
Сравнение Kimi K2.6 и Claude Opus 4.7 полезно только тогда, когда оно отвечает на рабочий вопрос: какую модель стоит запускать первой в coding-agent и API workflow, а где нельзя менять production default без контрольного прогона.
Короткий ответ такой: если вам нужны дешевые массовые прогоны, низкорисковые правки, тестовые заготовки и много попыток, первым кандидатом становится Kimi K2.6. Если работа связана с миграцией, платежным кодом, безопасностью, длинным контекстом или багом, который дороже токенов, первым нужно оставлять Claude Opus 4.7. Если команда собирается заменить Opus в маршрутизации по умолчанию, обе модели надо запускать на одном и том же workflow.
| Маршрут | Когда стартовать | Почему | Стоп-правило |
|---|---|---|---|
| Kimi first | Нужны дешевые большие серии coding-agent экспериментов | Цена Kimi позволяет превратить число попыток в часть стратегии | Не называйте это заменой Opus без проверки на вашем workflow |
| Opus first | Цена ошибки выше цены токенов | У Opus сильнее premium-контракт, 1M context и зрелая API-документация | Не меняйте default только из-за более низкой строки цены |
| Dual-run | Планируется смена default model или routing policy | Replacement quality измеряется дефектами и review cost | Нет порога потерь - нет переключения |
На 2026-04-23 официальный контракт фиксирует резкую разницу: Kimi K2.6 указывает cache-hit input $0.16/MTok, input $0.95/MTok, output $4.00/MTok и 262,144-token context; Anthropic указывает Claude Opus 4.7 по $5/MTok input, $25/MTok output, 1M context и 128k max output. Это доказывает сильный cost route для Kimi и premium-control route для Opus. Это не доказывает универсальную замену.
Быстрый ответ для русскоязычного читателя
В русскоязычном сегменте такие сравнения часто смешивают три слоя: страницы provider comparison, Reddit-дискуссии про замену Opus и видео с быстрой оценкой. Поэтому статья должна сначала отделить официальный контракт от сторонней поверхности. Если страница или видео показывают цену, еще не ясно, кому принадлежит эта цена. Если пост говорит, что модель «достаточно хороша», еще не ясно, на каком репозитории и с каким review это проверялось.
Практическая развилка остается простой. Kimi получает первый прогон там, где объем попыток важнее абсолютной надежности: массовые исправления, low-risk cleanup, test scaffolding, черновые агенты, открытая модельная полоса. Opus получает первый прогон там, где пропущенная ошибка возвращается миграцией, инцидентом или часами senior review. А когда речь идет о смене default, полезна только параллельная проверка.
Такой ответ не занижает Kimi. Наоборот, он дает модели честный шанс выиграть там, где цена действительно меняет поведение команды. Если дешевый маршрут позволяет сделать десять вариантов, отбраковать слабые и оставить лучший, он может оказаться лучше для low-risk batch work. Но если один скрытый дефект ломает платежный flow, дешевизна входа уже не главный показатель.
Официальный контракт важнее шума вокруг сравнения

| Контракт | Kimi K2.6 | Claude Opus 4.7 |
|---|---|---|
| Владелец фактов | Moonshot / Kimi | Anthropic |
| API-идентификатор | публичный маршрут K2.6 на платформе Kimi | claude-opus-4-7 |
| Цена на 2026-04-23 | cache hit $0.16/MTok, input $0.95/MTok, output $4.00/MTok | input $5/MTok, output $25/MTok |
| Контекст / output | 262,144 токена context | 1M context и 128k max output |
| Что это значит | Дешевле расширять число попыток | Лучше оставлять premium control для рискованных задач |
Факты о Kimi должны принадлежать Moonshot/Kimi: цена, cache-hit row, context window и доступность. Факты о Claude Opus 4.7 должны принадлежать Anthropic: model ID, цена, 1M context, 128k max output и поведение API при миграции. OpenRouter, Artificial Analysis, aitunnel или другие страницы сравнения могут быть полезными, но они не становятся владельцами first-party фактов.
Простая форма с одним миллионом входных и одним миллионом выходных токенов показывает масштаб: Kimi без cache hit дает около $4.95, Opus дает $30. Но workload cost не заканчивается строкой price list. Нужно считать retry, tool calls, wall-clock time, reviewer intervention, failed tests, hidden defects и rollback. В risky coding дешевле на входе иногда становится дороже после review.
Для Opus отдельно важна tokenization caveat. Anthropic пишет, что тот же текст может отображаться примерно в 1.0x-1.35x токенов в зависимости от content type. Это не фиксированная надбавка, но причина измерять реальные prompts перед бюджетом.
Что доказательства не могут доказать
Kimi K2.6 официально выглядит как серьезная текущая модель, и этого достаточно для pilot. Но официальный benchmark Kimi не является прямой таблицей против Claude Opus 4.7. В нем есть другие модели и предыдущие линии, поэтому нельзя превращать один столбец в доказательство replacement.
