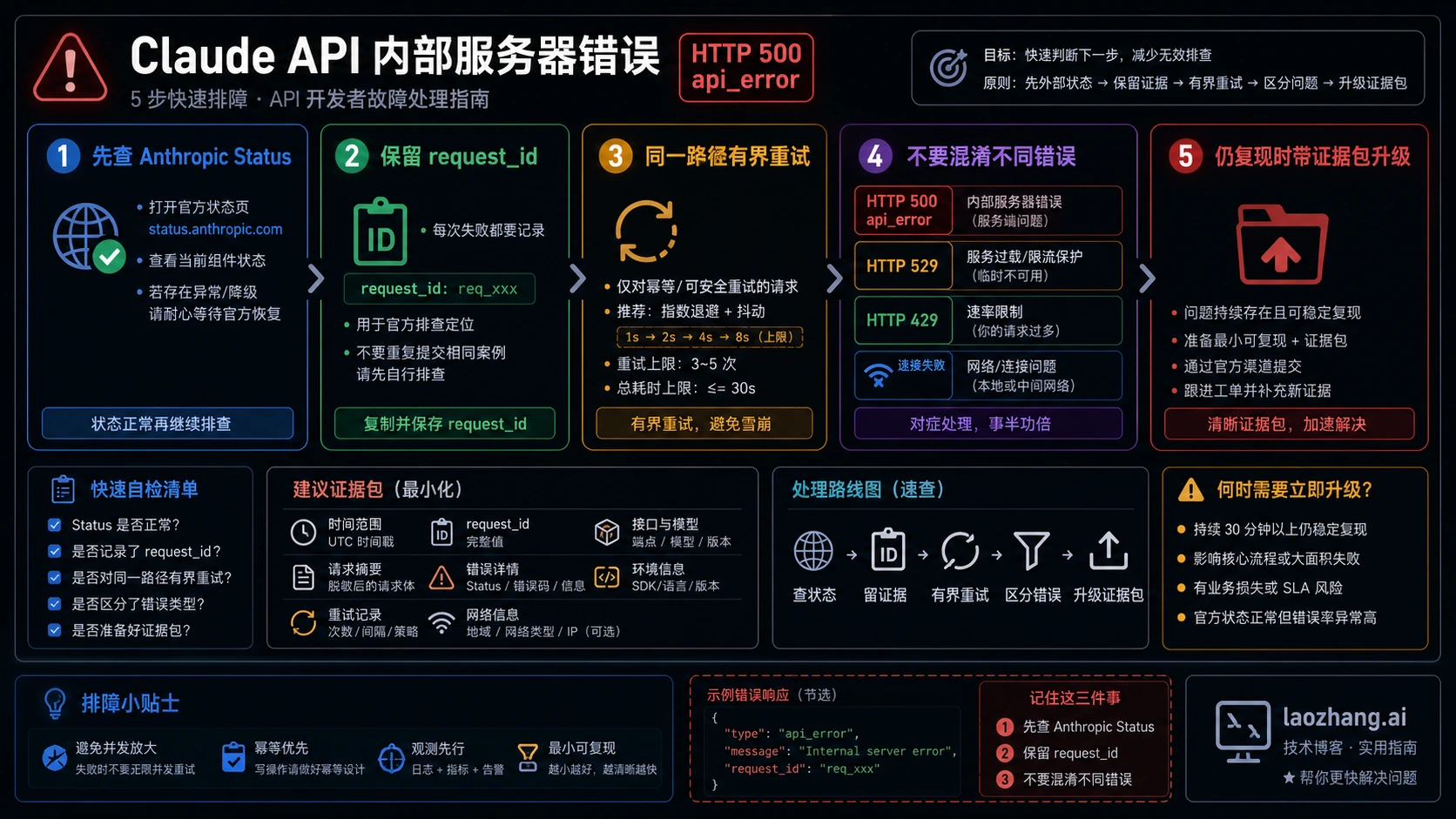
如果 Claude API 返回 API Error: 500,错误类型是 api_error,消息里写着 Internal server error,先把它当作已经返回的服务器侧 API 错误处理,而不是立刻判断为 API key、余额、prompt 或账号坏了。
第一分钟只做小动作:打开当前 Claude Status,保存完整错误体和 request_id 或响应头里的 request-id,只用很短的有上限 jitter 重试,并且保持 model、endpoint、认证路线、SDK 或网关路线、请求体都不变。
状态页只能作为有时间戳的信号。本轮在 2026-05-02T13:51Z 检查 Claude Status,公开 status API 显示 all systems operational,但最近几天仍有 API 与模型相关的已解决 elevated-error 事件。绿色状态页可以缩小 live incident 分支,却不能证明你的具体路径已经恢复。
60 秒分支板
先看这张表,再决定要不要换 key、改 prompt、改 billing 或切 provider。只要有 HTTP status、错误体和 request id,说明请求至少到达了 API 层;这和没有 status、没有 body、没有 request id 的连接失败不是同一个问题。
| 看到的信号 | 先归类为 | 第一动作 | 同路径验证 | 下一分支 |
|---|---|---|---|---|
500、api_error、Internal server error | 已返回的 Claude API 服务器侧错误 | 查状态、保存 request_id、做短预算重试 | 同 model、endpoint、认证路线和请求体 | 继续本文的 500 分支 |
529、overloaded_error | 容量过载 | 查状态、加入 jitter、降低并发或排队 | 冷却后保持同路径验证 | Claude API 529 过载 |
429、rate_limit_error | 限流、加速、额度或路线 owner 上限 | 看 limit header 和当前凭证路线 | 等窗口或修正路线后再试 | Claude API 限流 |
504、timeout_error | 超时或长请求 | 改 streaming、缩短输入、拆批或转 batch | 改一个请求形状后再验证 | 留在超时分支 |
没有 status、没有 body、没有 request-id | 连接层失败 | 查网络、VPN、proxy、firewall、DNS、TLS、SDK timeout | 只改一个网络变量再试 | Claude API 连接错误 |
Claude Code 终端显示 API Error: 500 | Claude Code 表面之上的 API 错误 | 查 /status、登录态、session、auth owner 和 route | 同一终端路径修一个分支再试 | Claude Code API Error 500 |
| 网关或 provider 路线返回 500 | 路线 owner 或兼容性分支 | 用直连 Anthropic 和网关做同形状对比 | 同 prompt、model 意图、timeout 和输入大小 | 做路线隔离,不要盲切 |
本文只解决干净的 Claude API Internal Server Error:HTTP 500、api_error、Internal server error。它可能是短暂抖动,也可能在某个 model、route、account path 或 request shape 上重复出现。你的目标不是马上“修一切”,而是保存足够证据,分出临时错误、持续服务器错误和错误分支。
500 api_error 在 Claude API 里是什么意思

