
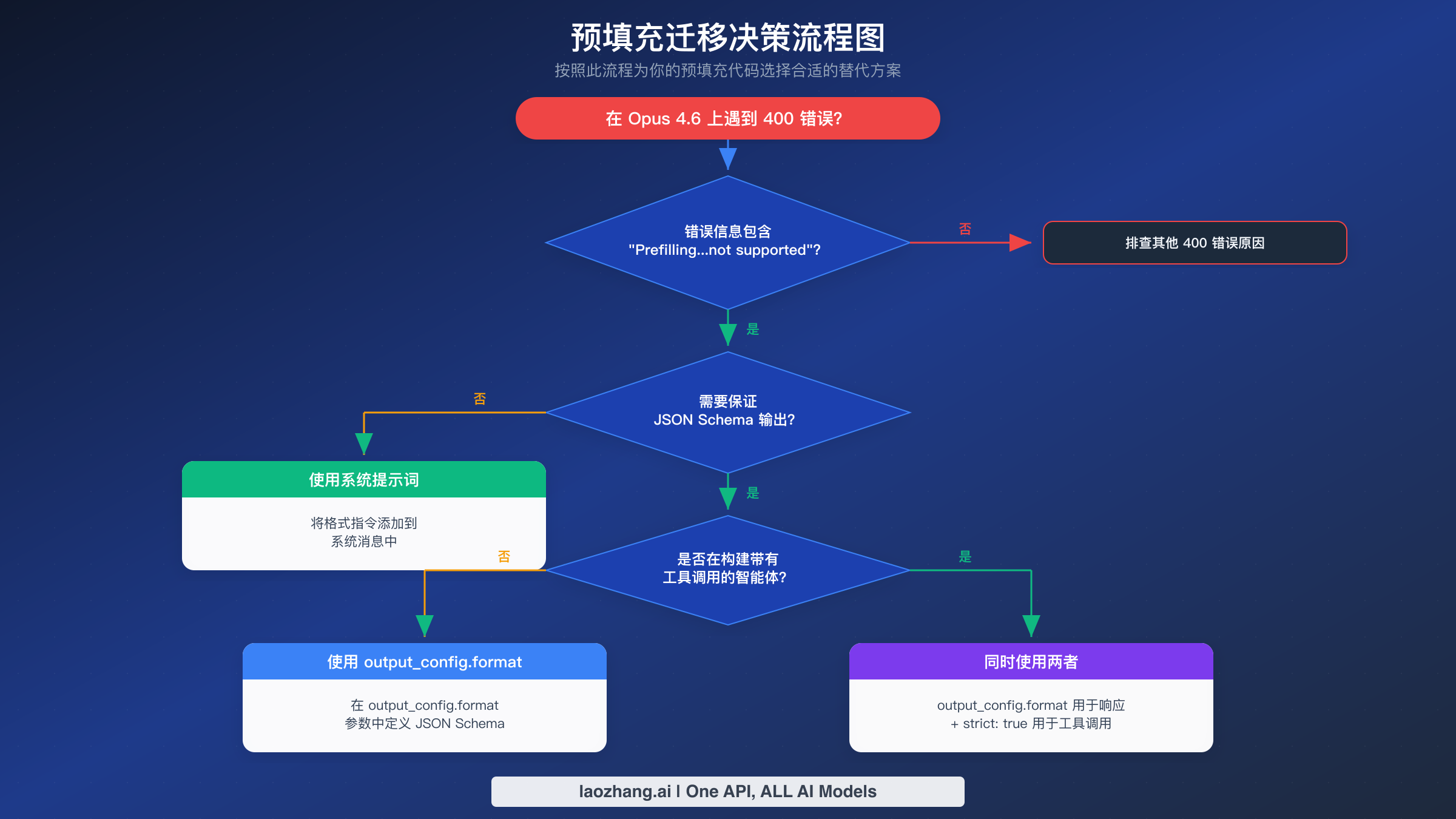
Claude Opus 4.6 引入了一个让许多开发者措手不及的破坏性变更:assistant 消息预填充功能不再可用。如果你最近将模型 ID 切换到 claude-opus-4-6 后 API 调用开始返回 400 错误,你并不是唯一遇到这个问题的人。本指南将详细说明具体发生了什么变化、Anthropic 为什么做出这个决定,以及三种修复代码的具体方案(附完整的前后对比示例)。
要点速览
Anthropic 在 Claude Opus 4.6(claude-opus-4-6)和 Sonnet 4.5(claude-sonnet-4-5-20250929)中移除了 assistant 消息预填充支持。任何在 messages 数组最后一项包含预填充 assistant 消息的 API 请求,都将返回 400 invalid_request_error,错误信息为:"Prefilling assistant messages is not supported for this model."
