今すぐモデルが必要なら、まずGPT-5.4を使うべきです。Claude Mythos PreviewはAnthropicが公開した複数のベンチマークで強く見えますが、現時点では招待参加者向けのresearch previewであり、読み終えたあとすぐに誰でも選べる通常の公開モデルではありません。
2026年4月9日時点で、OpenAIはGPT-5.4がChatGPT、API、Codexで利用可能だと案内しています。一方でAnthropicはMythos PreviewをProject Glasswingのパートナーとその他の招待組織に限定しています。つまりこのページが先に答えるべきなのはベンチマークの勝敗ではなく、今どのルートを使うべきかという判断です。多くの読者にとっては、今はGPT-5.4を使い続け、Mythosはpreview対象の中にいる場合かfuture-tier evalsを担当している場合にだけ真剣に追う、というのが正しい結論になります。
まず結論
見出しだけを見ると普通の「どちらが強いか」比較に見えるかもしれませんが、実際に役立つ答えはもっと狭いです。
| 本当の質問 | 今すぐ取るべき行動 | 理由 |
|---|---|---|
| 「今日すぐ使えるモデルはどちらか」 | GPT-5.4 | ChatGPT、API、Codexですでに利用できます。 |
| 「Mythos Previewは誰でも買える公開代替なのか」 | 違う | Anthropicは招待制のresearch previewとして扱っています。 |
| 「Mythosの登場で今のGPT-5.4の選択を変えるべきか」 | たいていは変えなくてよい | ベンチマーク優位だけではアクセス差は消えません。 |
| 「ではいつMythosを追う価値があるのか」 | すでに招待されている時、またはfuture-tier evalsを回している時 | その段階で初めてベンチマークが実務上の入力になります。 |
ここで一番誤解しやすいのは、「両社とも本物の事実を出している」ことと「両社が同じ種類の契約を出している」ことを混同する点です。AnthropicはMythos Previewについて、participant pricingと強い初期ベンチマークを実際に公開しています。OpenAIもGPT-5.4について、公開提供状況と公開価格を実際に示しています。ただし重要なのは、それらが同じ層の契約ではないことです。片方は閉じたpreview、もう片方は今日から使える公開ルートです。
Claude Mythos Previewは今どういう存在なのか

Claude Mythos Previewは実在しますが、通常の公開モデル契約ではありません。Anthropicは、Project Glasswingのパートナーと、重要インフラやセキュリティに関わる40超の招待組織に提供していると説明しています。これはMythosを真面目に扱うには十分です。しかし、一般読者がこの記事を読んだあと、そのまま導入先として選べるモデルだと見なすには不十分です。
価格面も同じ境界を示しています。Anthropicは、初期usage credits期間の後は入力100万トークンあたり25ドル、出力100万トークンあたり125ドルというparticipant pricingを示しています。これ自体は重要な数字ですが、意味を持つのはすでにpreview対象の中にいる人だけです。GPT-5.4のAPI価格のように、誰でも今日の予算や導入判断にそのまま入れられる価格ではありません。先にアクセスの門を越える必要があるからです。
さらに重要なのは、Anthropicが2026年4月9日時点でClaude Mythos Previewを一般提供する予定は今のところないと書いている点です。これは、将来AnthropicがMythos級の公開モデルを別の契約で出さないという意味ではありません。ただ、少なくとも今の判断では、Mythos Previewを「もうすぐ普通の公開メニューに並ぶ候補」として扱うべきではない、という意味です。
したがって、いちばん安定した理解はこうです。Mythos Previewはfrontier capabilityのシグナルであって、今日の標準ルートではありません。Anthropicの上位性能が再び伸びている可能性を示す価値はありますが、そのことだけで、一般ユーザーが今使えるモデル選びをGPT-5.4から切り替える理由にはなりません。
GPT-5.4が今すぐ使える理由