Anthropic 的 API error reference 把 HTTP 500 定义为 api_error,同时把 429 rate_limit_error、504 timeout_error 和 529 overloaded_error 分开。官方错误体包含 error.type、error.message 和 request_id,每个 API 响应也会带 request-id header。
这个分类就是恢复边界。已返回的 500 api_error 表示 API 内部出现非预期失败,不是常规账号状态提示。不要因为看到 500 就先旋转 key、充值、改 prompt、清浏览器缓存或换网络。这些分支都有自己的信号。既然 API 已经返回 api_error,就从服务器侧错误处理和证据保存开始。
request_id 比截图更关键。截图能帮助团队理解现场,但 request identifier 才能让 Anthropic support 或内部平台团队追踪某一次具体调用。SDK 能拿 header 时,保存 request-id;错误 JSON 里有 request_id 时,保存它;两者都没有时,说明你可能根本不在“已返回错误”分支,应先去查连接层。
也要把 500 和 529 分开。两者都会让一个昨天正常的集成突然失败,也都可能是 Anthropic 侧的压力,但客户端动作不一样。529 要避免 retry storm,降低并发、排队、冷却后验证。500 要先查 status、短预算重试、保存 request id,并在同路径持续失败时升级。
500 和 504 也不同。504 指向请求时长、idle drop、streaming 或长任务形状。Anthropic 文档对长请求建议 streaming 或 Message Batches。若精确信号是 timeout_error,就不要继续把它写成 Internal Server Error;先有意改变请求形状,再验证。
安全恢复循环

好的 500 恢复循环应该很朴素:
- 检查当前 Claude Status,并记录时间戳。
- 保存完整错误体、
request_id或request-id。 - 只有在任务可以安全重复时,做有上限的 jitter 重试。
- 保持 model、endpoint、auth route、SDK 或 gateway path、request shape 稳定。
- 短预算后同路径仍然 500,就停止随机改变量。
- 用紧凑证据包升级,而不是继续猜。
第一步是状态检查,不是大改代码。如果 status 页面有 API incident,不要继续换本地变量;等 incident 清理后,用同一条失败路径再试。同路径重试能告诉你 incident 是否就是完整解释。如果你在 incident 期间同时换了 model、prompt、key、gateway 和 timeout,后面就不知道是哪一步影响了结果。
状态是绿色时,才进入小预算重试。“小”不是固定次数。用户正在等的聊天请求可能只适合一两次几秒内重试;后台批处理可以等更久;带副作用的 workflow 需要先做 caller-side 去重,确认重复调用不会产生重复动作。重点是 retry policy 必须有 cap、jitter 和 stop condition。
然后做同路径验证。同一个 model、同一个 endpoint、同一个认证 owner、同一个 request body、同一个 SDK 或网关路线,最好连 network path 也先不变。如果同路径短暂停顿后成功,大概率是短暂 API 错误。如果同路径连续返回 500 api_error,升级证据更强。如果只有在你改了五个变量后成功,你其实不知道修复点在哪里。
不要太早进入 provider shopping。网关可以作为生产降级路线,也可以做隔离对比,但切路线会改变证据。先保存原始失败,再把直连与网关作为明确的比较,而不是把“换了以后好了”当成根因。
