
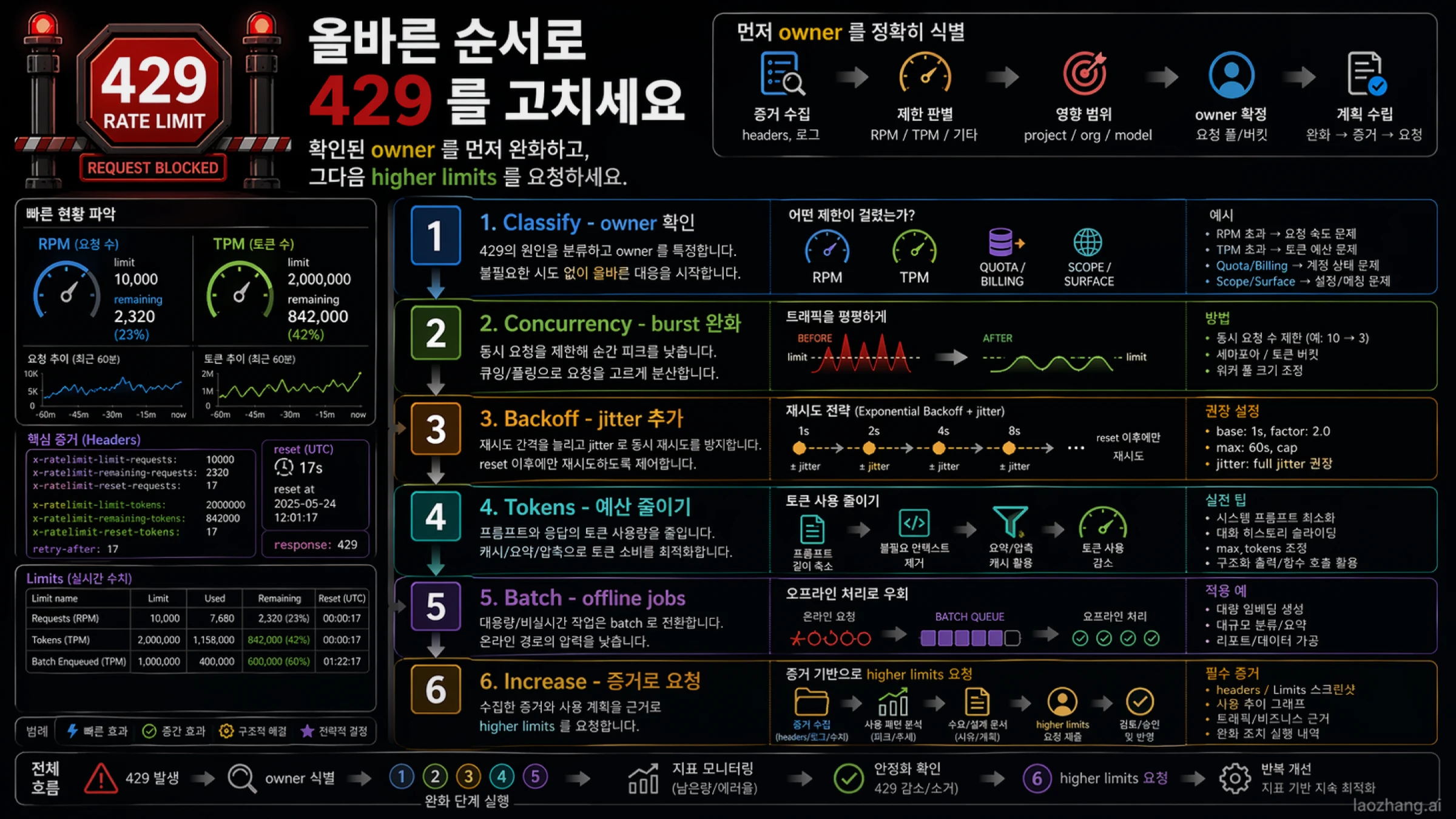
OpenAI API 429는 하나의 재시도 에러가 아닙니다. request rate 에 먼저 걸린 것일 수도 있고, token rate 가 먼저 바닥난 것일 수도 있습니다. quota 나 billing 상태가 owner 인 경우도 있고, project나 model scope 가 어긋난 경우도 있습니다. 심지어 ChatGPT 나 Codex 같은 다른 product surface 의 제한을 Platform API 429로 오해한 경우도 있습니다. 그래서 가장 먼저 해야 할 일은 retry loop 를 늘리는 것이 아니라 owner 를 가르는 것입니다.
