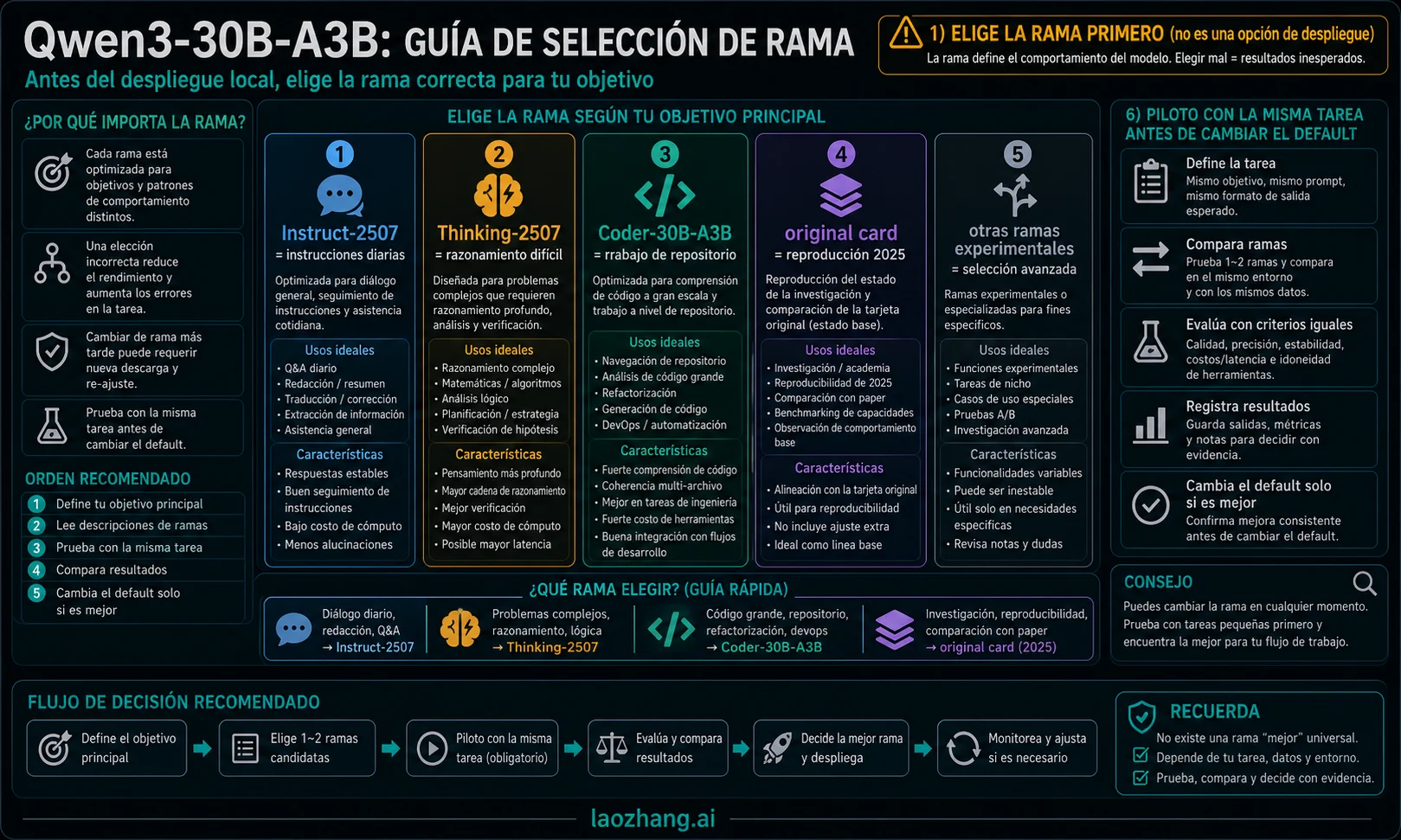
Al 22 de mayo de 2026, Qwen3-30B-A3B no debería tratarse como una sola elección de despliegue local. Primero elige la rama: Qwen/Qwen3-30B-A3B-Instruct-2507 para instrucciones normales, summaries, chat y agent prompts ligeros; Qwen/Qwen3-30B-A3B-Thinking-2507 para razonamiento difícil; Qwen/Qwen3-Coder-30B-A3B-Instruct para coding a escala de repositorio; y el Qwen/Qwen3-30B-A3B original solo cuando necesites reproducir el hybrid model de abril de 2025.
