
Claude Code에 MCP 서버를 너무 많이 연결하면 처음에는 편해 보이지만, 곧 컨텍스트가 빨리 차고, compact가 자주 일어나고, 도구 선택이 흔들리며, 한 번의 로그 조회나 데이터베이스 조회 뒤에 대화가 무거워질 수 있습니다. 이 문제는 단순히 서버 개수가 많아서만 생기지 않습니다. 도구 정의, 도구 결과, 오래된 세션 흔적, 비슷한 도구가 너무 많은 선택 면이 모두 같은 context window를 씁니다.
2026년 5월 23일 기준 Claude Code 문서는 MCP 제어, Tool Search, MCP tool output이 10,000 tokens를 넘을 때의 경고를 설명합니다. Tool Search는 지원되는 경로에서 tool definition을 필요할 때까지 미루어 앞단의 schema 부담을 줄일 수 있습니다. 하지만 관련 없는 서버, 큰 반환값, 오래된 대화, proxy나 호환 provider의 차이까지 공짜로 만드는 기능은 아닙니다.
먼저 서버 목록이 아니라 컨텍스트 예산표를 봐야 합니다.
| 비용 | 보이는 증상 | 첫 조치 |
|---|---|---|
| 도구 정의 | 외부 호출 전부터 이름, 설명, schema가 많이 보인다. | Tool Search 상태를 확인하고 현재 작업에 필요 없는 server는 미룬다. |
| 도구 결과 | 로그, 테이블, issue, DB row를 받은 뒤 대화가 급격히 무거워진다. | summary, filter, limit, pagination, cursor, handle을 반환한다. |
| 세션 잔여물 | 오래된 오류, 계획, 재시도가 남아 새 판단과 섞인다. | 현재 결정을 요약하고 오래된 branch를 닫거나 새 thread를 시작한다. |
| 선택 면 | 여러 server가 비슷한 read/search/list를 노출한다. | workflow마다 owner를 하나로 줄이고 넓은 custom server는 분리한다. |
바로 할 일은 작습니다. Claude Code에서 /mcp를 실행해 이번 작업에 활성화된 server를 확인하고, 각각에 keep, defer, disable, split, redesign 중 하나를 붙이세요. 필요한 것이 반복 방법이면 skill이 맞고, 외부 데이터나 action surface가 필요하면 MCP가 맞습니다. MCP를 남긴다면 반환값을 작게 만드는 것이 조건입니다.
먼저 컨텍스트 예산으로 나누기
MCP server는 설정 파일의 이름 하나가 아닙니다. MCP tool에는 name, description, input schema, 경우에 따라 output schema와 반환 content가 있습니다. Claude Code가 이를 언제 모델에게 보여 주는지는 로딩 경로에 따라 다르지만, 도구 정의 자체가 컨텍스트 비용이라는 점은 변하지 않습니다.
더 큰 비용은 tool result입니다. database MCP가 하나뿐이어도 8,000 rows, 전체 trace, 큰 JSON, 모든 파일 매치, Playwright snapshot을 그대로 반환하면 context window가 빠르게 줄어듭니다. 반대로 owner가 분명하고 작은 summary만 반환하는 서버 몇 개는 실제로 훨씬 안정적일 수 있습니다.
