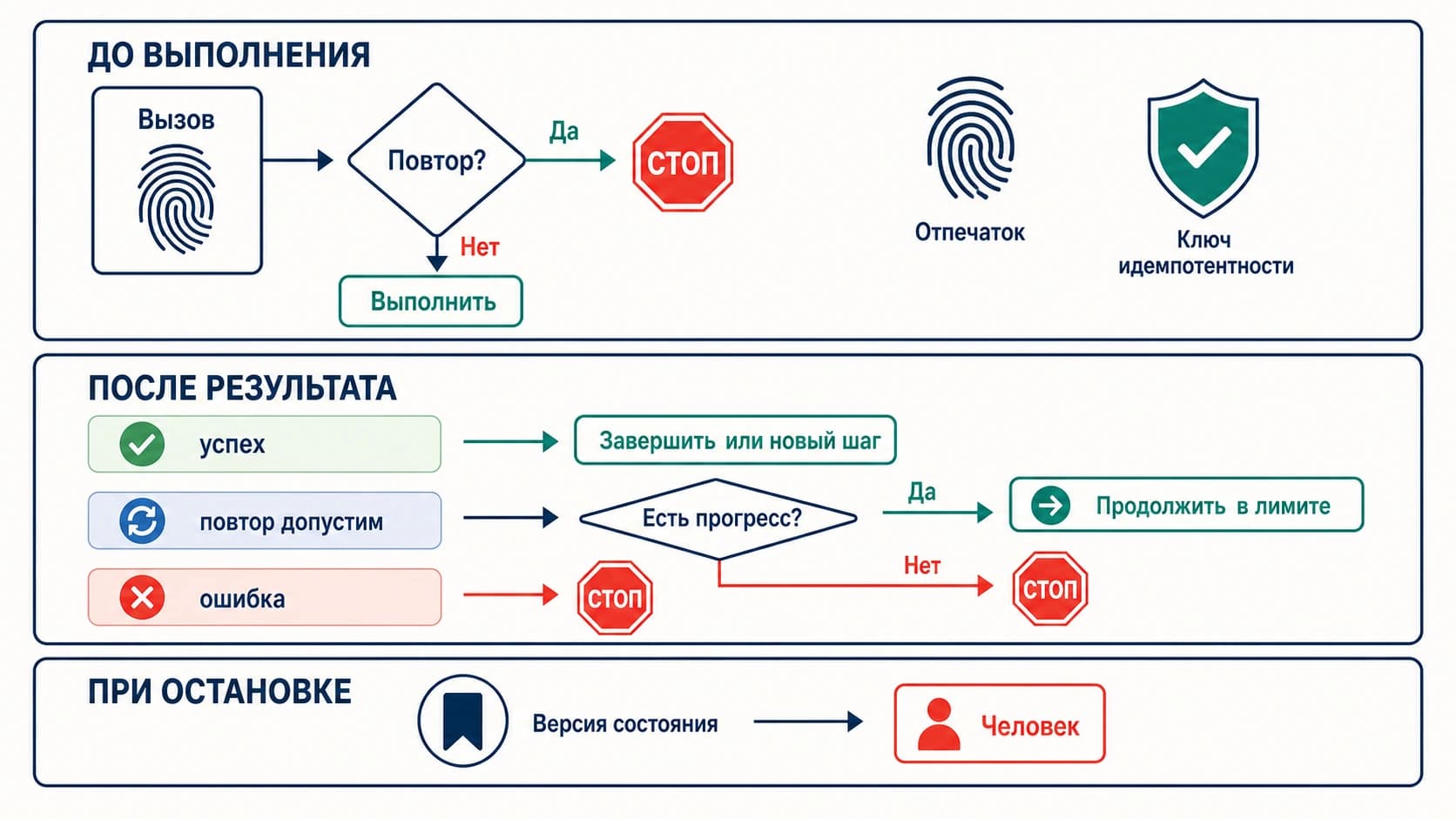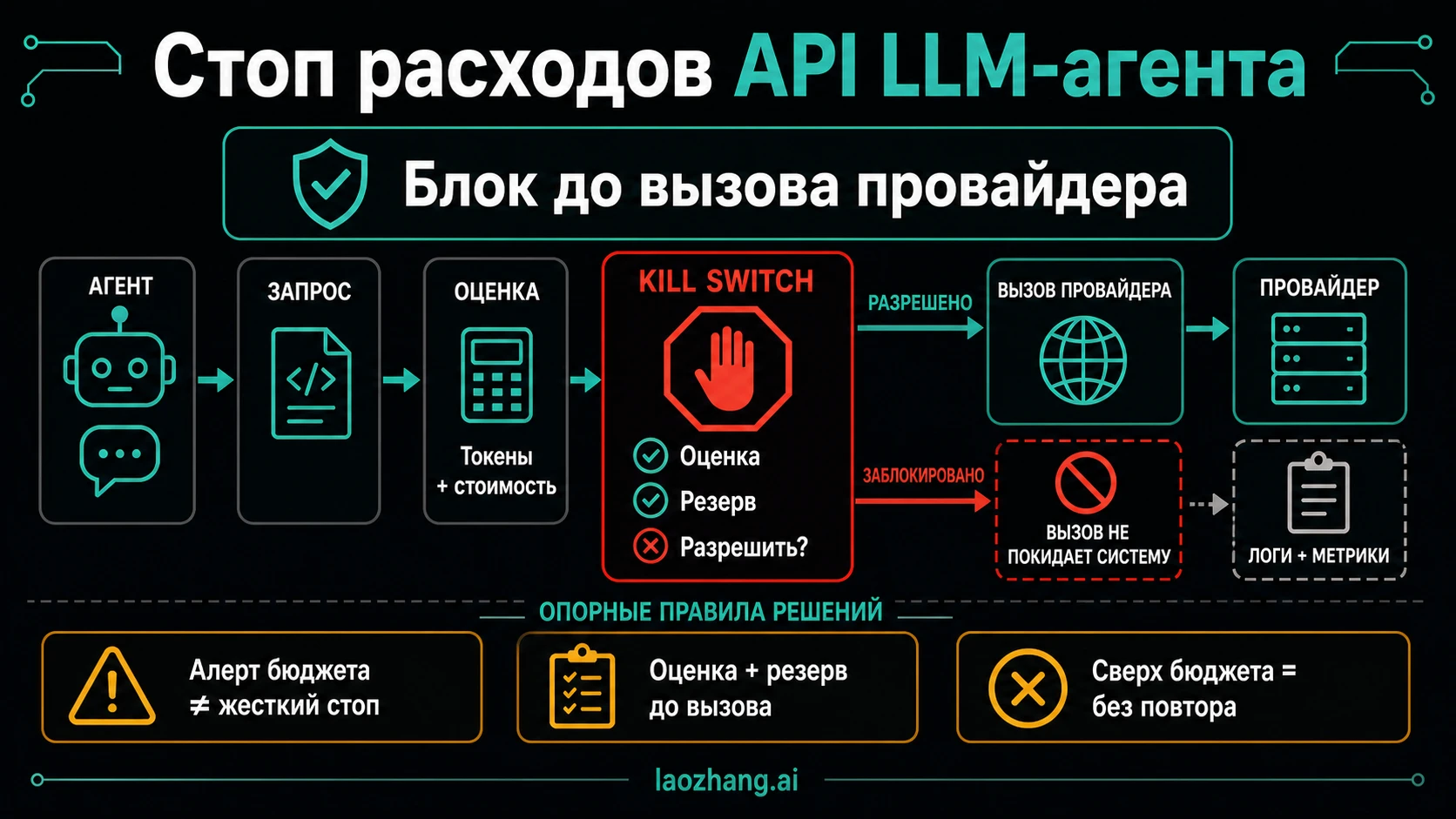
Kill switch расходов API для LLM-агента должен срабатывать до того, как запрос уйдет к платному провайдеру. Если агент умеет повторять шаги, запускать подагентов, вызывать инструменты или переключаться на запасной маршрут, бюджетная проверка должна стоять на пути каждого такого вызова. Отчет в billing dashboard и письмо о превышении бюджета полезны, но они приходят слишком поздно для runaway loop.