A3B describe la forma sparse MoE y el bloque de parámetros activados. No decide la etiqueta de runtime, la longitud real de contexto, la cuantización, el KV cache, la memoria ni el coste de revisión. El despliegue real depende de branch, quantization, context budget, inference framework, batch, concurrency y tipo de tarea.
| Trabajo | Rama inicial | Verifica antes de cambiar el default |
|---|---|---|
| Instrucciones locales, resúmenes, chat, agent prompts ordinarios | Qwen/Qwen3-30B-A3B-Instruct-2507 | Es una rama non-thinking; no esperes trazas <think>. |
| Razonamiento duro, planificación, revisión adversarial | Qwen/Qwen3-30B-A3B-Thinking-2507 | Mide latencia, verbosidad, tiempo de revisión y calidad en tareas difíciles. |
| Repositorios, tool loops, tareas largas de código | Qwen/Qwen3-Coder-30B-A3B-Instruct | Trátala como rama Coder, no como alias de la tarjeta original. |
| Reproducción de abril de 2025 o comparación con evals antiguas | Qwen/Qwen3-30B-A3B | Usa la owner card original y su límite 32K native context. |
| Exploración de rutas Qwen más nuevas | Evalúa Qwen3.6-35B-A3B aparte | Qwen3.6 es un sucesor, no la misma fila de modelo. |
Regla de parada: no reemplaces el default actual hasta que el mismo prompt, mismos archivos, mismas herramientas, mismo presupuesto de contexto, mismos tests, misma latencia, misma política de reintentos y misma rúbrica de reviewer pasen en la rama candidata sin más defectos ocultos.
Respuesta rápida
Instruct-2507 es la primera rama para uso local cotidiano. Sirve para summaries, clasificación, borradores, chat, explicación de logs, extracción estructurada y agent prompts ligeros. Su ficha de Hugging Face la posiciona como non-thinking branch y registra 262.144 tokens de native context. Eso la hace más razonable como default de baja fricción.
Thinking-2507 debe probarse aparte. Encaja donde el razonamiento adicional reduce errores: planificación con muchas restricciones, síntesis de documentos largos, troubleshooting complejo, revisión adversarial y problemas donde una respuesta corta suele fallar. Su coste real incluye salida más larga, latencia y más tiempo humano de revisión.
Coder-30B-A3B debe ser el primer test para código. Los materiales Qwen3-Coder se centran en coding and tool use, así que es la rama correcta para repo search, cambios multiarchivo, test-writing, refactor locality y disciplina de herramientas. Aun así, el nombre no garantiza que tu repositorio pase más tests; hay que medirlo.
La tarjeta original mantiene valor como baseline. Si necesitas reproducir artículos de abril de 2025, builds cuantizadas antiguas, comportamiento hybrid thinking/non-thinking o paridad con evals previas, la original Qwen/Qwen3-30B-A3B es la fuente correcta. No debería convertirse silenciosamente en tu default nuevo.
Qué significa A3B
El anuncio Qwen3 y la tarjeta original de Hugging Face describen un sparse mixture-of-experts model. La owner card registra 30.5B parámetros totales, 3.3B parámetros activados, 48 capas, 128 experts y 8 active experts. Esa forma explica por qué el nombre resulta atractivo para pruebas locales: el modelo total es grande, pero cada token activa una porción menor.
