
Gemma 4 no es un solo modelo. Si solo vas a recordar una idea, que sea esta: E2B y E4B forman la rama edge, mientras que 26B A4B y 31B forman la rama workstation. A 3 de abril de 2026, esa separacion importa mas que cualquier captura de benchmark aislada, porque decide si deberias empezar desde un telefono, un portatil, una workstation o una prueba online rapida.
Eso tambien hace que Gemma 4 se sienta distinto a muchos anuncios de modelos nuevos. No es solo “el siguiente open release de Google”. Es una familia de cuatro modelos bajo Apache 2.0, donde la rama pequena se construyo para eficiencia local y movil, y la rama grande para contexto mas largo y razonamiento local mas pesado sobre hardware de desarrollador. Si lees solo las paginas de lanzamiento, todo puede parecer demasiado amplio. El movimiento realmente util es reducirlo a una sola pregunta: necesitas un modelo edge o un modelo para workstation?
Las afirmaciones centrales de esta guia se verificaron el 3 de abril de 2026 contra el Gemma release log de Google, el launch blog, la Gemma 4 model card, la pricing page de Gemini Developer API y el Android Developers Blog.
Empieza por aqui: que rama de Gemma 4 deberias mirar primero

| Si tu objetivo real es... | Empieza por... | Por que | Principal coste |
|---|---|---|---|
| Un modelo offline o de baja latencia para edge, movil o dispositivos locales pequenos | E4B | Es la opcion por defecto mas solida para edge: mas margen que E2B y sigue pensada para uso local eficiente | Tiene menos techo que la rama grande y no es la mejor opcion para el reasoning mas pesado de workstation |
| La puerta de entrada mas ligera a Gemma 4 | E2B | Tiene sentido cuando RAM, bateria o latencia son el cuello de botella real | Su techo es menor que el de E4B |
| Un modelo local de clase workstation sin saltar de inmediato al dense mas pesado | 26B A4B | Su diseno MoE activa solo 3.8B parametros en inferencia y por eso suele ser el default practico de la rama grande | La historia del producto es mas compleja que la de un dense flagship simple |
| El modelo dense mas grande de la familia | 31B | Tiene sentido si priorizas calidad bruta o una base mas fuerte para fine-tuning | La carga de hardware es mayor que con 26B A4B |
| Probar la rama grande antes de montarla por tu cuenta | 26B A4B o 31B en AI Studio | Es la via oficial mas rapida para sentir la rama grande | La pricing page actual no la presenta como un paid Gemma SKU normal |
| Audio / speech en dispositivo | E4B o E2B | El audio nativo esta en la rama pequena | La rama grande no ocupa la misma posicion de producto |
La recomendacion inicial puede ser muy directa: si empiezas desde hardware edge, empieza por E4B; si empiezas desde una workstation, empieza por 26B A4B. Esas dos paradas son las mas sensatas salvo que ya sepas que necesitas el footprint minimo o que de verdad buscas el trade-off completo de 31B.
Que es Gemma 4 en realidad
Gemma 4 es la familia abierta mas nueva de Google. El release log oficial la registra con fecha 31 de marzo de 2026, y el anuncio publico del launch blog es del 2 de abril de 2026. Google la presenta como la familia open model paralela a la linea de investigacion e infraestructura que desemboca en Gemini 3, pero eso no significa que Gemma 4 sea solo “Gemini con otro nombre y mas barato”. La distincion importante es operacional: Gemma es la familia open weight que puedes ejecutar, adaptar y desplegar tu mismo; Gemini es la linea gestionada por Google.
Esa diferencia importa porque cambia el tipo de decision. Elegir Gemini suele ser una decision de pricing y de contrato de API. Elegir Gemma 4 es antes que nada una decision de despliegue. Estas decidiendo si quieres correr un modelo edge local, un modelo local de clase workstation o una superficie hosted para evaluar primero el open model antes de definir como desplegarlo.
Google tambien deja mas claro el borde del producto esta vez que en muchos lanzamientos anteriores. La model card oficial describe Gemma 4 como una familia multimodal de modelos abiertos con entrada de texto e imagen, audio nativo en la rama pequena y salida de texto en toda la linea. Conviene decirlo de forma directa porque en la semana del lanzamiento aparecen malentendidos con facilidad: Gemma 4 no es un generador de imagenes ni de video. Es una familia multimodal abierta orientada a salida de texto, reasoning, coding, comprension tipo OCR y flujos relacionados.
