
Claude Code は確かにセッションをまたいでプロジェクトを覚えます。ただし、それは 1つの巨大な永久メモリで動いているわけではありません。Anthropic の公開ドキュメントを 2026 年 4 月 8 日時点で確認すると、内蔵 memory は大きく 2 層に分かれています。あなたが書く CLAUDE.md と、Claude が反復的な修正から学ぶ auto memory です。
混乱しやすいのは、「Claude Code memory」という言葉の中に 3 つの仕事を押し込んでしまうことです。明示的に書くべきルール、学習に任せるべき習慣、そしてそもそも Claude Code の内蔵 memory ではなく外部レイヤーで扱うべき継続性があります。ここを切り分けると、memory は曖昧な概念ではなく、設定可能な実務システムとして見えてきます。
実務上の判断は単純です。失うと困るルールは CLAUDE.md に書く。反復的な修正から学べることは auto memory に任せる。クロスツールやクロスマシンの継続性が欲しいなら、その時点で外部 memory layer を考える。Claude が忘れたと感じたら、まず /memory と /context を見て、そもそも何がロードされていたかを確認してください。
Claude Code に何を覚えさせるべきか
本当に役立つ問いは、「Claude Code に memory があるか」ではなく、「何をどの層に持たせるべきか」です。
CLAUDE.md は明示ルールの層です。リポジトリの workflow、必須テスト、危険な操作の境界、重要なディレクトリ、守らせたい開発ルールなど、毎回のセッション開始時点で見えていてほしいものはここに置きます。ただし Anthropic の現在の docs が明示している通り、CLAUDE.md は hard enforcement ではなく context です。曖昧な文や衝突する指示が増えると、Claude は不安定になります。
auto memory は学習層です。毎回の修正から身についていく癖、たとえばどのテストコマンドを先に使うか、どういうレビューの書き方を好むか、どの略語をこのプロジェクトでは使うか、といったパターンに向いています。便利ですが、現在の公式 contract では machine-local です。ここを曖昧にすると、「どこでも自動的に引き継がれる memory」と誤解しやすくなります。
プラグインや外部 memory 層は別カテゴリです。Anthropic の marketplace には memory 拡張製品がありますが、それは plugin layer が存在するという意味であって、Claude Code の標準 memory が最初から不足しているという意味ではありません。まずは built-in を正しく使い、その境界が実際に仕事を止めていると確認できたときだけ拡張を考えるべきです。
覚えやすい判断は次の 1 行です。必ず残したいものは書く、繰り返しから学べるものは学ばせる、本当に境界を越える必要があるときだけ外に出す。
起動時に何が入って、何が入らないのか
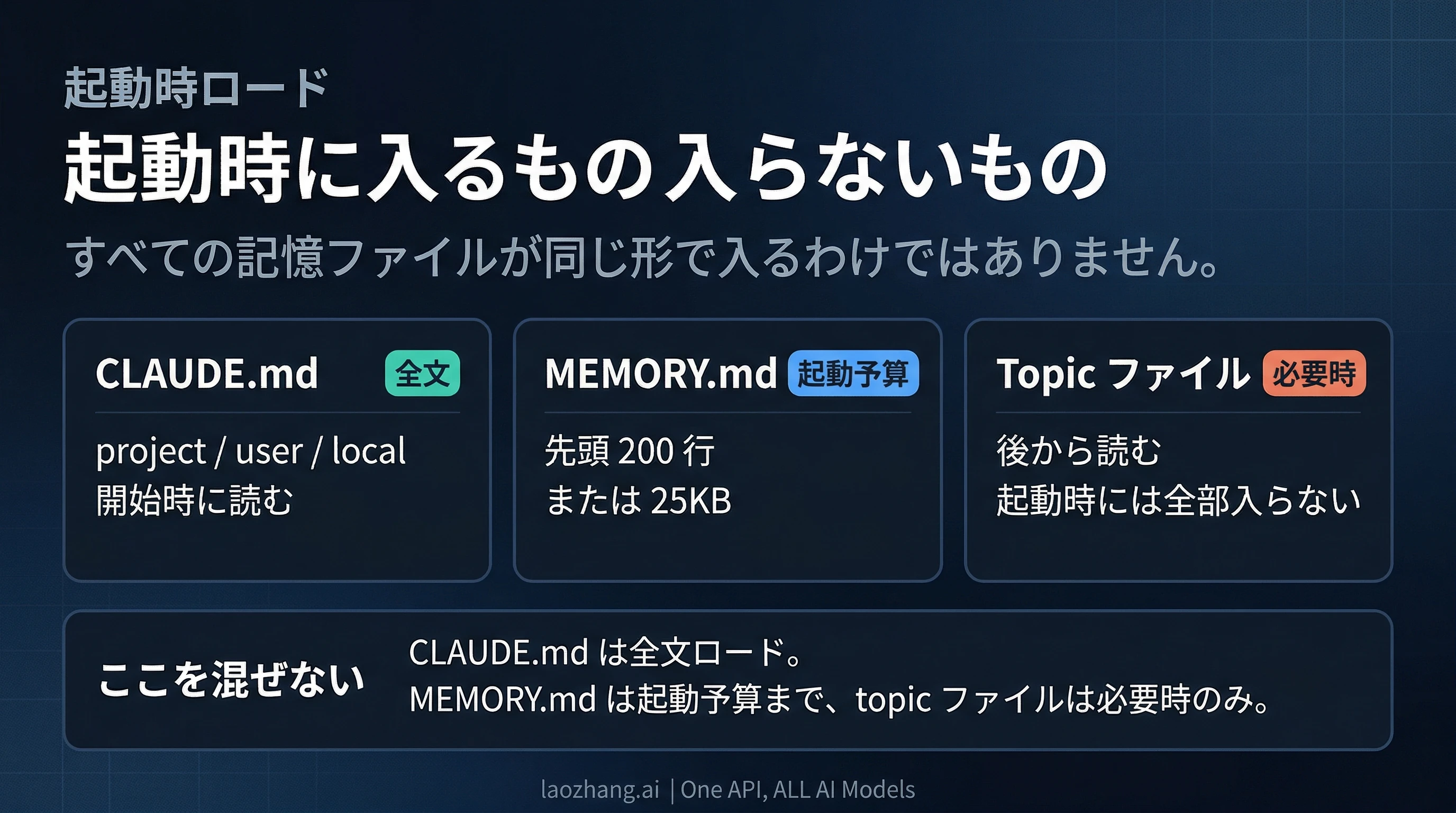
memory の混乱は、ロードの違いを見落としたときに起きやすくなります。
Anthropic の current docs では、CLAUDE.md は会話開始時に読み込まれます。だからこそ、最初のターンから必要なルールはここに置くべきです。後でたまたま拾われることを期待する場所ではありません。
一方で auto memory 側はもっと限定的です。memory フォルダには MEMORY.md と topic ファイルがあり、起動時にロードされるのは MEMORY.md の先頭 200 行、または 25KB までです。topic ファイルは必要になったときに読まれます。つまり、ファイルが存在することと、今のセッションに入っていることは同じではありません。
