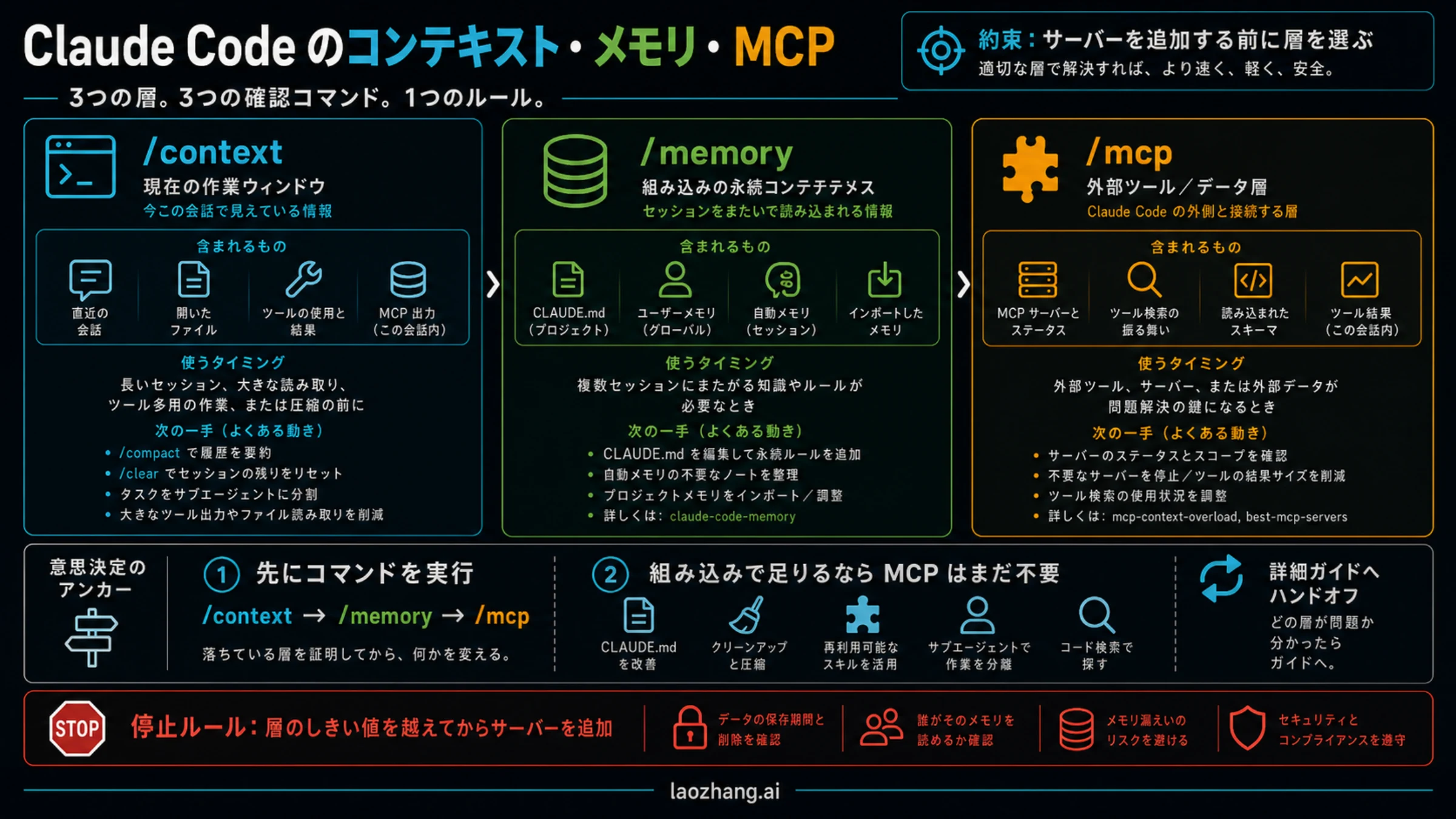
Claude Codeのコンテキスト、メモリ、MCPは同じものではありません。長いセッションで返答がぶれた、次のセッションでプロジェクトルールを忘れた、MCPの結果が大きすぎて会話が乱れた、という現象は似て見えます。しかし所有者は違います。memory MCPを入れる前に、現在の作業窓、起動時に読み込まれる内蔵メモリ、外部ツール層のどこで失敗したかを証明してください。
最初の順序はこうです。
| 症状 | 先に見るもの | 証明できること | サーバー追加前の小さい修正 |
|---|---|---|---|
| 長い会話の後半で判断がずれる | /context | 会話、ファイル、tool結果、MCP出力が現在の窓を圧迫しているか | 境界で圧縮、不要分岐を消す、タスクを分ける、出力を絞る |
| 新しいセッションで規約を覚えていない | /memory | どのCLAUDE.md、import、auto memoryが読み込まれているか | 正しいスコープの内蔵メモリを直す |
| 外部ツールが多い、重い、切れている | /mcp | どのMCP serverが接続され、外部層が何をしているか | noisy serverを切る、tool scopeを狭める、接続を直す |
| 毎回同じ手順を説明している | /skillsまたはsubagent | 必要なのは記憶ではなく再利用手順かどうか | skill化する、または大きな調査を隔離する |
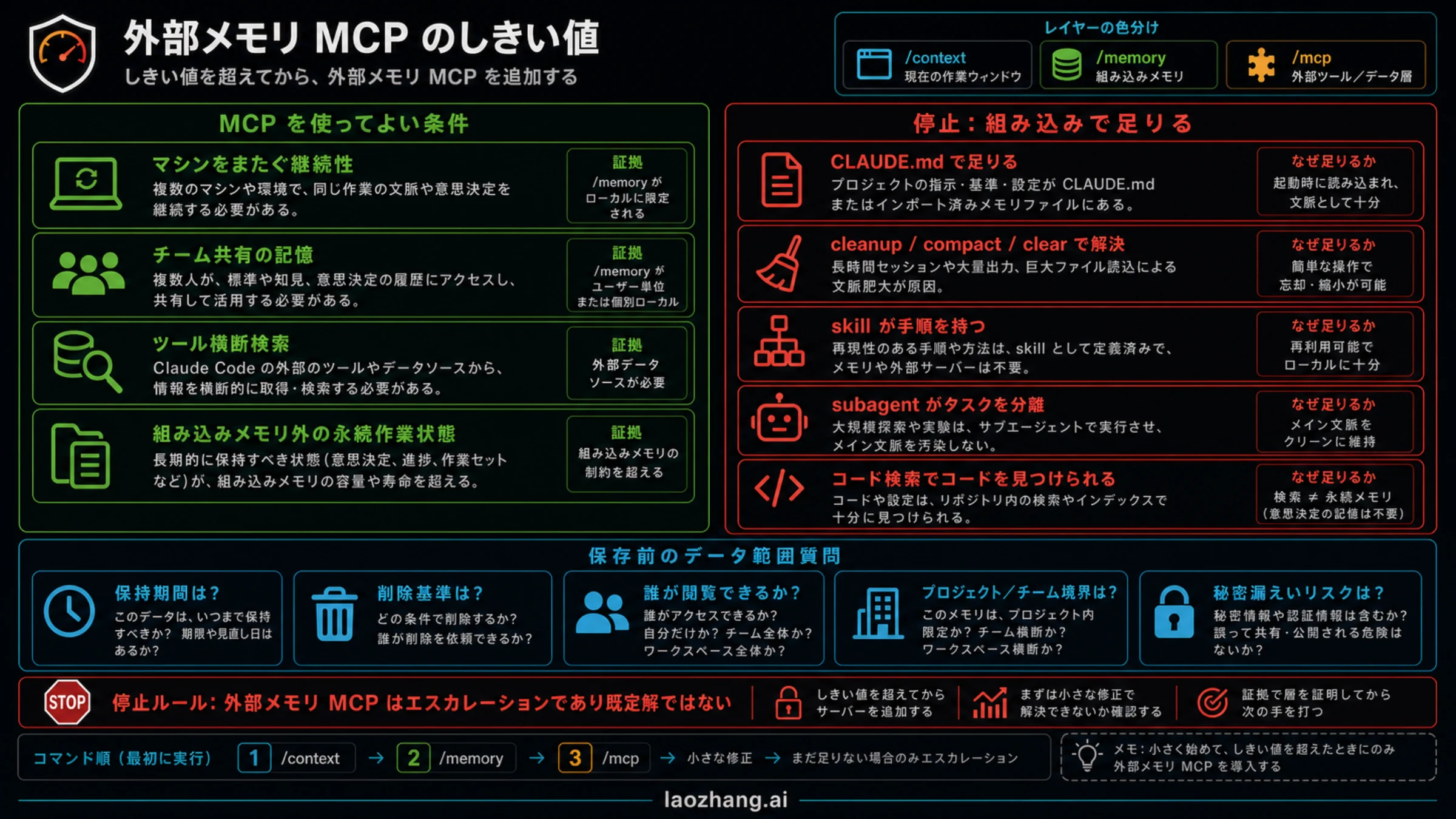
停止ルールは単純です。きれいなCLAUDE.md、/compact、/clear、skill、subagent、コード検索で解決できるなら、外部memory MCPはまだ不要です。外部サーバーが必要になるのは、複数マシンや複数ツールをまたぐ継続性、チーム共有の記憶、内蔵メモリに置けない動的な作業状態が本当に必要なときです。その場合でも、保存場所、削除方法、閲覧権限、秘密情報が入るリスクを確認してから導入します。
速答:壊れた層を先に決める

Claude Codeの継続性は、ひとつの「記憶力」ではなく複数の層です。現在の会話はモデルが今見ている作業窓です。内蔵メモリは、セッション開始時にその窓へ読み込まれるプロジェクト情報やユーザー設定です。MCPは外部ツール、データ、アクションへ接続する層です。skillは再利用できる方法を持ち、subagentは主スレッドを汚したくない大きな調査を隔離します。
