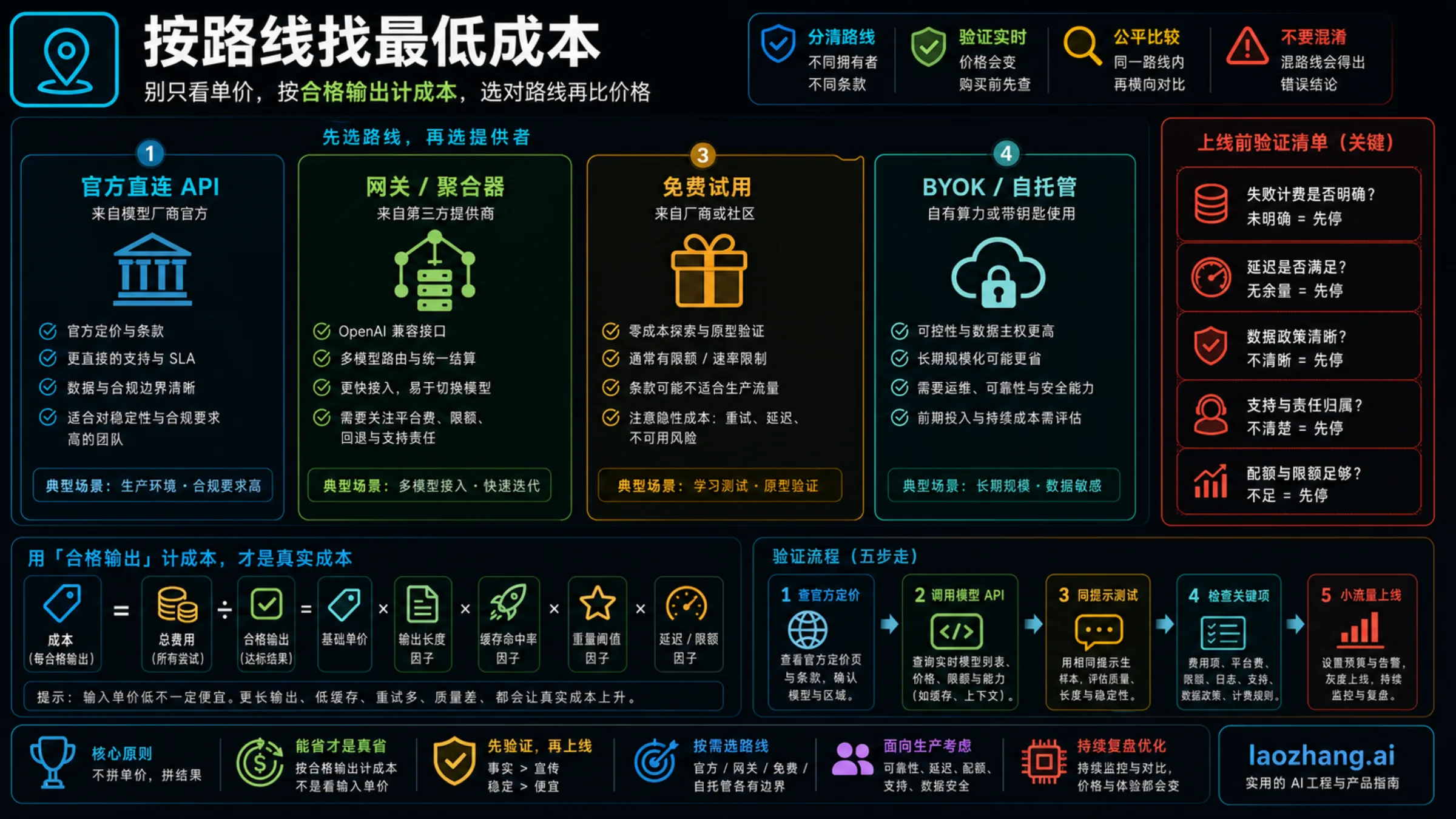
最便宜的 LLM API provider 不是一个固定公司,而是一个经过验证的路线选择。以 2026-07-01 的核验结果看,DeepSeek V4 Flash 是这里能确认的最低官方付费 token 起点;但生产里的最终选择还要看输出长度、缓存命中、质量门槛、重试率、延迟、额度、网关费用、数据边界和谁负责支持。
先选路线,再看价格。官方直连 API 给你模型厂商自己的价格和生命周期责任;网关或聚合平台给你 OpenAI-compatible 迁移、多模型切换、日志和一个支持入口;免费路线适合做 prompt 实验;BYOK 或自托管只有在运维能力和利用率足够高时才可能便宜。不要把这四类放进一张“最低价榜”里。
| 路线 | 第一项测试 | 为什么可能便宜 | 立即停止的条件 |
|---|---|---|---|
| 官方直连 API | 用 DeepSeek V4 Flash 测最低官方付费 token floor;用 Gemini 2.5 Flash-Lite Batch/Flex 测低价批处理 | 价格行、账单单位和生命周期由模型厂商负责 | 质量、地区、额度或版本生命周期不适合你的任务。 |
| 网关或聚合平台 | OpenRouter、SiliconFlow、laozhang.ai 都要先做实时模型/API 核验 | 一个兼容接口、多模型路由、日志和支持入口能减少迁移成本 | 费用、失败调用计费、额度、支持责任或数据政策不清楚。 |
| 免费实验路线 | 免费模型、试用额度、sandbox | 适合原型和同 prompt 对比 | 生产前必须核验限速、条款、可用性和支持路径。 |
| BYOK 或自托管 | 自己的 key、自己的 GPU 或自管推理 | 数据路径和长期单位经济可控 | 运维、延迟、监控和利用率吃掉节省。 |
快速公式是:有效产出成本 = 总账单 / 通过验收的输出数。只有当同一批 prompt 跑完、账单单位被核验、失败和重试被记录、上线切片有花费上限时,才能说某条路线在你的场景里便宜。
当前低成本官方价格路线
官方价格是最稳的锚点,因为价格行由模型厂商自己发布,账单单位、生命周期说明和支持边界更清楚。它仍然不是最终答案。一个输入 token 很低的模型,如果需要更长输出、更多重试或更高成本 fallback,实际成本会输给表面更贵的路线。
这些数字在 2026-07-01 核验:DeepSeek V4 Flash: $0.14 cache-miss input and $0.28 output per 1M tokens, cache-hit input much lower; Gemini 2.5 Flash-Lite: $0.10 input and $0.40 output, Batch/Flex $0.05/$0.20; OpenAI gpt-5.4-nano: $0.20 input and $1.25 output; Mistral Small 4: $0.15/$0.60; Claude Haiku 4.5: $1/$5. 这些价格只能说明起点,不能替代你的工作负载测试。
