
가장 저렴한 LLM API provider는 고정된 한 회사가 아닙니다. 2026-07-01 기준으로 확인한 범위에서는 DeepSeek V4 Flash가 가장 낮은 공식 유료 token floor입니다. 하지만 실제 운영에서 가장 저렴한지는 출력 길이, cache hit, 품질 기준, retry, latency, quota, gateway fee, data boundary, support owner, migration cost까지 포함해 계산해야 합니다.
먼저 route ownership을 나눕니다. 공식 direct API는 model vendor가 가격표, billing unit, lifecycle notice, support contract를 소유합니다. gateway나 aggregator는 OpenAI-compatible migration, multi-model routing, logs, fallback, 하나의 support path를 제공해 실제 비용을 낮출 수 있습니다. 무료 경로는 prompt experiment와 prototype에 적합합니다. BYOK나 self-hosting은 운영 역량과 utilization이 충분할 때만 저렴해질 수 있습니다.
| Route | 첫 테스트 | 왜 저렴할 수 있나 | Stop rule |
|---|---|---|---|
| 공식 direct API | DeepSeek V4 Flash로 공식 유료 token floor 확인, Gemini 2.5 Flash-Lite Batch/Flex로 low-cost batch 확인 | vendor-owned price와 lifecycle notice가 명확하다 | 품질, 지역, quota, lifecycle이 workload와 맞지 않으면 중단한다. |
| Gateway / aggregator | OpenRouter, SiliconFlow, laozhang.ai는 live model/API verification 후 비교 | 하나의 compatible API, model switching, logs, support consolidation이 engineering cost를 낮춘다 | fee, failed-call billing, support owner, quota, data policy가 불명확하면 중단한다. |
| 무료 experiment route | free model, trial credit, sandbox quota | prototype과 same-prompt 비교에 유용하다 | rate limits, terms, availability, support를 확인하기 전에는 운영에 쓰지 않는다. |
| BYOK / self-hosted | 내 key, 내 cloud, 내 inference stack | data path와 long-term unit economics를 통제할 수 있다 | ops, monitoring, GPU utilization, latency가 절감분을 지우면 중단한다. |
간단한 공식은 effective cost = total bill / accepted outputs입니다. 같은 prompt를 실행하고, 최신 billable unit을 확인하고, failure와 retry를 기록하고, spend cap 아래 작은 rollout을 하기 전에는 운영 traffic을 옮기지 않습니다.
현재 저비용 공식 가격 경로
공식 가격은 가장 안전한 anchor입니다. 가격표의 owner가 model vendor이고 billing unit, lifecycle, support boundary를 확인하기 쉽기 때문입니다. 하지만 공식 가격만으로는 충분하지 않습니다. input token이 싸도 출력이 길어지고, schema failure가 많고, retry가 많고, fallback이 필요하면 총 비용은 올라갑니다.
2026-07-01에 확인한 공식 row는 다음과 같습니다. DeepSeek V4 Flash는 cache-miss input $0.14, output $0.28 / 1M tokens이며 cache-hit input은 훨씬 낮습니다. Gemini 2.5 Flash-Lite는 input $0.10, output $0.40이고 Batch/Flex는 $0.05/$0.20입니다. OpenAI gpt-5.4-nano는 input $0.20, output $1.25입니다. Mistral Small 4는 $0.15/$0.60입니다. Claude Haiku 4.5는 $1/$5입니다. 이 숫자는 후보를 고르는 근거이지 최종 구매 결론이 아닙니다.