La division real: modelos edge frente a modelos workstation

La forma mas util de leer la familia Gemma 4 no es preguntarte que modelo es “el mejor” en abstracto. Es preguntarte que problema de despliegue esta resolviendo cada rama.
La rama edge es E2B y E4B. Segun la model card oficial, ambas soportan 128K de contexto, entrada de texto e imagen y audio nativo. El anuncio de Android de Google tambien deja claro que esta es la rama que alimenta la siguiente etapa de Gemini Nano y AICore en dispositivo. Eso significa que no son solo “modelos mas pequenos”. Son la parte de la familia pensada para cuando la latencia, la ejecucion local, la bateria y el hardware limitado importan mas que la maxima capacidad.
Dentro de esa rama edge, E4B es el default mas razonable para la mayoria de usuarios serios. Ofrece mas margen que E2B y sigue dentro de la parte de la familia que Google esta empujando con mas claridad hacia on-device y AI Edge. E2B es una opcion mas especializada: encaja cuando la eficiencia es la primera restriccion y estas dispuesto a cambiar techo por footprint.
La rama workstation es 26B A4B y 31B. Ambas suben a 256K de contexto, lo que ya cambia de verdad el juego para documentos largos, contextos de codigo mas amplios y flujos de razonamiento local mas pesados. Tambien empujan a Gemma 4 fuera del simple problema edge y la meten de lleno en el terreno de workstation local, self-hosting y despliegues mas cercanos a produccion.
El modelo mas interesante aqui es 26B A4B. La model card lo describe como un Mixture-of-Experts con 25.2B parametros totales y solo 3.8B parametros activos durante la inferencia. Traducido a una lectura practica: es el candidato mas natural a default de workstation para muchos lectores. Te da la rama de contexto largo y reasoning mas fuerte sin obligarte a arrancar por el dense mas pesado.
31B es el dense grande. Tiene sentido cuando te importa mas la calidad bruta de un dense model o cuando quieres una base mas robusta para experimentar y afinar, y estas dispuesto a asumir el coste de hardware que eso implica. Lo importante es no convertirlo en la respuesta automatica solo porque tiene el numero mas grande. Para muchos desarrolladores locales, 26B A4B sera el primer lugar serio donde empezar.
Que cambia frente a Gemma 3
La mejora de Gemma 4 frente a Gemma 3 importa, pero no por la razon superficial de que “subieron los benchmark”. El cambio mas profundo es que Google convirtio la familia en un sistema mucho mas utilizable.
Primero, la rama grande llega a 256K de contexto, mientras que la rama pequena se queda en 128K. Eso importa porque convierte a Gemma 4 en una candidata mucho mas seria para trabajo local con documentos largos y repositorios completos que un simple lanzamiento de open model pequeno. Segundo, tanto el material de lanzamiento como la model card subrayan native system-role support y native function-calling posture, algo muy relevante en workflows agenticos y estructurados. Tercero, la division de la familia esta mejor hecha: los modelos edge ya no parecen una nota al pie, y la rama workstation ya no se presenta como un solo bloque opaco.
Tambien hay mejoras concretas de capacidad. En la model card oficial, 31B muestra mejoras importantes frente a Gemma 3 27B en benchmarks destacados como matematica estilo AIME y coding estilo LiveCodeBench. El punto no es convertir la guia en una religion del benchmark. El punto es entender que el lanzamiento no es cosmetico. Debajo de Gemma 4 hay una historia real de progreso de capacidades y de mejor diseno de familia.
El otro cambio importante es la postura de despliegue. Google esta intentando que Gemma 4 se lea como una familia usable desde varios angulos: AI Studio para la ruta hosted de la rama grande, AI Edge y Android para la rama pequena, y soporte desde el dia uno en Hugging Face, Ollama, MLX, llama.cpp y vLLM para self-hosted. Eso es mas util que decir simplemente “Gemma 4 es mas inteligente”. La lectura mas correcta es otra: Gemma 4 deja mucho mas claro donde encaja cada parte de la familia.
