
El modelo LLM API más barato no es un ganador permanente. Es el modelo que consigue el menor costo total sin romper tu calidad mínima, longitud de salida, tasa de caché, privacidad, latencia y contrato operativo. La revisión del 2 de julio de 2026 empieza con precios oficiales del dueño del modelo y después añade Batch/Flex, free tier, provider contracts, retries y costo por salida aceptada.
| Carga de trabajo | Primer carril barato | Ancla oficial de precio | Cuándo deja de ser barato |
|---|---|---|---|
| Extracción masiva, respuestas cortas, alto caché | deepseek-v4-flash | $0.0028 cache-hit input, $0.14 cache-miss input, $0.28 output por 1M tokens | si falla calidad, región, latencia o disponibilidad |
| Stack OpenAI, llamadas baratas, Batch/Flex | gpt-5-nano | $0.05 input, $0.005 cached input, $0.40 output; Batch/Flex baja más | si output, tool calls o retries dominan |
| Carril Google de menor escala pagada | gemini-2.5-flash-lite | $0.10 input, $0.40 output; Batch/Flex $0.05 / $0.20 | si necesitas ciclo de vida o calidad de 3.1 |
| Carril Google más nuevo de alto volumen | gemini-3.1-flash-lite | $0.25 input, $1.50 output; Batch/Flex $0.125 / $0.75 | si solo buscas el row Google más barato |
| Los modelos baratos fallan calidad | Claude Haiku 4.5 | $1 input, $5 output / MTok | si un carril más barato ya pasa la calidad |
Regla de parada: no elijas por precio de input. Ejecuta los mismos prompts reales y calcula input, cached input, output, tools, retries, latency, free-tier terms y contrato del provider. Después compara costo por salida aceptada.
Empieza por la tabla oficial
La página oficial del dueño del modelo es la primera fuente de verdad porque confirma model ID, unidad de facturación, precio actual, descuentos y caveats. Los agregadores ayudan a descubrir candidatos, pero no convierten sus filas en precios oficiales de OpenAI, Google, DeepSeek, Anthropic o Mistral. Separa siempre precio oficial del dueño del modelo, precio del proveedor y coste del gateway.
El 2 de julio de 2026, OpenAI pricing lista gpt-5-nano con input / cached input / output estándar de $0.05 / $0.005 / $0.40 por 1M tokens y filas Batch/Flex más bajas. Google pricing separa gemini-2.5-flash-lite de gemini-3.1-flash-lite: la primera es el carril Google más barato de escala, la segunda es más nueva pero más cara. DeepSeek pricing separa cache-hit, cache-miss y output para deepseek-v4-flash. Anthropic pricing muestra Claude Haiku 4.5 como carril Claude barato de calidad, no como el mínimo raw.
Fórmula de costo real
El costo real no es el sticker price de un input token. Es el costo de obtener una salida que pasa tu barra de aceptación. Si un modelo barato produce más salidas rechazadas, respuestas largas, errores de schema, tool calls adicionales o retries, su factura real puede superar a un modelo más caro.

Tu hoja de cálculo debe incluir input tokens, cached input, output tokens, tool calls, quality retries, Batch/Flex latency tradeoff, región, impuestos, data terms y soporte. Prueba 20-50 tareas representativas, guarda intentos, latencia P50/P95, tasa de aceptación y razón de fallo. Divide la factura total entre salidas aceptadas.
Elige el primer carril por workload
La extracción masiva depende de caché y schema validity. Los resúmenes cortos dependen de fidelidad y control de longitud. Coding requiere compile o test pass rate. Agent loops multiplican tool calls y llamadas repetidas. Long-context analysis necesita citas fieles y latencia manejable. En output crítico, un modelo más caro puede ser más barato si reduce revisión humana.
