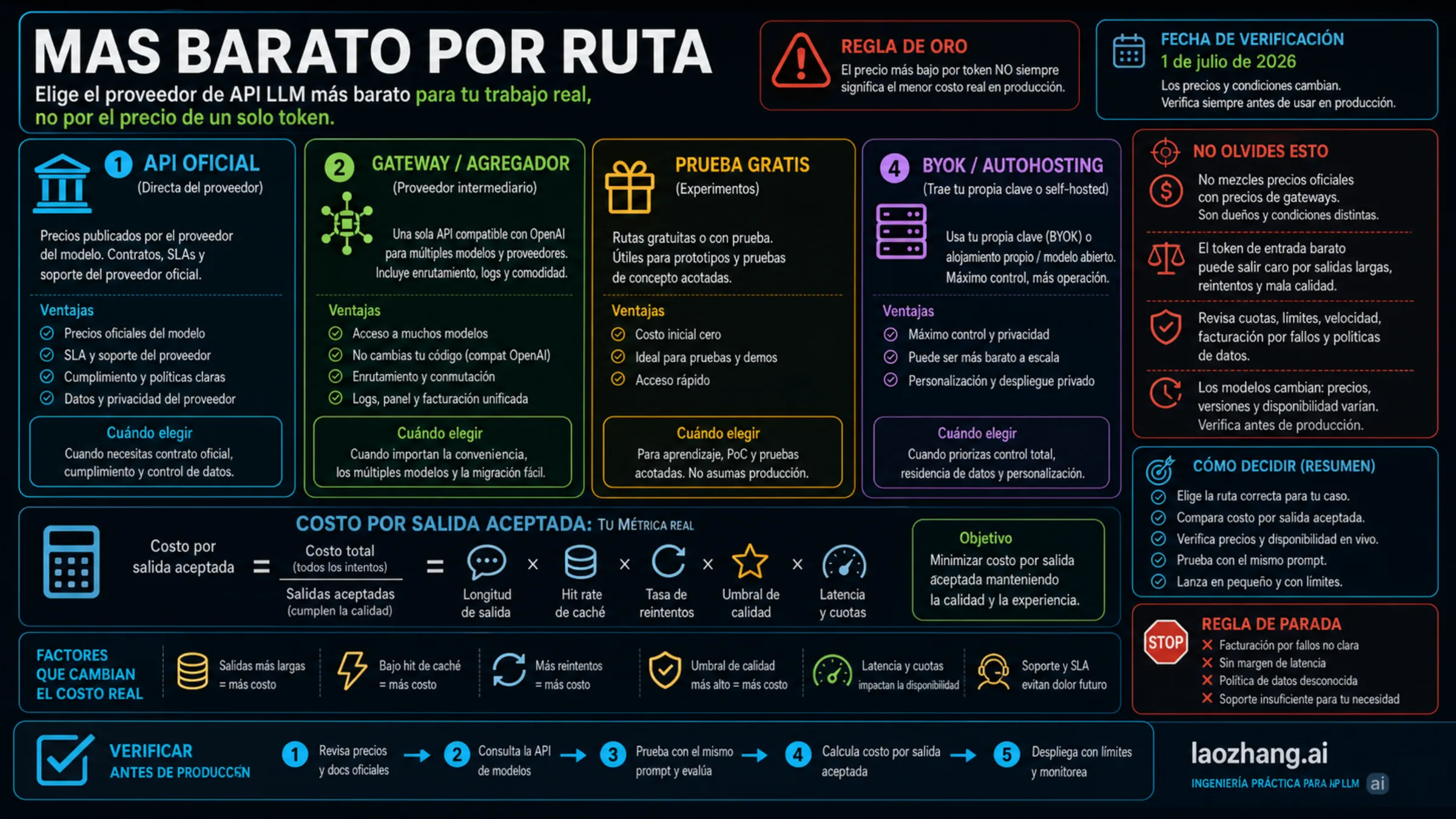
El proveedor API LLM más barato no es una empresa fija. Es la ruta que sigue siendo barata después de aplicar tu prueba de calidad. A 1 de julio de 2026, DeepSeek V4 Flash es el suelo de token oficial pagado más bajo verificado en esta comparación. Esa frase solo sirve para empezar. La elección de producción también depende de longitud de salida, tasa de caché, rechazos, reintentos, latencia, cuota, comisión de gateway, dueño del soporte, términos de datos y coste de migración.