Минимальная рабочая схема выглядит так: оценить максимальную стоимость запроса, атомарно зарезервировать эту сумму в общем ledger, вызвать провайдера только если резервирование прошло, затем сверить фактический usage и вернуть остаток резерва. Если лимит будет нарушен, агент получает terminal over_budget с retryable: false.
| Контроль | Что он останавливает | Роль в budget stop |
|---|---|---|
| Billing alert | Оператор поздно заметил рост расходов | Мягкий сигнал, запросы могут продолжаться |
| Provider или project cap | Управление счетом на стороне провайдера | Полезный backstop, не первый gate агента |
| Gateway budget | Трафик через единый proxy или gateway | Может быть жестким стопом, если нет обходов |
| Pre-provider gate | Следующий платный model call | Главный kill switch для автономного агента |
Правило остановки должно быть записано явно: после over_budget агент не повторяет запрос, не запускает helper, не переключается на другой платный ключ и не просит tool сделать скрытый model call. Новое действие возможно только после ручного изменения лимита или политики.
Что считать настоящим kill switch
Настоящий kill switch расходов не равен dashboard, email alert, quota graph или обычному rate limit. Он должен иметь право сказать no до начала оплачиваемой работы. Такой контроль можно разместить в runtime агента, внутреннем OpenAI-compatible proxy, API gateway, wrapper перед провайдером или sidecar-сервисе. Главное требование одно: именно через него проходит credential path, которым агент реально пользуется.
Самая частая ошибка архитектурная. Команда добавляет budget warning после того, как worker уже получил direct provider key. Это защищает финансовую почту, но не следующий API call. Если агент имеет planner loop, retry loop, tool loop и очередь sub-agent, все эти пути должны тратить бюджет через один gate.
Если агент уже повторяет один и тот же инструмент, сначала используйте руководство по диагностике tool loop: классифицируйте цикл и заблокируйте следующий небезопасный вызов, а не сводите инцидент только к расходам.
Разведите термины в runbook:
| Термин | Используйте для | Не используйте для |
|---|---|---|
| Spend limit | Денежный потолок проекта, команды, пользователя или run | Token throughput |
| Rate limit | Requests или tokens за временное окно | Полная месячная стоимость |
| Soft budget | Alerts, reporting, threshold governance | Блокировка до provider call |
| Hard stop | Запрос отклонен до новой платной работы | Письмо или отчет после факта |
Эта лексика нужна не ради чистоты текста. Во время инцидента оператор должен спросить не "где у нас поле budget", а "какой компонент может запретить следующий платный вызов".
Выберите слой контроля
Надежная production-схема почти всегда слоистая. Primary stop стоит в request path, а provider, platform, token caps и alerts работают как backstops и observability.