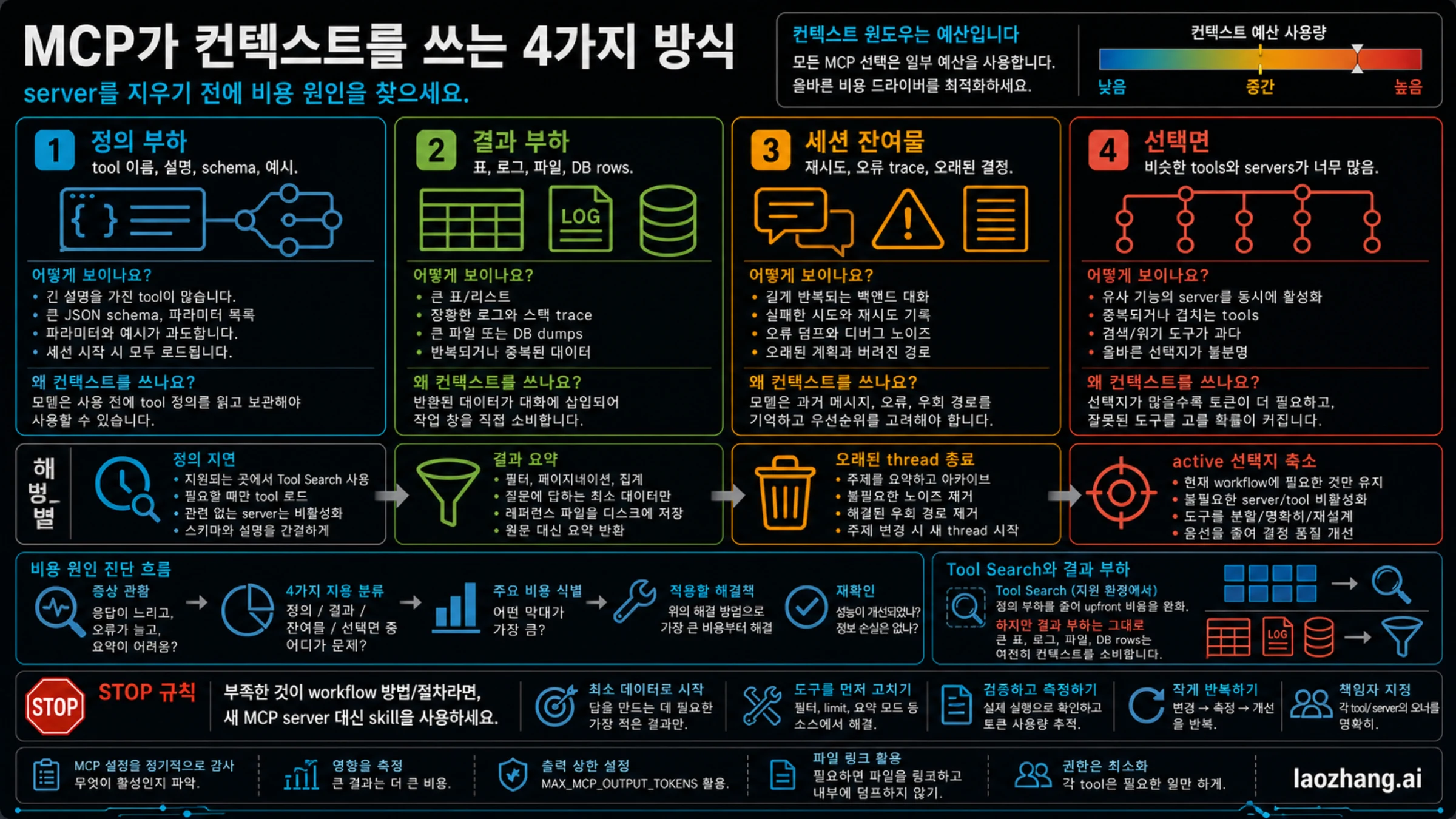
진단은 문제가 발생하는 시점으로 나눕니다. tool call 전부터 느리면 definitions, 이름 중복, 긴 descriptions, active server 목록을 봅니다. tool call 뒤에 나빠지면 output size와 반환 형태를 봅니다. 여러 번 수정한 뒤 판단이 뒤섞이면 MCP가 아니라 세션 잔여물이 원인일 수 있습니다.
| 증상 | 가능성이 높은 비용 | 확인 위치 |
|---|---|---|
| 외부 호출 전부터 느리다 | definitions 또는 decision surface | /mcp, server list, tool names, descriptions |
| 한 번 호출 뒤 흐려진다 | result load | logs, tables, files, raw rows, trace |
| 오래 고친 뒤 이전 판단이 섞인다 | session residue | old errors, old plans, abandoned branches |
| 도구를 자주 잘못 고른다 | decision surface | 비슷한 read/search/list가 여러 server에 있는지 |
이렇게 나누면 “전부 끄기”가 유일한 답이 아니라는 점이 보입니다. 목표는 외부 능력을 없애는 것이 아니라, 현재 작업에서 Claude가 고려해야 하는 active choice와 대화에 들어오는 데이터 크기를 줄이는 것입니다.
Tool Search는 도와주지만 결과는 남는다
Tool Search는 Claude Code의 MCP 조언을 업데이트합니다. 예전에는 MCP를 붙이면 모든 schema와 description이 앞에서부터 부담이 된다고 말하기 쉬웠습니다. 지금은 지원되는 경로에서 tool discovery와 definition loading을 미룰 수 있습니다.
하지만 Tool Search는 tool result를 압축하지 않습니다. Claude가 실제로 도구를 호출하면, 반환된 로그, 테이블, 파일, HTML, JSON, DB rows는 현재 conversation에 들어옵니다. context window는 현재 상호작용의 작업 기억이므로, 큰 결과는 나머지 추론 공간과 경쟁합니다.