El label de parámetros activados no resuelve el despliegue. La presión de memoria incluye loaded weights, cuantización, context length, KV cache, framework overhead, batch y concurrency. Un chat corto en 4-bit, un agente de código con contexto largo y un servicio con varias peticiones simultáneas son despliegues diferentes.
Los límites de contexto también cambian por rama. La tarjeta original registra 32.768 native context y 131.072 with YaRN. Instruct-2507 y Thinking-2507 registran 262.144 native context. La tarjeta Coder registra 262.144 native context y una frontera 1M with YaRN. Mezclarlas en una fila hace confusa cualquier comparación de speed, quality o memory.
Cómo elegir la rama
Empieza por el coste de equivocarte. Una tarea cotidiana de instrucción suele corregirse con una respuesta nueva. Una tarea de razonamiento puede llevarte a una conclusión falsa. Una tarea de código puede introducir defectos ocultos en el repositorio. Por eso una sola rama no debe ganar todos los escenarios.
Para trabajo normal de assistant local, empieza por Instruct-2507. Evalúa formato, concisión, respeto de instrucciones, límites de seguridad y estabilidad cuando el prompt no pide razonamiento visible. Si tu prueba exige una traza de thinking, estás midiendo otra rama.
Para razonamiento difícil, mide Thinking-2507 de forma separada. Las buenas tareas de evaluación son planificación con restricciones, síntesis larga, debugging complejo y revisión de riesgos donde el razonamiento adicional reduce errores. Si la salida solo se vuelve más larga y no reduce reparación, se queda en modo experimento.
