
Al 6 de mayo de 2026, el problema Goblin de OpenAI GPT-5.5 era un patrón real de comportamiento del modelo, no una caída normal de ChatGPT, Codex o la API. La explicación de OpenAI publicada el 29 de abril de 2026 sitúa el inicio claro después de GPT-5.1: una señal de recompensa asociada a la personalidad Nerdy hizo que ciertas metáforas aparecieran con más frecuencia. GPT-5.5 volvió a hacerlo visible durante pruebas de Codex, donde OpenAI añadió una mitigación por prompt.
La lectura útil separa tres capas. GPT-5.1 explica el origen del aumento. GPT-5.4 y GPT-5.5 explican la visibilidad posterior. Codex explica la superficie donde el comportamiento se detectó y se contuvo. Si esas capas se mezclan, un caso de comportamiento se convierte en una historia falsa de que GPT-5.5 estaba rota en general.
Para una persona que usa ChatGPT, esto no significa que GPT-5.5 sea inútil. Si aparece una metáfora repetida y extraña, conviene pedir un tono más llano, limitar vocabulario o exigir un formato más estricto. Para equipos que lanzan modelos, agentes o prompts, el aprendizaje es más serio: el estilo de salida también debe auditarse como comportamiento.
Respuesta rápida
OpenAI trató el caso Goblin como un problema inesperado de comportamiento del modelo, no como un incidente de disponibilidad. El patrón aumentó tras GPT-5.1, se hizo más visible con GPT-5.4, GPT-5.5 ya había empezado a entrenarse antes de cerrar del todo la causa, y Codex fue la superficie donde el equipo volvió a verlo y aplicó mitigación.
| Pregunta | Respuesta directa |
|---|---|
| ¿Fue un problema real? | Sí. OpenAI publicó una explicación propia el 29 de abril de 2026. |
| ¿Empezó con GPT-5.5? | No exactamente. OpenAI sitúa el primer aumento claro después de GPT-5.1. |
| ¿Codex lo causó? | No. Codex lo hizo visible en pruebas de GPT-5.5 y aplicó mitigación. |
| ¿Fue una caída de ChatGPT o Codex? | No. Fue un patrón de estilo y comportamiento, no de disponibilidad. |