세 경계를 분리해서 보세요.
| 경계 | Tool Search가 할 수 있는 것 | 해결하지 못하는 것 |
|---|---|---|
| 앞단 정의 | 지원 경로에서 discovery와 definition load를 지연한다. | 모호한 이름, 긴 설명, 중복 workflow owner. |
| tool results | 자체적으로는 압축하지 않는다. | 큰 logs, tables, traces, files, raw API payload. |
| 세션 기록 | 자체적으로는 정리하지 않는다. | 긴 thread, 반복 수정, 오래된 오류, 낡은 결정. |
ANTHROPIC_BASE_URL, proxy, compatible gateway, custom model path를 쓴다면 자신의 환경에서 확인해야 합니다. Tool Search가 켜져도 실제 호출 뒤에 대화가 나빠지면 다음 작업은 server 수 논쟁이 아니라 output compression입니다.
Keep, defer, disable, split, redesign
MCP 정리는 숫자를 가장 작게 만드는 일이 아닙니다. active list가 설명 가능한 상태가 되어야 합니다. 각 server에 대해 “이번 작업에서 이 server는 ____를 담당한다”라고 말할 수 있어야 합니다. 답이 “언젠가 쓸 수도 있음”이면 지금은 active가 아닙니다.
| 결정 | 언제 쓰나 | 예 |
|---|---|---|
| Keep | 현재 workflow를 실제로 소유하고 local file, memory, skill로 대체할 수 없다. | PR review 중 GitHub MCP, framework migration 중 docs MCP. |
| Defer | 가치가 있지만 지금 단계에는 필요 없다. | UI 수정 전에는 browser QA server를 미룬다. |
| Disable | 현재 작업에 도움이 안 되거나 다른 server와 겹친다. | 같은 library 문서를 두 docs server가 모두 답한다. |
| Split | 하나의 custom server가 관련 없는 읽기, 쓰기, 배포, metrics를 묶었다. | issue search와 deploy write를 분리한다. |
| Redesign | server는 필요하지만 tool shape가 너무 넓고 반환값이 크다. | dump_database를 search_errors(service, time_range, limit)로 바꾼다. |
/mcp는 현재 Claude Code 세션의 active server를 보는 데 좋습니다. 설정을 정리할 때는 claude mcp list, claude mcp get, claude mcp remove를 쓸 수 있습니다. 목적은 설정을 비우는 것이 아니라, 현재 작업의 owner만 남기는 것입니다.
첫 MCP를 고르는 단계라면 Best Claude Code MCP Servers 같은 목록이 더 맞습니다. 여기서는 이미 setup이 커진 뒤, 작업 단위로 다시 줄이는 과정을 다룹니다.
tool output은 대화에 들어오기 전에 줄이기
Tool Search 뒤에도 가장 큰 절감은 output compression에서 나옵니다. 한 번의 Playwright snapshot, GitHub issue list, log fetch, DB query, full file read가 여러 quiet server보다 더 많은 컨텍스트를 쓸 수 있습니다.
Claude Code의 10,000 tokens 경고와 MAX_MCP_OUTPUT_TOKENS는 마지막 guardrail입니다. 좋은 반환은 “간신히 제한 아래”가 아니라 “다음 판단에 충분한 최소 정보”입니다. 다음 판단에 오류 세 종류와 예시 한 줄이 필요하다면 전체 로그를 반환하면 안 됩니다.
| 규칙 | 나쁜 반환 | 더 좋은 반환 |
|---|---|---|
| summary first | 전체 로그 스트림 | anomaly, count, sample 3줄 |
| filter at source | 모든 row | service, time range, status, owner로 필터 |
| paginate | giant response 하나 | initial batch와 next_cursor |
| default cap | 무제한 matches | limit: 20, 필요할 때만 확대 |
| return handles | 전체 파일 또는 dataset | file path, object id, job id, stored result |
| preview before raw | raw payload 즉시 반환 | summary 먼저, raw는 별도 요청 |
질문하는 방식도 중요합니다. “DB 읽어줘” 대신 “지난 24시간 top 20 errors를 service별로 묶고 count와 sample trace 하나씩”이라고 묻습니다. “로그 봐줘” 대신 “deployment failed 이후의 error line만, health check 제외”라고 지정합니다. 좁은 질문은 tool이 작은 출력을 반환하도록 유도합니다.
compact MCP server 설계하기
직접 MCP server를 만든다면 가장 큰 개선은 on/off가 아니라 tool design입니다. compact server는 Claude에게 적은 수의 분명한 tool을 보여 줍니다. 이름은 결과 중심, description은 짧고 구분 가능, default는 summary, raw detail은 명시 요청이어야 합니다.
