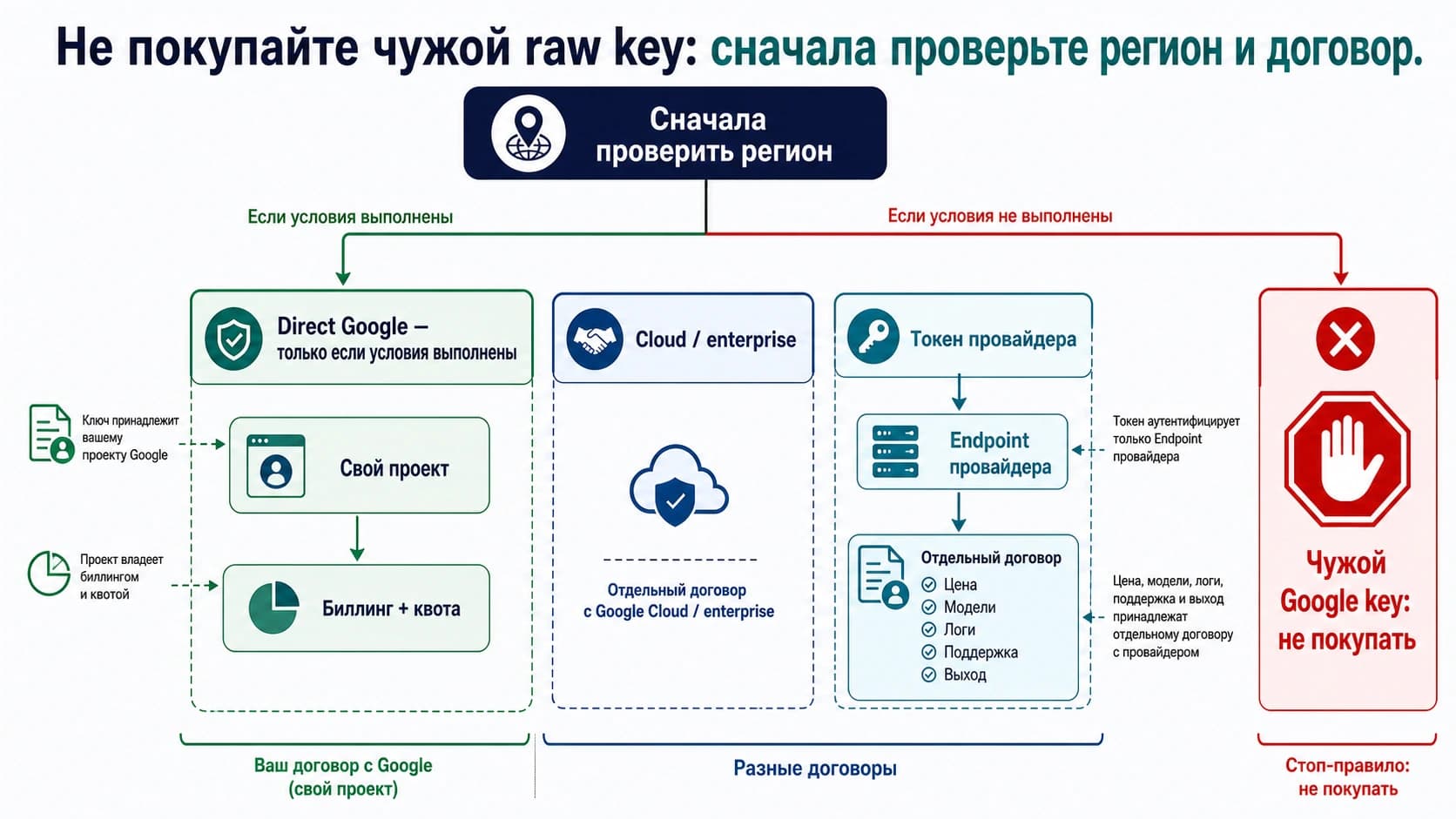
Не начинайте с вопроса, что дешевле: Realtime API или конвейер расшифровки речи. Сначала спросите, должен ли продукт понимать пользователя во время разговора, принимать перебивания, вызывать tools и отвечать голосом без заметной паузы. Если именно живой голосовой диалог является ценностью, gpt-realtime-2 может оправдать более высокий meter. Если продукту нужны расшифровка, summary, archive, QA review, compliance trail или analytics feed, сначала считайте маршрут от текста.