実務で起きやすい誤解は、メモリMCPや永続メモリを「忘れる問題」の最初の解決策にしてしまうことです。その需要は本物ですが、導入順序としては危険です。問題が現在のcontext windowの膨張なら、新しいmemory MCPはさらにtool定義、取得結果、権限判断を追加します。先に所有者を切り分けないと、解決策がそのまま新しいノイズになります。
| 失敗パターン | 所有者 | 確認面 | 次の行動 |
|---|---|---|---|
| 長いセッションで古い方針を引きずる | 現在のcontext window | /context | 圧縮、クリア、分割、出力制限 |
| 新規セッションで安定ルールがない | 内蔵memory | /memory | CLAUDE.mdやimportを直す |
| toolが重い、重複、切断されている | MCP | /mcp | serverを縮小、停止、修復する |
| 毎回同じ作業手順を説明する | skill | /skills | 手順をskillへ移す |
| 多数のファイル調査で主会話が乱れる | subagent | handoff summary | 調査を隔離して結論だけ戻す |
| 複数マシン、複数ツール、チームで動的記憶を共有する | 外部memory MCP | server policy | retention、deletion、permissionを確認する |
この表は、曖昧な困りごとをそのまま機能リストへ変えるためではありません。むしろ、memory MCPを最後の候補に下げるための表です。Claude Codeの「忘れた」は、内蔵メモリ不足、現在窓の圧迫、MCPの出力過多、手順の未skill化、単なるコード検索不足のどれでも起きます。
/contextが証明すること
/contextは現在の作業窓を見ます。そこには会話履歴、読んだファイル、tool結果、MCP出力、読み込まれた記憶、圧縮後の要約などが入ります。長いセッションの後半で品質が落ちるとき、最初に見るべきなのは長期記憶ではなく、この作業窓です。
典型的な症状は、すでに捨てた案をClaudeが再び採用する、巨大ログの読後に回答が粗くなる、MCP serverのJSONがそのまま会話を圧迫する、compaction後に重要な境界だけが消える、研究・実装・レビュー・公開判断が同じスレッドで混ざる、といったものです。これらは「記憶を足す」問題ではなく、「今見えている材料を減らす」問題です。
対処は地味ですが効果的です。まず自然なチェックポイントで/compactし、残すべき判断、パス、未完了事項だけを短く残します。次に、横道の調査は別スレッドやsubagentへ逃がします。toolには要約、handle、ページング、必要字段だけを返させます。すでに誤った分岐が多いなら、/clearでやり直し、プロジェクトメモリを再読み込みした方が早いこともあります。
