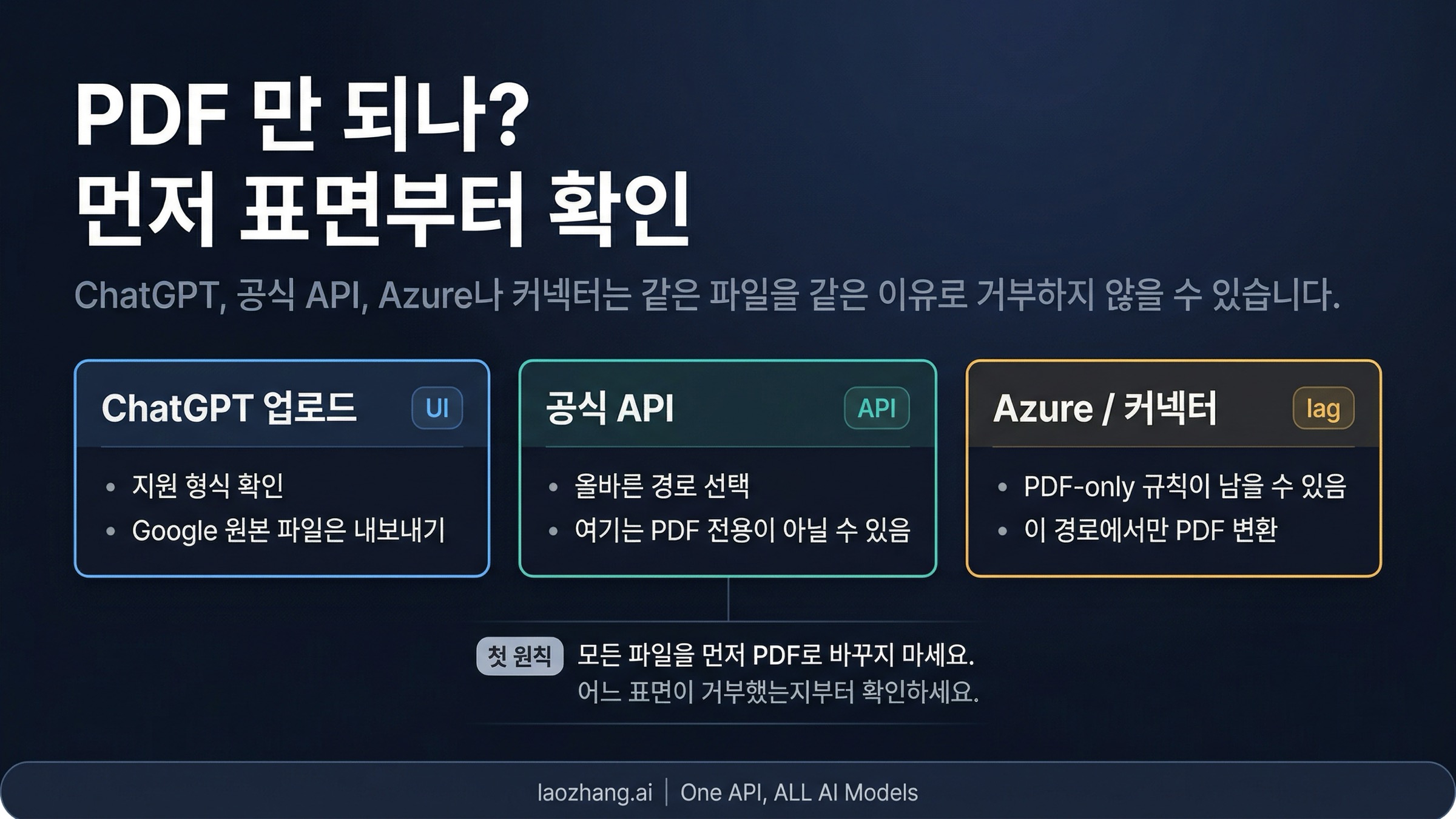
OpenAI에서 "지원되지 않는 파일 형식"이 뜨고 "PDF로 다시 시도"하라는 문구가 보여도, 바로 모든 파일을 PDF로 바꾸지는 마세요. ChatGPT 업로드, 현재 공식 OpenAI API, Azure나 다른 connector 경로는 아직 서로 다른 규칙으로 파일을 받는 경우가 있으므로, 가장 먼저 해야 할 일은 확장자를 바꾸는 것이 아니라 어느 입력 창구에서 거절이 일어났는지 확인하는 것입니다.