Маршрут должен идти раньше ценовой таблицы:
- Голосовой агент в реальном времени: используйте
gpt-realtime-2, когда качество голосового ответа, interruption, turn-taking и низкая задержка меняют результат сессии. - Только live transcript: используйте
gpt-realtime-whisper, когда нужен поток текста во время речи, но не нужен говорящий assistant. - Ограниченная аудио-транскрибация: используйте
gpt-4o-transcribeилиgpt-4o-mini-transcribe, когда файл, запись или звонок можно обработать после capture. - Собственный конвейер: добавляйте STT, text model, optional TTS, telephony, storage, monitoring и QA только тогда, когда эти части реально нужны workflow.
- Гибрид: оставьте Realtime для ценных live moments, а archive, review, summaries и analytics отправляйте в обработку от текста.
По состоянию на 14 июня 2026 года OpenAI указывает gpt-realtime-whisper как $0.017/minute, gpt-4o-transcribe как estimated $0.006/minute, а gpt-4o-mini-transcribe как estimated $0.003/minute. Прямой пересчет дает $1.02/hour, $0.36/hour и $0.18/hour для расшифровки с оплатой по длительности. У gpt-realtime-2 другая форма: audio input и audio output тарифицируются в tokens, и один counted hour пользовательской речи плюс один generated hour речи ассистента создает media-token floor $5.76/hour до text tokens, tools, повторяющейся истории, optional input transcription, telephony и компонентов конвейера.
Стоп-правило: не платите за spoken assistant output, если text достаточно. Дальше статья дает worksheet для решения, когда low-latency speech стоит дополнительных затрат, как растут Realtime costs и какие затраты конвейера должны оставаться переменными до проверки на вашем stack.
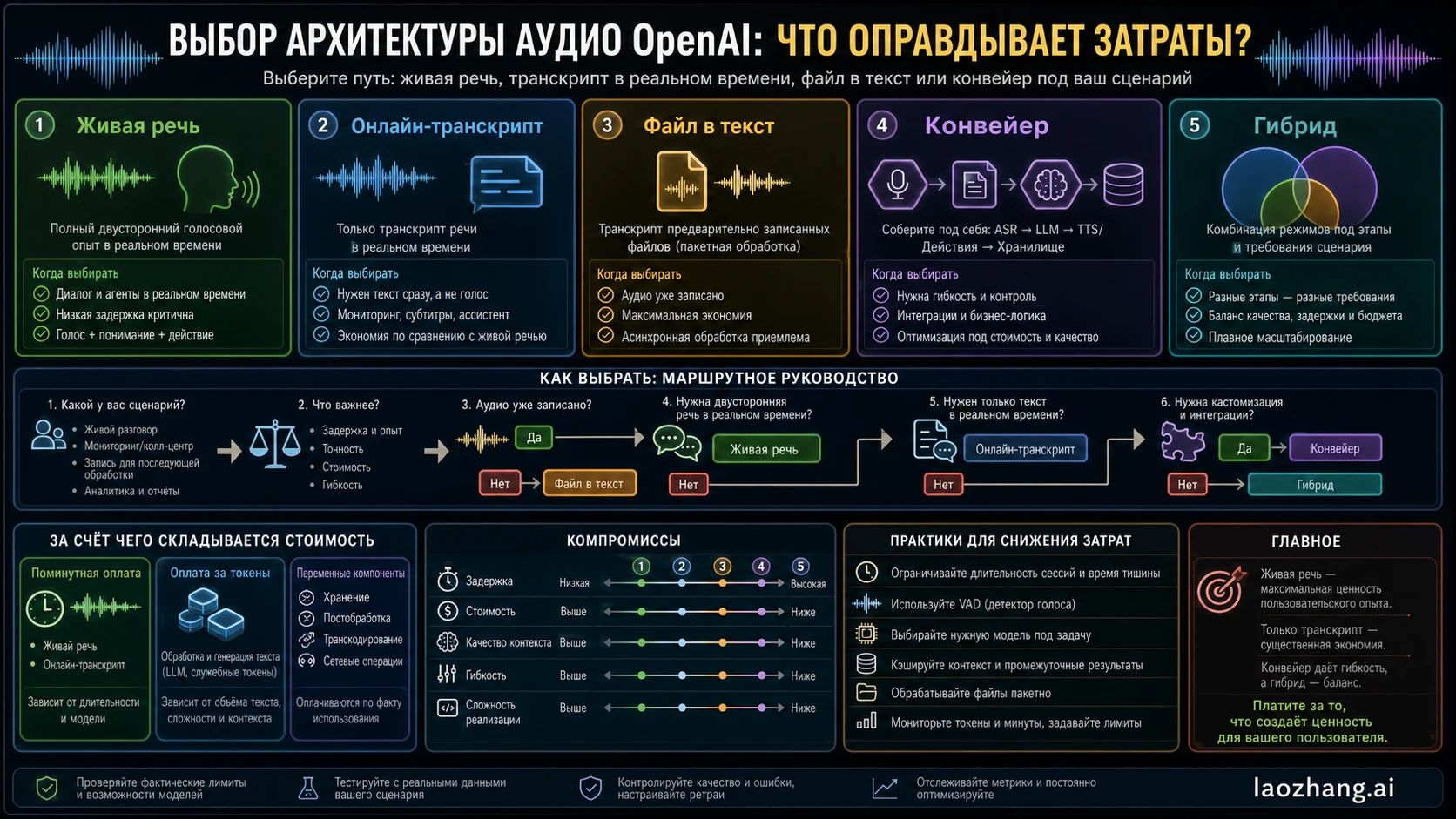
