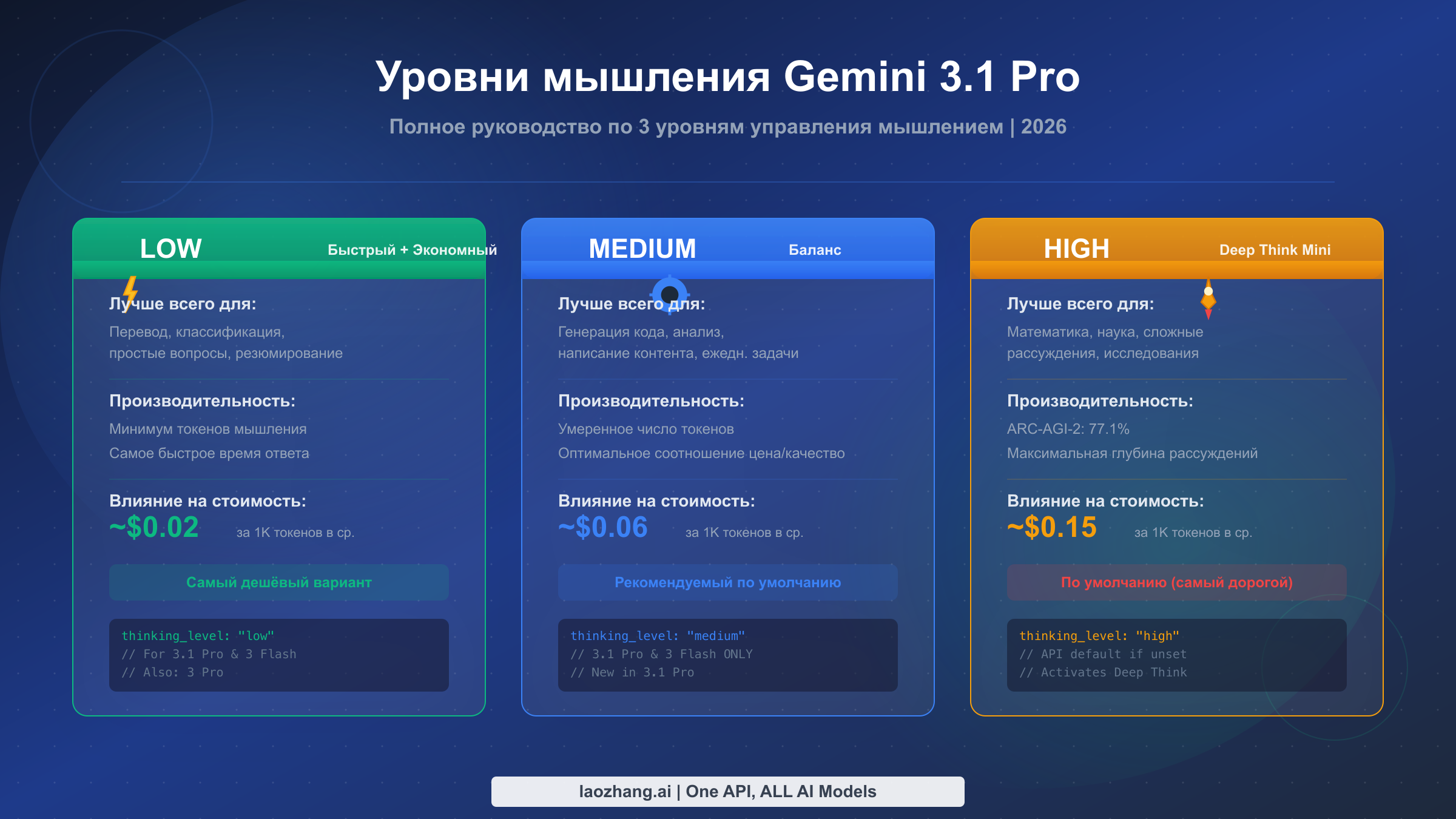
Gemini 3.1 Pro предлагает три уровня мышления — LOW, MEDIUM и HIGH — которые настраиваются через параметр thinking_level в API-запросах. Установите LOW для быстрых и экономичных задач вроде перевода и классификации. Используйте MEDIUM как повседневный режим по умолчанию для сбалансированного качества и стоимости. Выберите HIGH для активации Deep Think Mini — специализированного режима рассуждений, достигающего 77,1% на ARC-AGI-2 (февраль 2026, Google DeepMind). Если вы не укажете уровень, API по умолчанию использует HIGH — самый дорогой вариант, — поэтому всегда задавайте предпочтительный уровень явно.
Что такое уровни мышления Gemini 3.1 Pro и почему они важны
Google DeepMind выпустила Gemini 3.1 Pro 19 февраля 2026 года, представив значительное обновление в управлении поведением рассуждений модели. В отличие от предшественника Gemini 3 Pro, который поддерживал только два режима мышления (LOW и HIGH), Gemini 3.1 Pro предоставляет трёхуровневую систему — LOW, MEDIUM и HIGH — давая разработчикам гораздо более точный контроль над балансом между глубиной рассуждений, скоростью ответа и стоимостью API. Эта трёхуровневая система управления настраивается через параметр thinking_level внутри объекта ThinkingConfig, заменяя устаревший числовой подход thinking_budget, использовавшийся в серии Gemini 2.5.