Empieza por el dueño de la ruta. Una API oficial directa te da la fila de precio del vendor, la unidad de facturación, el aviso de ciclo de vida y el contrato de soporte. Un gateway o agregador puede ser más barato en la práctica cuando ofrece una superficie compatible con OpenAI, muchos modelos, logs, failover y un único camino operativo. Una ruta gratuita sirve para experimentos y muestras con el mismo prompt. BYOK o self-hosting solo gana cuando operación, utilización y latencia están controladas.
| Ruta | Primera prueba | Por qué puede ser barata | Regla de parada |
|---|---|---|---|
| API oficial directa | DeepSeek V4 Flash para el suelo pagado; Gemini 2.5 Flash-Lite Batch/Flex para trabajo batch barato | Precios del vendor, unidades más claras, avisos directos de ciclo de vida | Para si calidad, región, cuota o lifecycle no encajan con la carga. |
| Gateway o agregador | OpenRouter, SiliconFlow o laozhang.ai después de verificar modelo/API en vivo | Una API compatible, cambio de modelos, logs y soporte consolidado reducen coste de ingeniería | Para si fee, llamadas fallidas, dueño de soporte, cuota o política de datos no son claros. |
| Ruta gratuita experimental | Modelos gratis, créditos de prueba, sandbox | Sirve para prototipos y comparación de prompts | Para antes de producción si no verificaste límites, términos, uptime y soporte. |
| BYOK o self-hosting | Tu key, tu cloud o tu stack de inferencia | Control de datos y economía unitaria a largo plazo | Para si operación, mantenimiento, GPU utilization o latencia borran el ahorro. |
La fórmula rápida es: coste efectivo = factura total / salidas aceptadas. No muevas tráfico de producción hasta ejecutar los mismos prompts, verificar las unidades facturables actuales, registrar fallos y reintentos, y lanzar un segmento pequeño con límite de gasto.
Rutas Oficiales De Bajo Coste
Los precios oficiales son el ancla más segura porque el vendor del modelo posee la fila. Aun así son incompletos. Un modelo con input muy barato puede perder si necesita respuestas más largas, falla schemas, tarda demasiado o requiere fallback más caro para las tareas que no resuelve.
Las filas verificadas el 1 de julio de 2026 son: DeepSeek V4 Flash: $0.14 cache-miss input and $0.28 output per 1M tokens, cache-hit input much lower; Gemini 2.5 Flash-Lite: $0.10 input and $0.40 output, Batch/Flex $0.05/$0.20; OpenAI gpt-5.4-nano: $0.20 input and $1.25 output; Mistral Small 4: $0.15/$0.60; Claude Haiku 4.5: $1/$5. Estas filas no son una recomendación de compra por sí solas. Son carriles candidatos para una prueba controlada.
