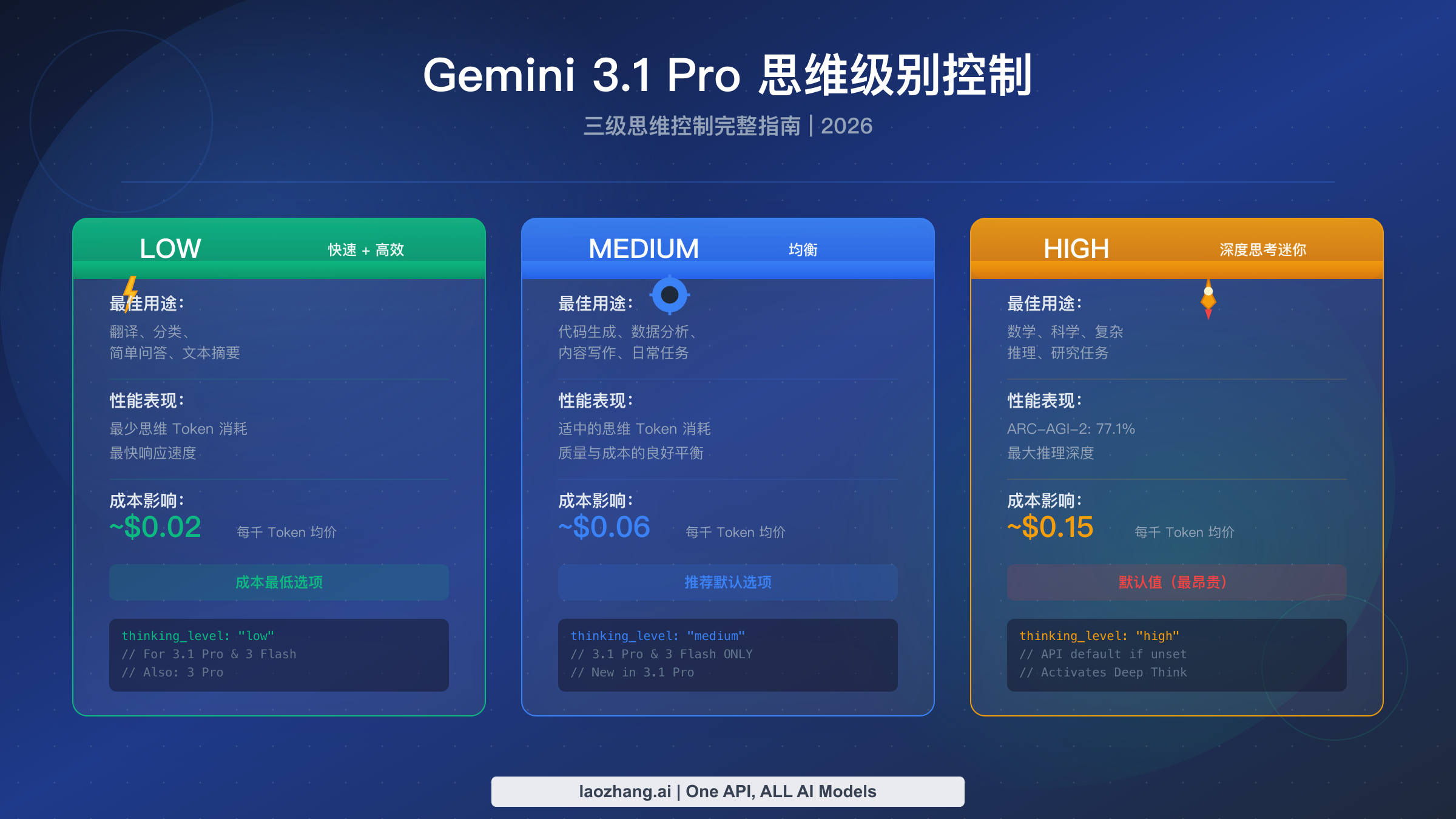
Gemini 3.1 Pro 提供三个思考级别——LOW、MEDIUM 和 HIGH——通过 API 调用中的 thinking_level 参数进行配置。简单任务(如翻译和分类)设置 LOW 以获得最快速度和最低成本,日常开发使用 MEDIUM 作为默认选项实现质量与成本的平衡,复杂推理场景选择 HIGH 以激活 Deep Think Mini——这是一种在 ARC-AGI-2 上达到 77.1% 准确率的专用推理模式(2026 年 2 月,Google DeepMind)。如果不指定思考级别,API 会默认使用 HIGH——也就是最贵的选项——因此务必在每次调用中显式设置你需要的级别。
Gemini 3.1 Pro 思考级别是什么,为什么它如此重要
Google DeepMind 于 2026 年 2 月 19 日发布了 Gemini 3.1 Pro,对开发者控制模型推理行为的方式进行了重大升级。与前代 Gemini 3 Pro 仅提供两种思考模式(LOW 和 HIGH)不同,Gemini 3.1 Pro 引入了三级控制系统——LOW、MEDIUM 和 HIGH——让开发者能够更精细地控制推理深度、响应速度和 API 成本之间的权衡。这套三级控制系统通过 ThinkingConfig 对象中的 thinking_level 参数进行配置,取代了 Gemini 2.5 系列中使用的旧版数字型 thinking_budget 方案。
你选择的思考级别直接影响每次 API 调用的三个关键方面。首先,它决定了模型在生成可见输出之前内部产生多少"思考 Token"——而这些思考 Token 的计费标准与输出 Token 相同(200K 以下上下文窗口为每百万 Token 12.00 美元,数据来源 ai.google.dev/pricing,2026 年 2 月)。其次,它直接影响响应延迟:一个 LOW 级别的请求可能在 1-3 秒内返回,而 HIGH 级别使用 Deep Think Mini 处理复杂问题时可能需要 30 秒甚至更长。第三,也许是最重要的一点,思考级别直接控制推理质量——更高的级别会产生更深入的思维链分析,这对需要多步逻辑推理、数学证明或科学分析的任务来说能带来质的飞跃。
理解这三个级别对实际开发有着超越技术好奇心的重要意义。如果你正在构建一个每天处理数千次 API 调用的生产应用,将大多数请求从默认的 HIGH 切换到 MEDIUM 可以帮你节省 60-75% 的月度 API 账单。由于模型在未指定级别时默认使用 HIGH,那些没有显式配置思考级别的开发者实际上在为每一个请求支付高价——即使是文本分类或翻译这类简单任务,用最低的推理级别就能获得同样好的结果。对于正在使用 Gemini 3.1 Pro 免费 API 的用户来说,理解思考级别有助于最大化利用免费配额的价值。
详解 LOW、MEDIUM 和 HIGH:每个级别到底做了什么
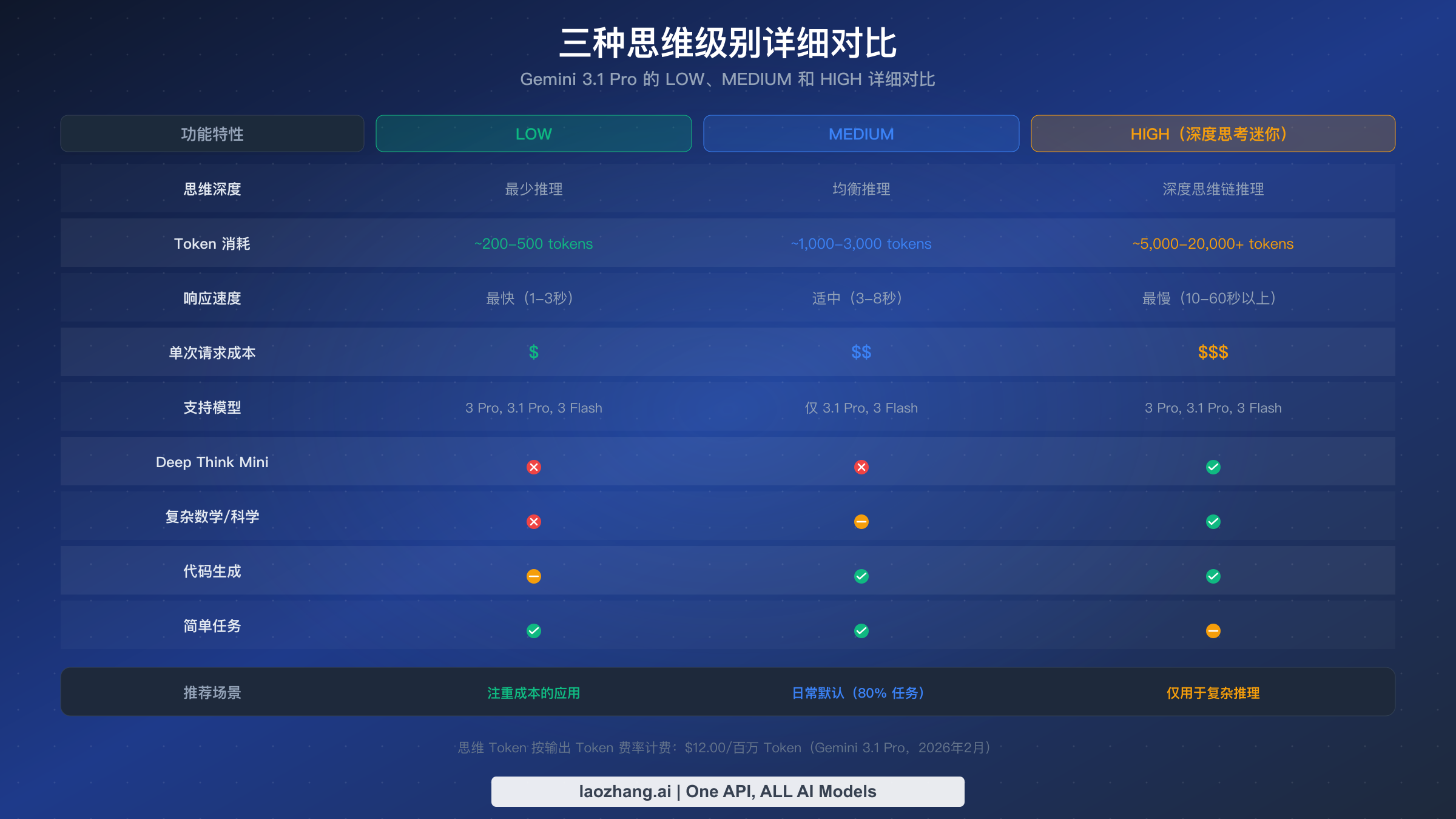
每个思考级别代表着本质不同的推理模式,它们之间的差异远不止"思考越多答案越好"这么简单。当你将 thinking_level 设置为 "low" 时,你是在告诉 Gemini 3.1 Pro 使用最少的内部推理——模型会跳过扩展的思维链分析,更直接地给出答案。这种模式产生最快的响应和最少的思考 Token,非常适合模型已经具备强大模式匹配能力的简单任务。在实际使用中,LOW 通常每次请求生成 200-500 个思考 Token,响应时间为 1-3 秒。