Выбранный уровень мышления напрямую влияет на три критических аспекта каждого API-запроса. Во-первых, он определяет, сколько «токенов мышления» модель генерирует внутренне перед формированием видимого ответа, — а эти токены тарифицируются по той же ставке, что и выходные токены ($12,00 за миллион токенов при контекстном окне до 200K, согласно ai.google.dev/pricing, февраль 2026). Во-вторых, уровень влияет на задержку ответа: запрос с уровнем LOW может вернуть результат за 1-3 секунды, тогда как запрос HIGH с Deep Think Mini может занять 30 секунд и более для сложных задач. В-третьих, и это, пожалуй, самое важное, уровень мышления напрямую управляет качеством рассуждений: более высокие уровни обеспечивают более тщательный анализ цепочки рассуждений, что значительно улучшает результаты на задачах, требующих многошаговой логики, математических доказательств или научного анализа.
Понимание этих трёх уровней важно по практическим причинам, выходящим далеко за рамки технического любопытства. Если вы создаёте продуктовое приложение, обрабатывающее тысячи API-запросов ежедневно, разница между использованием HIGH по умолчанию и стратегическим выбором MEDIUM для большинства запросов может сэкономить вам 60-75% ежемесячного счёта за API. Поведение модели по умолчанию — использование HIGH, когда уровень не указан — означает, что разработчики, не настраивающие уровни мышления явно, платят премиальную цену за каждый запрос, даже за простые задачи вроде классификации текста или перевода, где минимальное рассуждение даёт столь же хорошие результаты. Для тех, кто работает с бесплатным доступом к Gemini 3.1 Pro API, понимание уровней мышления помогает максимально эффективно использовать квоту бесплатного тарифа.
Подробный разбор LOW, MEDIUM и HIGH: что делает каждый уровень
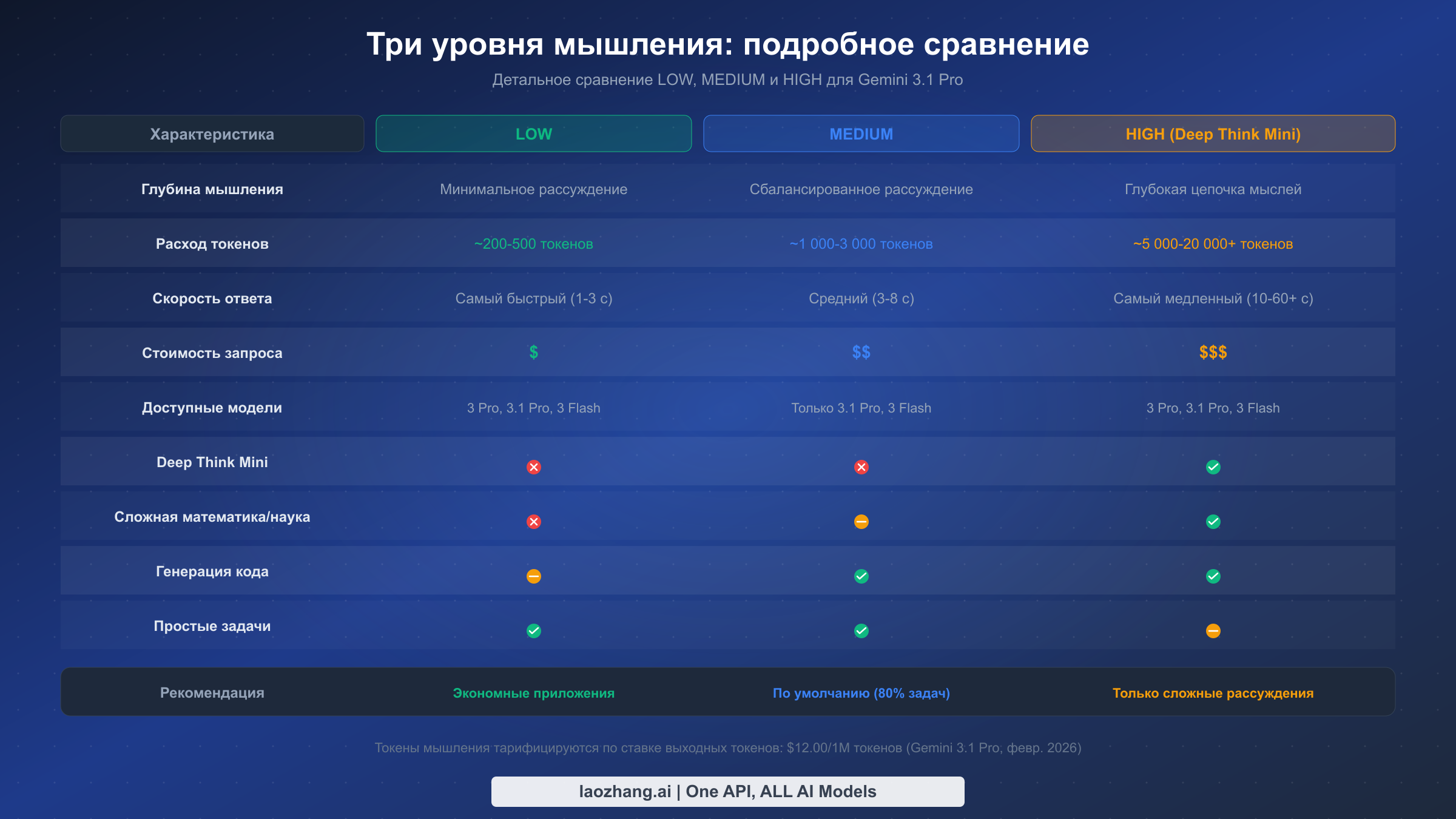
Каждый уровень мышления представляет собой принципиально иной режим рассуждений, и различия идут глубже, чем просто «больше мышления — лучше ответы». Когда вы устанавливаете thinking_level в значение "low", вы указываете Gemini 3.1 Pro использовать минимальное внутреннее рассуждение — модель пропускает расширенный анализ цепочки мышления и переходит к ответу более напрямую. Это обеспечивает самые быстрые ответы с наименьшим количеством токенов мышления, что идеально подходит для простых задач, где модель уже обладает сильным потенциалом распознавания паттернов. На практике LOW обычно генерирует 200-500 токенов мышления на запрос, что даёт время ответа 1-3 секунды.
