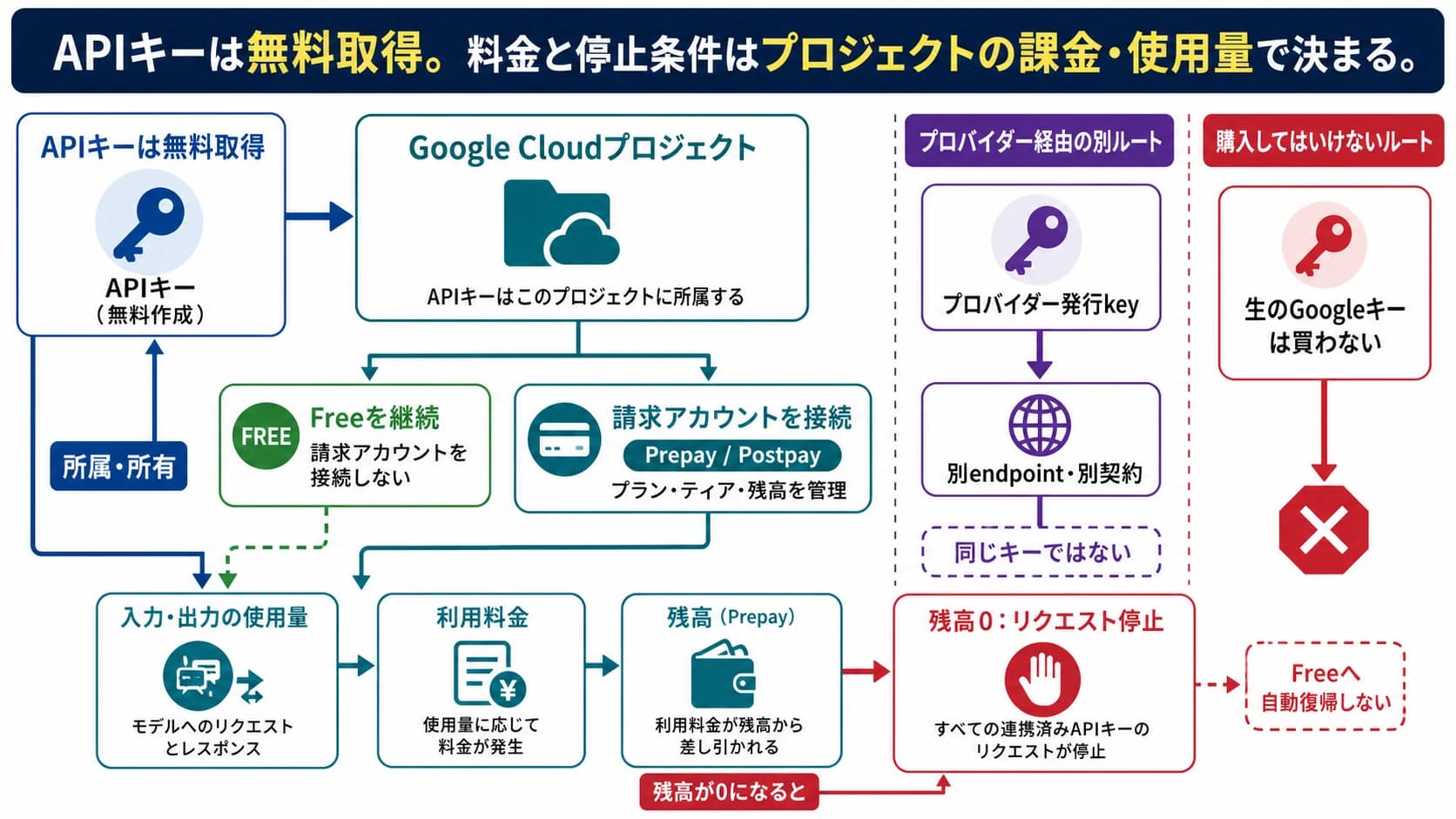
Realtime API と文字起こしパイプラインを比べるとき、最初に見るべきものは 1 分あたりの価格ではありません。プロダクトが会話中にユーザーを理解し、割り込みを受け、tool を呼び、自然な音声で即時に返す必要があるかを先に決めます。そのライブ音声対話が価値なら gpt-realtime-2 の追加コストは検討対象です。最終成果物が transcript、summary、archive、QA、compliance trail、analytics feed なら、まず文字起こし優先のルートで見積もります。
価格表を見る前にルートを分けます。
- ライブ音声エージェント:音声品質、割り込み、ターン交代、低遅延、会話中の tool use が価値なら
gpt-realtime-2を使います。 - ライブ文字起こしだけ:話している途中に文字が必要で、音声で返す assistant が不要なら
gpt-realtime-whisperを見ます。 - 録音またはファイルの文字起こし:音声をアップロード、録音後処理、または request として処理できるなら
gpt-4o-transcribeとgpt-4o-mini-transcribeを比較します。 - 自社パイプライン:STT、text model、optional TTS、telephony、storage、monitoring、QA は、本当に必要な component だけを足します。
- ハイブリッド:価値の高いライブ区間だけ Realtime を使い、アーカイブ、レビュー、要約、分析は文字起こし優先にします。
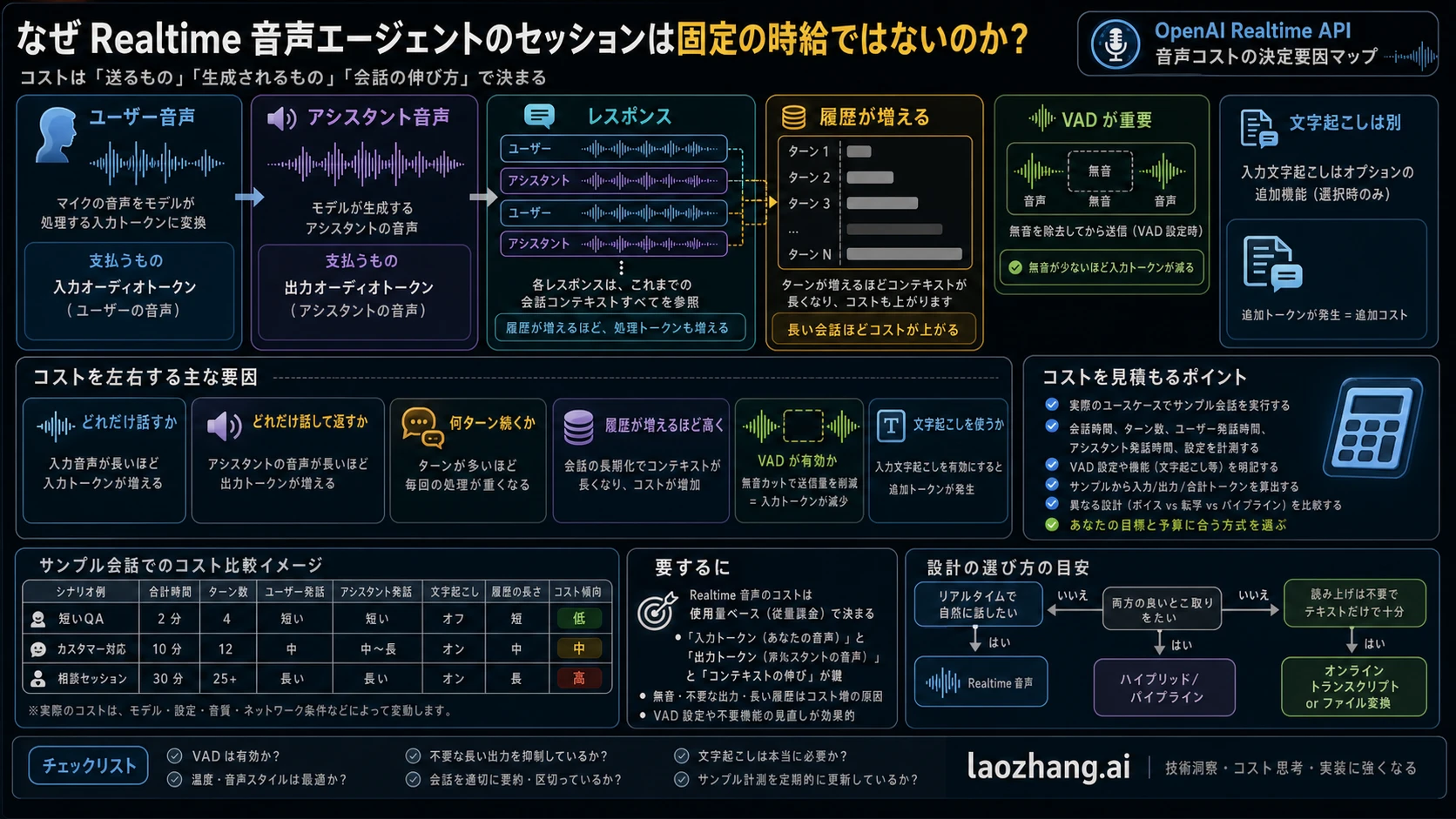
2026 年 6 月 14 日時点で、OpenAI は gpt-realtime-whisper を $0.017/minute、gpt-4o-transcribe を estimated $0.006/minute、gpt-4o-mini-transcribe を estimated $0.003/minute と掲載しています。単純換算では $1.02/hour、$0.36/hour、$0.18/hour です。一方で gpt-realtime-2 の音声エージェントは audio input と audio output を token で課金します。1 時間分の user audio と 1 時間分の assistant audio が計上されると media-token floor は $5.76/hour になりますが、ここには text tokens、tool calls、会話履歴の再送、optional input transcription、telephony、後処理 pipeline は含まれていません。
停止ルールは明確です。text で足りるなら、spoken assistant output に払わない。以下では、低遅延の音声に追加費用を払うべき場面、Realtime cost が増える理由、pipeline 側で変動費として残すべき component をワークシートに落とします。
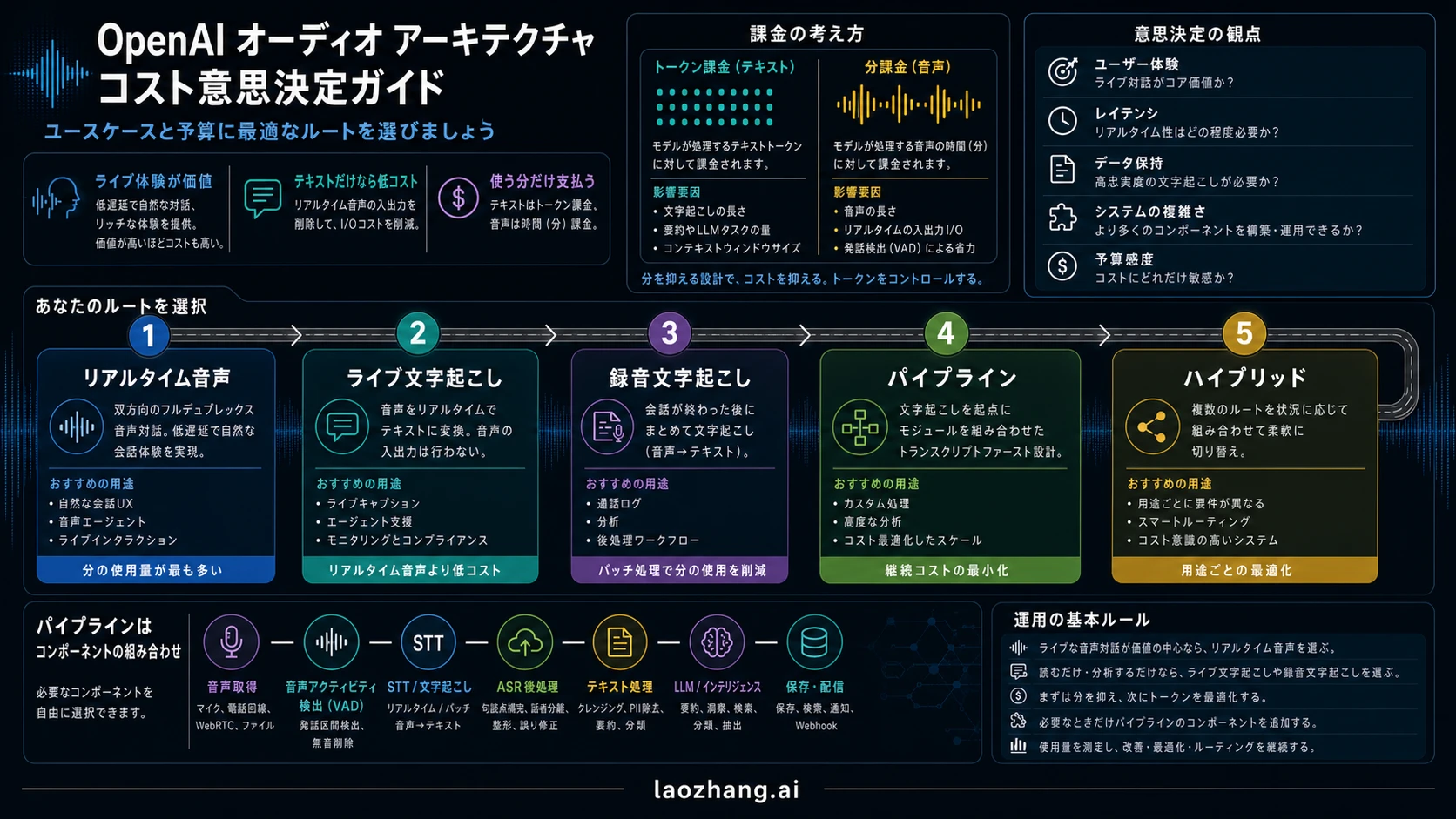
まずプロダクトの仕事でルートを選ぶ
「Realtime API か文字起こしパイプラインか」という問いは、抽象的な価格比較ではありません。先にプロダクトの仕事を決め、次に OpenAI のルートを決め、最後に billing unit を見ます。この順番を逆にすると、ライブ音声エージェントとライブ字幕を同じ Realtime と呼んでしまい、予算がずれます。
| プロダクトの仕事 | まず見積もるルート | モデル化する単位 | 使う場面 | 停止ルール |
|---|---|---|---|---|