| 官方路线 | 当前低成本行 | 为什么重要 | 边界 |
|---|---|---|---|
| DeepSeek direct | DeepSeek V4 Flash:cache-miss input $0.14、output $0.28 / 1M tokens;cache-hit input 远低 | 本次比较中最低的官方付费 token floor | 不等于所有代码、推理、地区和稳定性目标都赢;DeepSeek 还提示 deepseek-chat 和 deepseek-reasoner 兼容名会在 2026-07-24 15:59 UTC 退役。 |
| Google Gemini API | Gemini 2.5 Flash-Lite:input $0.10、output $0.40;Batch/Flex:$0.05/$0.20 | 适合能接受批处理或 flex 行为的大量任务 | 不要继续引用旧 Gemini 2.0 Flash-Lite 价格作为当前建议。 |
| OpenAI API | gpt-5.4-nano:input $0.20、output $1.25;Batch/Flex 更低 | OpenAI-native 工具链、账号政策和兼容性可能降低迁移风险 | 不是最低官方 floor,但可能减少工程和可靠性成本。 |
| Mistral API | Mistral Small 4:input $0.15、output $0.60 | 对欧洲治理、开放模型路线和低价文本任务有吸引力 | 要同时比较治理、延迟和质量,不只看 token。 |
| Anthropic API | Claude Haiku 4.5:input $1、output $5;Sonnet 5 introductory pricing 到 2026-08-31 | 原始价格不低,但在减少返工、审阅和失败率时可能赢 | Sonnet 5 的日期边界必须在窗口结束前复查。 |
正确的读法不是“永远选 DeepSeek”,而是“用 DeepSeek V4 Flash 做便宜付费路线的第一项测试,然后证明你的任务能接受输出”。如果便宜模型让拒收率翻倍,价格表就漏掉了最关键的成本。
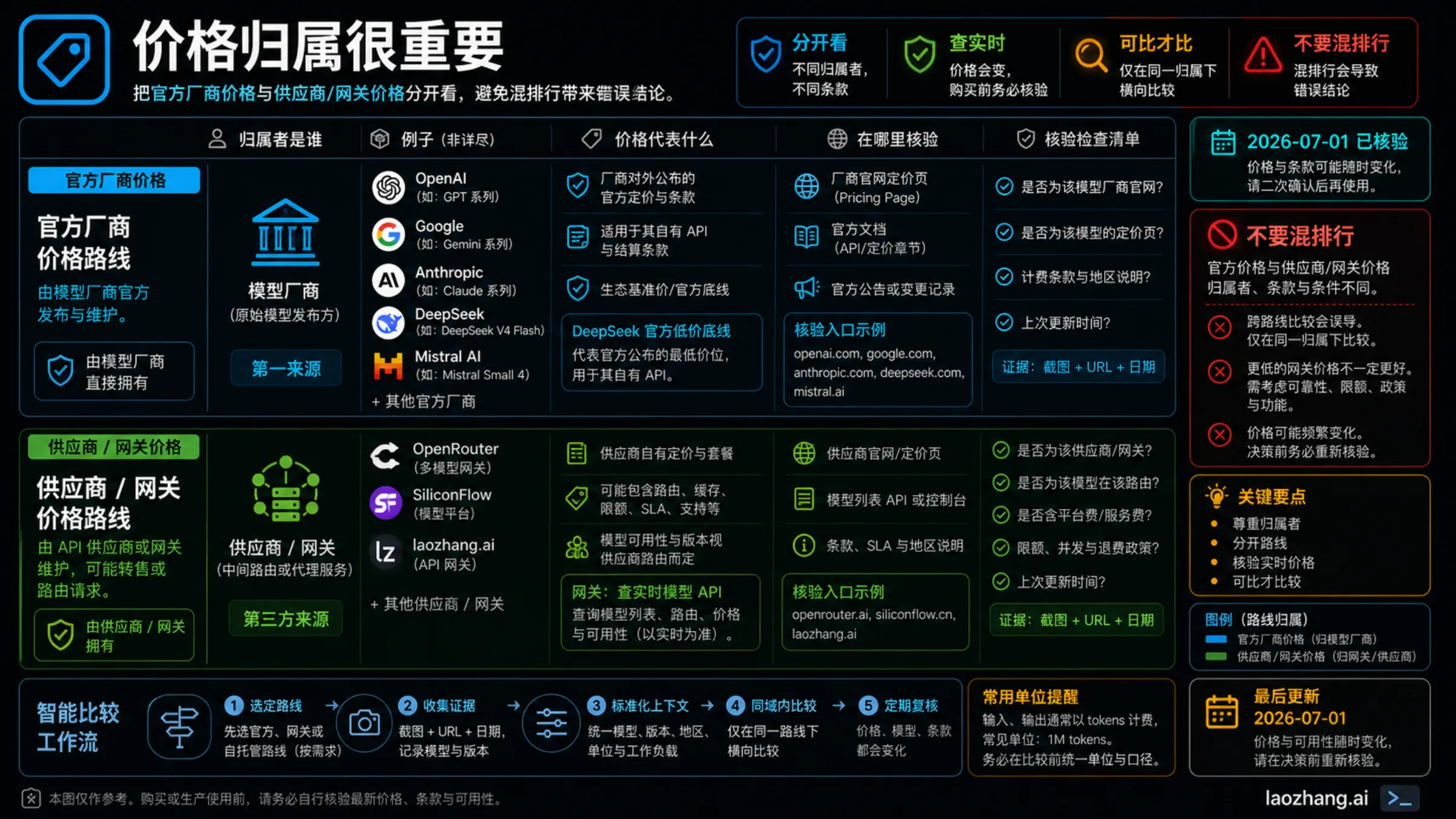
网关和 Provider 路线
