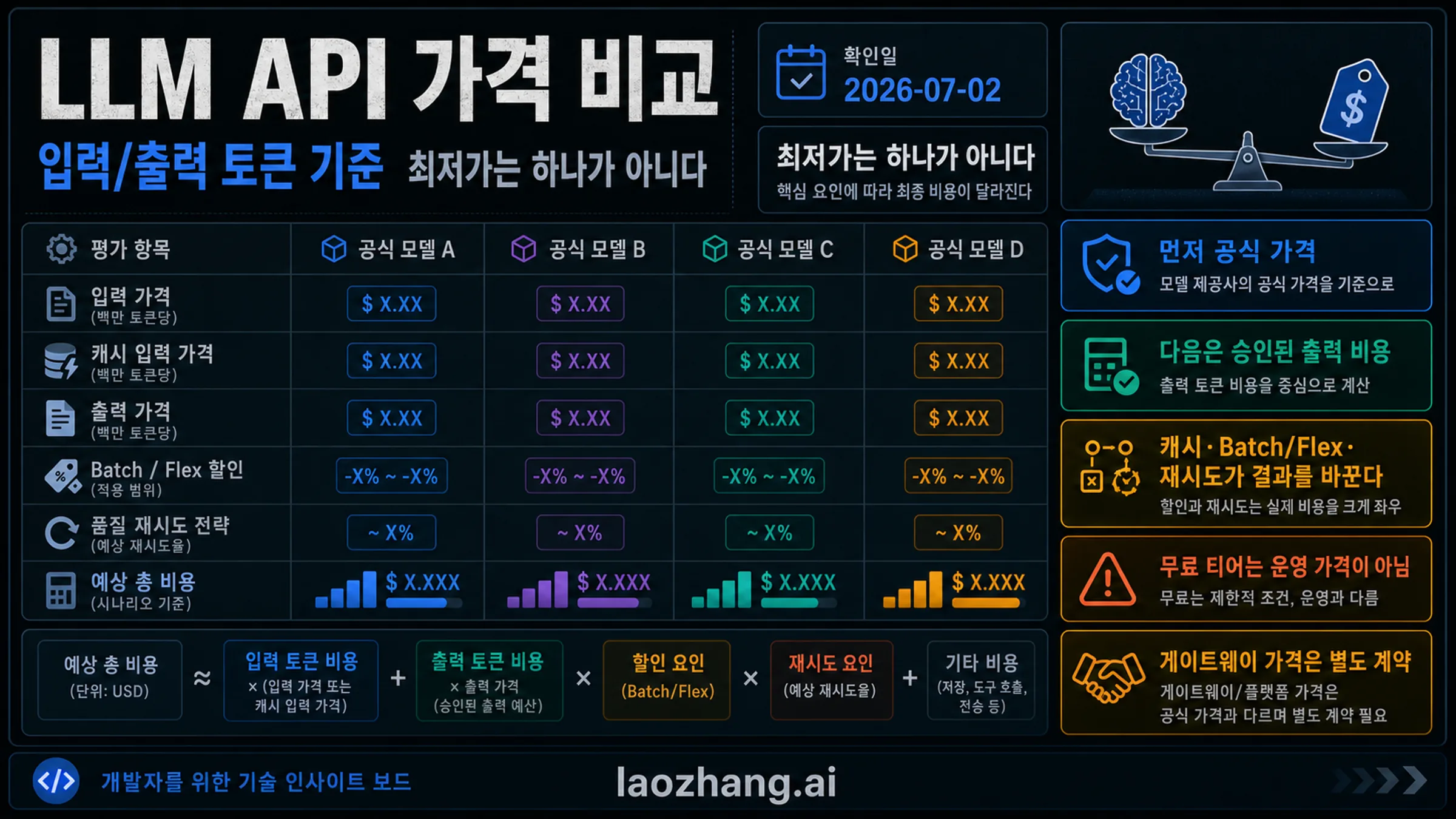
가장 저렴한 LLM API 모델은 하나로 고정되지 않습니다. 실제로는 입력 길이, 출력 길이, 캐시 적중률, 품질 기준, 개인정보 경계, 지연 시간, 지원 계약을 모두 통과한 뒤 승인된 출력 하나당 비용이 가장 낮은 모델입니다. 2026년 7월 2일 기준으로는 공식 모델 소유자의 가격표를 먼저 확인하고, 그 다음 Batch/Flex, 무료 티어, 재시도, 도구 호출, 게이트웨이 계약을 더해 판단합니다.
