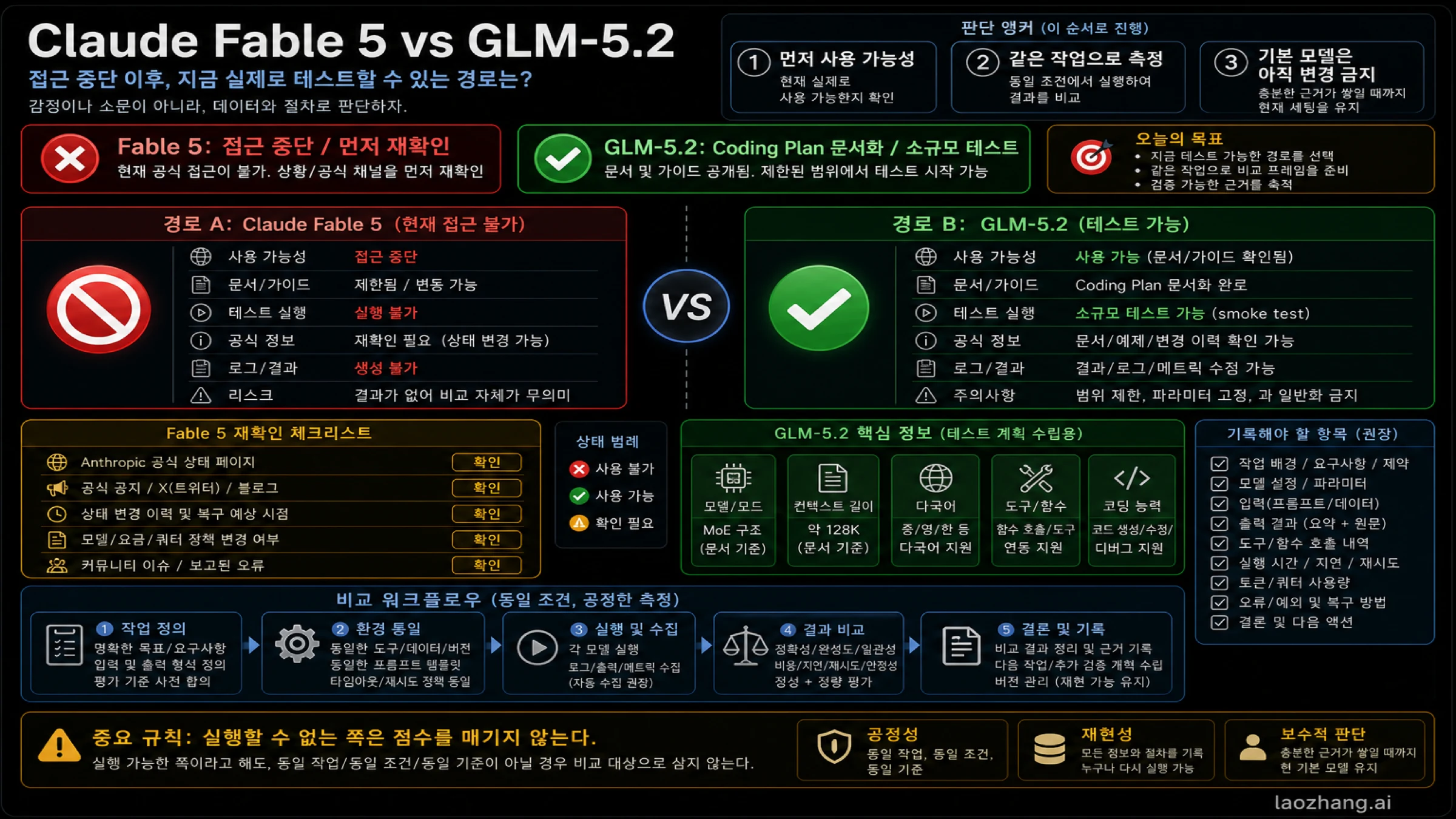
Claude Fable 5와 GLM-5.2는 지금 같은 조건으로 실행할 수 있는 두 선택지가 아닙니다. 2026년 6월 14일 확인한 공식 자료 기준으로 Anthropic은 Fable/Mythos 접근이 비활성화되었다고 설명합니다. 따라서 Fable 5는 기다렸다가 다시 확인해야 하는 분기입니다. 반면 Z.AI는 GLM Coding Plan 안에 GLM-5.2를 문서화하고 있어, GLM-5.2는 작은 Coding Agent 작업으로 먼저 검증할 수 있는 분기입니다.