Para código, empieza por Coder-30B-A3B. Mira si encuentra archivos correctos, limita el diff, conserva el estilo existente, elige tests apropiados, recupera errores de herramientas y evita cambios innecesarios. Escribir snippets no equivale a manejar un loop de repositorio.
Para una ruta Qwen más nueva, separa Qwen3.6. Si la pregunta real ya compara Qwen3.6 con Kimi o GLM, usa la comparación Qwen3.6, Kimi K2.6 y GLM-5.1. No conviertas una decisión exacta de Qwen3-30B-A3B en una tabla general de modelos.
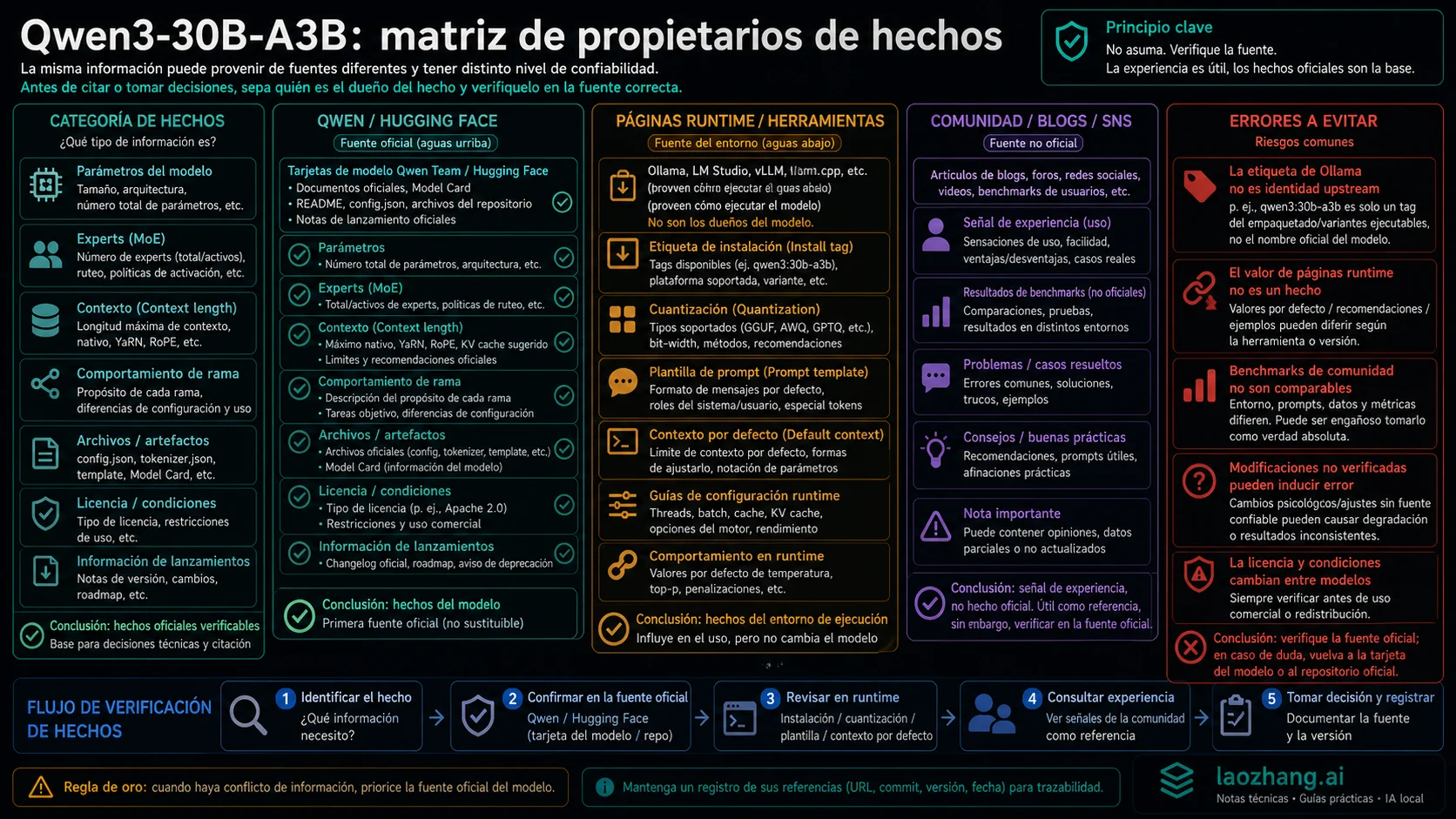
El runtime no posee los hechos
Ollama, LM Studio, llama.cpp, vLLM y SGLang son útiles porque convierten una decisión de modelo en un setup local runnable. Pero una etiqueta de runtime no es identidad upstream. Puede esconder cuantización, plantilla de prompt, contexto por defecto, branch mapping y parámetros del servidor.
La ruta qwen3:30b-a3b de Ollama es útil para empezar rápido. Sirve para observar velocidad, memoria, carga inicial y comportamiento básico. No debe ser la fuente de parámetro total, expert count, límites de contexto o comportamiento oficial de rama. Esos hechos pertenecen a Qwen y a las tarjetas Hugging Face.
Los paquetes cuantizados de comunidad siguen la misma regla. Un GGUF, AWQ o GPTQ puede ser perfecto para una GPU concreta, pero al cambiar cuantización, template, contexto o servidor estás evaluando el stack completo de despliegue. Separar model identity de stack behavior evita diagnósticos falsos.