Уровень MEDIUM представляет собой наиболее значительное нововведение в Gemini 3.1 Pro по сравнению с предыдущими моделями. Этот промежуточный уровень обеспечивает сбалансированное рассуждение — достаточный анализ цепочки мышления для работы с генерацией кода, написанием контента, умеренным анализом и большинством повседневных задач разработки, но без интенсивного обдумывания, которое запускает режим HIGH. MEDIUM обычно генерирует 1 000-3 000 токенов мышления на запрос при времени ответа 3-8 секунд. Именно этот уровень Google неявно проектировала как новый повседневный режим для большинства продуктовых нагрузок, хотя HIGH был установлен как значение API по умолчанию (решение, вероятно, призванное продемонстрировать полный потенциал модели, но обходящееся разработчикам в реальные деньги). Стоит отметить, что MEDIUM доступен только на Gemini 3.1 Pro и Gemini 3 Flash — если вы всё ещё используете Gemini 3 Pro, вам доступны только LOW и HIGH.
Уровень HIGH — это место, где всё становится особенно интересным, потому что установка thinking_level в значение "high" активирует Deep Think Mini — облегчённую версию системы рассуждений Deep Think от Google DeepMind. Deep Think Mini не просто выделяет больше токенов на мышление — он активирует качественно иной подход к рассуждению, который превосходно справляется со сложными многошаговыми задачами. Данные бенчмарков убедительны: Gemini 3.1 Pro с Deep Think Mini достигает 77,1% на ARC-AGI-2 (по сравнению с 31,1% у Gemini 3 Pro без него), 94,3% на GPQA Diamond и 80,6% на SWE-Bench Verified. Однако эта производительность имеет свою цену — HIGH обычно генерирует 5 000-20 000+ токенов мышления на запрос при времени ответа, которое может превышать 60 секунд для действительно сложных задач. Подробное сравнение этих уровней со всем семейством Gemini 3 смотрите в нашем подробном сравнении моделей Gemini 3.
| Бенчмарк | Gemini 3.1 Pro (HIGH) | Gemini 3 Pro | Claude Opus 4.6 | Источник |
|---|---|---|---|---|
| ARC-AGI-2 | 77,1% | 31,1% | 68,8% | VentureBeat, NxCode |
| GPQA Diamond | 94,3% | — | 91,3% | NxCode |
| SWE-Bench Verified | 80,6% | — | — | NxCode |
| Humanity's Last Exam | 44,4% | 37,5% | 40,0% | VentureBeat |
Как выбрать правильный уровень мышления для вашей задачи
Выбор правильного уровня мышления — это самое значимое решение, которое вы примете при интеграции Gemini 3.1 Pro, поскольку оно одновременно определяет качество результата, время ответа и стоимость. Вместо угадывания или использования HIGH для всего подряд можно применить системный подход, основанный на сложности задачи. Ключевое наблюдение состоит в том, что большинство приложений отправляют смесь простых и сложных запросов, и оптимальная стратегия назначает каждому запросу минимальный уровень мышления, необходимый для высококачественного результата.