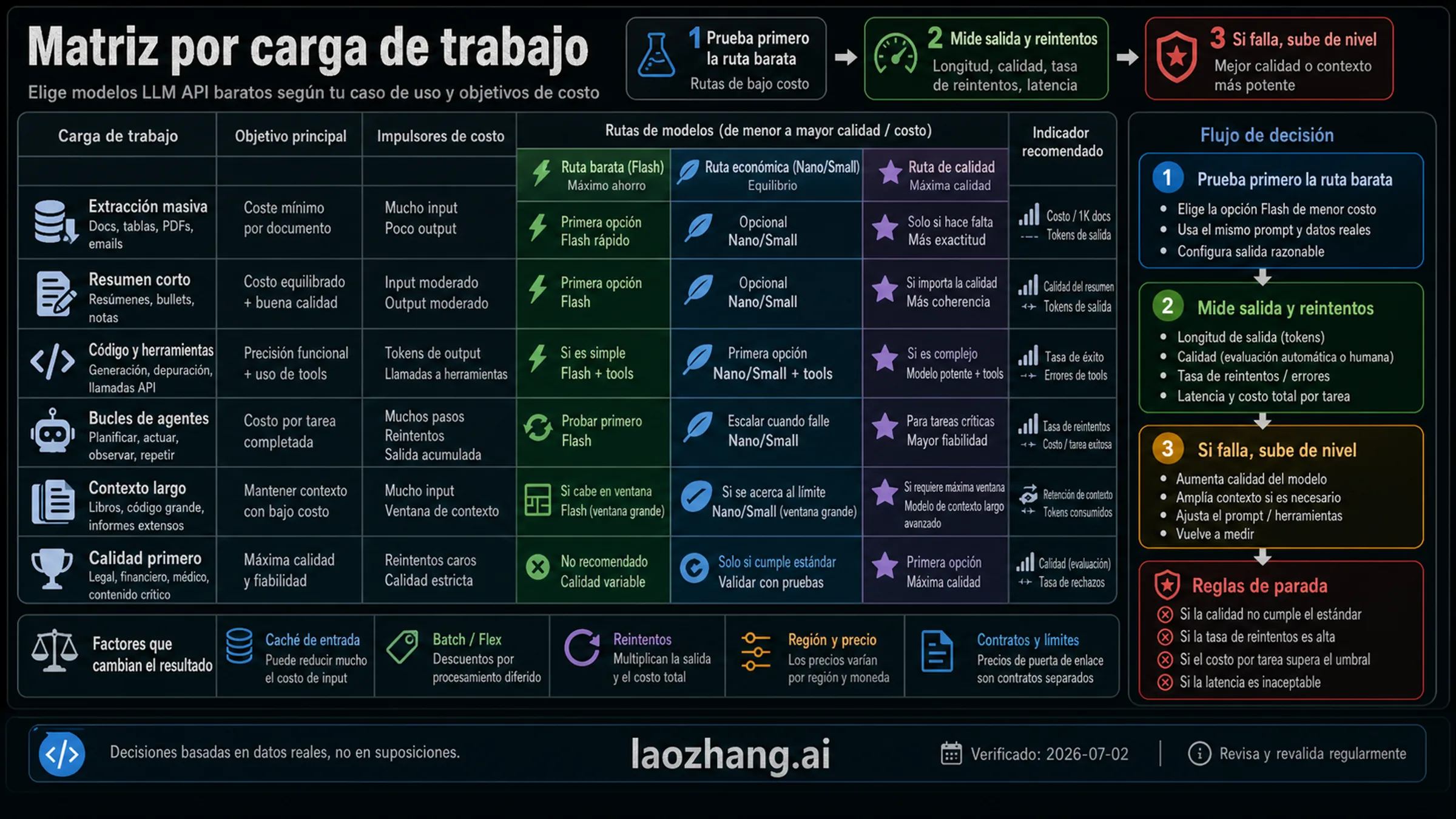
No empieces con diez modelos. Elige dos carriles baratos, define acceptance bar y fija upgrade trigger. Si el carril barato falla calidad o sube retries, pasa al siguiente nivel. Si dos rutas cuestan parecido, pesa soporte, contrato, observabilidad y facilidad de migración.