根据你的具体使用场景,你有三种替代方案可选:
| 方案 | 最适合场景 | 复杂度 | JSON 保证 |
|---|---|---|---|
output_config.format | 结构化 JSON 响应 | 中等 | 是,schema 验证 |
| 系统提示词指令 | 输出风格和格式控制 | 低 | 无保证 |
严格工具调用(strict: true) | 带函数调用的智能体工作流 | 高 | 是,针对工具参数 |
最快的修复方式是从 messages 数组中移除预填充的 assistant 消息,然后将格式化指令添加到系统提示词中。对于生产环境中需要保证 JSON 输出的应用,应迁移到 output_config.format 并定义 JSON schema。本指南的其余部分将逐一展示每种方案的具体实现方法。
为什么升级到 Opus 4.6 后 Claude API 返回 400 错误
在开始修复之前,有必要了解预填充是什么以及 Anthropic 为什么要移除它。这些背景信息很重要,因为你选择哪种替代方案取决于你最初使用预填充的目的。
预填充是什么。 在早期的 Claude 模型中,你可以在 messages 数组的最后一项放入一条 assistant 消息。模型会从该位置继续生成,将你提供的文本视为响应的开头。开发者通常使用这种技巧来强制输出 JSON(以 { 开头)、通过预填充特定结构来控制响应格式,或者通过提供开头词来引导模型朝特定方向回答。
以下是预填充在实际使用中的典型示例。你发送一条用户消息请求数据,然后附加一条仅包含左大括号的 assistant 消息。模型会从该大括号继续生成并完成整个 JSON 对象,这使得响应大概率(但从未保证过)是有效的 JSON。
pythonresponse = client.messages.create( model="claude-3-5-sonnet-20241022", max_tokens=1024, messages=[ {"role": "user", "content": "List the top 3 programming languages"}, {"role": "assistant", "content": "{"} # Prefilling ] )
现在在 Opus 4.6 上会发生什么。 当你使用 model="claude-opus-4-6" 发送同样的请求时,API 会在任何 token 生成之前立即拒绝请求。你收到的不是模型输出,而是一个错误对象:
json{ "type": "error", "error": { "type": "invalid_request_error", "message": "Prefilling assistant messages is not supported for this model." } }
HTTP 状态码是 400,意味着这是一个客户端错误。根据新模型的要求,你的请求格式不正确。不会消耗任何 token 也不会产生费用,但如果你不处理这个错误,应用程序将在此处崩溃。
Anthropic 为什么做出这个变更。 移除预填充是 Claude 4.x 模型向更强大的结构化输出机制进行架构升级的一部分。预填充一直是一种变通方案而非正式的 API 功能。它有几个根本性的局限:无法保证输出有效的 JSON(模型仍可能产生格式错误的输出)、在上下文窗口中消耗 token 却没有清晰的归属,以及与扩展思考等新功能冲突(模型需要控制自己的响应流程)。通过移除预填充,Anthropic 可以通过 output_config.format 提供真正有保障的结构化输出,在 API 层面根据 JSON schema 进行验证,而不是依赖生成技巧。
哪些模型受影响。 根据 Anthropic 当前文档(2026 年 2 月),Claude Opus 4.6(claude-opus-4-6)和 Claude Sonnet 4.5(claude-sonnet-4-5-20250929)不支持预填充。旧模型如 Claude 3.5 Sonnet 和 Claude 3 Opus 仍然支持预填充,因此针对这些模型 ID 的现有代码将继续正常工作。但这些旧模型最终会被弃用,所以迁移是不可避免的。
如何确认这就是你的问题。 验证你是否遇到了预填充错误(而非其他 400 错误)的最快方式是检查 API 响应体中的错误信息字符串。准确的文本是 "Prefilling assistant messages is not supported for this model."。如果你看到的是其他信息,如 "messages: roles must alternate between 'user' and 'assistant'" 或 "model not found",那你遇到的是不同的问题。同时检查你的 HTTP 客户端错误处理:某些框架会捕获 400 状态码但丢弃响应体,导致难以看到实际的错误信息。确保你的错误处理器记录完整的响应 JSON,而不仅仅是状态码。
三种预填充替代方案详解

选择正确的替代方案取决于你之前使用预填充的目的。每种方案在实现复杂度、输出保证和与其他 Claude 功能的兼容性方面有各自不同的权衡。下面我们逐一详细分析每种方案,帮助你做出明智的决策。
方案一:使用 output_config.format 配合 JSON Schema。 这是 Anthropic 官方推荐的预填充替代方案,适用于需要保证结构化输出的场景。你定义一个 JSON schema 来描述期望的响应结构,API 确保模型输出符合该 schema。验证发生在 API 层面而非提示词工程层面,这意味着你永远不会收到格式错误的 JSON。