| ライブ音声エージェント | gpt-realtime-2 | Response ごとの audio と text tokens | ユーザーが割り込み、turn-taking、tool use、音声応答を必要とする | text output で足りるならここから始めない |
| ライブ文字起こしだけ | gpt-realtime-whisper | live audio minutes | 話している最中の文字だけが必要 | audio が待てるなら bounded transcription を先に見る |
| 録音音声を text にする | gpt-4o-transcribe または gpt-4o-mini-transcribe | submitted audio minutes | files、recordings、post-call review、summaries、QA、compliance | live deltas が必須なら realtime transcription へ |
| 自社 pipeline | STT -> text model -> optional TTS -> operations layer | component ごとの meter | control、vendor mix、telephony fit、auditability、component optimization が必要 | TTS、telephony、text model を無条件に足さない |
| Hybrid | live moment は Realtime、back office は transcription-first | combined meters | live help に価値があるが、archive や analytics は音声を要しない | live session の終点と back office の起点を測る |
この表は、音声プロダクトを同じ箱に入れてしまう予算ミスを防ぎます。音声エージェントは interactive spoken loop を買っています。文字起こしパイプラインは text と downstream processing を買っています。同じ audio から始まっても、購入している成果物は違います。
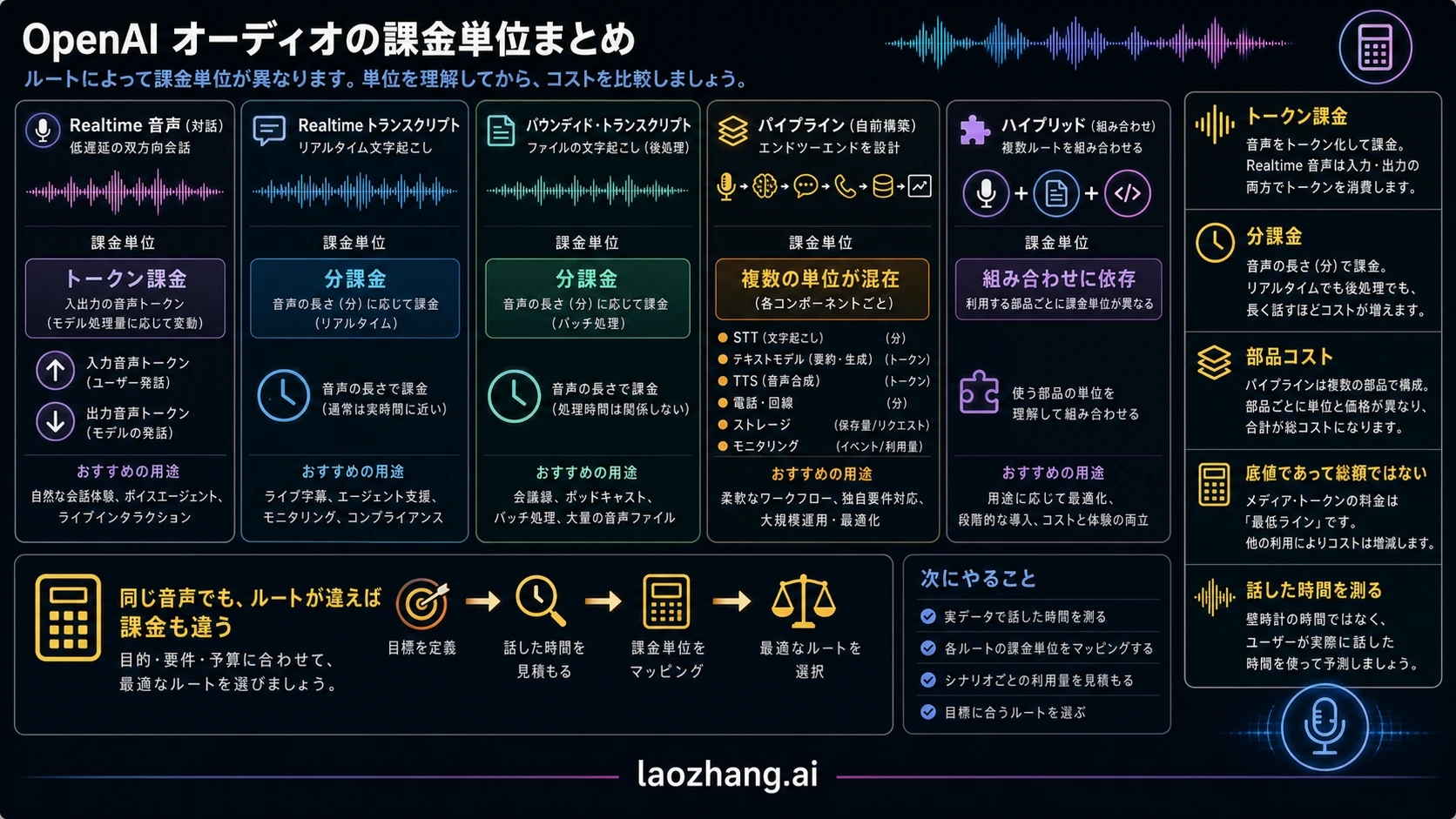
いま参照すべき OpenAI 公式価格
OpenAI の現在の price row を anchor にし、そこへ自社の measured workload を足します。2026 年 6 月 14 日に OpenAI pricing page で確認した、この判断に関係する row は次の通りです。
| ルート | 現在の OpenAI price row | 時間あたりの感覚 | 含まれていないもの |
|---|---|---|---|
gpt-realtime-whisper | $0.017/minute | 直接換算 $1.02/hour | text model work、storage、monitoring、telephony、non-OpenAI components |
gpt-4o-transcribe | estimated $0.006/minute | 直接換算 $0.36/hour | post-processing、summaries、classification、storage、orchestration |
gpt-4o-mini-transcribe | estimated $0.003/minute | 直接換算 $0.18/hour | accuracy review、domain vocabulary、post-processing、operations work |