| 워크로드 | 먼저 테스트할 저가 레인 | 공식 가격 기준 | 더 이상 싸지 않은 경우 |
|---|---|---|---|
| 대량 추출, 짧은 답변, 캐시 중심 | deepseek-v4-flash | cache-hit input $0.0028, cache-miss input $0.14, output $0.28 / 1M tokens | 품질, 지역, 지연, 가용성이 부족할 때 |
| OpenAI 생태계, 저가 호출, Batch/Flex | gpt-5-nano | $0.05 input, $0.005 cached input, $0.40 output. Batch/Flex는 더 낮음 | 출력이 길거나 도구 호출과 재시도가 많을 때 |
| Google 최저 scale lane | gemini-2.5-flash-lite | $0.10 input, $0.40 output. Batch/Flex $0.05 / $0.20 | 수명 주기나 품질상 3.1 lane이 필요할 때 |
| Google 최신 고빈도 lane | gemini-3.1-flash-lite | $0.25 input, $1.50 output. Batch/Flex $0.125 / $0.75 | Google 안에서 최저 token row만 찾을 때 |
| 저가 모델이 품질 기준을 못 넘을 때 | Claude Haiku 4.5 | $1 input, $5 output / MTok | 더 싼 모델이 이미 합격할 때 |
중단 규칙: 입력 가격만 보고 선택하지 마세요. 같은 실제 prompt로 입력, 캐시 입력, 출력, 도구 호출, 재시도, 무료 티어, 계약 경계를 측정한 뒤 승인된 출력 비용으로 비교해야 합니다.
공식 가격표를 먼저 본다
공식 페이지는 모델 ID, 과금 단위, 현재 가격, 할인 방식, 사용 가능성을 확인하는 첫 번째 증거입니다. 가격 비교 aggregator는 후보를 찾는 데 유용하지만, 그 표가 곧 OpenAI, Google, DeepSeek, Anthropic 또는 Mistral의 공식 가격이 되는 것은 아닙니다. 공식 가격, provider 가격, gateway 가격은 서로 다른 계약입니다.
OpenAI pricing은 gpt-5-nano의 standard input / cached input / output을 $0.05 / $0.005 / $0.40 per 1M tokens로 보여줍니다. Google pricing은 gemini-2.5-flash-lite와 gemini-3.1-flash-lite를 분리합니다. 전자는 Google의 더 낮은 scale lane이고, 후자는 더 새롭지만 비쌉니다. DeepSeek pricing은 deepseek-v4-flash의 cache-hit, cache-miss, output을 따로 보여줍니다. Anthropic pricing에서 Claude Haiku 4.5는 Claude의 저가 품질 lane입니다.
실제 비용 공식
실제 비용은 한 번의 입력 token 가격이 아니라 승인된 출력의 비용입니다. 저렴한 모델도 schema 오류, 긴 출력, 약한 추론, 거절, 재시도가 많으면 총비용이 올라갑니다. 최소한 input tokens, cached input, output tokens, tool calls, quality retries, Batch/Flex latency, region, tax, data terms를 함께 계산해야 합니다.
