
如果你第一轮想先用更低成本验证一条编码代理链路,尤其是终端驱动、工具调用频繁的任务,那就先看 GPT-5.3-Codex。如果真正昂贵的地方不在 token 单价,而在于长链路任务、大仓库上下文,或者一次输出不稳就会带来很高的人力返工,那就先看 Claude Opus 4.6。这是 2026 年 4 月 3 日 仍然成立的实用答案。
不过在看表格之前,有一点必须先说清楚。GPT-5.3-Codex 仍然是一个真实、当前可用的 OpenAI 模型,但它已经不能再代表今天整个 Codex 产品。OpenAI 在 2026 年 3 月 5 日 把 GPT-5.4 带进 Codex,又在 2026 年 3 月 17 日 描述了一个由更大模型负责规划与最终判断、由 GPT-5.4 mini 负责更窄子任务的 Codex 结构。所以这篇文章比较的是 Claude Opus 4.6 和 GPT-5.3-Codex 这两个模型,不是整个当前 Codex 产品。如果你真正想比较的是产品和工作流,请直接看 OpenAI Codex 2026 年 3 月更新解读 和 Claude Code vs Codex 工作流对比。
| 如果你的瓶颈更像这样 | 先看谁 | 为什么 |
|---|---|---|
| 更便宜的终端型编码代理循环 | GPT-5.3-Codex | 官方 API 单价更低,且 OpenAI 自己给了更完整的第一方编码基准附录 |
| 仓库级长程执行 | Claude Opus 4.6 | 1M 上下文、128k 输出,以及更适合高返工代价任务的模型定位 |
| 你的系统里同时存在这两种阶段 | 两个都用 | 先让 GPT-5.3-Codex 负责便宜首轮,再在上下文深度或返工风险升高时升级到 Opus 4.6 |
证据说明: 本文基于 OpenAI 和 Anthropic 当前官方模型页与产品页,于 2026 年 4 月 3 日 复核。这里的 benchmark 证据并不对称:OpenAI 为 GPT-5.3-Codex 发布了更完整的首发附录,Anthropic 则为 Opus 4.6 提供了较少但仍足够有用的公开 agent benchmark。下面的结论应该被理解为“先测谁”的判断依据,而不是一块完全对称的实验室比分板。
先确认比较对象
这篇比较之所以还能成立,前提是我们把对象卡得足够准。GPT-5.3-Codex 于 2026 年 2 月 5 日发布,OpenAI 当前 API 文档依然把它列为一个在役的编码模型,并写明了价格、reasoning effort、可用端点、400,000 token 上下文窗口 与 128,000 token 最大输出。所以这个模型名不是社区口语,更不是过时残留,它仍然值得被直接拿来和 Claude Opus 4.6 对比。
发生变化的是它外面的产品叙事。OpenAI 当前模型目录已经把 GPT-5.4 放在 agentic、coding 和专业工作流的主力位置上,而 2026 年 3 月 17 日 的 GPT-5.4 mini 公告又明确把 Codex 描述成一种由更大模型负责规划、协调与最终判断、由更小模型承担窄任务的协作方式。这并不是说 GPT-5.3-Codex 消失了,而是说明很多人在说 “Codex” 的时候,实际上已经不再只是在问 GPT-5.3-Codex 这个模型。
这一区别为什么重要?因为模型选择和产品选择,回答的是两类不同问题。模型对比要回答的是“哪个模型更值得先测”;产品对比要回答的是“该选哪套工具和工作流”。两者彼此有关,但并不相同。本文只留在模型这一层,就是为了把问题缩成一句更有用的话:现在的编码栈里,哪个模型更值得先上场?