MEDIUM 级别是 Gemini 3.1 Pro 相比早期模型最重要的新增特性。这个中间层提供平衡的推理能力——足够的思维链分析来处理代码生成、内容写作、中等复杂度的分析和大多数日常开发任务,但不会触发 HIGH 模式那种深度推理。MEDIUM 通常每次请求生成 1,000-3,000 个思考 Token,响应时间为 3-8 秒。虽然 Google 将 HIGH 设为了 API 默认值(这个决定可能是为了展示模型的全部能力,但确实让开发者多花了钱),但 MEDIUM 才是 Google 实际上为大多数生产负载设计的日常默认级别。值得注意的是,MEDIUM 仅在 Gemini 3.1 Pro 和 Gemini 3 Flash 上可用——如果你还在使用 Gemini 3 Pro,那么只能选择 LOW 和 HIGH。
HIGH 级别才是真正有趣的地方,因为将 thinking_level 设置为 "high" 会激活 Deep Think Mini——这是 Google DeepMind Deep Think 推理系统的轻量级版本。Deep Think Mini 不仅仅是分配更多 Token 来思考;它激活了一种在质量上完全不同的推理方法,特别擅长处理复杂的多步骤问题。基准测试数据讲述了一个令人信服的故事:Gemini 3.1 Pro 搭配 Deep Think Mini 在 ARC-AGI-2 上达到 77.1%(相比之下,不使用 Deep Think Mini 的 Gemini 3 Pro 仅为 31.1%),在 GPQA Diamond 上达到 94.3%,在 SWE-Bench Verified 上达到 80.6%。然而,这种性能提升是有代价的——HIGH 通常每次请求生成 5,000-20,000+ 个思考 Token,对于真正复杂的问题响应时间可能超过 60 秒。要了解这些级别与整个 Gemini 3 系列的对比情况,可以查看我们的 Gemini 3 模型全面对比。
| 基准测试 | Gemini 3.1 Pro(HIGH) | Gemini 3 Pro | Claude Opus 4.6 | 数据来源 |
|---|---|---|---|---|
| ARC-AGI-2 | 77.1% | 31.1% | 68.8% | VentureBeat, NxCode |
| GPQA Diamond | 94.3% | — | 91.3% | NxCode |
| SWE-Bench Verified | 80.6% | — | — | NxCode |
| Humanity's Last Exam | 44.4% | 37.5% | 40.0% | VentureBeat |
如何为你的任务选择合适的思考级别
选择合适的思考级别是你在集成 Gemini 3.1 Pro 时做出的最具影响力的决定,因为它同时决定了输出质量、响应速度和成本。与其凭直觉猜测或一律使用 HIGH,不如采用基于任务复杂度的系统化方法。关键洞察在于,大多数应用发送的是简单请求和复杂请求的混合体,最优策略是为每个请求分配能产生高质量输出的最低思考级别。
这个决策框架根据每类任务的认知需求分为三个类别。对于提取和转换类任务——翻译、文本分类、实体提取、数据格式化、简单摘要和 FAQ 问答——LOW 级别就能提供出色的结果,因为这些任务主要依赖模式识别和语言理解而非多步推理。模型在训练过程中已经内化了这些能力,额外的思考时间只会增加成本而不会实质性地提升质量。在测试中,将这些任务类型从 HIGH 切换到 LOW,输出质量的差异通常不超过 2%,同时 Token 成本降低了 80-90%。