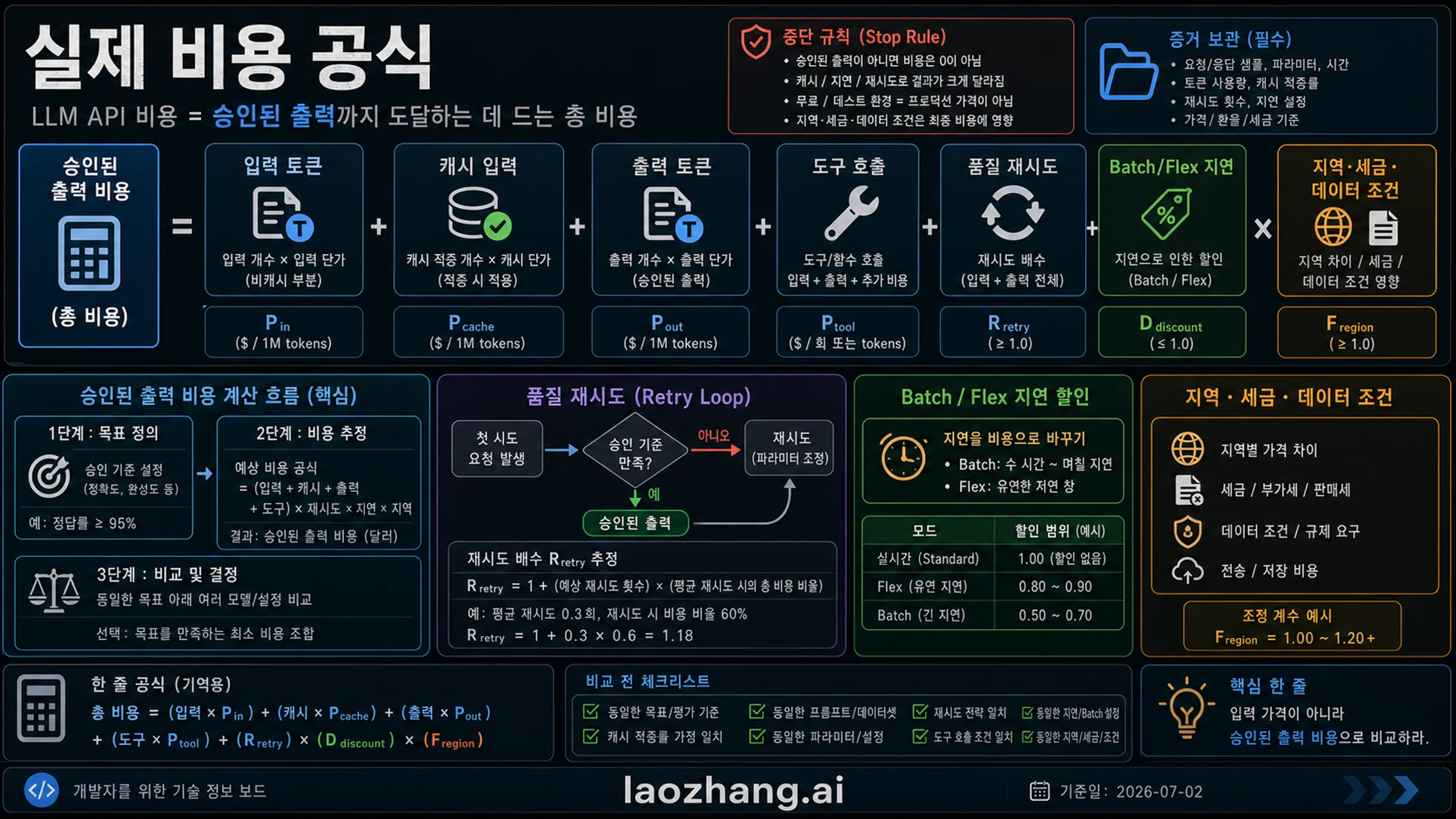
20-50개의 대표 작업으로 같은 prompt set을 실행하세요. 입력 크기, 출력 크기, 캐시 적중, 시도 횟수, 합격/불합격, P50/P95 지연, 실패 이유를 저장합니다. 그런 다음 총 청구액을 합격한 출력 수로 나누면 production 예산에 더 가까운 숫자가 됩니다.
워크로드별 첫 저가 레인을 고른다
대량 추출은 캐시와 schema validity가 중요합니다. 짧은 요약은 출력 길이와 사실성이 중요합니다. 코딩 작업은 compile 또는 test pass rate가 필요합니다. Agent 루프는 도구 호출과 반복 호출로 비용이 커집니다. 긴 컨텍스트 분석은 인용 정확도와 지연 시간이 중요합니다. 품질 우선 작업은 더 비싼 모델이 재시도와 사람 검토를 줄여 더 싸질 수 있습니다.