网关和聚合平台是 provider 路线,不是官方模型价格。它们可能因为减少迁移工作、提供统一 API、集中日志、快速切换 fallback 和一个支持入口而更便宜;也可能因为平台费、路由不透明、地区差异、失败调用计费或第二层支持边界而变贵。
| Provider 路线 | 必须核验 | 何时有用 | 不要这样写 |
|---|---|---|---|
| OpenRouter | 模型行、provider route、tokenizer 差异、免费模型限制、Pay-as-you-go 5.5% 平台费 | 模型目录广、低门槛测试、Models API 可按 pricing-low-to-high 排序 | 不要把 OpenRouter metadata 写成 OpenAI、Google、Anthropic、DeepSeek 或 Mistral 的官方价格。 |
| SiliconFlow | provider 自有价格、模型版本、地区、条款、当前可用性 | DeepSeek-family provider route 清晰,适合支付、地区或运营路径有需求的团队 | 不要把 SiliconFlow 的 DeepSeek provider 行等同于 DeepSeek direct。 |
| laozhang.ai | 当前模型列表、功能 flags、精确价格行、账单方式、日志、支持路径、console/API 数据 | 当任务是 OpenAI-compatible API 网关、模型切换、用量可见性和支持入口整合时有价值 | 不要在没有实时 Models API 或控制台核验时发布精确 per-model 价格。 |
对 laozhang.ai 的推荐必须是条件式:如果你的读者需要网关接入、OpenAI-compatible 迁移、多模型覆盖检查、用量日志或支持责任整合,它可以进入候选;如果读者只想要厂商官方价格、生命周期条款或直接支持,官方 API 更合适。公开文档描述了 pay-as-you-go API 集成和 OpenAI-compatible Models API;那是核验入口,不是把旧价格表固化到文章里的许可。
计算有效产出成本
真正便宜的 LLM API provider,是在你的质量门槛下,每个通过验收输出成本最低的路线。原始 input token 价格只是变量之一。

有效产出成本 = sample run 的总账单 / 通过验收的输出数。
| 变量 | 为什么会改写赢家 | 你要记录什么 |
|---|---|---|
| 输入 token | system prompt、工具 schema、检索片段和历史消息会让短输出任务的输入成本占大头 | 每个通过任务的平均可计费输入 |
| 输出 token | 有些模型需要更长解释才能通过审阅 | 通过输出的平均长度,而不是最大输出 |
| 缓存命中率 | prompt-heavy 工作流在 cached input 下可能完全换赢家 | 可缓存前缀比例和命中率 |