GPT-5.4はまったく別の種類の存在です。OpenAIは2026年3月5日にGPT-5.4を発表し、ChatGPT、API、Codexで利用できると案内しました。この比較では、利用可能であることは脇役ではなく答えの一部です。多くの読者が本当に知りたいのは、どの研究所がより印象的かではなく、今日どのルートなら実際に動かせるかだからです。
価格もそのまま意思決定に載せやすい形で公開されています。OpenAIは入力100万トークンあたり2.50ドル、キャッシュ済み入力100万トークンあたり0.25ドル、出力100万トークンあたり15ドルと案内しています。長いコンテキストが必要なワークフロー向けには、APIとCodexで最大1Mトークンのコンテキストをサポートするとしています。つまりGPT-5.4の現在の契約は、予算を組み、テストし、導入し、チームに説明するところまでを今日の時点で進められる公開ルートです。
だからこそ、Anthropicのベンチマーク物語を認めたうえでも、GPT-5.4が多くの人にとっての標準ルートに残ります。標準ルートとは、未来感の強い見出しを持つモデルではなく、今週の仕事を実際に流せるモデルです。次に知りたいことがGPT-5.4のアクセス経路や費用感なら、GPT-5.4 free APIのガイドがより実務的です。Codex側の自動化や開発フローが中心なら、2026年3月のOpenAI Codexアップデートの方が次の一歩として役立ちます。
この比較を抽象的な「モデル品質」の話だけに落としてはいけない理由もここにあります。多くの読者にとっての判断面は、「どの研究所がすごいか」ではなく、「閉じたpreviewにもう入っているふりをせずに、今日使えるルートはどれか」です。
公式の重複ベンチマークが示すことと、示さないこと
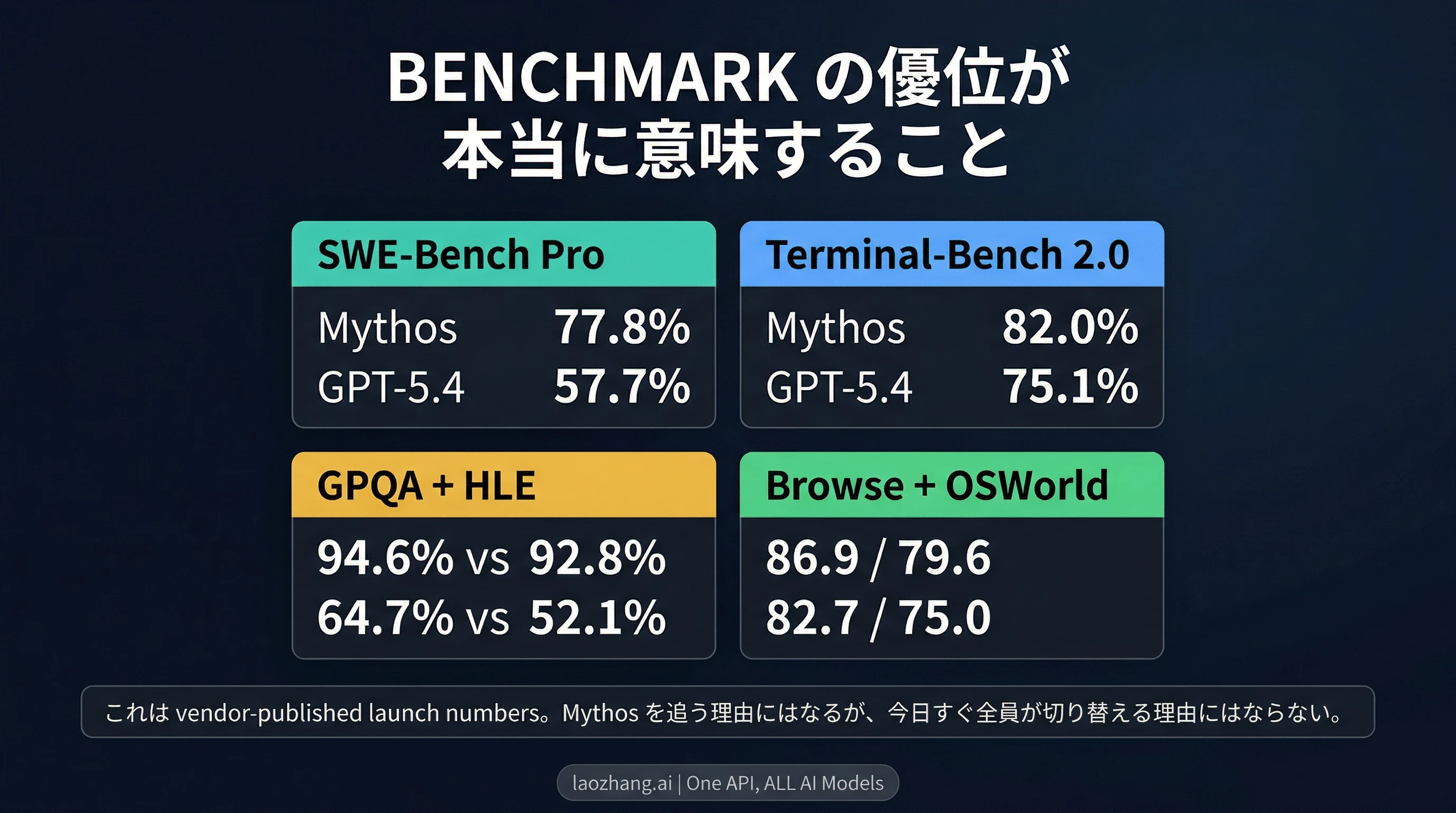
Mythos Previewが重複する評価名で公式にリードしているのは事実です。AnthropicのProject Glasswingページでは、Mythos PreviewについてSWE-Bench Pro 77.8%、Terminal-Bench 2.0 82.0%、SWE-Bench Verified 93.9%、GPQA Diamond 94.6%、Humanity's Last Exam with tools 64.7%、BrowseComp 86.9%、OSWorld-Verified 79.6%が示されています。OpenAIのGPT-5.4発表ページでは、SWE-Bench Pro 57.7%、Terminal-Bench 2.0 75.1%、GPQA Diamond 92.8%、Humanity's Last Exam with tools 52.1%、BrowseComp 82.7%、OSWorld-Verified 75.0%が示されています。
この差は、Mythosを単なる噂や話題先行で片付けてはいけない理由になります。もしAnthropicが、目立つ優位のない閉じたpreviewだけを出していたなら、実用的な助言はほとんど変わらず、このテーマにこれほど画面を割く必要もありませんでした。だからこそ、このページは存在する価値があります。
ただし、その表は中立的で万能な総合順位表を与えてくれるわけではありません。AnthropicもOpenAIも、それぞれ自社の公式ローンチ面で数字を出しています。重複する評価名には十分な参考価値がありますが、それでもなおvendor-published launch numbersであって、完全に同一設定、同一ツール、同一予算で回された単一の共通スコアボードではありません。したがって正しい読み方は、「Mythosの優位は無視できない」なのであって、「Mythosがあらゆる現在の買い方と運用判断を完全に置き換えた」ではありません。
この注意書きは文章上の逃げではなく、ルート判断そのものを変える境界です。ベンチマーク優位は、top-tier codingやreasoning、security-adjacent evalsを追う人にとってMythosをwatchlistに載せる理由になります。しかしそれだけで、一般ユーザーが今アクセスできて、試せて、導入できるモデルを捨てる理由にはなりません。
Mythosを本当に追うべきタイミング