한국어 안내문과 경험담을 보면 결제 부족 이야기, backoff 코드, quota 사례가 한 원인처럼 묶여 나오기 쉽습니다. 그러다 보니 429를 "sleep 을 넣는다", "크레딧을 충전한다", "key 를 바꾼다" 같은 단일 해법으로 받아들이기 쉽습니다. 하지만 실제로 빠른 해결은 response headers 와 Limits 페이지를 보고 지금의 route 를 멈춘 owner 가 누구인지 확인한 뒤, 가장 작은 수정만 적용하는 데서 시작합니다.
외워 둘 운영 규칙은 네 단계면 충분합니다. owner 를 본다. reset 을 본다. 가장 작은 수정으로 들어간다. route 와 traffic shape 가 안정되었을 때만 증액을 고민한다.
TL;DR
| 질문 | 짧은 답 |
|---|---|
| OpenAI API 429는 보통 무엇을 뜻하나 | request, token, quota, billing, scope, reset-window 중 하나의 경계에 닿았다는 뜻이다. |
| 가장 먼저 볼 것은 무엇인가 | x-ratelimit headers 와 계정의 Limits 페이지다. |
| 기술적으로 흔한 owner 는 무엇인가 | burst, 과한 concurrency, 너무 큰 token budget 이다. |
| 코드 밖에서 흔한 owner 는 무엇인가 | quota 부족, billing 상태, trial 경계, wrong surface 다. |
| 증액 전에 해야 할 일은 무엇인가 | concurrency 를 낮추고, backoff 와 jitter 를 넣고, token output 을 줄이고, Batch API 나 queue 로 빼는 것이다. |
| 먼저 하면 안 되는 것은 무엇인가 | blind retry, key rotation, ChatGPT/Codex 플랜 업그레이드를 API 해결책으로 보는 것이다. |
retry loop 보다 먼저 owner 를 본다
OpenAI의 공개 문서를 차분히 읽으면 429가 단일 문제가 아니라는 점이 분명해집니다. 계정에는 live limits 가 있고, usage tier 는 headroom 에 영향을 주며, response headers 는 남은 양과 reset 시점을 알려주고, mitigation 은 brute-force resend 가 아니라 bounded backoff 에서 시작합니다.
그래서 첫 질문은 "OpenAI API 제한이 몇이냐"가 아니라 "이번 request 를 멈춘 owner 가 누구냐"입니다. request-rate owner 와 token-rate owner 는 같은 429처럼 보여도 수정 방향이 다릅니다. quota 나 billing owner 라면 backoff 를 예쁘게 넣어도 근본이 안 바뀝니다. scope 가 틀렸다면 credits 를 추가해도 route 는 바로잡히지 않습니다.
운영 순서를 다시 쓰면 이렇습니다.
- owner 를 확인한다.
- reset signal 을 확인한다.
- 가장 작은 안전한 수정을 적용한다.
- route 와 traffic shape 가 안정된 뒤에만 higher limits 를 논의한다.
project, organization, key scope 가 헷갈린다면 OpenAI API Key 와 Organization ID 로 가는 편이 맞습니다. 실제로는 Codex 나 ChatGPT 사용창을 보고 있다면 OpenAI Codex usage limits 와 Codex API key vs subscription 쪽이 올바른 surface 입니다.
OpenAI rate limits 가 실제로 재는 것
OpenAI는 rate limit 를 하나의 고정 숫자로 설명하지 않습니다. 운영에서 중요한 층은 다음과 같습니다.
- Requests per minute: 짧은 시간에 보내는 request 수
- Tokens per minute: prompt 와 output 을 합친 token volume
- Usage tier: 계정 headroom 에 영향을 주는 층
- Live account limits: 실제 ceiling 은 Limits 페이지에 있음
- Reset signals: 언제 창이 다시 열리는지 알려주는 header
이 구조 때문에 오래된 글의 "OpenAI는 분당 몇 회" 표를 그대로 믿는 것은 위험합니다. 공개 문서는 개념과 mitigation 을 설명하지만, 지금 내 계정에 실제로 적용되는 ceiling 은 Limits 페이지가 가지고 있습니다.
request pressure 와 token pressure 도 반드시 분리해서 읽어야 합니다. RPM 문제는 burst, tight loop, 과한 concurrency 에서 많이 오고, TPM 문제는 긴 history, 큰 system prompt, 과한 output upper bound 에서 많이 옵니다. 둘을 섞어 보면 원인보다 약한 수정만 반복하게 됩니다.