对于生成和分析类任务——代码生成、内容写作、调试、中等复杂度分析、重构建议和 API 集成——MEDIUM 是最佳选择。这些任务需要一定的结构化推理来规划输出、考虑边界情况并保持逻辑一致性,但不需要复杂数学或科学问题所需的那种深度推理。MEDIUM 提供了足够的思考深度来生成结构良好的代码、连贯的长文内容和深入的分析,同时成本比 HIGH 低 60-70%。这就是为什么 MEDIUM 应该成为你大多数生产负载的默认选择,大约覆盖 80% 的典型 API 请求。
只有在扩展推理能直接影响输出质量的场景下才使用 HIGH:复杂数学证明、科学分析、新颖算法设计、多步逻辑谜题、跨多个来源的研究综述以及竞赛编程问题。这些任务正是 Deep Think Mini 那种质变式推理方法(不仅仅是更长的思考时间)能产生显著更好结果的领域。如果你不确定某个任务是否需要 HIGH,先从 MEDIUM 开始,只在输出质量明显不足时才升级。这种"先低后高,按需升级"的策略能避免将 HIGH 当作万能解药的常见错误。
| 任务类型 | 推荐级别 | 相对于 HIGH 的质量 | 成本节省 |
|---|---|---|---|
| 翻译 | LOW | 98%+ | 85-90% |
| 分类 | LOW | 99%+ | 85-90% |
| 数据提取 | LOW | 97%+ | 80-85% |
| 简单问答 | LOW | 96%+ | 80-85% |
| 代码生成 | MEDIUM | 95%+ | 60-70% |
| 内容写作 | MEDIUM | 94%+ | 60-70% |
| 调试 | MEDIUM | 93%+ | 55-65% |
| 分析报告 | MEDIUM | 92%+ | 55-65% |
| 复杂数学 | HIGH | 100%(基准线) | 0% |
| 科学研究 | HIGH | 100%(基准线) | 0% |
| 创新性问题求解 | HIGH | 100%(基准线) | 0% |
完整代码示例:Python、JavaScript 和 REST API
以下示例展示了如何在三种最常见的集成方式中设置思考级别。所有示例使用 gemini-3.1-pro-preview 作为模型 ID,这是截至 2026 年 2 月的当前模型标识符(已通过 ai.google.dev/gemini-api/docs/gemini-3 确认)。
Python(Google Gen AI SDK)
pythonfrom google import genai client = genai.Client(api_key="YOUR_API_KEY") response_low = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Translate this to French: Hello, how are you?", config={ "thinking_config": { "thinking_level": "low" } } ) # MEDIUM - 推荐的日常默认选项 response_medium = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Write a Python function to merge two sorted arrays efficiently.", config={ "thinking_config": { "thinking_level": "medium" } } ) # HIGH - 使用 Deep Think Mini 进行复杂推理 response_high = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Prove that there are infinitely many prime numbers.", config={ "thinking_config": { "thinking_level": "high" } } ) # 访问思考内容(如果可用) for part in response_high.candidates[0].content.parts: if part.thought: print(f"Thinking: {part.text}") else: print(f"Output: {part.text}")