内蔵メモリが担当すること
内蔵メモリは、新しいセッションの開始時点でClaude Codeが知っているべき安定情報を担当します。リポジトリ規約、命名、テストコマンド、公開境界、ユーザーの好み、短いルール、長い文書への参照などです。CLAUDE.md、import、auto memoryは起動時に読み込まれるため、実際にはcontext windowの一部になります。だから短く保つ必要があります。
良いメモリは、プロジェクトの作業を早くします。悪いメモリは、毎回のセッション開始時点から窓を重くします。長いログ、調査の全履歴、巨大な表、会議録、すべての過去判断をそのまま入れると、内蔵メモリが原因でcontextが圧迫されます。長い証拠はファイルに置き、メモリには「どこを見るか」と「いつ使うか」だけを残す方が安全です。
/memoryを見るべき場面は、新しいセッションで安定ルールが欠けているときです。ルールが保存されていないのか、違うスコープに保存されたのか、保存されているが現在窓が混雑して使われていないのかを分けます。前二者は内蔵メモリ修正、最後は/contextでの整理です。ここでも、外部memory MCPが第一手になることはほとんどありません。
MCPが担当すること
MCPは外部アクセスを担当します。コード検索、DB、ブラウザ、issue tracker、内部サービス、ドキュメント、アクション、外部ストレージなど、Claude Code単体では見えないものへ接続します。memory MCPもこの層に属するため、単なる記憶機能ではなく、外部serverとして評価する必要があります。
/mcpは、外部層そのものを疑うときに使います。serverは接続されているか、toolが重複していないか、説明が長すぎないか、呼び出し結果が大きすぎないか、不要なtoolが常時露出していないか。ここが乱れているなら、memory MCPを追加する前にMCPの棚卸しをするべきです。
コード検索とメモリも混同しないでください。コード検索は「どのファイルやsymbolを見るか」を解決します。内蔵メモリは「このプロジェクトで毎回守るべき判断」を解決します。外部memory MCPは、複数セッションや複数ツールをまたいで変化する作業状態を取り出すためのものです。コードの場所探しをmemoryに任せると、古い知識が残りやすくなります。
外部memory MCPの前に試す小さい修正
同じ作業手順を毎回説明しているなら、記憶ではなくskillが向いています。skillは手順、参照、チェックリスト、例を持てますが、すべてを毎回のcontextに読み込む必要はありません。memoryは「何を知っておくべきか」、skillは「どう実行するか」を担当します。この分担だけで、多くの継続性問題は軽くなります。