快速快照:真正有区分度的行在哪
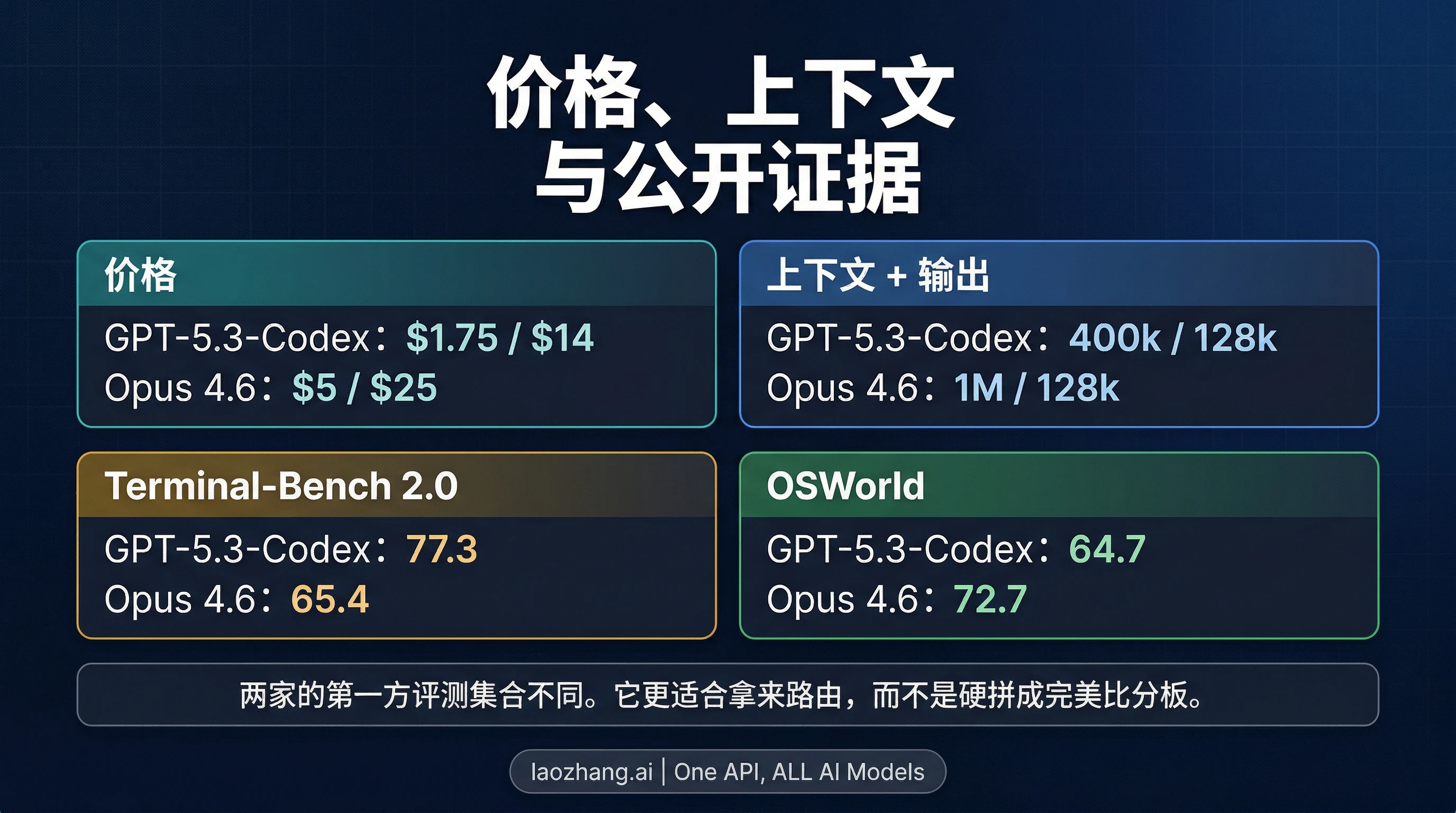
真正有价值的读法,不是“谁赢了更多行”,而是每一行到底在指向哪种失败成本。GPT-5.3-Codex 的定价,更像一个可以高频做压力测试的模型。Claude Opus 4.6 的定价,则更像一个预期帮你减少昂贵失误的模型。
| 维度 | GPT-5.3-Codex | Claude Opus 4.6 | 这一行真正说明什么 |
|---|---|---|---|
| 官方 API 价格 | $1.75 输入 / $14 输出 / 百万 tokens | $5 输入 / $25 输出 / 百万 tokens | GPT-5.3-Codex 更容易承受高频编码循环测试 |
| Cached input | $0.175 / 百万 tokens | Anthropic 需要结合其缓存规则单独理解 | OpenAI 这边更适合做重复性评估 |
| 上下文窗口 | 400k | 1M | Opus 更容易把大仓库或长规格一次放进同一个上下文窗口里 |
| 最大输出 | 128k | 128k | 这不是两者最关键的分界线 |
| 公开 Terminal-Bench 2.0 | 77.3 | 65.4 | OpenAI 给出了更明确的低成本编码代理评估依据 |
| 公开 OSWorld | 64.7 | 72.7 | Anthropic 给出了更强的环境型长程执行公开证据 |
从这个表里已经能看出大方向。GPT-5.3-Codex 更像便宜、适合先跑第一轮的模型,尤其当你的问题是“我能在不付 Opus 价格的前提下,把编码代理推到什么程度”。而 Claude Opus 4.6 更适合在上下文深度和失败成本主导总账单时先上,因为它能一次保留更多状态,同时并没有牺牲输出上限。
真正要避免的坑,是假装这些行组成了一块完美对称的 benchmark 故事。事实不是这样。OpenAI 的 headline 数字来自 2026 年 2 月 5 日 的首发附录,而且明确是在 xhigh reasoning effort 下跑出来的。Anthropic 当前关于 Opus 4.6 的公开论据则更窄,但依然足够有用:产品页和模型页强调 65.4% 的 Terminal-Bench 2.0、72.7% 的 OSWorld、公开 1M 上下文 与高端 agentic 定位。这些证据足够指导先后顺序,但不够支持任何一方“全面碾压所有编码 benchmark”的说法。
什么时候该先测 GPT-5.3-Codex
结论: 当你更在意“我能用较低价格买到多强的编码代理循环”时,GPT-5.3-Codex 更值得拿到第一轮测试。
根据: OpenAI 当前模型页把 GPT-5.3-Codex 定价为 $1.75 / $14 每百万 tokens,cached input 为 $0.175,并提供 400k 上下文、128k 输出 和可调 reasoning effort。OpenAI 的首发附录还给了它更完整的公开编码 benchmark 证据,包括 77.3% 的 Terminal-Bench 2.0 和 64.7% 的 OSWorld-Verified。