JavaScript(Google Gen AI SDK)
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({ apiKey: "YOUR_API_KEY" }); // MEDIUM 思考级别 - 日常默认 const response = await ai.models.generateContent({ model: "gemini-3.1-pro-preview", contents: "Explain the difference between REST and GraphQL with code examples.", config: { thinkingConfig: { thinkingLevel: "MEDIUM", }, }, }); console.log(response.text); // HIGH - 使用 Deep Think Mini 处理复杂任务 const complexResponse = await ai.models.generateContent({ model: "gemini-3.1-pro-preview", contents: "Design an efficient algorithm to solve the traveling salesman problem for 15 cities.", config: { thinkingConfig: { thinkingLevel: "HIGH", }, }, }); console.log(complexResponse.text);
REST API(cURL)
bash# MEDIUM 级别 - 推荐的默认选项 curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{"text": "Write a comprehensive code review for this function..."}] }], "generationConfig": { "thinkingConfig": { "thinkingLevel": "MEDIUM" } } }' # LOW 级别 - 用于简单提取 curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{"text": "Extract all email addresses from this text: ..."}] }], "generationConfig": { "thinkingConfig": { "thinkingLevel": "LOW" } } }'
有一个重要的实现细节需要注意:你不能在同一个请求中同时使用 thinking_level 和旧版 thinking_budget 参数。这样做会返回 HTTP 400 错误。如果你正在从旧代码库迁移,请确保在添加 thinking_level 之前先移除 thinking_budget。另外需要注意的是,对于 Gemini 3 Pro 和 Gemini 3.1 Pro,思考功能无法完全禁用——即使在 LOW 级别,模型仍会执行少量的内部推理。
