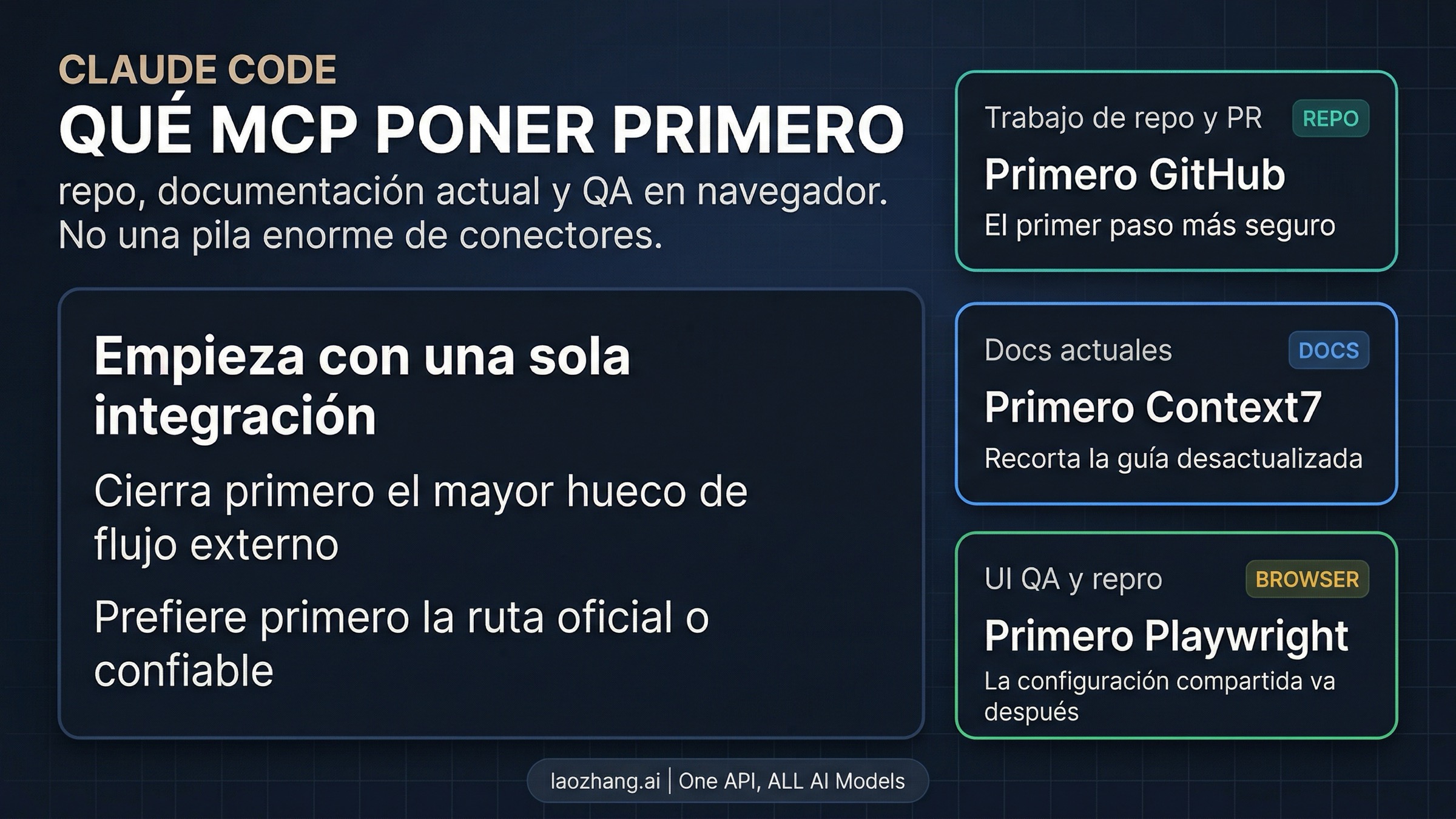
Si quieres una respuesta rápida, no empieces instalando todos los Claude Code MCP que parezcan populares. Empieza por la integración que cierra tu mayor external workflow gap. A fecha de 8 de abril de 2026, eso suele significar GitHub si el cuello de botella son repos, PR e issues; Context7 u otro current-docs MCP si lo que te frena son docs desactualizadas; Playwright si el trabajo real es browser QA y reproducción de UI; y observabilidad como Sentry solo cuando production debugging ya es parte real de tu semana. Si existe una official surface o una ruta claramente trusted, empieza por ahí. Y solo cuando el workflow ya se haya ganado su sitio conviene subir a .mcp.json o a un plugin-bundled MCP.
