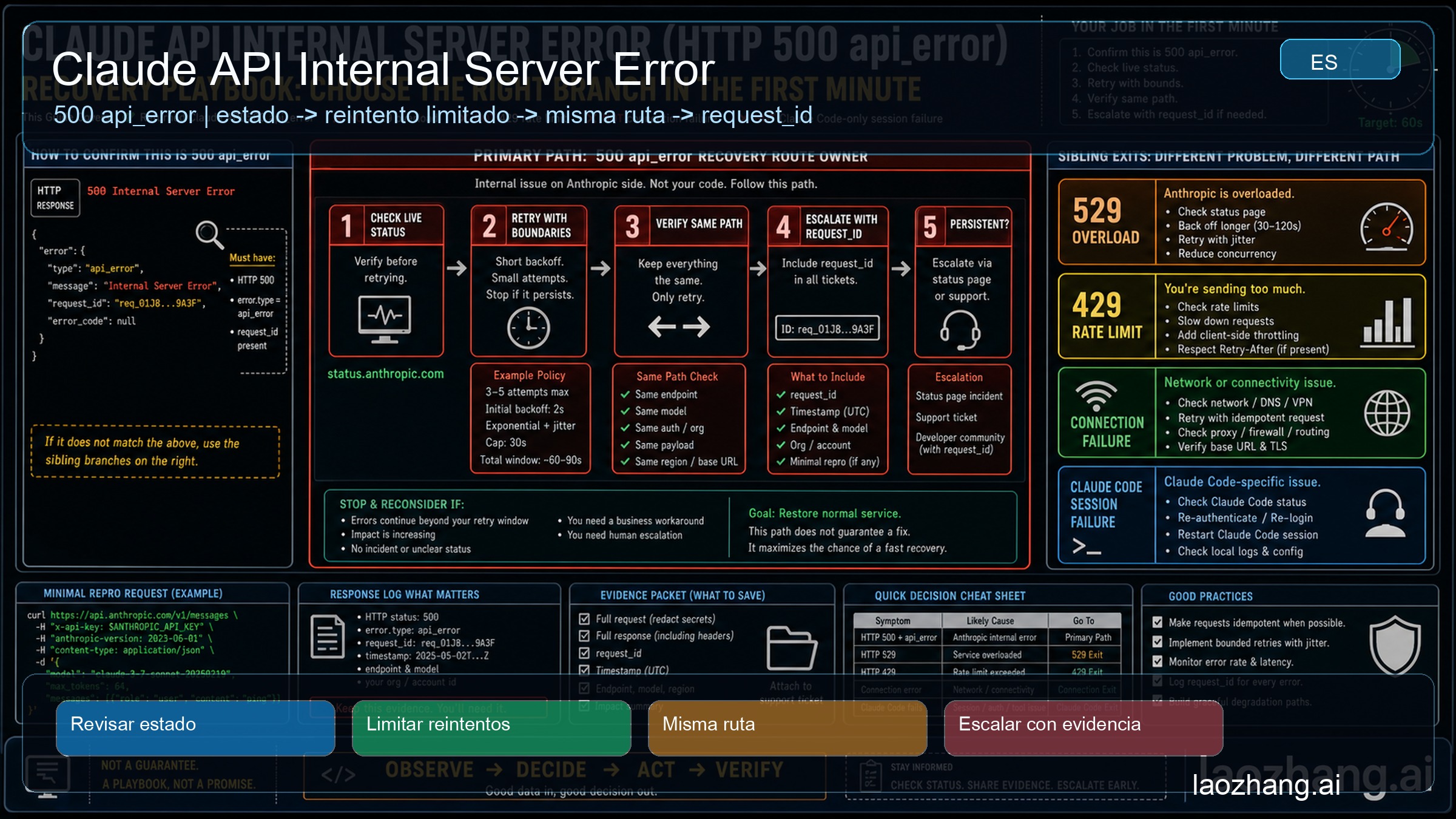
Si una llamada a Claude API devuelve API Error: 500, con api_error y el mensaje Internal server error, trátala primero como un error de servidor ya devuelto por la API. No es una prueba de que tu API key esté rota, de que la facturación haya fallado, de que el prompt sea inválido, de que la cuenta esté bloqueada o de que tengas que cambiar de proveedor.
El primer minuto debe ser pequeño y verificable: revisa el Claude Status actual, guarda el cuerpo completo del error, conserva request_id o el header request-id, y solo haz un retry corto con jitter y límite. En esa fase no cambies model, endpoint, auth route, SDK, gateway route ni request body.
El estado público es una señal fechada. En esta ejecución se comprobó Claude Status a 2026-05-02T13:51Z y el status API público respondió all systems operational, aunque los incidentes resueltos recientes todavía mostraban eventos API y model-specific de elevated errors. Una página verde reduce la rama de incidente activo, pero no demuestra que tu camino exacto ya esté recuperado.