Free tier no es precio de producción
Free tier sirve para aprender, probar prompts y hacer prototipos. Producción necesita capacidad predecible, billing owner, data terms, soporte y fallback. Google pricing separa Free Tier de Paid Tier y también cambia la frontera de uso de datos. Esa diferencia importa si tus prompts contienen customer data, source code o logs.
Trata free route como proof-of-fit, no como budget. Antes de producción confirma model ID, serving mode, quota, rate limits, billing state, data policy, Batch/Flex y overage behavior. Si hay usuarios reales o datos sensibles, el contrato importa más que el costo cero inicial.
Gateway y provider son contratos separados
Un gateway puede reducir migration cost: endpoint OpenAI-compatible, cambio de modelos, logs y un support owner. Pero gateway price no es official vendor price. Si OpenRouter, SiliconFlow, laozhang.ai u otro provider muestra una fila más barata, verifica model ID exacto, billing unit, cache behavior, failed-call billing, rate limits, refunds y data policy.
Para laozhang.ai, la recomendación segura es condicional: evalúalo como gateway para migración compatible con OpenAI, cobertura de modelos, logs y routing. Los precios exactos deben verificarse en el console/API actual, no copiarse desde screenshots viejos o aggregators.
Checklist antes de gastar
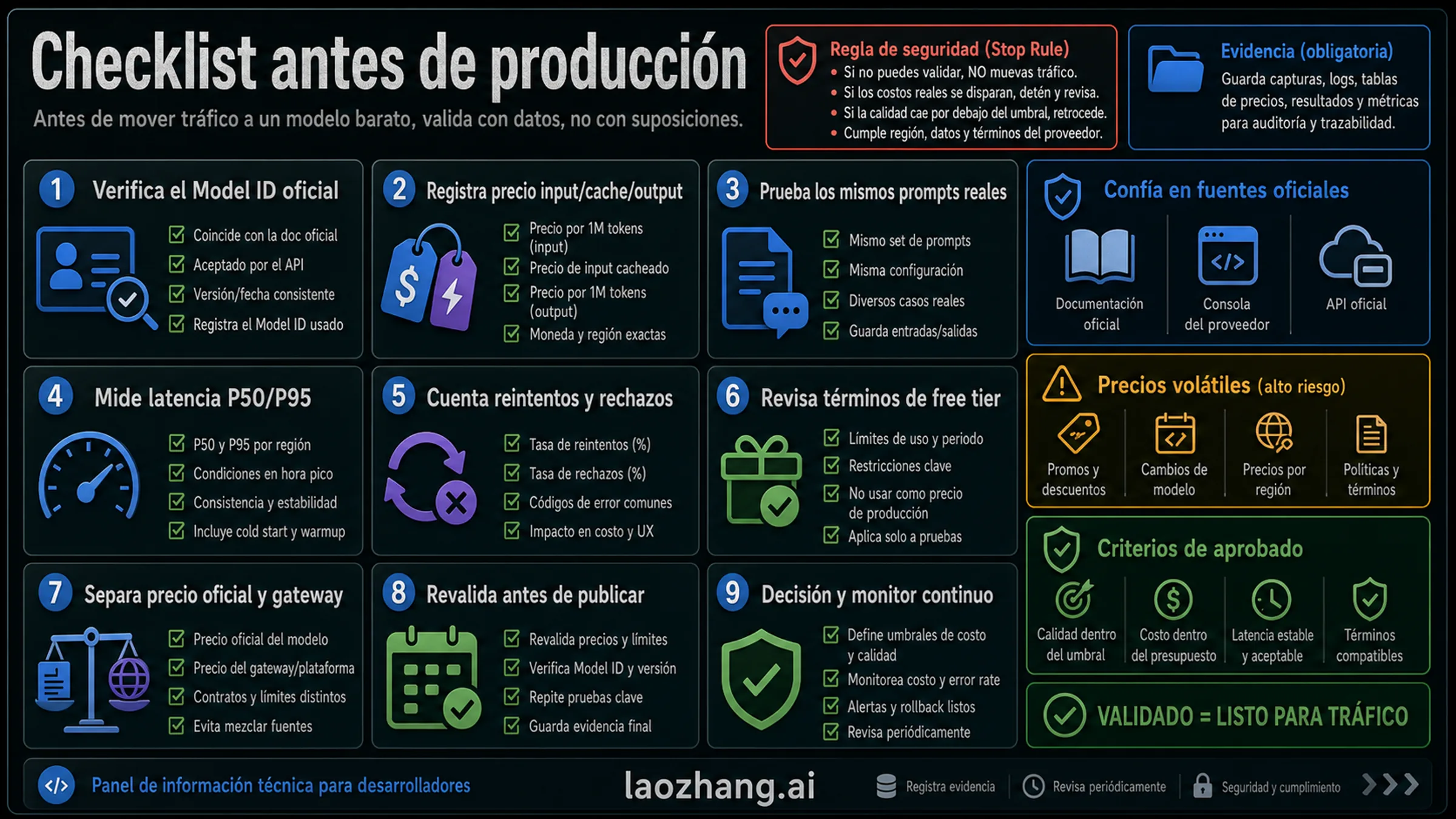
- Verifica el model ID oficial.
- Registra input, cached input, output y Batch/Flex.
- Prueba los mismos prompts reales.
- Mide P50/P95 latency y concurrencia.