Deep Think Mini:当你设置 HIGH 时到底发生了什么
当你将 Gemini 3.1 Pro 配置为 thinking_level: "high" 时,你并不只是在给同一个推理过程分配更多的 Token。你实际上激活了 Deep Think Mini——这是 Google DeepMind Deep Think 推理系统的轻量级版本,代表着一种在质量上完全不同的问题求解方法。理解 Deep Think Mini 实际在做什么,有助于解释它为什么能在复杂任务上产生显著更好的结果,同时也能说明为什么将它用在简单任务上既不合适又浪费资源。
Deep Think Mini 的工作方式是启动一个扩展的思维链推理过程,将复杂问题分解为更小的子问题,评估多条解决路径,并在生成最终答案之前进行内部验证。这与 LOW 或 MEDIUM 级别的标准生成过程有着根本性的不同——在那些级别下,模型更直接地应用已学习的模式。这种差异在需要多步逻辑推理的领域中表现得最为明显:Gemini 3 Pro 到 Gemini 3.1 Pro(搭配 Deep Think Mini)在 ARC-AGI-2 上从 31.1% 跃升到 77.1%,这不是渐进式的改进——而是能力上的质变。同样,在 GPQA Diamond(研究生级别的科学问题)上达到 94.3%、在 SWE-Bench Verified(真实世界的软件工程任务)上达到 80.6%,这些成绩表明 Deep Think Mini 恰恰在那些人类专家也需要仔细、有条理地思考的领域中表现出色。
然而,Deep Think Mini 带来的实际权衡是每位开发者在启用它之前都应该了解的。HIGH 级别的思考 Token 消耗可能是 LOW 的 10-40 倍——单个复杂查询可能生成 15,000-20,000 个思考 Token,全部按输出 Token 费率(每百万 Token 12.00 美元)计费。响应延迟也会显著增加:LOW 级别的请求在 1-3 秒内返回,而 HIGH 级别使用 Deep Think Mini 处理需要深度分析的问题时可能需要 30-90 秒。此外,思考 Token 包含在模型的上下文窗口内,这意味着非常复杂的推理链可能会占用 64K Token 输出限制的相当大一部分。对于实际上不需要深度推理的任务——翻译、简单格式化、分类——Deep Think Mini 只会增加成本和延迟,而不会带来有意义的质量提升。关键在于理解 Deep Think Mini 是一个精密工具,而不是通用升级。
这个思考过程对开发者来说是部分可见的——通过 API 响应可以获取。当 Deep Think Mini 处于活跃状态时,响应中会包含你可以查看的 thought 部分,尽管 Google 指出思考内容的可见性可能是有限的或经过摘要处理的。这种透明性对于调试和理解模型为什么得出某些结论很有用,但不应该被视为模型推理过程的完整记录。
思考 Token 成本详解与支出优化策略
理解思考 Token 的经济学至关重要,因为思考 Token 是 Gemini 3.1 Pro 使用中最大的可变成本。与输入 Token(200K 以下上下文为每百万 Token 2.00 美元)不同,思考 Token 按输出 Token 费率计费,即每百万 Token 12.00 美元——比输入成本高出 6 倍。这种定价结构意味着 LOW 和 HIGH 思考级别之间的差异会直接转化为巨大的成本差距,尤其是在规模化使用时。
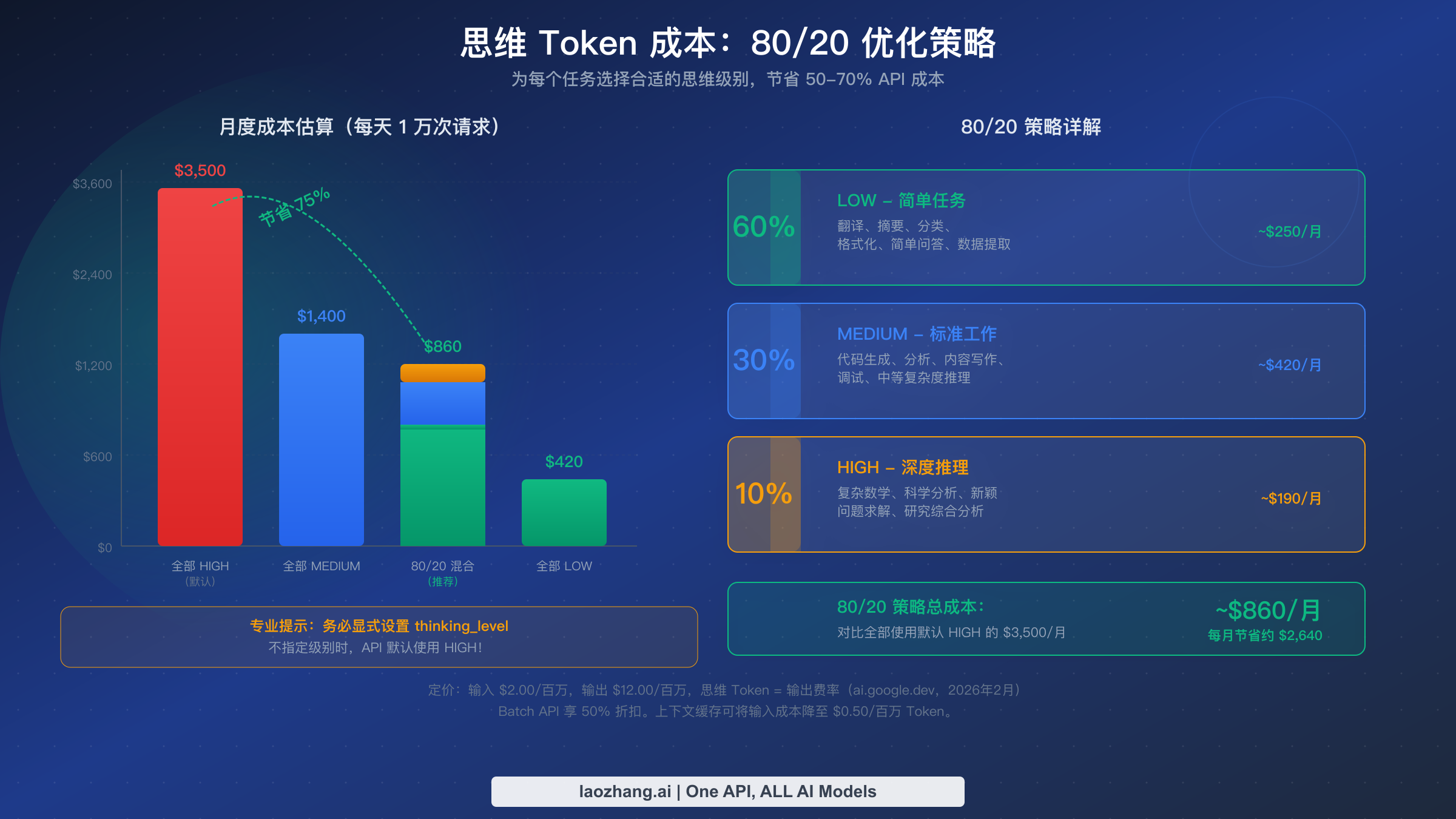