Tablero de decisión en 60 segundos
Usa este tablero antes de rotar claves, tocar billing, reescribir prompts, subir timeouts o cambiar de proveedor. Si tienes HTTP status, error body y request id, la solicitud al menos llegó a una capa de API. Eso no es lo mismo que una falla de conexión sin status, sin body y sin request id.
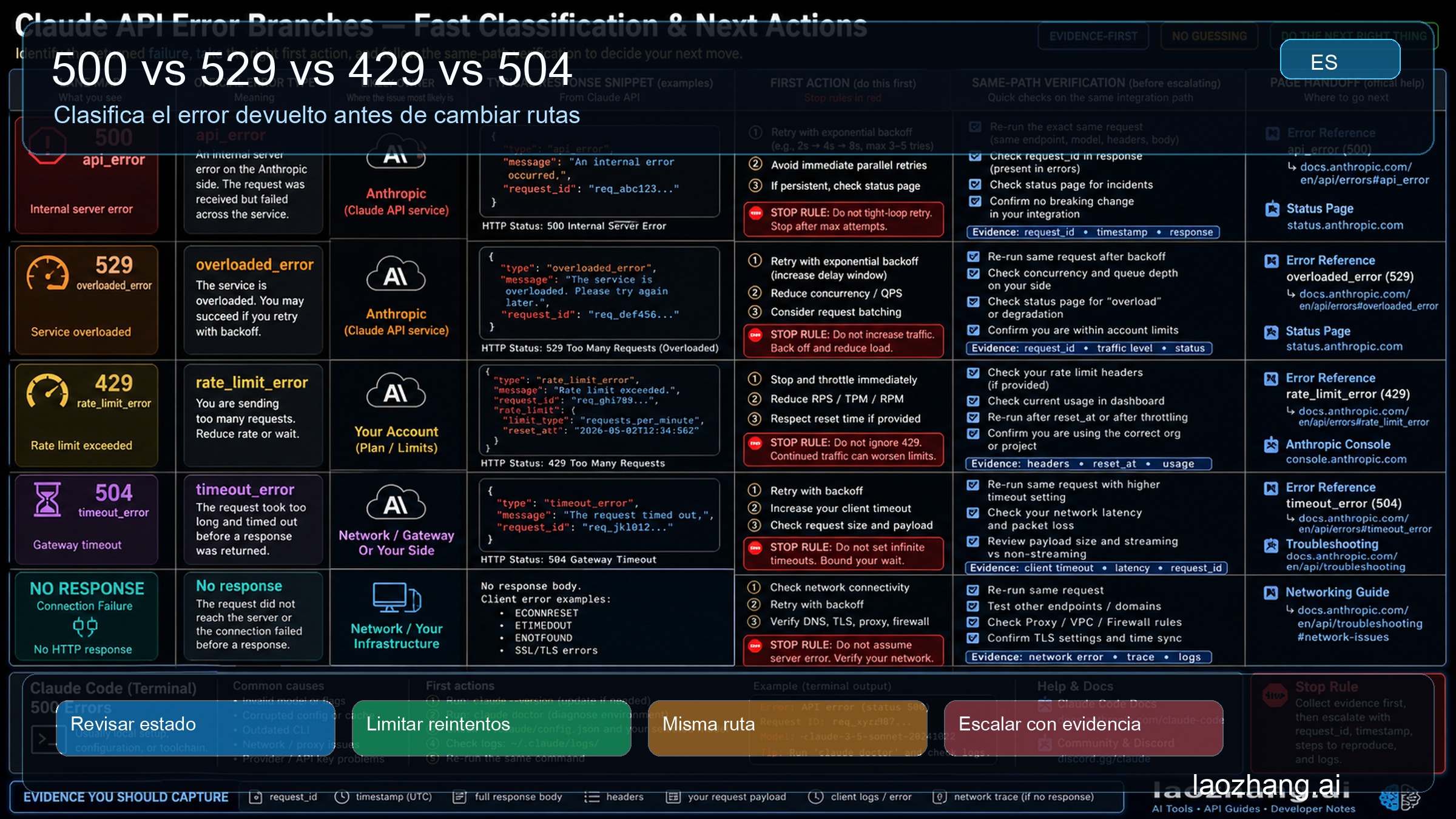
| Señal exacta | Trátala como | Primer movimiento | Verificación del mismo camino | Siguiente rama |
|---|---|---|---|---|
500, api_error, Internal server error | Error de servidor devuelto por Claude API | Revisar status, guardar request_id, retry corto | Mismo model, endpoint, auth route y request body | Mantener la rama 500 |
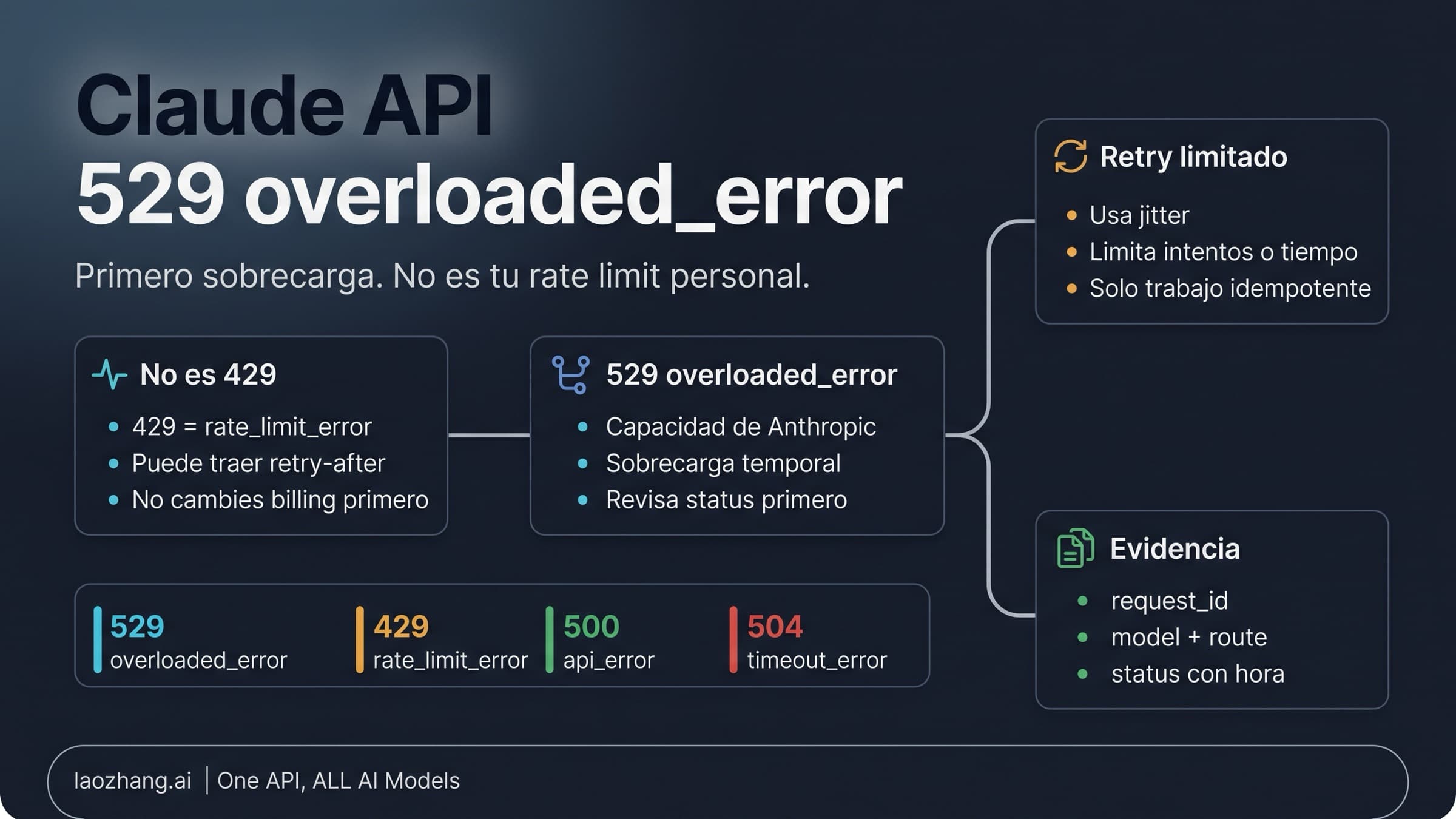