この違いを確認するために /memory と /context が重要になります。/memory では、どの CLAUDE.md、CLAUDE.local.md、rules ファイルが現在ロードされているかを確認できます。/context は live context breakdown を見るためのコマンドです。Claude が忘れたように見えたときは、まずここで「本当にロードされていたか」を確認するのが最短です。
もう 1 つ早めに明言しておくべきなのが machine-local の境界です。Anthropic が公開している保存パスはローカルの home 配下にあります。これは inspect しやすい反面、別マシンや別 environment に自動でついて回るような cloud memory ではありません。
CLAUDE.md を巨大ファイルにしないための整理法

良い CLAUDE.md は、長いものではなく分担がはっきりしたものです。
project レベルの CLAUDE.md には、リポジトリ全体で共有したいルールを入れます。テストの流れ、変更前に確認すべきこと、触ってはいけないディレクトリ、開発の作法などです。ここを「全部入り」のファイルにしてしまうと、守らせたいことがむしろぼやけます。Anthropic がファイルを比較的短く保つことを勧めているのも、そのためです。
user レベルの ~/.claude/CLAUDE.md は、自分の好みを置く場所です。どんな説明を好むか、どこまで自動実行を許すか、複数プロジェクトで共通する個人ルールなどがここに向いています。
CLAUDE.local.md は、ローカルだけで使いたい private な注記向けです。version control に載せたくないけれど、今のプロジェクトで自分には必要なメモがあるなら、この層が役に立ちます。
さらに、あるルールが特定のパスや狭い workflow にしか関係しないなら .claude/rules/ に分ける方が自然です。全部を 1 ファイルに押し込むより、必要な時に必要な文脈で読める方が強いからです。
そして見落とされやすいのが AGENTS.md です。Claude Code は AGENTS.md を直接読むのではなく、Anthropic は CLAUDE.md から import する形を推奨しています。リポジトリに AGENTS.md があるだけでは足りません。
インストールや認証自体がまだ不安定なら、先に Claude Code インストールガイド を見てください。memory の整理は、土台が安定しているほど簡単です。
auto memory の実務上の境界
auto memory は便利ですが、「勝手に全部覚えてくれる層」と考えると失敗します。正確には、見える・整理できる・制御できる学習層です。
公式 docs にはデフォルトの保存場所、MEMORY.md、topic ファイルが明記されています。つまりブラックボックスではありません。何を学んでいるかを inspect できる以上、memory の質が落ちるときは、memory layer 自体が散らかっている可能性も考えるべきです。
同時に、そこにははっきりした制限があります。起動時に入るのは MEMORY.md の一部だけで、topic ファイルは on demand です。常に見えていてほしいルールなら、topic ファイルの奥に置くのではなく、CLAUDE.md に戻すべきです。