그렇다고 GLM-5.2가 자동으로 Fable을 대체하는 것은 아닙니다. 접근 가능성은 테스트 순서를 정할 뿐, 기본 모델의 신뢰도를 정하지 않습니다. 결론을 내려면 같은 repo, 같은 issue, 같은 prompt, 같은 도구 권한, 같은 acceptance test, 그리고 diff, tests, logs, latency, quota, retries, rollback cost가 필요합니다.
| 경로 | 언제 쓰나 | 첫 행동 | 중단 규칙 |
|---|---|---|---|
| Fable 5 대기 | Anthropic 고유 동작, 정책, billing, fallback을 평가해야 할 때 | Anthropic access statement, model docs, pricing docs 재확인 | 실행할 수 없는 Fable에 live task 점수를 주지 않기 |
| GLM-5.2 소규모 테스트 | 이번 주 실제로 돌릴 Coding Agent 경로가 필요할 때 | Z.AI 문서화 경로에서 GLM-5.2 또는 GLM-5.2[1m] 확인 후 작은 작업 실행 | diff, tests, logs, latency, quota, rollback이 없으면 대체라고 부르지 않기 |
| 나중에 같은 작업 양쪽 실행 | 팀 기본 모델이나 production route 변경을 검토할 때 | 같은 task packet을 보존하고 Fable 복구 후 다시 실행 | 양쪽이 모두 runnable인 같은 작업 증거 없이는 승자를 정하지 않기 |
증거 메모: Anthropic의 Fable 발표, 접근 상태, 모델 및 가격 문서와 Z.AI GLM Coding Plan 문서는 2026년 6월 14일 확인했습니다. 접근 가능성, quota, routing, pricing은 바뀔 수 있으므로 새 추천이나 기본 route 변경 전에는 공식 문서를 다시 확인해야 합니다.
빠른 결론
실무적인 답은 모델 이름의 순위가 아니라 경로입니다. Fable 5는 접근이 중단된 동안 live Coding Agent 평가를 시작할 분기가 아닙니다. 큰 context, 높은 output ceiling, model ID, pricing row는 중요하지만, 지금 실행할 수 없다면 같은 작업 결과가 될 수 없습니다.
GLM-5.2는 “지금 무엇을 돌릴 수 있나”라는 질문에 대해 먼저 검증할 수 있는 분기입니다. Z.AI 문서는 GLM Coding Plan에서 GLM-5.2를 언급하고, tool route 안에서 사용할 수 있는 모델 라벨을 보여줍니다. 이는 smoke test를 시작할 이유가 됩니다. 그러나 Fable, Opus, Kimi 또는 현재 기본 모델보다 낫다는 증거는 아닙니다.
핵심은 “먼저 테스트한다”와 “이겼다”를 분리하는 것입니다. GLM-5.2는 첫 runnable branch일 수 있지만, 기본 모델이 되려면 같은 작업의 관찰 가능한 증거가 필요합니다.
한국어권 비교 담론에서 생기는 오해
한국어권의 설명은 AI 개요와 영상 콘텐츠를 통해 성능, 벤치마크, “역대 최강” 같은 표현을 앞에 두기 쉽습니다. 이런 설명은 모델 이름의 힘을 빠르게 보여주지만, 현재 Fable 접근 중단이라는 운영 경계가 약해질 수 있습니다.
실무에서는 순서를 바꿉니다. 먼저 현재 실행 가능한지 확인합니다. 그다음 그 경로가 어떤 공식 문서에 의해 소유되는지 봅니다. 마지막으로 같은 작업에서 patch, tests, logs, latency, quota, rollback을 측정합니다.
로컬 독자에게 필요한 것은 번역된 벤치마크 표가 아니라, 지금 안전하게 시도할 수 있는 경로와 아직 말하면 안 되는 결론의 경계입니다. 특히 “Fable이 강하다”와 “Fable을 지금 실행할 수 있다”는 다른 문장입니다.