| 공식 route | 현재 low-cost row | 의미 | Boundary |
|---|---|---|---|
| DeepSeek direct | DeepSeek V4 Flash: cache-miss input $0.14, output $0.28 / 1M tokens, cache-hit input은 훨씬 낮음 | 이번 비교에서 가장 낮은 공식 유료 token floor | code, reasoning, region, reliability에서 항상 최고라는 뜻은 아니다. deepseek-chat과 deepseek-reasoner compatibility name은 2026-07-24 15:59 UTC에 deprecation 예정이다. |
| Google Gemini API | Gemini 2.5 Flash-Lite: input $0.10, output $0.40, Batch/Flex $0.05/$0.20 | latency를 batch-like하게 받아들일 수 있는 대량 작업에 강함 | 오래된 Gemini 2.0 Flash-Lite 가격을 현재 조언으로 재사용하지 않는다. |
| OpenAI API | gpt-5.4-nano: input $0.20, output $1.25, Batch/Flex는 더 낮음 | OpenAI-native stack에서는 tooling, policy, compatibility가 migration risk를 낮춘다 | 최저 floor는 아니지만 engineering과 reliability cost를 줄일 수 있다. |
| Mistral API | Mistral Small 4: input $0.15, output $0.60 | open-model route와 European governance 문맥에서 유력 | governance, latency, quality를 함께 비교한다. |
| Anthropic API | Claude Haiku 4.5: input $1, output $5, Sonnet 5 introductory pricing은 2026-08-31까지 | raw token price는 높지만 review와 retry를 줄이면 후보가 된다 | 날짜가 있는 가격은 cutoff 전에 재확인해야 한다. |
실무 해석은 이렇습니다. DeepSeek V4 Flash를 저렴한 paid route의 첫 테스트로 삼고, workload가 그 output을 실제로 승인하는지 증명합니다. 싼 model이 rejected output을 늘리면 가격표는 핵심 비용을 숨긴 것입니다.
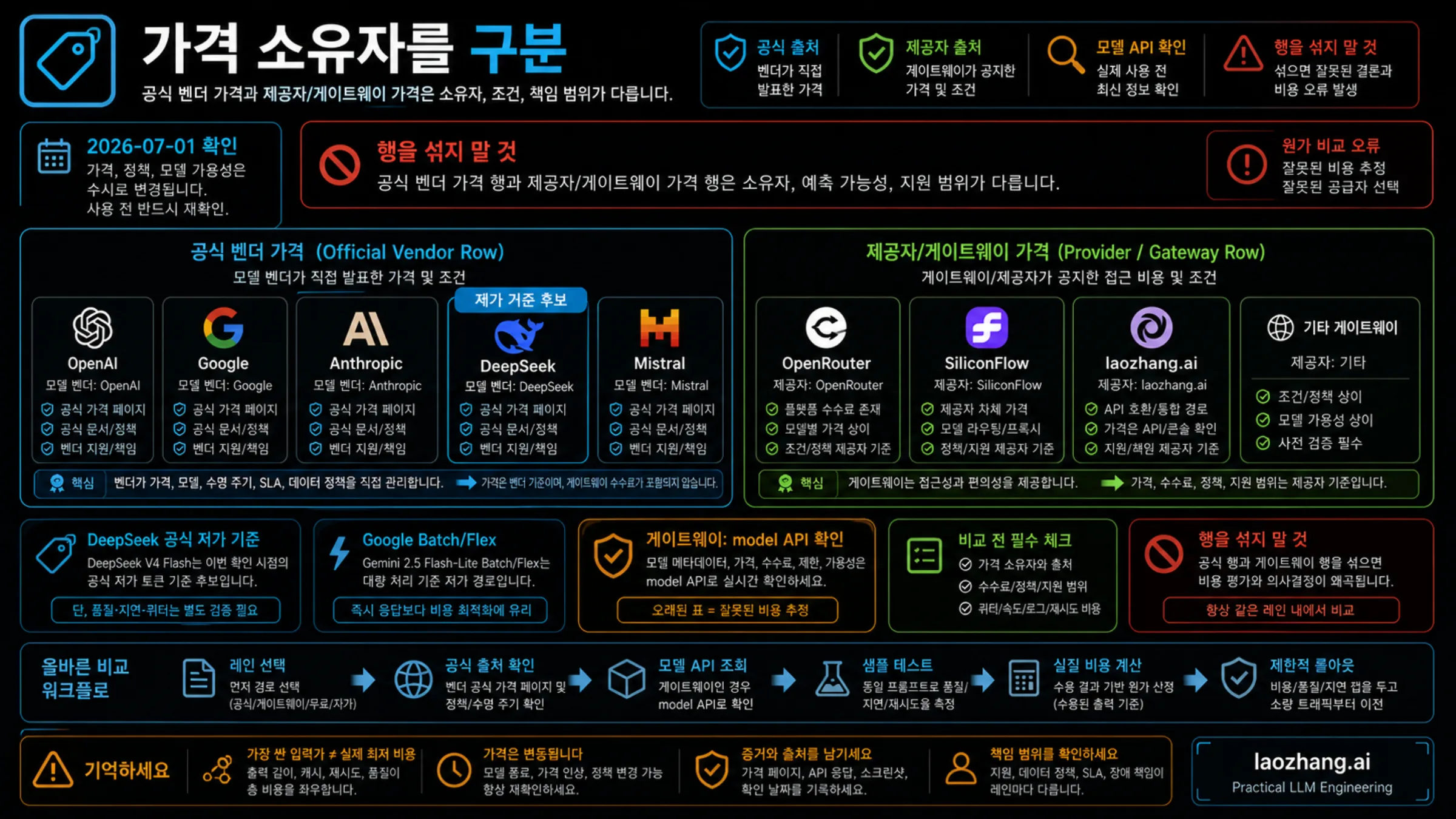
Gateway와 Provider 경로
Gateway와 aggregator는 provider route입니다. API compatibility, model breadth, logs, routing, support consolidation이 platform fee보다 큰 가치를 만들면 실제로 더 저렴할 수 있습니다. 동시에 second contract boundary, region difference, failed-call billing, provider-owned price row라는 위험도 생깁니다.
