
如果你想在 Codex 和 Claude Code 之间切换而不丢上下文,先不要复制整段聊天记录。真正要移动的是项目状态:仓库规则、当前任务目标、改过哪些文件、跑过哪些命令、失败证据、已经做过的决定,以及下一步最该做什么。代码状态交给 Git,长期规则放进 AGENTS.md 和 CLAUDE.md,临时任务状态写成一个两分钟能看完的 handoff packet。
Claude Code 和 Codex 现在都不是“能不能写代码”的问题。真正容易选错的是工作形态、额度读法和上下文交接方式:五小时窗口不等于五小时可用工作时长,消息数更多也不等于更省 token,一段长 transcript 也不等于可靠记忆。你要判断的是,在上下文、模型、工具、重试和人工 review 都算进去后,哪个工具能给你的真实仓库换回更多可交付结果。
我的当前结论很直接。每月 20 美元,如果你还没有固定偏好,先试 Codex;它把本地、IDE、Web、云任务和 code review 放在同一个订阅入口里,额度分类也更容易读。例外是本地复杂改动:如果你每天都在未提交变更、团队权限规则、长上下文调试里来回切,Claude Code 更适合作为主工具。到了 100 或 200 美元档,就不要问谁“更强”,而要看你的工作是 Claude Code 长会话更多,还是 Codex 异步任务和 review 更多,最后用“可接受 diff / 撞限次数 / 返工时间”来算。
快速选择表
| 当前场景 | 先用谁 | 原因 |
|---|---|---|
| 已经在两个工具之间切换 | 先写 handoff packet | 不要让下一个 agent 从模糊聊天记录里猜上下文。 |
| 每月 20 美元,想覆盖更多 coding-agent 场景 | Codex | Plus 包含 Web、CLI、IDE、iOS、云端集成和当前 Codex 模型。 |
| 每月 20 美元,主要在本地仓库里反复纠偏 | Claude Code | 本地会话、权限规则和上下文管理更贴近日常开发。 |
| 每月 100 美元,Claude 会话很重 | Claude Max 5x | Max 5x 买的是更大的 Claude 使用空间。 |
| 每月 100 美元,Codex 任务和 review 很多 | Codex Pro 5x | Pro 买的是更大的 Codex 五小时窗口和更多任务空间。 |
| 每月 200 美元,重度并行 | 按任务拆分 | Max 20x 适合大 Claude 会话,Codex Pro 20x 适合委派和 review。 |
| 团队已经两个都用 | 建路由规则 | 不要用信仰统一工具,用任务形态分流。 |
上下文交接:切换工具时不要丢工作