关键优势在于可靠性。与预填充只是"暗示"模型输出 JSON 不同,output_config.format 提供硬性保证。如果你在 schema 中定义了特定的必填字段,响应将始终包含这些字段且类型正确。这消除了预填充方案常见的重试逻辑和 JSON 解析错误处理的需要。代价是你需要预先定义 schema,并且使用新 schema 的第一次请求会有额外的延迟(API 需要编译 schema 约束)。后续使用相同 schema 的请求则速度很快。
需要注意一个重要限制:output_config.format 目前与 citations(引用)功能不兼容。如果你的应用使用了 Claude 的引用功能,需要选择其他方案。
方案二:系统提示词指令。 这是最简单的迁移路径,适用于不需要严格 schema 验证的场景。不再预填充 assistant 消息来暗示期望的格式,而是在系统提示词中包含明确的格式化指令。例如,你可以添加"Always respond in valid JSON with the following structure:"然后跟上示例结构。
优势是零额外复杂度。你不需要定义 schema、安装新版 SDK 或更改响应解析逻辑。系统提示词方案还与所有 Claude 功能兼容,包括 citations、扩展思考和工具调用。缺点是无法保证模型每次都会产生有效的 JSON。Claude 4.x 模型在遵循系统提示词指令方面非常可靠,但边缘情况确实存在,尤其是在非常复杂的嵌套结构或模型需要表达不确定性时。
方案三:严格工具调用(strict: true)。 这种方案最适合智能体工作流,即你需要模型在函数调用管道中生成结构化数据的场景。你定义带有输入 schema 的工具,并在每个工具定义上设置 strict: true。API 随后保证工具调用参数符合 schema,类似于 output_config.format 对直接响应的工作方式。
当你的应用已经在使用工具调用时,这种方案最有意义。你可以定义一个"响应"工具,其唯一目的就是结构化模型的输出,实际上将工具调用变成了一种结构化输出机制。复杂度比其他两种方案更高,因为你需要工具定义,并且必须以不同于普通文本响应的方式处理工具调用响应。不过,你可以将严格工具调用与 output_config.format 结合使用:前者用于函数调用参数,后者用于直接响应,为你的应用提供全面覆盖。
| 功能特性 | output_config.format | 系统提示词 | 严格工具调用 |
|---|---|---|---|
| JSON 保证 | 是 | 否 | 是(工具参数) |
| 需要 Schema | 是 | 否 | 是 |
| 首次请求延迟 | 较高 | 无 | 较高 |
| 兼容 citations | 否 | 是 | 是 |
| 兼容 thinking | 是 | 是 | 是 |
| 实现工作量 | 中等 | 低 | 高 |
| 最适合 | API 响应 | 快速迁移 | 智能体系统 |
分步迁移代码示例
本节提供每种替代方案的完整前后对比代码,你可以直接将这些示例复制到代码库中。所有示例都使用当前版本的 Anthropic SDK,并遵循 2026 年 2 月的官方 API 规范。
迁移路径一:从预填充迁移到 output_config.format
这是最常见的迁移路径,适用于之前使用预填充来强制 JSON 输出的应用。旧代码包含带有左大括号的 assistant 消息,新代码使用结构化 schema 定义来替代。
迁移前(在 Opus 4.6 上报错):
pythonimport anthropic client = anthropic.Anthropic() # This returns 400 on Opus 4.6 response = client.messages.create( model="claude-opus-4-6", max_tokens=1024, system="You are a helpful assistant that provides data in JSON format.", messages=[ {"role": "user", "content": "List the top 3 programming languages by popularity"}, {"role": "assistant", "content": "{"} # BREAKS on Opus 4.6 ] )
迁移后(在 Opus 4.6 上正常工作):
pythonimport anthropic client = anthropic.Anthropic() response = client.messages.create( model="claude-opus-4-6", max_tokens=1024, system="You are a helpful assistant that provides data in JSON format.", messages=[ {"role": "user", "content": "List the top 3 programming languages by popularity"} ], output_config={ "format": { "type": "json_schema", "schema": { "type": "object", "properties": { "languages": { "type": "array", "items": { "type": "object", "properties": { "name": {"type": "string"}, "rank": {"type": "integer"}, "description": {"type": "string"} }, "required": ["name", "rank", "description"], "additionalProperties": False } } }, "required": ["languages"], "additionalProperties": False } } } ) # Response content is guaranteed valid JSON matching your schema import json data = json.loads(response.content[0].text) print(data["languages"][0]["name"]) # Guaranteed to exist
如果你使用 Pydantic 进行数据验证,Anthropic Python SDK 提供了一个便捷的 .parse() 方法,将 schema 生成和响应解析合并为一步:
pythonfrom pydantic import BaseModel from typing import List class Language(BaseModel): name: str rank: int description: str class LanguageList(BaseModel): languages: List[Language] # Pydantic integration - schema auto-generated from model response = client.messages.parse( model="claude-opus-4-6", max_tokens=1024, messages=[ {"role": "user", "content": "List the top 3 programming languages by popularity"} ], output_format=LanguageList, ) # response.parsed is already a LanguageList instance for lang in response.parsed.languages: print(f"{lang.rank}. {lang.name}: {lang.description}")
TypeScript 等效代码:
typescriptimport Anthropic from "@anthropic-ai/sdk"; import { z } from "zod"; const client = new Anthropic(); // Using Zod schema const LanguageSchema = z.object({ languages: z.array(z.object({ name: z.string(), rank: z.number(), description: z.string(), })), }); const response = await client.messages.create({ model: "claude-opus-4-6", max_tokens: 1024, messages: [ { role: "user", content: "List the top 3 programming languages by popularity" } ], output_config: { format: { type: "json_schema", schema: LanguageSchema, }, }, }); const data = JSON.parse(response.content[0].text); console.log(data.languages[0].name);
迁移路径二:从预填充迁移到系统提示词
当你不需要 schema 级别的保证时,这是最快速的迁移方式。只需移除 assistant 消息,并将格式指令移入系统提示词即可。
迁移前(在 Opus 4.6 上报错):
pythonresponse = client.messages.create( model="claude-opus-4-6", max_tokens=1024, messages=[ {"role": "user", "content": "Analyze this code for bugs"}, {"role": "assistant", "content": "## Bug Analysis\n\n"} # BREAKS ] )
迁移后(在 Opus 4.6 上正常工作):
pythonresponse = client.messages.create( model="claude-opus-4-6", max_tokens=1024, system=( "You are a code review assistant. Always structure your response as follows:\n" "1. Start with a '## Bug Analysis' heading\n" "2. List each bug with severity level\n" "3. Provide fix suggestions for each bug" ), messages=[ {"role": "user", "content": "Analyze this code for bugs"} ] )