判断: 如果你的团队还在摸编码代理的边界,并且预计会有很多轮迭代、重试和评估回路,那就先用 GPT-5.3-Codex。
这里真正成立的理由,不是 leaderboard 神话,而是经济学。一个编码栈如果大部分时间都花在终端循环、patch 尝试、工具调用与自我纠偏上,它首先烧掉的往往不是巨型上下文,而是反复试错的次数。在这种系统里,GPT-5.3-Codex 给你的,是一种更便宜地学会“这个工作负载到底要多强模型”的方式。模型失败了,你也用更低成本学到了边界。模型如果已经够用,就没必要在整个流水线上都付 Opus 价格。
另一个更具体的原因,是 OpenAI 对终端型任务给出了更清楚的第一方公开材料。你不需要只凭一句“更适合 coding”来下注,而是可以同时看到价格、上下文、可调 reasoning effort 和编码类 benchmark。对还在建第一套评估方案的团队来说,这本身就是优势。
什么时候 Claude Opus 4.6 更值得先上
结论: 如果真正昂贵的不是 token,而是长文档、长链路任务和一次失败带来的大规模返工,那 Claude Opus 4.6 更值得作为第一轮测试对象。
根据: Anthropic 当前文档把 Opus 4.6 定义为 $5 / $25 每百万 tokens、1M 上下文、128k 最大输出 的模型。公开材料里还给出了 65.4% 的 Terminal-Bench 2.0、72.7% 的 OSWorld,并把它定位成更偏长链路、agentic 的高端模型。
判断: 如果你要处理的是大仓库、多步骤执行,或者一次错误首轮会带来大量审阅与返工,那就应该先测 Claude Opus 4.6。

这里真正要看的,不是“它是不是更聪明”,而是失败一次到底有多贵。如果模型需要持续维持很长的上下文,阅读大仓库、长设计文档、长事故记录,或者本身就要一次产出一个很大的可交付结果,那 1M 上下文 + 128k 输出 会直接改变任务的形状。
这也是价格不再等于总账单的地方。一个单价更高的模型,如果能减少重试、减少审阅时间、减少那种“看起来差不多,但三步之后崩掉”的半成品,它整体上仍然可能更便宜。Anthropic 当前公开给出的论据,也基本围绕这种任务形态展开。即便它的 benchmark 集合没有 OpenAI 首发附录那样完整对称,整体结论还是一致的:Opus 4.6 更适合那些价值高、链路长、一次失误就会放大返工成本的任务。
另一个常被低估的优势,是 更大的上下文会改变你组织工作的方式。1M token 上下文窗口,让你在引入检索和切块策略之前,先尝试用更完整的仓库与规格来问问题。这并不意味着你就不再需要好的工具使用和任务拆分,但它确实会让很多“天然很大”的任务在第一轮里更连贯。如果你的评估目标本来就是“一个模型能不能稳稳拿住整套工作集”,那 Opus 就比价格表看上去更值得先测。至于 Anthropic 侧更细的成本规划,可以继续看 Claude Opus 4.6 价格与订阅指南。