이번 주에 바뀐 것은 접근 가능성입니다
Anthropic은 2026년 6월 9일 Claude Fable 5를 발표했습니다. 이후 별도의 Fable/Mythos access statement에서 Fable 5와 Mythos 5 접근을 모든 고객에 대해 비활성화해야 한다고 설명했습니다. 이 변화 때문에 단순한 “Fable vs GLM” 표는 먼저 현재 접근 상태를 보여주지 않으면 독자를 오도합니다.
Z.AI 쪽 증거는 다릅니다. 여기서 GLM-5.2는 일반적인 API 카탈로그 한 줄이 아니라 GLM Coding Plan의 문서화된 경로로 읽어야 합니다. 문서가 제공하는 route는 테스트를 시작할 근거가 되지만, 모든 wrapper, 모든 비교 사이트, 모든 영상 리뷰가 같은 사실을 갖는 것은 아닙니다.
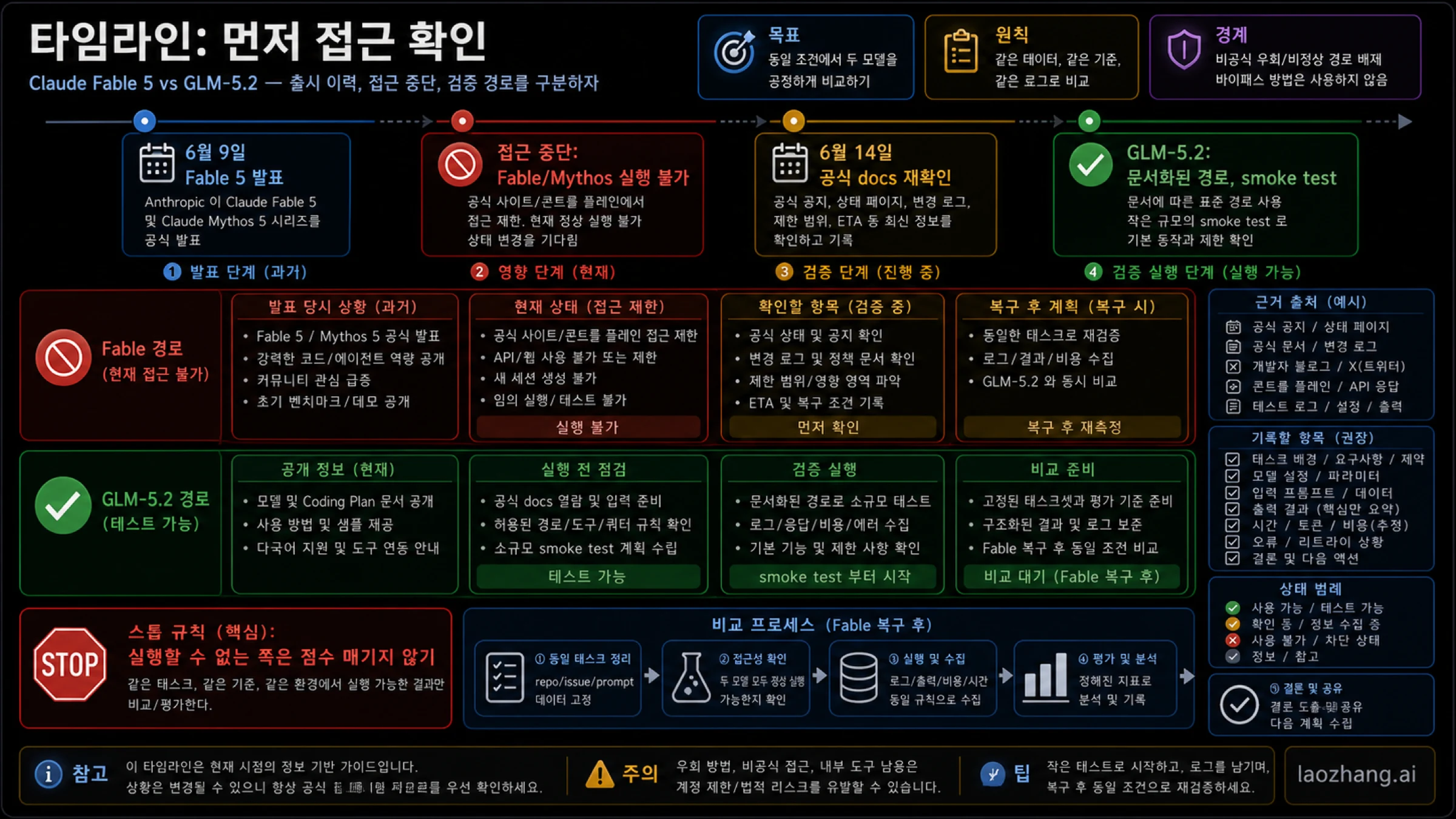
안전한 순서는 Fable 상태를 다시 확인하고, GLM-5.2 route를 확인한 뒤, 같은 작업을 측정하는 것입니다. Fable을 실행할 수 없다면 점수를 매기지 않습니다. GLM-5.2를 실행할 수 있다면 먼저 증거를 저장합니다.