gpt-realtime-2 audio input | $32.00/1M audio input tokens | user audio 1 token/100 ms で $1.152/hour | assistant audio、text、tools、history growth、optional transcription、pipeline components |
gpt-realtime-2 audio output | $64.00/1M audio output tokens | assistant audio 1 token/50 ms で $4.608/hour | user audio、text、tools、history growth、optional transcription、pipeline components |
分単位の文字起こしはそのまま換算できます。
textgpt-realtime-whisper: 60 minutes * $0.017 = $1.02/hour gpt-4o-transcribe: 60 minutes * $0.006 = $0.36/hour gpt-4o-mini-transcribe: 60 minutes * $0.003 = $0.18/hour
gpt-realtime-2 の media-token floor も計算できます。ただし floor であって見積書ではありません。
textUser audio input: 36,000 tokens/hour * $32 / 1,000,000 = $1.152/hour Assistant audio output: 72,000 tokens/hour * $64 / 1,000,000 = $4.608/hour Media-token floor: $1.152 + $4.608 = $5.76/hour
$5.76/hour を Realtime の最終時間単価と呼んではいけません。これは 1 時間の user audio と 1 時間の assistant audio だけを置いた floor です。text tokens、tool schemas、tool results、instructions、repeated history、optional input transcription、special tokens、telephony、storage、monitoring は別です。
Realtime 音声エージェントのコストが増える理由
Realtime cost guide は、voice-agent session が単純な audio file と違う理由を示しています。Cost は Response が作られたときに発生し、input/output tokens に基づきます。Input transcription を有効にすれば、その transcription model は別料金です。Connections と network bandwidth は現時点で別課金されないと説明されていますが、会話中に Responses が作られればコストは発生します。
実務上の driver は次の通りです。
- User audio:1 token per 100 ms。
- Assistant audio:1 token per 50 ms。長い音声回答は floor を押し上げます。
- Response count:各 Response が新しい generation event です。
- Conversation history:以前の会話内容が再び送られ、後半 turn が高くなることがあります。
- Empty audio control:VAD が silence を削れる一方、client が手動で追加すると無駄になります。
- Text and tool work:instructions、tool schemas、tool results、text output も token を使います。
- Optional input transcription:会話内 transcript が必要なら別の transcription cost が乗ります。