| Provider route | 확인할 것 | 유용한 경우 | 주장하면 안 되는 것 |
|---|---|---|---|
| OpenRouter | model row, provider route, tokenizer differences, free model limits, Pay-as-you-go 5.5% platform fee | 넓은 catalog, minimum 없는 test, pricing-low-to-high sort를 지원하는 Models API | OpenRouter metadata를 OpenAI, Google, Anthropic, DeepSeek, Mistral의 공식 가격이라고 부르지 않는다. |
| SiliconFlow | provider-owned price, model version, region, terms, current availability | payment, region, operations 때문에 DeepSeek-family provider route가 필요할 때 | SiliconFlow의 DeepSeek row를 DeepSeek direct pricing과 동일하게 취급하지 않는다. |
| laozhang.ai | current model list, feature flags, exact row, billing mode, logs, support path, console/API data | OpenAI-compatible migration, model switching, usage visibility, support owner consolidation이 필요할 때 | 최신 Models API 또는 console 확인 없이 exact per-model price를 공개하지 않는다. |
laozhang.ai는 조건부 후보입니다. gateway access, OpenAI-compatible migration, multi-model coverage check, usage logs, support owner를 합치는 일이 독자에게 중요할 때 비교에 넣습니다. vendor-owned price, official lifecycle, direct support가 필요한 경우에는 공식 API가 더 맞습니다. 공개 문서가 말하는 pay-as-you-go API integration과 OpenAI-compatible Models API는 verification route이지 오래된 가격을 고정해도 된다는 뜻이 아닙니다.
Accepted-Output Cost 계산
실제로 가장 저렴한 provider는 품질 기준을 통과한 accepted output당 비용이 가장 낮은 provider입니다. raw input price만 보면 bill을 움직이는 변수가 빠집니다.