평균값이 안전해 보여도 quantized window 에서 먼저 막힐 수 있다는 점도 중요합니다. 분당 평균이 맞다고 해서 순간적인 traffic shape 까지 안전한 것은 아닙니다.
코드를 바꾸기 전에 response 를 읽는다
Cookbook 와 rate-limit guide 는 같은 습관을 권합니다. 먼저 response 를 읽으라는 것입니다. 실패한 retry 도 budget 을 계속 쓰기 때문에, 아무것도 보지 않고 반복 재시도하면 incident 가 길어집니다.
우선 볼 headers 는 다음입니다.
- x-ratelimit-limit-requests
- x-ratelimit-remaining-requests
- x-ratelimit-reset-requests
- x-ratelimit-limit-tokens
- x-ratelimit-remaining-tokens
- x-ratelimit-reset-tokens

이 신호만으로도 첫 분기를 꽤 줄일 수 있습니다.
| 신호 | 보통 의미하는 것 | 첫 행동 |
|---|---|---|
| remaining-requests 가 거의 0 | request frequency 나 concurrency 가 너무 높음 | parallelism 을 낮추고 burst 를 평탄화 |
| remaining-tokens 가 거의 0 | prompt 와 output 이 너무 큼 | token budget 을 줄임 |
| reset 이 짧음 | route 자체는 대체로 맞고 창이 닫혀 있음 | reset 이후 jitter 를 섞어 재시도 |
| Limits 페이지의 headroom 이 낮음 | account 나 route ceiling 이 좁음 | 먼저 최적화하고 필요 시 증액 판단 |
| headers 는 멀쩡한데 실패 | scope, billing, wrapper, endpoint 가능성 | project, org, model, surface 확인 |
status, error body, endpoint, model, project context, x-ratelimit 값을 남겨 두면 나중에 incident evidence 로 비교할 수 있습니다.
가장 작은 분류 코드는 이렇게 쓸 수 있습니다.
tsconst resetRequests = res.headers.get("x-ratelimit-reset-requests"); const resetTokens = res.headers.get("x-ratelimit-reset-tokens"); const remainingRequests = res.headers.get("x-ratelimit-remaining-requests"); const remainingTokens = res.headers.get("x-ratelimit-remaining-tokens"); const owner = remainingRequests === "0" ? "requests" : remainingTokens === "0" ? "tokens" : "unknown"; // request 와 token 이 함께 걸리면 더 늦은 reset 을 기준으로 잡는다.
중요한 것은 코드의 우아함보다 잘못된 branch 로 가지 않는 것입니다.
429를 owner 별로 나눈다
1. Request-rate owner
가장 흔한 것은 burst 입니다. request 수, concurrency, retry loop 가 현재 route 의 허용치를 넘고 있습니다. billing 보다 traffic shape 를 먼저 고쳐야 하는 경우입니다.
2. Token-rate owner
request 수가 많지 않아도 각 request 가 무거우면 TPM 이 먼저 막힙니다. 긴 history, 큰 system prompt, 과도한 output upper bound 가 대표적입니다.
3. Quota 또는 billing owner
이 owner 에서는 backoff 가 근본 해결이 아닙니다. 사용 가능한 quota 가 없거나 billing 이 unhealthy 하다면 account state 를 봐야 합니다. credits 나 trial 경계가 문제라면 OpenAI API free trial 이 맞는 sibling 입니다.
4. Project, organization, model scope owner
request 는 syntax 상 맞아도 route 가 다르면 limit behavior 가 달라집니다. 환경을 복사해 왔는데 scope 가 달랐던 경우는 생각보다 흔합니다.
5. Wrong product surface owner
ChatGPT, Codex, wrapper 의 제한과 Platform API throughput 은 같은 계약이 아닙니다. ChatGPT 업그레이드가 API 429를 자동으로 고쳐 주지 않고, Codex 사용창도 API throughput 그 자체가 아닙니다.
가장 작은 수정부터 traffic 을 다듬는다
owner 를 알게 되면 작은 수정부터 시작합니다. OpenAI 공개 가이드가 일관되게 추천하는 것은 bounded backoff with jitter 입니다.
일반적인 순서는 다음과 같습니다.
- route 가 맞다면 먼저 reset 을 기다린다.
- burst 가 원인이면 concurrency 를 내린다.
- exponential backoff 와 jitter 를 넣는다.
- token pressure 라면 prompt 와 output 을 줄인다.
- 실시간이 아닌 작업은 queue 나 Batch API 로 보낸다.