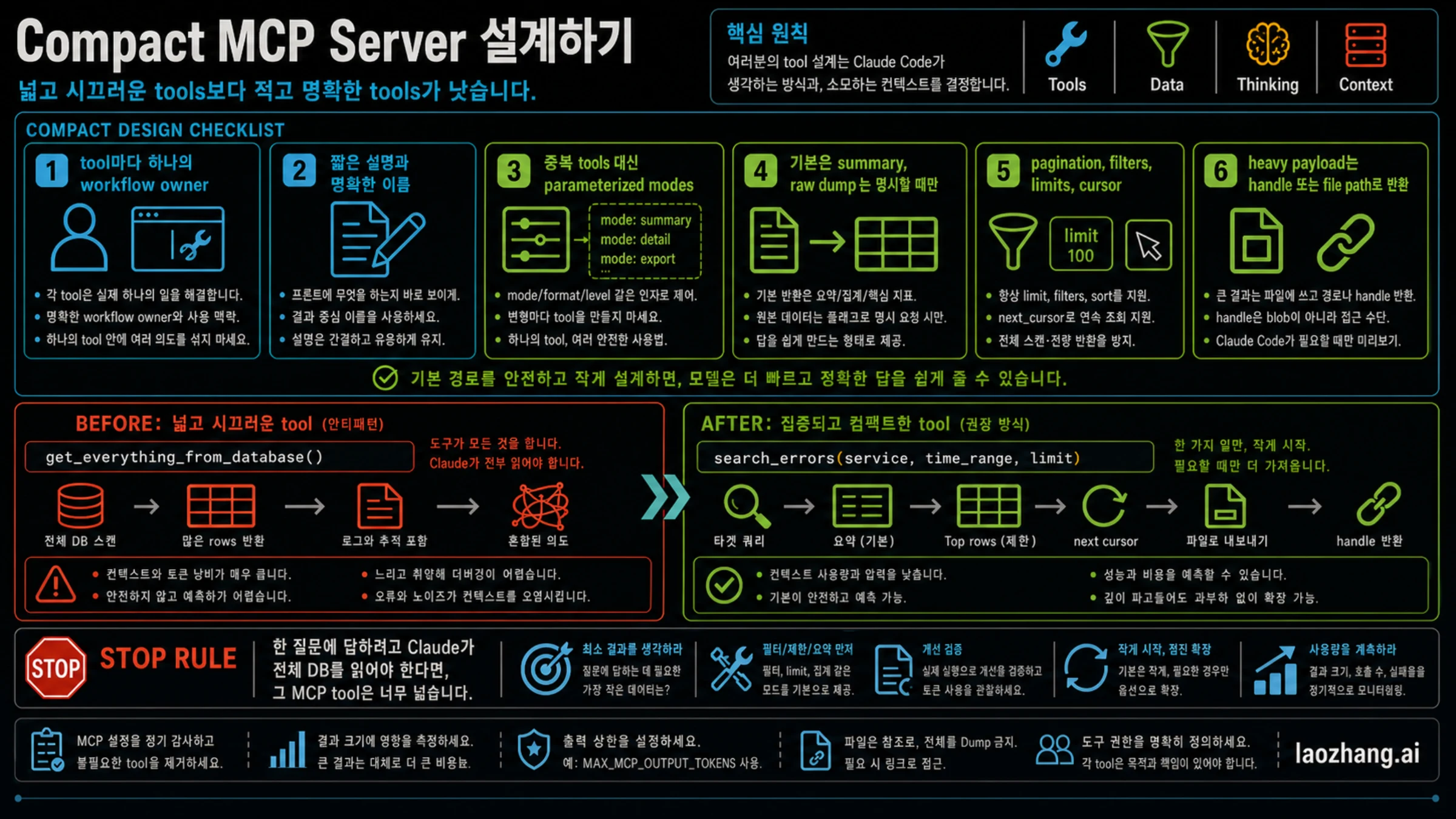
체크리스트는 다음과 같습니다.
- 하나의 tool은 하나의 일을 한다. issue, log, metric, file, deployment를 한 호출에 섞지 않는다.
- 구현이 아니라 결과를 이름으로 쓴다. query_system보다 search_recent_errors가 낫다.
- description은 선택을 돕기 위한 것이지 backend 문서 전체가 아니다.
- 비슷한 tool을 늘리기보다 mode: summary/detail/export를 사용한다.
- summary를 default로 하고 raw output은 explicit parameter로만 연다.
- 큰 데이터에는 filter, limit, pagination, cursor를 반드시 둔다.
- 큰 payload는 path, id, handle로 반환한다.
- read-only exploration과 write/destructive action을 분리한다.