실패가 ChatGPT에서 났다면 먼저 Google Docs, Sheets, Slides 같은 네이티브 파일을 export했는지 확인해야 합니다. 현재 공식 API에서 난 오류라면 input_file 또는 file_search 중 어떤 경로가 실제 작업에 맞는지부터 봐야 합니다. Azure나 connector에서 난 오류라면 그쪽에서는 PDF가 여전히 가장 빠른 해법일 수 있습니다. 가장 작은 수정 후에는 반드시 같은 경로에서 다시 확인하세요. 같은 경로가 분명히 지원되는 파일을 계속 거절한다면, 그것은 "OpenAI는 이제 PDF만 받는다"는 증거가 아니라 경로를 잘못 골랐거나 그 입력 창구가 아직 최신 규칙을 따라오지 못하고 있다는 뜻입니다.
30초 분기표

확장자만 보지 말고, 먼저 거절이 난 입력 창구를 기준으로 나눕니다.
| 어디서 거절되나 | 가장 가능성 높은 원인 | 가장 안전한 첫 행동 | 같은 경로에서 확인하는 법 | 판단을 더 올려야 하는 시점 |
|---|---|---|---|---|
| ChatGPT 업로드 | 네이티브 Google 파일, 직접 업로드 비지원 형식, 또는 PDF가 더 적합한 레이아웃 중심 문서 | 먼저 Google Docs / Sheets / Slides에서 export한다. 그 외에는 명확히 지원되는 형식으로 다시 올리거나, 레이아웃이 중요하면 PDF로 시도한다 | 같은 ChatGPT 업로드 흐름이 파일을 다시 받아들인다 | export한 지원 형식도 계속 실패한다 |
| 공식 OpenAI API | 잘못된 파일 경로, input_file에 대한 기대 오류, 또는 실제로는 file_search가 맞는 작업 | 현재 문서와 맞는 경로로 바꾸고, 모든 문서 작업을 하나의 방식으로 밀어 넣지 않는다 | 같은 요청 경로가 파일을 받고 결과도 작업에 맞게 나온다 | 문서에 맞춘 경로에서도 지원 파일을 거절한다 |
| Azure 또는 connector | 그 입력 창구가 아직 PDF 전용처럼 동작한다 | 그곳에서는 PDF로 export / convert하거나, 작업을 현재 공식 OpenAI 경로로 옮긴다 | 같은 입력 창구가 파일을 받아들인다 | PDF도 실패하거나 해당 동작이 공식 문서와 계속 다르다 |
이 글에서 사용한 OpenAI 공식 help pages와 developer docs는 2026년 4월 8일에 다시 확인했습니다. 결론은 단순합니다. 현재 공식 OpenAI가 전부 PDF-only인 것은 아닙니다. 다만 같은 오류 문구가 일부 인접 경로에서는 여전히 나오기 때문에, 인용구 자체보다 분기표가 더 중요합니다.
ChatGPT에서 거절되는 경우
이 가지는 API 도구 문제보다 업로드 지원 문제에 가깝습니다. OpenAI의 현재 supported file types 문서와 File Uploads FAQ는 PDF만이 아니라 여러 문서, 프레젠테이션, 스프레드시트, 텍스트, 코드 파일을 설명합니다. 즉 DOCX, PPTX, TXT, MD, CSV, JSON, XLSX 같은 형식은 ChatGPT 쪽에서 곧바로 "PDF로 바꿔야 한다"로 이해할 일이 아닙니다.