| 重试率 | timeout、JSON/schema 失败、弱推理或安全拒答都会增加付费尝试 | 每个通过答案的 attempts |
| 质量门槛 | 高质量要求会更频繁拒收便宜输出 | 标注样本的 acceptance rate |
| 延迟与额度 | 低价路线可能因为限速被迫 fallback 到更贵路线 | P95 latency、TPM/RPM headroom、fallback share |
| 网关费用 | 平台费、markup、最低充值或失败调用计费会改变总账单 | provider invoice / accepted outputs |
一个简单例子:Provider A 生成 1000 个候选只花 $0.20,但只有 600 个通过,成本是 $0.000333 / accepted output。Provider B 花 $0.25,但 900 个通过,成本是 $0.000278。B 在价格表里贵,在产品里更便宜。
免费、试用、BYOK 和自托管
“免费”通常不是生产价格,而是实验入口。它可以让你快速比较 prompt、接口形态和大致质量,但它不能替代上线账单、限速、条款和支持路径。
| 路线 | 适合做什么 | 隐性成本 | 生产边界 |
|---|---|---|---|
| 网关里的免费模型 | 原型、课堂演示、同 prompt 样本 | 严格限制、低优先级、模型变更或 fallback | 不核验限速、条款和 uptime,就不要依赖。 |
| 厂商试用额度 | 比较新的官方 API | 到期、地区限制、账号限制 | 上线前必须切回付费价格行计算。 |
| BYOK through gateway | 保留厂商账号,同时用一个路由层 | 网关费、key 管理、数据路径、支持拆分 | 要知道故障由厂商还是网关负责。 |
| 自托管开源模型 | 数据控制、固定基础设施、高利用率任务 | GPU 利用率、监控、量化质量、维护 | 只有利用率高且质量足够时才便宜。 |
如果你的任务只是“有没有免费 Gemini API”,那是更窄的问题;如果你的任务是选择 provider,免费路线只应该进入样本测试,不应该直接变成生产推荐。
切换前的验证流程
不要用静态价格表迁移生产流量。价格表只负责筛候选,迁移前必须核验实时路线。
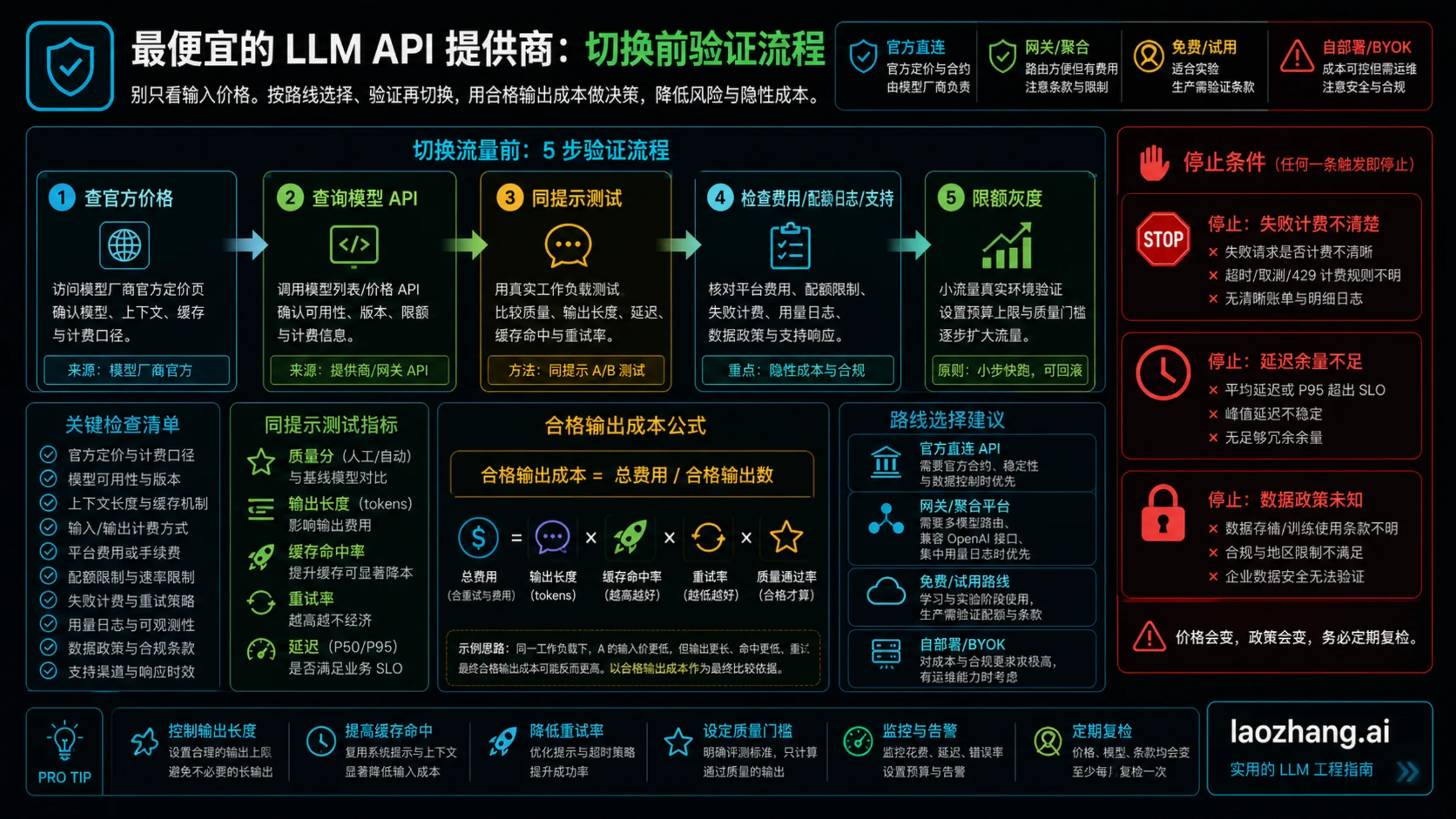
- 先检查模型厂商官方价格页,确认 direct API 的价格行、计费单位和日期。
- 如果走网关,先查当前 model/API metadata 或控制台,再引用 provider 价格。
- 用同一批 prompt 跑每条候选路线,不要用不同任务混算。
- 记录输入 token、输出 token、缓存、失败、重试、延迟和通过输出数。