- Cuenta retries, refusals, errores de schema y tool calls.
- Separa precio oficial, precio del proveedor y coste del gateway.
- Pon spend cap y kill switch en agentes y batch jobs.
- Revalida precio y disponibilidad antes del lanzamiento.
Puntos de partida recomendados
Si buscas el lowest official paid token floor, prueba DeepSeek V4 Flash, pero valida calidad, región y disponibilidad. Si tu stack es OpenAI-native, mira gpt-5-nano y si Batch/Flex encaja con tu latencia. Si necesitas carril barato Google, empieza por gemini-2.5-flash-lite y compara gemini-3.1-flash-lite solo si necesitas la nueva lane. Si los baratos fallan, mide Claude Haiku 4.5 como baseline de calidad.
La conclusión final no debe ser "este proveedor siempre gana". Debe decir: con este prompt set, output length, cache hit rate y quality bar, este modelo tiene el menor costo por salida aceptada.
Plantilla de prueba presupuestaria
Antes de comprar capacidad o aprobar un presupuesto de producción, no copies la tabla de precios como si fuera el coste final. Construye un registro pequeño para tu propia carga: mismos prompts, mismo system prompt, mismos fragmentos de RAG, mismos límites de salida y el mismo criterio de aceptación. Para cada candidato registra tokens de entrada, prefijo reutilizable en caché, tokens de salida, errores de formato, rechazos, tiempo de reparación manual, latencia p50/p95, región, cuota, propietario de soporte y estado final aceptado. Solo con ese registro puedes comparar el coste por salida aceptada.
