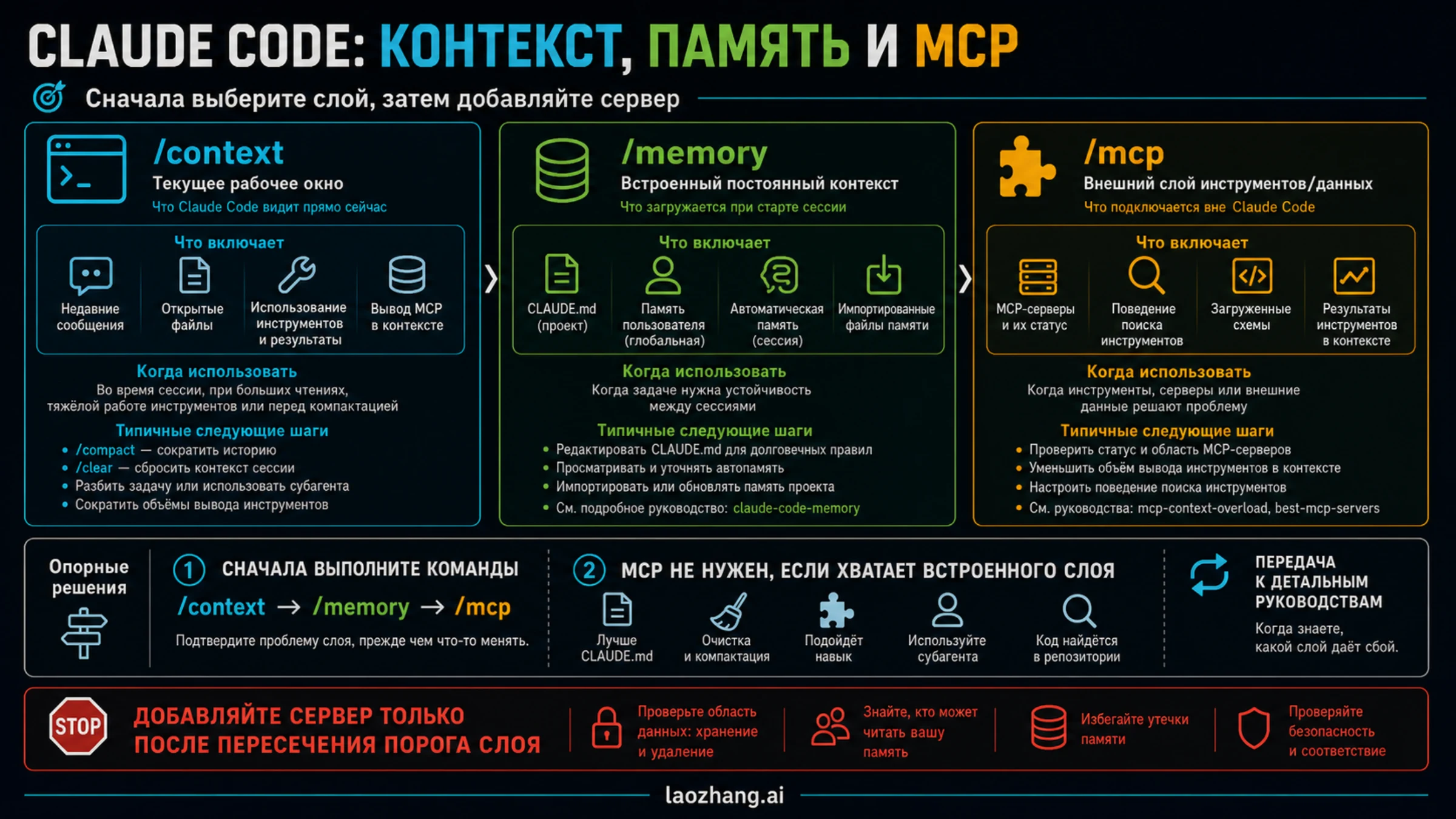
Контекст, память и MCP в Claude Code решают разные задачи. Если агент "забыл" правило, начал тянуть старую ветку решения или стал хуже отвечать после длинной сессии, не начинайте с установки memory MCP. Сначала докажите, где именно произошел сбой: в текущем рабочем окне, во встроенной памяти, которая загружается при старте, или во внешнем инструментальном слое.