- 用总账单除以通过输出数,而不是只比较 input price。
- 检查失败调用计费、quota、日志、支持责任、数据保留和地区条款。
- 只放一小段流量,并设置 spend cap、质量 fallback 和回滚路径。
如果失败调用是否计费不清楚、延迟没有并发余量、模型兼容名接近生命周期变化、日志不足以控预算、数据条款冲突或 provider 说不清谁负责上游故障,就不要迁移。
按工作负载推荐第一项测试
这些不是采购结论,只是第一轮测试路线。
| 工作负载 | 先测什么 | 备选 | 原因 |
|---|---|---|---|
| 便宜聊天、抽取、轻 summarization | DeepSeek V4 Flash direct | Gemini 2.5 Flash-Lite 或 OpenAI gpt-5.4-nano | 从官方付费 floor 开始,再看通过率和输出长度。 |
| 大量异步 summarization | Gemini 2.5 Flash-Lite Batch/Flex | OpenAI Batch/Flex 低价行 | 延迟不敏感时,批处理可能比交互路线便宜。 |
| OpenAI-compatible 多模型迁移 | OpenRouter 或 laozhang.ai,前提是实时 API 核验 | 最终赢家的官方 direct API | 网关便利能省工程时间,但要先算费用和责任边界。 |
| DeepSeek-family provider route | 先 DeepSeek direct,再测 SiliconFlow | 其他已核验 metadata 的网关 | provider 自有价格需要 provider 标签和实时核验。 |
| coding 或 agent 任务 | DeepSeek、OpenAI、Claude 和一个 gateway fallback 同 prompt 测 | 有最低 accepted-output cost 的模型 | 重试率和工具可靠性可能压过 token 价。 |
| 治理敏感任务 | Mistral 或满足地区/数据条款的 direct route | 自托管或 BYOK | 合规和数据责任可能值得付费。 |
同一个产品里也常常有多条路线:分类器用低价官方行,代码助手用更强模型,网关只负责 fallback。不要强行让一个 provider 承包所有工作。
Provider 检查清单
在说“最便宜”之前,至少回答这些问题。价格行是谁拥有的:模型厂商、网关、云平台、转售商,还是你的基础设施团队?它是 input、output、cached input、batch/flex、per request 还是工具调用单位?它覆盖哪个模型版本、地区和生命周期状态?失败调用、timeout、安全拒答和重试怎样计费?RPM、TPM、daily quota、spend limit 怎样工作?日志、导出和告警够不够支持预算控制?上游模型失败时谁负责支持?数据保留、训练使用和地区条款是否符合任务?同 prompt 样本在你的质量门槛下是否通过?上线切片是否有 cap 和 rollback?
