Claude Fable 5 и GLM-5.2 сегодня нельзя рассматривать как две одинаково доступные опции. На момент проверки 14 июня 2026 года Anthropic сообщает, что доступ к Fable/Mythos отключен, поэтому Fable 5 является веткой “подождать и перепроверить”. Z.AI документирует GLM-5.2 внутри GLM Coding Plan, поэтому GLM-5.2 является веткой, которую можно первой проверить на маленькой задаче для coding agent.
Это не означает, что GLM-5.2 автоматически заменяет Fable. Доступность определяет порядок тестирования, но не качество по умолчанию. Чтобы принять инженерное решение, нужен один и тот же репозиторий, один issue, один prompt, одинаковые инструменты, одинаковый acceptance test, а также логи, diff, latency, quota usage, retries и rollback cost.
| Ветка | Когда использовать | Первый шаг | Стоп-правило |
|---|---|---|---|
| Ждать Fable 5 | Нужны именно поведение, политика, биллинг или fallback Anthropic. | Проверить statement по доступу, model docs и pricing docs Anthropic. | Не оценивать Fable 5 на live task, если ветку нельзя запустить. |
| Smoke-test GLM-5.2 | Нужна проверяемая route для coding agent уже сейчас. | Настроить документированную route Z.AI и запустить ограниченную задачу. | Не считать заменой без diff, tests, logs, latency, quota и rollback. |
| Сохранить dual-run packet | Рассматривается смена default model или production route. | Сохранить тот же task packet и повторить его, если Fable вернется. | Нет победителя без same-task evidence от обеих runnable branches. |
Заметка об источниках: launch, access, model и pricing материалы Anthropic, а также документация Z.AI GLM Coding Plan были проверены 14 июня 2026 года. Доступность, route, quota и цены являются волатильными; перед публикацией новой рекомендации или сменой default route нужно снова открыть официальные источники.
Короткий ответ
Практический ответ начинается не с рейтинга, а с route. Fable 5 не подходит как стартовая live-ветка для coding-agent evaluation, пока официальный доступ отключен. Его спецификации важны: large context, output ceiling, model ID, pricing row. Но спецификация, которую нельзя запустить, не дает честного результата на той же задаче.
GLM-5.2 стоит проверить первым, если вопрос звучит так: “что я могу запустить сейчас?” Документация Z.AI указывает GLM-5.2 в GLM Coding Plan и показывает tool route, которую можно проверить. Это достаточное основание для smoke test. Но это не основание писать, что GLM-5.2 лучше Fable, Opus, Kimi или вашего текущего baseline.
Слово “первым” здесь критично. GLM-5.2 может быть первой runnable branch, не становясь универсальным ответом. Отдельно держите availability, route configuration, cost unit, patch quality, review load and rollback risk.
Что показывает локальная выдача
В русской выдаче Google виден AI Overview, который быстро превращает тему в сравнение сильных сторон: Fable якобы лидирует в агентном кодинге, GLM-5.2 выделяется open weights и контекстом. Такая структура опасна, потому что она звучит как готовый verdict и легко скрывает главный факт: одну из веток нельзя честно прогнать в live test прямо сейчас.
Русскоязычная страница должна исправить этот перекос. Читателю важнее понять, где заканчивается публичная спецификация и где начинается воспроизводимая проверка. Reddit, Habr, SourceForge, видео и автоматические summary могут подсказать темы, но не могут заменить вашу собственную same-task проверку.
Поэтому локальная версия начинается с доступности и стоп-правила. Если Fable нельзя запустить, не ставьте ему score. Если GLM-5.2 можно запустить, не объявляйте его заменой без evidence packet.
Что изменилось на этой неделе
Anthropic объявила Claude Fable 5 9 июня 2026 года. Затем отдельное access statement сообщило, что доступ к Fable 5 и Mythos 5 отключается для всех клиентов. Это меняет всю форму сравнения: обычная таблица “модель против модели” вводит в заблуждение, если не начинает с runnable status.