Быстрый порядок такой:
| Симптом | Первая команда | Что она доказывает | Меньшее исправление до сервера |
|---|---|---|---|
| Ответы плывут в длинной сессии | /context | Текущее окно забито разговором, файлами, tool results или MCP output | Сжать на границе, очистить остатки, разбить задачу, уменьшить вывод |
| Новая сессия не помнит правило проекта | /memory | Какие CLAUDE.md, imports или auto memory реально загружены | Исправить durable memory в нужной области |
| Внешние инструменты шумят или подключены неправильно | /mcp | Какие MCP servers активны и какой внешний слой вмешивается | Отключить шумный server, сузить scope, исправить подключение |
| Один и тот же процесс приходится объяснять заново | /skills или субагент | Нужен метод, а не память | Вынести процедуру в skill или изолировать большое чтение |
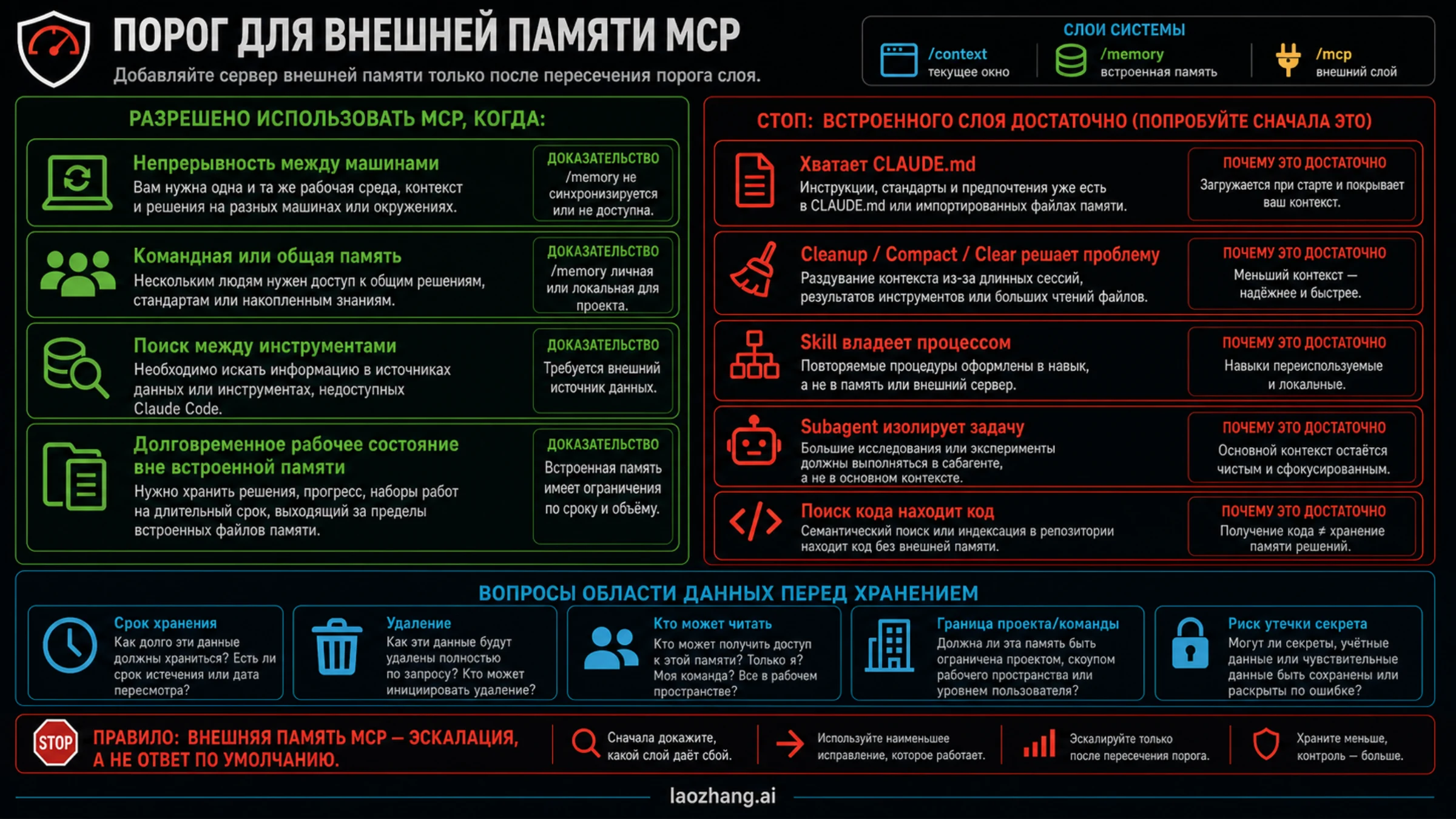
Стоп-правило простое: если чистый CLAUDE.md, /compact, /clear, skill, субагент или поиск по коду решает проблему, внешний memory MCP пока не нужен. Он становится оправданным только тогда, когда требуется непрерывность между машинами, общий командный recall, поиск состояния между инструментами или динамическая рабочая память, которая слишком велика для встроенных файлов. До подключения проверьте хранение, удаление, доступ и риск попадания секретов.
Быстрый ответ: какой слой сломался?

Непрерывность Claude Code лучше понимать как набор слоев. Активная беседа - это рабочее окно, которое Claude видит сейчас. Встроенная память - это проектный или пользовательский контекст, загруженный при старте. MCP - внешний слой доступа к инструментам, данным и действиям. Skills хранят повторяемый метод. Субагенты изолируют большие исследования, которые не должны загрязнять главную нить.