Сначала выберите маршрут по задаче продукта
Сравнение Realtime API и transcription pipeline ломается, когда команда сравнивает одну минутную цену с целым продуктовым loop. Правильный порядок такой: задача продукта, маршрут OpenAI, единица тарификации, затем переменные компоненты вокруг нее.
| Задача продукта | Первый маршрут для расчета | Cost unit | Когда использовать | Стоп-правило |
|---|---|---|---|---|
| Живой голосовой assistant | gpt-realtime-2 | audio и text tokens per Response | Пользователям нужны interruption, turn-taking, tool use и voice output во время сессии | Если text output достаточен, не начинайте здесь |
| Только live transcript | gpt-realtime-whisper | minutes of live audio | Нужен текст во время речи | Если audio может подождать, считайте bounded transcription |
| Audio to text для файлов и записей | gpt-4o-transcribe или gpt-4o-mini-transcribe | minutes of submitted audio | Uploads, recordings, post-call review, summaries, QA, compliance | Если нужны live deltas, переходите к realtime transcription |
| Custom pipeline | STT -> text model -> optional TTS -> operations layer | separate component meters | Нужны control, vendor mix, telephony fit, auditability или optimization | Не добавляйте TTS, telephony или review без workflow reason |
| Hybrid | Realtime для live moment, transcription-first для back office | combined meters | Live help создает value, но archive и analytics не требуют speech output | Измеряйте границу live session и back-office processing |
Эта таблица защищает от частой ошибки бюджета. Голосовой агент и transcript оба работают с аудио, но покупают разный результат. Голосовой агент покупает interactive spoken loop. Transcription pipeline покупает текст и downstream processing.