| Ruta oficial | Fila barata actual | Por qué importa | Límite |
|---|---|---|---|
| DeepSeek direct | DeepSeek V4 Flash: input cache-miss $0.14 y output $0.28 por 1M tokens; cache-hit input es mucho menor | El suelo oficial pagado más bajo verificado aquí | No lo trates como mejor opción para todo código, razonamiento, región o fiabilidad. DeepSeek también avisa de deprecación de compatibilidad para deepseek-chat y deepseek-reasoner el 2026-07-24 15:59 UTC. |
| Google Gemini API | Gemini 2.5 Flash-Lite: input $0.10 y output $0.40 por 1M tokens; Batch/Flex $0.05/$0.20 | Ruta oficial fuerte cuando la latencia puede ser batch-like | No reutilices precios antiguos de Gemini 2.0 Flash-Lite como consejo actual. |
| OpenAI API | gpt-5.4-nano: input $0.20 y output $1.25 por 1M tokens; Batch/Flex es menor | Línea barata propiedad de OpenAI cuando tooling, policy y compatibilidad importan | No es el suelo pagado más bajo, pero puede reducir riesgo de migración y fiabilidad. |
| Mistral API | Mistral Small 4: input $0.15 y output $0.60 por 1M tokens | Competitiva para open-model route y necesidades de gobernanza europea | Compara gobernanza, calidad, latencia y disponibilidad juntas. |
| Anthropic API | Claude Haiku 4.5: input $1 y output $5 por MTok; Sonnet 5 introductory pricing termina el 2026-08-31 | No es la ruta bruta más barata, pero puede reducir revisión y reintentos | Mantén visible la fecha y agenda una revisión antes del corte. |
La lectura práctica no es "elige siempre DeepSeek". Es "usa DeepSeek V4 Flash como primera prueba pagada barata, y demuestra que tu carga acepta la salida". Si el modelo barato duplica las salidas rechazadas, la tabla de precios escondió el coste real.
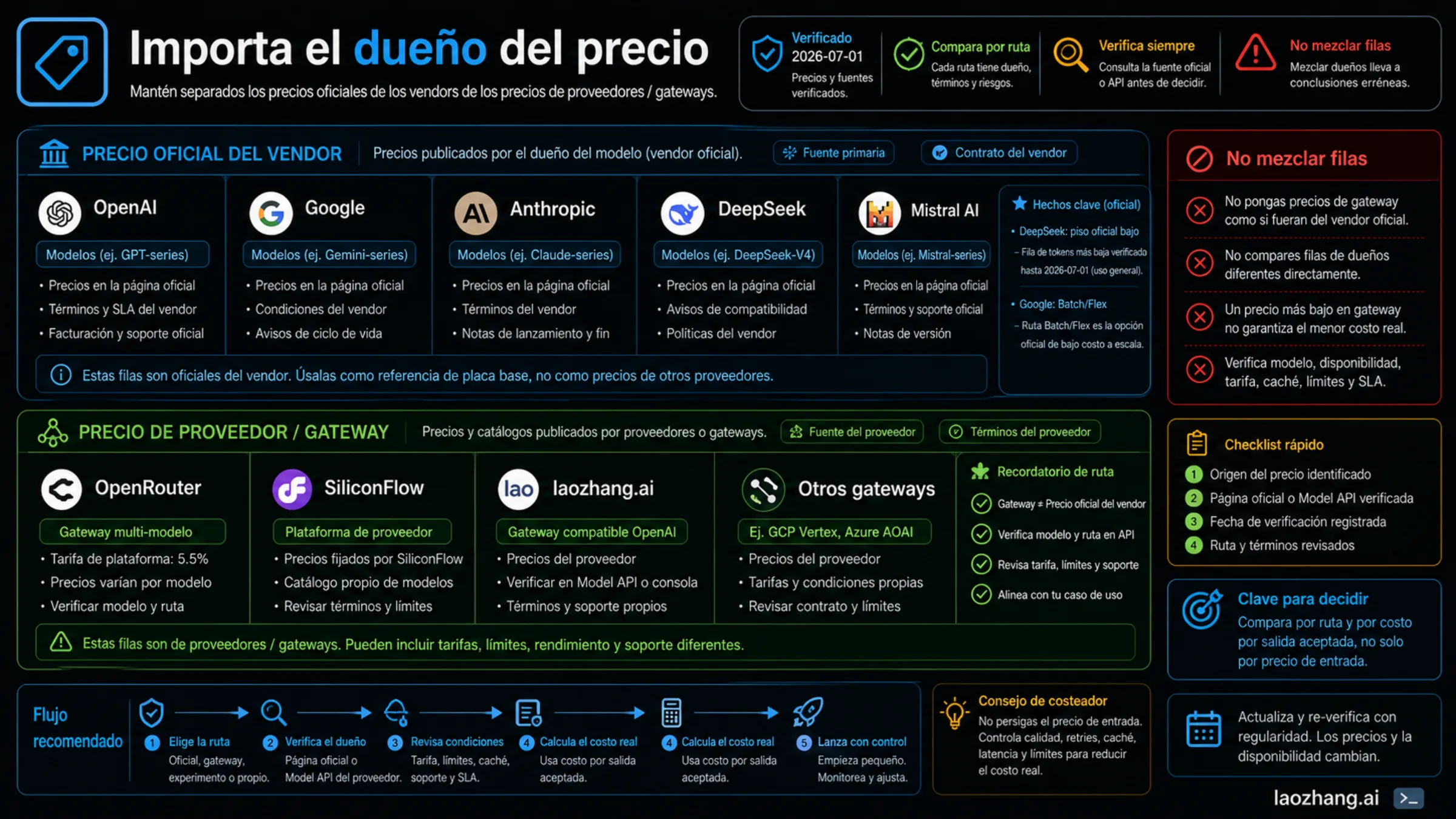
Rutas Gateway Y Provider
Gateways y agregadores son rutas de provider. Pueden bajar el coste total cuando compatibilidad API, amplitud de modelos, logs, routing y soporte consolidado ahorran más ingeniería que la comisión. También pueden añadir un segundo límite contractual, comportamiento regional distinto, facturación de fallos poco clara o filas de precio que no son oficiales del vendor.
| Ruta provider | Qué verificar | Por qué puede servir | No afirmes |
|---|---|---|---|
| OpenRouter | Fila de modelo, provider route, tokenizer, límites de modelos gratis, fee Pay-as-you-go de 5.5% | Catálogo amplio, pruebas sin mínimo, Models API con orden pricing-low-to-high | No llames su metadata precio oficial de OpenAI, Google, Anthropic, DeepSeek o Mistral. |