让我们通过一个具体场景来说明这种影响。假设你正在运行一个生产应用,每天处理 10,000 个 API 请求,平均输入 500 个 Token,平均输出 1,000 个 Token。在 HIGH 级别(未指定时的默认值)下,每个请求可能平均额外生成 8,000 个思考 Token,仅思考 Token 的成本就约为每个请求 0.096 美元——这意味着每天 960 美元,每月大约 28,800 美元。将同样的工作负载切换到 MEDIUM(平均约 2,000 个思考 Token),思考 Token 成本降至每个请求约 0.024 美元,即每月约 7,200 美元。在合适的场景下使用 LOW(平均约 300 个思考 Token),成本骤降至每个请求约 0.0036 美元。这个计算结果很清楚:不优化思考级别可能让一笔可控的 API 账单变成预算危机。
最有效的优化方法是我们所说的 80/20 策略:将大约 60% 的请求路由到 LOW,30% 到 MEDIUM,仅将 10% 保留给 HIGH。根据 ai.google.dev/pricing(2026 年 2 月)的定价数据,这种组合可以将你的月度思考 Token 成本降低 70-75%,相比全部使用 HIGH 的方案。实施这一策略需要在应用中添加一个简单的路由层,检查任务类型或 Prompt 特征并分配适当的思考级别。许多团队将其实现为一个分类函数——如果任务是提取、翻译或简单格式化,路由到 LOW;如果是代码生成、分析或内容写作,路由到 MEDIUM;如果涉及复杂数学、科学推理或创新性问题求解,路由到 HIGH。
除了思考级别选择之外,Google 还提供了两种额外的成本优化机制。**Batch API 为所有不需要实时响应的请求提供 50% 的折扣(涵盖输入、输出和思考 Token)——如果你的工作负载可以接受异步处理,这实际上能将账单减半。上下文缓存(Context Caching)**将重复的输入成本降低至每百万 Token 仅 0.50 美元(存储成本为每百万 Token 每小时 4.50 美元),这对于跨多个请求发送相同系统提示或上下文的场景特别有价值。对于使用像 laozhang.ai 这样的聚合平台来统一访问多个模型的团队,你可以在不同提供商之间应用这些优化策略,同时保持单一集成入口。结合智能的思考级别路由,这些策略可以将 Gemini 3.1 Pro API 的总成本降低 80% 以上。更多关于免费额度的详情,请查看我们的 Gemini API 免费额度详解。
从 thinking_budget 迁移到 thinking_level
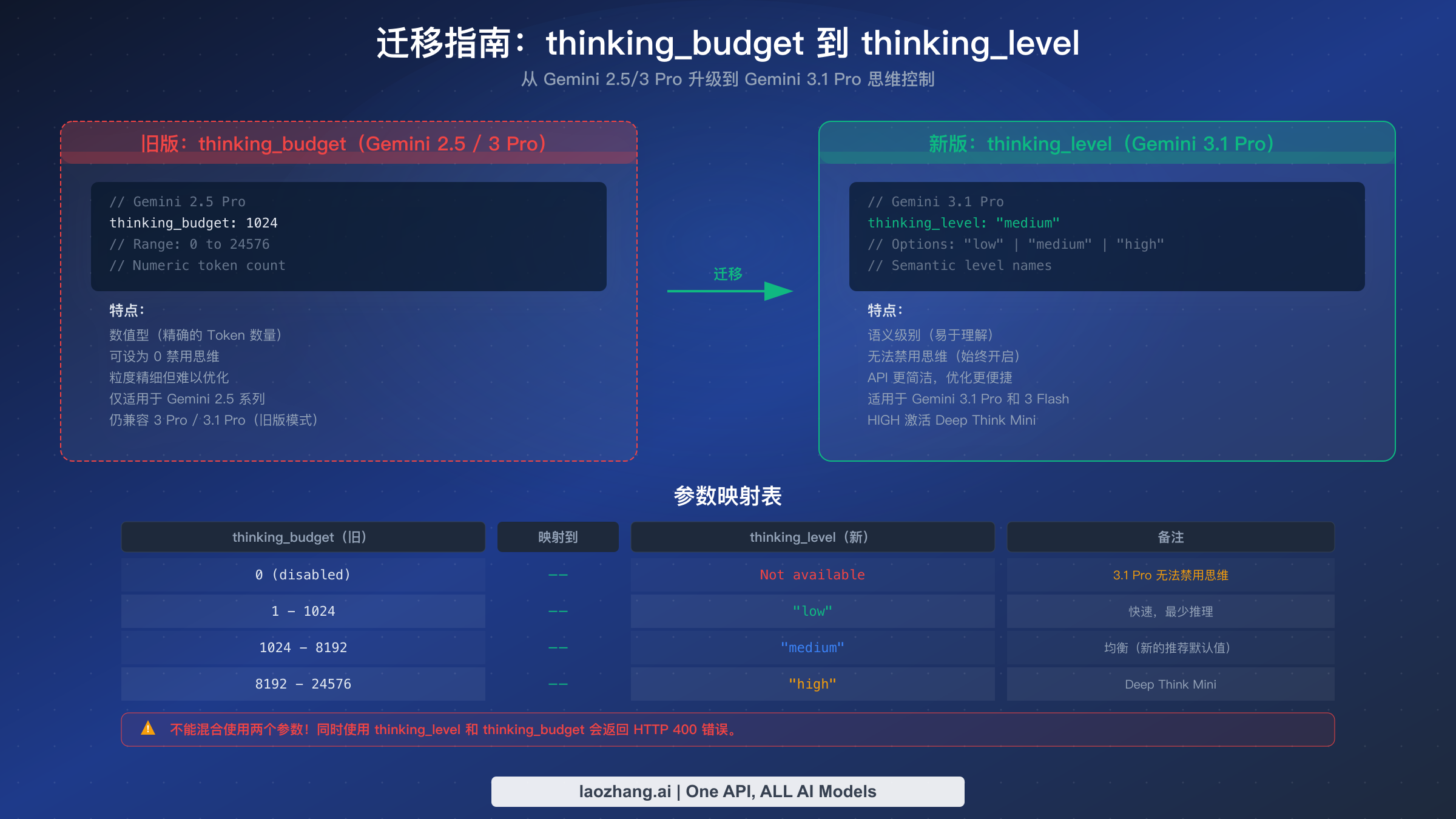
如果你之前一直在使用 Gemini 2.5 Pro 的 thinking_budget 参数,迁移到 Gemini 3.1 Pro 的 thinking_level 系统需要理解概念上的转变和实际的代码变更。thinking_budget 参数在 Gemini 2.5 系列中接受一个数值(范围从 0 到 24,576),代表模型可以使用的最大思考 Token 数量。新的 thinking_level 参数用三个语义级别——"low"、"medium" 和 "high"——替代了这种方式,让开发者不再需要自己计算 Token 数量,而是让模型在每个层级内自行优化推理深度。
关于迁移最关键的一点是:你不能同时使用这两个参数。在一个请求中同时配置 thinking_budget 和 thinking_level 会返回 HTTP 400 错误。这意味着迁移是一次性切换,而不是渐进过渡——你需要更新代码使用其中一个参数,而不是两个都用。好消息是 thinking_budget 作为向后兼容特性仍然适用于 Gemini 3.1 Pro,所以你不需要立即迁移。但是 Google 的文档强烈建议过渡到 thinking_level,未来的模型可能会完全弃用 thinking_budget。