大きな調査はsubagentに逃がします。主スレッドには、結論、証拠パス、残りリスク、次の行動だけが必要です。コードベース全体の探索、競合調査、ログ分析、ローカライズ方針の比較のような仕事は、読んだ過程を全部主会話に残すと、後続判断のノイズになります。隔離された調査から短いhandoffだけを戻す方が安定します。
また、/compactと/clearを軽く見ないでください。/compactは、すでに決まった判断を短い状態に変えるためのものです。/clearは、会話の残留が多すぎるときに、プロジェクトメモリを読み直して出直すためのものです。この2つで回復するなら、問題は外部記憶ではなく、現在のcontext管理です。
外部memory MCPが正当化される条件
外部memory MCPが正当化されるのは、内蔵メモリでは届かない連続性があるときです。複数マシンや複数IDEで同じ作業状態を共有したい。チームで同じプロジェクト事実を参照したい。issue、docs、chat、コードイベントをまたいで検索したい。CLAUDE.mdに置くには動的すぎる、または大きすぎる作業記憶を扱いたい。こうした条件がそろって初めて、serverが候補になります。
ただし、導入前にデータ質問へ答える必要があります。保存先はどこか。誰が読めるか。削除はどう行うか。raw transcript、summary、embedding、ユーザー記入のfactのどれを保存するか。秘密情報や顧客データが入ったらどう防ぐか。退避とrollbackはあるか。これらが曖昧なら、便利そうでもデフォルトにしない方がいいです。
導入するときも、小さく始めます。1プロジェクト、保存してよいfact、保存禁止のfact、削除方法、成功条件を先に決めます。数回の実務後に、繰り返し説明が減ったか、context bloatが減ったか、検索が正確になったか、誤記憶が増えていないかを見ます。証拠がなければ実験のままにします。
修正マトリクスと証拠パケット

アーキテクチャを変える前に、最低限の証拠を残します。
| 残す証拠 | 重要な理由 | 使い道 |
|---|---|---|
| 症状と発生タイミング | 新規セッション問題か長時間セッション問題かを分ける | /memoryと/contextの優先順を決める |
| /context出力 | 現在窓の圧迫源を見る | 圧縮、分割、出力制限を決める |
| /memory出力 | 実際に読み込まれた記憶を確認する | CLAUDE.mdやimportの修正先を決める |
| /mcp状態 | 外部serverとtool層を見る | server停止、縮小、修復を決める |