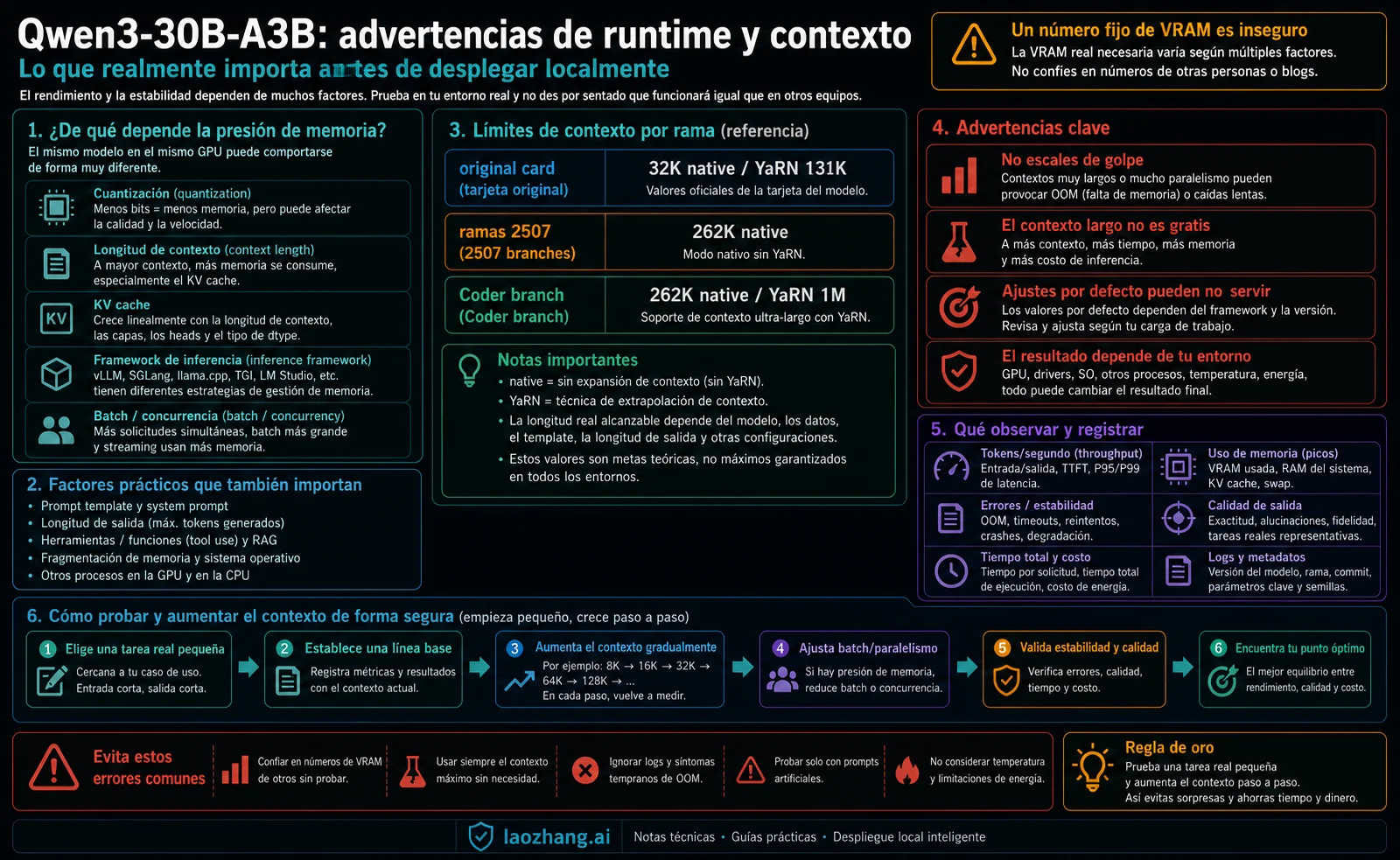
Hardware y contexto
Una respuesta honesta sobre hardware es condicional. La cuantización puede bajar memoria y cambiar calidad. A mayor contexto, mayor KV cache. Batch y concurrency elevan el pico. Cada framework maneja offload, attention y paging de forma distinta. Un número fijo de VRAM solo describe una configuración fija.
Para chat corto, mide load time, first token, tokens por segundo y estabilidad de formato. Para code agent, incluye archivos reales del repositorio, outputs de herramientas, reintentos y contexto largo. Para Thinking branch, registra longitud de salida, reviewer time y reducción real de errores. No uses una sola prueba pequeña para decidir todos los defaults.