大半の読者にとって、Mythosは今の計画を変える理由にはなりません。今日必要なモデルを選ぶなら、答えはまだGPT-5.4です。アクセス、価格、導入という現在形の判断に必要な条件を、GPT-5.4はすでに満たしているからです。将来のpreview契約が魅力的に見えるからといって、今動く仕事を待ちの姿勢に変えるメリットはあまりありません。
一方でもっと早い段階からMythosが重要になる読者もいます。すでにpreview対象の中にいるなら、比較はもう抽象論ではありません。その場合は、Mythosが自分たちのワークロードでどれだけ改善し、評価や運用調整、将来の移行準備に見合うかを本当に見に行く価値があります。また、frontier-model watchlistやsecurity評価、上位コーディング系のエスカレーション設計を担当している人にとっても、Mythosは単なるニュースではなく、将来の上位ティアに備えるシグナルです。
それ以外の多くの人にとって、Mythosは「今の行き先」ではなく「追跡対象」として扱うのが最も安定します。今のGPT-5.4業務を進め、比較のための基準線を維持し、アクセス境界が変わるか自組織がpreviewに入った時にだけ追加コストを払う。この姿勢の方が、将来性能が強そうだからという理由だけで現実の仕事を止めるよりずっと合理的です。
本当の質問がもっと広いなら
このページが最も役立つのは、「GPT-5.4が今日すでに使える状況で、Mythosのベンチマーク優位は今の選択を変えるべきか」という狭い問いに答える時です。
もし本当の問いが「公開ルートとしてChatGPTとClaudeのどちらを使うべきか」なら、読むべき次のページはChatGPT vs Claudeです。あちらはpublic-vs-publicの選択を扱い、コーディング、文章作成、価格、全体のプロダクト差分をより広く整理しています。
もし本当の問いが「Anthropicの中で、今出荷されているモデルを使うべきか、それともpreview tierを追うべきか」なら、Claude Capybara vs Opus 4.6の方が合っています。そちらはAnthropic内部のルート境界に正面から答えるページです。
外へルーティングするのは話題から逃げるためではありません。むしろ、このページを有用なまま保つためです。Mythosのベンチマーク優位は本物ですが、preview対象の中にいない限り、GPT-5.4が今のdeployable defaultである、という細い答えに焦点を保つほどこのページは強くなります。
FAQ
「Claude Mythos」とClaude Mythos Previewは同じものですか
現在の公開文脈では、「Claude Mythos」は公式名称であるClaude Mythos Previewの略称として使われることがほとんどです。重要なのは略称か正式名かではなく、Anthropicがそれを公開self-serve製品ではなく、閉じたpreviewとして扱っていることです。
Mythosのparticipant pricingがあれば、GPT-5.4の普通の代替になりますか
なりません。participant pricing自体は実在しますが、あくまで閉じたpreview契約に紐づいています。GPT-5.4の価格は今日そのまま調達して導入できる公開ルートに紐づいています。この2つは同じ調達条件ではありません。
MythosはGPT-5.4に対して「全体として勝っている」と言えますか
より正確に言うなら、Mythosは複数の重複するvendor-published launch benchmarksでリードしています。しかしそれは、あらゆるワークフロー、ツール条件、レイテンシ条件、アクセス条件で無条件の総合勝者だと証明したことにはなりません。
本当に比較したいのが公開モデル同士なら、Opusを見るべきですか
はい。実際の選択が今すぐ使える公開モデル同士なら、cross-platformならChatGPT vs Claude、Anthropic内部の比較ならClaude Capybara vs Opus 4.6の方が適切です。
最後に一行で言うとどうなりますか
Mythosのベンチマーク優位は、追跡対象に入れる価値があります。ただしそれだけでは、一般ユーザーにとっての現在の標準ルートとしてGPT-5.4を押しのける理由にはなりません。今日モデルが必要ならGPT-5.4を使い、すでにpreviewに入っているかfuture-tier evalsを担当している場合にだけ、Mythosをより狭い実務文脈で本格的に評価してください。