На стороне Z.AI evidence layer другой. GLM-5.2 в этой статье рассматривается не как абстрактная строка каталога, а как документированная route в GLM Coding Plan. Документация указывает модель и показывает provider path для coding tools. Это говорит, что можно сделать проверку. Это не говорит, что каждая обертка, каждый старый рейтинг и каждый benchmark row одинаково применимы.

Правильный порядок: проверить статус Fable, проверить route GLM-5.2, затем сравнивать work. Если Fable нельзя запустить, не оценивайте его на той же задаче. Если GLM-5.2 можно запустить, сначала соберите logs, diff, tests, latency and quota.
Таблица официального контракта
| Контрактный пункт | Claude Fable 5 | GLM-5.2 |
|---|---|---|
| Кто владеет фактом | Anthropic | Z.AI |
| Статус на 2026-06-14 | Недоступен по statement Fable/Mythos access. | Документирован внутри GLM Coding Plan. |
| Метка модели | claude-fable-5 | glm-5.2 и glm-5.2[1m] |
| Context/output boundary | Документы Anthropic указывают 1M context и 128k output, но это не делает ветку runnable. | Документы Z.AI показывают 1M-context class для coding route. |
| Cost unit | Цена Anthropic за миллион токенов. | Quota units и multipliers внутри Coding Plan. |
| Что это дает coding agent | Сильная спецификация, но wait-and-recheck. | Candidate для bounded smoke test. |
| Чего это не доказывает | Что Fable можно тестировать сегодня. | Что GLM-5.2 лучше или является replacement. |
Такая таблица нужна не для crown, а для ownership. Anthropic владеет доступом, model ID, pricing и limit claims по Fable. Z.AI владеет route claims по GLM-5.2. Ваш repository владеет финальным фактом: прошел ли patch acceptance bar.
Если реальный workflow идет через Claude Code, держите route ownership отдельно. Provider path, base URL and credential ownership — это конфигурация, а не доказательство качества модели. Смежные настройки описаны в Claude Code API configuration, а различие ключа и подписки — в Claude Code API key vs subscription billing.