系统提示词方案在控制响应风格和结构方面特别有效,尤其是当你不需要 JSON 输出时。如果你之前使用预填充来让响应以特定文本开头(如标题或特定短语),这几乎总是正确的替代方案。一个效果很好的技巧是在系统提示词中包含期望输出格式的明确示例。不要寄希望于模型遵循模糊的指令,而是直接展示理想响应的前几行应该是什么样子。Claude 4.x 模型在遵循示范模式方面表现出色,这种方式比旧的预填充技巧更可靠,同时又比定义完整 JSON schema 简单得多。
对于需要在数千次 API 调用中保持一致格式的场景(例如,必须始终以特定语调回复的面向客户的聊天机器人),可以将系统提示词与用户消息中的 few-shot 示例相结合。包含一两个你想要的问答格式示例,然后提出实际问题。这为模型提供了强引导,同时没有预填充的限制,也没有 schema 定义的开销。
迁移路径三:从预填充迁移到严格工具调用
这条路径非常适合构建智能体或需要结构化函数调用参数的场景。你定义一个带有严格 schema 的工具,模型的工具调用保证匹配该 schema。
迁移前(在 Opus 4.6 上报错):
pythonresponse = client.messages.create( model="claude-opus-4-6", max_tokens=1024, messages=[ {"role": "user", "content": "What's the weather in Tokyo?"}, {"role": "assistant", "content": '{"tool": "get_weather", "args": {"city": "'} ] )
迁移后(在 Opus 4.6 上正常工作):
pythonresponse = client.messages.create( model="claude-opus-4-6", max_tokens=1024, messages=[ {"role": "user", "content": "What's the weather in Tokyo?"} ], tools=[ { "name": "get_weather", "description": "Get current weather for a city", "strict": True, "input_schema": { "type": "object", "properties": { "city": {"type": "string", "description": "City name"}, "units": { "type": "string", "enum": ["celsius", "fahrenheit"], "description": "Temperature units" } }, "required": ["city"], "additionalProperties": False } } ] ) # Tool calls are guaranteed to match the schema for block in response.content: if block.type == "tool_use": print(f"Tool: {block.name}") print(f"Input: {block.input}") # Always valid JSON matching schema
output_config.format 的 cURL 示例:
bashcurl https://api.anthropic.com/v1/messages \ -H "content-type: application/json" \ -H "x-api-key: $ANTHROPIC_API_KEY" \ -H "anthropic-version: 2023-06-01" \ -d '{ "model": "claude-opus-4-6", "max_tokens": 1024, "messages": [ {"role": "user", "content": "List 3 programming languages"} ], "output_config": { "format": { "type": "json_schema", "schema": { "type": "object", "properties": { "languages": { "type": "array", "items": { "type": "object", "properties": { "name": {"type": "string"}, "rank": {"type": "integer"} }, "required": ["name", "rank"], "additionalProperties": false } } }, "required": ["languages"], "additionalProperties": false } } } }'
常见陷阱与边缘情况
即使你已经移除了预填充的 assistant 消息并实现了三种替代方案之一,在迁移过程中仍有一些微妙的问题可能让你踩坑。本节基于 GitHub issue、社区反馈和官方迁移文档,介绍开发者最常遇到的问题。