そのため、「Realtime は 1 時間いくら」と一行で答えるのは launch planning には弱すぎます。60 分の support call で assistant が短く答えるだけのケースと、20 分の tutoring session で assistant が長く話し、tools を使い、長い context を持つケースでは、後者のほうが高くなることがあります。
節約は route を変える前に session design から始めます。VAD を効かせて silence を input に入れない。old history が答えを改善しなくなったら session を終えるか summarize する。tool schemas と system instructions を短くする。短い答えで足りるなら monologue を避ける。input transcription は本当に会話内 transcript が必要なときだけ有効にする。pilot では Response count、assistant speech duration、late-turn history size を必ず測ります。
Realtime の利点も明確です。gpt-realtime-2 は low latency、interruption handling、voice response quality、会話中の tool use を 1 つの session で扱います。これが conversion、containment、accessibility、task completion を上げるなら、追加費用は product value の一部です。
文字起こし優先パイプラインのコストモデル
文字起こし優先は、最初の paid step を plain speech-to-text にできるため安く始まりやすいです。Files と bounded audio については Speech to text guide が gpt-4o-transcribe、gpt-4o-mini-transcribe、gpt-4o-transcribe-diarize を示します。File uploads は 25 MB cap があり、live transcript deltas とは形が違います。Spoken assistant なしで live text が必要なら Realtime transcription guide の gpt-realtime-whisper が近い route です。
ただし、製品が text 以外も作るなら STT で止めないでください。Summary、extraction、routing、QA、coaching、moderation、analytics、compliance をするなら stack 全体を数えます。
| Component | Count as | Price treatment |
|---|---|---|
| Audio capture and transport | app、browser、WebRTC、telephony、recording infrastructure | stack と region による variable |
| STT | gpt-realtime-whisper、gpt-4o-transcribe、gpt-4o-mini-transcribe | OpenAI minute rows が estimate の anchor |
| Text model | summarization、extraction、routing、QA、coaching、moderation、agent logic | model、tokens、cache、retries で変わる |