最稳的上下文不是某个 agent 的聊天历史,而是两个工具都能重新读取的工程证据。Codex 会读取 AGENTS.md 里的项目指导;Claude Code 的主入口是 CLAUDE.md,不是 AGENTS.md。如果仓库已经有 AGENTS.md,就让 CLAUDE.md 导入 @AGENTS.md,再把 Claude 专属规则写在下面。这样共享规则只有一份,不会因为手工复制而漂移。
切换时按这几层拆:
| 上下文层 | 放在哪里 | 交接规则 |
|---|---|---|
| 仓库长期规则 | AGENTS.md,并由 CLAUDE.md 导入 | 一份共享规则,不要维护两份近似文件。 |
| 当前任务状态 | issue、PR 备注或 HANDOFF.md | 写目标、当前进度、失败证据和下一步,不贴整段 transcript。 |
| 代码事实 | Git diff、分支、测试输出、日志 | 下一个工具从文件和验证结果开始,不从语气判断开始。 |
| 权限与安全 | 任务包里的允许/禁止范围 | 只描述需要的权限,不粘贴 API key、token、私密日志。 |
| 长期经验 | 反复出现的规则才进长期记忆 | 一次性任务噪音不要写进长期规则。 |
handoff packet 可以很短:
md## Agent handoff packet 目标: 当前状态: 改过的文件: 跑过的命令/测试: 已知失败: 已经做出的决定: 不要重复做: 下一步: 权限/安全边界:
一个好的交接不是“继续上面的内容”,而是“修 auth/session.test.ts 的 expired-token refresh 失败;改动集中在 src/auth/session.ts 和测试文件;不要碰 billing middleware;下一步先补 refresh guard,再跑 npm test -- auth/session.test.ts”。这类交接既能让 Codex 接上 Claude Code 的探索,也能让 Claude Code 接上 Codex 产出的 diff。
团队场景里还要给 handoff packet 加三条硬规则。第一,交接前必须看一次 Git 状态,区分已提交、未提交、未跟踪文件和由 agent 新增的临时文件;否则下一个工具可能把旧 diff 当成自己要维护的目标。第二,交接包必须写“不要重复做什么”,例如不要重新设计鉴权流程、不要重跑昂贵的数据迁移、不要改动已经被 reviewer 接受的文件。第三,交接包必须写清验证责任:Codex 接手时要给出可 review 的 diff 和命令输出,Claude Code 接手时要解释本地失败原因和权限边界。这样切换工具才是工程交接,不是把同一个模糊任务交给两个 agent 重新猜一遍。
不要把长期记忆当作万能同步层。Claude Code 的 memory 和 Codex 的会话摘要都能减少重复解释,但它们不应该成为任务真相。任务真相应该能被人类 reviewer 打开、修改、拒绝和归档。最简单的做法是在 issue 或 PR 顶部放一个短区块:主路径是谁、验证路径是谁、验证路径只回答哪个问题、超过多少分钟就停止。这个区块比长聊天记录更适合团队复盘,也更能避免两个工具在同一段代码上各自发散。