Структура принятия решений делится на три категории в зависимости от когнитивных требований каждого типа задач. Для задач извлечения и преобразования — перевод, классификация текста, извлечение сущностей, форматирование данных, простое реферирование и ответы на FAQ — LOW обеспечивает отличные результаты, поскольку эти задачи опираются в первую очередь на распознавание паттернов и понимание языка, а не на многошаговое рассуждение. Модель уже усвоила эти навыки в ходе обучения, поэтому дополнительное время на мышление добавляет затраты, не улучшая качество сколько-нибудь заметно. В тестах переключение с HIGH на LOW для этих типов задач обычно показывает менее 2% разницы в качестве результата при снижении стоимости токенов на 80-90%.
Для задач генерации и анализа — генерация кода, написание контента, отладка, умеренный анализ, рекомендации по рефакторингу и интеграция API — MEDIUM находится в «золотой середине». Эти задачи выигрывают от некоторого структурированного рассуждения для планирования вывода, учёта пограничных случаев и поддержания логической согласованности, но не требуют глубокого обдумывания, необходимого для сложных математических или научных задач. MEDIUM обеспечивает достаточную глубину мышления для создания хорошо структурированного кода, связного длинного контента и тщательного анализа, при этом стоимость на 60-70% ниже, чем при HIGH. Вот почему MEDIUM должен быть вашим режимом по умолчанию для большинства продуктовых нагрузок, покрывая примерно 80% типичных API-запросов.
Зарезервируйте HIGH исключительно для задач, где расширенное рассуждение напрямую влияет на качество результата: сложные математические доказательства, научный анализ, разработка новых алгоритмов, многошаговые логические головоломки, синтез исследований из множества источников и задачи олимпиадного программирования. Это задачи, где качественно иной подход Deep Think Mini к рассуждению — а не просто более длительное мышление — даёт измеримо лучшие результаты. Если вы не уверены, нужен ли для задачи уровень HIGH, начните с MEDIUM и повышайте только если качество результата заметно недостаточно. Подход «начинай с малого, повышай по необходимости» предотвращает распространённую ошибку использования HIGH как подстраховки, когда более простого рассуждения было бы достаточно.
| Тип задачи | Рекомендуемый уровень | Типичное качество vs HIGH | Экономия |
|---|---|---|---|
| Перевод | LOW | 98%+ | 85-90% |
| Классификация | LOW | 99%+ | 85-90% |
| Извлечение данных | LOW | 97%+ | 80-85% |
| Простые вопросы-ответы | LOW | 96%+ | 80-85% |
| Генерация кода | MEDIUM | 95%+ | 60-70% |
| Написание контента | MEDIUM | 94%+ | 60-70% |
| Отладка | MEDIUM | 93%+ | 55-65% |
| Аналитические отчёты | MEDIUM | 92%+ | 55-65% |
| Сложная математика | HIGH | 100% (базовый) | 0% |
| Научные исследования | HIGH | 100% (базовый) | 0% |
| Решение новых задач | HIGH | 100% (базовый) | 0% |
Полные примеры кода: Python, JavaScript и REST API
Следующие примеры показывают, как установить уровни мышления в каждом из трёх наиболее распространённых методов интеграции. Все примеры используют идентификатор модели gemini-3.1-pro-preview, который является актуальным на февраль 2026 года (подтверждено на ai.google.dev/gemini-api/docs/gemini-3).
Python (Google Gen AI SDK)
pythonfrom google import genai client = genai.Client(api_key="YOUR_API_KEY") response_low = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Translate this to French: Hello, how are you?", config={ "thinking_config": { "thinking_level": "low" } } ) # MEDIUM - рекомендуемый повседневный режим response_medium = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Write a Python function to merge two sorted arrays efficiently.", config={ "thinking_config": { "thinking_level": "medium" } } ) # HIGH - Deep Think Mini для сложных рассуждений response_high = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Prove that there are infinitely many prime numbers.", config={ "thinking_config": { "thinking_level": "high" } } ) # Доступ к содержимому мышления (когда доступно) for part in response_high.candidates[0].content.parts: if part.thought: print(f"Thinking: {part.text}") else: print(f"Output: {part.text}")
JavaScript (Google Gen AI SDK)
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({ apiKey: "YOUR_API_KEY" }); // MEDIUM - повседневный режим по умолчанию const response = await ai.models.generateContent({ model: "gemini-3.1-pro-preview", contents: "Explain the difference between REST and GraphQL with code examples.", config: { thinkingConfig: { thinkingLevel: "MEDIUM", }, }, }); console.log(response.text); // HIGH - для сложных задач с Deep Think Mini const complexResponse = await ai.models.generateContent({ model: "gemini-3.1-pro-preview", contents: "Design an efficient algorithm to solve the traveling salesman problem for 15 cities.", config: { thinkingConfig: { thinkingLevel: "HIGH", }, }, }); console.log(complexResponse.text);
REST API (cURL)
bash# Уровень MEDIUM - рекомендуемый режим по умолчанию curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{"text": "Write a comprehensive code review for this function..."}] }], "generationConfig": { "thinkingConfig": { "thinkingLevel": "MEDIUM" } } }' # Уровень LOW - для простого извлечения данных curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "contents": [{ "parts": [{"text": "Extract all email addresses from this text: ..."}] }], "generationConfig": { "thinkingConfig": { "thinkingLevel": "LOW" } } }'
Важная деталь реализации: нельзя использовать одновременно thinking_level и устаревший параметр thinking_budget в одном запросе. Попытка сделать это вернёт ошибку HTTP 400. Если вы мигрируете со старой кодовой базы, обязательно удалите thinking_budget перед добавлением thinking_level. Также обратите внимание, что для Gemini 3 Pro и Gemini 3.1 Pro мышление нельзя полностью отключить — даже на уровне LOW модель выполняет некоторое минимальное внутреннее рассуждение.