Donde conviene ejecutar Gemma 4 hoy
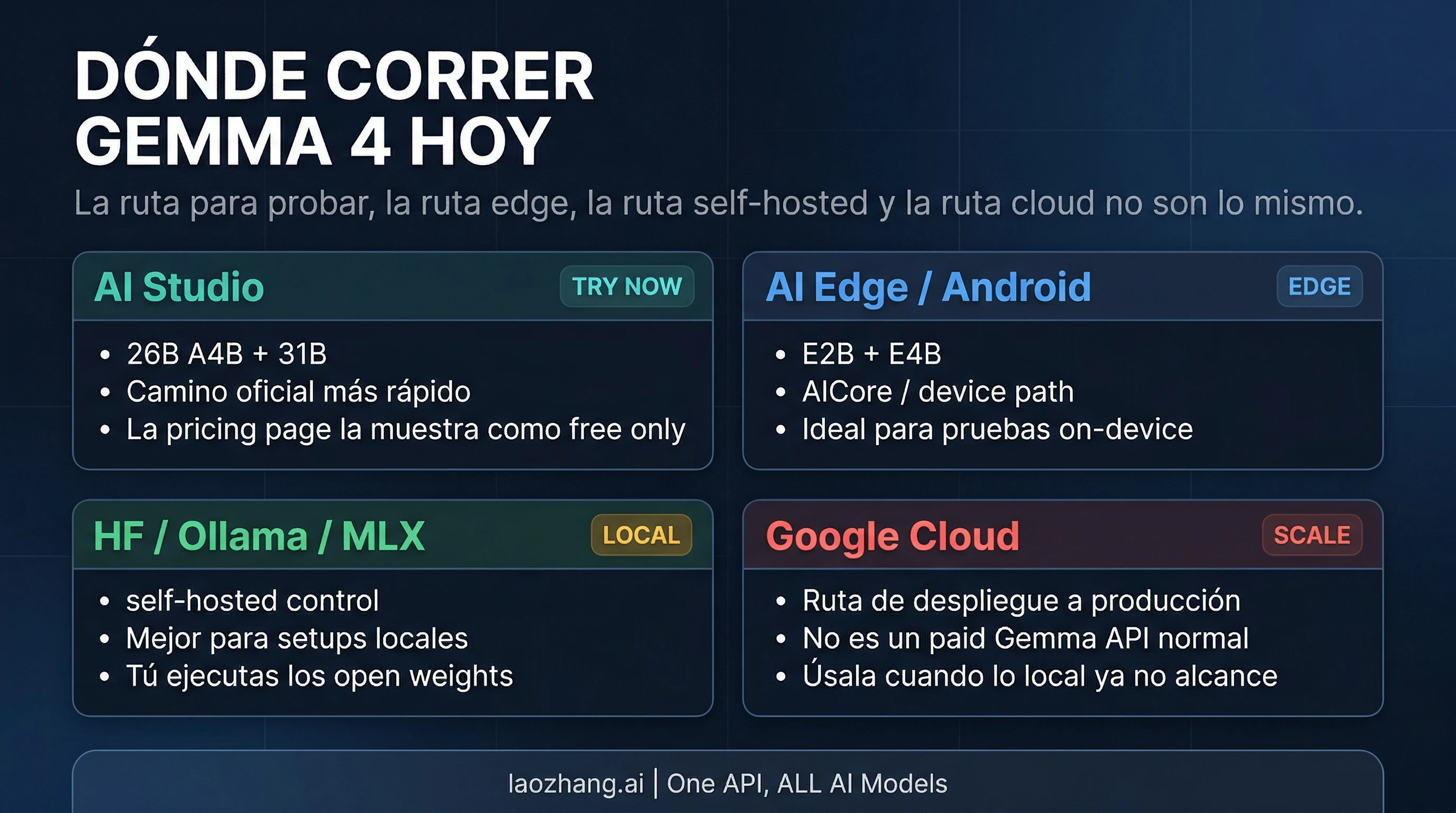
Donde deberias ejecutar Gemma 4 depende de la rama que hayas elegido.
Si quieres la forma mas simple de probar la rama grande, el blog oficial de Google apunta a AI Studio para 31B y 26B A4B. Es la ruta oficial mas rapida para evaluar la rama workstation sin montar primero un stack local. Pero hay un matiz importante: la pricing page actual de Gemini Developer API muestra Gemma 4 como free only y no la presenta como una linea paid normal. Eso significa que “se puede probar online” es correcto, pero describirla hoy como una opcion de pago estandar iria mas alla de lo que muestra la pagina oficial.
Si te interesa la rama edge, las senales oficiales van por otro lado. El Android Developers Blog conecta Gemma 4 con AICore Developer Preview y con futuros dispositivos apoyados en Gemini Nano 4, mientras que el material de lanzamiento apunta E4B y E2B hacia AI Edge. La rama pequena, por tanto, se lee como una ruta real de on-device, no como un simple extra de marketing.