| Campo presupuestario | Cómo medirlo | Por qué cambia el ganador |
|---|---|---|
| Tokens de entrada | Separa system prompt, texto de usuario, contexto recuperado y tool schemas | El contexto largo favorece una fila de entrada barata solo cuando realmente se necesita |
| Entrada cacheada | Mide prefijo reutilizable y tasa de cache hit | Una fila cache-hit barata solo importa con reutilización alta |
| Tokens de salida | Define longitud esperada y máxima por tarea | La salida suele costar más que la entrada y puede cambiar el ranking |
| Reintentos de calidad | Cuenta errores de schema, errores factuales, rechazos y edición humana | Una llamada barata se vuelve cara si baja la tasa de aceptación |
| Batch/Flex | Separa trabajos asíncronos de flujos en tiempo real | El descuento sirve solo si el negocio puede esperar |
| Límite contractual | Separa precio oficial, contrato del proveedor y coste del gateway | Soporte, logs, reembolsos y datos también son coste de producción |
Usa al menos tres conjuntos de prueba. El primero debe cubrir tareas cortas y estables: extracción, clasificación, etiquetado, deduplicación y limpieza de campos. Ahí suelen destacar carriles baratos como DeepSeek V4 Flash, OpenAI nano o Google Flash-Lite. El segundo debe cubrir salidas más largas pero acotadas: resúmenes, comparaciones, borradores de correo, descripciones de producto o secciones de informe. Ahí pesan la longitud de salida, los errores factuales y el control del formato. El tercero debe cubrir tareas de alto riesgo: cambios de código, revisión contractual, razonamiento financiero o agentes con varios pasos. En esas tareas la fila de token es solo el punto de entrada; importan más la tasa de aprobación, la trazabilidad y la reducción de revisión humana.
Si un carril barato gana en extracción pero falla en resúmenes largos, no lo conviertas en el modelo predeterminado de toda la aplicación. Enruta por tarea. Pon trabajos cortos y deterministas en el carril barato, limita longitud y reintentos en tareas medias, y conserva un modelo más fuerte como línea base para código, cumplimiento o agentes. Ese enrutamiento es más defendible que un ranking de marcas porque explica cuándo la fila más barata deja de ser la opción más barata de producción.
Antes de lanzar, haz una revisión inversa. El responsable de negocio confirma si la salida se puede usar sin reescritura. El responsable de ingeniería revisa latencia, rate limits, fallos y observabilidad. El responsable de seguridad revisa política de datos, retención de logs, región y soporte. Si cualquiera de los tres rechaza el carril, el precio bajo por token todavía no es ahorro operativo.
Flujo de verificación antes del gasto
Toda comparación sensible a precios necesita una rutina fechada. El día de publicación vuelve a abrir las páginas oficiales y confirma model ID, precio de entrada, precio de entrada cacheada, precio de salida y filas Batch/Flex. Después confirma que no mezclas condiciones de nivel gratuito con supuestos de pago, especialmente uso de datos, cuotas, soporte y disponibilidad.
Si usas un gateway o un proveedor compatible con OpenAI, registra su precio como un contrato separado. Verifica model ID real, unidad de facturación, cobro por llamadas fallidas, rate limits, reembolsos, logs y política de datos. Luego ejecuta una pequeña prueba de factura con los mismos prompts. No mires solo el coste promedio: revisa coste p95, coste de tareas fallidas y coste por salida aceptada. Finalmente escribe disparadores de subida: tasa de fallo de schema por encima del umbral, reparación manual excesiva, latencia p95 alta, fallo regional o incompatibilidad de datos. Esos disparadores convierten la comparación en una regla operativa.
Preguntas frecuentes
¿Cuál es el modelo LLM API más barato ahora?
DeepSeek V4 Flash y OpenAI gpt-5-nano son los primeros checks baratos; en Google, gemini-2.5-flash-lite es el carril barato de escala. El ganador final depende del workload.
¿DeepSeek siempre es el más barato?
No. Sus filas son muy bajas, pero calidad, latencia, región o disponibilidad pueden subir el costo real con retries y revisión.
¿Un free LLM API sirve para producción?
Normalmente no como precio de producción. Free tier sirve para prototipos; producción requiere quota, paid terms, soporte, data policy y billing.
¿Qué modelo barato uso para coding?
Prueba DeepSeek, OpenAI nano, Google Flash-Lite y tu provider actual con tareas reales. Ordena por test pass rate y costo por salida aceptada.
¿Claude es demasiado caro?
Su raw token row es más alto, pero Claude Haiku 4.5 puede ser más barato en trabajos de calidad si reduce retries y revisión humana.
¿Puedo confiar en agregadores de precios?
Úsalos para discovery. Antes de gastar, vuelve a la página oficial del dueño del modelo o al console del provider.