В русской выдаче легко увидеть обратный уклон: много материалов обещают "persistent memory" и memory MCP как прямое решение. Это полезный сигнал спроса, но плохой порядок диагностики. Если проблема вызвана раздуванием текущего окна, новый server добавит еще больше tool definitions, retrieval results и решений о доверии. Поэтому первый вопрос не "какой memory MCP поставить", а "какой слой уже должен был решить этот симптом".
| Паттерн сбоя | Вероятный владелец | Поверхность проверки | Правильный следующий шаг |
|---|---|---|---|
| Длинная сессия держит старые варианты | Current context window | /context | Сжать, очистить, разделить поток или сократить outputs |
| Правило проекта не появляется в новой сессии | Built-in memory | /memory | Исправить CLAUDE.md, import или user memory |
| MCP tools дублируются, шумят или падают | MCP | /mcp | Сузить server, отключить лишнее, проверить transport |
| Повторяемый workflow каждый раз объясняется заново | Skill | /skills | Описать процедуру в skill, а не в длинной памяти |
| Нужно прочитать много боковых файлов | Subagent | Handoff summary | Изолировать чтение и вернуть только вывод |
| Нужна память между машинами, tools или командой | External memory MCP | Server policy и пробный пакет | Оценить privacy, retention, deletion и rollback |
Этот порядок защищает от архитектурного перебора. Если маршрут доказал, что проблема во встроенной памяти, внешний server не нужен. Если маршрут доказал, что MCP layer уже шумит, сначала чините server scope. Если проблема в процедуре, лучше skill. Только после этого memory MCP становится инженерным вариантом, а не реакцией на слово "память".
Что доказывает /context
/context показывает текущее рабочее окно. В этом окне находятся инструкции, прочитанные файлы, ответы модели, результаты tools, сведения о выбранных tools, сжатые summaries и загруженная memory. Поэтому команда полезна, когда качество ухудшается внутри одной длинной сессии. Она не доказывает, что вам нужна долговременная память; она доказывает, сколько активного материала уже приходится держать модели.