Deep Think Mini: что происходит при установке HIGH
Когда вы настраиваете Gemini 3.1 Pro с thinking_level: "high", вы не просто выделяете больше токенов для того же процесса рассуждений. Вы активируете Deep Think Mini — облегчённую версию системы рассуждений Deep Think от Google DeepMind, которая представляет собой качественно иной подход к решению задач. Понимание того, что именно делает Deep Think Mini, помогает объяснить как его значительно лучшие результаты на сложных задачах, так и его нецелесообразность (и расточительность) для простых.
Deep Think Mini работает, запуская расширенный процесс рассуждений по цепочке мышления, который разбивает сложные задачи на подзадачи, оценивает несколько путей решения и выполняет внутреннюю верификацию перед формированием окончательного ответа. Это принципиально отличается от стандартного процесса генерации на уровнях LOW или MEDIUM, где модель применяет выученные паттерны более напрямую. Практический эффект наиболее заметен в областях, требующих многошагового логического рассуждения: скачок с 31,1% до 77,1% на ARC-AGI-2 между Gemini 3 Pro и Gemini 3.1 Pro с Deep Think Mini демонстрирует, что это не просто инкрементальное улучшение — это качественный сдвиг в возможностях. Аналогично, 94,3% на GPQA Diamond (вопросы научного уровня для аспирантов) и 80,6% на SWE-Bench Verified (реальные задачи программной инженерии) показывают, что Deep Think Mini превосходен именно в тех областях, где эксперты-люди должны думать тщательно и методично.
Однако Deep Think Mini сопряжён с важными практическими компромиссами, которые каждый разработчик должен понимать, прежде чем его включать. Потребление токенов мышления на уровне HIGH может быть в 10-40 раз выше, чем на LOW — один сложный запрос может сгенерировать 15 000-20 000 токенов мышления, каждый из которых тарифицируется по ставке выходных токенов $12,00 за миллион. Задержка ответа также значительно возрастает: если запрос LOW возвращает результат за 1-3 секунды, запрос HIGH с Deep Think Mini может занять 30-90 секунд для задач, требующих глубокого анализа. Кроме того, токены мышления включаются в контекстное окно модели, что означает, что очень сложные цепочки рассуждений могут потребить значительную часть лимита выходных токенов в 64K. Для задач, которые на самом деле не выигрывают от глубокого рассуждения — переводы, простое форматирование, классификация — Deep Think Mini добавляет стоимость и задержку без ощутимого улучшения качества. Ключ в понимании того, что Deep Think Mini — это инструмент точного применения, а не универсальное обновление.
Процесс мышления частично доступен разработчикам через ответ API. Когда Deep Think Mini активен, ответ содержит части мышления (thought parts), которые можно просмотреть, хотя Google отмечает, что видимость содержимого мышления может быть ограниченной или обобщённой. Эта прозрачность полезна для отладки и понимания, почему модель пришла к определённым выводам, но на неё не следует полагаться как на полную запись процесса рассуждений модели.
Стоимость токенов мышления и оптимизация расходов

Понимание экономики токенов мышления критически важно, поскольку токены мышления представляют собой наибольшую переменную статью расходов при использовании Gemini 3.1 Pro. В отличие от входных токенов (стоимость которых составляет $2,00 за миллион при контексте до 200K токенов), токены мышления тарифицируются по ставке выходных токенов $12,00 за миллион — это 6-кратная наценка по сравнению с входными токенами. Такая структура ценообразования означает, что разница между уровнями мышления LOW и HIGH напрямую транслируется в драматические различия стоимости, особенно в масштабе.
Рассмотрим конкретный сценарий для иллюстрации. Предположим, вы запускаете продуктовое приложение, обрабатывающее 10 000 API-запросов в день со средним вводом 500 токенов и средним выводом 1 000 токенов. На уровне HIGH (по умолчанию, если не указать) каждый запрос может генерировать в среднем дополнительные 8 000 токенов мышления, что стоит примерно $0,096 за запрос только за токены мышления — это $960 в день или приблизительно $28 800 в месяц только за мышление. Переключите ту же нагрузку на MEDIUM (с ~2 000 токенов мышления в среднем), и затраты на токены мышления снижаются до $0,024 за запрос, или около $7 200 в месяц. Используйте LOW там, где это уместно (с ~300 токенов мышления в среднем), и стоимость падает примерно до $0,0036 за запрос. Математика очевидна: неоптимизированные уровни мышления могут превратить управляемый счёт за API в бюджетный кризис.