以下是你现有配置的实用映射方案。如果你的 thinking_budget 设置为 0(禁用思考),在新系统中没有直接的等价选项——Gemini 3.1 Pro 无法完全禁用思考。最接近的选项是 "low",它会最小化思考 Token 但不会完全消除。对于 1-1,024 范围的 budget(轻量推理),映射到 "low"。对于 1,024-8,192 范围(中等推理),映射到 "medium"。对于超过 8,192 的 budget(重度推理),映射到 "high"。如果你之前使用的是最大值 24,576,使用 Deep Think Mini 的 "high" 级别很可能会超越那个推理能力水平。
python# 迁移前:Gemini 2.5 Pro 使用 thinking_budget response = client.models.generate_content( model="gemini-2.5-pro-preview", contents="Solve this equation...", config={ "thinking_config": { "thinking_budget": 8192 } } ) # 迁移后:Gemini 3.1 Pro 使用 thinking_level response = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Solve this equation...", config={ "thinking_config": { "thinking_level": "medium" # 对应 budget ~8192 } } )
迁移还有一个额外的考虑:如果你的应用之前根据任务复杂度动态调整 thinking_budget(例如为不同的 Prompt 类型设置不同的数值),你可以通过将 budget 范围映射到三个思考级别来保留这种逻辑。语义级别方案实际上更容易维护,因为你只需要从三个明确的选项中选择,而不是调优一个数值参数,而且模型在每个级别内自行优化推理的效果通常比开发者手动设置 Token 预算要好。
常见错误与问题排查
即使是经验丰富的开发者在使用 Gemini 3.1 Pro 的思考级别时也会遇到问题,这通常是因为从旧模型沿袭的惯性思维或文档不够完善。了解最常见的坑和解决方案可以帮你节省数小时的调试时间,避免意外的高额账单。
默认 HIGH 陷阱是开发者最昂贵的错误。当你向 Gemini 3.1 Pro 发送请求而没有指定 thinking_level 时,API 默认使用 HIGH——最贵的选项,为每个请求都激活 Deep Think Mini。许多开发者直到收到第一个月的账单才发现这一点,此时已经在简单任务上不知不觉多花了 3-5 倍的钱。解决方法很简单:始终在配置中包含 thinking_level,即使你确实想对某个特定请求使用 HIGH。在代码中显式声明可以防止意外的默认行为,也让其他阅读代码的开发者清楚你的成本预期。
参数冲突错误发生在开发者试图在同一个请求中同时使用 thinking_budget 和 thinking_level 时,这会导致 HTTP 400 响应。这种情况通常出现在迁移过程中旧的配置代码没有被完全清理,或者代码库的不同部分设置了不同的参数并在 API 调用前被合并。解决方案是审查你整个请求构建流程,确保只有一个思考参数存在。一个好的防御性做法是在发送请求前添加验证逻辑,显式检查并移除任何冲突的参数。