529, overloaded_error | Sobrecarga de capacidad | Revisar status, añadir jitter, reducir presión | Mismo camino tras cooldown | Claude API 529 overloaded |
429, rate_limit_error | Límite, aceleración, cuota o techo del route owner | Revisar limit headers y credential route | Reintentar solo tras la ventana o corrección | Claude API rate limit |
504, timeout_error | Timeout o solicitud demasiado larga | Streaming, reducción, partición o batch | Cambiar una sola forma de request y verificar | Quedarse en timeout |
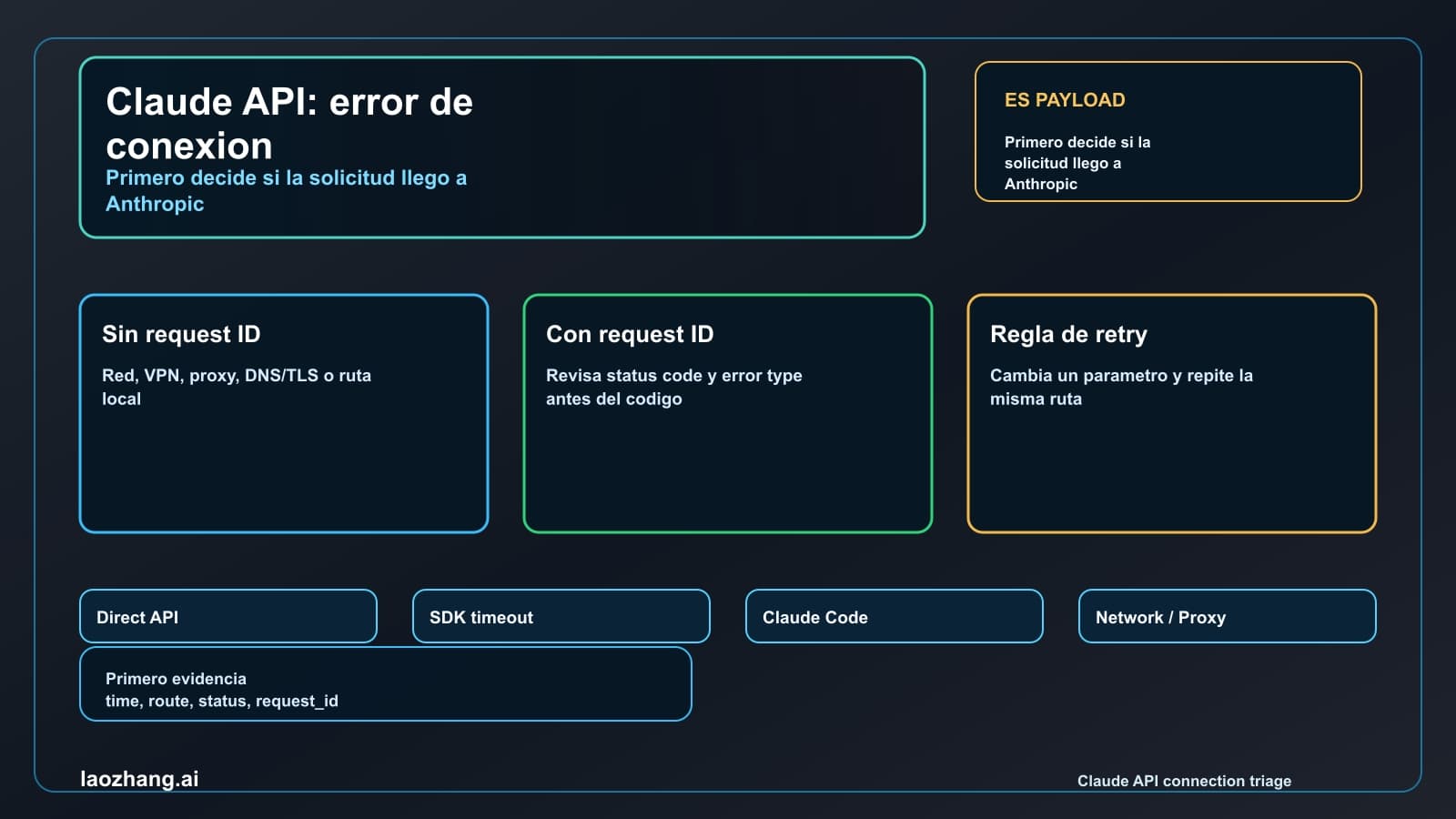
Sin status, sin body, sin request-id | Falla de conexión | Red, VPN, proxy, firewall, DNS, TLS, SDK timeout | Mismo payload tras cambiar una variable de red | Claude API connection error |
Claude Code muestra API Error: 500 | Superficie Claude Code sobre la API | Revisar /status, sesión, login, auth owner y route | Mismo terminal tras una corrección por rama | Claude Code API Error 500 |
| Gateway o provider route devuelve 500 | Route owner o compatibilidad | Comparar direct Anthropic y gateway sin cambiar prompt | Mismo prompt, model intent, timeout e input size | Comparar rutas, no adivinar |
La respuesta útil es estrecha: un Claude API Internal Server Error limpio pertenece a la rama 500 api_error. Puede ser transitorio. También puede repetirse en un model path, account route o request shape concreto. Tu trabajo no es cambiar todo al mismo tiempo, sino conservar la evidencia que distingue un fallo temporal, un fallo persistente del camino y una rama mal clasificada.