扩展思考与预填充的交互。 如果你的应用之前同时使用了预填充和 Claude 的思考功能,迁移时需要格外小心。Opus 4.6 也改变了 thinking API:thinking: {type: "enabled", budget_tokens: 32000} 已被弃用,取而代之的是 thinking: {type: "adaptive"} 配合新的 effort 参数。尝试在旧的预填充模式上使用旧的思考配置会产生一个不同于单纯预填充错误的报错,这可能让调试变得混乱。
同时使用这两个功能的正确迁移方式如下:
python# Before: prefilling + old thinking (broken on Opus 4.6) response = client.messages.create( model="claude-opus-4-6", max_tokens=16000, thinking={"type": "enabled", "budget_tokens": 10000}, betas=["interleaved-thinking-2025-05-14"], messages=[ {"role": "user", "content": "Analyze this dataset"}, {"role": "assistant", "content": "{"} ] ) # After: output_config + adaptive thinking (works on Opus 4.6) response = client.messages.create( model="claude-opus-4-6", max_tokens=16000, thinking={"type": "adaptive"}, output_config={ "effort": "high", "format": { "type": "json_schema", "schema": { "type": "object", "properties": { "analysis": {"type": "string"}, "key_findings": { "type": "array", "items": {"type": "string"} } }, "required": ["analysis", "key_findings"], "additionalProperties": False } } }, messages=[ {"role": "user", "content": "Analyze this dataset"} ] ) # No beta headers needed - both features are GA on Opus 4.6
注意这里同时发生了三个变化:移除预填充、更新思考配置、删除 beta 头。遗漏任何一个都会产生不同的错误,所以务必一起处理。
工具参数引号差异。 Opus 4.6 在工具调用参数中处理 JSON 转义的方式与早期模型不同。如果你的代码依赖工具调用输入中的特定 JSON 格式模式(例如,假定双重转义引号或特定的空白格式),即使工具调用在语义上是正确的,你也可能遇到解析失败。修复方法很简单:始终使用标准 JSON 解析器(Python 中的 json.loads(),JavaScript 中的 JSON.parse()),而不是在工具调用参数上使用字符串匹配或正则提取。
additionalProperties: false 要求。 当使用 output_config.format 配合 type: "json_schema" 时,schema 中的每个对象都必须包含 "additionalProperties": false。这不仅仅是最佳实践,API 会拒绝缺少该字段的 schema。如果你通过数据类或 TypeScript 接口自动生成 schema,确保你的 schema 生成器添加了这个属性。Pydantic 和 Zod 在使用相应 SDK 方法时会自动处理,但自定义 schema 生成器通常会遗漏这一点。
python# This will be rejected by the API bad_schema = { "type": "object", "properties": {"name": {"type": "string"}}, "required": ["name"] # Missing: "additionalProperties": false } # This works good_schema = { "type": "object", "properties": {"name": {"type": "string"}}, "required": ["name"], "additionalProperties": False # Required! }
多模型应用中的版本检查。 如果你的应用支持多个 Claude 模型(例如,复杂任务用 Opus 4.6,简单任务用 Haiku 4.5),你需要针对预填充的条件逻辑。你不能对两条模型路径使用相同的 messages 数组。最简洁的方式是根据目标模型动态构建 messages 数组,或者更好地,将所有模型路径都迁移到三种替代方案之一,这些方案在所有当前 Claude 模型上都表现一致。
流式传输与 output_config.format。 当结合使用 output_config.format 和流式传输时,响应仍然以增量文本块到达。JSON 直到完整响应结束才进行验证。这意味着你无法可靠地解析流式块中的部分 JSON。如果你需要增量处理,考虑在流式场景中使用系统提示词方案,在非流式请求中使用 output_config.format。另一种方式是将 schema 设计为顶层数组,使每个元素可以在到达时独立处理。