| Optional TTS | text processing 後の speech output | launch route で検証するまで variable |
| Telephony | PSTN、SIP、call recording、phone numbers、compliance features | provider と region で確認 |
| Storage and retrieval | audio files、transcripts、embeddings、logs、retention policy | privacy と retention で変わる |
| Monitoring and QA | human review、audits、metrics、failure replay、alerting | regulated workflow では STT row より大きいこともある |
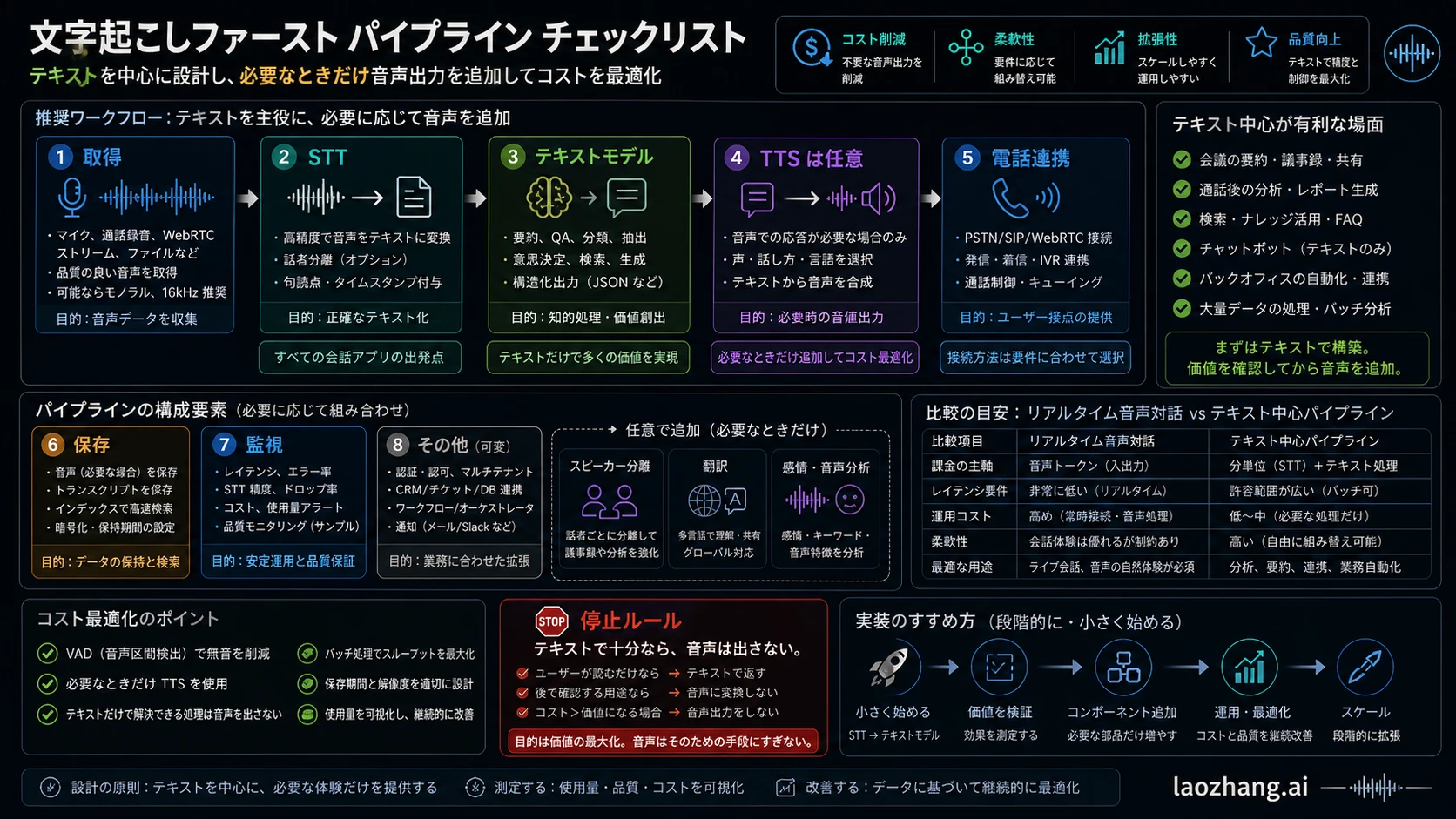
この pipeline は、spoken output が不要な製品では Realtime voice-agent session より予測しやすく、安くなることが多いです。Debug しやすい点も大きいです。Audio、transcript、text-model output、summary、classification、audit log という artifact が残るため、再処理や比較ができます。
弱点は latency と integration load です。STT -> text model -> TTS を streaming しても、native spoken session になるわけではありません。Text-centered workflow、component control、auditability が必要だから選ぶのであって、STT row が安いから全体も必ず安いと考えないでください。
ライブ音声に払う価値がある場面
gpt-realtime-2 に払うのは、session 中の spoken interaction が user behavior を変える場合です。Sales や onboarding call、割り込みが重要な tutoring や coaching、accessibility flow、通話中に tools を呼ぶ voice agent、speech quality が interface になる consumer experience、human escalation を減らす support containment が候補です。
Pilot question は「Realtime は STT より高いか」ではありません。「live speech が追加 meter を上回る value を作るか」です。測るべき指標は次の通りです。
| Metric | Why it matters |
|---|---|
| real user talk time | counted user audio を決める |
| assistant speech time | audio output を決め、media-token floor を支配しやすい |
| Responses per session | generation event の数を決める |
| average history size by turn | late-session cost growth を示す |
| tool calls per session | hidden text と tool context を捕捉する |
| completion or containment lift | voice loop が回収できるかを見る |
| human fallback rate | transcription route で足りたケースを見つける |