공식 계약표
| 확인 항목 | Claude Fable 5 | GLM-5.2 |
|---|---|---|
| 먼저 볼 공식 소유자 | Anthropic | Z.AI |
| 2026-06-14 현재 상태 | Fable/Mythos access statement 기준 불가 | GLM Coding Plan 안에 문서화 |
| 볼 모델 라벨 | claude-fable-5 | glm-5.2 및 glm-5.2[1m] |
| context/output 경계 | Anthropic docs는 1M context와 128k output을 보여주지만 중단 상태를 해결하지 않음 | Z.AI coding route는 1M context class를 보여줌 |
| 비용 단위 | Anthropic의 token price row | Coding Plan quota와 multiplier |
| Coding Agent 의미 | 강한 specification이지만 wait-and-recheck | 작은 작업으로 검증할 후보 |
| 증명하지 않는 것 | 오늘 Fable을 실행할 수 있다는 것 | GLM-5.2가 더 좋거나 자동 대체라는 것 |
이 표는 우승자를 정하기 위한 것이 아니라 소유자를 나누기 위한 것입니다. Fable 접근, model ID, pricing은 Anthropic이 소유합니다. GLM-5.2 Coding Plan route는 Z.AI가 소유합니다. 당신의 repo에서 patch가 통과했는지는 당신의 tests, logs, review, rollback이 소유합니다.
Claude Code를 쓰는 경우 provider path나 base URL 설정도 분리해야 합니다. 경로 설정은 모델 품질 증거가 아닙니다. 관련 설정은 Claude Code API configuration, credential과 billing 경계는 Claude Code API key vs subscription billing을 참고하세요.
비용 단위를 먼저 맞추세요
Fable과 GLM-5.2는 보이는 비용 단위가 다릅니다. Fable에는 token price row가 있습니다. GLM-5.2는 여기서 Coding Plan quota와 multiplier 문맥으로 보입니다. 한쪽의 token price와 다른 쪽의 quota를 바로 비교하면 실제 비용을 놓치기 쉽습니다.
Coding Agent 비용은 tokens만이 아닙니다. tool calls, long context, retries, review time, CI time, rollback time이 모두 포함됩니다. 싸게 보이는 실패 시도는 사람이 여러 번 고치면 싸지 않습니다. 비싸 보이는 한 번의 성공이 실제로는 더 저렴할 수도 있습니다.