Сигналы context-problem обычно выглядят так: Claude ссылается на старый план, который уже отменен; после чтения большого лога ответы стали хуже; MCP server вернул огромный JSON; после compaction исчезли важные границы; в одном чате смешаны research, implementation, review и publish. В этих случаях внешний memory server может ухудшить ситуацию, потому что retrieval добавляет еще один поток данных в уже тесное окно.
Практический порядок исправления: сначала сжимайте на естественной границе, где уже есть стабильное решение. Затем переносите побочные исследования в отдельную сессию или субагента. Потом требуйте от tools короткие summaries, handles, фильтры, pagination и конкретные поля. Если окно уже несет слишком много ошибочных веток, лучше начать чистую сессию с теми же project memories, чем пытаться лечить все новой памятью.
За что отвечает встроенная память
Встроенная память отвечает за устойчивые инструкции и фон, который должен появляться в новой сессии без повторного объяснения. Это правила репозитория, naming conventions, команды тестов, ограничения релиза, пользовательские предпочтения, короткие ссылки на более длинные документы. Она загружается в context window, поэтому тоже должна быть компактной.
Хорошая memory не является архивом всех разговоров. Не кладите туда длинные логи, полные research trails, большие таблицы, список каждого принятого решения и сырые transcripts. Такие данные лучше хранить в файлах, issues, docs или внешней базе, а в memory оставить короткую ссылку и правило использования. Иначе вы сами создадите раздутое стартовое окно, которое будет мешать каждой новой задаче.
/memory нужен, когда Claude в новой сессии не знает то, что должен был знать. Команда помогает отличить три случая: правило не сохранено; правило сохранено в неправильной области; правило загружено, но текущий контекст настолько перегружен, что модель плохо им пользуется. Первые два случая чинятся memory files. Третий возвращает вас к /context. Ни один из них не требует автоматической установки memory MCP.
За что отвечает MCP
MCP отвечает за внешний доступ. Это tools, services, databases, issue trackers, search, browsers, внутренние платформы и действия, которые Claude Code не видит по умолчанию. Memory-like storage тоже может быть MCP server, но тогда он наследует все риски внешнего слоя: transport, permissions, tool descriptions, output size, retention и deletion.
/mcp нужен, когда сам внешний слой выглядит подозрительно. Server disconnected? Слишком много tools? Одинаковые функции выставлены несколькими servers? Tool description длиннее, чем польза от tool? Каждый вызов возвращает сырой большой payload? Сначала исправьте это. Если добавить memory MCP поверх шумного MCP layer, вы получите больше состояний, которые надо проверять, а не больше надежности.
Важно не путать code retrieval, project memory и durable working state. Code retrieval отвечает на вопрос "где файл или символ". Project memory отвечает "какое правило проекта должно быть видно в начале". External memory MCP нужен для cross-session или cross-tool recall, который не помещается в короткую built-in memory. Когда эти границы размыты, команда начинает хранить кодовые факты как память и быстро получает устаревший слой.
Меньшие исправления до внешней памяти
Многие проблемы непрерывности являются не memory-problem, а workflow-problem. Повторяемая процедура должна жить в skill. Skill может содержать инструкции, references, checklists и примеры, но не обязан полностью загружаться в каждую сессию. Memory напоминает, что важно; skill объясняет, как выполнять работу. Это дешевле и управляемее, чем превращать весь процесс в долгосрочную память.
Большие боковые исследования лучше отдавать субагенту или отдельной нити. Главному чату нужны выводы, пути к evidence, остаточный риск и next action, а не вся история чтения. Для codebase audit, логов, локализации, статьи или миграции такая изоляция часто дает больше качества, чем любой memory server, потому что главная сессия перестает тащить лишние ветки.
Также проверьте cleanup commands. /compact полезен, когда решение уже найдено и нужно оставить только сжатый state. /clear полезен, когда разговор загрязнен настолько, что проще начать заново с проектной memory. Если эти команды восстанавливают качество, вы доказали, что проблема в current context management, а не во внешнем recall.