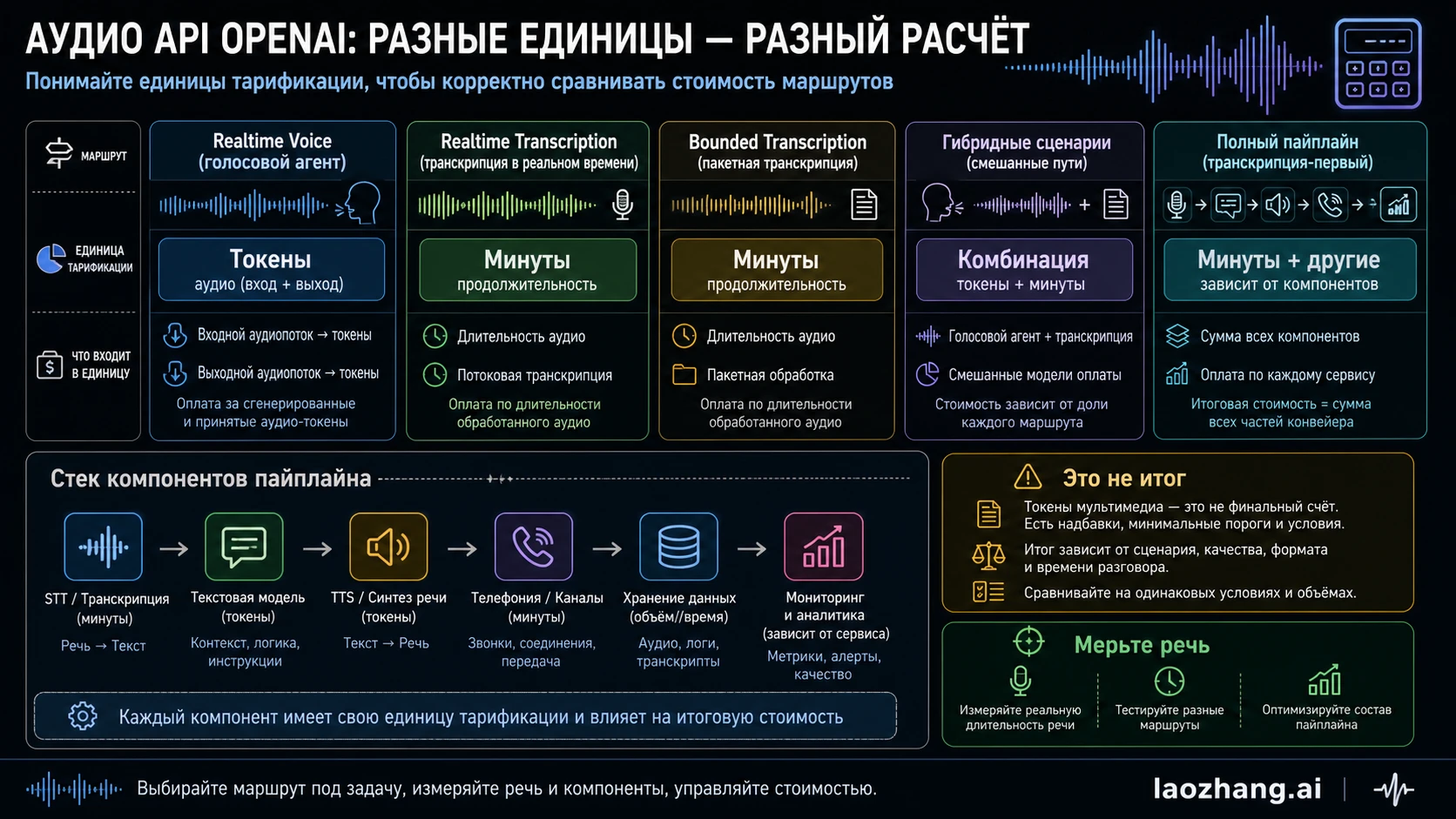
Текущие цены OpenAI, которые нужны для расчета
Используйте текущие rows OpenAI как anchors, затем добавляйте measured workload. Проверено 14 июня 2026 года: OpenAI pricing page дает следующие rows для маршрутов в этом решении.