여기서 가장 흔한 숨은 분기는 일반 Office 파일이 아니라 Google Docs, Sheets, Slides의 네이티브 클라우드 파일입니다. .gdoc, .gsheet, .gslides는 직접 업로드 형식이 아닙니다. 파일이 Google 네이티브라면 먼저 export한 뒤 다시 시도해야 합니다. PDF가 여기서 여전히 유용한 이유도 같습니다. ChatGPT가 무조건 PDF만 받기 때문이 아니라, 실제 작업이 순수 텍스트가 아니라 차트, 레이아웃, 삽입 이미지, 시각적 관계 보존에 있기 때문입니다.
많은 사람이 이 지점에서 시간을 잃습니다. 정확한 오류 문구를 검색하고 "PDF로 변환하라"는 뭉뚱그린 조언을 본 뒤, 거절이 Google 네이티브 파일 때문인지, 아직 지원 형식으로 export하지 않았기 때문인지, 아니면 렌더링된 결과를 유지하는 편이 더 중요한 작업인지 묻지 않습니다. OpenAI help 문서 자체의 말은 그 신화보다 훨씬 좁습니다. 물어야 할 질문은 "ChatGPT가 파일을 지원하나?"가 아니라 "내가 필요한 내용을 보존할 수 있는 올바른 export 형식을 올리고 있나?"입니다.
이 가지의 검증은 짧아도 됩니다. 실패했던 바로 그 ChatGPT 업로드 화면에 export한 파일을 다시 넣어 보세요. 다른 앱이나 wrapper에서 성공했다고 해서 원래 문제를 해결한 것은 아닐 수 있습니다. 같은 ChatGPT 경로가 분명히 지원되는 export 파일을 계속 거절한다면, 더 이상 단순 export 분기라고 보면 안 됩니다.
만약 실제 문제는 unsupported file type가 아니라 사용량 상한이었다면, 이 글을 다른 독자 과제로 늘리지 마세요. 그 경우에는 현재 플랜의 업로드 한도를 따로 확인하는 편이 맞습니다.
공식 OpenAI API에서 거절되는 경우
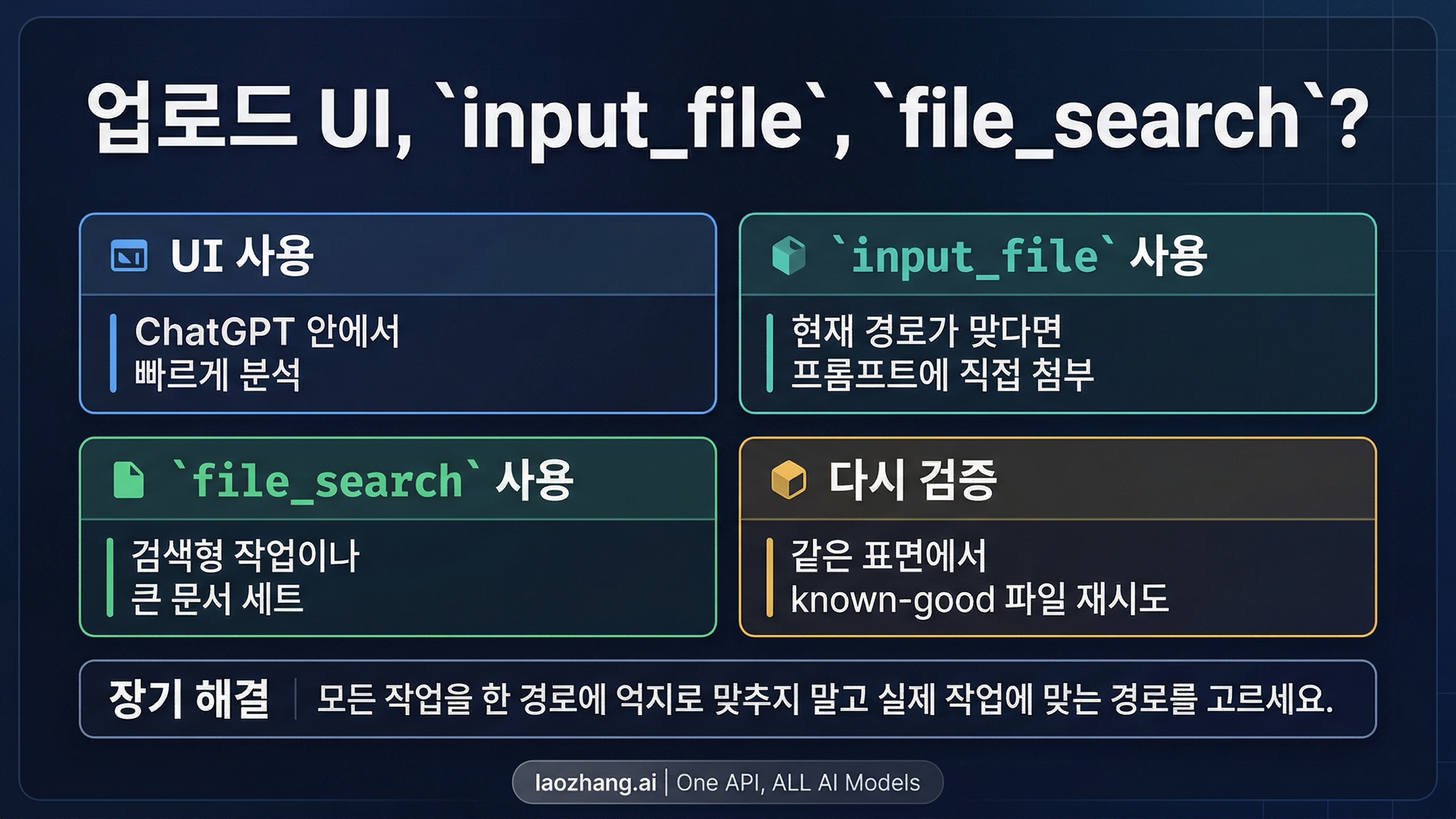