如果交接包写不出这些内容,说明任务还没有被拆清楚。此时不要升级模型,也不要换工具重试;先回到人类决策,把验收命令、禁止目录和失败条件补齐。
写不清交接包,本身就是真正明确暂停信号。
额度、token 和真实工作时长怎么换算
开发者讨论里经常出现“Claude Code 100 小时 vs Codex 20 小时”“5-hour limit”这类说法。它们有参考价值,但不能当公式。真实工作时长取决于四件事:上下文是否越来越大、用的是 Sonnet/Opus 还是 GPT-5.5/GPT-5.3-Codex、任务是在本地还是云端跑、最后人工 review 花多久。
Codex 更容易做成可见的额度账本。OpenAI 当前 Codex pricing 明确说 local messages 和 cloud tasks 共享五小时窗口,还可能有周限制;同一个 message 的消耗会因为模型、任务大小、复杂度、本地或云端执行而变化。因此不要只看剩余额度百分比,要记录完成任务数、通过检查的 diff、失败分支和 review 时间。
Claude Code 更容易在一个小时里被人持续操纵,但长会话也更容易烧额度。Anthropic 文档说明,每一轮都会带上之前对话、项目上下文和新 prompt;调试越久、读过的文件越多、生成过的 diff 越多,后续每一轮的负担越重。所以 '/clear'、'/compact'、模型选择、关掉不必要工具,都会直接影响五小时窗口的体感续航。
最实用的换算不是“每美元多少小时”,而是“每次撞限前拿到多少可接受工作单元”。Claude Code 如果帮你两次快速找准复杂根因,而 Codex 给你六个可合并分支,它们都是价值,只是形态不同。选择那个撞限后最容易恢复工作的工具。
具体记录时,可以把一次工作拆成四列:任务目标、agent 实际读写了什么、你花了多久 review、最后是否进入主分支。Claude Code 的优势通常体现在“少走弯路”和“更快确认方向”;Codex 的优势通常体现在“可排队执行”和“失败分支可丢弃”。这两个优势不能只用小时数相除,必须回到交付物质量。
还有一个判断点是“中断成本”。Claude Code 撞限时,常见损失是本地思路被打断,下一次要重建上下文;Codex 撞限或失败时,常见损失是一个异步分支没有产出,但主会话不一定被打断。因此同样一次 limit hit,对不同工作流的伤害不同。你需要记录的不只是撞限次数,还要记录恢复到可继续工作的分钟数,以及是否需要重新解释任务背景。
如果恢复成本很高,优先选择不容易打断主线的方案;如果恢复成本低,优先选择单位时间产出更多可审查变更、可重复验证的方案,并保留复盘样本。
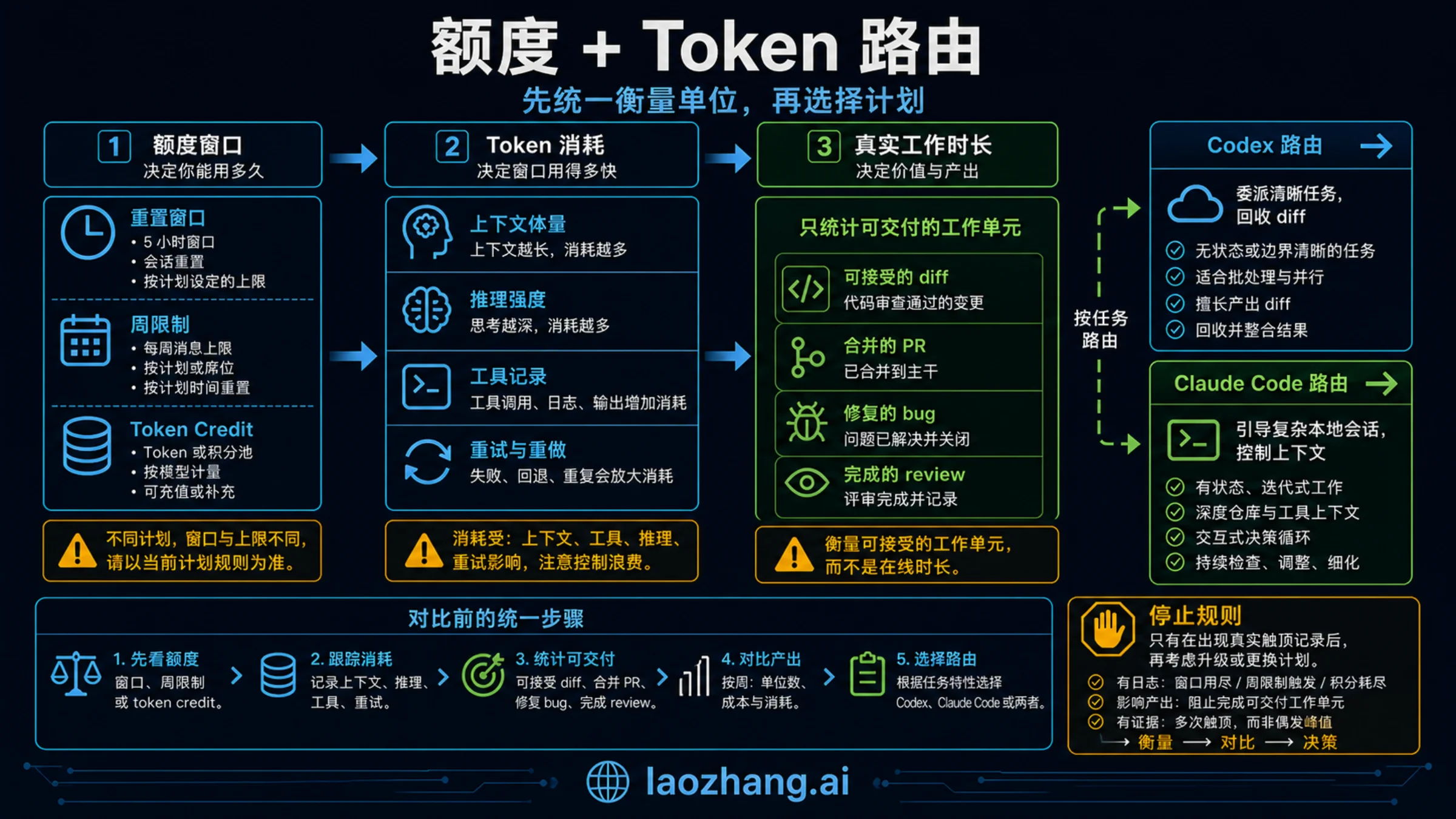
额度:不要把两个产品都压成一个数字