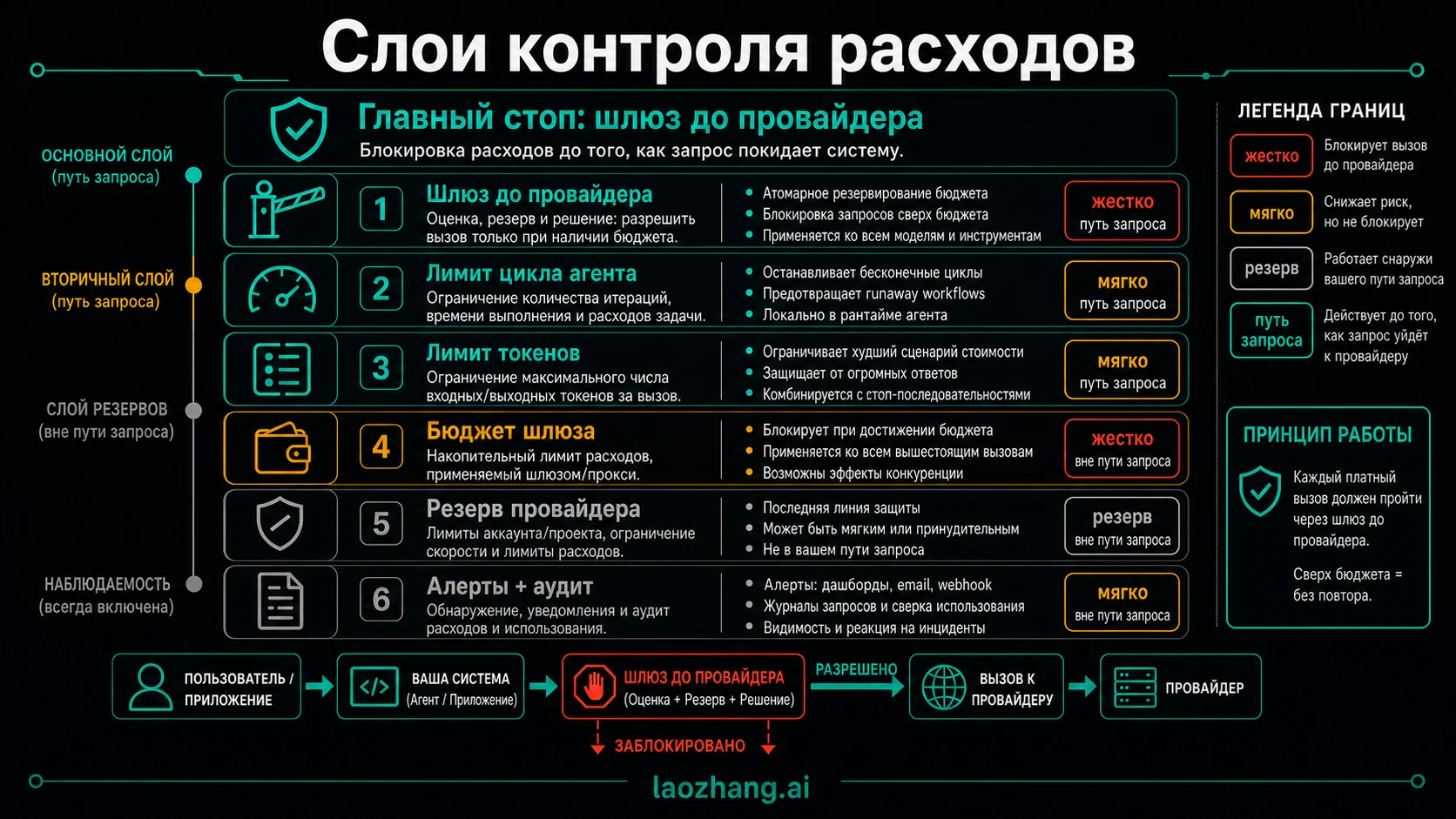
| Слой | Силен в чем | Слабое место | Как использовать |
|---|---|---|---|
| Agent loop limit | Бесконечные циклы, слишком много tool steps, долгий wall-clock | Не знает точный счет провайдера | Локальный safety rail |
| Per-call token cap | Ограничивает худший single request | Не остановит тысячи маленьких запросов | Guardrail формы запроса |
| Pre-provider spend gate | Отклоняет следующий платный request до выхода из системы | Требует общего ledger и дисциплины маршрутов | Primary kill switch |
| Gateway budget | Общий контроль across keys, teams, providers и models | Любой bypass делает дыру; concurrency надо тестировать | Shared control plane |
| Provider/project cap | Account governance у провайдера | Может быть мягким, задержанным или не учитывать retry semantics агента | Backstop |
| Alerts и audit logs | Detection, notification, postmortem | Не обязаны остановить следующий call | Observability |
Если у вас уже есть OpenAI-compatible proxy, начните там: один base URL легче контролировать, чем десятки SDK-вызовов. Если только runtime агента видит все tool-triggered calls, ставьте gate в runtime и заставьте подагентов наследовать тот же budget scope. Если у вас несколько providers, внутренний gateway обычно проще для аудита, чем копирование budget logic в каждый worker.