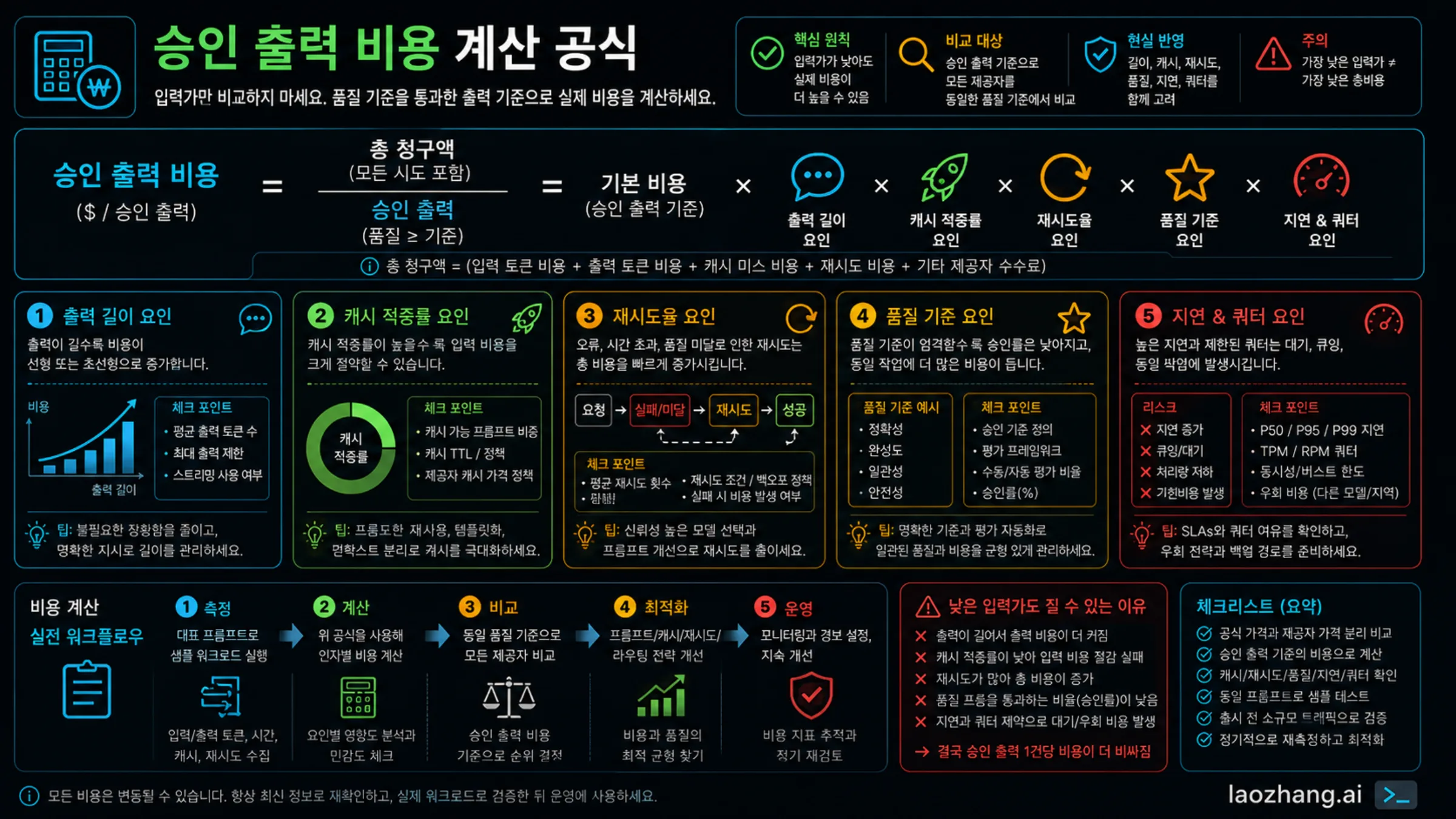
accepted-output cost = sample run의 total bill / acceptance bar를 통과한 output 수.
| Variable | winner가 바뀌는 이유 | 측정할 것 |
|---|---|---|
| Input tokens | system prompt, tool schema, retrieval chunk, history가 짧은 작업에서도 cost를 키운다 | accepted task당 평균 billable input |
| Output tokens | 어떤 model은 review 통과를 위해 더 긴 설명이 필요하다 | accepted output 평균 길이 |
| Cache hit rate | prompt-heavy workflow는 cached input에서 winner가 바뀐다 | cacheable prefix share와 hit percentage |
| Retry rate | timeout, schema failure, weak reasoning, refusal이 billable attempts를 늘린다 | accepted answer당 attempts |
| Quality threshold | 높은 기준은 싼 output을 더 많이 reject한다 | labeled sample의 acceptance rate |
| Latency and quota | rate limit은 비싼 fallback이나 batch delay를 만든다 | P95 latency, TPM/RPM headroom, fallback share |
| Gateway fee | platform fee, markup, failed-call billing, minimum spend가 invoice를 바꾼다 | provider invoice / accepted outputs |
예를 들어 Provider A는 1000개 후보 output에 $0.20만 쓰지만 600개만 통과하면 accepted output당 $0.000333입니다. Provider B는 $0.25를 쓰지만 900개가 통과하면 $0.000278입니다. 가격표에서는 B가 비싸지만 product에서는 B가 저렴합니다. 따라서 같은 spreadsheet에는 bill, acceptance rate, latency, failed attempts, support boundary가 모두 들어가야 합니다.