Codex 的当前优势之一是额度表更容易被拆开理解。OpenAI 的 Codex pricing 页面把 Plus 标为每月 20 美元,面向每周几次集中的编码会话,并列出 Web、CLI、IDE extension、iOS、自动 code review、Slack 集成,以及 GPT-5.5、GPT-5.4、GPT-5.3-Codex 和 GPT-5.4-mini。这里最关键的是“分类”:本地消息、云任务、代码审查和模型选择不是同一个额度。
所以,看到论坛里说“Codex 给得更多”或“Codex 很快耗尽”时,要先问三个问题:用的是哪个模型?跑的是本地消息、云任务还是 review?看的是五小时窗口还是周限制?如果这三层没有分清,结论很容易过期。
Claude Code 的额度逻辑不同。Anthropic 的 Claude Code usage 文档把登录方式放在第一层:用企业 seat 登录,是组织计划内的滚动窗口;用 API key,则是按 token 计费。它还明确提醒用户管理上下文窗口,因为长会话会持续携带历史内容,既影响质量,也影响额度消耗。'/clear' 适合切换任务,'/compact' 适合长任务中段续航。
Anthropic 在 2026 年 5 月 6 日又宣布提升容量:Pro、Max、Team 和 seat-based Enterprise 的 Claude Code 五小时 rate limit 翻倍,并取消 Pro 与 Max 的高峰期限制下调。这说明旧的抱怨不能直接照搬,但也不代表 Claude Code 变成无限。
成本:订阅价格只是第一层
表面看,两边价格很像。Claude Pro 是 20 美元/月,Max 5x 是 100 美元/月,Max 20x 是 200 美元/月。Codex 这边,Plus 是 20 美元/月,Pro 从 100 美元/月起,也有 5x 或 20x 的更高限制。
差别在第二层。Claude Code 可以走订阅,也可以走 API key。Anthropic 的成本文档说明,API 用法按 token 消耗计费;Pro 和 Max 订阅用户的使用量包含在订阅里,'/usage' 的美元估算并不等于订阅账单。它还给出企业部署的经验数:活跃开发者平均每天约 13 美元,每月约 150 到 250 美元,但模型选择、代码库大小、并行实例和自动化都会改变成本。
Codex 对个人用户的订阅入口更简单:Plus 和 Pro 直接包含 Codex。但简单不等于没有成本。GPT-5.5 本地消息、云任务、review 都会占用窗口;你付的不是单次 API 账单,而是有限的高价值工作机会。
低风险做法是先买一个月 20 美元,记录一周:哪类任务最常撞限制,哪类任务返工最多,哪个工具给出的 diff 更好 review。没有这份记录,不要直接跳 100 或 200 美元档。
稳定性:看状态页,也要看工作风险
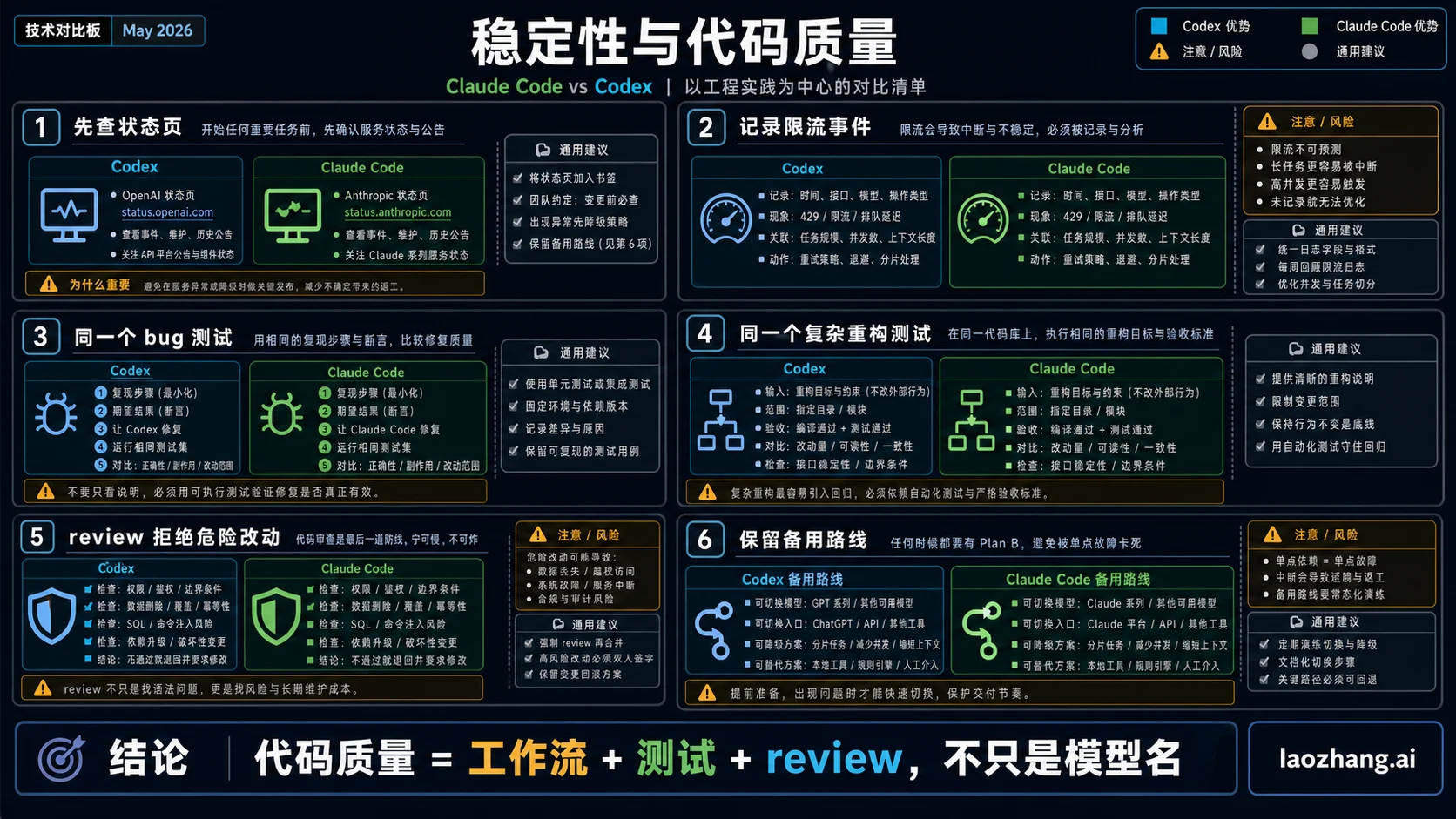