生产环境里的 500 控制
手动排障只能救一次,生产控制要让系统在波动时也遵守分支纪律。
用 retry budget,不要无限重试。限制尝试次数、总耗时和并发回放,加入 jitter,日志里记录第几次重试、等待窗口和最终结果。事故后你应该能回答:第一次失败是否被 retry 恢复,还是同一路线一直失败。
把幂等和非幂等任务分开。只读分类、内部批处理项、用户可见的付费或创建动作,不能共用同一个 retry policy。500 不一定告诉你下游是否已经执行过部分动作。带副作用的调用要先有 request key、job id 或业务去重,再决定是否重试。
对同一路线的重复 500 api_error 加 circuit breaker。当错误率超过阈值,暂停非紧急调用,后台任务入队,前台给降级状态。恢复时先用小 probe 检查同路径是否恢复,再逐步打开流量。这样可以避免一个短时 API 事件被你的客户端放大成 retry storm。
日志要带分支信息。至少保存 HTTP status、error.type、error.message、request_id 或 request-id、model、endpoint、SDK 版本、auth route、gateway route、请求大小级别、retry count 和时间戳。不要记录 secret、完整用户 prompt、私有数据或未脱敏环境变量。日志的目标是分支定位,不是暴露上下文。
模型切换要作为产品降级决策,而不是第一诊断动作。如果一个 model path 失败、另一个 model 能满足当前用户任务,可以临时降级。但要把它标成 degraded mode,并保留原始 500 证据,以便稍后验证原路径是否恢复。
表面和路线拆分
“Claude API Internal Server Error” 经常出现在混合环境里。直接 API、Claude Code、SDK exception、gateway、timeout、没有响应的连接失败,都可能在读者压力很大时被描述成“Claude API 500”。
如果可见表面是 Claude Code,路线不同。Claude Code 会调用 Claude API,但终端还叠加登录态、恢复 session、OAuth 与 API key owner、shell 环境变量、代理和命令级诊断。终端里看到 500 时,先看 Claude Code API Error 500;如果同时夹杂 500、529、429,用 Claude Code 500/529/rate-limit 路由。
如果可见表面是 SDK exception,先判断是返回了 API status,还是连接异常。带 status 500、headers、错误体的对象属于本文。没有 HTTP status 的 APIConnectionError 一类失败属于 no-response 分支,所以 Claude API 连接错误 会把 request ID 边界放在最前面。
如果可见表面是网关或 provider route,不要猜,做对比。用同一个 prompt、model intent、input size、timeout class 和环境走直连 Anthropic,再走网关。直连成功而网关失败,可能是 route mapping、provider capacity、credential owner、proxy 行为或兼容性;两边都同样返回 500,信号更广,但仍然要保存原路径 request identifier。
如果精确错误变了,就换分支。529 overloaded_error 属于过载恢复;429 rate_limit_error 属于限流与凭证路线诊断;504 timeout_error 属于请求时长和形状;没有响应属于网络、代理、TLS、SDK timeout 或 route owner。把出口写清楚,才能避免一句“稍后重试”误伤所有情况。
升级证据包