Наиболее эффективный подход к оптимизации — то, что мы называем стратегией 80/20: направляйте примерно 60% запросов на LOW, 30% на MEDIUM и оставляйте только 10% для HIGH. На основе данных о ценах с ai.google.dev/pricing (февраль 2026) такое распределение может снизить ежемесячные затраты на токены мышления на 70-75% по сравнению с использованием HIGH для всего. Реализация этой стратегии требует простого маршрутизирующего слоя в вашем приложении, который анализирует тип задачи или характеристики промпта и назначает соответствующий уровень мышления. Многие команды реализуют это как функцию, классифицирующую входящие запросы — если задача связана с извлечением, переводом или простым форматированием, направляйте на LOW; если это генерация кода, анализ или написание контента, направляйте на MEDIUM; если речь идёт о сложной математике, научных рассуждениях или решении новых задач, направляйте на HIGH.
Помимо выбора уровня мышления, Google предлагает два дополнительных механизма оптимизации затрат. Batch API даёт 50% скидку на все затраты по токенам (входные, выходные и мышления) для запросов, не требующих ответа в реальном времени — если ваша нагрузка допускает асинхронную обработку, это фактически сокращает ваш счёт вдвое. Кэширование контекста снижает стоимость повторяющихся входных токенов всего до $0,50 за миллион (при стоимости хранения $4,50 за миллион токенов в час), что особенно ценно, если вы отправляете одинаковый системный промпт или контекст во многих запросах. Для команд, использующих агрегационные платформы вроде laozhang.ai, которые обеспечивают единый API-доступ к нескольким моделям, вы можете применять эти стратегии оптимизации к разным провайдерам, сохраняя единую точку интеграции. В сочетании с интеллектуальной маршрутизацией уровней мышления эти стратегии могут снизить общие затраты на API Gemini 3.1 Pro на 80% и более по сравнению с неоптимизированным использованием. Подробнее о бесплатных вариантах читайте в нашем руководстве по лимитам бесплатного тарифа Gemini API.
Миграция с thinking_budget на thinking_level
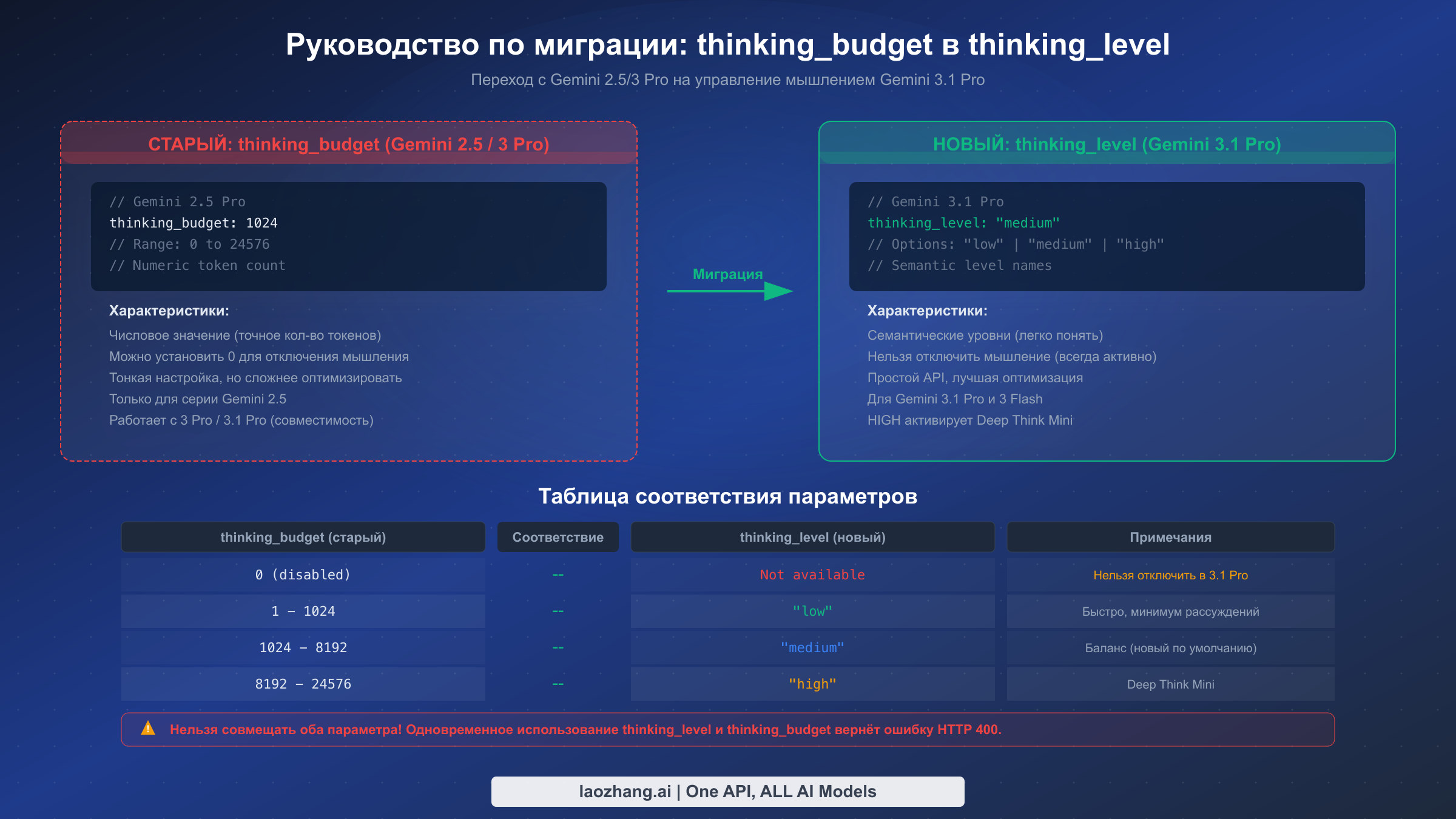
Если вы использовали Gemini 2.5 Pro с параметром thinking_budget, миграция на систему thinking_level в Gemini 3.1 Pro требует понимания как концептуального сдвига, так и практических изменений в реализации. Параметр thinking_budget, используемый в серии Gemini 2.5, принимал числовое значение (от 0 до 24 576), задающее максимальное количество токенов мышления, которое модель могла использовать. Новый параметр thinking_level заменяет его тремя семантическими уровнями — "low", "medium" и "high" — которые абстрагируют подсчёт токенов и позволяют модели самой оптимизировать глубину рассуждений в рамках каждого уровня.