这个清单比价格表更严格,因为它要防止“低价测试”变成“高成本事故”。真正的便宜选择应该同时经得起账单、质量、可用性、责任和回滚检查。
常见问题
现在谁是最便宜的 LLM API provider?
以 2026-07-01 核验到的官方付费 token floor 看,DeepSeek V4 Flash 是这里最低的官方价格行。但这不代表它对所有任务都最便宜。你还要比较输出长度、缓存、重试、延迟、quota、网关费用和支持责任后的有效产出成本。
OpenRouter 一定比 direct API 便宜吗?
不一定。OpenRouter 能减少集成工作,并用一个网关暴露多模型路线,但 Pay-as-you-go 有平台费,模型价格也取决于具体 route。把它当作 gateway-owned metadata,生产前重新核验。
应该把 laozhang.ai 写成最便宜 provider 吗?
不应该直接这样写。laozhang.ai 适合开发者网关任务,例如 OpenAI-compatible API、模型切换、用量可见性和支持入口整合。只有当前 Models API 或控制台证明某个模型价格适合你的工作负载时,才能谈精确价格。
免费 LLM API 能上生产吗?
默认不要。免费路线适合 prompt 比较、原型和教学。生产需要可预测账单、日志、fallback 行为、支持责任、条款和限速。
为什么低 input price 会输?
因为账单不是 input token 一项。长输出、低缓存命中、schema 失败、重试、严格质量审阅、延迟 fallback 和网关费都会让低输入价变成高 accepted-output cost。
价格多久复查一次?
每次生产迁移前、每次大幅涨量前、每次看到模型生命周期、provider fee 或免费条款变化时都要复查。带截止日期的价格行要在窗口结束前安排复查。
结论
用官方 token floor 选第一批候选,不要用它直接下采购结论。DeepSeek V4 Flash 值得成为很多文本任务的便宜付费第一测;Gemini 2.5 Flash-Lite Batch/Flex 值得用于异步规模任务;OpenAI、Anthropic 和 Mistral 可能因为兼容性、质量、治理或可靠性减少返工而赢;OpenRouter、SiliconFlow、laozhang.ai 这类网关可能因为路由、日志、兼容性或支持整合省下工程成本。最后的动作很简单:核验当前价格,跑同一批 prompt,用总账单除以通过输出数,再带 cap 小流量上线。