오래된 PDF-only 조언에 가장 많이 흔들리는 곳이 바로 이 가지입니다. OpenAI의 현재 PDF files and other document formats는 Responses API의 input_file 경로가 PDF뿐 아니라 text files, code files, rich documents, presentations, spreadsheets도 받는다고 밝힙니다. 이것은 오래된 snippets나 포럼 답변이 암시하는 것보다 훨씬 넓은 규칙입니다.
하지만 받아들여진다는 것과 작업에 맞는다는 것은 다릅니다. 같은 문서는 non-PDF 파일 안의 embedded images와 charts는 추출되지 않는다고도 말합니다. 따라서 DOCX나 PPTX가 API에 들어가더라도, 실제 작업이 diagram, slide 관계, annotation, mixed layout을 모델에 보여 주는 것이라면 최선의 입력이 아닐 수 있습니다. 받아들여지는 파일과 가장 알맞은 파일은 같은 뜻이 아닙니다.
이 가지를 가장 빠르게 정리하는 방법은 경로를 실제 작업과 연결하는 것입니다.
| 실제 작업이... | 더 나은 경로 | 이유 |
|---|---|---|
| 한 문서를 prompt context 안에 바로 넣는 것 | input_file | 별도 검색 구성을 하지 않고 바로 읽힐 수 있다 |
| 여러 문서를 검색하거나 나중에 인용하는 것 | file_search | 현재 file search 문서는 많은 non-PDF 형식을 지원하고 검색 작업에 더 잘 맞는다 |
| 차트, 도표, 삽입 visual, 복합 레이아웃을 보존하는 것 | 시각적 보존에 대해 가장 분명한 현재 규칙이 PDF 쪽에 있다 |
실무에서 공식 API가 이 오류를 낼 때는 대개 세 가지 중 하나입니다. 파일 경로가 작업과 맞지 않다. 형식은 받아들여지지만 실제 작업은 시각적 보존 때문에 PDF를 요구한다. 또는 요청이 wrapper, connector, 오래된 예제 위를 지나가며 current API contract를 좁게 읽고 있다. 어느 경우도 "OpenAI가 이제 PDF만 받는다"는 뜻은 아닙니다.