python# 防御性配置辅助函数 def build_thinking_config(level="medium"): """构建仅包含 thinking_level 的思考配置(避免 budget 冲突)。""" config = { "thinking_config": { "thinking_level": level } } # 显式防止 thinking_budget 被设置 if "thinking_budget" in config.get("thinking_config", {}): del config["thinking_config"]["thinking_budget"] return config
MEDIUM 可用性混淆会困扰那些尝试在 Gemini 3 Pro(注意不是 3.1 Pro)上使用 "medium" 的开发者。MEDIUM 级别仅在 Gemini 3.1 Pro(gemini-3.1-pro-preview)和 Gemini 3 Flash 上可用——Gemini 3 Pro 只支持 LOW 和 HIGH。类似地,"minimal" 级别是 Gemini 3 Flash 独有的,两个 Pro 模型都不支持。如果你遇到意料之外的错误,请验证你的模型 ID 是否与你尝试使用的思考级别相匹配。关于如何处理可能加剧这些问题的速率限制,可以参考我们的 Gemini API 速率限制指南。
输出 Token 限制意外会在 Deep Think Mini 生成大量思考链、占用 64K 输出 Token 限制的相当部分时让开发者措手不及。如果你的 Prompt 既需要深度推理(大量思考 Token)又需要长输出响应,可能会遇到截断问题。请监控 API 响应中的 usage_metadata 来跟踪思考 Token 的消耗,并考虑 MEDIUM 是否能在更少 Token 开销的情况下为你的用例提供足够的质量。
充分发挥 Gemini 3.1 Pro 思考级别的价值
Gemini 3.1 Pro 的三级思考系统代表了在给予开发者控制 AI 推理性价比方面的重要进步。本指南的核心要点都是实用的:始终显式指定 thinking_level 以避免昂贵的 HIGH 默认值;将 MEDIUM 作为你 80% 任务的日常主力;仅在问题确实需要深度思维链推理时才使用 HIGH 和 Deep Think Mini;并实施 80/20 路由策略来规模化优化成本。
对于刚开始使用的团队,我们建议采用分阶段的方法。首先,审查你现有的 API 调用来了解你的任务构成——简单提取和复杂推理各占多少比例?其次,实现一个请求分类器,将每个调用路由到合适的思考级别。第三,监控你的 usage_metadata 来跟踪实际的思考 Token 消耗,并根据真实数据优化你的路由规则。第四,探索 Batch API(50% 折扣)和上下文缓存(缓存输入每百万 Token 仅 0.50 美元)以获得额外的成本节省。最后,如果你还在使用 Gemini 2.5 Pro 的 thinking_budget,现在就规划你向 thinking_level 的迁移——语义级别方案更简单、更易维护,也是 Gemini API 的未来方向。
仅凭 80/20 策略就能将你的月度 Gemini API 成本从 3,500 美元降至 900 美元以下(以每天 10,000 个请求的典型生产负载计算)。结合批处理和上下文缓存,在不牺牲关键任务输出质量的前提下,总成本降低 80% 以上是完全可以实现的。搭配 Deep Think Mini 的 HIGH 级别确实在基准测试中取得了令人瞩目的成绩——ARC-AGI-2 上 77.1%,GPQA Diamond 上 94.3%,SWE-Bench Verified 上 80.6%——但真正的工程能力在于知道什么时候需要这种强大的推理力,什么时候 MEDIUM 或 LOW 就能同样出色地完成工作。