稳定性不能只凭品牌印象。2026 年 5 月 23 日,OpenAI 状态页显示 Codex 有一个“更多用户遇到 rate limit”的 ongoing incident,同时 Codex 在 2026 年 2 月到 5 月窗口里的 aggregate uptime 仍是 99.98%。这不是简单的好或坏,而是提醒你:高整体 uptime 仍可能和你当天最关心的额度问题同时存在。
Claude 状态页在同一天显示当天没有 incident,但 5 月 12 日到 22 日之间有多起已解决事件,涉及 Claude.ai、Opus 4.7、Haiku 4.5、Claude Code login 或 Web surface。对开发者来说,这意味着不要把一次稳定体验当成永久保证,也不要把一次事故当成永久判决。
更实用的办法是按工作风险设规则。交互式长会话怕中断,就保留可切换模型或轻量任务;异步任务怕浪费时间,就把任务限定在可丢弃分支里。团队要记录的是哪类故障影响工作:本地会话中断、云任务失败、review 延迟、登录失败,还是模型质量下降。
代码质量:评估工作流,不只评估模型名
OpenAI 对 GPT-5.5 的主张很强:它在 agentic coding 上比 GPT-5.4 更强,在 Codex 任务中使用更少 token,并且更擅长跨大系统保持上下文、处理模糊失败、用工具验证假设和把改动推进到周边代码。这个证据支持 Codex 在“可委派、可测试、可 review”的工程任务上继续变强。
Anthropic 对 Opus 4.7 的主张也很强:它强调 advanced software engineering、长任务一致性、指令遵循、输出前自检,以及 Claude Code 中更高的默认 effort。这个证据支持 Claude Code 在“复杂、长期、需要精细判断”的本地或半本地任务上继续有优势。
所以别问哪个一定写出更好代码。更好的测试是四个任务:一个有现成测试的 bug、一个带未提交本地状态的复杂重构、一个边界清楚的异步实现、一个需要拒绝危险改动的 review。谁的可用 diff 更多、返工更少、测试更可靠、承认不确定性更清楚,谁才是你当前代码库里的更好工具。
权限与安全边界
Claude Code 的权限系统更细。它有 allow、ask、deny 规则,可以放进版本控制并在组织内分发;权限模式包括 'default'、'acceptEdits'、'plan'、'auto'、'dontAsk' 和 'bypassPermissions'。其中 'bypassPermissions' 只适合隔离环境,因为它会跳过很多提示。
Codex 的优势是边界更好解释。OpenAI 文档把 Codex cloud 描述为 OpenAI 托管的隔离容器:setup 阶段可以安装依赖,agent 阶段默认离线,除非你开启互联网访问。本地 CLI 和 IDE 则通过 OS 级 sandbox 控制,默认无网络,写权限限制在当前 workspace。Codex Auto preset 可以在工作目录内读文件、编辑、运行命令;跨 workspace 或网络命令会请求批准。