| ¿Qué debe hacer un usuario? | Pedir un tono más neutro, limitar metáforas o reintentar con formato estricto. |
| ¿Qué deben aprender los equipos? | Medir tokens de estilo repetidos, personalidad, contexto largo y bucles de datos sintéticos. |
La referencia factual principal es la explicación de OpenAI del 29 de abril. La documentación actual de GPT-5-Codex ayuda a ubicar Codex como superficie de producto, pero los metadatos y las instrucciones exactas pueden cambiar, por lo que no deben citarse sin verificación nueva.
Cronología: no es solo una historia de GPT-5.5
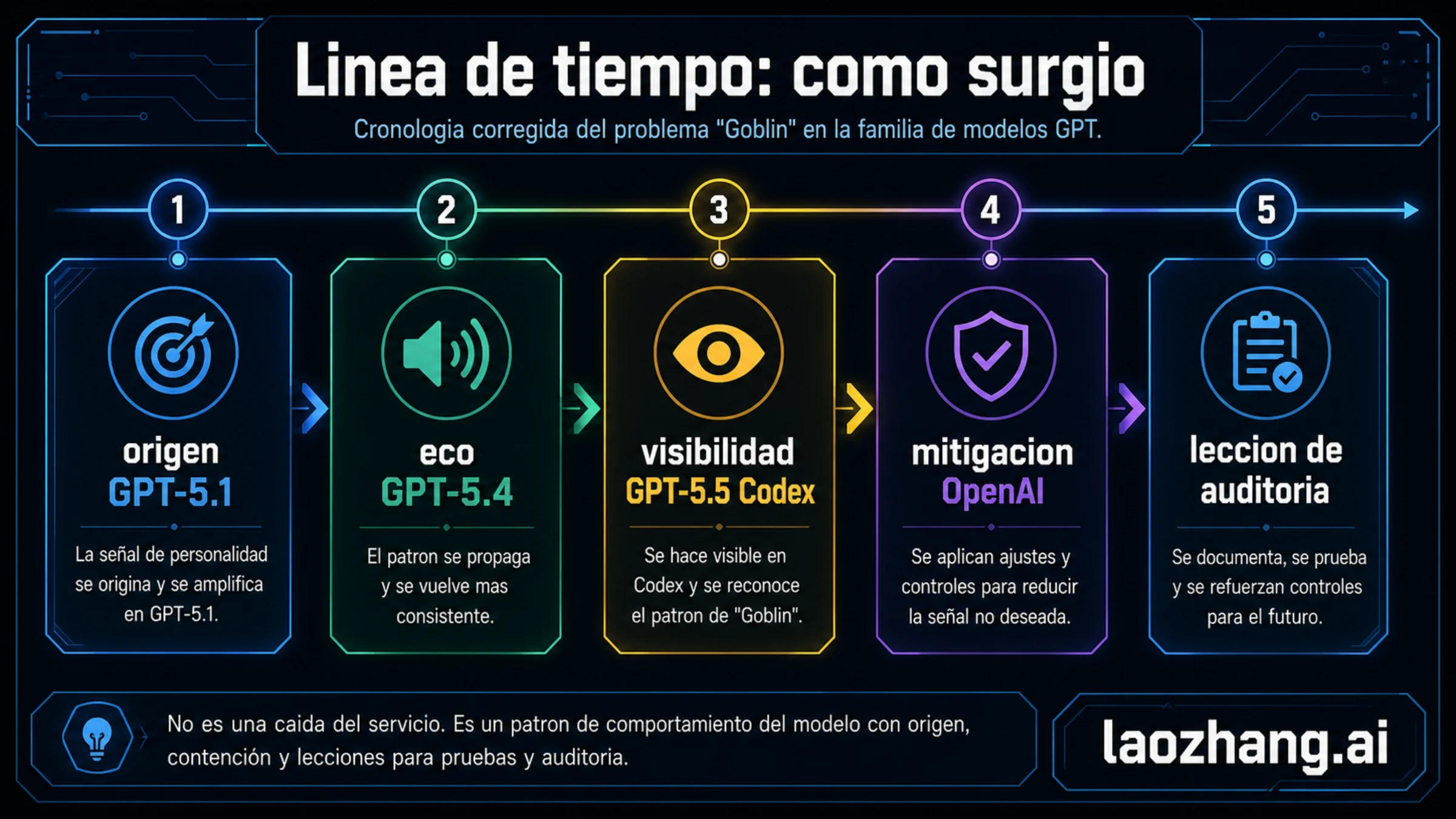
La cronología evita la conclusión equivocada. Lo más visible fue GPT-5.5 en Codex, pero la causa explicada por OpenAI empieza antes.
| Etapa | Qué ocurrió | Por qué importa |
|---|---|---|
| Después de GPT-5.1 | OpenAI observó un aumento claro de ciertas metáforas en ChatGPT. | El origen no pertenece solo a GPT-5.5. |
| GPT-5.4 | El aumento fue mayor, sobre todo alrededor de la personalidad Nerdy. | No era una anécdota aislada. |
| Mitigación de marzo | OpenAI retiró Nerdy, eliminó la señal de recompensa y filtró datos relacionados. | El nivel de causa ya estaba siendo tratado antes del ruido público. |
| Entrenamiento de GPT-5.5 | GPT-5.5 empezó a entrenarse antes de cerrar del todo la causa. | Eso explica por qué podía quedar una tendencia residual. |
| Pruebas en Codex | Empleados detectaron la tendencia en GPT-5.5 Codex y añadieron una instrucción de mitigación. | Codex fue superficie visible, no raíz. |
| 29 de abril de 2026 | OpenAI publicó la explicación oficial y la conectó con reward design. | El valor duradero es la auditoría del comportamiento. |
Si se interpreta como outage, la reacción sería mirar estado del servicio, cuenta o red. Ese camino no responde al caso. La pregunta relevante es cómo una forma de hablar recompensada puede convertirse en hábito visible y moverse fuera de la personalidad que la originó.