Si lo que quieres es control local y self-hosted, el material de Google destaca la ecosystem open model habitual: Hugging Face, Kaggle, Ollama, Transformers, MLX, llama.cpp, vLLM y otros runtimes. Esa es la ruta correcta si tu objetivo real es ejecutar Gemma 4 en tu propia workstation, integrarla en un flujo local de coding o meterla en un stack local mas amplio. Si ese es tu siguiente paso, tiene mas sentido leer la guia en ingles sobre OpenClaw LLM setup que otra recapitulacion generica del lanzamiento.
Si ya estas pensando en despliegue a escala de produccion, Google empuja esa narrativa hacia Google Cloud, no hacia una linea simple de pago por uso dentro de la tabla actual de Gemini. Ese borde de producto importa. “Gemma 4 puede correr dentro del ecosistema de Google” es verdad. “Gemma 4 hoy se comporta como un hosted Gemini normal de pago” no es lo que muestra la pricing page publica.
Las mejores elecciones segun el escenario
Si quieres un default general para edge, empieza por E4B. Es la opcion que mejor equilibra la direccion de producto que Google esta marcando en edge con el margen que necesitas para un uso local multimodal serio.
Si tu cuello de botella real es memoria, bateria o latencia, empieza por E2B. No es el default de toda la familia, pero si es la respuesta mas honesta cuando el footprint importa mas que el techo.
Si buscas un modelo local para coding o reasoning sobre hardware de clase workstation, empieza por 26B A4B. Esta es la recomendacion practica mas importante de toda la guia. Gracias al diseno MoE, puedes entrar en la rama grande sin convertir automaticamente el dense mas pesado en tu primera parada. Para muchos desarrolladores que quieren un modelo abierto local para coding, reasoning y contexto mas largo, 26B A4B sera el primer objetivo de evaluacion con mas sentido.
Si priorizas calidad bruta de dense model o margen para fine-tuning, da el salto a 31B. Tiene sentido solo cuando tu presupuesto de hardware es mas fuerte y quieres la ruta dense a proposito, no por inercia.
Si necesitas audio on-device, quedate en la rama E2B / E4B. La model card deja clara esa frontera de producto, y esa frontera pesa mas que perseguir el mayor numero de parametros posible en la rama equivocada.
Si solo quieres comprobar si Gemma 4 merece tu tiempo antes de montar nada, no empieces por construir un despliegue local. La rama grande se prueba primero en AI Studio y la pequena por la via Android / AI Edge preview. El peor primer paso es invertir horas en una ruta local sin haber decidido aun a que rama perteneces.
Cuando Gemma 4 no es la respuesta correcta
Gemma 4 se sobrevende con facilidad porque toca varios temas muy atractivos a la vez: open weights, Apache 2.0, contexto largo, un reasoning posture fuerte y una ambicion edge muy clara. Aun asi, eso no la convierte en la mejor ruta para todos los usuarios.
Si lo que realmente necesitas es una API gestionada con pricing estable y claro, Gemma 4 hoy no es tan directa como la ruta managed de Gemini. De hecho, la utilidad de la pricing page actual esta precisamente en que deja ver esa frontera. En ese caso, lo mas util es seguir con la guia en ingles sobre Gemini API pricing.
Si lo que necesitas es el stack frontier cerrado mas fuerte posible y no quieres asumir ningun trabajo de self-hosting ni de open weights, Gemma 4 tampoco es necesariamente la respuesta. Su fortaleza esta en la apertura y la capacidad de despliegue, no en borrar la diferencia entre open models y sistemas frontier gestionados.
Y si lo que buscas es generacion de imagen o video, Gemma 4 es claramente la familia equivocada. La model card es bastante explicita: Gemma 4 es una familia multimodal que recibe texto e imagen y entrega texto, no una linea de generacion visual.
El modelo mental correcto
La mejor forma de pensar Gemma 4 no es como otro nombre de lanzamiento, sino como una familia abierta de dos ramas.
La primera rama es la rama edge: E2B y E4B, donde importan mas la ejecucion local, el uso multimodal en dispositivo y la practicidad de nivel dispositivo. La segunda es la rama workstation: 26B A4B y 31B, donde lo importante es el contexto mas largo y el razonamiento local mas pesado. Si eliges bien la rama primero, Gemma 4 se vuelve bastante simple. Si saltas ese paso, los cuatro modelos vuelven a mezclarse.
Por eso la respuesta rapida mas util sigue siendo la mas sencilla: si quieres una ruta edge seria, empieza por E4B; si quieres una ruta workstation seria, empieza por 26B A4B. Solo ve mas pequeno cuando la eficiencia sea el cuello de botella real, y solo ve mas denso cuando tengas claro el coste de 31B.