因此,Claude Code 适合权限细则复杂的团队;Codex 适合想要更少概念旋钮、清晰本地与云端边界的团队。
混合工作流
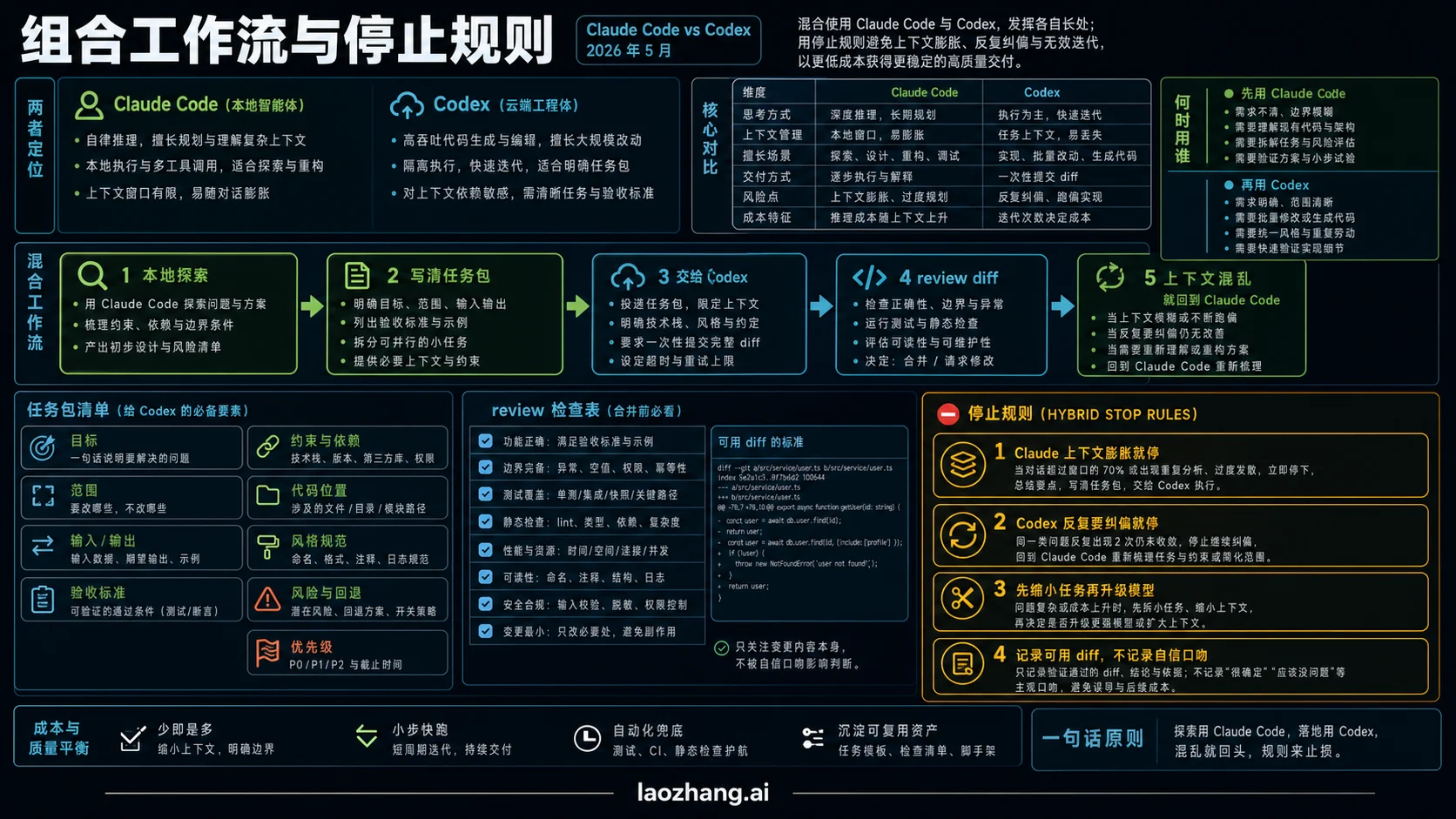
用 Claude Code 处理不确定的前半段:读仓库、看失败、验证假设、确认改动落点。等任务变成清晰的实现单元,再交给 Codex 跑分支、补测试或做 review。这样不是“两个都买所以两个都用”,而是让每个工具只做它的优势段。
停止规则也要写清楚。Claude Code 会话上下文膨胀、开始绕圈、或任务已经变成干净 ticket 时,就停下来交给 Codex。Codex 任务连续漏掉仓库语境、需要反复中途纠偏、或 diff 比手写更难 review 时,就停下来回到 Claude Code。
购买前的一周校准
真正有价值的选择不是看一天的手感,而是看一周的工作记录。第一天只做低风险任务:让 Codex 跑一个边界清楚的小改动,让 Claude Code 读一次你熟悉的本地仓库。不要马上升级,也不要用一次惊艳或一次翻车下结论。你要记录的是工具在真实开发节奏里的表现:有没有撞到额度、有没有因为上下文变大而开始胡乱推进、有没有把一个清楚任务做成难以 review 的大 diff。
第二到第四天,把任务分成三类。第一类是“可以委派”的任务,例如补测试、修明显 bug、按文档迁移一个配置项、把 review 建议落到分支里。这类任务适合先给 Codex,因为它的价值在于让任务离开当前会话,最后以 diff、日志和 review 结果回来。第二类是“需要盯着方向”的任务,例如拆历史债、处理多个未提交文件、判断错误根因、和 agent 一起探索修复路径。这类任务更适合 Claude Code,因为本地上下文、权限提示和连续纠偏本身就是工作的一部分。第三类是“还没想清楚”的任务,不应该直接丢给任何 agent;先写出目标、失败条件、可运行命令和禁止改动范围。
第五到第七天,开始看成本。不是只看订阅价格,而是看“可用结果”价格。一个 20 美元计划如果让你每周少做十次机械 review,就可能已经值;一个 100 美元计划如果只是让 agent 生成更多需要返工的 diff,就不值。记录四个数字:有效 diff 次数、被你完全重写的次数、撞限或等待次数、因为 agent 输出导致额外排查的次数。这个记录比论坛里任何“谁更强”的帖子都更接近你的真实答案。
升级到 100 或 200 美元前,再问一个问题:你是缺 Claude Code 的长会话空间,还是缺 Codex 的并行委派空间?如果每天最痛的是本地探索被打断、上下文需要反复重建、权限规则要细控,先看 Claude Max。如果最痛的是 backlog 太多、review 太慢、清楚任务没法排队跑,先看 Codex Pro。两个答案都不是永久决定;它们只是当前工作流的预算配置。