Сначала нормализуйте cost unit
Fable и GLM-5.2 показывают разные единицы. У Fable есть official token pricing row. У GLM-5.2 в данной evidence set видна Coding Plan route с quota и multiplier logic. Нельзя просто сравнить одну price cell с другой и получить production decision.
Coding-agent task расходует не только tokens. Он расходует tool calls, long context, retries, reviewer time, CI time and rollback time. Дешевая неудачная попытка может быть дороже дорогой попытки, которая сразу дает acceptable patch.
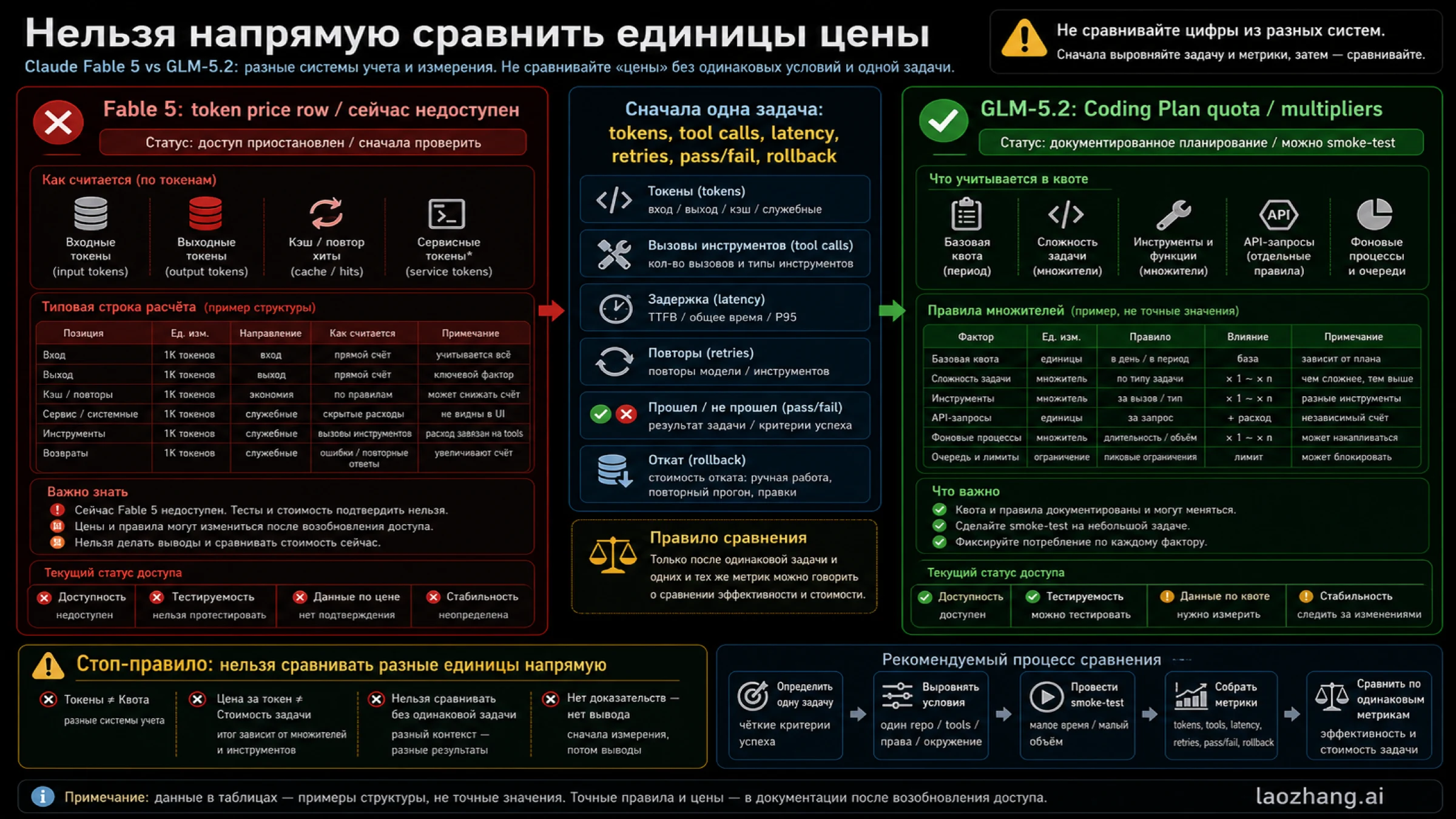
| Метрика | Почему нужна |
|---|---|
| Input tokens | Длинный контекст репозитория может доминировать стоимость. |
| Output tokens | Patch explanation и logs могут быть дорогой частью. |
| Tool calls | Coding route может иметь throttling или quota behavior вокруг tools. |
| Latency | Дешевая route, которая блокирует review, не всегда дешевле. |
| Pass/fail | Failed cheap attempts превращаются в human recovery. |
| Retries | Растят quota burn и reviewer fatigue. |
| Rollback | Настоящая цена плохого patch часто вне invoice. |
Если вы не можете заполнить эти строки, честный вывод звучит так: units are not comparable yet. Это лучше, чем уверенная, но не воспроизводимая price conclusion.
Когда GLM-5.2 стоит проверить первым
GLM-5.2 стоит запускать первым для ограниченных задач: воспроизводимый bug, small migration, исправление теста, документационный patch, локальный refactor с clear acceptance. Задача должна быть достаточно реальной, чтобы показать поведение агента, и достаточно маленькой, чтобы review был быстрым.
Не начинайте с GLM-5.2, если вам нужно именно Anthropic behavior: policy, billing, fallback semantics, Claude-native route. Не делайте GLM-5.2 единственной веткой для security-sensitive, compliance-heavy или expensive-to-debug tasks.