| Маршрут | Current OpenAI price row | Hourly intuition | Что не включено |
|---|---|---|---|
gpt-realtime-whisper | $0.017/minute | $1.02/hour direct conversion | text model work, storage, monitoring, telephony, non-OpenAI components |
gpt-4o-transcribe | estimated $0.006/minute | $0.36/hour direct conversion | post-processing, summaries, classification, storage, orchestration |
gpt-4o-mini-transcribe | estimated $0.003/minute | $0.18/hour direct conversion | accuracy review, domain vocabulary, retries, operations work |
gpt-realtime-2 audio input | $32.00/1M audio input tokens | $1.152/hour for one counted user-audio hour at 1 token per 100 ms | assistant audio, text, tools, history growth, optional transcription, pipeline components |
gpt-realtime-2 audio output | $64.00/1M audio output tokens | $4.608/hour for one generated assistant-audio hour at 1 token per 50 ms | user audio, text, tools, history growth, optional transcription, pipeline components |
Duration-billed transcription считается прямо:
textgpt-realtime-whisper: 60 minutes * $0.017 = $1.02/hour gpt-4o-transcribe: 60 minutes * $0.006 = $0.36/hour gpt-4o-mini-transcribe: 60 minutes * $0.003 = $0.18/hour
Media-token floor для gpt-realtime-2 тоже прост, но это только floor:
textUser audio input: 36,000 tokens/hour * $32 / 1,000,000 = $1.152/hour Assistant audio output: 72,000 tokens/hour * $64 / 1,000,000 = $4.608/hour Media-token floor: $1.152 + $4.608 = $5.76/hour
Нельзя называть $5.76/hour полной часовой ценой Realtime. Число предполагает один counted hour пользовательского audio и один generated hour assistant audio. Оно исключает text tokens, repeated conversation context, tool schemas, tool results, optional input transcription, special tokens, telephony, storage, monitoring и все, что происходит вне Realtime session.
Почему стоимость голосового Realtime растет
Realtime cost guide объясняет, почему voice-agent session не похожа на простой audio file. Стоимость возникает при создании Response и считается по input/output tokens. Input transcription, если включена, тарифицируется отдельной моделью. OpenAI также отмечает, что connections и network bandwidth сейчас не имеют отдельной платы, но открытая сессия не становится бесплатной, когда в ней создаются Responses.