升级应该发生在小循环之后:状态查过,错误证据存了,重试有上限,同路径仍然返回 500 api_error。这时继续随机改变量通常会降低证据质量。
建议证据包包括:
- exact HTTP status 和 error type,例如
500 api_error - 完整错误体里的
request_id,或 response headerrequest-id - 每次失败的 timestamp 和 timezone
- model、endpoint、SDK、SDK version、runtime
- 直连 Anthropic、gateway、proxy 或 provider route owner
- auth owner,但不要暴露 secret
- request size class、是否 streaming
- retry count、backoff window、jitter 行为和最终结果
- 当时 Claude Status 结果和相关 incident link
- 最小可复现形状,必须脱敏
- 一句话业务影响
不要把证据包变成数据泄漏。不要贴 API key、客户数据、完整私有 prompt、proxy 全量日志或未脱敏 env dump。证据包要证明分支并提供 trace handle,而不是把现场全部倒出去。
同路径纪律在升级时最有价值。“500 后我换 provider 就好了”证据很弱。“2026-05-02T13:51Z status green,同 model 和 endpoint 在 40 秒 jitter budget 内返回三次 500 api_error,request ids 如下”才是可行动的信息。
FAQ
Claude API Internal Server Error 和 529 overload 是一回事吗?
不是。Anthropic 把 HTTP 500 定义为 api_error,把 529 定义为 overloaded_error。500 走已返回服务器侧错误处理;529 走过载恢复、降压和防 retry storm。
Claude Status 是绿色,是否说明问题一定在本地?
不是。绿色状态页只是公开组件在某个时间点的信号,可以缩小 active incident 分支,但不能证明你的 model、endpoint、账号路线、地区、SDK、网关或请求形状都恢复。仍然要保存同路径证据。
应该先轮换 API key 吗?
不应该。干净的 500 api_error 不是先换 key 的证据。只有在 auth、key owner、泄漏、route mismatch 有明确信号时才处理凭证。
重试几次才安全?
用预算,不用固定神奇次数。限制次数或总耗时,加入 jitter,只重试可安全重复的工作。带副作用的流程先做去重,再决定是否 retry。
如果错误发生在 Claude Code 里怎么办?
走 Claude Code 分支。Claude Code 会加入登录态、session、OAuth/API key 路线、shell proxy 变量和命令诊断。先看 /status,再进入 Claude Code API Error 500,不要把终端直接当普通 SDK。
发给支持时最重要的信息是什么?
HTTP status、error.type、error.message、request_id 或 request-id、timestamp、model、endpoint、SDK version、route owner、retry timeline、status 结果和脱敏复现形状。越短越容易看出 500 分支。
工作规则
Claude API Internal Server Error 是一个 500 api_error 恢复分支,不是恐慌式改 key、billing、prompt 或 provider 的理由。先查实时状态,保存 request identifier,做有上限的 jitter 重试,同路径验证;如果同路径仍然失败,再带证据升级。