| SiliconFlow | Precio propiedad del provider, versión, región, términos y disponibilidad actual | Ruta visible de familia DeepSeek que puede ayudar con pago, región u operación | No trates una fila DeepSeek de SiliconFlow como DeepSeek direct pricing. |
| laozhang.ai | Lista actual de modelos, feature flags, fila exacta, billing mode, logs, soporte, consola/API | Útil para migración OpenAI-compatible, cambio de modelos, visibilidad de uso y un dueño de soporte | No publiques precios exactos por modelo sin Models API o consola actual. |
Para laozhang.ai, la recomendación segura es condicional. Entra en la comparación cuando el trabajo es acceso por gateway, migración compatible con OpenAI, comprobación de cobertura de modelos, logs de uso o consolidación de soporte. No reemplaza precios oficiales cuando necesitas filas propiedad del vendor, lifecycle oficial o soporte directo. La documentación pública describe integración pay-as-you-go y Models API compatible con OpenAI; eso es una ruta de verificación, no permiso para congelar una tabla vieja.
Calcula El Coste Por Salida Aceptada
El proveedor práctico más barato es el que entrega el coste más bajo por salida aceptada en tu barra de calidad. El precio bruto de input ignora muchas variables que mueven la factura.

Coste por salida aceptada = factura total del sample run / salidas que pasaron la barra de aceptación.
| Variable | Por qué cambia el ganador | Qué medir |
|---|---|---|
| Input tokens | System prompts, schemas de tools, retrieval chunks e historial pueden dominar tareas cortas | Input facturable medio por tarea aceptada |
| Output tokens | Algunos modelos necesitan respuestas más largas para pasar revisión | Longitud media de salida aceptada |
| Cache hit rate | Workflows con prompt pesado pueden abaratarse con cached input | Proporción cacheable y porcentaje de hits |
| Retry rate | Timeouts, schema failures, razonamiento débil o refusals crean intentos facturables | Attempts por respuesta aceptada |
| Quality threshold | Una barra alta rechaza más salidas baratas | Acceptance rate de una muestra etiquetada |
| Latency and quota | Rate limits fuerzan fallback caro o batch delay | P95 latency, TPM/RPM headroom, fallback share |
| Gateway fee | Platform fee, markup, failed-call billing o mínimo cambian la factura | Factura completa del provider / salidas aceptadas |
Ejemplo: Provider A cuesta $0.20 por 1.000 salidas candidatas, pero solo 600 se aceptan. Su coste es $0.000333 por salida aceptada. Provider B cuesta $0.25, pero 900 salidas pasan. Su coste es $0.000278. B parece más caro en la tabla y más barato en el producto. Por eso la hoja de cálculo debe incluir factura, tasa de aceptación, latencia, intentos fallidos y límite de soporte.