Un piloto seguro empieza pequeño. Usa una tarea real pero controlada, confirma branch y runtime, luego aumenta contexto de forma gradual. Registra memory pressure, crashes, paging, caída de calidad y recovery. No abras máximo contexto antes de saber si las tareas cortas son estables.
Piloto con la misma tarea
La comparación funciona cuando todo excepto el modelo se mantiene igual. Elige cinco a diez tareas reales: explicación de log, resumen, razonamiento multi-step, bug pequeño, refactor multiarchivo, test writing, lectura de contexto largo y requisito ambiguo. El default actual y la rama candidata deben recibir los mismos datos.

| Fila de prueba | Mantén igual | Registra |
|---|---|---|
| Prompt | Tarea, reglas de sistema, formato | Si resuelve sin reparación extra |
| Contexto | Archivos, logs, snippets, token budget | Referencias perdidas, drift, restricciones olvidadas |
| Herramientas | Comandos, permisos, retry rules | Precisión de herramientas y acciones innecesarias |
| Tests | Unit tests, eval set, revisión manual | Accepted diff, checks fallidos, defectos ocultos |
| Operación | Hardware, runtime, quantization, batch | Latencia, memoria, crashes y recovery |
Cambia el default solo cuando la rama candidata iguale o supere al default actual en task completion, ediciones del reviewer, retries, hidden defects y operating cost. Un modelo rápido que exige más reparación humana no es más rápido. Un modelo más inteligente que no entra en tu presupuesto de memoria o latencia no es mejor default.
Fuentes que conviene mantener separadas
El anuncio Qwen3 de Qwen posee el framing de familia, open-weight MoE y tabla de modelos. La tarjeta Qwen/Qwen3-30B-A3B de Hugging Face posee los hechos originales: parámetros, experts, activated experts, hybrid behavior y original context boundary. Las tarjetas Instruct-2507 y Thinking-2507 poseen el comportamiento de esas ramas y los 262K native context rows.
La tarjeta Qwen3-Coder-30B-A3B y el blog Qwen3-Coder poseen el framing de coding-agent branch. Ollama y otros runtimes poseen conveniencia de instalación, no identidad upstream. El material Qwen3.6 posee la frontera de sucesor. Separar esas fuentes permite actualizar una fila cuando cambia una rama o runtime tag.
Preguntas frecuentes
¿Qwen3-30B-A3B todavía merece la pena localmente?
Sí, si la rama encaja. Instruct-2507 vale para instrucciones locales compactas, Thinking-2507 para tareas de razonamiento, Coder-30B-A3B para loops de código y original branch para reproducción de abril de 2025.
¿A3B significa que es un modelo 3B?
No. A3B se refiere a parámetros activados en un sparse MoE. La tarjeta original registra 30.5B parámetros totales y 3.3B activados. La memoria depende del stack completo.
¿Instruct-2507 o Thinking-2507?
Usa Instruct-2507 para respuestas limpias y rápidas sin thinking traces. Usa Thinking-2507 si el problema es lo bastante difícil para justificar más latencia y revisión.
¿Qwen3-Coder-30B-A3B es el mismo modelo?
No. Es una rama Coder relacionada. Pruébala primero para repository-scale coding y tool use, pero no la cites como si fuera la original card.
¿Ollama basta para saber la rama?
Ollama da una ruta práctica, pero verifica upstream model ID, quantization, context setting y prompt template. La conveniencia de runtime no es propiedad oficial del modelo.
¿Cuánta VRAM necesito?
No hay un número único honesto. Quantization, context length, KV cache, framework overhead, batch y concurrency cambian la presión de memoria.
¿Cuándo mirar Qwen3.6?
Cuando el trabajo sea explorar una ruta Qwen local/coding más nueva, no decidir la rama exacta de Qwen3-30B-A3B. Qwen3.6-35B-A3B es comparación sucesora, no replacement silencioso.