Самое важное, что нужно знать о миграции — одновременное использование обоих параметров невозможно. Отправка запроса с настроенными одновременно thinking_budget и thinking_level вернёт ошибку HTTP 400. Это значит, что миграция представляет собой полный переход, а не постепенную трансформацию — нужно обновить код для использования одного параметра, а не обоих. Хорошая новость в том, что thinking_budget по-прежнему работает с Gemini 3.1 Pro как функция обратной совместимости, поэтому немедленная миграция не обязательна. Однако документация Google настоятельно рекомендует переход на thinking_level, и будущие модели могут полностью отказаться от thinking_budget.
Вот практическое соответствие для ваших существующих конфигураций. Если thinking_budget был установлен в 0 (мышление отключено), прямого эквивалента в новой системе нет — Gemini 3.1 Pro не может полностью отключить мышление. Ближайший вариант — "low", который минимизирует токены мышления, но не устраняет их полностью. Для бюджетов в диапазоне 1-1 024 (лёгкое рассуждение) используйте "low". Для бюджетов в диапазоне 1 024-8 192 (умеренное рассуждение) используйте "medium". Для бюджетов выше 8 192 (глубокое рассуждение) используйте "high". Если вы использовали максимальный бюджет 24 576, "high" с Deep Think Mini, скорее всего, превзойдёт этот уровень возможностей рассуждения.
python# ДО: Gemini 2.5 Pro с thinking_budget response = client.models.generate_content( model="gemini-2.5-pro-preview", contents="Solve this equation...", config={ "thinking_config": { "thinking_budget": 8192 } } ) # ПОСЛЕ: Gemini 3.1 Pro с thinking_level response = client.models.generate_content( model="gemini-3.1-pro-preview", contents="Solve this equation...", config={ "thinking_config": { "thinking_level": "medium" # соответствует бюджету ~8192 } } )
Дополнительный момент при миграции: если ваше приложение динамически настраивало thinking_budget в зависимости от сложности задачи (например, устанавливая разные числовые значения для разных типов промптов), вы можете сохранить эту логику, сопоставив ваши диапазоны бюджета с тремя уровнями мышления. Подход с семантическими уровнями на самом деле проще в поддержке, поскольку вы выбираете из трёх чётких вариантов вместо настройки числового параметра, и модель лучше оптимизирует своё рассуждение в рамках каждого уровня, чем разработчики обычно достигают при ручной установке бюджета токенов.
Типичные ошибки и устранение проблем
Даже опытные разработчики сталкиваются с проблемами при работе с уровнями мышления Gemini 3.1 Pro, зачастую из-за допущений, перенесённых из более ранних моделей, или неполной документации. Понимание наиболее распространённых подводных камней и их решений может сэкономить часы отладки и предотвратить непредвиденные расходы.