Gratis, Trial, BYOK Y Self-Hosted
El acceso gratuito es valioso, pero no es precio de producción. Suele ser un trial, un modelo de gateway con cuota, un sandbox educativo o una promoción temporal. Cada ruta debe alimentar la prueba con el mismo prompt, no reemplazar la debida diligencia.
| Carril | Bueno para | Coste oculto | Límite de producción |
|---|---|---|---|
| Modelo gratis en gateway | Prototipos, demos, prompt comparison | Límites estrictos, prioridad menor, cambios de ruta, fallback | No dependas hasta verificar términos, rate limits y uptime. |
| Trial credits del vendor | Comparar una API oficial nueva | Expiración, account limits, disponibilidad regional | Cambia a filas pagadas antes del cálculo de lanzamiento. |
| BYOK through gateway | Mantener tu cuenta vendor usando un router | Gateway fee, key management, support split, data path | Debes saber si el fallo lo posee vendor o gateway. |
| Self-hosted open model | Control de datos y workloads de alta utilización | GPU utilization, monitoring, calidad de cuantización, mantenimiento | Solo es más barato con alta utilización y calidad suficiente. |
En decisiones de producción en español, "API gratis" y "API barata" deben separarse. La ruta gratis crea evidencia. La ruta operativa necesita billing predecible, logs, fallback y dueño del soporte.
Flujo De Verificación Antes De Cambiar
No migres tráfico de producción desde una tabla estática. Usa la tabla para elegir candidatos y verifica la ruta viva.
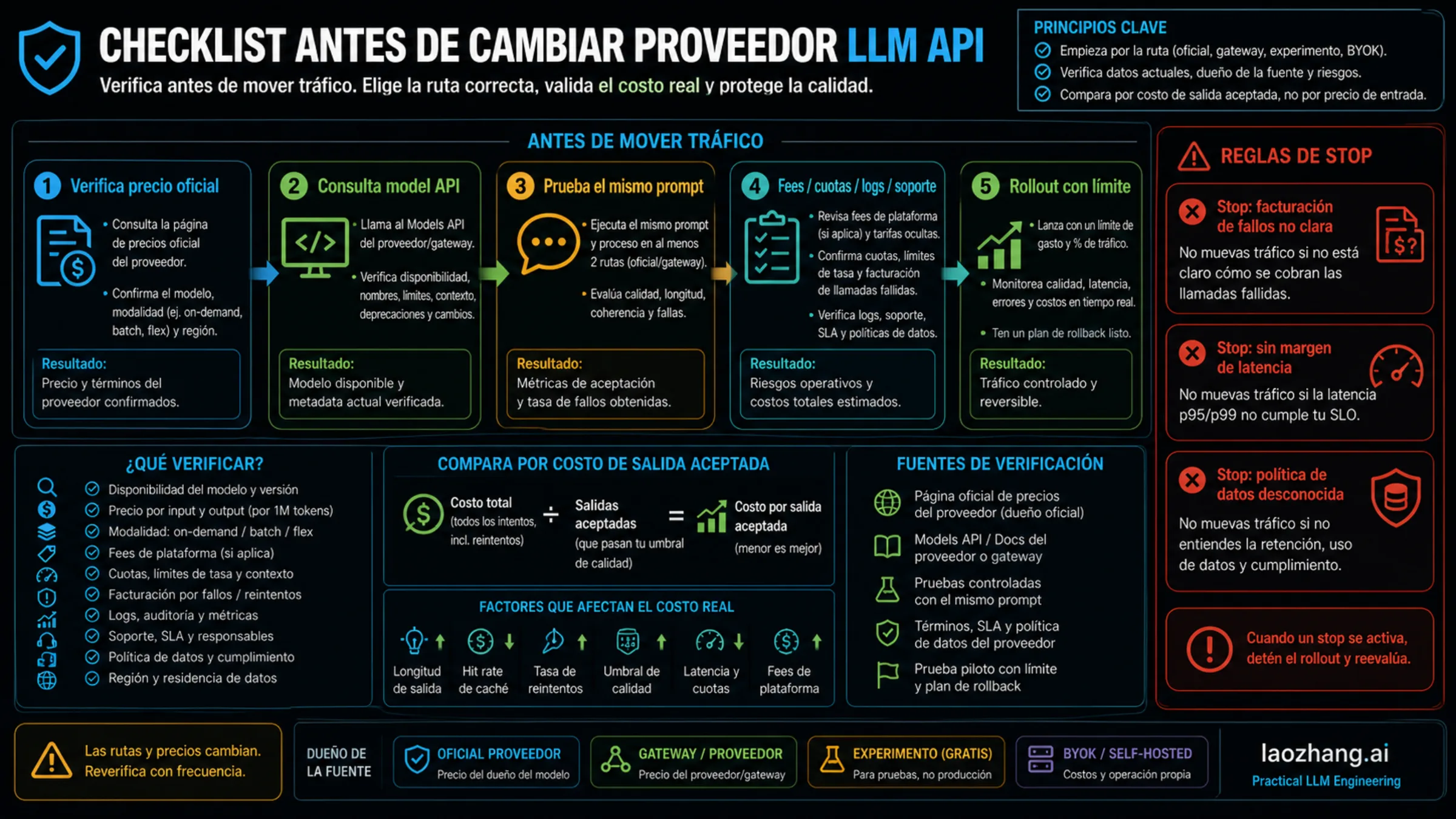
- Revisa la página oficial de precios del vendor para la fila de API directa.
- Si usas gateway, consulta metadata actual de modelo/API o consola antes de citar precio provider.
- Ejecuta el mismo set de prompts contra cada ruta candidata.
- Registra input tokens, output tokens, caché, fallos, reintentos, latencia y salidas aceptadas.
- Compara factura total dividida por salidas aceptadas.
- Inspecciona failed-call billing, quota, logs, support owner, data retention y términos regionales.
- Mueve solo un slice pequeño con spend cap, quality fallback y rollback.