Esta respuesta es bastante más estrecha que la mayoría de listas largas de “MCP recomendados para Claude Code”, pero por eso suele ser más útil. El error caro aquí no es perderte otro nombre de server. El error caro es convertir Claude Code en una pila de conectores antes de que una sola integración haya demostrado que vale la pena.
A 8 de abril de 2026, la documentación actual de Anthropic ya separa official connectors, remote MCP servers, local o project-scoped MCP configs y plugin-bundled MCP, en lugar de tratarlos como un marketplace plano. Las Claude Code MCP docs también dejan claro que los servers de proyecto viven en .mcp.json, que requieren approval antes de usarse y que los servers de terceros traen una frontera de confianza y un prompt-injection risk que no conviene aplanar. Eso significa que la primera decisión no es solo una tool choice. También es una decisión de packaging y de confianza.
“Nota de evidencia: esta guía se apoya en las Claude Code MCP docs, Connectors overview y connector help-center guide actuales de Anthropic, revisadas el 8 de abril de 2026, y en el lenguaje con el que un lector hispanohablante formula hoy
qué instalar primero.
Un route board rápido para la primera decisión

Antes de comparar una docena de server names, decide qué workflow está roto hoy de verdad.
| Si tu bottleneck está en... | Primer MCP para probar | Mejor first surface | Stop rule |
|---|---|---|---|
| repo, issues, PR y contexto de review | GitHub | official o vetted GitHub integration | si lo único que falta es contexto fuera del repo, para en GitHub |
| docs de framework o API que llegan viejas | Context7 u otro current-docs MCP | trusted remote docs server | si un docs path ya funciona, no apiles más tools de documentación |
| browser QA, UI flows y repro steps | Playwright | trusted automation server, normalmente primero en personal | sube a project scope solo cuando el workflow ya sea realmente compartido |
| incidents, traces y debugging de producción | Sentry u otro observability connector | úsalo solo si incident response ya es un trabajo recurrente | si los incidents no son tu trabajo central, no lo añadas aún |
La idea de este tablero no es canonizar cuatro nombres para siempre. Es obligarte a responder la pregunta que muchos directorios evitan: qué deberías añadir primero y qué deberías decidir no añadir todavía.
La primera decisión no es qué server elegir, sino qué surface estás eligiendo
Mucha gente llega aquí buscando una shopping list de MCP servers. En la práctica, el primer error suele ocurrir un paso antes: tratar todas las integrations de Claude Code como si fueran el mismo tipo de cosa.
No lo son. En el current ecosystem de Anthropic ya hay surfaces lo bastante distintas como para cambiar la recomendación. Official connector es el arranque más limpio cuando Anthropic ya soporta ese service de forma directa, porque te da el camino con menos friction y menos ownership de configuración desde el primer día. Remote MCP server es otra cosa: suele tener sentido cuando necesitas una tool o data source sin ruta first-party, pero también exige confiar en quien opera ese server. Project-scoped .mcp.json es otra capa distinta, porque ahí la integración deja de ser solo tuya y pasa a ser decisión del repo. Y plugin-bundled MCP es la respuesta de packaging para el momento en que el propio setup ya necesita distribución y lifecycle management, no solo experimentos locales.
Por eso una giant top-20 list es un punto de partida tan flojo. Asume que el problema real es discovery. Con mucha más frecuencia, el problema real es elegir la surface más pequeña que cierre el missing workflow sin abrir un lío de trust boundary.
Una secuencia más útil es esta:
- ¿Existe un official connector o al menos una surface claramente vetted para ese service?
- Si no existe, ¿hay un remote MCP server que cierre un gap real y repetido?
- Si lo hay, ¿sigues en un personal workflow o esto ya pertenece a un shared repo workflow?
- Si debe vivir en el repo, ¿basta con
.mcp.jsono el setup ya merece plugin-style packaging?
Si respondes esas cuatro preguntas con honestidad, elegir un server name se vuelve mucho más fácil. Si te las saltas, todas las integrations parecen igual de plausibles.
Los starter MCP que de verdad merecen espacio el primer día

La mejor ruta inicial depende mucho menos de la popularidad y mucho más de qué es lo que más interrumpe tu trabajo. Por eso una guía workflow-first es más útil que una leaderboard.
GitHub es el mejor primer MCP para la mayoría de workflows centrados en repos
Si el día se te rompe una y otra vez alrededor de issues, pull requests, diffs, review comments o repository metadata, GitHub suele ser la integración inicial más fuerte para la mayoría de equipos. Cierra un loop real que Claude Code no puede resolver del todo solo con los archivos locales.
Además, es la clase de integración cuya utilidad aparece muy rápido. No necesitas una teoría complicada para justificarla. Si sales constantemente de Claude Code para mirar PR threads, issue history o el estado actual del repo, GitHub ya es tu mejor primera jugada con bastante probabilidad.