| 大きなtool結果 | context bloatの原因を特定する | summary、pagination、handleを要求する |
| compaction境界 | 何を残すべきかを明確にする | 圧縮後の抜けを防ぐ |
| 保存と削除の条件 | 外部memoryの安全性を判断する | memory MCPの可否を決める |
この証拠パケットは、より小さい修正では足りない理由を示すためのものです。証拠が内蔵メモリを指すならCLAUDE.mdを直します。現在窓を指すなら材料を減らします。MCPを指すならserverを絞ります。手順を指すならskill化します。外部recallを指すときだけ、memory MCPの比較に進みます。
よくある質問
Claude Codeのcontextとmemoryは同じですか?
同じではありません。contextは現在の作業窓です。memoryは、新しいセッション開始時にその窓へ読み込まれる持続的な背景です。memoryはcontextの一部になりますが、context自体は長期保存ではありません。
Claude Code memory MCPをすぐ入れるべきですか?
通常は違います。まず/context、/memory、/mcpで層を切り分けます。内蔵メモリ、cleanup、skill、subagent、コード検索で解決できないcross-sessionやcross-tool recallがある場合だけ検討します。
Tool SearchがあればMCPのcontextコストは消えますか?
消えません。Tool Searchは最初に読み込むtool定義を減らせますが、使ったtoolと返ってきた結果はモデルが扱う材料になります。短い説明、上限付き出力、filter、summary、handleは必要です。
プロジェクトルールはCLAUDE.mdかMCP serverのどちらに置くべきですか?
ほとんどの安定ルールはCLAUDE.mdかimportされた内蔵メモリに置きます。MCPは外部アクセスや外部アクションのための層です。短い規約を外部tool呼び出しにすると、安定性が下がることがあります。
memoryではなくskillを使うのはいつですか?
問題が反復手順ならskillです。レビュー、リリース、データ整形、記事制作、障害対応のような方法はskillに向きます。memoryは起動時に知るべきfactや好みを持ちます。
コード検索はmemoryですか?
違います。コード検索はファイルやsymbolを見つけるためのものです。memoryは判断やルールを保つものです。外部memory MCPは、その二つを超えた持続的recallが必要なときに使います。