- 그래도 필요할 때만 higher limits 를 요청한다.
retry path 는 실패할수록 조용해져야 합니다. 최소 패턴은 다음과 같습니다.
tsconst base = 500; // ms const max = 15000; for (let attempt = 0; attempt < 6; attempt += 1) { const wait = Math.min(max, base * 2 ** attempt); const jitter = Math.random() * 0.25 * wait; await sleep(wait + jitter); }
TPM 문제에서는 token trimming 이 가장 싼 수정이 되는 경우가 많습니다. max output 을 현실에 맞게 줄이고, history 를 짧게 하고, 불필요한 context 를 제거합니다. 실시간이 아니어도 되는 작업이면 Batch API 나 queue 로 옮기는 편이 더 낫습니다.
증액은 안정된 증거 뒤에만 한다
많은 팀이 higher limits 를 너무 빨리 생각합니다. 그러면 구조 문제를 가리게 됩니다.
증액을 고민해도 되는 조건은 적어도 다음과 같습니다.
- route 가 맞다.
- billing 이 건강하다.
- owner 가 분명하다.
- retry 가 이미 bounded 상태다.
- prompt 와 output budget 이 합리적이다.
- 그래도 sustained capacity 가 부족하다.
이 단계에서 usage tier 나 limit increase request 가 의미를 가집니다. 요청 전에 model, endpoint, request/token pressure, reset 패턴, concurrency profile, 이미 한 최적화, Batch API 로도 부족한 이유를 정리해 두는 것이 좋습니다.
Stop rules
한국어 운영 문맥에서도 특히 자주 나오는 오수정은 다음과 같습니다.

- key rotation 을 먼저 하지 않는다. 같은 account 와 route 가 owner 면 효과가 약하다.
- throughput 을 보지 않고 credits 를 추가하지 않는다. quota 나 billing 에는 도움이 될 수 있어도 RPM/TPM 을 자동으로 올리지는 않는다.
- ChatGPT 나 Codex 플랜 업그레이드를 API 해결책으로 보지 않는다.
- 오래된 표의 정확한 숫자를 current truth 로 쓰지 않는다.
- blind retry 를 하지 않는다. 실패한 retry 도 budget 을 사용한다.
다음 표로 판단하면 흔들림이 줄어듭니다.
| owner | 다음 행동 |
|---|---|
| Request burst | parallelism 을 낮추고 jitter 를 넣는다 |
| Token pressure | prompt 와 output size 를 줄인다 |
| 짧은 reset window | 기다렸다가 안전하게 다시 시도한다 |
| Billing / quota | account state 를 고친다 |
| Project / model scope | route 와 scope 를 바로잡는다 |
| API 밖 surface | 그 surface 전용 runbook 으로 이동한다 |
FAQ
OpenAI API 429는 무엇을 뜻하나요?
request, token, quota, billing, scope, reset-window 중 하나의 경계에 닿았다는 뜻입니다. 먼저 분류 문제로 다뤄야 합니다.
현재 정확한 limit 는 어디서 보나요?
계정의 Limits 페이지입니다. 공개 문서는 개념과 header 이름을 설명하고, live ceiling 은 계정 화면이 가지고 있습니다.
credits 를 넣으면 throughput 도 늘어나나요?
아닙니다. credits 는 quota 또는 billing owner 인 경우에만 관련이 있습니다. request-rate 나 token-rate ceiling 을 자동으로 올려 주지 않습니다.
ChatGPT Plus, Pro, Codex 구독으로 Platform API 429가 해결되나요?
해결되지 않습니다. 소비자 제품과 Platform API 는 별도 계약입니다.
Batch API 는 언제 유효한가요?
작업이 즉시 응답일 필요가 없을 때입니다. 실시간이 아닌 작업을 synchronous path 에 남겨 두지 않는 편이 낫습니다.
higher limits 는 언제 요청해야 하나요?
route, billing, retry, token budget 이 정리되었는데도 sustained capacity 가 부족할 때입니다.
실무 결론
OpenAI API 429를 가장 빠르고 정직하게 고치는 방법은 retry 를 늘리는 것도, 무언가를 먼저 업그레이드하는 것도 아닙니다. owner 를 보고, reset 을 보고, 가장 작은 수정으로 들어가는 것입니다. request 문제면 burst 를 완화하고, token 문제면 payload 를 줄이고, billing 이나 quota 문제면 account state 를 고치고, scope 문제면 올바른 project, organization, model, endpoint 로 돌아가면 됩니다. 비실시간 작업은 synchronous path 밖으로 빼는 편이 더 안전합니다.