Vertex AI 和 Amazon Bedrock 注意事项。 如果你通过 Google Cloud 的 Vertex AI 或 Amazon Bedrock 访问 Claude(而非直接使用 Anthropic API),预填充限制同样适用。无论托管平台是什么,错误信息和行为都是相同的。但 SDK 方法名和参数路径可能略有不同。在 Vertex AI 上,output_config 参数通过相同的 messages API 结构传递。在 Bedrock 上,确保你使用的是支持 output_config 参数的最新版 AWS SDK,因为较旧的 SDK 版本可能不暴露此字段。查阅特定平台的文档以了解确切的参数映射,并注意新的 Anthropic API 功能有时需要几天才能传播到 Vertex AI 和 Bedrock。
优雅地处理过渡期。 在迁移期间,你可能希望应用同时支持新旧两种模型,特别是当不同客户或环境使用不同模型版本时。一种实用的方法是创建一个包装函数,检查模型 ID 并相应调整请求:
pythondef create_message(client, model, messages, system=None, output_schema=None, **kwargs): """Wrapper that handles prefilling differences across model versions.""" # Models that don't support prefilling no_prefill_models = ["claude-opus-4-6", "claude-sonnet-4-5-20250929"] # Check if last message is an assistant prefill if messages and messages[-1]["role"] == "assistant": if model in no_prefill_models: # Remove prefill and use output_config instead messages = messages[:-1] if output_schema: kwargs["output_config"] = { "format": { "type": "json_schema", "schema": output_schema } } return client.messages.create( model=model, messages=messages, system=system, **kwargs )
这种模式让你可以渐进式迁移而不破坏现有功能。当你确认每条代码路径都能使用新方案正常工作后,就可以移除兼容层,直接使用 output_config.format。
如果你在预填充问题之外还遇到其他 Claude API 错误(例如 API Key 认证问题),可以参考 Claude API 认证问题排查指南 进行单独诊断。
完整迁移检查清单

使用这份检查清单确保你涵盖了迁移的每个方面。每个项目都标记为破坏性变更(部署前必须修复)或建议变更(最佳实践应修复)。先处理所有破坏性变更,然后再解决建议项目。
必须修复的破坏性变更:
以下项目如果不处理,将导致 API 调用失败。每一个都会在 Opus 4.6 上产生 400 错误或意外行为。
首先,在整个代码库中搜索 assistant 消息作为 messages 数组最后一项出现的所有实例。这是预填充错误的主要原因。移除这些 assistant 消息并用上述三种方案之一替代。特别注意动态构建 messages 数组的代码路径,预填充逻辑可能隐藏在辅助函数或中间件中。
其次,将模型 ID 更新为 claude-opus-4-6。如果你使用特定模型版本而非别名,确保字符串完全匹配。与 Sonnet 和 Haiku 模型不同,Opus 4.6 的模型 ID 格式不包含日期后缀。
第三,验证 JSON 解析使用标准解析器。如果你之前使用字符串切片从预填充响应中提取 JSON(例如,移除响应开头预填充的 {),该逻辑已不再需要,在新的结构化输出格式下会出错。对完整的响应内容使用 json.loads() 或 JSON.parse()。
第四,如果你从 Claude 3.x 迁移,确保不在同一请求中同时发送 temperature 和 top_p。Opus 4.6 强制要求同时只能指定其中一个采样参数。
第五,处理新的停止原因。Opus 4.6 除了现有的 end_turn、max_tokens、stop_sequence 和 tool_use 之外,还可能返回 refusal 和 context_window 作为停止原因。如果你的代码对停止原因有 switch 语句或条件逻辑,添加这些新值的处理以防止意外行为。
最佳实践的建议变更:
这些项目不会导致即时失败,但代表了将在未来版本中移除的已弃用模式。现在就处理它们可以避免以后再次紧急迁移。
将 thinking: {type: "enabled"} 迁移到 thinking: {type: "adaptive"}。旧的思考配置在 Opus 4.6 上仍然有效但已标记为弃用,将来会被移除。自适应思考更高效,因为模型会根据任务复杂度动态分配思考力度,而不是使用固定的 token 预算。
将 output_format 迁移到 output_config.format。旧版 output_format 参数仍然有效但已弃用。新的 output_config 参数是超集,还支持用于控制思考力度的 effort 参数。