GitHub le gana a MCP más vistosos no por ser más “avanzado”, sino porque reduce context switching en un workflow que ya sabes que existe. Un buen primer MCP debería acortar un bottleneck real, no añadir un nuevo playground que ahora también tendrás que mantener.
Si GitHub era lo único que te faltaba, para ahí de momento. No necesitas una segunda o tercera integración solo porque la primera funcionó.
Un current-docs MCP suele ser el mejor primer add de terceros cuando el problema es la frescura de la documentación
Para mucha gente, lo que falta primero no es otro issue tracker ni otra tool de navegador. Lo que falta es dejar de recibir respuestas basadas en memoria vieja cuando el framework, la librería o el SDK cambiaron hace poco.
Ahí es donde Context7 o un current-docs MCP parecido se gana su sitio. Suele ser el primer third-party server que merece entrar, porque el valor es obvio: mejor implementation guidance, menos APIs alucinadas y menos alt-tab manual para comprobar docs actuales.
Este tipo de integración de docs es fácil de infravalorar porque no parece tan espectacular como la browser automation. Pero si la documentación vieja ya te está costando reintentos varias veces por semana, puede ser el first add con más leverage de todos.
También hay un stop rule muy claro aquí. Si un docs path limpio ya resolvió el freshness problem, no añadas más tools de documentación de inmediato. El objetivo no es darle a Claude cinco formas de leer la misma documentación. El objetivo es dejar de perder tiempo por guidance desactualizada.
Playwright es el primer add correcto cuando falta prueba observable del comportamiento UI
Cuando el bottleneck ya no está en escribir código sino en verificar que el código se comporta bien en el navegador, el primer MCP suele ser Playwright.
Las integrations tipo Playwright se ganan el day-one space porque convierten una conversación frontend vaga en observable behavior. Si Claude Code puede abrir la app, recorrer un flow, inspeccionar el state de la página y ayudar a reproducir un bug, lo que cambia no es solo la cantidad de información. Cambia el tipo de trabajo que se vuelve posible.
Eso resulta especialmente útil para equipos atrapados en el bucle de “creo que esto debería funcionar” seguido de comprobaciones manuales en el navegador. Cuando la browser automation forma parte del workflow, Claude puede ayudar a validar UI fixes, reproducir regressions y acortar el camino entre hipótesis y evidence.
La parte que pide disciplina es el packaging. No saltes a un shared project setup solo porque Playwright ya mostró valor. Si el workflow todavía lo está demostrando una sola persona, déjalo en personal. .mcp.json solo tiene sentido cuando ese patrón de browser testing ya es lo bastante estable como para que el repo lo posea.
Sentry y otros observability connectors solo deberían ir pronto si incident work es parte real del trabajo
El acceso a observabilidad es potente, pero no es un day-one add universal. Solo debe entrar pronto cuando production debugging o incident response ya forman parte real de tu weekly workflow.
Si tus semanas giran con frecuencia alrededor de exceptions, traces, error triage o investigación de guardia, un monitoring connector como Sentry puede ser un primer o segundo add de mucho valor. Le da a Claude Code el operational context que el código local no trae consigo, y eso es justo lo que suele faltar en incident work.
Pero este también es el punto donde muchos setups se vuelven demasiado ambiciosos demasiado rápido. Las integrations de observabilidad impresionan, así que los equipos las instalan antes de demostrar que Claude necesita de verdad ese live access para el trabajo que hacen. Si los incidents son ocasionales y no centrales, no conviertas observability en un prestige add.
Cuándo official connectors ganan a raw servers, y cuándo project scope gana a personal setup

Una vez que el workflow está claro, la siguiente decisión es quién debe poseer la integración.
Usa primero la official o la surface claramente vetted cuando exista. Las current connector surfaces de Anthropic ya son lo bastante buenas como para no saltar por defecto a raw server config solo porque parezca más técnico. El camino first-party no siempre existe, pero cuando existe suele reducir setup ambiguity y trust overhead.
Usa un remote MCP server cuando el workflow es real pero la official surface no existe. Este es el caso normal para muchas third-party tools. Y también es el punto donde trust importa más. Las current Claude Code MCP docs de Anthropic advierten de forma explícita que Anthropic no ha verificado la corrección ni la seguridad de todos los third-party servers, y que un server que expone untrusted content puede abrir un prompt-injection risk. Eso no significa “nunca uses third-party MCP”. Significa “usa third-party MCP solo para un recurring workflow real”.