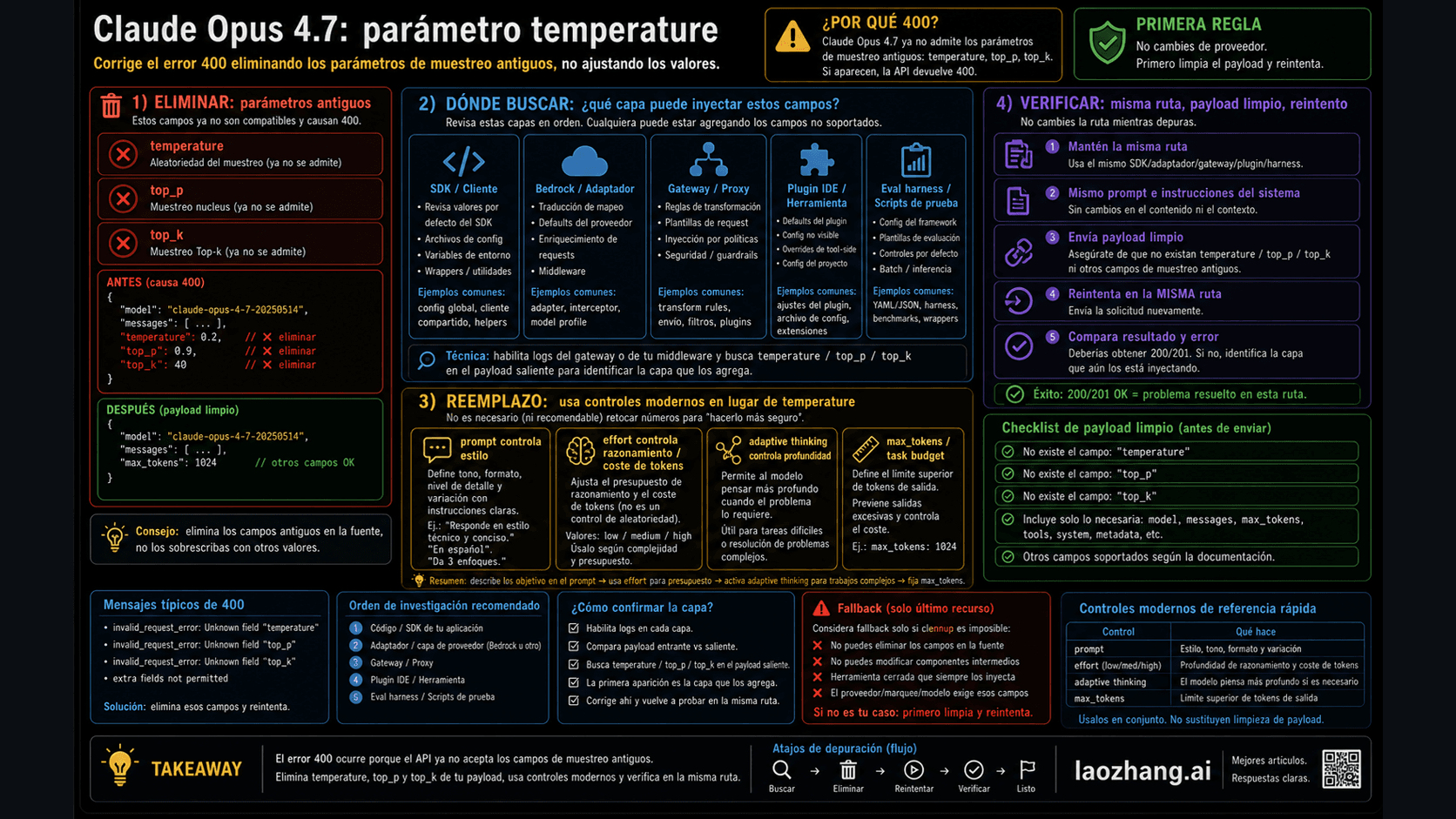
Qué significa 500 api_error en Claude API
La API error reference de Anthropic define HTTP 500 como api_error. La misma referencia separa 429 rate_limit_error, 504 timeout_error y 529 overloaded_error. Las respuestas de error incluyen error.type, error.message y request_id; cada API response también incluye el header request-id.
Esa taxonomía oficial marca la frontera de recuperación. Un 500 api_error devuelto es una falla interna inesperada de API, no un mensaje normal de estado de cuenta. No lo conviertas de inmediato en una hipótesis de billing, key age, prompt inválido o cache local. Esas ramas tienen señales propias. Si la API ya devolvió api_error, empieza por manejo de error de servidor y captura de evidencia.
request_id es más importante que la captura de pantalla. Una imagen del texto Internal server error ayuda a explicar el momento, pero el identificador de request permite que soporte o tu equipo de plataforma rastreen una llamada concreta. Si tu SDK expone headers, guarda request-id. Si el JSON trae request_id, guárdalo. Si no existe ninguno, quizá no estás en la rama returned-error y la guía de conexión es mejor.
Separa 500 de 529. Ambos pueden sentirse como problema del lado de Anthropic, porque una integración que funcionaba deja de funcionar sin despliegue local. Pero el comportamiento del cliente cambia. Una rama 529 pide reducir presión, poner cola, enfriar y evitar retry storm. Una rama 500 pide status, retry breve, request identifiers y escalación si el mismo camino sigue fallando.
También separa 500 de 504. Un timeout_error apunta a duración, idle drop, streaming o necesidad de batch. Para trabajos largos, Anthropic recomienda streaming o Message Batches. Si la señal exacta es timeout, cambia la forma del request de manera intencional; no lo trates como Internal Server Error ni empieces por credenciales.