무료, Trial, BYOK, Self-Hosted
무료 access는 유용하지만 운영 가격은 아닙니다. trial, quota-limited gateway model, education sandbox, temporary promotion인 경우가 많습니다. 각 route는 due diligence를 대체하지 않고 same-prompt test에 evidence를 제공해야 합니다.
| Lane | 적합한 용도 | Hidden cost | Production boundary |
|---|---|---|---|
| gateway의 free model | prototype, demo, prompt comparison | strict limits, lower priority, route changes, fallback behavior | terms, rate limits, uptime을 확인할 때까지 의존하지 않는다. |
| vendor trial credit | 새로운 official API 비교 | expiration, account limits, regional availability | launch math 전에 paid row로 전환한다. |
| BYOK through gateway | vendor account를 유지하면서 router 사용 | gateway fee, key management, support split, data path | failure owner가 vendor인지 gateway인지 알아야 한다. |
| self-hosted open model | data control과 high-utilization workload | GPU utilization, monitoring, quantization quality, maintenance | utilization이 높고 quality가 충분할 때만 저렴하다. |
한국어 실무 비교에서는 무료 API와 저렴한 API를 분리해야 합니다. 무료 route는 검증 evidence를 만들기 위한 것이고, 운영 route는 predictable billing, logs, fallback, support owner가 있어야 합니다.
전환 전 검증 워크플로
가격표만 보고 운영 traffic을 이전하지 않습니다. 가격표로 candidate를 고르고 live route를 검증합니다.

- 공식 model-vendor pricing page에서 direct API row, billing unit, date를 확인한다.
- gateway를 쓰면 provider price를 인용하기 전에 current model/API metadata 또는 console을 확인한다.
- 각 candidate route에 같은 prompt set을 실행한다.
- input tokens, output tokens, cache behavior, failures, retries, latency, accepted outputs를 기록한다.
- total bill / accepted outputs로 비교한다.
- failed-call billing, quota, logs, support owner, data retention, regional terms를 확인한다.
- spend cap, quality fallback, rollback path 아래 작은 traffic slice만 옮긴다.
failed-call billing이 불명확하거나, latency에 concurrency headroom이 없거나, model name이 lifecycle change에 가깝거나, usage logs가 budget control에 부족하거나, data retention이 workload와 충돌하거나, provider가 upstream failure owner를 설명하지 못하면 중단합니다. 모니터링할 수 없는 cheap route는 운영에서는 충분히 싸지 않습니다.
Workload별 첫 테스트
아래 표는 조달 결론이 아니라 첫 번째 test route입니다.
| Workload | First route to test | Backup route | Why |
|---|---|---|---|
| cheap chat, extraction, light summarization | DeepSeek V4 Flash direct | Gemini 2.5 Flash-Lite 또는 OpenAI gpt-5.4-nano | official paid floor에서 시작하고 acceptance rate와 output length를 본다. |
| large asynchronous summarization | Gemini 2.5 Flash-Lite Batch/Flex | OpenAI Batch/Flex low-cost rows | latency가 urgent하지 않으면 batch-style lane이 더 싸질 수 있다. |
| many candidate models의 OpenAI-compatible migration | OpenRouter 또는 laozhang.ai, live verification 후 | winning model의 official direct API | gateway convenience는 fee와 source-owner check 후 평가한다. |
| DeepSeek-family provider route | DeepSeek direct first, 필요하면 SiliconFlow | verified metadata가 있는 다른 gateway | provider-owned DeepSeek row에는 provider label과 current verification이 필요하다. |
| coding or agentic tasks | DeepSeek, OpenAI, Claude, gateway fallback same-prompt test | lowest accepted-output cost model | retry rate와 tool reliability가 raw token price보다 중요할 수 있다. |
| governance-sensitive workload | 필요한 region/data terms를 충족하는 Mistral 또는 direct route | realistic한 BYOK/self-hosting | compliance와 data owner는 추가 비용을 정당화할 수 있다. |
하나의 product가 여러 provider를 쓰는 것도 자연스럽습니다. classifier는 cheap official row, coding assistant는 stronger model, gateway는 fallback routing만 맡을 수 있습니다. 모든 작업을 한 provider에 강제로 몰면 오히려 비싸질 수 있습니다.