Usa project-scoped .mcp.json cuando la integración deba pertenecer al repo y no a una sola persona. Mucha gente falla aquí porque trata el shared config como una medalla de seriedad. En realidad, un server de proyecto solo tiene sentido cuando varias personas del repo se benefician de la misma integration y el setup ya está lo bastante estable como para estandarizarlo. Si todavía estás en fase de “voy a probar si me sirve”, mantenlo personal.
Usa plugin-bundled MCP cuando la integración ya tiene necesidades de packaging y lifecycle. Para la mayoría de equipos eso no es el primer paso, sino un paso posterior. El plugin bundling importa cuando la distribución, el startup behavior o la activación consistente en el equipo ya forman parte del problema.
La secuencia práctica es simple: personal first, shared config second, packaged distribution later. Si inviertes ese orden, casi siempre empiezas pagando por sophistication antes de haber ganado usefulness.
La peor primera jugada es el connector sprawl
La forma más fácil de hacer que Claude Code “parezca más potente” en el sentido equivocado es seguir añadiendo integrations porque cada una, vista por separado, parece razonable.
El connector sprawl crea al menos tres costes.
El primero es trust cost. Las current MCP docs de Anthropic dejan claro que la confianza en terceros no viene dada. Si un server puede traer o transformar untrusted content, también puede convertirse en parte de un prompt-injection path o de otro workflow risk más amplio. Un third-party server debería justificarse por valor real, no por lo bien que se ve en una demo.
El segundo es attention cost. Más integrations no añaden solo capability. También añaden otro setup que recordar, otro camino de debugging, otro approval path y otro hábito que mantener. Si un server solo ayuda de vez en cuando, su maintenance burden puede superar con facilidad su valor.
El tercero es usage cost. Claude Code ya es context-heavy. Tool definitions, tool results y loops de automation más amplios hacen las sesiones más ruidosas y más caras. Si el workflow no es lo bastante importante como para justificar ese coste, la integración no está ayudando tanto como parece.
Por eso el stop rule importa tanto: si una integración ya cerró el gap real, haz una pausa. Deja que el siguiente gap se revele solo. Un stack compacto que de verdad usas casi siempre gana a un stack amplio que solo admiras.
Conviene marcar otra frontera de forma explícita. Si el problema real no es external tool access sino reusable workflow knowledge dentro del repo, la lectura correcta es nuestra guía de Claude Code skills. Skills encaja mejor cuando falta conocimiento procedural interno. MCP encaja mejor cuando falta acceso externo a tools o datos.
Y si antes de elegir integrations todavía no tienes asentado el setup más amplio de Claude Code, esta página no debería convertirse en la entrada total. Empieza antes por la guía de instalación de Claude Code. Esta página debe seguir siendo más estrecha: ayuda a elegir la primera integración, no a reconstruir todo el entorno.
FAQ
¿Qué MCP debería añadir primero en Claude Code?
El que cierre tu mayor external workflow gap. Para la mayoría de developers muy centrados en repos, eso suele ser GitHub. Para problemas de docs freshness, un current-docs MCP como Context7. Para frontend verification, Playwright. No elijas por novedad. Elige por interruption cost.
¿Debería usar connectors o raw MCP server configs?
Usa la surface más simple y más trusted que ya te deje terminar el trabajo. Si existe un official connector o una ruta claramente vetted, esa suele ser la mejor first move. Llega a raw o third-party server config solo cuando el workflow es real y la ruta official no existe.
¿Cuándo tiene sentido .mcp.json?
Cuando la integración la necesita el repo, no solo una persona. Si todavía estás comprobando si el workflow importa de verdad, déjalo en personal. El shared config debería reflejar una necesidad estable y repetida, no un experimento temprano.
¿Los third-party MCP servers son seguros?
No automáticamente. Las current Claude Code MCP docs de Anthropic advierten de forma explícita que no todos los third-party MCP servers han sido verificados en corrección o seguridad, y que los servers que exponen untrusted content pueden traer prompt-injection risk. Trátalos como dependencias reales de workflow, no como extensiones inocuas del navegador.
¿Cuántos MCP debería añadir al principio?
Normalmente uno o dos bastan. Si la primera integración ya resuelve el main gap, para ahí. El mejor setup inicial de Claude Code MCP no es el más grande, sino el más pequeño que ya ha empezado a pagarse solo.
¿Esto es lo mismo que elegir Claude Code skills?
No. Skills resuelve reusable workflow knowledge interno y MCP resuelve external tool y data access. Solo se parecen en el borde donde todavía estás decidiendo si lo que falta es conocimiento o acceso.
La estrategia realmente útil con Claude Code MCP es más pequeña que el propio término de búsqueda. Empieza por el workflow bottleneck, no por el mapa del ecosistema. Da prioridad a official o clearly trusted surfaces y deja el shared project setup para cuando el workflow ya sea repetido y claro. Casi todo lo demás es ruido.