Para la migración si no está clara la facturación de llamadas fallidas, si la latencia no tiene margen de concurrencia, si el nombre de modelo está cerca de un cambio de ciclo de vida, si los logs no bastan para control de presupuesto, si los términos de datos chocan con la carga o si el provider no explica quién posee fallos upstream. Una ruta barata que no se puede monitorear no es suficientemente barata.
Recomendaciones Por Carga De Trabajo
Usa estas filas como primeras pruebas, no como respuestas de compra.
| Carga | Primera ruta a probar | Backup | Por qué |
|---|---|---|---|
| Chat barato, extracción, resumen ligero | DeepSeek V4 Flash direct | Gemini 2.5 Flash-Lite u OpenAI gpt-5.4-nano | Empieza por el suelo oficial pagado y mide aceptación y salida. |
| Resumen asíncrono a gran escala | Gemini 2.5 Flash-Lite Batch/Flex | OpenAI Batch/Flex low-cost rows | Batch puede ganar cuando la latencia no urge. |
| Migración OpenAI-compatible con muchos modelos | OpenRouter o laozhang.ai tras live verification | API oficial directa del modelo ganador | El gateway puede ahorrar ingeniería después de revisar fee y dueño del precio. |
| Acceso DeepSeek-family por provider route | DeepSeek direct primero; luego SiliconFlow si ayuda región, pago u operación | Otro gateway con metadata verificada | Las filas DeepSeek provider-owned necesitan etiqueta provider y verificación actual. |
| Coding o agents | Same-prompt test en DeepSeek, OpenAI, Claude y gateway fallback | Modelo con menor coste por salida aceptada | Retry rate y tool reliability pueden dominar el token bruto. |
| Workloads con gobernanza | Mistral o direct route con región y términos requeridos | BYOK o self-hosting si la operación es realista | Compliance y data owner pueden justificar pagar más. |
Un mismo producto puede usar varios providers. Un classifier puede correr en una fila oficial barata, un coding assistant puede necesitar un modelo más fuerte y un gateway puede encargarse solo del fallback. Forzar una sola empresa para todo suele ser más caro.