Recovery loop seguro
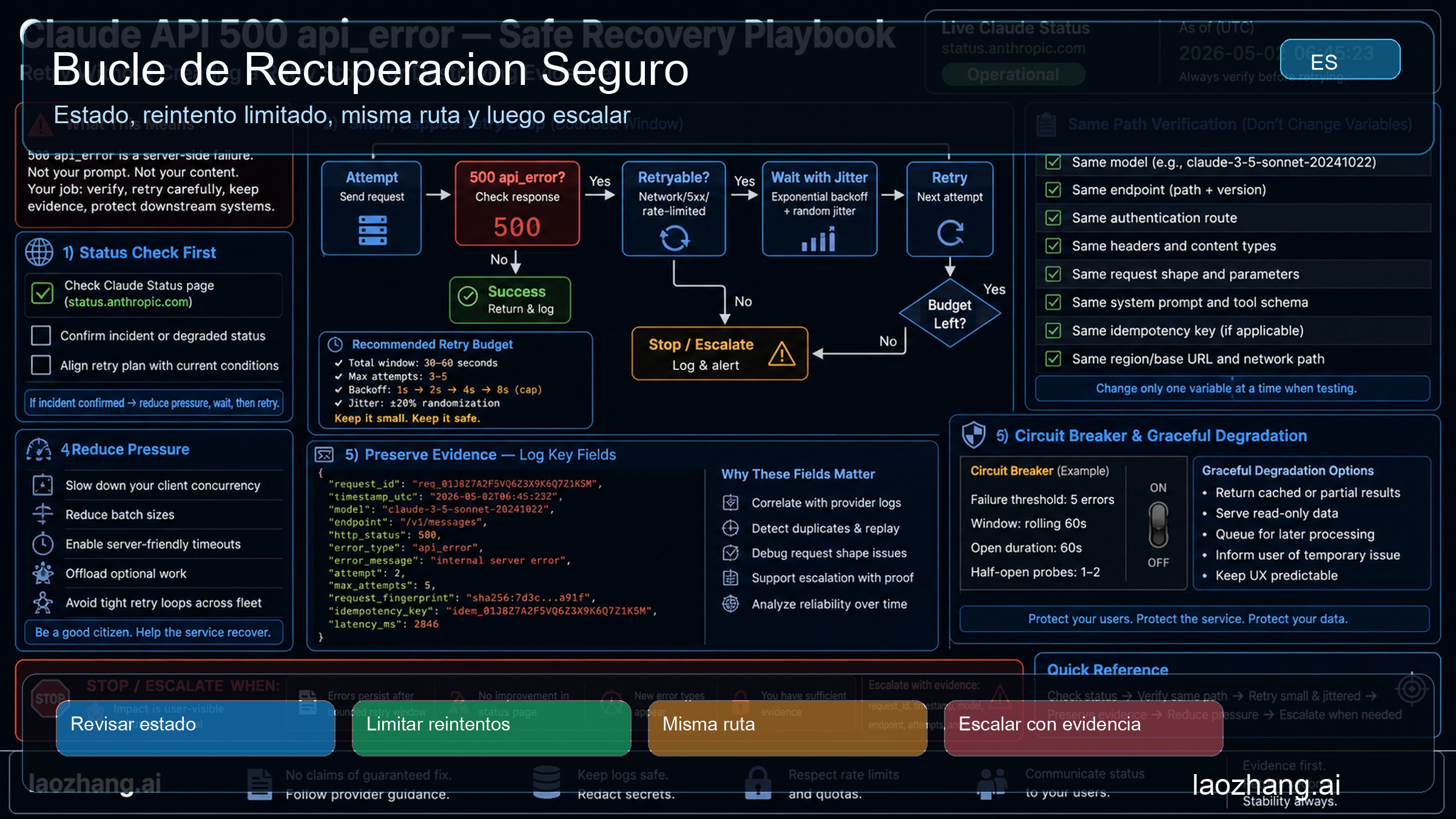
Un buen recovery loop para 500 es deliberadamente aburrido. Primero revisa Claude Status y anota la hora. Luego guarda error body, response headers y request_id. Después decide si el trabajo es seguro de repetir. Una llamada read-only, un item interno de batch y una acción visible para el usuario no deben compartir la misma regla de retry.
Si haces retry, usa un presupuesto. Define número de intentos, tiempo total, jitter y stop condition. Un turno de chat donde el usuario espera puede tolerar una o dos repeticiones en segundos. Un batch de fondo puede esperar más. Una acción con efectos secundarios requiere deduplicación del lado del caller antes de cualquier retry.
La verificación debe quedarse en el mismo camino. Mismo model, endpoint, auth owner, SDK o gateway, request body y timeout class. La estabilidad del camino no es una preferencia estética. Es la única forma de saber si el path original se recuperó. Si cambias model, key, prompt, gateway, timeout y red al mismo tiempo, un éxito posterior no revela la causa.
Si Claude Status muestra un incidente activo de API, deja de hacer cirugía local. Pausa trabajo no urgente, encola jobs de fondo y vuelve a probar el mismo path cuando el incidente se actualice. Cambiar variables durante un incidente destruye la comparación limpia. Si el status está verde, un retry corto aún puede ser válido, pero debe tener límite.
Cuando el mismo camino tiene éxito después de una pausa corta, probablemente fue un error transitorio de API. Si el mismo camino sigue devolviendo 500 api_error después del presupuesto, detente. Ese es el punto de evidencia, no de cambios aleatorios. Un gateway puede servir como ruta degradada o comparación, pero guarda primero la falla original.
Controles de producción para 500 repetidos
La triage manual resuelve una vez. En producción necesitas que retry, logging, circuit breaker y degraded mode respeten la misma disciplina de ramas.