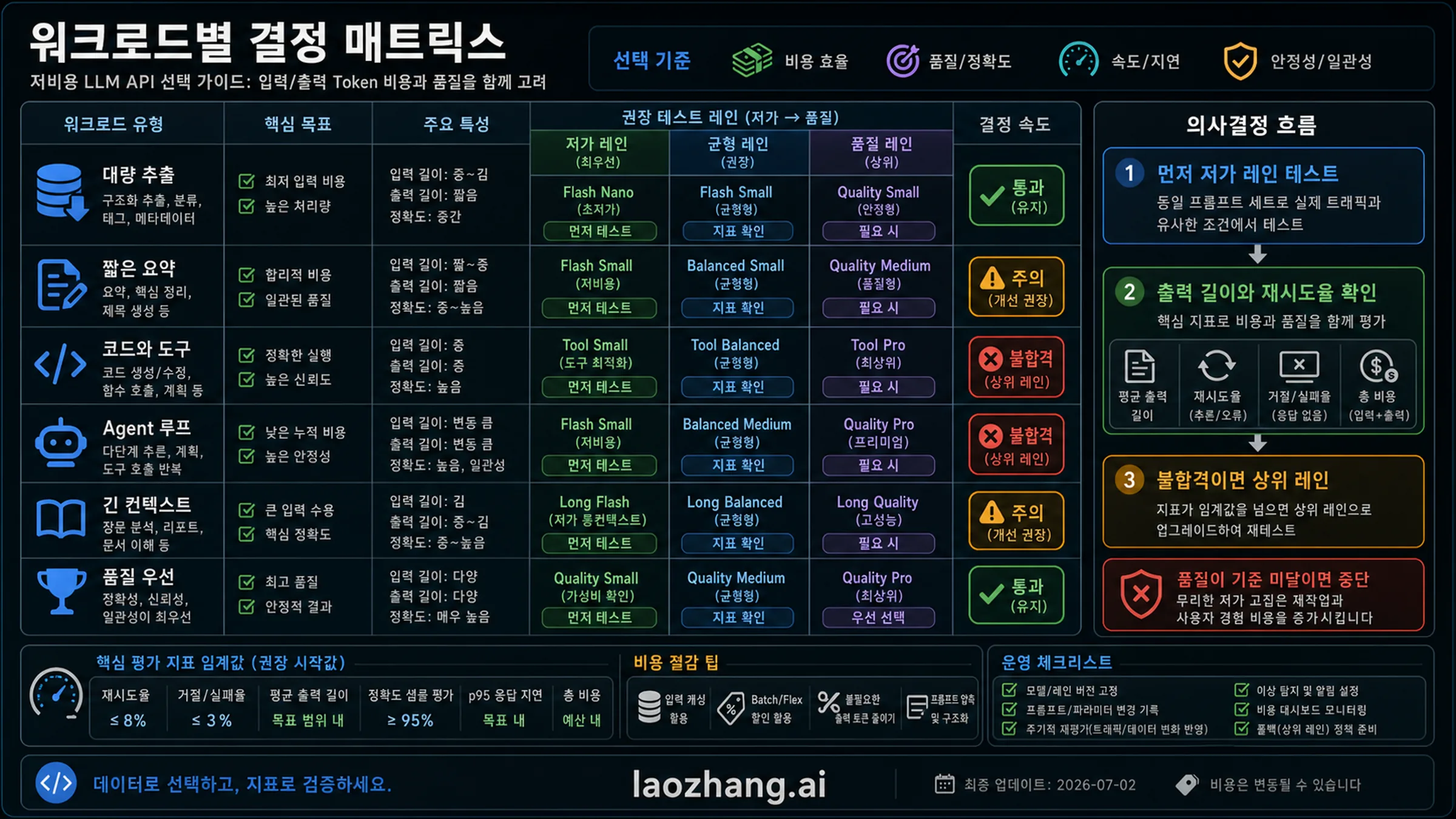
처음부터 많은 모델을 비교하지 말고 두 개의 저가 lane을 고르세요. acceptance bar와 upgrade trigger를 미리 정합니다. 저가 lane이 품질 기준을 통과하지 못하거나 재시도율이 높으면 상위 lane으로 이동합니다. 가격이 비슷하면 기존 stack, 지원, 계약, 모니터링 편의성도 비교합니다.
무료 티어는 운영 가격이 아니다
무료 티어는 학습, prompt 검증, prototype에 좋습니다. 하지만 production traffic에는 예측 가능한 quota, billing owner, data terms, support path, fallback plan이 필요합니다. Google pricing은 Free Tier와 Paid Tier를 분리하고 데이터 사용 경계도 다르게 둡니다.