나쁜 tool은 get_everything_from_database()입니다. rows, logs, traces, metadata를 모두 반환해 Claude가 전체를 읽고 판단하게 만듭니다. 좋은 tool은 search_errors(service, time_range, limit)입니다. summary, top rows, next_cursor를 돌려주고 다음 deep dive를 선택할 여지를 줍니다.
무거운 탐색을 main thread 밖으로 옮기기
정답이 항상 “MCP를 덜 쓰기”는 아닙니다. “main thread에서 모든 MCP 탐색을 하지 않기”도 답입니다. Claude Code subagents는 noisy data를 조사하고, branch hypothesis를 확인하고, compact summary를 main thread로 돌려주는 데 유용합니다.
다만 subagent가 자동으로 압축 경계가 되지는 않습니다. tool inheritance를 넓게 두면 main thread와 같은 tools를 받아 같은 문제를 반복합니다. 탐색 agent에는 필요한 server만 주고, raw dump 대신 findings, counts, paths, risks, next actions를 반환하도록 지시하세요.
Skill은 또 다른 층입니다. 필요한 것이 반복 가능한 방법, checklist, reference bundle, script sequence라면 skill이 맞습니다. 필요한 것이 외부 데이터나 action surface라면 MCP가 맞습니다. 둘 다 필요하면 MCP는 reach를, skill은 operating method를 맡게 합니다. 오래 유지할 규칙은 긴 transcript가 아니라 memory에 둡니다.
20분 MCP 정리 루틴
Claude Code가 너무 빨리 compact되고, tool을 잘못 고르고, 큰 output 뒤에 흐려질 때 다음 루틴을 씁니다.
- /mcp를 실행해 active server를 적는다.
- 각 server를 keep, defer, disable, split, redesign으로 분류한다.
- current workflow owner가 없는 server는 끈다.
- 같은 작은 작업을 다시 실행하고 문제가 tool call 전인지 후인지 본다.
- 전이라면 definitions, names, descriptions, Tool Search support를 본다.
- 후라면 output size, summary, filter, limit, cursor, handle을 본다.
- 여러 retry 뒤라면 current decision을 요약하고 새 thread로 간다.
- 필요한 것이 방법이면 server를 늘리지 말고 skill을 만든다.
좋은 지표는 configured servers 총수가 아닙니다. 현재 작업에서 Claude가 고려해야 하는 active choices 수와, tool call이 conversation에 들여오는 데이터 크기입니다. 지루해 보이는 작은 setup이 실제로 가장 강한 setup일 때가 많습니다.
자주 묻는 질문
Tool Search가 MCP 컨텍스트 과부하를 해결하나요?
완전히는 아닙니다. 지원 경로에서 upfront tool definitions를 줄일 수 있지만, tool results, 오래된 conversation, 중복 server, 넓은 custom tools는 따로 줄여야 합니다.
Claude Code에서 MCP server는 몇 개가 적당한가요?
고정된 수는 없습니다. 현재 workflow owner인 server만 active로 둡니다. 큰 DB dump를 반환하는 server 하나가 조용한 server 여러 개보다 더 큰 문제일 수 있습니다.
MCP tool output이 너무 크면 어떻게 하나요?
source에서 압축합니다. summary, filter, pagination, limit, cursor, file path, object id, handle을 사용하세요. raw data는 default가 아니라 explicit request여야 합니다.
skill과 MCP는 어떻게 나누나요?
방법, 절차, checklist, reference가 필요하면 skill입니다. 외부 시스템 접근이나 action surface가 필요하면 MCP입니다. 둘 다 필요하면 역할을 분리합니다.
compact MCP server의 조건은 무엇인가요?
적은 tools, 분명한 owner, 짧은 descriptions, bounded output, filters, limits, cursors, summary first, read/write separation입니다. 하나의 tool이 모든 것을 반환하지 않게 합니다.
모든 MCP를 끄는 것이 가장 안전한가요?
진단으로는 유용하지만 장기 해법은 아닙니다. 필요한 접근은 남기고, 나머지는 defer 또는 disable하며, 너무 큰 output을 반환하는 tool은 redesign해야 합니다.
Claude Code MCP 컨텍스트 과부하는 통합을 많이 붙인 벌이 아니라, 작업 기억을 예산으로 보지 않은 결과입니다. 현재 workflow의 owner만 남기고, 큰 결과는 conversation에 들어오기 전에 줄이고, 방법은 skill에 두며, noisy exploration은 좁은 context로 옮기세요. Claude가 잘 추론하는 MCP setup은 대개 작지만 충분한 setup입니다.