多数团队真正该测试的双模型分工
对很多团队来说,2026 年最干净的答案,并不是找一个永久赢家,而是建立一套明确的切换规则。
把 GPT-5.3-Codex 放在便宜的首轮编码代理任务里:终端型循环、宽口径评估批次、还在摸失败形状的早期自动化。然后在任务扩展成大仓库上下文、长链路多步执行,或者一次失败会导致高返工成本时,把任务升级到 Claude Opus 4.6。这不是一种礼貌性的“两个都不错”,而是一种非常具体的两阶段分工。

关键细节在于升级规则。如果你的任务描述还比较窄,你主要在乎的是低成本地反复评估,就让 GPT-5.3-Codex 继续承担这一段。一旦任务因为上下文增长、重试变多,或者输出本身开始变成高价值工件而超出这条便宜首测线,就把任务升级到 Opus。这个升级,不应该只看 token 单价,而应该看重试成本与返工成本。很多比较文章只盯着官方定价,结果错过了平庸首轮带来的真实总成本。
这也是产品提及真正有用的地方。如果你已经知道自己要同时保留 OpenAI 和 Anthropic 两条线,一层统一网关,比如 laozhang.ai,可以减少分别管理计费、鉴权和模型切换的摩擦。这里提它,不是为了把文章变成产品推销,而是因为这篇文章给出的最佳实操答案,本来就很可能是一套多模型架构,而多模型架构在接入层更薄时会更容易运作。
更大的结论是:模型选择应该跟着工作阶段走。一个便宜的首轮模型和一个高价的执行模型,完全可以在同一套编码系统里并存,而且这往往比强行让一个前沿模型接管所有工作更合理。
如果你真正想问的是今天的 Codex
很多输入 “GPT-5.3-Codex” 的读者,其实部分是在问另一件事:今天的 Codex 到底是什么? 在这个问题上,本文不该越界。OpenAI 当前的产品框架已经明显转向了 GPT-5.4 时代的 Codex 叙事,包括 app、CLI、IDE、cloud 等多个入口,以及更大模型负责规划、更小模型负责支持任务的分工。也正因为如此,GPT-5.3-Codex 在这里仍是一个合理比较对象,但它已经不再等于整个产品答案。
所以最实用的下一步很简单。如果你在选的是模型,就留在这篇文章,用上面的分工规则做决定。如果你在选的是产品或开发方式,下一篇该看的是 OpenAI Codex 2026 年 3 月更新解读。如果你真正纠结的是 Anthropic 工具路线和 OpenAI 工具路线怎么选,请去看 Claude Code vs Codex。如果你在 Anthropic 侧的后续问题,更偏向角色分工和高端成本规划,那 Claude 4.6 Agent Teams 指南 和 Opus 价格指南会更精准。
结论
如果要把全文压缩成一句最短但仍然诚实的话,那就是:当你的任务是更便宜的编码代理循环,先上 GPT-5.3-Codex;当任务已经长到上下文深度、执行连续性和输出规模比 token 单价更昂贵时,先上 Claude Opus 4.6。 如果你的系统明确同时包含这两种阶段,那就别再强行找一个假装能统治所有工作的万能赢家,而是有意识地把两者分工起来。