Ловушка HIGH по умолчанию — самая дорогостоящая ошибка, которую совершают разработчики. Когда вы отправляете запрос к Gemini 3.1 Pro без указания thinking_level, API по умолчанию использует HIGH — самый дорогой вариант, активирующий Deep Think Mini для каждого запроса. Многие разработчики обнаруживают это только при получении первого ежемесячного счёта, невольно потратив в 3-5 раз больше необходимого на простые задачи. Решение простое: всегда включайте thinking_level в вашу конфигурацию, даже если для конкретного запроса вам нужен HIGH. Явное указание в коде предотвращает случайные значения по умолчанию и делает ваши намерения по затратам понятными другим разработчикам, читающим код.
Ошибка конфликта параметров возникает, когда разработчики пытаются использовать одновременно thinking_budget и thinking_level в одном запросе, что приводит к ответу HTTP 400. Обычно это случается при миграции, когда старый конфигурационный код не полностью очищен, или когда разные части кодовой базы устанавливают разные параметры, которые объединяются перед вызовом API. Решение — провести аудит всей цепочки формирования запроса и убедиться, что присутствует только один параметр мышления. Хорошая защитная практика — добавить валидацию перед отправкой запросов, которая явно проверяет наличие и удаляет конфликтующий параметр.
python# Защитный помощник конфигурации def build_thinking_config(level="medium"): """Создаёт конфигурацию мышления только с thinking_level (без конфликта бюджета).""" config = { "thinking_config": { "thinking_level": level } } # Явно предотвращаем установку thinking_budget if "thinking_budget" in config.get("thinking_config", {}): del config["thinking_config"]["thinking_budget"] return config
Путаница с доступностью MEDIUM подводит разработчиков, которые пытаются использовать "medium" с Gemini 3 Pro (не 3.1 Pro). Уровень MEDIUM доступен только на Gemini 3.1 Pro (gemini-3.1-pro-preview) и Gemini 3 Flash — Gemini 3 Pro поддерживает только LOW и HIGH. Аналогично, уровень "minimal" является эксклюзивным для Gemini 3 Flash и недоступен ни на одной из моделей Pro. Если вы получаете неожиданные ошибки, проверьте, что идентификатор вашей модели соответствует уровням мышления, которые вы пытаетесь использовать. Рекомендации по обработке лимитов частоты запросов, которые могут усугубить эти проблемы, смотрите в нашем руководстве по лимитам Gemini API.
Сюрприз с лимитом выходных токенов подстерегает разработчиков, когда Deep Think Mini генерирует обширные цепочки мышления, потребляющие значительную часть лимита в 64K выходных токенов. Если ваш промпт требует и глубокого рассуждения (много токенов мышления), и длинного ответа, вы можете столкнуться с усечением. Отслеживайте usage_metadata в ответах API для контроля потребления токенов мышления и подумайте, может ли MEDIUM обеспечить достаточное качество для вашего сценария при меньших затратах токенов.
Как извлечь максимум из уровней мышления Gemini 3.1 Pro
Трёхуровневая система мышления Gemini 3.1 Pro представляет собой существенный шаг вперёд в предоставлении разработчикам контроля над балансом стоимости и производительности в рассуждениях ИИ. Ключевые выводы этого руководства носят практический характер: всегда указывайте thinking_level явно, чтобы избежать дорогого режима HIGH по умолчанию; используйте MEDIUM как рабочую лошадку для 80% задач; зарезервируйте HIGH и Deep Think Mini для задач, действительно требующих глубокой цепочки рассуждений; и внедрите стратегию маршрутизации 80/20 для оптимизации затрат в масштабе.
Для начинающих команд мы рекомендуем поэтапный подход. Во-первых, проведите аудит существующих API-вызовов, чтобы понять структуру ваших задач — какой процент составляет простое извлечение данных, а какой — сложные рассуждения? Во-вторых, реализуйте классификатор запросов, направляющий каждый вызов на соответствующий уровень мышления. В-третьих, отслеживайте usage_metadata для контроля фактического потребления токенов мышления и уточняйте правила маршрутизации на основе реальных данных. В-четвёртых, исследуйте Batch API (скидка 50%) и кэширование контекста ($0,50/1M токенов для кэшированного ввода) для дополнительной экономии. Наконец, если вы всё ещё используете Gemini 2.5 Pro с thinking_budget, планируйте миграцию на thinking_level уже сейчас — подход с семантическими уровнями проще, удобнее в поддержке и рассчитан на будущее Gemini API.
Одна лишь стратегия 80/20 может снизить ваши ежемесячные затраты на Gemini API с $3 500 до менее чем $900 для типичной продуктовой нагрузки из 10 000 ежедневных запросов. В сочетании с пакетной обработкой и кэшированием контекста достижимо общее снижение затрат на 80% и более без ущерба качеству результатов на задачах, которые действительно важны. Модель с Deep Think Mini на уровне HIGH достигает впечатляющих результатов бенчмарков — 77,1% на ARC-AGI-2, 94,3% на GPQA Diamond, 80,6% на SWE-Bench Verified — но настоящее инженерное мастерство заключается в понимании, когда вам нужна эта мощность, а когда MEDIUM или LOW справятся с задачей не хуже.