Usa retry budget, no retry infinito. Limita attempts, elapsed time y concurrency. Añade jitter. Registra retry count, backoff window y resultado final. Después del incidente, el servicio debe poder responder cuántas llamadas se recuperaron por retry, cuántas terminaron fallando y qué path compartían.
Separa trabajo idempotente y no idempotente. Una clasificación read-only, un job interno, una creación visible para el usuario y una acción cercana a pago no deberían tener el mismo retry policy. Un server error no garantiza que nada haya ocurrido downstream. Usa request key, job id o deduplicación de negocio antes de repetir.
Añade circuit breaker para 500 api_error repetido en la misma ruta. Si la tasa de error pasa un umbral, pausa llamadas no urgentes, encola batch work o muestra un estado degradado controlado. Para reabrir, usa primero un same-path probe pequeño y luego sube tráfico gradualmente. Eso evita que un incidente corto se convierta en una tormenta creada por tu cliente.
Los logs deben ser branch-aware. Como mínimo guarda HTTP status, error.type, error.message, request_id o request-id, model, endpoint, SDK version, auth route, gateway route, request size class, retry count y timestamp. No registres API keys, datos de clientes, prompts privados, logs completos de proxy ni dumps de entorno sin redactar.
Cambiar model debe ser una decisión de producto, no la primera maniobra diagnóstica. Si un model path falla y otro model sirve para el trabajo del usuario, un fallback temporal puede ser razonable. Etiquétalo como degraded routing, conserva evidencia del path original y verifica luego si se recuperó.
Separar superficie y route owner
La frase Claude API Internal Server Error aparece en entornos mixtos. Direct API, Claude Code, SDK exception, gateway, timeout y connection failure sin respuesta pueden verse parecidos cuando solo miras un log rojo.
Si la superficie visible es Claude Code, usa la rama Claude Code. Claude Code llama a Claude API, pero añade login state, resumed sessions, OAuth frente a API-key ownership, variables de shell, proxies y diagnósticos de comando. Para terminal, empieza con Claude Code API Error 500. Si se mezclan 500, 529 y 429, usa el router Claude Code 500/529/rate-limit.
Si la superficie es una excepción de SDK, distingue API status devuelto de excepción de conexión. Un objeto con status 500, headers y error body pertenece a este artículo. Una falla sin HTTP status pertenece a no-response branch. Por eso Claude API connection error empieza con la frontera de request ID.
Si la superficie es un gateway o provider route, compara en lugar de adivinar. Ejecuta el mismo prompt, model intent, input size, timeout class y runtime por direct Anthropic si tienes acceso. Luego ejecuta el gateway. Si direct funciona y gateway falla, el owner puede ser route mapping, provider capacity, credential ownership, proxy behavior o compatibility. Si ambos fallan igual con 500, la señal es más amplia, pero aún necesitas request identifiers del path original.
Si cambia el error exacto, cambia de rama. 529 overloaded_error es overload recovery. 429 rate_limit_error es límites y credential route. 504 timeout_error es duración y request shape. Sin respuesta es red, proxy, TLS, SDK timeout o route owner. Las salidas claras evitan que todo se reduzca a "intenta más tarde".