무료 route는 proof-of-fit으로 사용하고 budget으로 고정하지 마세요. 운영 전에는 model ID, serving mode, quota, rate limit, billing state, data policy, Batch/Flex, 초과 비용을 확인합니다. customer data, source code, logs가 prompt에 들어가면 무료 여부보다 terms가 더 중요합니다.
게이트웨이 가격은 별도 계약
Gateway는 migration cost를 낮출 수 있습니다. 하나의 OpenAI-compatible endpoint, 여러 모델 전환, 로그, 통합 지원을 제공하기 때문입니다. 하지만 gateway price는 official vendor price가 아닙니다. OpenRouter, SiliconFlow, laozhang.ai 같은 provider row는 exact model ID, billing unit, cache behavior, failed-call billing, rate limits, refund, data policy를 따로 검증해야 합니다.
laozhang.ai는 OpenAI-compatible migration, model coverage, logs, routing을 위한 gateway route로 평가할 수 있습니다. 정확한 가격은 현재 console/API에서 확인해야 하며, 오래된 screenshot이나 aggregator 행을 공식 가격처럼 고정하면 안 됩니다.
비용 투입 전 체크리스트
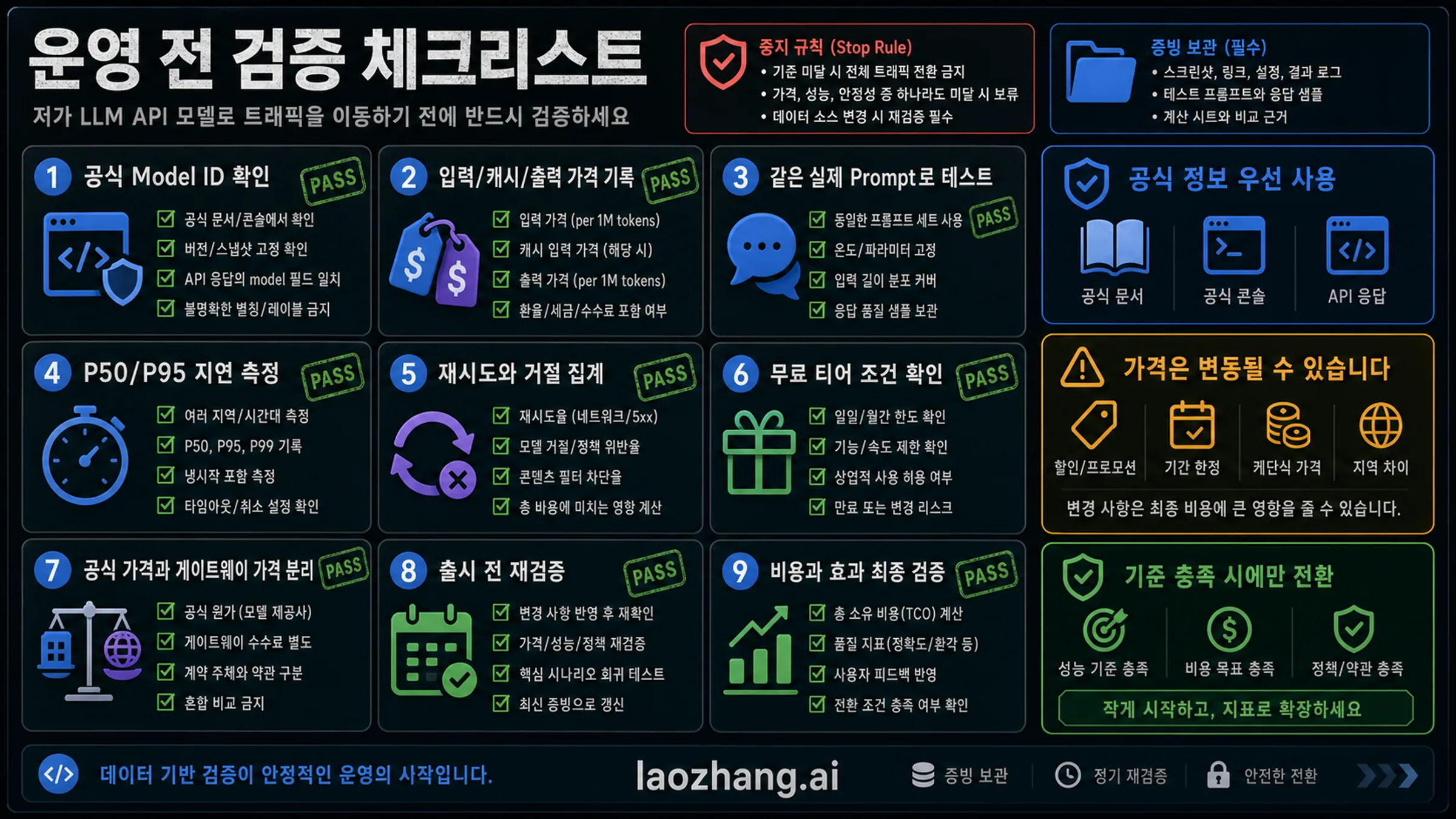
- 공식 model ID를 확인합니다.