Плохой вариант - partial gate. Planner идет через бюджет, evaluator или retrieval tool держит прямой ключ, а emergency fallback route разрешен без ledger. При аварии агент все равно найдет путь к счету.
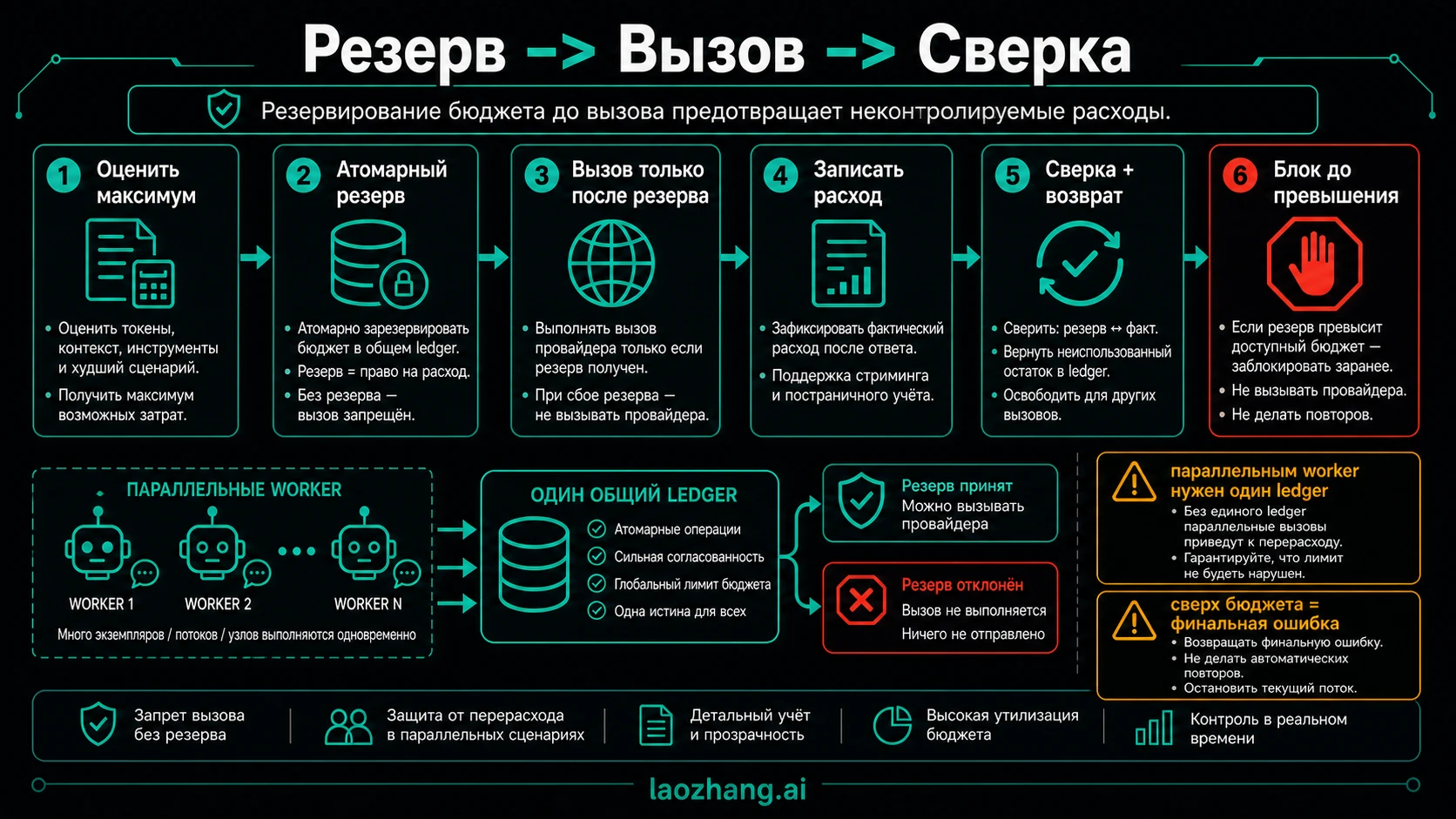
Реализуйте reserve, call, reconcile
До ответа провайдера точную цену вы не знаете, поэтому gate должен резервировать худший допустимый сценарий. Это консервативно, но именно так вы избегаете гонки между параллельными worker.