Paquete de escalación
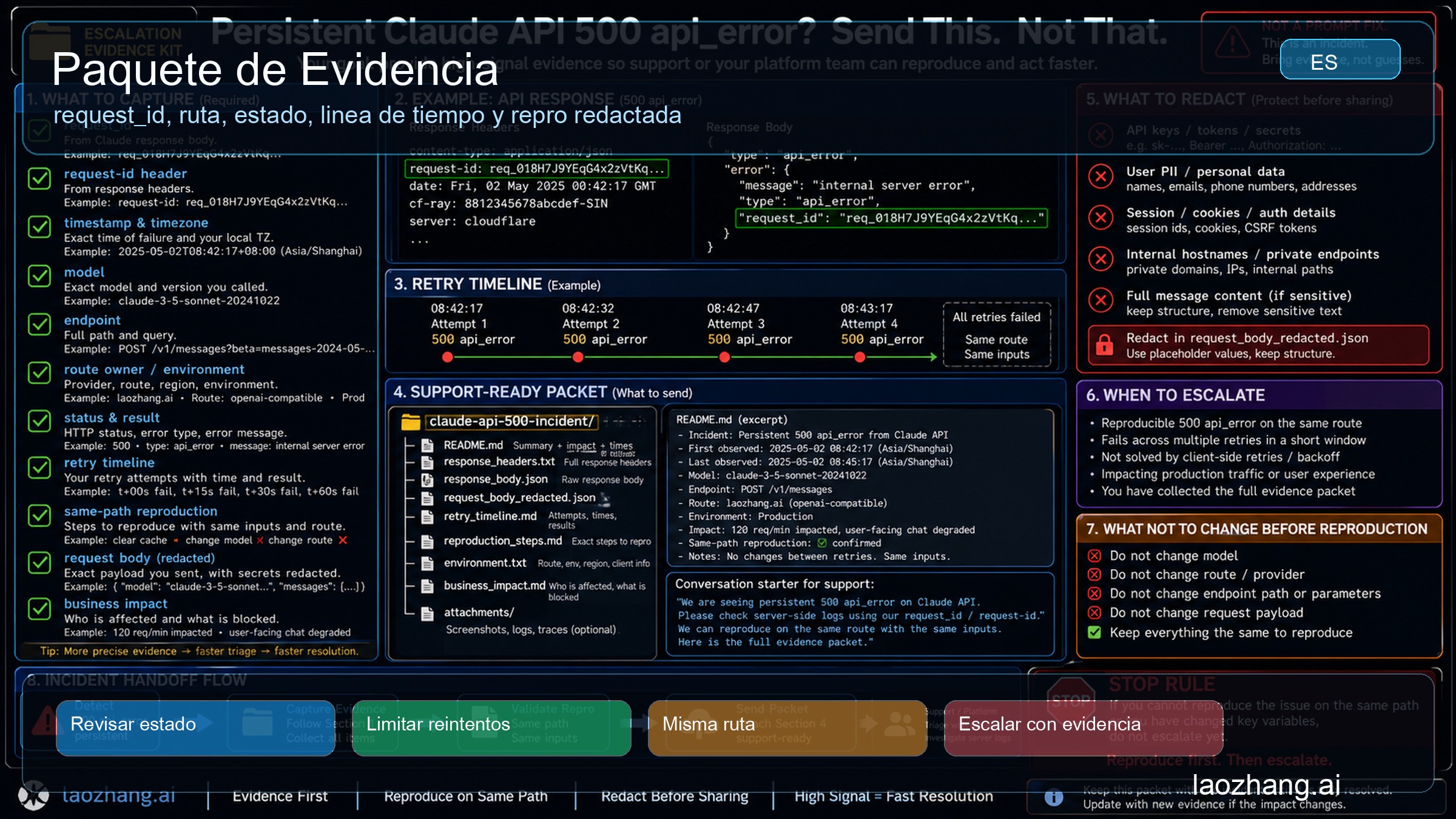
Escala después de completar el loop pequeño: status revisado, request evidence guardado, retry limitado y el mismo path todavía devuelve 500 api_error. A partir de ahí, los cambios aleatorios suelen empeorar la evidencia.
El paquete debe incluir exact HTTP status y error type; error body con request_id o header request-id; timestamp y timezone de cada intento; model, endpoint, SDK, SDK version y runtime; direct Anthropic, gateway, proxy o provider route owner; auth owner sin secretos; request size class; si era streaming o no; retry count, backoff window, jitter behavior y final result; estado de Claude Status en ese momento; mínima reproducción redactada; e impacto de negocio en una frase.
Mantén fuera los secretos. No pegues API keys, datos de clientes, prompts privados, logs completos de proxy ni variables de entorno sin redactar. Un buen paquete demuestra la rama y da trace handles. Un mal paquete obliga a soporte a leer ruido y crea riesgo de fuga.
La disciplina de mismo camino hace fuerte la escalación. "Hubo 500, cambié provider y funcionó" es evidencia débil. "Status green at 2026-05-02T13:51Z, same model and endpoint returned 500 api_error three times over a 40-second jittered budget, request IDs attached" es una señal que se puede investigar.
FAQ
¿Claude API Internal Server Error es lo mismo que 529 overload?
No. Anthropic define HTTP 500 como api_error y 529 como overloaded_error. Un 500 limpio pertenece a returned server-side error handling. Un 529 limpio pertenece a reducción de presión, cooldown y prevención de retry storm.
¿Claude Status en verde prueba que el problema es local?
No. Una página verde es una señal pública con timestamp. Reduce la rama de incidente activo, pero no prueba que tu model, endpoint, account route, región, SDK, gateway o request shape estén recuperados.
¿Debo rotar la API key primero?
No. Rotar key es una primera acción débil para un 500 api_error devuelto. Toca credenciales solo si hay evidencia de auth, key ownership, leakage o route mismatch.
¿Cuántos retries son seguros?
Usa un presupuesto, no un número universal. Limita attempts o elapsed time, añade jitter y reintenta solo trabajo seguro de repetir. Con efectos secundarios, primero necesitas deduplicación.
¿Y si aparece en Claude Code?
Usa la rama Claude Code. El terminal añade login state, session state, OAuth/API-key routing, shell proxy variables y command diagnostics. Empieza con /status y Claude Code API Error 500.
¿Qué envío a soporte?
Envía status code, error.type, error.message, request_id o request-id, timestamps, model, endpoint, SDK version, route owner, retry timeline, status result y reproducción redactada. Que sea corto y muestre claramente la rama 500 api_error.
Regla de trabajo
Claude API Internal Server Error es una rama de recuperación 500 api_error, no una razón para cambiar con pánico key, billing, prompt o provider. Revisa live status, conserva identifiers, reintenta poco con jitter, verifica el mismo path y escala solo cuando el mismo path sigue fallando con evidencia limpia.