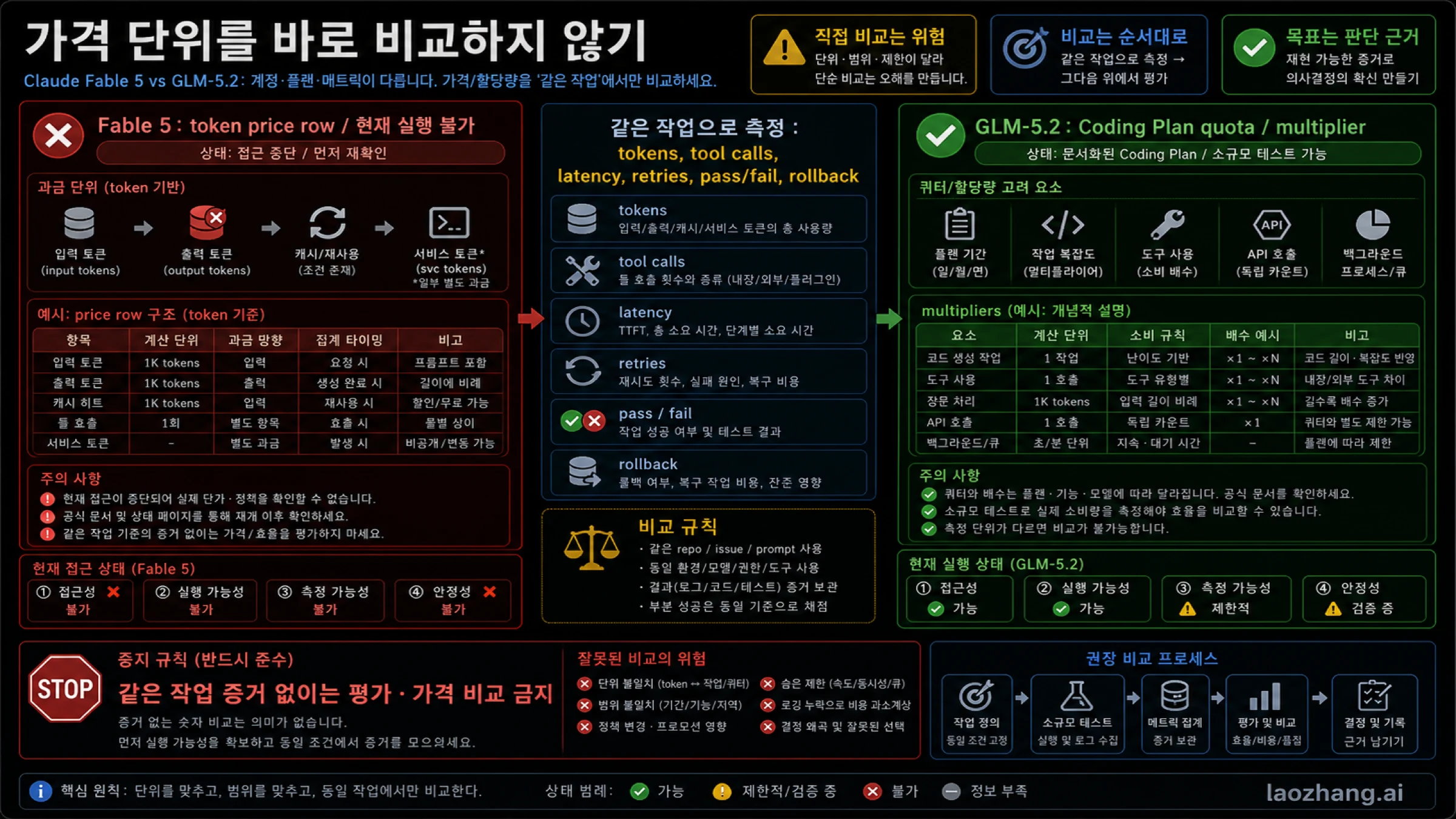
| 측정 항목 | 필요한 이유 |
|---|---|
| input tokens | repo 문맥이 길면 비용 또는 quota를 크게 사용합니다. |
| output tokens | patch 설명과 logs가 output 비용을 키울 수 있습니다. |
| tool calls | agent route는 도구 사용 패턴에 따라 제한이나 quota가 달라질 수 있습니다. |
| latency | 싼 route라도 review와 CI를 막으면 실무에서는 손해입니다. |
| pass/fail | 실패한 싼 시도는 사람의 복구 비용을 만듭니다. |
| retries | quota, 시간, 신뢰를 동시에 소모합니다. |
| rollback | 나쁜 patch의 실제 비용은 청구서에 나타나지 않습니다. |
이 표를 채울 수 없다면 아직 단위를 비교할 수 없다고 말해야 합니다. 그것이 근거 없는 가격 승자보다 더 정직합니다.
GLM-5.2를 먼저 테스트할 때
GLM-5.2를 먼저 테스트할 만한 경우는 범위가 좁고 검토 가능한 작업입니다. 재현 가능한 bug, 작은 migration, 테스트 실패 수정, 문서 patch, 명확한 refactor가 좋습니다. 실패하더라도 쉽게 revert할 수 있어야 합니다.
Anthropic 고유 policy, billing, fallback, Claude-native route를 평가해야 한다면 Fable 복구를 기다려야 합니다. security, compliance, data migration, 깊은 도메인 판단이 필요한 작업을 첫 smoke test로 삼는 것도 위험합니다.