Минимальные поля ledger:
| Поле | Зачем нужно |
|---|---|
| budget_id | Команда, пользователь, проект, agent run или иной владелец лимита |
| limit_amount | Разрешенный максимум на период или run |
| reserved_amount | Сумма, заблокированная in-flight calls |
| actual_amount | Фактическая сумма после сверки usage |
| period_start / period_end | Окно сброса бюджета |
| request_id | Связь решения с provider logs |
| agent_run_id | Группировка planner, worker, sub-agent и tool calls |
| decision | allowed, blocked, reconciled или released |
| reason | cap reached, missing estimate, unknown model, override или policy block |
Flow до вызова:
tsasync function guardedModelCall(request) { const estimate = estimateWorstCaseCost(request); const reservation = await ledger.reserveAtomically({ budgetId: request.budgetId, requestId: request.requestId, agentRunId: request.agentRunId, amount: estimate, }); if (!reservation.allowed) { return { error: "over_budget", retryable: false }; } const response = await provider.responses.create(request.payload); await ledger.reconcile({ reservationId: reservation.id, actualAmount: costFromUsage(response.usage), usage: response.usage, }); return response; }
Ключевое слово - atomically. Если пять worker одновременно читают remaining budget и все вызывают provider, usage logs придут уже после перерасхода. Резервирование должно быть транзакцией базы, Redis script, durable workflow step или gateway operation, которая не допускает interleaving для одного budget_id.
Streaming требует отдельного правила. Первичный reserve равен максимальному выводу, который вы разрешили. Если usage доступен только в конце stream, сверяйте при закрытии. Если client disconnected до финального usage, не освобождайте весь reserve автоматически: оставьте conservative charge, пометьте unknown или запустите reconciliation job по provider logs.
Заставьте агента остановиться
Budget response должен быть частью agent semantics. Обычный timeout или 429 иногда можно повторять. over_budget нельзя повторять для того же scope.
json{ "error": "over_budget", "retryable": false, "budget_id": "team-alpha-agent-run", "next_allowed_action": "human_budget_override" }
Три правила распространения:
| Правило | Почему |
|---|---|
| Planner больше не планирует paid work | Иначе root loop продолжит создавать blocked jobs |
| Sub-agent наследует parent budget scope | Иначе helper потратит после остановки родителя |
| Tool calls, которые вызывают model, проходят тот же gate | Иначе tools становятся скрытым расходом |
Retry policy должен иметь отдельный stop list: over_budget, policy_blocked и missing_budget_scope не ретраятся. Их надо логировать, показывать оператору и завершать run. Нельзя разрешать агенту "попробовать другой маршрут" без новой бюджетной политики, потому что это меняет owner, key, gateway и liability.