团队落地模板
团队不要从“统一哪一个工具”开始,而要从“哪些任务允许 agent 进入”开始。建议把任务先分成四个标签:local-investigation、delegated-implementation、review-only、blocked-human-decision。第一类默认 Claude Code,要求开发者在本地会话里保持测试命令、权限范围和停止规则。第二类默认 Codex,要求任务包写清楚目标文件、验收命令、不得修改的目录和预期 diff 粒度。第三类可以交给 Codex review,也可以让 Claude Code 做局部解释,但必须由人决定是否合并。第四类不要交给 agent,因为问题本身还没有被人拆清楚。
团队还要把“稳定性”拆成可记录事件。不要写“Codex 不稳定”或“Claude 更稳”这种无法复盘的句子。记录具体类型:登录失败、rate limit、云任务失败、本地命令被权限挡住、输出质量下降、review 结果延迟、模型切换后表现变化。每条记录都带日期、计划、模型、任务类型和影响范围。三周后你会看到真正的模式:也许某个工具在周一上午容易撞限,也许某类 repo 更适合 Claude Code,也许 Codex 对固定模板任务反而最省时间。
最后,把安全边界写进任务包。Claude Code 任务要明确哪些目录可以改、哪些命令必须先问、什么时候用 '/clear' 重开上下文。Codex 任务要明确是否允许联网、setup 阶段装什么、agent 阶段跑哪些测试、生成的分支怎样 review。这个模板会让“哪个工具更好”的争论变成可执行的交付规则,也更适合以后把流程交给新同事。
如果团队里已经有人同时买了两个工具,还要避免另一种浪费:把同一件事在两个 agent 里各跑一遍,然后挑一个看起来顺眼的结果。正确做法是先指定主路径,再指定对照路径。比如安全相关改动可以由 Claude Code 做本地探索和风险解释,再让 Codex 做独立 review;机械依赖升级可以由 Codex 先跑分支,再让 Claude Code 帮你解释失败测试。对照路径只回答一个明确问题,不负责重新做全量实现。
复盘时也不要只看成功案例。最值得保存的是失败样本:某个 Codex cloud task 为什么反复漏掉仓库约定,某次 Claude Code 长会话为什么从精准变成发散,某个权限提示是否说明任务包写得太宽。把这些失败样本转成下一次 prompt、权限规则或停止条件,工具选择才会越来越稳。否则,你只是在订阅之间来回切换,而不是让开发流程变好。
还有一个经常被忽略的点:不要把“代码质量”只交给 agent 自己评价。每次试用都要带上人类已经信任的验证方式,例如现有测试、类型检查、lint、线上日志、回滚路径和 reviewer 的明确问题。Claude Code 说自己理解了仓库不等于它真的理解;Codex 生成了漂亮分支也不等于可以合并。只有当工具输出能通过你原本就会使用的工程证据,选择才有意义。