좋은 테스트는 좁습니다. architecture, tests, deployment, docs를 한 번에 바꾸게 하지 마세요. 한 번의 실행에서 보는 것은 issue 이해, reviewable diff, 지정 tests 통과, 명확한 failure reason입니다.
기본 모델은 아직 바꾸지 마세요
기본 모델 변경은 production decision입니다. Fable이 중단되었다는 사실은 테스트 순서를 바꾸지만, GLM-5.2를 기본 모델로 만드는 이유가 되지는 않습니다. GLM-5.2가 한 작업을 통과해도 그것은 그 route와 그 작업에서의 결과입니다.
변경 전에는 같은 task packet, 같은 acceptance bar, 같은 evidence packet, 같은 rollback plan, 같은 decision threshold를 요구하세요. 어떤 결과가 rollback을 강제하는지 실행 전에 정하지 못한다면 기본 모델은 아직 바꿀 수 없습니다.
| 요구사항 | 통과 조건 |
|---|---|
| 같은 task packet | repo, issue, prompt, files, tools, time budget이 같음 |
| 같은 acceptance bar | tests, review checklist, failure budget이 같음 |
| 같은 evidence packet | logs, diff, test output, latency, quota, failure reason 저장 |
| 같은 rollback plan | revert, isolate, rerun 방법이 있음 |
| 같은 threshold | good enough와 rollback 조건을 미리 정함 |
Fable 접근이 돌아오면 저장한 packet을 그대로 다시 실행하세요. 새로운 GLM 작업을 과거 Fable 인상과 비교하지 마세요. Fable specification과 GLM execution log를 직접 비교하는 것도 피해야 합니다.
같은 작업 평가 체크리스트
가장 깨끗한 검증은 작은 작업입니다. 하나의 repo, 하나의 issue, 하나의 acceptance test를 고릅니다. 실제 문제여야 하지만 review가 가능한 크기여야 합니다.
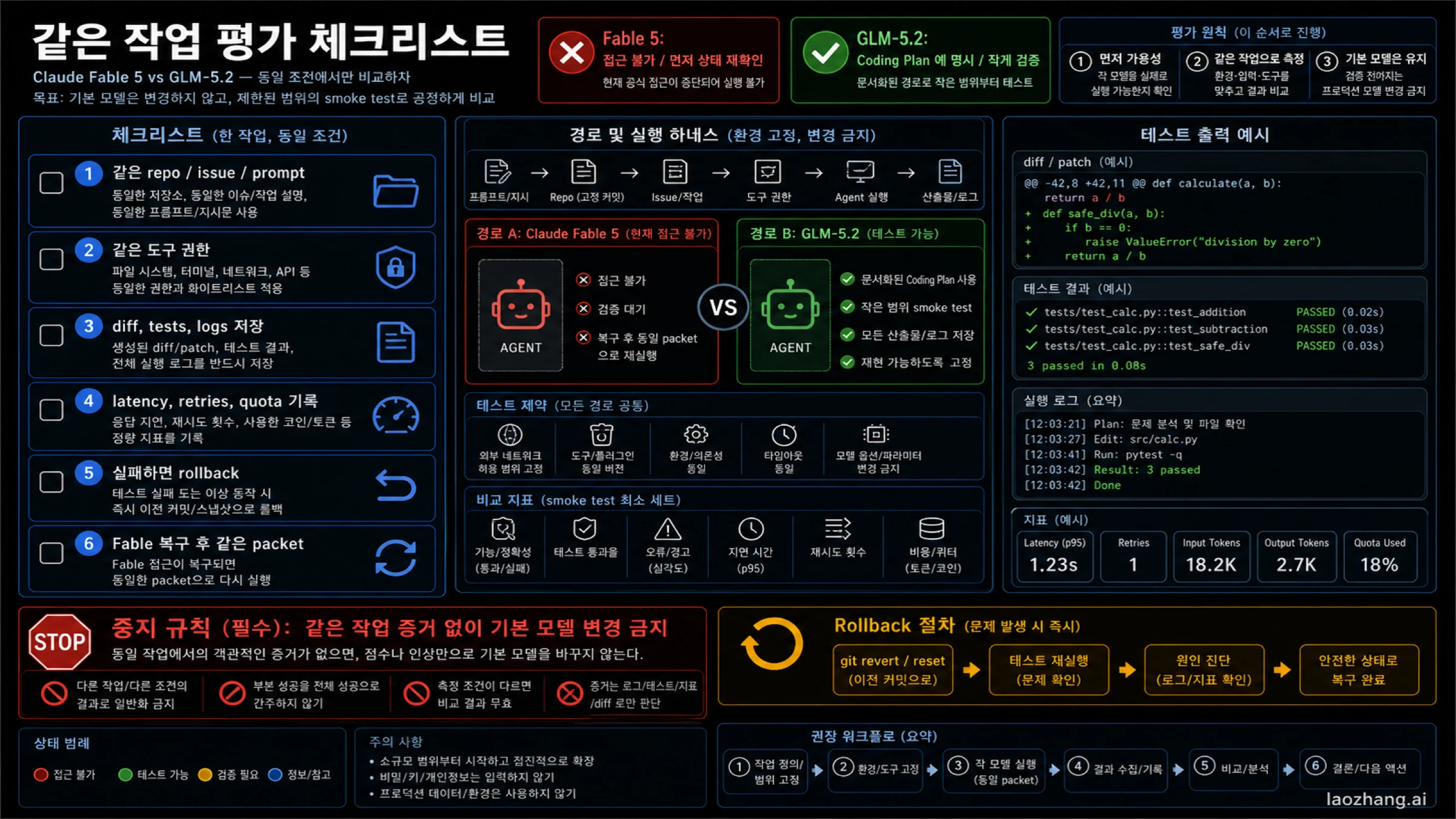
- prompt, branch, files, allowed tools, time budget을 고정합니다.
- Z.AI documented route로 GLM-5.2를 실행합니다.
- model label, provider route, diff, logs, tests, latency, quota, failure reason을 저장합니다.