Проверьте границы провайдеров и gateway
Provider controls полезны, но это разные механизмы. Перед публикацией runbook проверьте текущую документацию, потому что бюджетные функции и dashboard behavior меняются.
| Surface | Что проверить сейчас | Практическая граница |
|---|---|---|
| OpenAI project budgets | В текущей справке OpenAI project monthly budgets описаны как soft spending thresholds: API requests могут продолжаться после превышения. Rate limits docs отдельно говорят о throughput limits и usage/spend limits. | Не используйте project budget как единственный request-path kill switch. |
| OpenAI Responses usage | Responses содержат usage fields для reconciliation. | Полезно после call, недостаточно для pre-call block. |
| Anthropic limits | Документация Anthropic разделяет spend limits и rate limits. | Хороший backstop, но прямые calls агента все равно ведите через gate. |
| LiteLLM proxy | Документы LiteLLM описывают budgets, agent/session caps и spend tracking. | Подходит, если весь paid traffic проходит через proxy. |
| Cloudflare AI Gateway | Spend limits могут возвращать HTTP 429 после cost limit, с caveat по eventual consistency. | Сильный gateway вариант, но concurrency bursts и bypass routes надо тестировать. |
| Vercel Spend Management | Может notify, запускать webhooks или pause production deployments при настройке. | Platform brake, не замена per-agent gate. |
Для OpenAI rate-limit symptoms держите отдельную ветку incident response. Rate limit отвечает на throughput; spend kill switch отвечает на вопрос, должен ли ваш агент вообще отправлять следующий платный запрос.
Протестируйте без вызова провайдера
Готовность kill switch доказывается не красивым логом blocked, а тем, что после лимита provider counter остается нулевым.
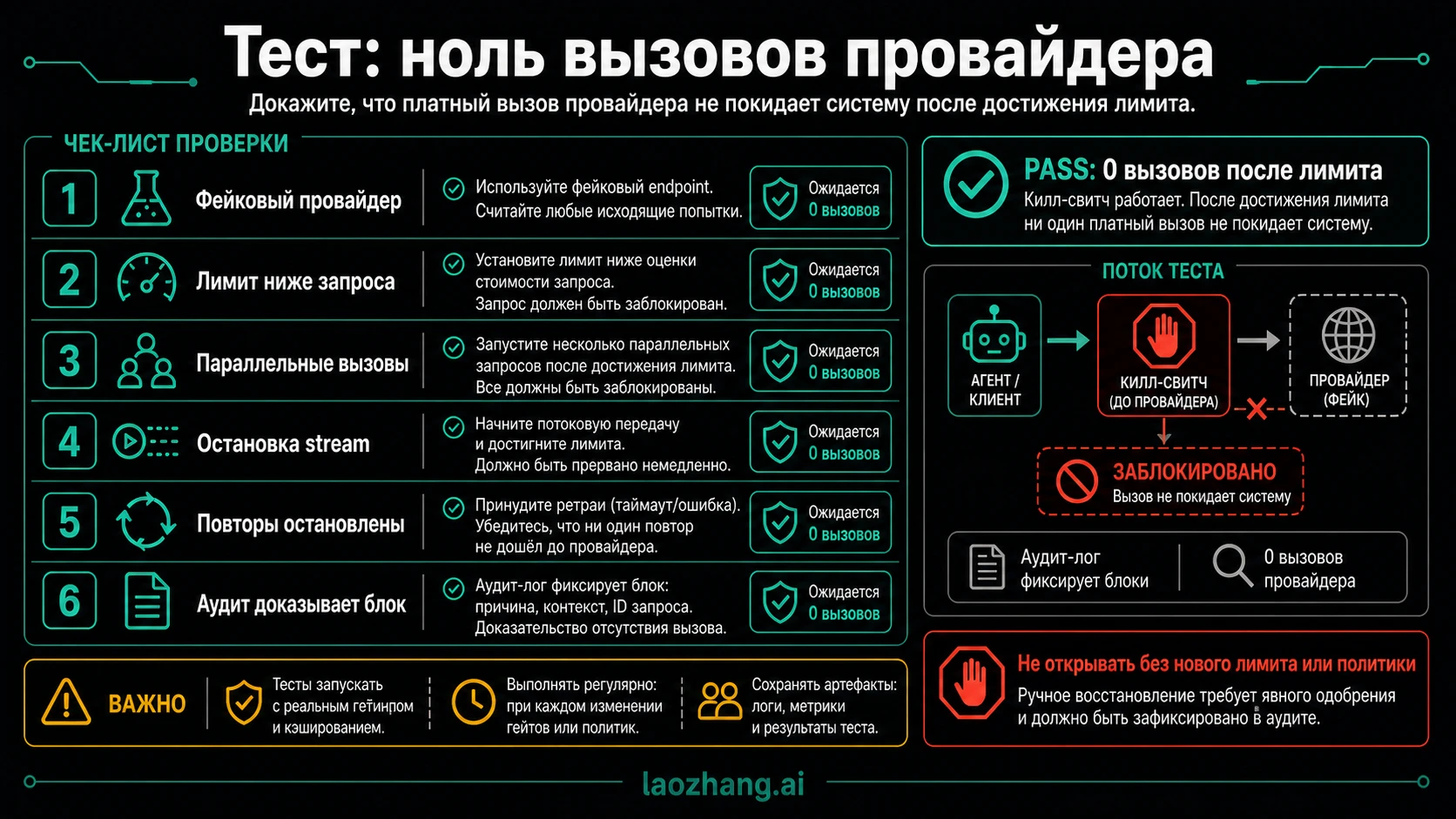
| Тест | Setup | Pass condition |
|---|---|---|
| Fake provider | Подмените endpoint локальным counter service | После исчерпания бюджета counter равен 0 |
| Cap below request | Remaining budget ниже estimate | Gate возвращает over_budget до network call |
| Parallel workers | Запустите конкурентные requests, которые превысили бы cap при гонке | Только зарезервированные calls проходят |
| Streaming abort | Оборвите stream до финального usage | Ledger держит conservative reserve до reconciliation |