Практические drivers такие:
- User audio: 1 token per 100 ms.
- Assistant audio: 1 token per 50 ms; длинные ответы часто доминируют.
- Response count: каждый Response является новым generation event.
- Conversation history: предыдущий контент снова отправляется в контекст, поэтому поздние turns могут стоить дороже.
- Empty audio control: VAD может фильтровать silence, если client не добавляет его вручную.
- Text and tool work: instructions, schemas, tool results и text output тоже важны.
- Optional input transcription: если нужен transcript внутри Realtime, возникает отдельная transcription cost.
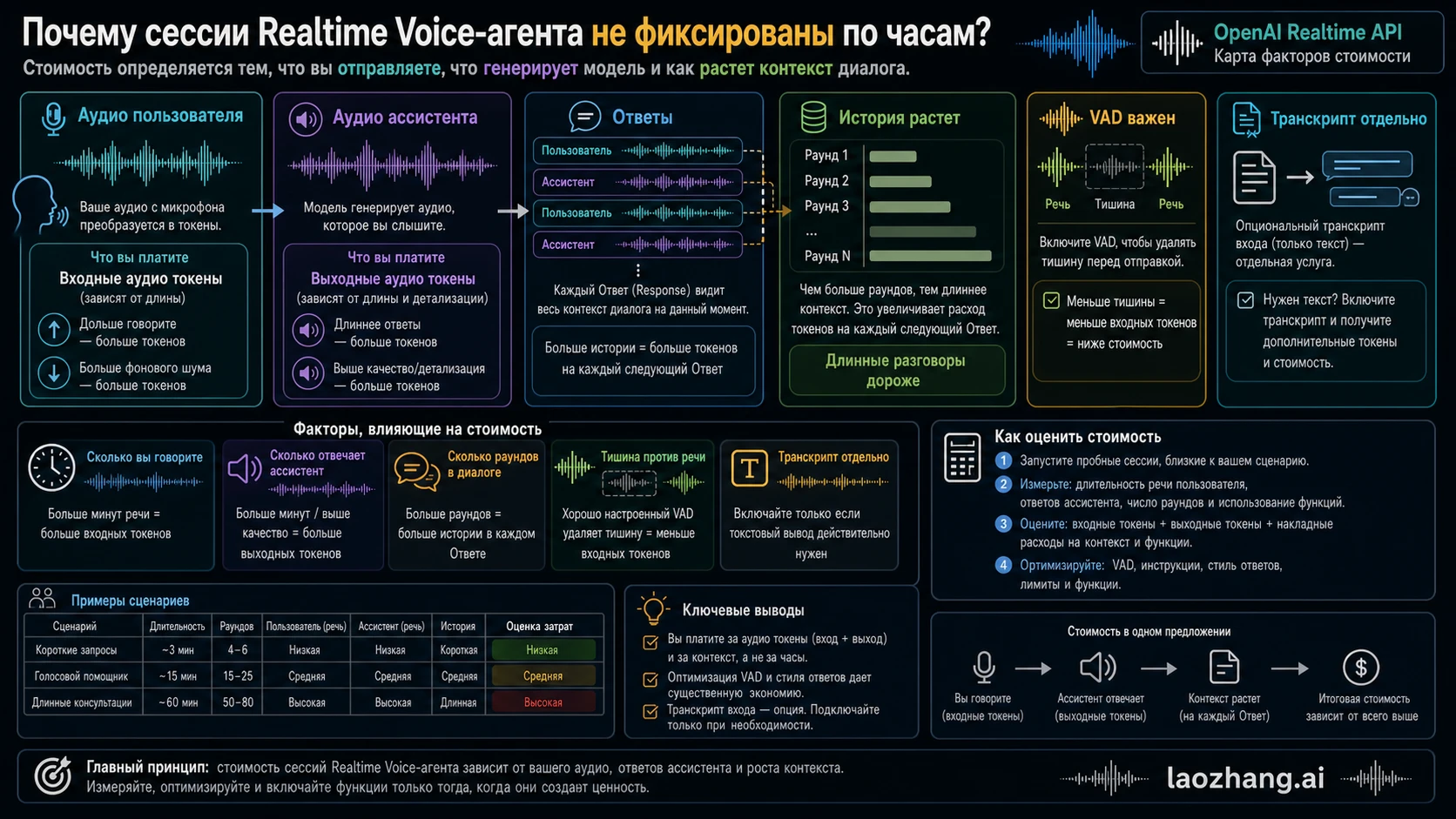
Поэтому фраза “Realtime стоит X долларов в час” слишком слабая для launch planning. Тихий 60-минутный support call с короткими ответами ассистента может стоить иначе, чем 20-минутная tutoring session, где assistant много говорит, вызывает tools и несет длинный context через десятки Responses.
Экономия начинается с дизайна сессии. Держите VAD включенным, чтобы silence не попадал в input. Завершайте или суммаризируйте long sessions, когда old history уже не улучшает next answer. Сокращайте tool schemas и system instructions. Избегайте assistant monologues, когда достаточно короткого ответа. Включайте input transcription только там, где product действительно нуждается в transcript из live session. Перед коммерческим запуском измеряйте Response count, assistant speech duration и average history size в реальных пилотах.
Преимущество Realtime также реально. gpt-realtime-2 покупает native spoken interaction loop: low latency, interruption handling, voice response quality и tool use during conversation. Если эти свойства повышают conversion, containment, accessibility или task completion, дополнительная стоимость является ценой продукта, а не waste.
Модель стоимости transcription-first pipeline
Transcription-first pipeline начинает дешевле, потому что первый paid step может быть plain speech-to-text. Для files и bounded audio Speech to text guide ведет к gpt-4o-transcribe, gpt-4o-mini-transcribe, gpt-4o-transcribe-diarize; file uploads ограничены 25 MB и имеют другой shape, чем live deltas. Для live text без spoken assistant Realtime transcription guide ближе к gpt-realtime-whisper.