これらの metrics が business outcome や user outcome を改善しているなら、Realtime は raw hourly row が高くても正しい支出になります。改善が見えないなら、すべての audio workflow を Realtime に広げないことが重要です。
文字起こし優先が勝つ場面
Text が最終 artifact なら transcription-first から始めます。Meeting summaries、call QA、compliance review、searchable archives、support analytics、coaching notes、review が必要な medical/legal intake draft、asynchronous voice notes、post-call classification は典型例です。
停止ルールは仕様に書けます。User が assistant の声を必要としないなら assistant audio output に払わない。Transcript が audio 終了後でよいなら bounded transcription を先に見る。Live captions だけなら gpt-realtime-whisper を gpt-realtime-2 より先に見る。Summaries と classifications が capture 後なら、STT row ではなく text-model work として budget する。Compliance trail が必要なら、pipeline artifacts は live spoken loop より inspect しやすいことが多いです。
この route は quality gate も作りやすいです。Original audio を保存し、transcription を rerun し、model outputs を比較し、prompt changes を検査し、non-urgent work を batch し、high-risk samples だけ human review に回せます。Operations teams にとって、この control は数秒の latency より価値があります。
ハイブリッド:Realtime を価値のあるライブ区間に限定する
Production では hybrid が現実的です。Speech が result を変える live segment だけ Realtime を使い、spoken output が不要な archive、review、compliance、analytics は transcription-first に渡します。
単純な hybrid sequence は次の通りです。
- Interruption、turn-taking、speech が必要な live interaction のときだけ
gpt-realtime-2session を開始する。 - User audio duration、assistant audio duration、Response count、tool calls、input transcription の有無を記録する。
- Transcript artifact は product と privacy policy が必要とする場合だけ保存または export する。
- Post-call summaries、QA、compliance classification、analytics、search indexing は text route か transcription-first route で実行する。
- Live boundary と back-office boundary が安定するまで sample sessions を weekly review する。
