:性价比大比拼
在三大领先 AI 模型之间做选择,需要对比的不仅是标价,还有每一美元能获得什么。下表使用截至 2026 年 2 月的 Anthropic、OpenAI 和 Google 的定价数据。
| 维度 | Claude Opus 4.6 | GPT-5 | Gemini 2.5 Pro |
|---|---|---|---|
| 输入价格 | $5.00/百万 Token | $1.25/百万 Token | $1.25/百万 Token |
| 输出价格 | $25.00/百万 Token | $10.00/百万 Token | $10.00/百万 Token |
| 上下文窗口 | 200K(1M 测试版) | 400K | 1M(2M 测试版) |
| 最大输出 | 128K Token | 64K Token | 64K Token |
| 批处理折扣 | 50% | 50% | 50% |
| 免费层级 | 有限(API 额度) | 有限 | 有(带速率限制) |
| 编程基准测试 | 最高(Terminal-Bench 2.0) | 强 | 强 |
| 推理能力 | 最高(GDPval-AA、HLE) | 接近持平 | 良好 |
就原始每 Token 成本而言,Opus 4.6 贵 4 倍。 GPT-5 和 Gemini 2.5 Pro 的定价均为每百万 Token $1.25/$10,使其每 Token 价格显著低于 Opus 4.6 的 $5/$25。对于模型质量差异不大的工作负载——简单分类、基础提取、模板化生成——GPT-5 或 Gemini 提供更好的成本效率。
就每单位质量的成本而言,差距显著缩小。 Opus 4.6 在 GDPval-AA 基准测试中以约 144 Elo 分领先 GPT-5,并在 Terminal-Bench 2.0 和 Humanity's Last Exam 上取得最高分。对于复杂编程任务、多步骤研究和代理编排,Opus 4.6 通常能在更少的迭代中完成任务——意味着尽管每 Token 价格更高,但总 Token 消耗更少。一个 Opus 一次完成的任务,较便宜的模型可能需要三次尝试,从而逆转了成本优势。
上下文窗口和输出长度是差异化因素。 Opus 4.6 支持 128K 输出 Token,是 GPT-5 和 Gemini 目前提供的两倍,使其成为长文本生成任务的明确选择。Gemini 2.5 Pro 在原始上下文窗口大小上领先,提供 2M 测试版选项。GPT-5 的 400K 上下文窗口介于两者之间。如果你的工作负载涉及处理超长文档,Gemini 慷慨上下文的免费层级可能是最具成本效益的起点。
实际建议不是只选一个模型。 使用可迁移架构,根据任务需求在提供商之间路由。将复杂推理发送到 Opus,大量简单任务发送到 GPT-5 或 Gemini(均为 $1.25/$10),延迟敏感的请求发送到响应最快的模型。这种多提供商方式——通过具有统一 API 端点的中转服务轻松实现——让你获得所有三个生态系统的最佳优势,同时在整体上保持成本优化。
充分利用你的 Claude 投资
2026 年的 Claude 定价体系提供了比以往更多的选择,这既是机遇也是挑战。核心决策框架很简单。以对话方式与 Claude 交互的个人用户应从 $20/月的 Pro 订阅开始,只有在持续达到限制时才升级到 Max。API 开发者应仔细选择默认模型层级——Haiku 用于简单任务、Sonnet 用于均衡工作负载、Opus 用于复杂推理——并在投入更高速率限制层级之前,先投资提示缓存和批处理。团队应评估 Claude Code 访问权限是否值得从标准版升级到高级席位。
本指南的隐藏费用部分值得在任何重大部署前重新审阅。快速模式为标准价格的 6 倍、长上下文为 2 倍输入费用、数据驻留为 1.1 倍——这些都是可以叠加的乘数。在最坏情况下,单个请求的成本可达标题价格的 13 倍。从第一天起就在应用中构建成本监控——使用 API 响应中的 usage 对象和 Claude Code 中的 /cost 命令——可以在意外费用出现在发票上之前预防问题。
最后,请记住 Claude 定价在上下文中是有竞争力的。Opus 4.6 每 Token 价格高于 GPT-5 或 Gemini 2.5 Pro,但其基准测试领先的推理能力意味着你通常需要更少的 Token 来完成相同的任务。最具成本效益的方法很少是"所有事情都用最便宜的模型"——而是将模型能力匹配到任务复杂度,同时应用上述优化策略。通过提示缓存、批处理、模型混合和智能 Token 管理,团队通常可以在不牺牲输出质量的情况下,相比朴素的全 Opus 定价实现 50-90% 的节省。