所以,最终表格可以很短:任务是否清楚、是否需要本地持续纠偏、是否能独立 review、失败是否容易丢弃、是否触碰敏感目录、是否需要当天高稳定性。前三项偏 Codex,后三项偏 Claude Code 或人工先拆解。这个表格比“哪个模型更聪明”更适合放进团队规范。
如果一周后仍然难选,就先保留 20 美元档,不升级。真正该升级的信号不是“想多用一点”,而是记录里连续出现同一种瓶颈,并且这个瓶颈已经阻碍交付。
没有这种证据,升级只是换一种不确定性,也会让团队更难复盘真实问题。
落地时可以把这个判断放进 issue 模板:本次任务主路径是谁,验证路径是谁,验证路径只回答哪一个问题,超过多少分钟就停止。这样既能利用两个工具的优势,也能避免同一个需求被两个 agent 扩写成两套互不兼容的方案。
如果验证路径发现的是任务定义问题,而不是实现问题,下一步应该回到人类拆解,而不是继续加模型额度。
这条规则能避免把管理问题误判成模型问题,也能减少无意义的订阅升级和团队反复争论成本。
常见问题
Claude Code 能直接读 AGENTS.md 吗?
不能把它当作主入口。Claude Code 默认读 CLAUDE.md。如果仓库已经给 Codex 写了 AGENTS.md,就在 CLAUDE.md 里导入 @AGENTS.md,再补 Claude 专属说明。
要把整个 Codex 聊天记录贴给 Claude Code 吗?
不要。贴 handoff packet:目标、文件、命令、失败、决定、不要重复做的事和下一步。真正的上下文应该回到仓库、diff、测试和任务包。
20 美元档先买谁?
没有固定偏好时先买 Codex Plus。它覆盖的 coding-agent surface 更多,额度分类也更清晰。主要例外是本地复杂开发者:如果你每天都在未提交变更和权限规则里工作,Claude Pro 加 Claude Code 可能更顺手。
Claude Code 提升额度后还会不够用吗?
会。5 月 6 日的提升增加了空间,但长上下文、模型选择和高 effort 仍会消耗额度。把它理解成更大的工作窗口,不是无限窗口。
谁的代码质量更好?
Codex 更适合可委派、可测试、可 review 的任务;Claude Code 更适合长时间交互、复杂推理和权限敏感的本地任务。代码质量最终取决于测试、review、上下文卫生和停止规则。
谁更稳定?
两边都要看当天状态页。OpenAI 当天有 Codex rate-limit incident,但总体 uptime 仍高;Claude 当天无 incident,但前几天有多起已解决事件。关键工作前要有 fallback。
团队要不要统一一个工具?
除非团队任务高度一致,否则统一路由规则比统一工具更好:复杂探索给 Claude Code,明确委派和 review 给 Codex。