- input, cached input, output, Batch/Flex 가격을 기록합니다.
- 같은 실제 prompt로 테스트합니다.
- P50/P95 지연과 concurrency를 측정합니다.
- 재시도, 거절, 형식 오류, tool calls를 셉니다.
- 공식 가격, provider 가격, gateway fee를 분리합니다.
- Agent나 대량 처리에는 spend cap과 kill switch를 넣습니다.
- 출시 전 가격과 가용성을 다시 확인합니다.
추천 시작점
최저 official paid token floor가 필요하면 DeepSeek V4 Flash부터 테스트하되 품질, 지역, 가용성을 확인하세요. OpenAI stack이라면 gpt-5-nano와 Batch/Flex latency를 봅니다. Google 저가 route라면 gemini-2.5-flash-lite를 먼저 보고, 필요하면 gemini-3.1-flash-lite를 비교합니다. 저가 모델이 실패하면 Claude Haiku 4.5를 quality baseline으로 측정합니다.
최종 결론은 “이 모델이 항상 가장 싸다”가 아니라 “이 prompt set, 이 출력 길이, 이 cache hit rate, 이 품질 기준에서는 이 모델의 승인된 출력 비용이 가장 낮다”여야 합니다.
예산 테스트 템플릿
구매나 운영 예산을 정할 때는 가격표의 숫자를 그대로 옮기면 안 됩니다. 먼저 자신의 워크로드용 작은 원장을 만들어야 합니다. 같은 prompt, 같은 system 지시, 같은 RAG 조각, 같은 출력 상한, 같은 승인 기준으로 후보 모델을 실행하고 입력 토큰, 재사용 가능한 캐시 prefix, 출력 토큰, 형식 오류, 거절, 수동 수정 시간, P50/P95 지연 시간, 지역, quota, 지원 책임자, 최종 승인 여부를 기록합니다. 이 원장이 있어야 낮은 token row가 실제 절감인지, 아니면 재시도와 사람이 고치는 시간으로 비용을 옮긴 것인지 구분할 수 있습니다.
| 예산 항목 | 기록 방법 | 최저가 판단에 미치는 영향 |
|---|---|---|
| 입력 토큰 | system, user, 검색 문맥, tool schema를 분리 | 긴 문맥 작업에서는 낮은 입력가가 중요하지만 불필요한 문맥은 낭비입니다 |
| 캐시 입력 | 재사용 prefix와 cache hit rate를 측정 | cache-hit 가격은 재사용률이 높을 때만 의미가 있습니다 |
| 출력 토큰 | 작업별 목표 길이와 최대 길이를 정함 | 출력 단가는 높아서 긴 답변이 순위를 바꿉니다 |
| 품질 재시도 | 형식 오류, 사실 오류, 거절, 수동 수정 횟수 | 합격률이 낮으면 저렴한 호출도 비싸집니다 |
| Batch/Flex | 비동기 작업과 실시간 작업을 분리 | 할인은 기다릴 수 있는 처리에만 맞습니다 |
| 계약 경계 | 공식 가격, 공급자 계약, 게이트웨이 비용을 분리 | 지원, 로그, 환불, 데이터 조건도 운영 비용입니다 |
테스트 세트는 최소 세 종류가 필요합니다. 첫째는 짧은 출력의 안정적인 작업입니다. 예를 들면 추출, 분류, 태깅, 중복 제거, 필드 정리입니다. 이 세트에서는 DeepSeek V4 Flash, OpenAI nano, Google Flash-Lite 계열 저가 레인의 장점이 잘 보입니다. 둘째는 요약, 비교, 이메일 초안, 제품 설명처럼 출력이 길어질 수 있지만 합격 기준을 정하기 쉬운 작업입니다. 여기서는 출력 단가, 길이 제어, 사실 오류가 비용을 바꿉니다. 셋째는 코드 수정, 계약 검토, 재무 판단, 여러 단계 Agent입니다. 이 작업에서는 token row보다 테스트 통과율, 감사 가능성, 사람 리뷰 감소가 더 중요합니다.