移除不再需要的 beta 头。以下 beta 标志在 Opus 4.6 上已成为正式功能,包含它们不会有任何效果:interleaved-thinking-2025-05-14、effort-2025-11-24、fine-grained-tool-streaming-2025-05-14。此外,移除旧版 beta 头如 token-efficient-tools-2025-02-19 和 output-128k-2025-02-19,它们同样已成为正式功能。
最终部署步骤:
在推送到生产环境之前,在开发环境中针对 Opus 4.6 运行完整的测试套件。特别注意验证响应格式的测试,因为这些最可能受到预填充移除的影响。验证所有 API 响应在新的结构化输出格式下都能正确解析。部署后,监控 24 小时的错误率并准备好回滚计划。如果出现意外问题,回退到 claude-sonnet-4-5-20250929 或你之前的模型是一个合理的短期策略。
Opus 4.6 中其他你应该了解的破坏性变更
虽然预填充移除是最具破坏性的变更,但 Opus 4.6 还包含若干其他破坏性变更可能影响你的应用。在同一个迁移窗口中一并处理这些问题可以减少多次部署周期。
自适应思考取代固定思考预算。 thinking: {type: "enabled", budget_tokens: N} 配置已弃用,替代方案是 thinking: {type: "adaptive"},让模型根据任务复杂度自行决定投入多少思考。你可以通过 effort 参数(支持 max、high、medium、low、min 级别)来影响这一行为。该功能现在是正式功能,不再需要 effort-2025-11-24 beta 头。如果你之前为特定场景精细调整思考预算,effort 参数以更低的运维开销提供了类似的控制力度。
output_format 参数已弃用。 如果你已经在通过旧版 output_format 参数使用结构化输出,注意该参数现已被弃用,取而代之的是 output_config.format。语法略有不同:
python# Deprecated (still works, will be removed) response = client.messages.create( model="claude-opus-4-6", output_format={"type": "json_schema", "schema": {...}}, ... ) # Current (recommended) response = client.messages.create( model="claude-opus-4-6", output_config={ "format": {"type": "json_schema", "schema": {...}} }, ... )
output_config 参数是一个容器,除了 format 之外还支持 effort,提供了更具扩展性的配置面。
值得采用的新功能。 Opus 4.6 带来了若干改进,使得迁移的价值不仅仅限于修复预填充错误。该模型现在支持 128K 输出 token(比之前翻倍),适合之前需要多次 API 调用的长文本生成任务。一个新的快速模式以研究预览形式提供,价格为 $30/M 输入和 $150/M 输出 token,为延迟敏感的应用提供约 2.5 倍的生成速度。Compaction API(测试版)为长对话启用服务端上下文压缩,对于遇到上下文窗口限制的聊天应用特别有价值。数据驻留控制允许你通过 inference_geo 参数指定推理处理的地理位置,满足在 GDPR 或类似数据主权法规下运营的合规要求。
Opus 4.6 标准模式的定价为每百万输入 token $15、每百万输出 token $75(Anthropic 文档,2026 年 2 月)。作为对比,Sonnet 4.5 的价格点明显更低,为 $3/$15 每百万 token,而 Haiku 4.5 提供最具性价比的选择,为 $1/$5 每百万 token。如果你的预填充迁移恰好与更广泛的成本优化同步进行,可以考虑你的一些 Opus 工作负载是否可以由带结构化输出的 Sonnet 4.5 来处理,后者提供相同的 output_config.format 能力,而成本仅为五分之一。
关于 Opus 4.6 与 Sonnet 4.5 在不同任务类别上的详细对比(包括基准测试和定价权衡),请参阅我们的 Claude Opus 与 Sonnet 对比指南。
及时了解 Claude API 变更
Claude API 迭代迅速,及时了解破坏性变更可以预防像预填充移除这样的生产事故。Anthropic 会为每个主要模型版本发布迁移指南,这是获取已弃用功能及其替代方案信息最可靠的来源。官方文档 platform.claude.com/docs 实时更新,应该是你在任何迁移过程中的主要参考资料。
无论你现在是在修复预填充错误还是在规划更广泛的 Opus 4.6 迁移,核心要点是:assistant 消息预填充已从当前 Claude 模型中永久移除。越早迁移到三种结构化输出方案之一(output_config.format、系统提示词或严格工具调用),你的应用对未来 API 变更就越有弹性。从匹配你当前使用场景的方案开始,在开发环境中充分测试,然后自信地部署。
从预填充到结构化输出的迁移对生产应用来说最终是一个积极的变化。虽然预填充是一个效果出奇好的巧妙技巧,但它从来就不是为生产级使用设计的功能。新的方案提供了真正的保证、更好的错误处理,以及与 Claude API 生态系统其余部分的集成。迁移的短期阵痛换来的是更可靠、更易维护的代码,这些代码在 Claude 模型演进时将继续正常工作。