Когда внешний memory MCP оправдан
External memory MCP имеет смысл после реального порога. Первый порог - cross-machine continuity: вы работаете на нескольких машинах или IDE, и локальный built-in memory не синхронизирует состояние. Второй - shared team recall: команда хочет, чтобы одни и те же project facts читались несколькими агентами и людьми. Третий - cross-tool retrieval: решения, issues, docs и рабочие события находятся в разных системах, и нужен общий searchable layer. Четвертый - динамическое состояние слишком большое или слишком часто меняется для CLAUDE.md.
Даже после порога надо ответить на data questions. Где server хранит данные? Кто может читать? Как удалить запись? Что происходит с secrets, client data и raw transcripts? Хранится текст, summary, embedding или user-written fact? Есть ли audit trail и rollback? Если ответов нет, memory MCP не должен становиться default workflow.
Лучший способ внедрения - ограниченный пилот. Выберите один project scope, разрешенные факты, запрещенные факты, deletion path и критерий успеха. После нескольких реальных задач сравните: стало ли меньше повторных объяснений, меньше context bloat, яснее retrieval, меньше ошибок? Если доказательства нет, server остается экспериментом, а не частью базовой архитектуры.
Матрица исправления и пакет доказательств

Перед изменением архитектуры соберите пакет доказательств:
| Что зафиксировать | Почему это важно | Как используется |
|---|---|---|
| Симптом и момент появления | Отличает new-session failure от long-session drift | Выбирает /memory или /context как первый ход |
| /context output | Показывает pressure и loaded categories | Решает, нужна ли очистка или split |
| /memory output | Показывает, какие files реально загружены | Решает, куда писать правило |
| /mcp status | Показывает active servers и внешний layer | Решает, нужно ли отключать или чинить server |
| Large tool results | Находит источник context bloat | Требует summary, pagination или handles |
| Compaction boundary | Объясняет, что должно пережить сжатие | Предотвращает потерю решений |
| Data policy | Проверяет retention и permissions | Решает, допустим ли memory MCP |
Пакет должен доказать, почему меньший fix не подходит. Если evidence указывает на memory, редактируйте CLAUDE.md. Если указывает на context, уменьшайте active material. Если на MCP, сужайте server. Если на procedure, пишите skill. Если на external recall, проверяйте data policy и только тогда выбирайте memory MCP.
Часто задаваемые вопросы
Контекст Claude Code и память - одно и то же?
Нет. Контекст - текущее рабочее окно. Встроенная память - устойчивые project или user facts, которые загружаются в это окно при старте. Memory может стать частью context, но сам context не является долговременным хранилищем. Поэтому длинная сессия может "забывать" не потому, что нет memory MCP, а потому что окно перегружено.
Нужно ли сразу ставить Claude Code memory MCP?
Нет, не первым шагом. Запустите /context, /memory и /mcp, затем примените меньший fix. Memory MCP оправдан, когда встроенная память, cleanup, skill, subagent и code retrieval не решают cross-session или cross-tool recall.
Tool Search убирает context cost у MCP?
Нет. Tool Search может уменьшить первоначальную загрузку tool definitions, но использованные tools и их results все равно становятся материалом для рассуждения. Нужны compact descriptions, bounded outputs, filters, summaries и handles.
Правила проекта хранить в CLAUDE.md или MCP server?
Обычно в CLAUDE.md или imported built-in memory. MCP нужен для внешнего доступа и действий. Если короткое правило требует tool call при каждом использовании, вы сделали систему более хрупкой, чем локальная project memory.
Когда использовать skill вместо memory?
Используйте skill для повторяемого метода: release checklist, review flow, локализация, data cleaning, incident triage. Используйте memory для фактов и предпочтений, которые должны быть видны при старте.
Поиск по коду - это память?
Нет. Code retrieval помогает найти файлы и символы. Memory помогает помнить решения и правила. Внешний memory MCP нужен, когда требуется durable recall за пределами этих двух задач.