Сторонние сравнения ценны как метод. Они показывают, какие failure modes стоит воспроизвести: passing tests с плохой архитектурой, слишком широкий refactor, пропущенные migration steps, неверные assumptions, длинные tool loops, красивый summary без исправленного root cause. Но они не должны владеть production routing.
| Тип доказательства | Что поддерживает | Что не поддерживает |
|---|---|---|
| First-party Kimi | Kimi дешевле, current и заслуживает pilot | Kimi уже заменяет Opus везде |
| First-party Anthropic | Opus имеет premium API contract, 1M context и migration notes | Opus всегда оправдывает цену |
| Third-party comparison | Категории тестов и видимые риски | Официальную цену или default routing |
| Ваш dual-run | Локальное решение о замене | Универсальный вывод для всех команд |
Как провести coding-agent pilot
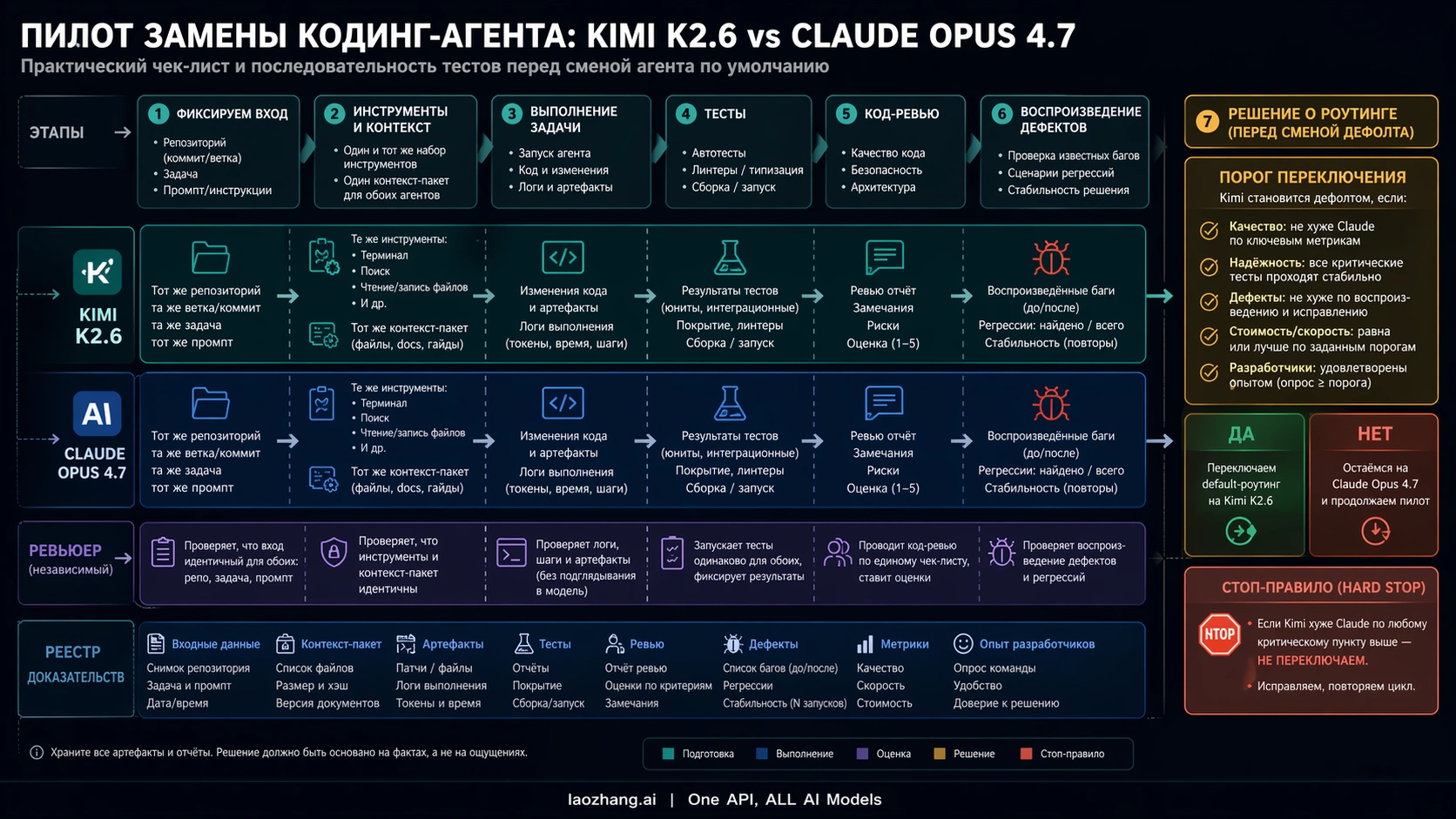
Пилот должен быть скучным. Возьмите задачи, где Opus уже был полезен: маленький bug fix, средний refactor, test-writing task, long-context task и задачу с неполной спецификацией. Для agentic coding оставьте tools и repo navigation. Для API batch оставьте реальные prompt templates, timeout и retry policy.