Хорошая проверка имеет узкий scope. Не просите модель одновременно менять architecture, tests, deployment scripts and docs. Один запуск должен отвечать на один вопрос: может ли route понять issue, создать reviewable diff, пройти указанные tests и оставить понятный failure reason.
Не меняйте default model сейчас
Default model — это production decision. Недоступность Fable говорит, какую ветку нельзя честно мерить сегодня. Она не говорит, что любая runnable branch готова стать default. Даже удачный GLM-5.2 run доказывает только одну задачу, одну route и один acceptance bar.
Перед сменой default требуйте одинаковый task packet, одинаковую acceptance bar, одинаковый evidence packet, rollback plan and decision threshold. Если команда заранее не знает, какой result заставляет вернуться назад, значит смена еще не готова.
| Требование | Pass condition |
|---|---|
| Same task packet | Один repo, issue, prompt, file set, tools and time budget. |
| Same acceptance bar | Одинаковые tests, review checklist и failure budget. |
| Same evidence packet | Logs, diff, test output, latency, quota, failure reason. |
| Same rollback plan | Понятно, как revert, isolate или rerun. |
| Same decision threshold | До запуска решено, что значит good enough. |
Если Fable access вернется, повторите сохраненный packet. Не сравнивайте новый GLM task со старым впечатлением от Fable. Не сравнивайте Fable spec с GLM execution log.
Checklist одной задачи
Самый чистый test должен быть маленьким. Выберите один repo, один issue и один acceptance test. Он должен быть meaningful, но reviewable.

- Зафиксируйте prompt, branch, files, allowed tools and time budget.
- Запустите GLM-5.2 через документированную Z.AI route.
- Сохраните model label, provider route, diff, logs, tests, latency, quota note and failure reason.
- Оценивайте только observable outcomes: patch quality, tests pass, retry count, review load and rollback effort.
- Если Fable вернулся, выполните тот же packet без изменения task.
- Когда обе ветки runnable, сравнивайте accepted-task cost и failure mode, а не catalog hype.
Полезный вывод звучит так: “GLM-5.2 прошел наш bounded migration task с одним retry и приемлемой quota burn”. Неполезный вывод: “GLM-5.2 победил, потому что Fable был suspended”.
Часто задаваемые вопросы
Claude Fable 5 доступен сейчас?
Согласно access statement Anthropic, проверенному 14 июня 2026 года, доступ к Fable 5 и Mythos 5 отключен для всех клиентов. Перед любой проверкой откройте актуальные страницы Anthropic.
GLM-5.2 лучше Claude Fable 5?
Это нельзя честно утверждать, пока Fable не runnable. GLM-5.2 можно тестировать первым, но “лучше” требует same task, same inputs and observable outcomes from both branches.
Какую model string искать?
Для Fable смотрите claude-fable-5 и текущий access status Anthropic. Для GLM смотрите glm-5.2 и glm-5.2[1m] в документации Z.AI Coding Plan.
GLM-5.2 дешевле Fable?
Не в простой строке. Fable использует per-token price row, GLM-5.2 использует quota и multipliers. Сравнивайте после измерения tokens, tools, retries, latency, pass/fail and rollback на одной задаче.
Можно ли заменить Fable на GLM-5.2?
Используйте GLM-5.2 как live test route, а не automatic replacement. Если Fable вернется, повторите тот же packet. Default меняется только после evidence from same task.
Итог
Честное сравнение спрашивает не “какое имя сильнее”, а “какую route можно проверить без самообмана”. На 14 июня 2026 года Fable 5 имеет official contract, но access suspended. GLM-5.2 имеет documented Z.AI Coding Plan route, которую можно проверить маленькой задачей.
Начните с этого: recheck Fable, verify GLM route, normalize units, run one same task, save evidence, and only then discuss defaults.