また Anthropic の current docs では、/memory で inspect できることに加え、autoMemoryEnabled: false や CLAUDE_CODE_DISABLE_AUTO_MEMORY=1 といった制御も示されています。これは「切るための機能」というより、問題の切り分けに使える control surface です。
/compact のあと、あるいは次のセッションで忘れる理由

Claude が忘れたように見えるとき、原因はたいてい 4 つに分かれます。
1 つ目は そもそもロードされていない ケースです。/memory を見れば、多くの勘違いはここで解けます。
2 つ目は ルールが曖昧、または衝突している ケースです。CLAUDE.md は context であって強制 policy ではない以上、曖昧な文や競合する指示は「memory が壊れた」ような振る舞いを生みます。
3 つ目は 会話にしか存在しなかった ケースです。Anthropic の troubleshooting では、/compact 後に消える内容は conversation-only だった可能性が高いと説明されています。これが一番実務的な診断です。残すべきことは書くしかありません。
4 つ目が 本当に built-in の境界を超えている ケースです。クロスツール、クロスマシン、より広い retrieval が必要なら、そこで初めて plugin layer を考える意味があります。
順番としては、まず /memory、次に rule の置き場所、次に rule の書き方、次に /context、最後に外部レイヤー、という流れが最も安全です。もし実際の問題が usage や context inflation なら、Claude Code の usage ガイド の方が近道です。
プラグインが役立つ場面と、まだ早い場面
プラグインが役立つのは、質問自体が Claude Code の built-in memory を超えたときです。複数ツールをまたぐ継続性、複数マシン間の共有、より広い retrieval、チーム全体の知識レイヤー。こうした needs なら外部 memory layer は合理的です。
逆に早すぎるのは、まだ built-in を使い切っていない段階です。CLAUDE.md と auto memory の分担が曖昧なまま、/memory も見ず、conversation だけに期待しているなら、プラグインは confusion を隠すだけになりがちです。
一番堅い方針は、まず built-in を整え、その上で「どの境界が実際に痛いのか」を言語化してから外に出ることです。
よくある質問
Claude Code はセッションをまたいで覚えますか。
はい。ただし、1 つの永久 memory ではなく、CLAUDE.md と auto memory の層で継続性を作ります。
何を CLAUDE.md に書くべきですか。
失うと困る明示ルールです。workflow、テスト、危険操作の境界、重要な開発規約がここに入ります。
MEMORY.md はどこにありますか。
現在の公式 docs では ~/.claude/projects/<project>/memory/ 配下です。machine-local です。
なぜ /compact のあとに忘れるのですか。
会話だけに存在していた内容は compaction 後に消えます。永続化したいなら CLAUDE.md に書く必要があります。
memory プラグインは必要ですか。
たいていは不要です。まず built-in の層を正しく使い、それでも越えられない境界が明確になったら検討するのが安全です。
Claude Code memory をうまく使うコツは、万能の巨大メモリを期待しないことです。明示ルールは書く、習慣は学ばせる、境界を超える要件だけ外部化する。この分担が見えれば、memory はずっと扱いやすくなります。