| Retry policy | Смоделируйте timeout, 429 и over_budget | Ретраятся только retryable errors |
| Audit packet | Проверьте ledger, request_id, agent_run_id, reason | Оператор может объяснить блокировку |
Повторяйте эти тесты после изменения price metadata, model routing, retry policy, gateway config или storage. Если fake provider получает запрос после cap, это еще cost monitor, а не kill switch.
Production runbook
- Заморозьте direct provider credentials и проверьте, что worker не может обойти gate.
- Уточните budget scope: user, team, project, agent run или monthly account cap.
- Проверьте ledger: actual spend, reserved spend, in-flight calls, unknown items.
- Убедитесь, что агент получил terminal over_budget.
- Остановите retries, sub-agent scheduling и tool-triggered model calls.
- Сверьте provider logs с ledger records.
- Решите: поднять cap, сузить задачу или закрыть run.
- Для human override запишите approver, новый cap, срок действия и причину.
Самый опасный override - "попробуем через другой route". Это уже новая budget decision, а не retry.
Часто задаваемые вопросы
Достаточно ли OpenAI project budget?
Нет. Текущая справка OpenAI описывает project budgets как soft thresholds. Они полезны для governance и alerts, но runaway agent должен быть остановлен request-path gate до provider call.
Что возвращать: HTTP 402, 429 или domain error?
Выберите статус, который умеет ваш клиент, но payload важнее. В нем должны быть budget cap exceeded и retryable: false. Gateway может использовать 429, internal runtime часто удобнее возвращать over_budget.
Как оценить стоимость до ответа?
Берите maximum allowed input, output, tool, image или streaming cost. После call сверяйте actual usage и освобождайте остаток.
Что делать с поздним usage?
Держите reserve до reconciliation или помечайте unknown с conservative charge. Не открывайте бюджет сразу после interrupted stream.
Нужны ли sub-agent отдельные budgets?
Можно, но parent cap должен наследоваться. Helper не должен тратить после остановки parent run.
Если у нас уже есть gateway?
Проверьте, что каждый paid model path идет через gateway. Потом протестируйте low cap, parallel calls и fake provider. Gateway становится primary kill switch только без bypass routes.