これにより、高い route は本当に必要な部分にだけ結びつきます。Onboarding agent は call の間だけ Realtime を使い、CRM notes と QA は後で処理できます。Call-center monitor は supervisor visibility のために live transcription を使い、voice agent を全時間しゃべらせない選択ができます。Voice note app は、正確な text と clean summary が後で出ればよいので Realtime を使わない可能性があります。
Hybrid の設計で大切なのは live value の終点です。そこを越えた step は、なぜ realtime speech が必要なのかを毎回再説明しなければなりません。
予算ワークシート
少なくとも 3 つの estimate を作ります。transcription-only、Realtime media floor、full pipeline です。最初は公式 row を入れ、pilot data で置き換えます。
| Worksheet line | Formula |
|---|---|
| Live transcript-only cost | live_audio_minutes * $0.017 for gpt-realtime-whisper |
| Bounded high-accuracy transcription cost | audio_minutes * $0.006 for gpt-4o-transcribe |
| Bounded low-cost transcription cost | audio_minutes * $0.003 for gpt-4o-mini-transcribe |
| Realtime user-audio floor | user_audio_hours * $1.152 for gpt-realtime-2 audio input |
| Realtime assistant-audio floor | assistant_audio_hours * $4.608 for gpt-realtime-2 audio output |
| Realtime media-token floor | user_audio_floor + assistant_audio_floor |
| Realtime session estimate | media floor + text tokens + tool tokens + history growth + optional input transcription |
| Pipeline estimate | STT + text model + optional TTS + telephony + storage + monitoring + QA |
Low、typical、high の 3 ケースで回します。Realtime では user talk time より先に assistant speech time と Response count を動かしてください。ここが margin risk を出しやすいです。Transcription-first では audio duration、text-model output length、retry rate、storage retention、human-review load を変えます。
Launch 前には real pilot sessions から evidence を集めます。Median と p95 の user audio duration、assistant audio duration、Response count、late turn の average history size、input transcription usage、tools と follow-up processing の text tokens、failed/retried sessions、transcript ごとの human review minutes、launch date の OpenAI price rows です。