Но не заканчивайте worksheet на STT. Если workflow делает summaries, extraction, routing, QA, coaching, moderation, analytics или compliance, считайте весь stack.
| Компонент | Что считать | Price treatment |
|---|---|---|
| Audio capture and transport | app, browser, WebRTC, telephony, recording infrastructure | variable by stack and region |
| STT | gpt-realtime-whisper, gpt-4o-transcribe, gpt-4o-mini-transcribe | OpenAI minute rows anchor the estimate |
| Text model | summary, extraction, routing, QA, coaching, moderation, agent logic | variable by model, tokens, cache, retries |
| Optional TTS | speech output after text processing | variable unless verified for launch route |
| Telephony | PSTN, SIP, recording, phone numbers, compliance features | variable by provider and region |
| Storage and retrieval | audio, transcripts, embeddings, logs, retention policy | variable by privacy and retention |
| Monitoring and QA | human review, audits, metrics, failure replay, alerts | variable and often larger than STT in regulated work |

Этот pipeline может быть дешевле и предсказуемее Realtime voice-agent session, особенно когда продукт не требует speech output. Его проще debug: каждый component оставляет artifact: audio, transcript, text-model output, summary, classification или audit log.
Tradeoff состоит в latency и integration load. Cascaded STT -> text model -> TTS можно stream, но он не становится native spoken session. Выбирайте pipeline, потому что workflow text-centered или нужен component control, а не потому, что один STT row выглядит универсально дешевым.
Когда живая речь стоит оплаты
Платите за gpt-realtime-2, когда spoken interaction меняет user behavior во время сессии. Хорошие кандидаты: sales или onboarding calls, tutoring, coaching, accessibility flows, voice agents that call tools while the user is present, consumer voice UX, support containment where a resolved spoken call avoids human escalation.
Pilot question должен быть не “Realtime дороже STT?”, а “создает ли live speech достаточно value для дополнительного meter?”. Измеряйте:
| Метрика | Зачем нужна |
|---|---|
| real user talk time | drives counted user audio |
| assistant speech time | drives audio output and often dominates media-token floor |
| Responses per session | controls generation events |
| average history size by turn | reveals late-session cost growth |
| tool calls per session | captures hidden text and tool context |
| completion or containment lift | tells whether voice loop pays back |
| human fallback rate | catches cases where transcription would work |
Если эти metrics показывают улучшение business или user outcome, Realtime может быть правильной тратой даже при более низкой raw hourly row у transcription route. Если metrics не показывают value, не расширяйте Realtime на все audio workflows по инерции.
Когда transcription-first выигрывает
Начинайте transcription-first, когда text является основным artifact. Типичные winners: meeting summaries, call QA, compliance review, searchable archives, support analytics, coaching notes, medical or legal intake drafts that need review, asynchronous voice notes, post-call classification.
Практические stop rules: если user не нуждается в voice reply, не платите за assistant audio output; если transcript может появиться после окончания audio, сначала сравните bounded transcription; если нужны live captions без spoken assistant, price gpt-realtime-whisper before gpt-realtime-2; если summaries и classifications выполняются после capture, считайте их как text-model work outside STT row; если workflow требует compliance trail, pipeline artifacts часто легче inspect, чем live spoken loop alone.
Этот маршрут дает больше quality gates. Можно хранить original audio, rerun transcription, compare model outputs, inspect prompt changes, batch non-urgent work и направлять human review только на high-risk samples. Для operations teams такой control часто важнее нескольких seconds latency.
Гибридный бюджет: Realtime только там, где речь создает ценность
Hybrid часто является лучшей production shape. Используйте Realtime для live segment, где speech меняет result, затем используйте transcription-first processing для всего, что не требует spoken output.
Простая последовательность:
- Start
gpt-realtime-2session only for live interaction that needs interruption, turn-taking, and speech. - Capture metadata: user audio duration, assistant audio duration, Response count, tool calls, input transcription flag.
- Store or export transcript only if product and privacy policy need it.
- Run post-call summaries, QA, compliance classification, analytics, and search indexing through text or transcription-first routes.
- Review sample sessions weekly until the live boundary and back-office boundary are stable.