- patch quality, tests pass, retry count, review load, rollback effort만 봅니다.
- Fable이 돌아오면 같은 packet을 변경하지 않고 실행합니다.
- 양쪽이 모두 runnable일 때 accepted-task cost와 failure mode를 비교합니다.
좋은 결론은 “GLM-5.2가 이 bounded migration task를 한 번의 retry로 통과했고 quota도 허용 범위였다”입니다. 나쁜 결론은 “Fable이 중단되었으니 GLM-5.2가 이겼다”입니다.
자주 묻는 질문
Claude Fable 5는 지금 사용할 수 있나요?
2026년 6월 14일 확인한 Anthropic access statement 기준으로 Fable 5와 Mythos 5 접근은 모든 고객에게 비활성화되어 있습니다. 테스트 전 현재 공식 문서를 다시 확인하세요.
GLM-5.2가 Claude Fable 5보다 좋나요?
Fable이 runnable이 아닌 동안 공정한 live claim은 할 수 없습니다. GLM-5.2는 먼저 테스트할 수 있는 route이지만, 좋다는 결론은 같은 작업, 같은 입력, 같은 결과로 측정해야 합니다.
어떤 model string을 봐야 하나요?
Fable 쪽은 claude-fable-5와 현재 access status를 봅니다. GLM 쪽은 Z.AI Coding Plan의 glm-5.2와 glm-5.2[1m]을 확인합니다.
GLM-5.2가 더 저렴한가요?
간단히 말할 수 없습니다. Fable은 token price row이고 GLM-5.2는 quota와 multiplier route입니다. 같은 작업의 tokens, tools, retries, latency, pass/fail, rollback을 기록한 뒤 비교하세요.
GLM-5.2를 Fable 대체로 써도 되나요?
현재 테스트 가능한 route로는 사용할 수 있습니다. 자동 대체로 쓰지는 마세요. Fable이 복구되면 같은 packet을 실행하고, 품질과 위험 기준을 넘을 때만 기본 모델 변경을 검토하세요.
결론
이 비교의 핵심 질문은 이름이 더 강한 모델이 무엇인지가 아닙니다. 지금 어떤 route를 정직하게 검증할 수 있는지입니다. 2026년 6월 14일 기준 Fable 5는 official contract가 있지만 access suspended이고, GLM-5.2는 Z.AI Coding Plan에 documented route가 있어 작은 테스트를 시작할 수 있습니다.
먼저 Fable 상태를 재확인하고, GLM route를 검증하고, 비용 단위를 맞추고, 같은 작업을 저장하세요. 같은 작업 증거가 없다면 기본 모델을 바꾸지 않는 것이 가장 안전합니다.