올바른 경로로 바꾼 뒤에도 API 요청이 계속 실패한다면, 이제 볼 것은 파일 층 밖입니다. project scope, key type, wrapper-specific routing이 여전히 올바른 파일 형태의 요청을 깨뜨릴 수 있습니다. 그 가지에 들어갔다면 다음 읽을 것은 OpenAI API Key 와 Organization ID 가이드입니다. 그 글은 credential 문제와 scope selection 문제를 분리해서 설명합니다.
Azure 또는 connector에서 거절되는 경우
이 가지는 "PDF로 다시 시도"가 그 입력 창구에 한해서는 문자 그대로 맞을 수 있는 유일한 곳입니다. 문제는 많은 글이 여기서 멈추고, 부분적으로만 맞는 동작을 OpenAI 전체의 진실처럼 올려 버린다는 점입니다.
이번 조사에서도 그런 차이를 보여 주는 현재 증거를 찾았습니다. 비교적 최근의 Microsoft Q&A 스레드는 Azure OpenAI file-search workflow에서 supported format .pdf complaint가 여전히 나타나는 모습을 보여 줍니다. 동시에 현재 공식 OpenAI 문서는 일부 first-party 경로에서 더 넓은 문서 지원을 설명합니다. connector 커뮤니티에서도 패턴은 같습니다. 사용자는 실제 오류를 보는데, 답변은 "PDF로 바꾸세요"에서 끝나고 connector 규칙과 current first-party 규칙의 차이는 설명되지 않습니다.
운영적으로 이 구분은 중요합니다. 지금 그 낡은 입력 창구에 남아 있어야 한다면, PDF export나 conversion은 가장 작은 올바른 수정이 될 수 있습니다. 경로를 바꿀 수 있다면, 장기적으로는 current official OpenAI path로 옮기는 편이 더 나을 수 있습니다. 하면 안 되는 일은 Azure나 특정 automation module의 동작을 OpenAI 모든 업로드 경로의 전역 진실처럼 취급하는 것입니다.
여기서는 경계도 분명해야 합니다. 같은 Azure 또는 connector 경로가 깨끗한 PDF export 뒤에도 계속 실패한다면, 더 이상 단순한 형식 선택 문제가 아닙니다. 그때는 구현이 따라오지 못했거나, 모듈 동작이 다르거나, 문서상 지원과 실제 운영 동작이 어긋나 있을 가능성을 의심해야 합니다.
그래도 PDF가 더 좋은 형식인 때

PDF는 지금도 자주 정답입니다. 그래서 오래된 조언이 완전히 사라지지 않았습니다. 문제는 PDF를 쓰는 것이 아니라 PDF를 게으른 기본 설명으로 쓰는 것입니다.
현재 OpenAI help guidance도 document-heavy ChatGPT workflow에서는 diagrams, embedded visuals, 복잡한 layout을 더 안정적으로 보존하려면 PDF가 강한 형식이라고 봅니다. 현재 API 문서도 developer 관점에서 같은 점을 더 선명하게 말합니다. non-PDF file은 받아들여질 수 있지만, non-PDF 안의 embedded images와 charts는 추출되지 않습니다. 앞 문장은 "업로드가 통과하나"를, 뒤 문장은 "내가 필요한 형태로 내용이 남나"를 답합니다. 이 둘을 분리하는 순간 이 주제는 훨씬 단순해집니다.
문서가 시각적으로 밀도가 높거나, Google Docs / Sheets / Slides에서 export한 rendered result를 유지해야 하거나, 같은 입력 창구가 이미 PDF를 더 잘 다룬다는 것이 드러났다면 PDF를 선택하세요. 웹 어딘가의 OpenAI 관련 화면 하나가 그런 오류를 보여 줬다고 해서 모든 파일 작업의 기본 답을 PDF로 바꾸면 안 됩니다.