Так Realtime остается связанным с частью продукта, которая действительно требует живой речи. Onboarding agent может говорить с пользователем в Realtime, но CRM notes и QA делать позже. Call-center monitor может использовать live transcription для supervisor visibility, но не заставлять voice agent говорить всю сессию. Voice note app может вообще избежать Realtime, если ему нужны accurate text и clean summary after recording.
Главный вопрос hybrid design: где заканчивается live value. Как только live value закончилась, каждый следующий step должен заново доказать, почему ему нужна realtime speech, а не cheaper text-centered route.
Бюджетная таблица
Считайте три estimates: transcription-only, Realtime media floor, full pipeline. Потом замените placeholders данными пилота.
| Worksheet line | Formula |
|---|---|
| Live transcript-only cost | live_audio_minutes * $0.017 for gpt-realtime-whisper |
| Bounded high-accuracy transcription cost | audio_minutes * $0.006 for gpt-4o-transcribe |
| Bounded low-cost transcription cost | audio_minutes * $0.003 for gpt-4o-mini-transcribe |
| Realtime user-audio floor | user_audio_hours * $1.152 for gpt-realtime-2 audio input |
| Realtime assistant-audio floor | assistant_audio_hours * $4.608 for gpt-realtime-2 audio output |
| Realtime media-token floor | user_audio_floor + assistant_audio_floor |
| Realtime session estimate | media floor + text tokens + tool tokens + history growth + optional input transcription |
| Pipeline estimate | STT + text model + optional TTS + telephony + storage + monitoring + QA |
Прогоняйте low, typical и high usage. Для Realtime сначала меняйте assistant speech time и Response count; именно они часто выявляют margin risk. Для transcription-first route меняйте audio duration, text-model output length, retry rate, storage retention и human-review load.
Перед launch соберите evidence из реальных sessions: median и p95 user audio duration, median и p95 assistant audio duration, Response count, average history size by late turn, input transcription usage and model, text tokens in tools and follow-up processing, failed or retried sessions, human review minutes per transcript, current OpenAI price rows on launch date.
Перепроверяйте цены в день deploy. Model IDs, availability, minute rows, token rows и account-specific access меняются, а старые calculators быстро стареют.
Часто задаваемые вопросы
Realtime API всегда дороже конвейера расшифровки?
Нет. Realtime voice-agent sessions обычно имеют более высокий floor, чем plain transcription, но правильный вопрос — создает ли live spoken interaction value. Если нужны interruption, low latency, tool use during call и spoken output, Realtime может окупаться. Если нужен text artifact, transcription-first обычно дешевле начать и проще бюджетировать.
gpt-realtime-whisper это то же самое, что gpt-realtime-2?
Нет. gpt-realtime-whisper предназначен для live transcription-only workflows, где нужны transcript deltas без spoken assistant output. gpt-realtime-2 — это Realtime voice-agent route для live spoken assistant sessions. Смешивание этих rows портит cost comparison.
Почему $5.76/hour нельзя назвать ценой Realtime за час?
Потому что это media-token floor для одного counted hour user audio плюс одного generated hour assistant audio по текущим rows gpt-realtime-2. Он исключает text tokens, repeated history, tools, optional input transcription, special tokens, telephony и pipeline components.
Какой маршрут нужен для live captions?
Начните с realtime transcription-only. OpenAI route для pricing — gpt-realtime-whisper, если нужны live transcript deltas без spoken assistant. Если audio может подождать до конца recording, сравните gpt-4o-transcribe и gpt-4o-mini-transcribe.
Собственный STT -> LLM -> TTS pipeline всегда лучше Realtime?
Нет. Pipeline может быть дешевле для text-centered work и удобнее для compliance, telephony, debugging и vendor mix. Но он добавляет integration work и component latency. Если experience зависит от natural interruption и spoken response quality, native Realtime session может быть лучшим route.
Самое безопасное production rule?
Сначала выберите route, затем используйте текущие official OpenAI rows для parts that OpenAI prices directly, все остальное помечайте как variable и проверяйте пилотом. Не платите за spoken assistant output, когда text достаточно, и не называйте media-token floor финальным bill.