Обе модели запускаются на одной repository snapshot, с одной задачей, одним budget, теми же stop conditions, теми же unit/integration/lint checks и тем же reviewer. Считать нужно не только цену токенов, но и retries, tool loops, manual edits, hidden bug severity, время ревью и число откатов.
Порог переключения записывается до старта. Например: Kimi может стать default для low-risk batch edits, если real defects не хуже Opus больше чем на 10%, а стоимость падает больше чем вдвое. Но для migration или security-sensitive code нужен почти parity или более длинный dual-run. Это не противоречие, а нормальная risk pricing.
Маршруты по workload

| Workload | Начинать с Kimi | Начинать с Opus | Dual-run перед default |
|---|---|---|---|
| High-volume agent experiments | Да | Только как quality control sample | Перед важными repo |
| Low-risk cleanup и tests | Да | Если review time стал bottleneck | Перед auto-merge |
| Repo-wide migration | Только после control run | Да | Да |
| Security или payment code | Обычно нет | Да | Да |
| Long-context production analysis | Если 262k context хватает и цена важнее | Если нужен 1M или 128k output | Если вывод заменит решение Opus |
| Open-source/self-host evaluation | Kimi естественный first route | Opus не open-model route | Если output конкурирует с production decision |
Если реальный вопрос только про переход внутри Anthropic, используйте Claude Opus 4.7 vs Claude Opus 4.6. Если вы выбираете между Anthropic, OpenAI и Google, открывайте Claude Opus 4.7 vs GPT-5.4 vs Gemini 3.1 Pro. Эта страница должна оставаться узкой: Kimi versus Opus как route decision.
API-заметки перед сменой default
Не смешивайте first-party Kimi, provider route и marketplace route. У каждой поверхности будут свои latency, quota, billing, logs, support и failure terms. Если в отчете стоит цена Kimi, рядом должен быть указан владелец этой цены. Иначе команда будет сравнивать один прайс с другим контрактом.
С Anthropic тоже нельзя сделать только string replace. Opus 4.7 меняет или уточняет поведение вокруг sampling parameters, extended thinking, tokenizer behavior, high-resolution images и task budgets. Если ваш client передает старые параметры, проблема migration может быть в harness, а не в prompt.
Минимальный rollout log должен включать cost table, defect table, review table и routing table. Cost table отделяет cached input, non-cached input и output. Defect table считает severity. Review table фиксирует human minutes. Routing table показывает, какие задачи уходят Kimi-only, Opus-only или dual-run.
Шаблон оценки
| Что записывать | Как записывать | Почему это нужно |
|---|---|---|
| Cost | input, cached input, output, retry, tools | Дешевая строка цены не равна дешевому workflow |
| Quality | blocker, major, minor, style | Один blocker важнее десяти косметических замечаний |
| Time | wall-clock, reviewer minutes, rerun count | В agent coding стоимость часто уходит в review |
| Route | Kimi-only, Opus-only, dual-run, rollback | Pilot должен стать routing rule |
Как превратить pilot в правило команды
После первого dual-run не оставляйте итог в форме «Kimi вроде справился» или «Opus выглядит надежнее». Превратите результат в routing matrix. Первый слой: Kimi-only для обратимых, низкорисковых и хорошо проверяемых задач. Второй слой: Opus-only для migration, security, payment logic, сложных refactor и long-context production analysis. Третий слой: dual-run для задач на границе, где команда собирается менять default или где review cost исторически высок.
Эта матрица должна иметь дату пересмотра. Цены Kimi, provider routes, доступность и open-source boundary могут измениться. У Opus тоже могут меняться API behavior, tokenizer behavior и task-budget controls. Когда меняется контракт, не переносите старый вывод автоматически: прогоните маленький control pack снова и обновите routing rule.
Часто задаваемые вопросы
Kimi K2.6 дешевле Claude Opus 4.7?
Да, по first-party ценам на 2026-04-23 Kimi значительно дешевле: $0.95/MTok input, $4.00/MTok output и $0.16/MTok cache hit против $5/$25 у Opus. Provider prices могут отличаться.
Может ли Kimi заменить Opus?
Может только после проверки на вашем workflow. Более честная формулировка: Kimi заслуживает pilot для cost-sensitive coding work, но не является автоматической production replacement.
Что лучше для coding agents?
Opus 4.7 безопаснее первым для high-risk coding, migrations и long-context production work. Kimi K2.6 лучше первым для дешевых массовых прогонов, если output можно review или отклонить.
Доказывает ли benchmark Kimi победу над Opus 4.7?
Нет. Официальный benchmark Kimi полезен, но он не является прямым head-to-head против Opus 4.7.
Что проверить перед сменой default?
Один repo snapshot, одна спецификация, один tool budget, одни tests, один reviewer и заранее заданный threshold качества. Без этого default change является догадкой.
Можно ли использовать OpenRouter или Artificial Analysis для решения?
Можно как scouting surface, но official model ID, price, context и API behavior должны возвращаться к Kimi и Anthropic.
Что если нужен 1M context?
Начинайте с Claude Opus 4.7, если 1M context является центральным требованием. Kimi 262k context большой, но это другой контракт.