Deploy 日に価格を再確認します。Model IDs、availability、minute rows、token rows、account-specific access は変わり得ます。古い calculator はすぐ古くなります。
よくある質問
Realtime API は常に文字起こしパイプラインより高いですか?
常にではありません。Realtime voice-agent session は plain transcription より高い floor を持ちやすいですが、重要なのは live spoken interaction が価値を作るかです。Interruption、low latency、tool use、spoken output が必要なら払う意味があります。Text artifact が目的なら transcription-first が始めやすく、予算化しやすいです。
gpt-realtime-whisper と gpt-realtime-2 は同じですか?
違います。gpt-realtime-whisper は transcript deltas が必要な live transcription-only workflow 向けです。gpt-realtime-2 は live spoken assistant session の Realtime voice-agent route です。同じ Realtime として扱うと cost comparison が壊れます。
なぜ $5.76/hour を Realtime の時間単価と言えないのですか?
それは current gpt-realtime-2 audio token rows から出した media-token floor だからです。Text tokens、repeated history、tools、optional input transcription、special tokens、telephony、pipeline components は含まれていません。
ライブ字幕にはどの route を使うべきですか?
まず realtime transcription-only を見ます。Spoken assistant なしで live transcript deltas が必要なら gpt-realtime-whisper が価格を見る route です。Audio が recording 後でよいなら gpt-4o-transcribe と gpt-4o-mini-transcribe を比較します。
自社 STT -> LLM -> TTS pipeline は常に Realtime より有利ですか?
いいえ。Text-centered work、compliance、telephony、debugging、vendor mix には有利なことがありますが、integration work と component latency が増えます。Natural interruption と spoken response quality が体験の中心なら、native Realtime session のほうがよいことがあります。
最も安全な production rule は何ですか?
まず route を選び、OpenAI が直接価格を出している部分は current official rows で anchor し、それ以外は variable として pilot で測ります。Text で足りるときは spoken assistant output に払わず、media-token floor を final bill と呼ばないことです。