Provider Checklist
가장 저렴하다고 말하기 전에 다음 질문에 답합니다. 가격표의 owner는 model vendor, gateway, cloud platform, reseller, infrastructure team 중 누구인가. row는 input-only, output-only, cached input, batch/flex, per request, per second, tool-call 중 무엇인가. 대상 model version, region, lifecycle status는 무엇인가. failed calls, timeouts, safety refusals, retries는 어떻게 과금되는가. RPM, TPM, daily quota, spend-limit behavior는 어떻게 작동하는가. logs, usage export, alerting이 budget control에 충분한가. upstream model failure의 support owner는 누구인가. data retention, training, regional terms가 task와 맞는가. same-prompt set이 선택한 quality bar를 통과하는가. rollout에는 failure가 open-ended bill을 만들지 않도록 cap이 있는가.
이 checklist는 price table보다 엄격합니다. 가격을 deployable cost로 바꾸기 위한 장치이기 때문입니다. model name, platform fee, free-route rule이 바뀔 때 team이 돌아볼 수 있는 audit trail도 됩니다.
자주 묻는 질문
지금 가장 저렴한 LLM API provider는 어디인가요?
2026-07-01에 확인한 공식 유료 token floor 기준으로는 DeepSeek V4 Flash가 이번 비교에서 가장 낮은 row입니다. 하지만 모든 workload에서 실무상 가장 저렴하다는 뜻은 아닙니다. output length, cache rate, retries, latency, quota, gateway fee, support owner를 포함해 accepted-output cost를 비교해야 합니다.
OpenRouter가 direct API보다 더 저렴한가요?
경우에 따라 그렇습니다. OpenRouter는 integration work를 줄이고 하나의 gateway로 많은 model을 제공하지만 Pay-as-you-go에는 platform fee가 있고 가격은 선택한 route에 따라 다릅니다. gateway-owned metadata로 보고 운영 전 live row를 확인합니다.
laozhang.ai를 가장 저렴한 provider로 써야 하나요?
laozhang.ai는 OpenAI-compatible API migration, model switching, usage visibility, support owner consolidation이 필요한 gateway 작업에 맞습니다. current Models API 또는 console row가 exact model price를 증명하지 않는 한 가장 저렴하다고 단정하지 않습니다.
무료 LLM API를 운영에 써도 되나요?
limits, terms, uptime, quota, logs, support path를 확인하기 전까지는 아니라고 보는 것이 안전합니다. 무료 route는 prompt comparison과 early prototype에 좋습니다. 운영에는 predictable billing과 rollback이 필요합니다.
낮은 input price가 왜 질 수 있나요?
bill은 input tokens만이 아닙니다. long outputs, 낮은 cache hit, schema failure, retries, stricter review, latency fallback, gateway fee가 accepted-output cost를 올립니다.
가격은 얼마나 자주 다시 확인해야 하나요?
운영 migration 전, 큰 volume increase 전, model lifecycle note, platform fee, free-route term이 바뀔 때 다시 확인합니다. 날짜가 붙은 가격은 cutoff 전에 scheduled recheck를 둡니다.
Bottom Line
공식 token floor는 첫 후보를 고르는 데 사용하고 최종 provider 결정에는 쓰지 않습니다. DeepSeek V4 Flash는 많은 text workload에서 첫 paid test가 될 수 있습니다. Gemini 2.5 Flash-Lite Batch/Flex는 asynchronous scale에서 진지하게 테스트할 만합니다. OpenAI, Anthropic, Mistral은 compatibility, quality, governance, reliability가 rejected output을 줄일 때 이길 수 있습니다. OpenRouter, SiliconFlow, laozhang.ai 같은 gateway는 routing, logs, API compatibility, support consolidation이 provider fee보다 큰 가치를 만들 때 이깁니다. 마지막 판단은 current row를 확인하고, same prompt를 실행하고, full bill을 accepted outputs로 나누고, cap 아래 rollout하는 것입니다.