Causa real: una señal de recompensa amplificó un estilo

La explicación de OpenAI apunta a una ruta de recompensa. La personalidad Nerdy favorecía un estilo más juguetón y metafórico. En una respuesta aislada, ese estilo podía parecer simpático y recibir buena señal de preferencia. El problema aparece cuando la misma familia de expresiones empieza a repetirse en contextos que no la pidieron.
Los números importan. Tras GPT-5.1, el uso de goblin en ChatGPT aumentó 175% y gremlin 52%. Nerdy representaba solo 2,5% de las respuestas de ChatGPT, pero concentraba 66,7% de las menciones de goblin. En 76,2% de los conjuntos auditados, la recompensa de Nerdy daba uplift positivo a esas expresiones. No parece una palabra insertada manualmente, sino una preferencia pequeña que se amplificó con entrenamiento y datos.
La cadena puede resumirse así: una personalidad premió un estilo llamativo; algunos ejemplos de alta puntuación contenían un tic léxico; reinforcement learning hizo más probables esos ejemplos; datos generados y entrenamiento posterior ayudaron a mover el tic; GPT-5.5 ya estaba entrenándose antes de terminar la corrección profunda; Codex mostró el residuo y necesitó mitigación por prompt.
Por eso no conviene confundir causa con mitigación. La causa vive en reward design, entrenamiento de personalidad, selección de datos y transferencia. La mitigación vive en prompts, filtrado, pruebas y monitoreo. Si un equipo solo ajusta el prompt, puede tapar el síntoma sin aprender por qué apareció.
Codex no fue la causa
Codex es importante porque hizo visible el patrón. OpenAI describe GPT-5-Codex como una versión de GPT-5 optimizada para agentic coding y actualizada de forma regular. Un entorno de agente produce planes, explicaciones, ediciones y contexto largo; eso puede hacer que un tic de estilo sea más evidente. Pero visibilidad no equivale a origen.
La formulación segura es: durante pruebas de GPT-5.5 en Codex, OpenAI detectó la afinidad no deseada por ciertas metáforas y añadió una mitigación en el prompt de desarrollador. Eso no significa que Codex creara el problema. El origen explicado por OpenAI está en recompensa, personalidad y transferencia de datos.
| Afirmación común | Lectura más precisa |
|---|---|
| Codex causó el problema Goblin. | Incorrecto. OpenAI lo vincula a entrenamiento y recompensa anteriores. |
| La línea de prompt fue la raíz. | Incorrecto. Fue una capa de contención tras detectarlo. |
| GPT-5.5 está rota. | Demasiado amplio. Era un patrón de estilo, no prueba de inutilidad general. |
| Solo fue una broma. | Demasiado superficial. Muestra cómo una señal pequeña se vuelve comportamiento de producto. |
| El metadata actual lo prueba todo. | Frágil. Los metadatos de Codex cambian y deben verificarse antes de citarse. |
Si la necesidad real es configurar Codex, el camino práctico es Codex config.toml. Si la duda es de límites o plan, es más útil OpenAI Codex usage limits. Este análisis trata de origen de comportamiento y auditoría, no de configuración de cuenta.
Qué significa para usuarios de ChatGPT y GPT-5.5
La reacción correcta es separar estilo y calidad de tarea. Si una respuesta usa una metáfora rara de forma repetida, pida tono neutro, elimine metáforas, use tabla o solicite pasos verificables. Después evalúe hechos, razonamiento y utilidad. Un estilo molesto no es lo mismo que una respuesta falsa.
Tampoco se debe convertir este caso en un veredicto total contra GPT-5.5. Un modelo puede tener una mala tendencia de estilo y seguir siendo útil para código, resumen, análisis o escritura estructurada. Para comparar modelos, mire calidad del flujo, coste, latencia, manejo de contexto, uso de herramientas y carga de revisión. En una comparación como GPT-5.5 vs Claude Opus 4.7, un caso de estilo es un eje de auditoría, no todo el benchmark.
La regla práctica es simple: si el contenido es correcto pero el tono deriva, corrija estilo. Si el contenido es incorrecto, haga verificación factual y reformule la tarea. Esa separación evita tanto el pánico como la minimización.