DOCX가 지원되어도 chart-heavy report에는 약할 수 있습니다. PPTX가 받아들여져도 텍스트와 그래픽의 관계를 모델이 읽어야 하는 deck에는 좋지 않을 수 있습니다. 받아들여지는지는 "통과하나"를, PDF 선호는 "원하는 방식으로 살아남나"를 답합니다.
수정 후 검증과 장기 경로 선택
파일이 다시 받아들여졌다고 해서 거기서 멈추지 마세요. 문제가 났던 같은 입력 창구에서 짧게 검증해야 합니다.
- 가장 작은 수정 후 반드시 같은 경로에서 다시 시도한다. 다른 길로 옮겨 원래 문제를 가리지 않는다.
- 파일이 받아들여지기만 하는지 말고, 읽기, 검색, 시각 정보 보존 같은 실제 작업에도 쓸 수 있는지 확인한다.
- 파일이 Google Docs, Sheets, Slides에서 왔다면 실제로 통했던 export 형식을 남겨 둔다.
- 문제가 다른 OpenAI 경로에서만 사라진다면, 원래 입력 창구는 그 가지만의 지연으로 취급하고 "OpenAI는 PDF-only"라는 이야기로 되돌아가지 않는다.
장기 경로는 반복하는 작업을 따라야 합니다. ChatGPT에서 일반 문서를 자주 올린다면 현재 help docs가 이미 지원하는 export 형식을 그대로 쓰면 됩니다. programmatic retrieval이 반복된다면 one-shot upload를 억지로 쓰지 말고 file_search 중심으로 바꾸는 편이 낫습니다. chart나 layout fidelity가 핵심이라면 그 workflow에서는 PDF를 기본으로 정하는 것이 재발을 줄입니다.
FAQ
OpenAI는 지금 PDF만 지원하나?
아닙니다. 2026년 4월 8일 기준으로 다시 확인한 current official OpenAI help pages와 developer docs는 ChatGPT uploads와 일부 first-party API routes에서 여러 non-PDF file formats를 설명합니다. PDF-only처럼 보이는 오류는 일부 Azure나 connector path에서는 여전히 실제일 수 있지만, 그것은 그 입력 창구만의 동작입니다.
ChatGPT에서는 어떤 파일 형식이 원래 지원되나?
현재 OpenAI help pages는 일반적인 문서, 프레젠테이션, 스프레드시트, 텍스트, 코드 형식을 설명합니다. 자주 숨은 원인이 되는 것은 DOCX나 PPTX 자체보다, 먼저 export가 필요한 Google 네이티브 파일입니다.
왜 DOCX나 PPTX가 어떤 OpenAI 경로에서는 되고 다른 경로에서는 안 되나?
"OpenAI"가 하나의 업로드 규칙이 아니기 때문입니다. ChatGPT uploads, 현재 공식 API, Azure OpenAI, third-party connectors는 지금도 서로 다른 규칙을 적용하거나 업데이트 속도가 다를 수 있습니다.
언제 input_file 대신 file_search를 골라야 하나?
한 문서를 한 번 prompt에 넣는 일이 아니라, 여러 문서를 검색하고 저장된 파일에서 인용하는 retrieval 작업이라면 file_search가 더 맞습니다.
언제 PDF가 진짜로 더 좋은 답이 되나?
layout, charts, diagrams, embedded visuals를 보존해야 할 때, Google Docs / Sheets / Slides에서 export한 rendered result가 필요할 때, 또는 사용하는 입력 창구가 지금도 PDF를 분명히 선호할 때입니다.
기억할 작업 규칙
가장 빠르고 깔끔한 수정은 "모든 파일을 PDF로 바꾸기"가 아닙니다. 먼저 거절한 입력 창구를 찾고, 그곳에 맞는 가장 작은 file 또는 경로 수정을 적용하고, 같은 자리에서 검증한 뒤, 그다음에야 PDF를 장기 기본 형식으로 삼을지 결정한다. 이 순서가 가장 덜 돌아갑니다.