추출에서는 이기지만 요약에서는 자주 실패하는 모델을 전체 기본 모델로 두면 안 됩니다. 짧고 결정적인 작업은 저가 레인에 두고, 중간 길이 작업은 출력 길이와 재시도 상한을 설정하며, 코드나 규정 준수 작업은 더 강한 모델을 품질 기준으로 남기는 방식이 낫습니다. 이런 라우팅은 “한 모델이 항상 최저가”라는 순위보다 청구서와 운영에서 재현하기 쉽습니다.
도입 전에는 역방향 검토도 해야 합니다. 비즈니스 담당자는 결과가 바로 사용 가능한지 확인합니다. 엔지니어링 담당자는 지연 시간, rate limit, 실패 처리, 관측 가능성을 확인합니다. 보안 담당자는 데이터 조건, 로그 보관, 지역, 지원 경로를 확인합니다. 이 중 하나라도 통과하지 못하면 낮은 token row는 아직 운영 절감으로 볼 수 없습니다.
지출 전 재확인 절차
가격에 의존하는 비교는 공개 당일 다시 확인해야 합니다. 먼저 공식 pricing 페이지에서 model ID, input, cached input, output, Batch/Flex 행을 확인합니다. 그다음 무료 티어와 유료 티어를 섞어 쓰지 않았는지 봅니다. 특히 data use, quota, support, availability는 프로토타입에서는 작아 보여도 운영에서는 핵심 조건입니다.
게이트웨이나 OpenAI-compatible provider를 쓰는 경우 그 가격은 공식 가격이 아니라 별도의 공급자 계약으로 기록합니다. 실제 model ID, 과금 단위, 실패 호출 과금, rate limit, 환불, 로그, 데이터 정책을 따로 확인합니다. 이후 같은 prompt로 작은 청구 테스트를 실행하고 평균 비용이 아니라 P95 비용, 실패 작업 비용, 승인된 출력 비용을 봅니다. 마지막으로 schema 실패율, 수동 수정 시간, P95 지연, 지역 가용성, 데이터 조건 불일치가 임계값을 넘을 때 상위 모델로 올리는 조건을 적어 둡니다.
자주 묻는 질문
지금 가장 싼 LLM API 모델은 무엇인가요?
DeepSeek V4 Flash와 OpenAI gpt-5-nano가 첫 저가 체크 대상입니다. Google에서는 gemini-2.5-flash-lite가 낮은 scale lane입니다. 최종 승자는 워크로드에 따라 달라집니다.
DeepSeek가 항상 가장 싼가요?
아닙니다. 가격 row는 매우 낮지만 품질, 지연, 지역, 가용성이 맞지 않으면 재시도와 검토 비용이 올라갑니다.
무료 LLM API를 운영에 써도 되나요?
보통 무료 티어는 prototype에 적합합니다. 운영에는 quota, paid terms, support, data policy, billing이 필요합니다.
코딩 작업에는 어떤 모델을 골라야 하나요?
DeepSeek, OpenAI nano, Google Flash-Lite, 기존 provider를 같은 실제 task로 테스트하고 test pass rate와 승인된 출력 비용으로 판단하세요.
Claude는 너무 비싼가요?
raw token row는 높지만 Claude Haiku 4.5가 재시도와 사람 검토를 줄이면 품질 우선 작업에서 더 싸질 수 있습니다.
가격 비교 aggregator를 믿어도 되나요?
후보 탐색에는 유용합니다. 실제 지출 전에는 공식 owner page나 provider console로 다시 확인해야 합니다.