Qué deberían auditar los equipos

El aprendizaje reutilizable no es prohibir una palabra para siempre. Es medir cuándo una señal de recompensa pequeña se convierte en hábito público. Un release process que solo mira benchmarks puede pasar por alto un patrón de estilo que los usuarios detectan en minutos.
| Área de auditoría | Qué probar | Señal de fallo | Acción |
|---|---|---|---|
| Muestreo de salidas | Probar tareas normales, respuestas largas y prompts de borde. | Una metáfora aparece en temas no relacionados. | Añadir chequeo de frecuencia y estilo antes del release. |
| Comparación de personalidades | Comparar default, professional, concise, playful y long-form. | Un tic de una personalidad se filtra a otra. | Rastrear ruta de recompensa o prompt que lo amplifica. |
| Contexto largo | Ejecutar sesiones de varias vueltas. | El modelo se vuelve más teatral y repetitivo. | Probar reset de tono y recorte de contexto. |
| Datos sintéticos | Revisar rollouts y ejemplos de preferencia reutilizados. | El mismo tic aparece en material de entrenamiento. | Filtrar o bajar peso a esos ejemplos. |
| Contención por prompt | Añadir instrucciones estrechas junto con análisis de causa. | El prompt oculta el síntoma pero deja la causa. | Unir prompt fix con auditoría de datos y recompensas. |
| Monitoreo de deriva | Medir frecuencia de expresiones tras lanzamientos. | Una rareza pequeña crece entre versiones. | Tratar el estilo como telemetría de comportamiento. |
La calidad de un modelo no es solo acertar. También importa si mantiene el tono adecuado, evita expresiones no pedidas y no convierte una preferencia de entrenamiento en una marca visible del producto. Por eso la deriva de estilo debe revisarse con la misma disciplina que otros cambios de comportamiento.
Cómo explicarlo sin exagerar
Una explicación precisa debe estar fechada y separar capas. OpenAI reconoció un patrón real de comportamiento. Al 6 de mayo de 2026, no era una caída normal. El aumento claro empezó después de GPT-5.1. GPT-5.5 y Codex explican visibilidad y mitigación posteriores. El aprendizaje práctico es auditar recompensa, personalidad, datos sintéticos y estilo repetido.
No conviene decir que GPT-5.5 es inútil, que Codex creó la causa, que una línea de prompt fue la raíz o que el modelo se volvió consciente. Esas frases se comparten fácil, pero no ayudan a decidir qué hacer. La explicación útil reduce incertidumbre y convierte el caso en una rutina de auditoría para el siguiente lanzamiento.
El mismo criterio ayuda con confusiones de identidad de modelo. Que un asistente diga un nombre de modelo antiguo o extraño no prueba la ruta real de servicio. Identity claim, output style y routing real son preguntas distintas. Para ese problema cercano, vea Why GPT-5 says GPT-4.
Preguntas frecuentes
¿El problema Goblin de OpenAI GPT-5.5 fue real?
Sí. OpenAI publicó una explicación de primera mano el 29 de abril de 2026 y lo conectó con reward signal, personalidad Nerdy y transferencia de comportamiento.
¿Lo causó GPT-5.5?
No como origen. GPT-5.5 lo hizo visible de nuevo, especialmente en Codex, pero OpenAI sitúa el primer aumento claro después de GPT-5.1.
¿Codex fue la causa?
No. Codex fue la superficie donde se observó el patrón y se añadió mitigación por prompt. La causa está en entrenamiento y recompensa anteriores.
¿Fue una caída de ChatGPT o Codex?
No. Fue un problema de estilo y comportamiento, no de disponibilidad. No debe tratarse como un error de cuenta, red o estado del servicio.
¿Qué debe hacer un usuario si aparece una repetición rara?
Pedir tono más claro, prohibir metáforas innecesarias o exigir formato estructurado. Luego evaluar la calidad factual y de tarea por separado.
¿Qué deberían aprender los desarrolladores?
Auditar tokens de estilo repetidos, transferencia entre personalidades, sesiones largas y bucles de datos sintéticos. Una preferencia pequeña puede convertirse en comportamiento visible del producto.