Checklist Del Provider
Antes de llamar barata a una ruta, responde por escrito. ¿Quién posee la fila de precio: model vendor, gateway, cloud platform, reseller o tu equipo de infraestructura? ¿La fila es input-only, output-only, cached input, batch/flex, per request, per second o tool-call? ¿Qué versión, región y lifecycle cubre? ¿Cómo se facturan llamadas fallidas, timeouts, safety refusals y reintentos? ¿Cómo funcionan RPM, TPM, daily quota y spend limit? ¿Logs, exportación de uso y alerting bastan para controlar presupuesto? ¿Quién posee soporte cuando falla el modelo upstream? ¿Qué términos de data retention, training y región aplican? ¿La ruta pasa tu same-prompt set en la barra de calidad elegida? ¿El rollout tiene cap para que un fallo no cree una factura abierta?
Este checklist es más estricto que una tabla de precios porque convierte precio en coste desplegable. También crea la pista de auditoría que un equipo necesita cuando cambia un nombre de modelo, una comisión de platform o una regla gratuita.
Preguntas frecuentes
¿Cuál es el proveedor API LLM más barato ahora?
Para el suelo de token oficial pagado verificado el 1 de julio de 2026, DeepSeek V4 Flash es la fila más baja de esta comparación. No significa que sea el proveedor práctico más barato para todas las cargas. Compara coste por salida aceptada con longitud de salida, caché, reintentos, latencia, cuota y support owner.
¿OpenRouter es más barato que una API directa?
A veces. OpenRouter puede reducir trabajo de integración y exponer muchos modelos en un gateway, pero Pay-as-you-go incluye platform fee y el precio depende de la ruta elegida. Trátalo como metadata propiedad del gateway y verifica la fila en vivo antes de producción.
¿Debería usar laozhang.ai como proveedor más barato?
Usa laozhang.ai cuando el trabajo sea gateway access: migración API compatible con OpenAI, model switching, visibilidad de uso y un único support owner. No lo llames el proveedor más barato salvo que Models API o consola actual pruebe el precio exacto del modelo para tu carga.
¿Las API LLM gratuitas son seguras para producción?
Asume que no hasta verificar límites, términos, uptime, quota, logs y soporte. Las rutas gratis son buenas para prompt comparison y prototipos. Producción necesita billing predecible y rollback.
¿Por qué puede perder un input price bajo?
Porque la factura no es solo input tokens. Salidas largas, baja caché, schema failures, reintentos, revisión estricta, latency fallback y gateway fee pueden subir el coste por salida aceptada.
¿Cada cuánto hay que revisar precios?
Revisa antes de cada migración de producción, antes de subir volumen, y cuando cambien lifecycle notes, platform fee o términos de ruta gratuita. Las filas con fecha necesitan revisión programada antes del cutoff.
Bottom Line
Usa el suelo oficial de token para elegir el primer candidato, no para decidir el proveedor final. DeepSeek V4 Flash merece la primera prueba pagada barata para muchas cargas de texto. Gemini 2.5 Flash-Lite Batch/Flex merece prueba seria para escala asíncrona. OpenAI, Anthropic y Mistral pueden ganar cuando compatibilidad, calidad, gobernanza o fiabilidad reducen salidas rechazadas. Gateways como OpenRouter, SiliconFlow y laozhang.ai pueden ganar cuando routing, logs, compatibilidad API o soporte consolidado ahorran más que la comisión. La decisión final es operativa: verifica la fila actual, ejecuta los mismos prompts, divide la factura completa por salidas aceptadas y despliega detrás de un cap.